MySQL事务隔离级别:从并发困境到架构革新
在当今数据驱动的时代,数据库事务处理如同现实世界中的金融交易,需要确保数据的一致性、可靠性和隔离性。想象一下银行转账场景:如果A向B转账100元,这个操作必须要么完全成功(A账户减100,B账户加100),要么完全失败,绝不能出现中间状态。这就是事务的原子性要求。
然而,当多个事务同时执行时,数据库系统面临着一个核心挑战:如何在保证数据正确性的同时,提供尽可能高的并发性能?MySQL作为世界上最流行的开源关系数据库,其事务隔离级别的架构设计正是为了解决这一“平行宇宙”难题而诞生的精妙解决方案。

事务隔离的基本原理与挑战
事务的ACID特性
在深入探讨隔离级别之前,我们首先需要理解事务的四个基本特性,即ACID:
-
原子性(Atomicity):事务中的所有操作要么全部完成,要么全部不完成
-
一致性(Consistency):事务执行前后,数据库必须处于一致状态
-
隔离性(Isolation):并发事务之间相互隔离,互不干扰
-
持久性(Durability):事务完成后,对数据的修改是永久性的
其中,隔离性是最复杂、最微妙的特性,它直接决定了并发事务之间的可见性规则。(扩展阅读:分布式系统数据一致性演进:从ACID到BASE的理论突破与实践创新)
并发事务的三大问题
在早期的数据库系统中,开发人员发现并发事务会引发三类典型问题:
脏读(Dirty Read)
一个事务读取了另一个未提交事务修改的数据。如果后者回滚,前者读取的就是不存在的数据。
-- 事务A
START TRANSACTION;
UPDATE accounts SET balance = balance - 100 WHERE user_id = 1;
-- 此时balance为900,但事务尚未提交-- 事务B
START TRANSACTION;
SELECT balance FROM accounts WHERE user_id = 1; -- 读取到900(脏读)
COMMIT;-- 事务A
ROLLBACK; -- 余额恢复为1000,但事务B已经基于错误的数据做出了决策不可重复读(Non-repeatable Read)
在同一事务中,多次读取同一数据得到不同结果,因为其他事务在期间修改了该数据。
-- 事务A
START TRANSACTION;
SELECT balance FROM accounts WHERE user_id = 1; -- 返回1000-- 事务B
START TRANSACTION;
UPDATE accounts SET balance = 900 WHERE user_id = 1;
COMMIT;-- 事务A
SELECT balance FROM accounts WHERE user_id = 1; -- 返回900,与第一次读取不一致
COMMIT;幻读(Phantom Read)
在同一事务中,多次执行相同查询得到不同数量的记录,因为其他事务在期间新增或删除了符合条件的记录。
-- 事务A
START TRANSACTION;
SELECT COUNT(*) FROM accounts WHERE balance > 500; -- 返回10条记录-- 事务B
START TRANSACTION;
INSERT INTO accounts (user_id, balance) VALUES (11, 600);
COMMIT;-- 事务A
SELECT COUNT(*) FROM accounts WHERE balance > 500; -- 返回11条记录,出现幻读
COMMIT;SQL标准中的事务隔离级别
四种标准隔离级别
为了解决上述并发问题,SQL标准定义了四种事务隔离级别,从宽松到严格依次为:
-
读未提交(READ UNCOMMITTED):允许读取未提交的数据变更
-
读已提交(READ COMMITTED): 只能读取已提交的数据变更
-
可重复读(REPEATABLE READ):确保同一事务中多次读取结果一致
-
串行化(SERIALIZABLE):完全串行化执行,最高级别的隔离
下表清晰地展示了各隔离级别能够防止的并发问题:
| 隔离级别 | 脏读 | 不可重复读 | 幻读 |
|---|---|---|---|
| 读未提交 | ❌ | ❌ | ❌ |
| 读已提交 | ✅ | ❌ | ❌ |
| 可重复读 | ✅ | ✅ | ❌ |
| 串行化 | ✅ | ✅ | ✅ |
MySQL的默认隔离级别:可重复读
MySQL的InnoDB存储引擎默认使用可重复读(REPEATABLE READ)隔离级别,这与Oracle等数据库的默认设置(读已提交)不同。这一设计选择背后有着深刻的架构考量。
-- 查看当前会话的隔离级别
SELECT @@transaction_isolation;-- 设置隔离级别
SET SESSION TRANSACTION ISOLATION LEVEL READ COMMITTED;
SET SESSION TRANSACTION ISOLATION LEVEL REPEATABLE READ;
SET SESSION TRANSACTION ISOLATION LEVEL SERIALIZABLE;MySQL事务隔离的架构设计
多版本并发控制(MVCC)机制
MySQL实现事务隔离的核心技术是多版本并发控制(MVCC)。与传统的锁机制不同,MVCC通过维护数据的多个版本来实现非阻塞读操作。
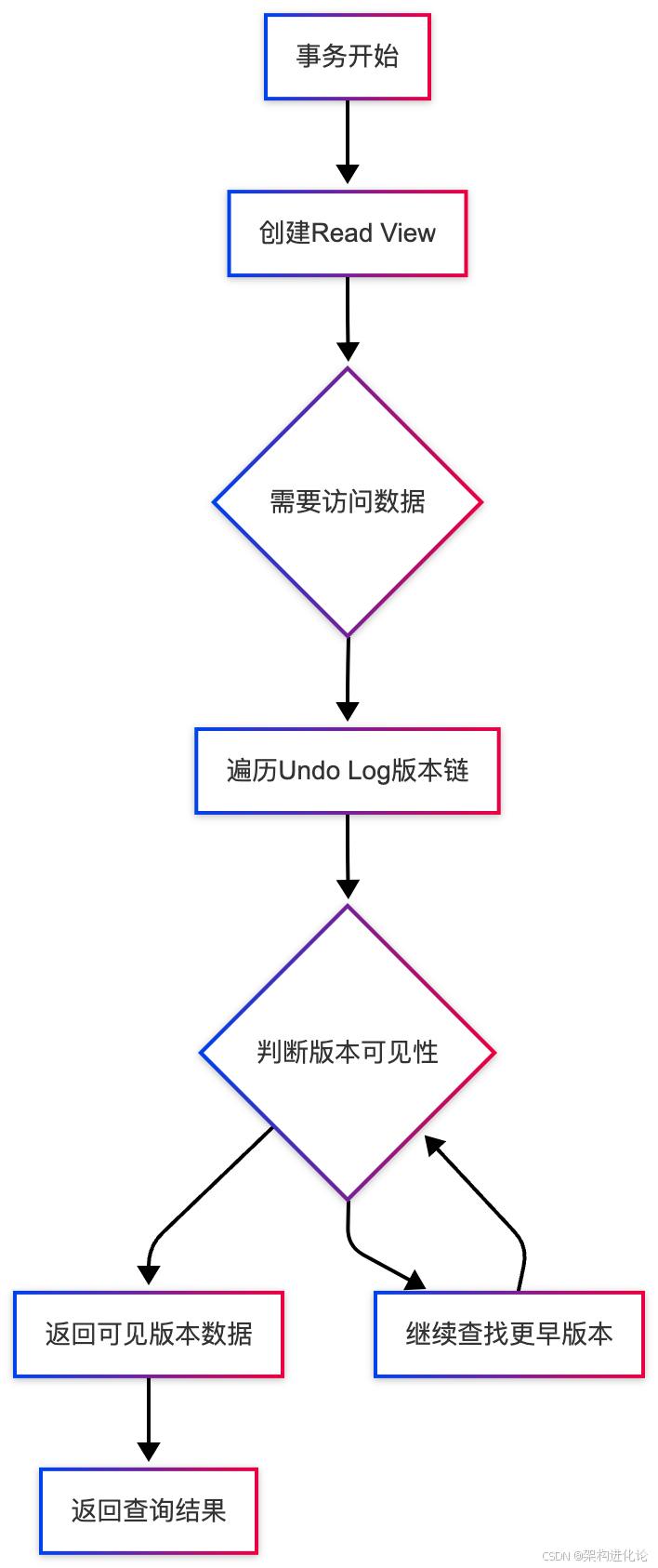
MVCC的核心组件:
隐藏的版本字段:
-
DB_TRX_ID:最近修改该行数据的事务ID -
DB_ROLL_PTR:指向Undo Log中旧版本数据的指针 -
DB_ROW_ID:行ID(隐藏主键)
Undo Log:存储数据的历史版本,形成版本链(扩展阅读:MySQL事务日志深度解析:Undo Log与Redo Log的协同设计奥秘、数据库日志系统解析:从数据持久化到实时同步的架构演进)
Read View:事务在快照读时产生的一致性视图
Read View的创建与可见性判断
当事务执行快照读时,InnoDB会为其创建Read View,用于判断数据版本的可见性。
// Read View的简化结构(概念性代码)
struct read_view_t {trx_id_t low_limit_id; // 高水位:大于等于此值的事务ID不可见trx_id_t up_limit_id; // 低水位:小于此值的事务ID可见ids_t creator_trx_id; // 创建Read View的事务IDids_t* ids; // 活跃事务ID列表ulint n_ids; // 活跃事务数量
};可见性判断算法:
-
如果
DB_TRX_ID < up_limit_id,说明数据在Read View创建前已提交,可见 -
如果
DB_TRX_ID >= low_limit_id,说明数据在Read View创建后修改,不可见 -
如果
up_limit_id <= DB_TRX_ID < low_limit_id,检查事务是否在活跃列表中
-
在活跃列表中:事务未提交,不可见
-
不在活跃列表中:事务已提交,可见
不同隔离级别的MVCC实现差异
读已提交(READ COMMITTED)
每次执行SELECT语句时都会创建新的Read View,因此能看到其他事务已提交的修改。
可重复读(REPEATABLE READ)
仅在第一次执行SELECT时创建Read View,后续查询都复用这个视图,确保读取一致性。
-- 演示可重复读与读已提交的区别
-- 会话A
START TRANSACTION;
SELECT balance FROM accounts WHERE user_id = 1; -- 第一次读取-- 会话B
UPDATE accounts SET balance = balance + 100 WHERE user_id = 1;
COMMIT;-- 会话A
-- 如果隔离级别是READ COMMITTED,这里会看到更新后的值
-- 如果隔离级别是REPEATABLE READ,这里仍然看到旧值
SELECT balance FROM accounts WHERE user_id = 1; -- 第二次读取
COMMIT;MySQL的架构创新:无锁快照读
传统锁机制的局限性
在MVCC出现之前,数据库主要依靠锁机制来实现事务隔离:
-
共享锁(S锁):读取时加锁,阻止其他事务写入
-
排他锁(X锁):写入时加锁,阻止其他事务读写
这种机制会导致严重的性能问题:
-
读写冲突:读操作阻塞写操作
-
死锁风险:循环等待锁资源
-
并发度低:锁竞争限制系统吞吐量
MVCC的读写分离设计
MySQL的MVCC实现了读写分离,读操作访问快照版本,写操作创建新版本,两者互不阻塞。
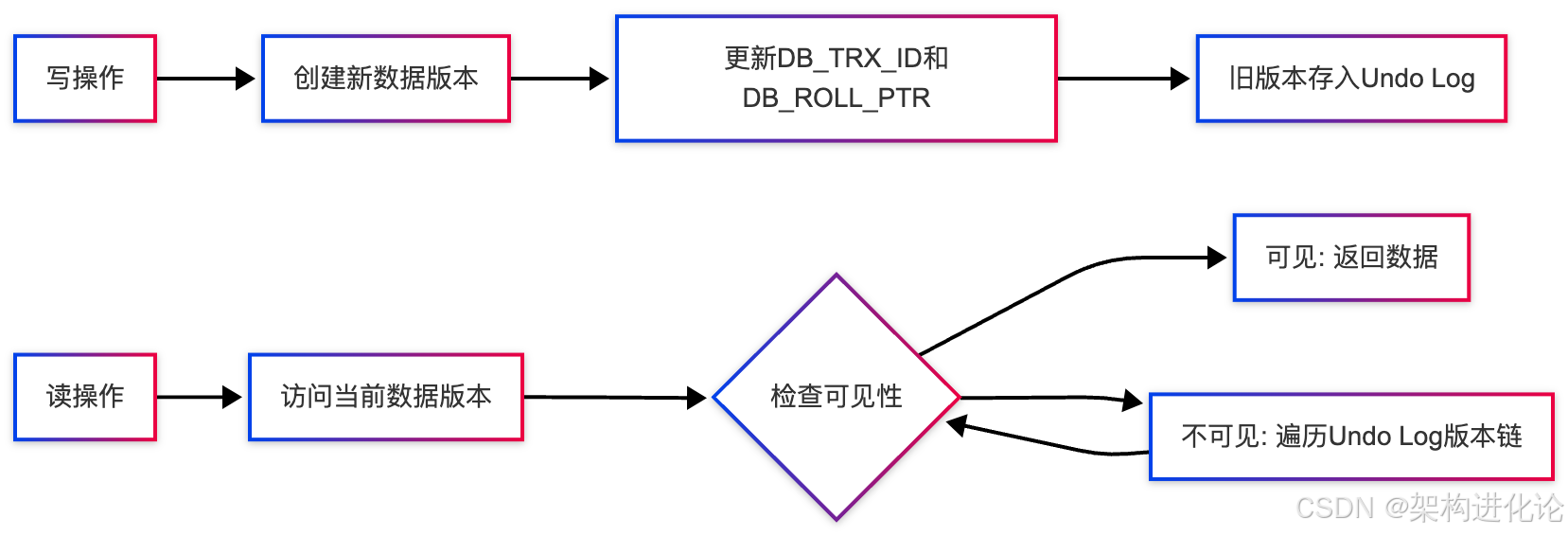
这种设计的优势:
-
读不阻塞写:读操作访问历史版本,不干扰当前写入
-
写不阻塞读:写操作创建新版本,不影响正在进行的读操作
-
避免死锁:读操作不需要加锁,减少死锁可能性
MySQL在可重复读级别下的幻读解决方案
幻读问题的特殊性
虽然SQL标准规定可重复读隔离级别允许幻读,但MySQL的InnoDB通过Next-Key Locking机制在可重复读级别下也避免了幻读。
-- 幻读场景示例
-- 事务A
START TRANSACTION;
SELECT * FROM accounts WHERE balance BETWEEN 500 AND 1000;
-- 返回3条记录-- 事务B
START TRANSACTION;
INSERT INTO accounts (user_id, balance) VALUES (12, 800);
COMMIT;-- 事务A
SELECT * FROM accounts WHERE balance BETWEEN 500 AND 1000;
-- 在标准可重复读下可能返回4条记录(幻读)
-- 但在MySQL的可重复读下仍然返回3条记录Next-Key Locking机制
Next-Key Lock是Record Lock(记录锁)和Gap Lock(间隙锁)的结合,它不仅锁定记录本身,还锁定记录之前的间隙。
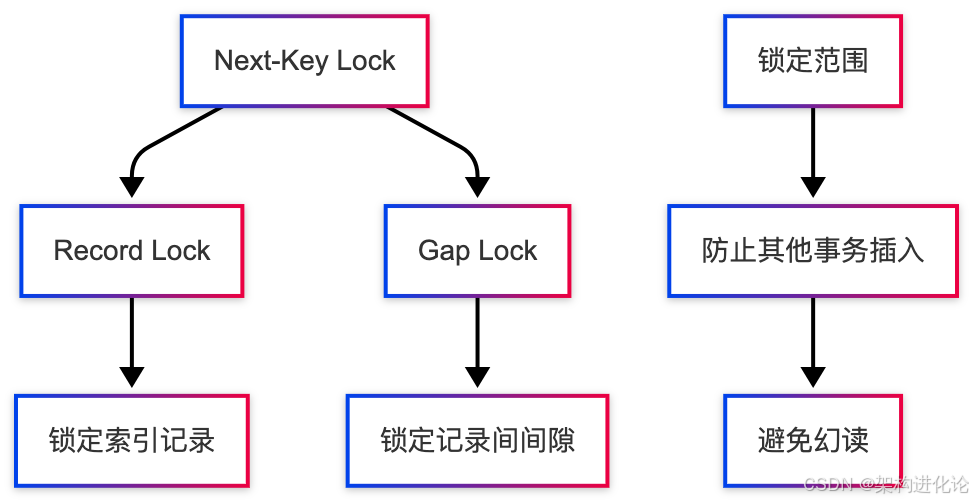
Next-Key Lock的工作机制:
等值查询:
-
对唯一索引:退化为行锁
-
对非唯一索引:锁定匹配记录及前后间隙
范围查询:
-
锁定查询范围内的所有记录和间隙
-
防止范围内插入新记录
-- Next-Key Lock示例
START TRANSACTION;
-- 假设在balance字段上有非唯一索引
SELECT * FROM accounts WHERE balance = 800 FOR UPDATE;-- 此时其他事务无法执行以下操作:
-- INSERT INTO accounts (user_id, balance) VALUES (13, 800); -- 被Gap Lock阻止
-- UPDATE accounts SET balance = 800 WHERE user_id = 5; -- 被Record Lock阻止MySQL事务隔离的存储引擎架构
InnoDB的架构全景
InnoDB存储引擎的事务处理架构是一个精心设计的复杂系统:
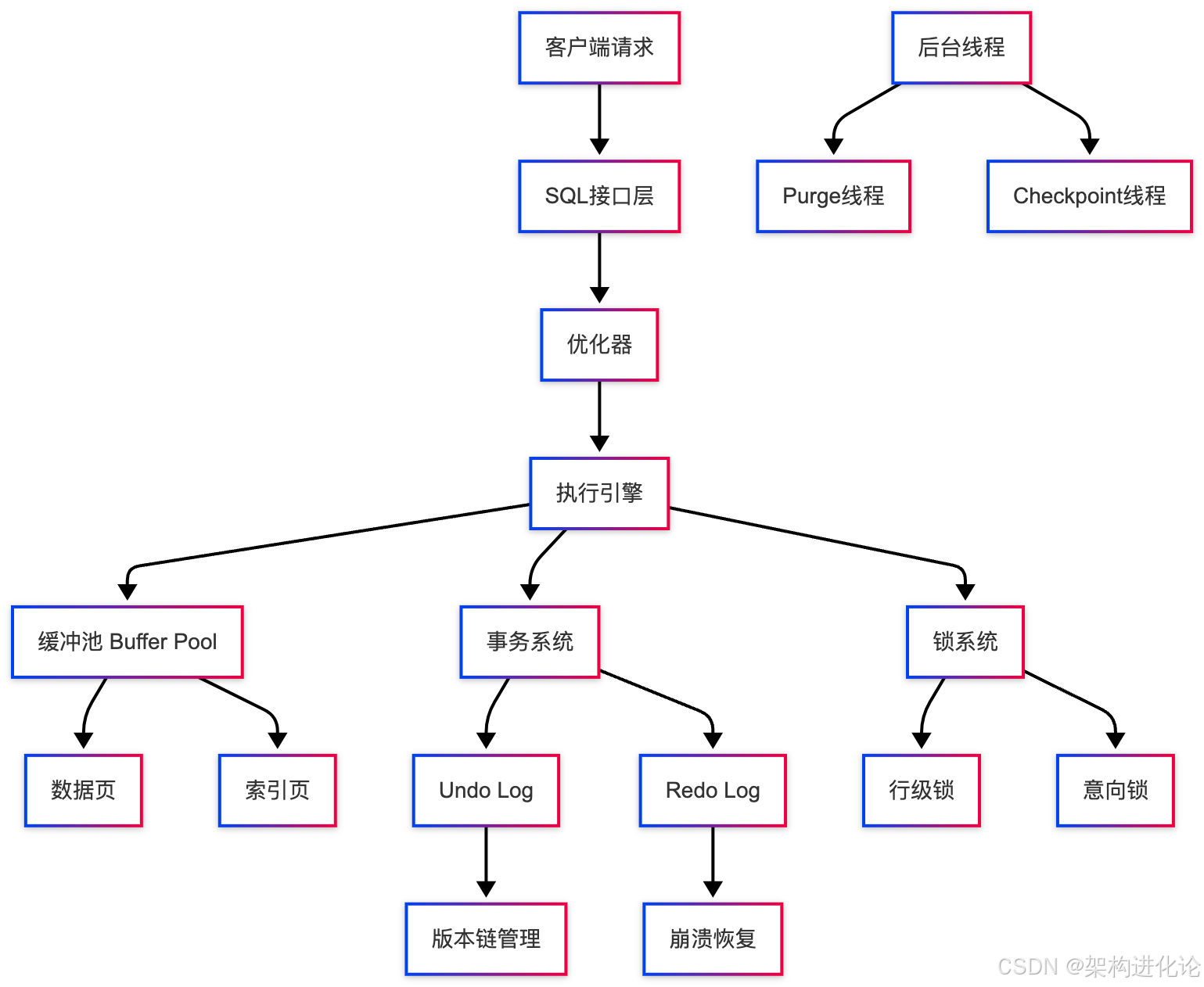
关键组件深度解析
缓冲池(Buffer Pool)
-
内存缓存区域,减少磁盘I/O
-
采用LRU算法管理页面
-
支持预读和写合并优化
Undo Log
-
存储数据修改前的旧版本
-
用于事务回滚和MVCC版本链
-
按回滚段(Rollback Segment)组织
Redo Log
-
记录物理修改,用于崩溃恢复
-
采用WAL(Write-Ahead Logging)原则(扩展阅读:预写日志(WAL):数据持久化的守护者与现代架构创新、预写日志(WAL):数据库的“记账本”原理)
-
循环写入,提高写入性能
实战案例:电商库存管理中的事务隔离
高并发下的库存扣减挑战
在电商秒杀场景中,库存扣减是典型的高并发事务处理场景。错误的实现会导致超卖或性能瓶颈。
问题场景:
-- 错误实现:查询后更新,存在竞态条件
START TRANSACTION;
SELECT stock FROM products WHERE product_id = 1001; -- 假设返回1
-- 此时另一个事务也查询库存,同样看到库存为1
UPDATE products SET stock = stock - 1 WHERE product_id = 1001;
COMMIT;
-- 结果:超卖,库存变为-1基于事务隔离的正确解决方案
方案一:悲观锁
START TRANSACTION;
-- 使用SELECT FOR UPDATE加排他锁
SELECT stock FROM products WHERE product_id = 1001 FOR UPDATE;-- 业务逻辑:检查库存是否充足
IF stock > 0 THENUPDATE products SET stock = stock - 1 WHERE product_id = 1001;COMMIT;
ELSEROLLBACK;
END IF;方案二:乐观锁
-- 添加版本号字段
ALTER TABLE products ADD COLUMN version INT DEFAULT 0;START TRANSACTION;
SELECT stock, version FROM products WHERE product_id = 1001;-- 业务逻辑处理
IF stock > 0 THEN-- 基于版本号更新UPDATE products SET stock = stock - 1, version = version + 1 WHERE product_id = 1001 AND version = :old_version;-- 检查影响行数IF ROW_COUNT() = 0 THEN-- 版本号冲突,更新失败ROLLBACK;ELSECOMMIT;END IF;
ELSEROLLBACK;
END IF;方案三:原子操作
-- 直接原子更新,避免显式事务
UPDATE products
SET stock = stock - 1
WHERE product_id = 1001 AND stock > 0;-- 检查影响行数确定是否成功
IF ROW_COUNT() > 0 THEN-- 扣减成功
ELSE-- 库存不足
END IF;性能对比与选型建议
| 方案 | 适用场景 | 优点 | 缺点 |
|---|---|---|---|
| 悲观锁 | 高竞争场景 | 实现简单,保证强一致性 | 并发度低,死锁风险 |
| 乐观锁 | 低竞争场景 | 高并发,无锁竞争 | 实现复杂,重试逻辑 |
| 原子操作 | 简单扣减 | 性能最高,实现简单 | 无法处理复杂业务逻辑 |
MySQL事务隔离的性能优化实践
监控与诊断工具
查看锁信息:
-- 查看当前锁信息
SELECT * FROM information_schema.INNODB_LOCKS;
SELECT * FROM information_schema.INNODB_LOCK_WAITS;-- 查看事务状态
SELECT * FROM information_schema.INNODB_TRX;监控性能指标:
-- 查看锁等待统计
SHOW STATUS LIKE 'Innodb_row_lock%';-- 查看事务相关统计
SHOW STATUS LIKE 'Com_commit';
SHOW STATUS LIKE 'Com_rollback';优化策略与最佳实践
1. 合理设置隔离级别
-- 在配置文件中设置默认隔离级别
[mysqld]
transaction-isolation = READ-COMMITTED-- 或者按会话动态调整
SET SESSION TRANSACTION ISOLATION LEVEL READ COMMITTED;2. 优化事务设计
-
尽量缩短事务执行时间
-
避免在事务中进行网络I/O或复杂计算
-
将大事务拆分为小事务
3. 索引优化
-- 为经常用于查询条件的字段创建合适索引
CREATE INDEX idx_balance ON accounts(balance);
CREATE INDEX idx_product_stock ON products(stock) WHERE stock > 0;-- 分析查询执行计划
EXPLAIN SELECT * FROM accounts WHERE balance > 500;4. 避免长事务
-- 监控长事务
SELECT * FROM information_schema.INNODB_TRX
WHERE TIME_TO_SEC(TIMEDIFF(NOW(), trx_started)) > 60;-- 设置事务超时
SET SESSION innodb_lock_wait_timeout = 50;MySQL事务隔离的演进与未来展望
历史演进路径
MySQL 5.0及之前
-
主要使用MyISAM存储引擎,不支持事务
-
InnoDB作为可选插件,提供基本的事务支持
MySQL 5.1 - 5.5
-
InnoDB成为默认存储引擎
-
完善了MVCC和锁机制
-
引入了多回滚段优化
MySQL 5.6 - 5.7
-
优化了Undo Log管理
-
提升了高并发下的性能
-
增强了在线DDL能力
MySQL 8.0
-
原子DDL操作
-
增强的数据字典
-
更好的JSON支持
-
窗口函数等高级特性
未来发展趋势
1. 更细粒度的并发控制
-
基于时间戳的并发控制
-
硬件事务内存支持
-
机器学习优化的锁机制
2. 云原生架构适配
-
分布式事务优化
-
多租户隔离增强
-
弹性扩展支持
3. 新硬件技术利用
-
持久内存(PMEM)优化
-
RDMA网络加速
-
GPU/TPU异构计算
MySQL事务隔离的架构智慧
MySQL的事务隔离级别架构设计体现了数据库领域数十年的智慧结晶。从最初的简单锁机制到如今的MVCC多版本控制,MySQL在保证数据一致性的同时,不断追求更高的并发性能。
核心设计理念:
-
读写分离:通过MVCC实现读不阻塞写、写不阻塞读
-
版本管理:利用Undo Log维护数据历史版本,支持一致性视图
-
锁优化:Next-Key Locking在性能和一致性间取得平衡
-
可配置性:提供多级隔离级别,适应不同业务场景
实践建议:
-
理解业务需求,选择适当的隔离级别
-
监控事务性能,及时发现和解决瓶颈
-
遵循最佳实践,避免常见陷阱
-
持续学习新技术,适应架构演进
MySQL的事务隔离架构不仅是技术的实现,更是工程哲学的体现:在复杂的约束条件下寻找最优解,在理论完美与现实可行之间达成平衡。这种设计思想值得每一位架构师和技术决策者深入学习与借鉴。
随着数据规模的持续增长和业务复杂度的不断提升,MySQL的事务处理能力将继续演进,为构建可靠、高性能的数据密集型应用提供坚实基础。