LLMs之 Ranking:OpenRouter LLM Rankings的简介、安装和使用方法、案例应用之详细攻
LLMs之 Ranking:OpenRouter LLM Rankings的简介、安装和使用方法、案例应用之详细攻
目录
OpenRouter LLM Ranking的简介
1、特点
2、榜单解读
Leaderboard(总榜)
Categories
Programming
Roleplay
Marketing
SEO
Tool Calls
Images
Top Apps
OpenRouter LLM Ranking的核心内容
1、背景(Why)
2、目标与设计原则 (What)
3、数据与评测方法 (How)
数据来源:
评测方法:
4、维度与指标体系
核心指标:
主要维度:
OpenRouter LLM Ranking的使用方法
1、排名结果与解读 (Results & Insights)
2、实际应用价值 (So What)
3、限制与展望 (Limitations & Future Work)
限制
展望
OpenRouter LLM Ranking的简介
OpenRouter LLM Rankings 是一个动态的排行榜,它展示了在 OpenRouter 平台上各个大型语言模型(LLM)的实际使用情况。与基于学术基准测试的排行榜不同,该排行榜的核心是追踪和展示不同模型在真实世界应用中的“Token 使用量”,从而反映出模型在市场上的受欢迎程度和应用广度。它不仅对单个模型进行排名,还提供了多个维度来分析整个 LLM 生态系统的动态。
官网地址:https://openrouter.ai/rankings
1、特点
- 基于真实使用量排名: 排行榜的核心指标是“Token usage”(Token 使用量),这代表了模型在 OpenRouter 平台上的实际消耗量,直接反映了其在开发者和应用中的流行度。
- 多时间维度分析: 用户可以查看不同时间范围内的排名,包括“Top today”(今日热门)、“Top this week”(本周热门)和“Top this month”(本月热门),从而观察模型的短期和长期趋势。
- 多维度分类与比较: 提供了极其丰富的分类视角来比较模型:
- 按模型作者(Market Share): 比较不同公司或组织(如 x-ai, google, anthropic)所占的市场份额。
- 按用例(Categories): 比较模型在特定应用场景下的受欢迎程度,涵盖编程、角色扮演、市场营销、SEO、科技、科学、翻译等十多个领域。
- 按自然语言(Languages): 比较模型在处理不同人类语言(如英语、中文、西班牙语等)时的使用情况。
- 按编程语言(Programming): 比较模型在处理不同编程语言(如 Python, JavaScript, Java)时的使用情况。
- 按特定能力(Tool Calls, Images): 单独追踪模型在工具调用(Tool Calls)和图像处理(Images)等高级功能上的使用量。
- 应用生态透明化: “Top Apps”板块列出了在 OpenRouter 上消耗 Token 最多的公开应用,并注明了这些应用是“自愿选择加入使用情况追踪”(opting into usage tracking)。这为观察哪些类型的应用在驱动模型使用方面提供了独特的视角。
- 动态趋势展示: “Trending”板块旨在突出显示当前正在快速增长或获得关注的模型。
2、榜单解读
基于对OpenRouter平台多维数据的分析,其大模型市场竞争格局呈现以下系统性特点:
| 市场呈现“一超多强”的集中化格局 | 整体市场份额由Anthropic和Google主导,两者合计占据近七成市场。然而在细分领域,专业化模型正形成“垂直壁垒”——X-AI的Grok Code Fast 1在编程领域独占48.7%份额,Anthropic的Claude Opus 4在SEO领域占据24.2%,显示出“通用模型打基数,专业模型占山头”的双轨并行态势。 |
| 应用场景驱动模型分化明显 | • 编程场景:由代码专用模型(Grok Code Fast 1)主导 • 图像处理:Google Gemini系列形成产品矩阵,占据超60%份额 • 角色扮演:DeepSeek系列领先(合计22.2%),且市场高度分散(其他类45.7%) • 工具调用:OpenAI的GPT-4o-mini(18.4%)领先,体现其函数调用能力优势 |
| 开发者生态成为关键增长引擎 | Top Apps榜单显示,AI编码助手(如Kilo Code、Cline)构成应用主体,说明OpenRouter已成为开发工具链的重要一环。同时liteLLM等开源库的入选,印证了平台对开发者的友好性。 |
| 市场竞争动态活跃 | 排行榜显示,Google通过Gemini系列多版本覆盖策略(在TOP10中常占4席)实施饱和攻击,而新兴厂商如X-AI、DeepSeek通过聚焦细分场景实现快速突围。免费模型(如MiniMax M2)的活跃也表明价格策略仍是重要竞争维度。 |
总体而言,OpenRouter市场正从通用模型竞争转向“场景深耕”阶段,厂商需在保持技术通用性的同时,在特定领域构建差异化优势。
Leaderboard(总榜)
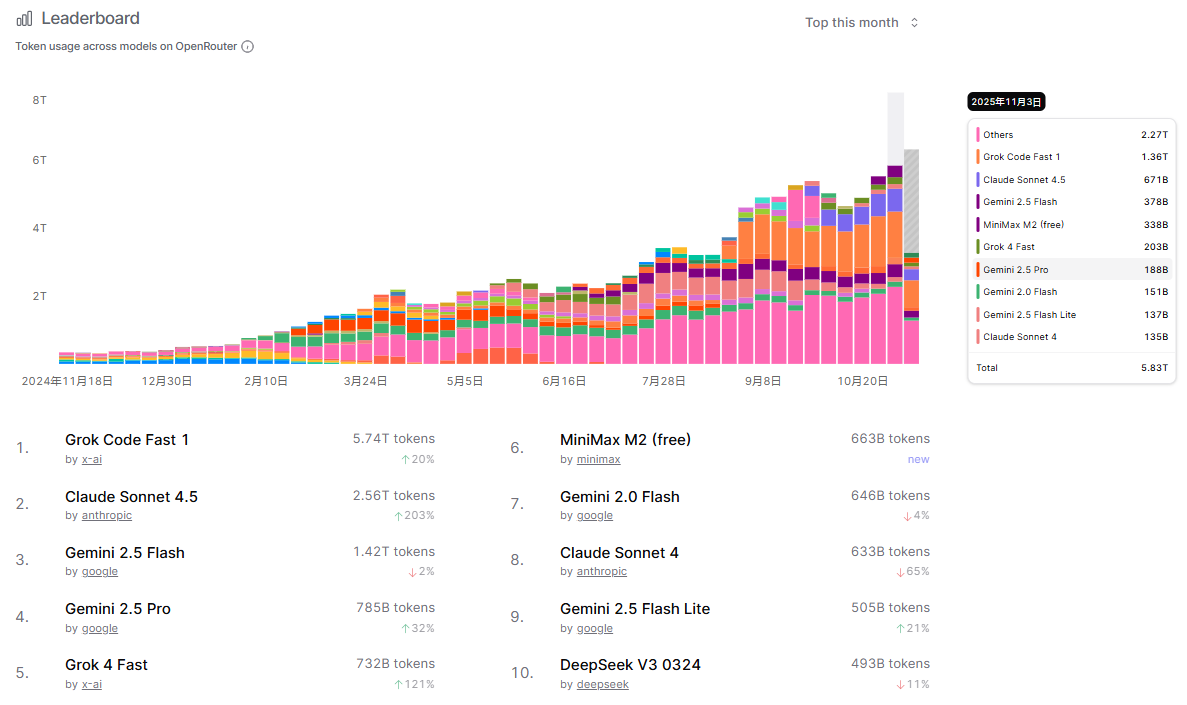
这张图片展示了OpenRouter平台上本月(截至2025年1月)的模型token使用量总排行榜。趋势图显示,从2024年11月至10月,平台整体token使用量维持在高位活跃区间(约27至87的指数水平),并在近期趋于稳定,表明用户对模型服务的需求持续旺盛。在具体模型排名上,X-AI的Grok Code Fast 1位列第一,凸显其在代码生成等专业任务中的统治性地位。Anthropic的Claude Sonnet 4.5和Google的Gemini 2.5 Flash紧随其后,分列二、三名,反映出这三家厂商的模型在综合应用场景中占据用户首选。值得注意的是,Google模型在Top 10中占据四席(包括Gemini 2.5 Pro、Flash Lite和2.0 Flash),显示出其产品矩阵的广度与市场渗透力。此外,X-AI的Grok 4 Fast、MiniMax的免费模型M2以及DeepSeek的V3 0324也跻身前十,体现了市场在追求高性能的同时,对免费或高性价比模型也存在稳定需求。总榜格局呈现出“专业模型领跑、通用模型紧跟”的竞争态势。
Market Share
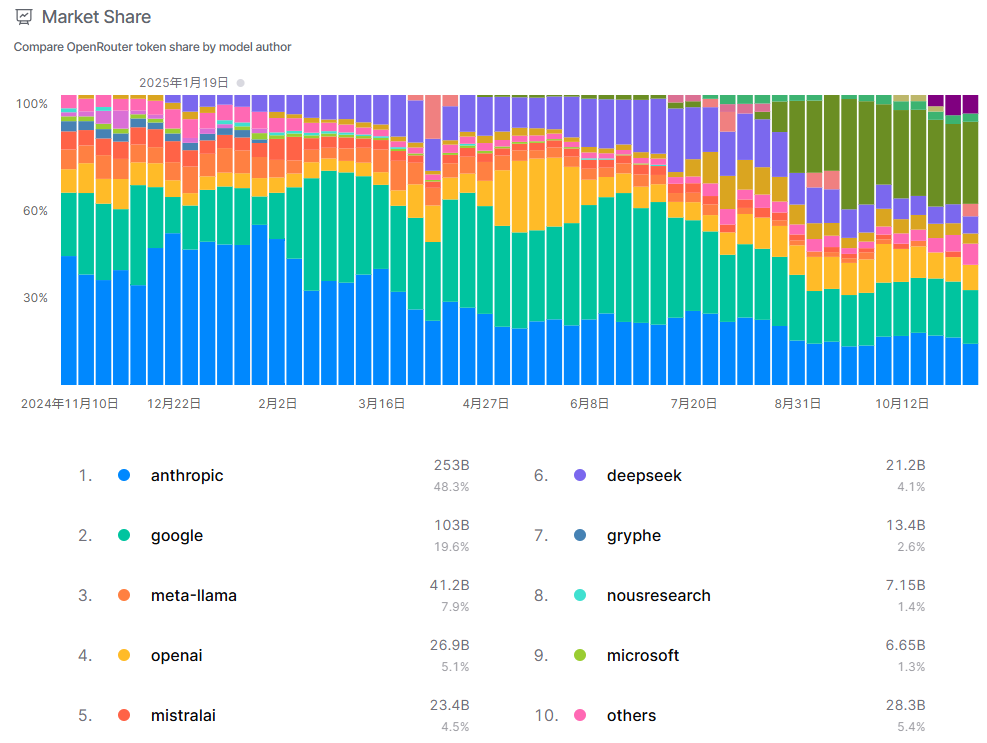
这张图片展示了OpenRouter平台上不同模型作者的token市场份额对比,数据截至2025年1月19日。从趋势图来看,市场份额在时间序列上(从2024年11月10日至10月12日)呈现动态变化,但整体格局稳定。具体份额分布中,Anthropic以253Btoken和48.3%的份额占据主导地位,几乎占据半壁江山,显示出其模型在用户中的广泛采用。Google以103Btoken和19.6%的份额位列第二,而Meta-LLama、OpenAI和MistralAI分别以7.9%、5.1%和4.5%的份额跟随其后。值得注意的是,DeepSeek、Gryphe和NousResearch等新兴作者份额较小,但“其他”类别仍占5.4%,反映了市场存在长尾分布,竞争多元。总体而言,Anthropic和Google作为头部玩家,主导了token消费,而其他作者则在细分领域争夺份额。
Categories
Programming
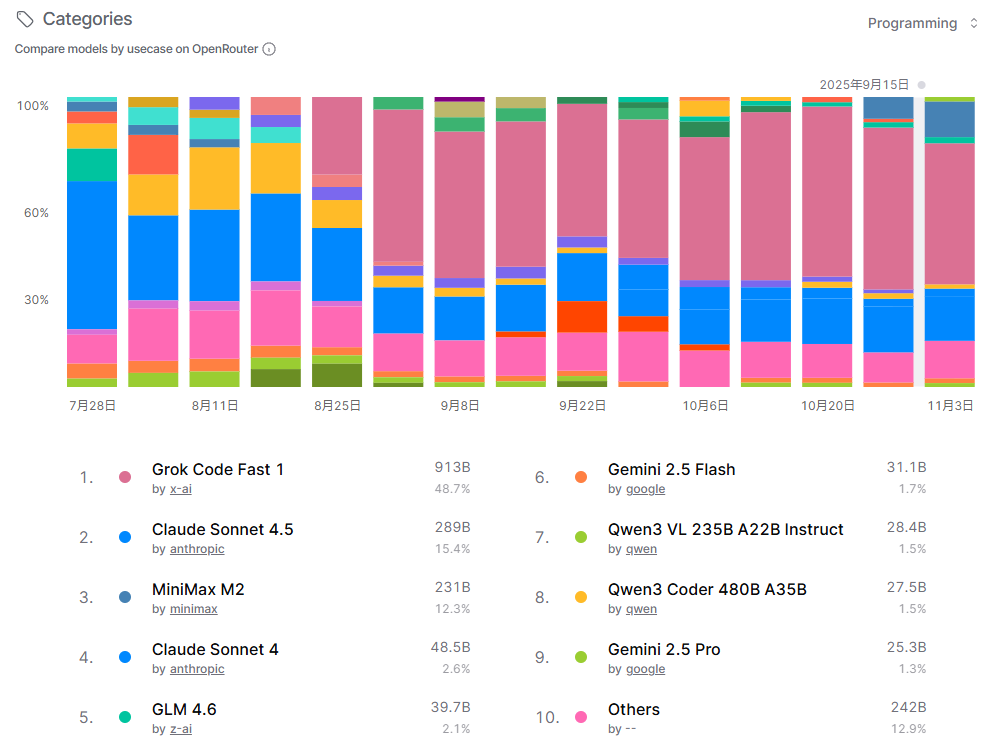
这张图片展示了OpenRouter平台上编程用例的模型对比,数据时间范围从7月28日至11月3日。在编程领域,Z-AI的Grok Code Fast 1模型以913Btoken和48.7%的份额占据绝对主导地位,几乎占据半壁江山,凸显了其在代码生成和开发任务中的高度专业化优势。Anthropic的Claude Sonnet 4.5以289Btoken和15.4%的份额位列第二,而MiniMax M2以231Btoken和12.3%紧随其后,显示出多模型竞争的态势。前10名中,Claude Sonnet系列、Z-AI的GLM 4.6以及Google和Qwen的模型份额相对较小,但“其他”类别仍占12.9%,反映了编程用例中用户对模型的选择较为集中,头部模型如Grok Code Fast 1凭借其针对性优化成为开发者的首选。趋势图显示份额分布相对稳定,表明编程任务对模型性能要求较高,市场格局不易变动。
Roleplay
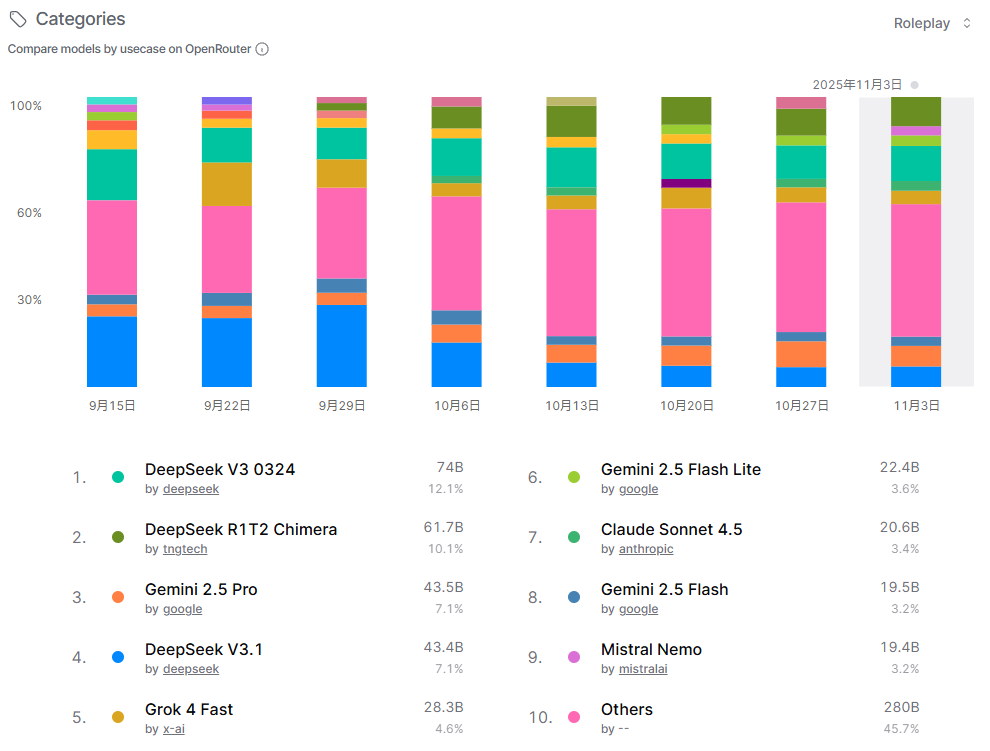
这张图片聚焦于角色扮演用例的模型对比,时间范围从9月15日至11月3日。角色扮演场景强调模型的对话生成和内容多样性,DeepSeek的模型表现突出,其中DeepSeek V3 0324以74Btoken和12.1%的份额领先,DeepSeek R1T2 Chimera以10.1%的份额紧随其后,显示出DeepSeek在娱乐化应用中的强大影响力。Google的Gemini 2.5 Pro和DeepSeek V3.1并列第三,各占7.1%,而X-AI的Grok 4 Fast和Anthropic的Claude Sonnet 4.5也占有一定份额。值得注意的是,“其他”类别占比高达45.7%,说明角色扮演市场高度分散,用户偏好多样化,长尾模型占据近半壁江山。趋势图显示份额波动较大,可能源于用户对新鲜内容和模型更新的快速响应,整体上角色扮演用例正成为OpenRouter生态中增长活跃的领域。
Marketing
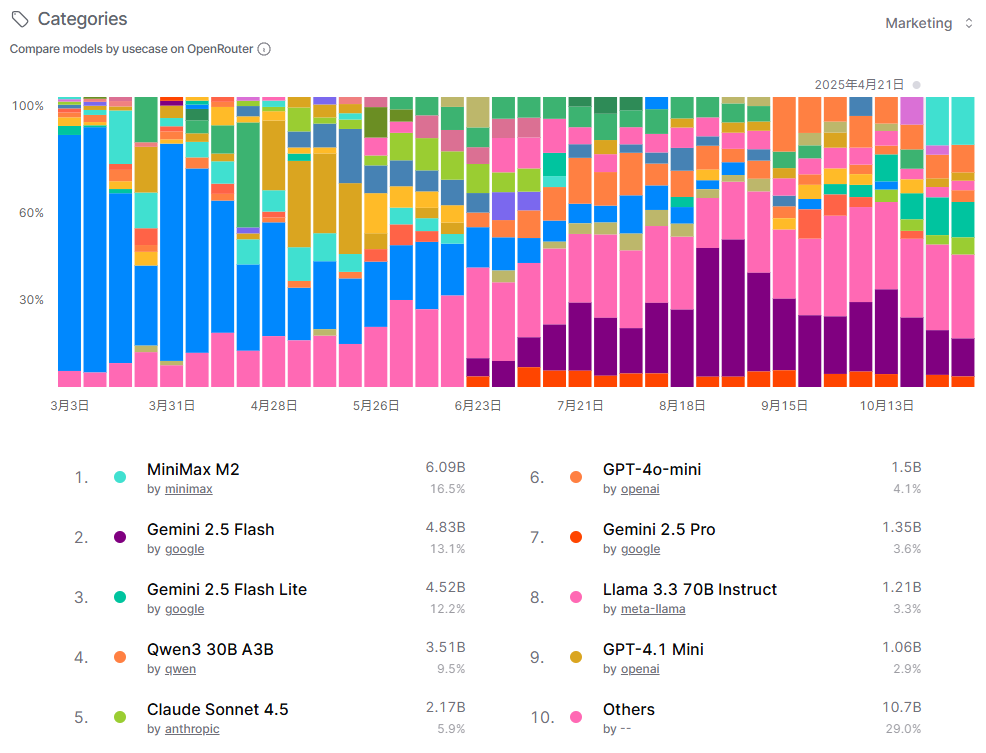
这张图片呈现了营销用例的模型对比,时间跨度从3月3日至10月13日。营销任务注重内容创作和推广效果,MiniMax M2以6.09Btoken和16.5%的份额位居第一,彰显了其在生成营销文案和策略方面的专业能力。Google的Gemini系列表现强劲,Gemini 2.5 Flash和Gemini 2.5 Flash Lite分别以13.1%和12.2%的份额位列第二、三位,显示出Google模型在多媒体营销中的综合优势。Qwen和Anthropic的模型份额相对较小,而OpenAI和Meta-LLama的模型也进入前十,但“其他”类别占29.0%,表明营销市场存在较多竞争者。趋势图显示份额分布相对平稳,反映出营销任务对模型的稳定性和创意输出有较高要求,头部模型如MiniMax M2和Google Gemini系列通过持续优化保持了用户忠诚度。
SEO
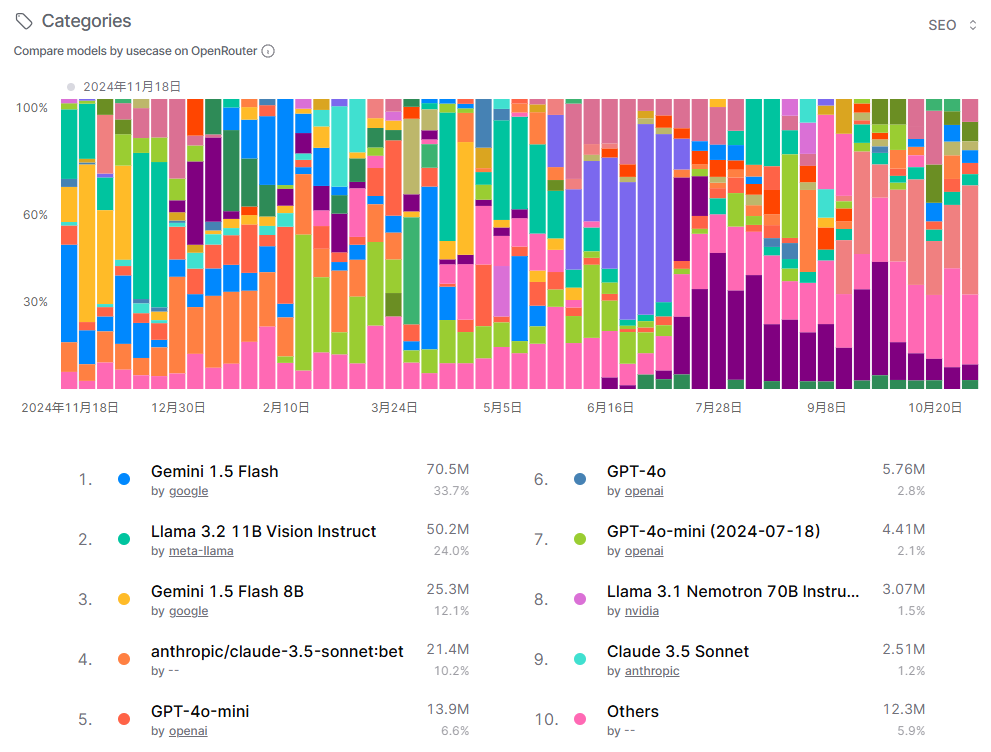
这张图片聚焦于SEO(搜索引擎优化) 这一具体应用场景,对比了不同模型在相关内容生成上的使用情况,数据时间范围延伸至2025年11月3日。趋势图显示,SEO类别的模型使用量从2024年11月至2025年10月期间,整体呈现先显著增长后在高位波动的态势,反映出市场对AI驱动SEO内容的需求日益强烈。在模型份额分布上,Anthropic的Claude Opus 4以24.2% 的绝对优势领先,共计3.92Btoken,这表明其在生成符合搜索引擎偏好、高质量结构化内容方面获得了用户的高度认可。Google的Gemini系列则展现了集团优势,其多个变体(包括Flash Preview、Flash Lite Preview、Flash、Flash Lite及Pro版本)共占据前10名中的5席,虽然单个模型份额在3.0%至3.9%之间,但总和极为可观,凸显了Google自身在搜索生态与语言模型结合上的天然优势。此外,OpenAI的GPT-4o-mini和MiniMax的M2也榜上有名。值得注意的是,“其他”类别占比也达到24.2%,与第一名份额持平,这说明SEO任务需求多样且分散,仍有大量长尾模型在被特定用户群体所采用。
Tool Calls
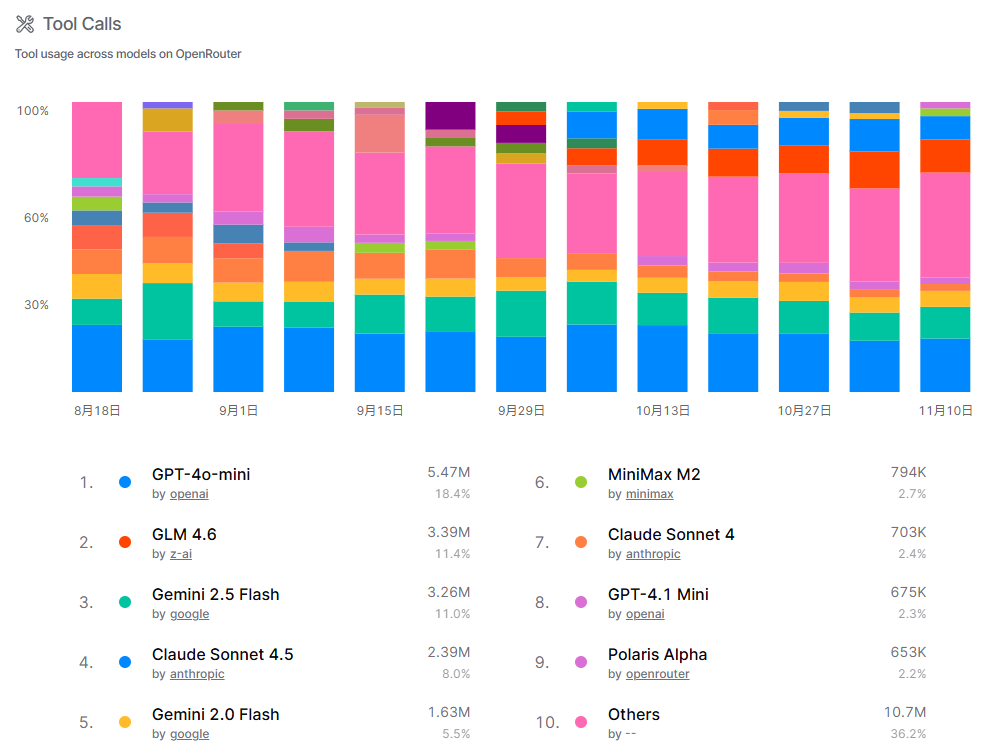
这张图片聚焦于OpenRouter平台上各模型的工具调用情况,时间范围从8月18日至11月10日。工具调用是衡量模型功能扩展性的关键指标,数据显示,OpenAI的GPT-4o-mini以5.47M次调用和18.4%的份额领先,表明其在工具集成方面的优势。Z-AI的GLM 4.6和Google的Gemini 2.5 Flash分别以11.4%和11.0%的份额紧随其后,显示出多模型竞争的态势。Anthropic的Claude Sonnet系列也有显著表现,合计占10.4%。此外,“其他”类别占比高达36.2%,说明工具使用分散 across numerous models,反映了用户对多样化功能的需求。趋势图显示调用量波动较大,可能受模型更新或用户偏好变化影响,整体上工具调用正成为平台的重要应用场景。
Images
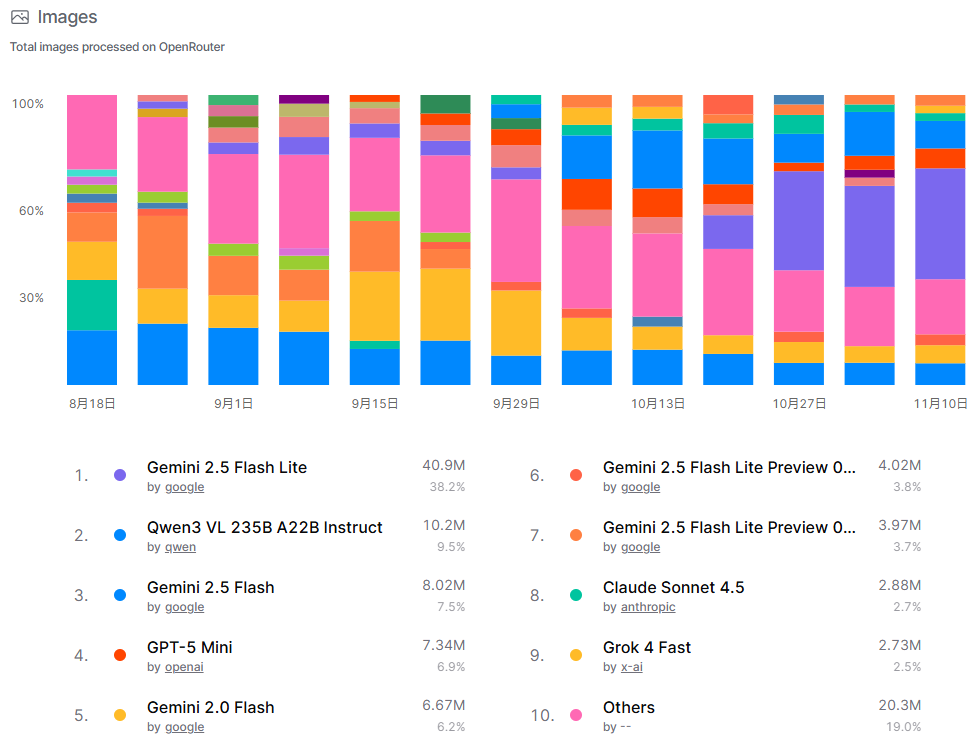
这张图片呈现了OpenRouter平台处理的图像总量,时间范围从8月18日至11月10日。图像处理是视觉AI模型的核心能力,Google的Gemini系列表现突出,其中Gemini 2.5 Flash Lite以40.9M张图像和38.2%的份额位居第一,彰显了Google在多媒体处理领域的领先地位。Qwen的Qwen3 VL模型以10.2M张和9.5%的份额位列第二,而OpenAI的GPT-5 Mini和Google的其他Gemini变体也贡献了较大份额。前10名中,Google模型占据了多个席位,合计份额超过60%,显示出高度集中性。Anthropic和X-AI的模型份额相对较小,“其他”类别占19.0%,表明图像处理市场主要由少数头部模型主导,但长尾模型仍有一定空间。趋势图显示处理量总体增长,反映了图像生成和分析需求的上升。
Top Apps
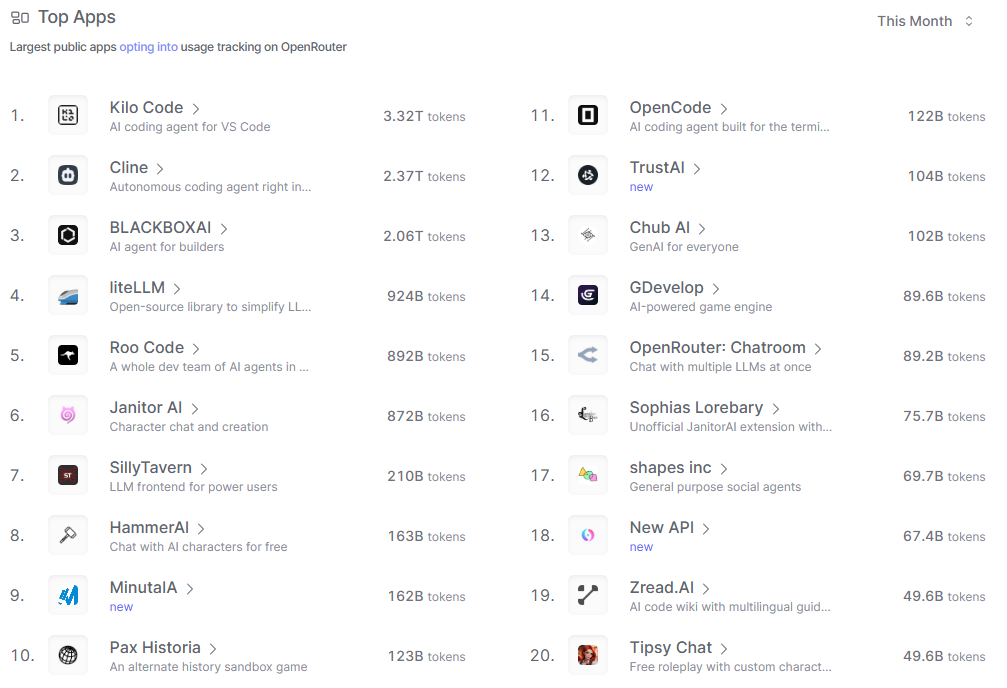
这张图片列出了OpenRouter平台上选择加入使用跟踪的顶级公共应用程序,共计20个。这些应用涵盖了多种类型,其中以AI编码代理为主,如Kilo Code、Cline和BLACKBOXAI,突出了开发工具在OpenRouter生态中的核心地位。此外,角色扮演和聊天应用(如Janitor AI、SillyTavern和HammerAI)也显著,显示了娱乐和社交场景的广泛应用。开源库如liteLLM和游戏类应用如Pax Historia进一步丰富了生态多样性。值得注意的是,部分应用标记为“new”(如MinutalA、TrustAI和New API),表明平台不断有新成员加入,推动创新。整体上,这张图表揭示了OpenRouter作为多模型集成的枢纽,正被广泛应用于代码开发、内容创作和游戏等领域,反映了AI技术的普及和用户需求的多元化。
OpenRouter LLM Ranking的核心内容
1、背景(Why)
页面内容本身没有直接阐述创建此排行榜的背景或动机(Why),但我们可以从其功能和设计中推断出其核心目的。OpenRouter 作为一个聚合了众多 LLM 的平台,其用户(主要是开发者)面临着一个关键问题:“在如此多的模型中,我应该选择哪一个?”
传统的性能排行榜虽然有用,但无法完全反映模型在实际应用中的适用性和受欢迎程度。因此,OpenRouter 创建这个基于真实使用量数据的排行榜,其背景是为了:
- 提供市场信号: 向开发者展示哪些模型在真实世界中被广泛使用,帮助他们做出更符合市场趋势的技术选型。
- 增加平台透明度: 公开平台上的模型和应用使用数据,展示 OpenRouter 生态的活跃度和规模,从而吸引更多用户和开发者。
- 反映社区偏好: 排行榜的结果是社区“用脚投票”的结果,它反映了在特定任务(如编码、角色扮演)上,开发者和用户的集体偏好。
2、目标与设计原则 (What)
- 核心目标: 透明、多维度地展示 OpenRouter 平台上所有大型语言模型的真实使用情况和市场动态,为开发者提供决策支持。
- 设计原则:
- 数据驱动与真实性: 所有排名均基于平台产生的真实、客观的“Token 使用量”数据,而非合成的基准测试分数。
- 用户中心与实用性: 设计了多种分类和过滤功能(按用例、语言、时间等),旨在满足开发者在不同场景下选择模型时的实际需求。
- 全面性与粒度: 不仅提供宏观的模型排名,还深入到模型作者、具体应用、特定能力(如工具调用)等多个粒度,提供一个全面的生态视图。
- 生态系统透明化: 通过展示“Top Apps”列表,揭示了模型使用背后的驱动力,体现了开放和透明的原则。
3、数据与评测方法 (How)
数据来源:
模型排名的数据来源于“Token usage across models on OpenRouter”,即平台上所有通过 API 调用的模型的 Token 消耗总量。
图像排名的数据来源于“Total images processed on OpenRouter”,即平台上处理的图像总数。
“Top Apps”的数据来源于“Largest public apps opting into usage tracking on OpenRouter”,即那些选择公开其使用数据的应用所产生的 Token 消耗量。
评测方法:
该排行榜的“评测”方法并非基于模型的性能测试(如准确率、延迟),而是数据聚合与统计。
基本方法是:追踪和记录在特定时间段内,每个模型、每个应用所处理的 Token 数量。
然后,根据不同的维度(如用例、语言)对这些数据进行分类、汇总和排序,最终以绝对数量(如 143B tokens)和百分比份额(如 27.9%)的形式呈现。
4、维度与指标体系
该排行榜构建了一个多维度的指标体系来衡量模型的市场表现:
核心指标:
Token 数量: 模型或应用消耗的 Token 总量,是衡量使用体量的基本单位。
百分比份额: 某个模型或作者在特定分类下所占的市场份额,直观反映其相对地位。
主要维度:
时间维度: 今日、本周、本月。
实体维度:
模型(Model): 如 x-ai/grok-code-fast-1。
模型作者(Author): 如 x-ai, google, anthropic。
应用(App): 如 Kilo Code, Cline。
功能/任务维度:
用例类别(Categories): 编程、角色扮演、市场营销等。
自然语言(Languages): 英语、中文、德语等。
编程语言(Programming): Python, JavaScript, C++等。
特定能力(Capabilities): 工具调用、图像处理。
OpenRouter LLM Ranking的使用方法
1、排名结果与解读 (Results & Insights)
根据页面提供的数据,可以解读出以下关键信息:
作者市场份额: 在模型作者层面,“x-ai”以 27.9% 的份额位居第一,紧随其后的是“google”(18.7%)和“anthropic”(14.0%)。这显示了这三家公司在 OpenRouter 平台上的强大影响力。
热门模型分析:
无论是“本周”还是“今日”热门榜单,x-ai/grok-code-fast-1 都以显著优势位列第一。例如,在本周榜单中,它占据了 26.4% 的份额。
其他持续受欢迎的模型包括 anthropic/claude-4.5-sonnet-20250929、minimax/minimax-m2 和 google/gemini-2.5-flash。
应用生态洞察:
“Top Apps”榜单揭示了 OpenRouter 平台的主要使用场景。排名前五的应用中,有四个(Kilo Code, Cline, BLACKBOXAI, Roo Code)明确是 AI 编码助手或开发工具。这强烈表明编程辅助是驱动 OpenRouter 平台 Token 消耗的最主要力量。这也解释了为什么一个专为编码优化的模型(grok-code-fast-1)能够占据榜首。
解读关键: 这个排行榜是市场流行度的晴雨表,而非绝对性能的度量衡。一个模型排名高,可能因为它性能优越、性价比高、在某个热门应用中被设为默认选项,或者在特定领域(如编码)表现突出。
2、实际应用价值 (So What)
为开发者提供决策依据: 开发者可以根据自己的应用场景(如需要处理德语、专注于角色扮演或编码),查看相应分类下的热门模型,从而快速做出技术选型,避免“闭门造车”。
- 揭示行业趋势: 排行榜直观地展示了哪些模型和应用正在获得市场青睐。例如,编码类应用的统治地位表明 AI 在软件开发领域已深度普及。
- 促进市场竞争: 对于模型提供商而言,这是一个公开的竞技场,可以让他们了解自身产品在真实世界中的表现和竞争对手的情况,从而调整其产品策略和定价。
- 发现新兴工具: “Top Apps”列表不仅展示了模型的使用情况,还帮助开发者发现流行的新兴 AI 应用和开发库(如 liteLLM, SillyTavern),促进了生态内的知识传播。
3、限制与展望 (Limitations & Future Work)
限制
流行度不等于质量: 这是该排行榜最主要的限制。使用量最高的模型不一定是在所有方面都“最好”的模型。其性能、准确性、安全性等关键质量指标并未在此展示。
平台数据偏差: 排名结果仅反映 OpenRouter 平台的用户行为。如果该平台的用户群体在某些领域(如编程)有特别强的偏好,那么排名结果将向这些领域倾斜,不一定能完全代表全球 LLM 的整体使用情况。
应用追踪的非完整性: “Top Apps”列表明确指出是基于“自愿选择加入追踪”的应用。这意味着可能存在一些使用量巨大但未选择加入的应用,导致该列表并非完全精确的全景图。
缺乏成本和性能指标: 排行榜没有提供模型的定价、延迟(Latency)或推理速度等对实际部署至关重要的商业和性能指标。
展望
页面内容本身并未明确提及未来的计划。但基于其现有框架,可以推断其发展方向可能包括:增加更多维度的分析(如成本效益分析、延迟排名)、覆盖更多新兴的模型能力、以及鼓励更多应用加入使用情况追踪以提供更全面的生态视图。