RAGFlow 0.22.0 特性总览——支持数据源、完善 Parser、Agent 优化以及 Admin UI
RAGFlow 知识库的构建过程主要由文件上传、解析与切片三个核心步骤组成。在 0.21.0 版本中,RAGFlow 通过 Ingestion pipeline 显著提升了解析与切片阶段的灵活性;
而在本次 0.22.0 版本中,我们将重点放在数据上传环节,旨在进一步提升开发者在构建知识库时的整体效率。
除此以外,本版本还带来了以下重要更新:
-
Ingestion pipeline 的 Parser 节点新增更多模型选择,进一步提升文件解析效果
-
优化了 Agent 的 Retrieval 与 Await Response 节点
-
新增 Admin UI,为系统提供了更加直观高效的可视化操作界面
接下来,我们将逐一介绍这些特性与改进。
支持丰富的外部数据源
Data sources 模块是 RAGFlow v0.22.0 版本中引入的核心功能之一,旨在 Dataset 中接入外部数据源,用户可以把自己分散在各个不同数据源上的文件,同步到 RAGFlow 中。
用户可以在个人中心的 “数据源” 菜单中添加并配置多种外部数据源,例如 Confluence、AWS S3、Google Drive、Discord、Notion,从而实现数据的统一管理与自动同步。
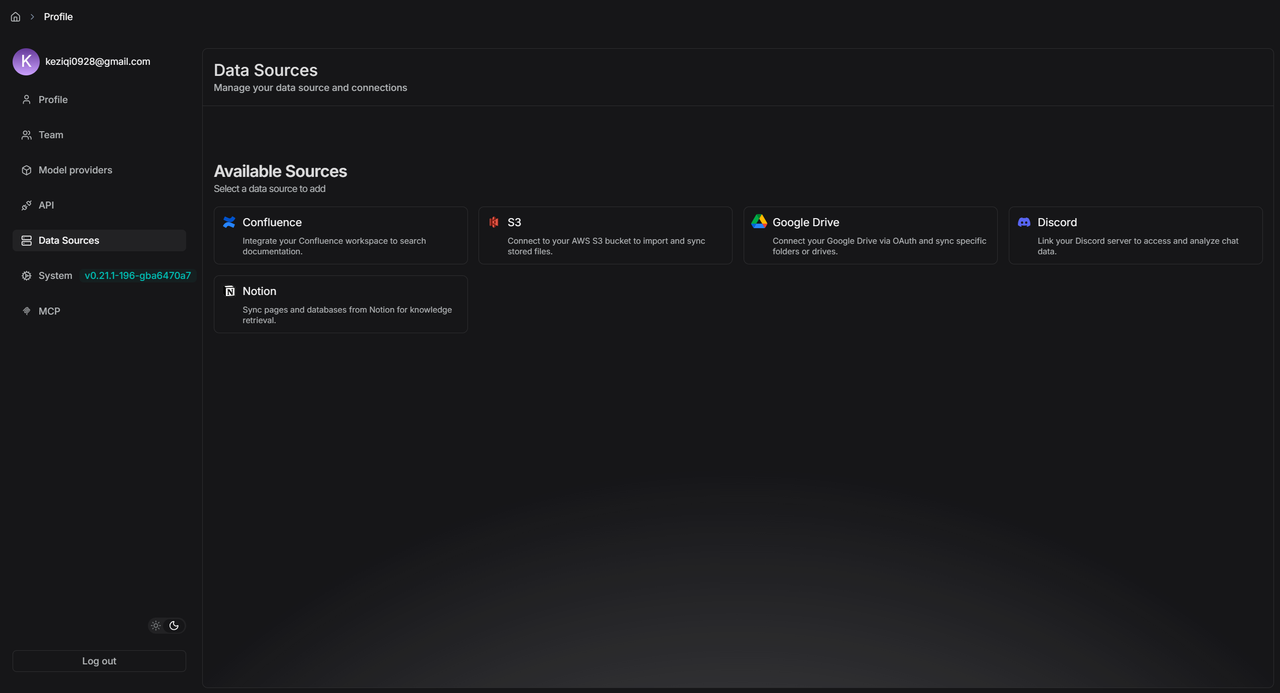
S3
接下来以 S3 为例,先确保在地址为 https://portal.aws.amazon.com 的 AWS 管理账户下有 S3 存储桶。
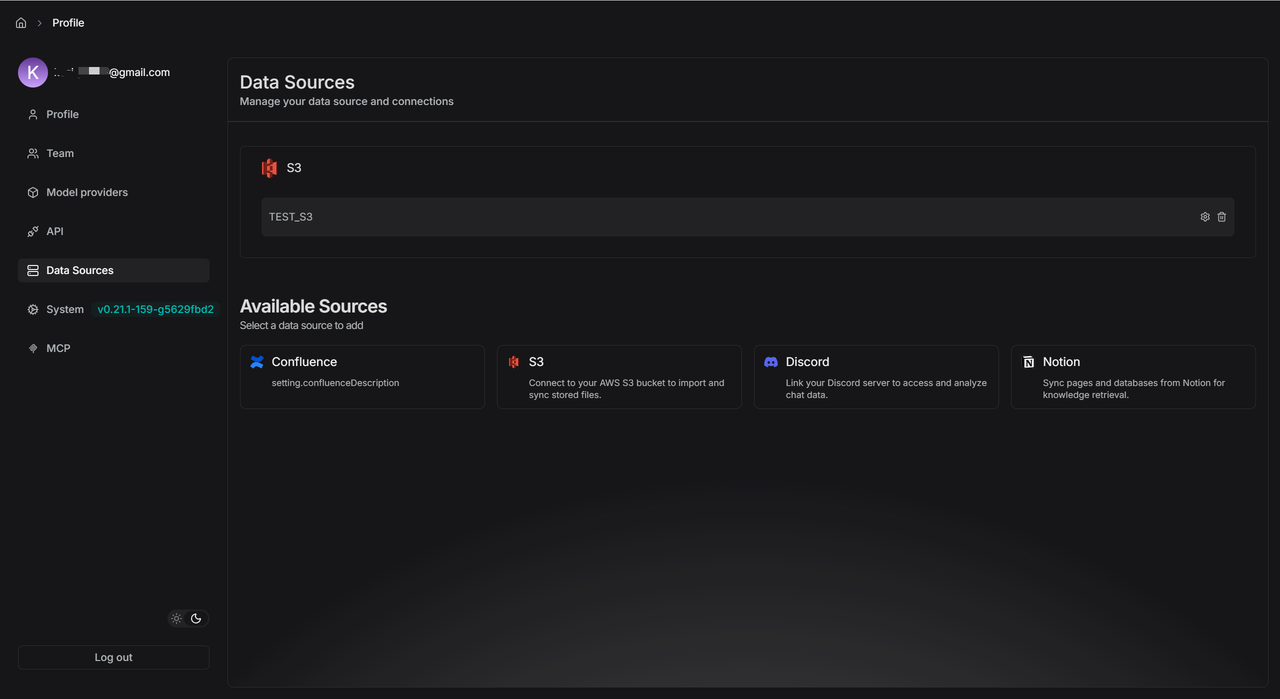
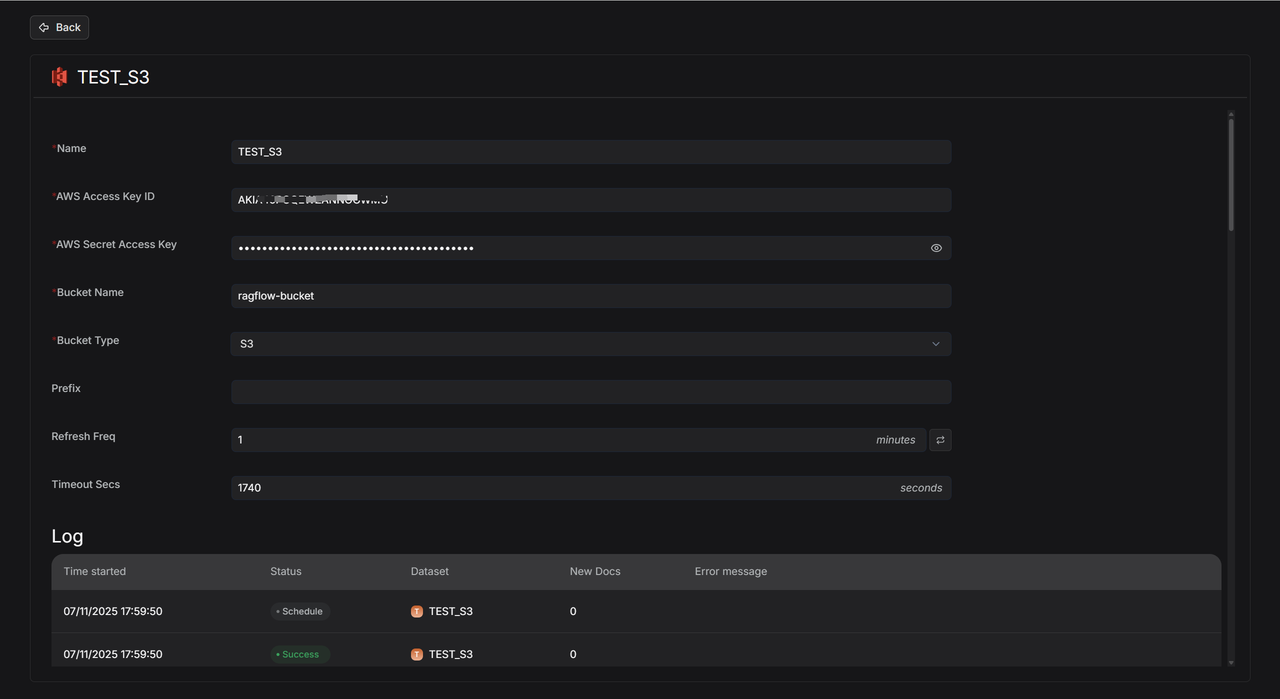
将 S3 的配置添加至 S3 数据源的配置表单。
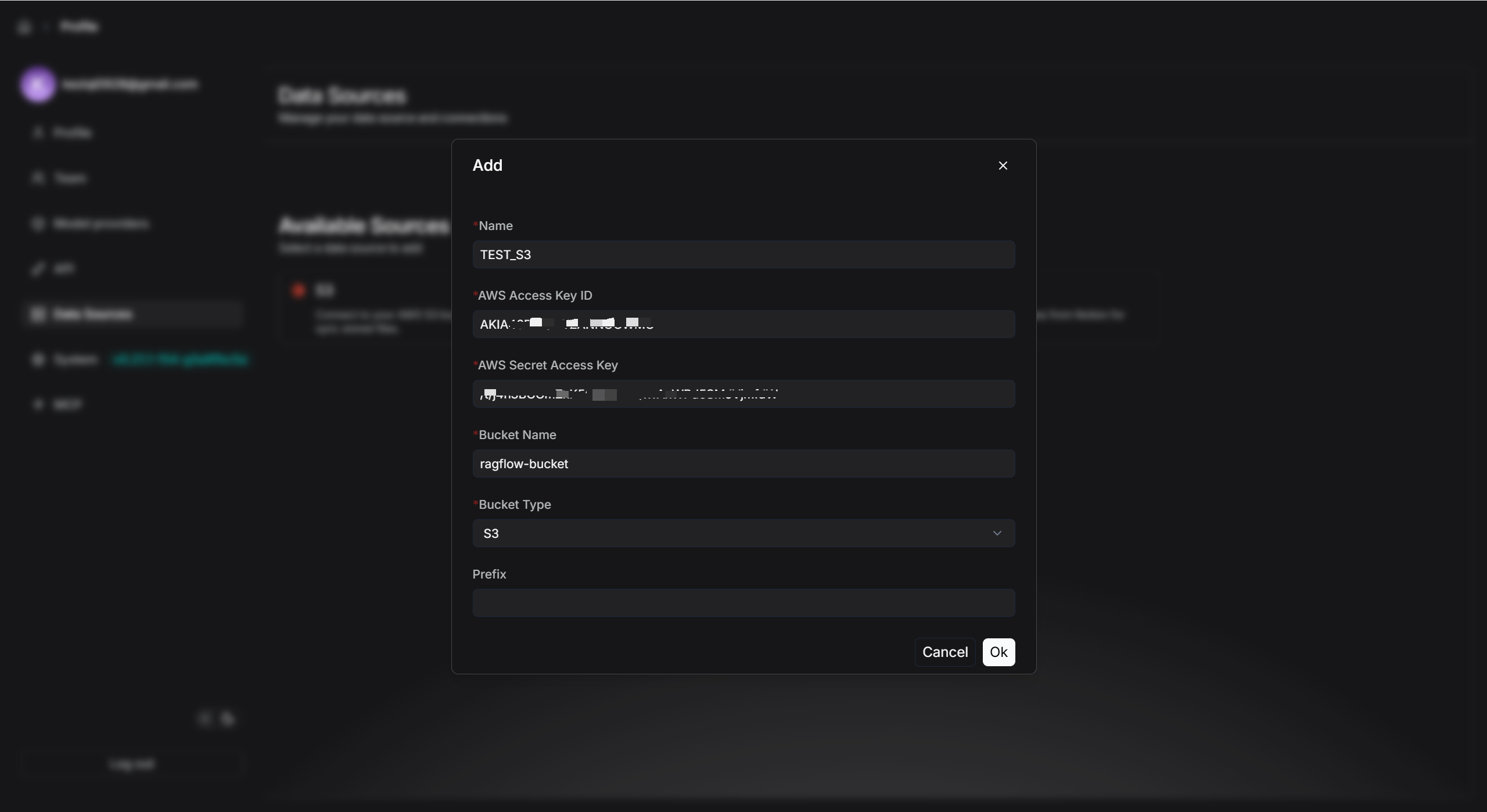
添加成功之后,点击设置图标,查看数据源详情。
当将 “Refresh Freq” 设置为 “1” 时,系统会启动一个以 1 分钟为周期的监听循环。
设置完成后 RAGFlow 会检测指定的 AWS S3 Bucket(如示例中的 ragflow-bucket)是否有新文件,若检测到新文件,系统会立即开始同步所有新增内容,直至处理完成。
同步结束后,系统将进入 1 分钟的等待状态,然后自动开启下一轮检测。右侧的 “暂停” 按钮可用于随时启用或暂停该自动刷新机制。
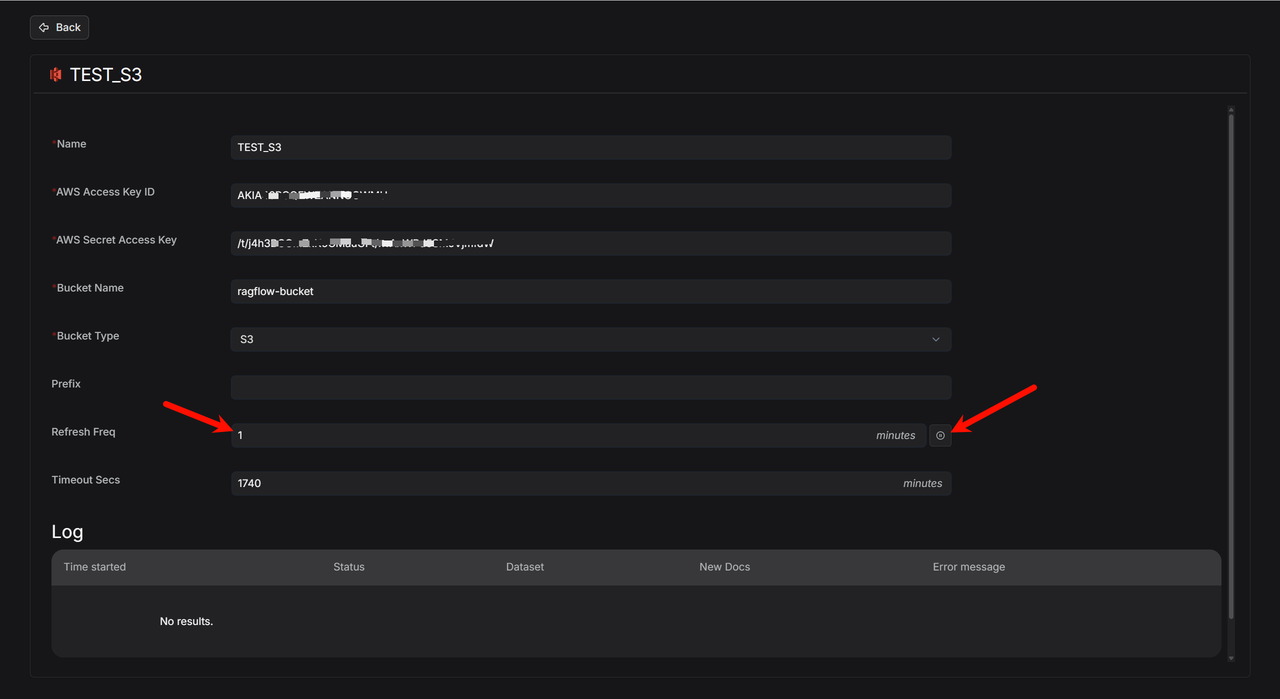
新建一个知识库 TEST_S3 ,点击 Configuration ,然后滑动至最下面,点击 Link Data Source ,对需要的数据源进行链接。
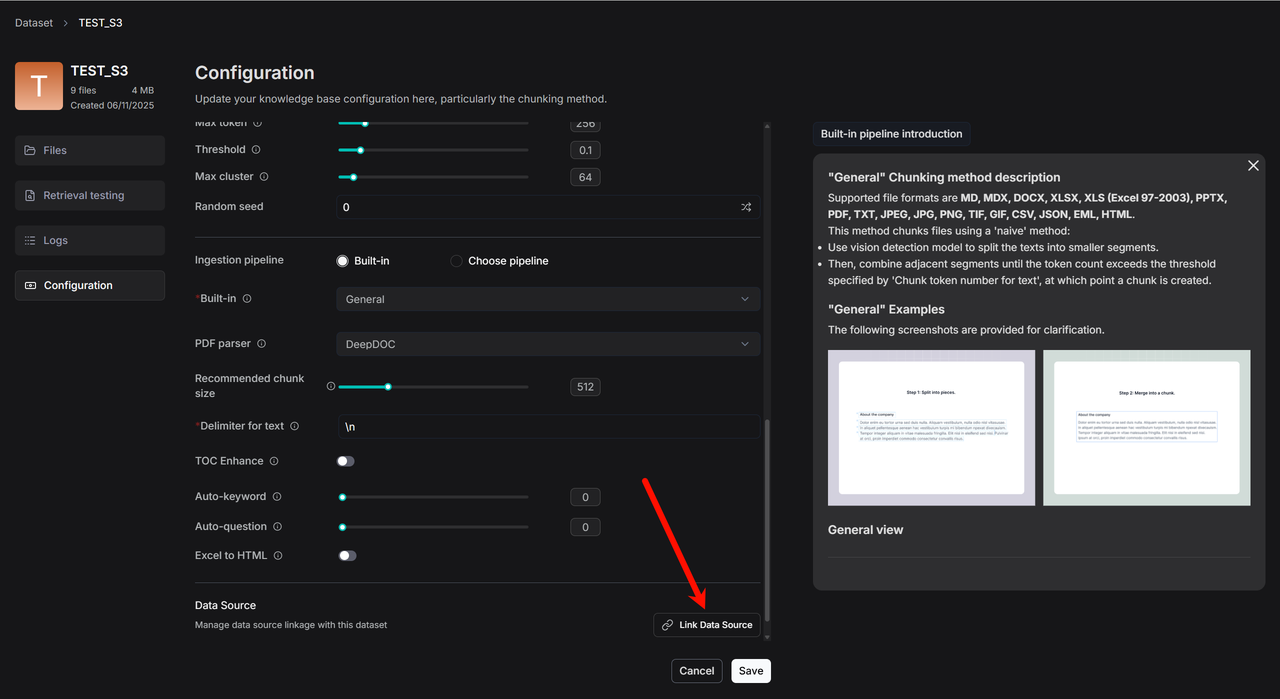
选择 S3 数据源。
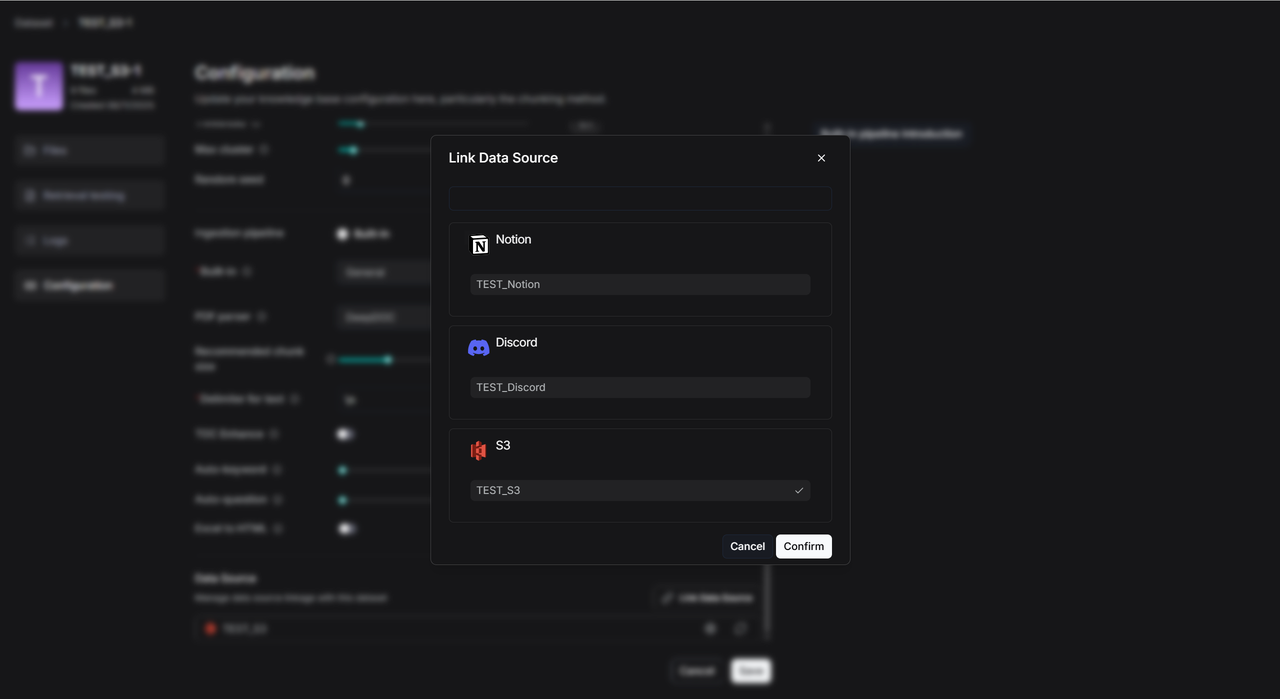
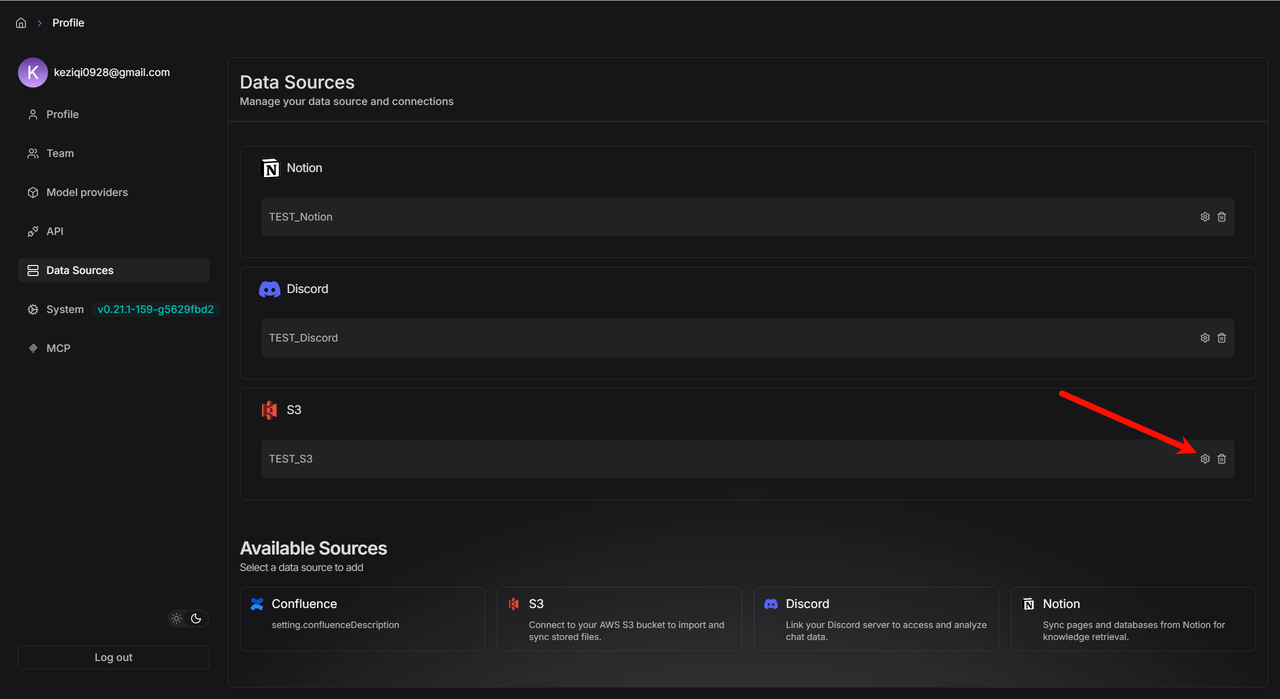
成功链接之后,有三个图标,一个是重新构建,一个是设置图标,一个是断开链接图标。
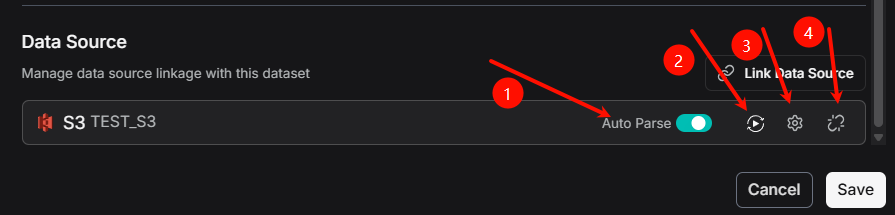
点击 1 处的 Auto Parse 按钮,文件就会在传入之后自动开始解析。
点击 2 处的重新构建图标按钮,在知识库里所有被导入的文件和日志都将被删除,然后重新导入文件。
点击 4 处的断开链接图标,就可以解除关联。
选择 Unlink ,解除关联的数据源 ,知识库已经上传的所有文件都将保留,只是不会向这个知识库同步文件了。
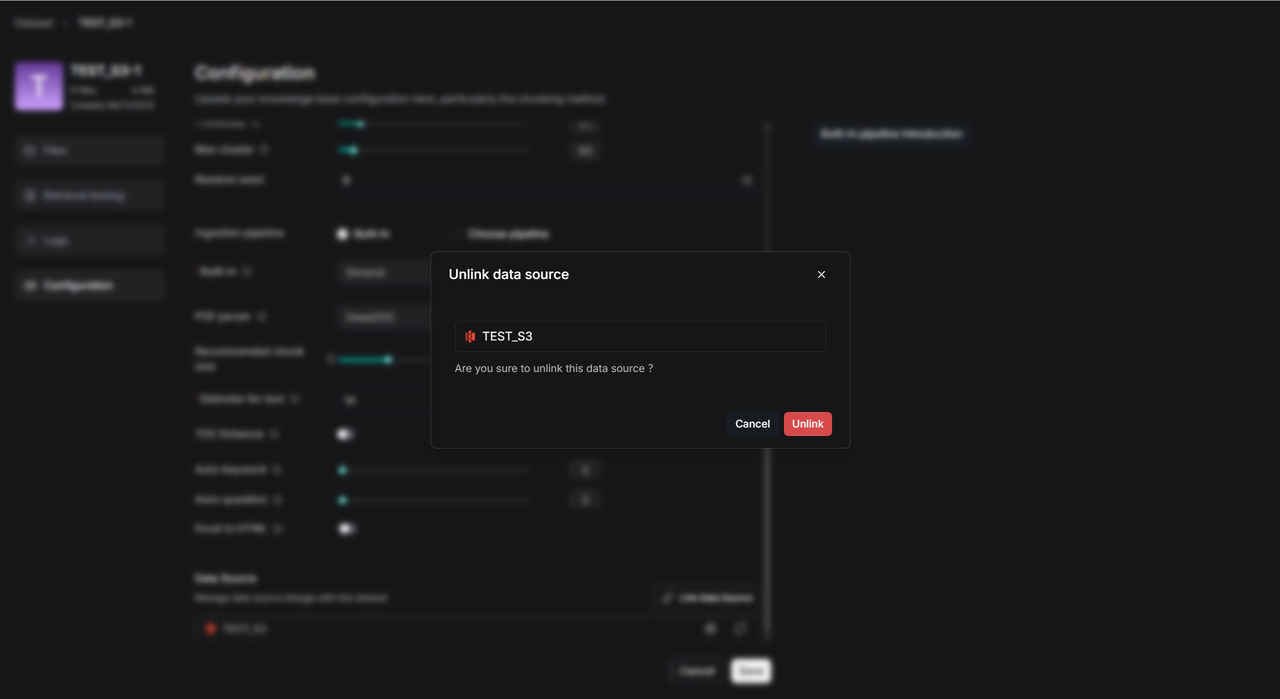
在知识库里,点击 3 处的设置图标,然后可以查看同步的日志。
Status 中的 Schedule 表示任务已列入计划,正在队列中等待执行下一次文件检查。
Running 指正在传输文件。
Success 表示已经完成一次“查看有没有新文件要上传”。
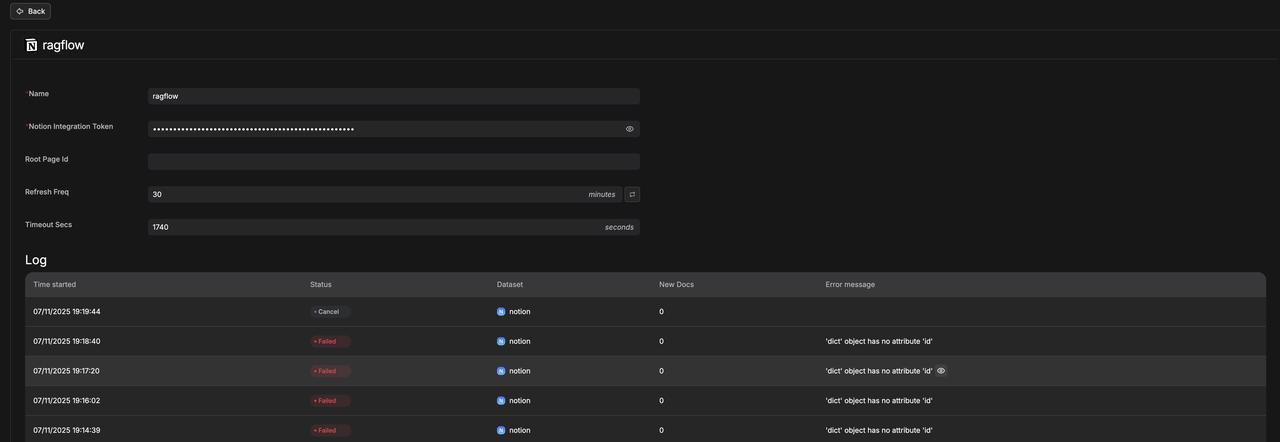
Failed 是指上传失败,在 Error message 里会有报错原因。
Cancel 指的是点击了“暂停”图标之后暂停传输。
S3 数据源成功传输并解析文件。
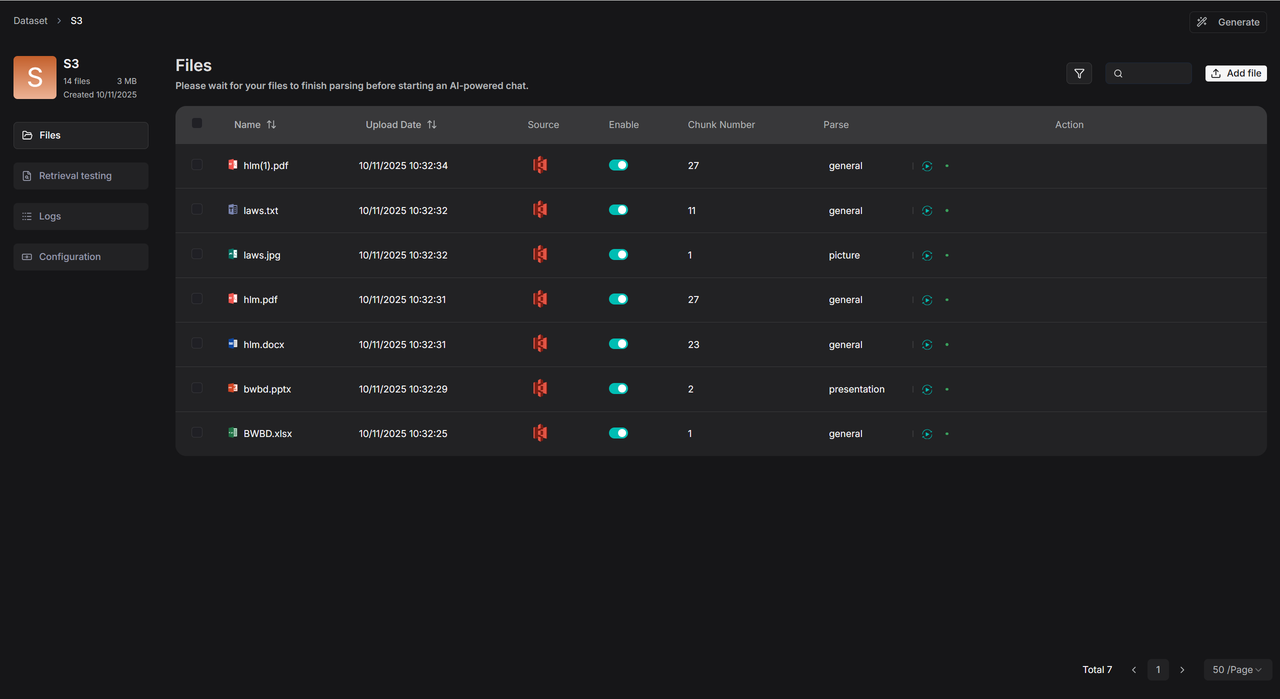
一个知识库可以链接多个数据源。
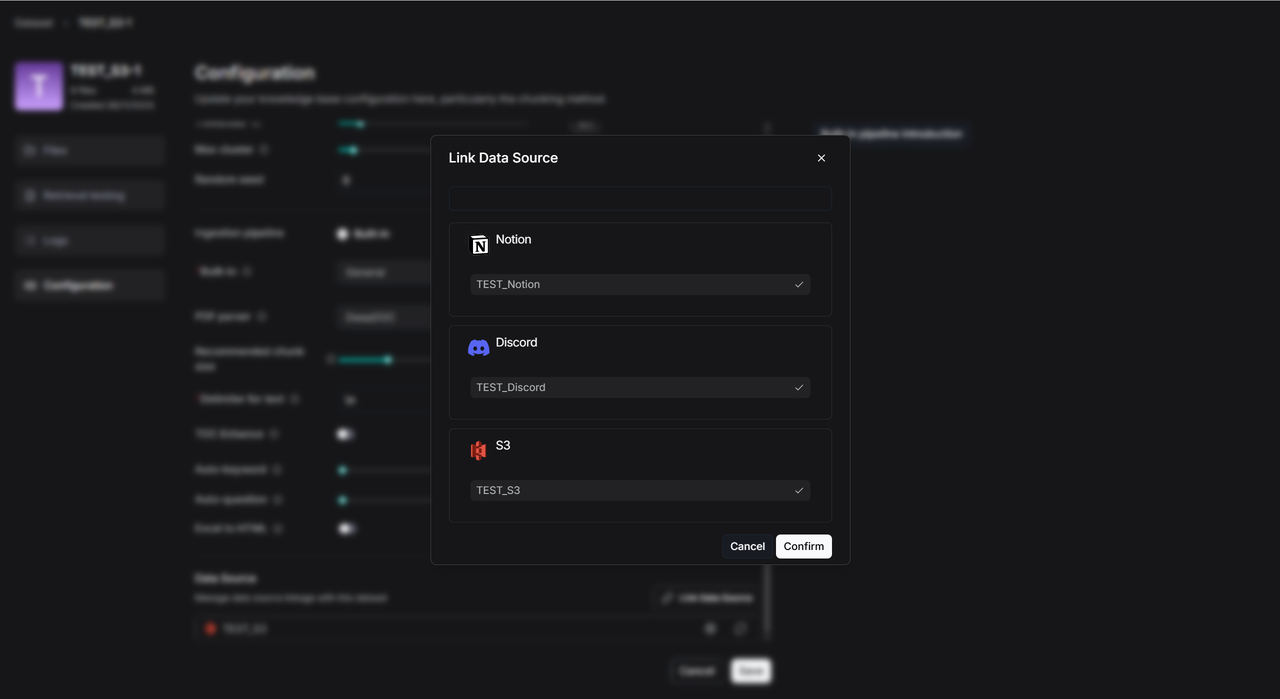
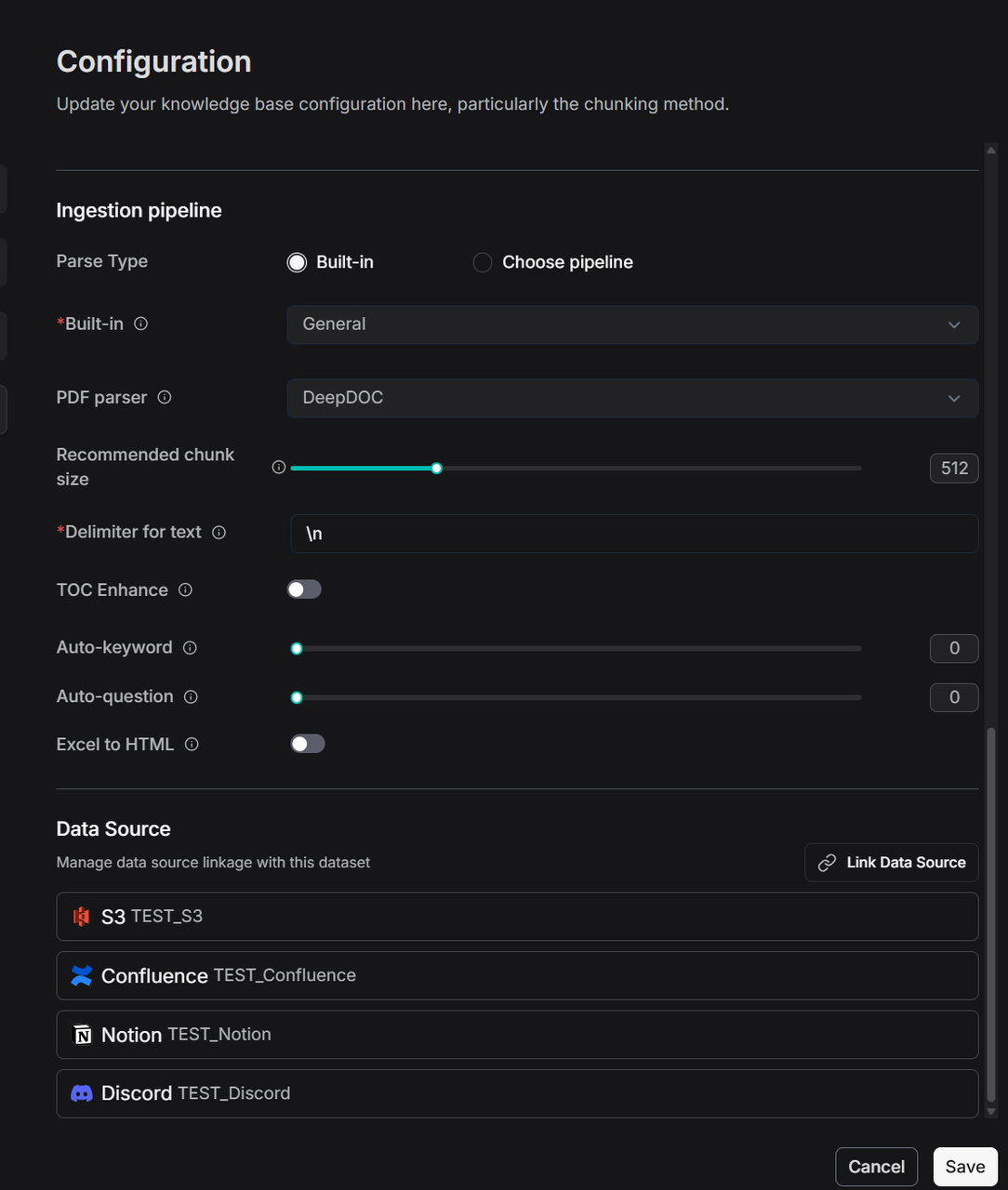
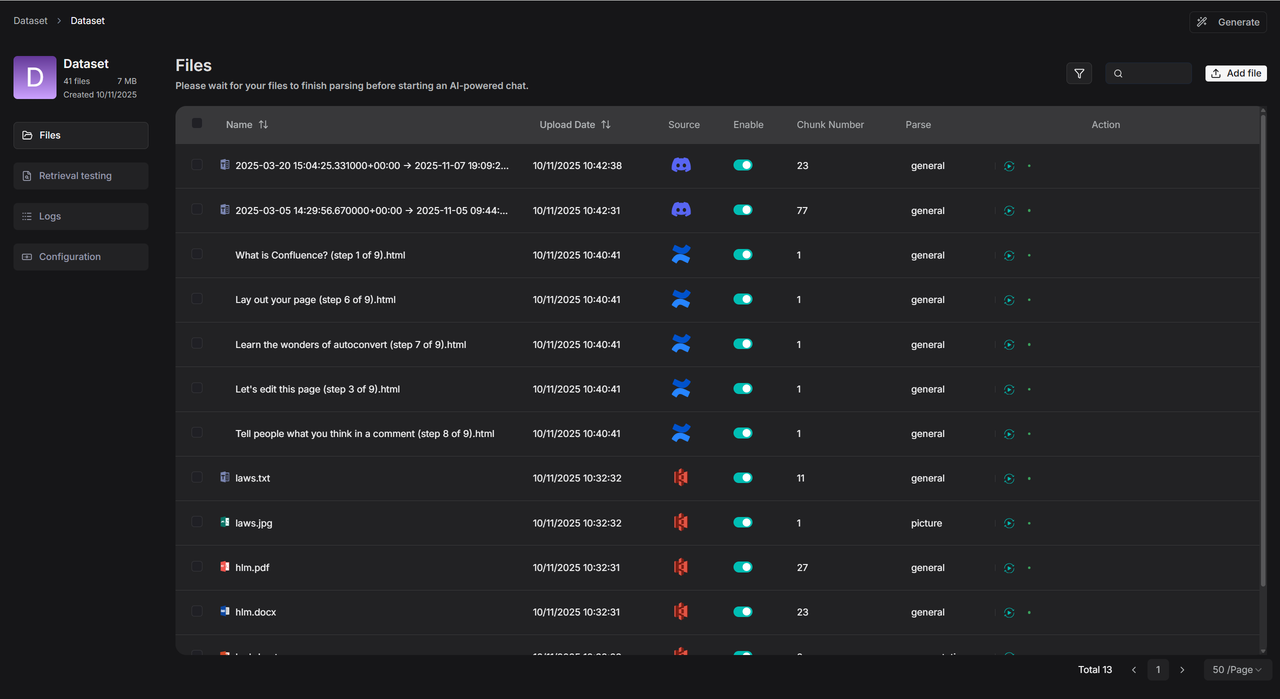
一个数据源可以被多个知识库所链接。
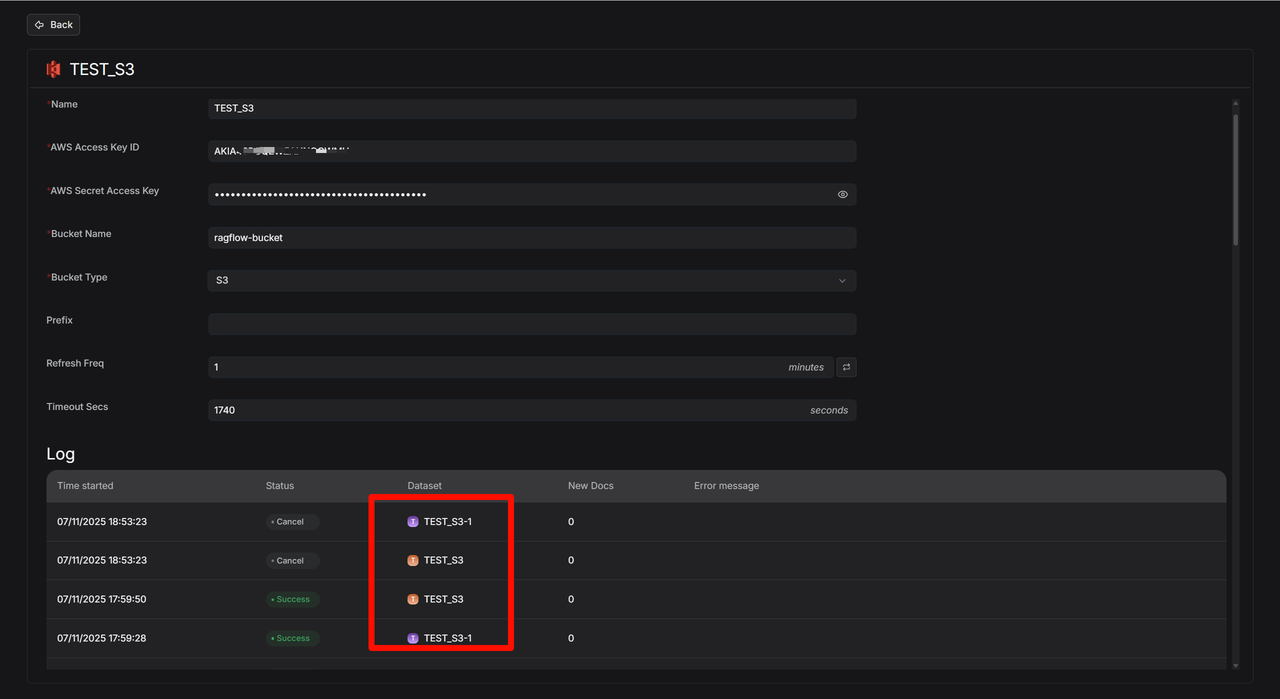
Confluence
Confluence 数据源详情:
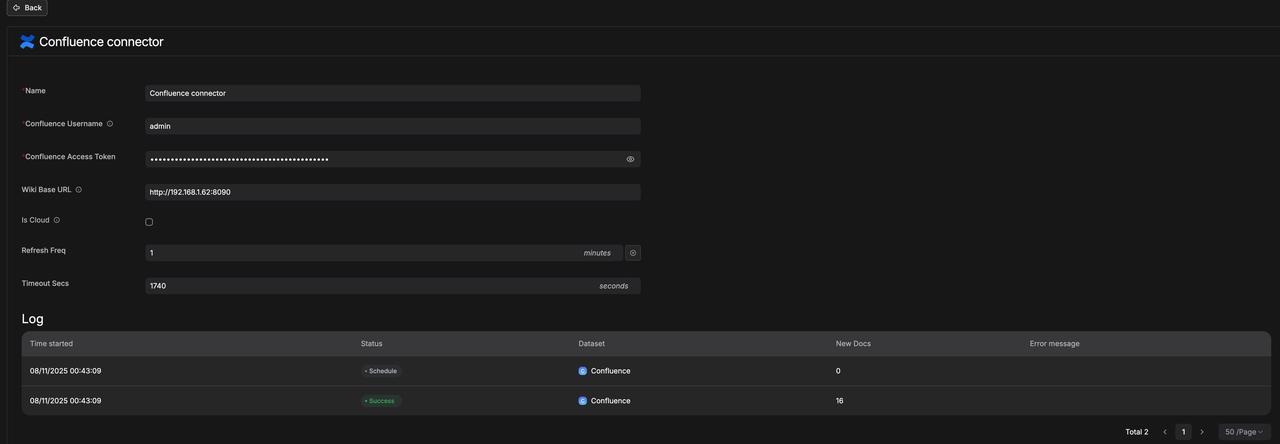
从 Confluence 传输文件,并解析成功。
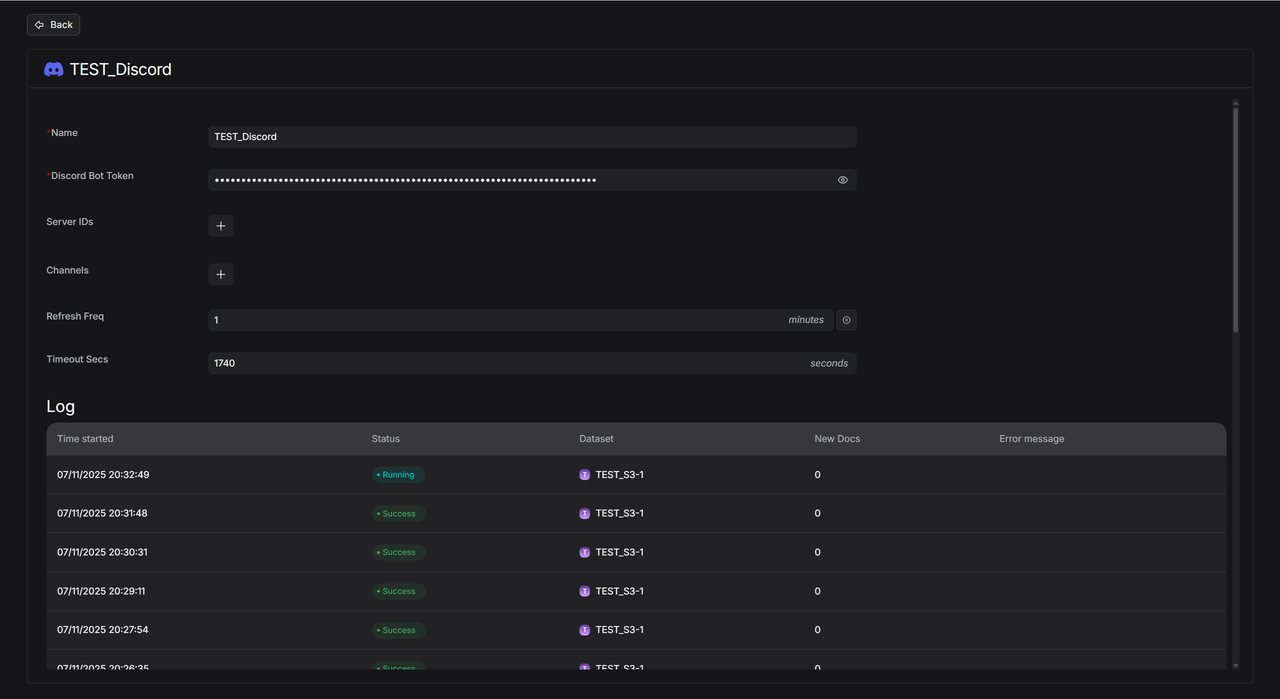
Discord
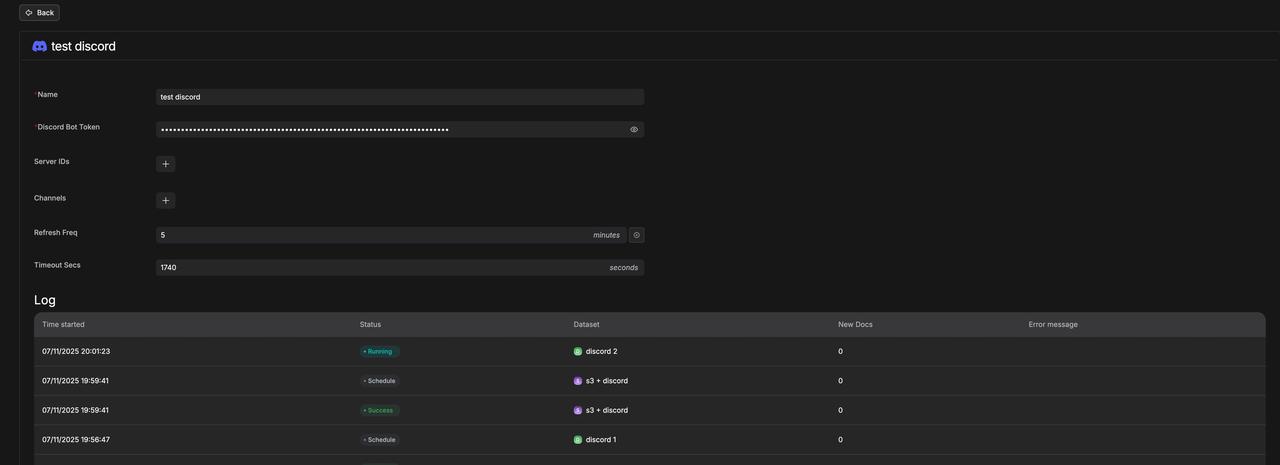
Discord 数据源详情:
从 Discord 传输文件,并解析成功。

Notion
Notion 数据源详情:
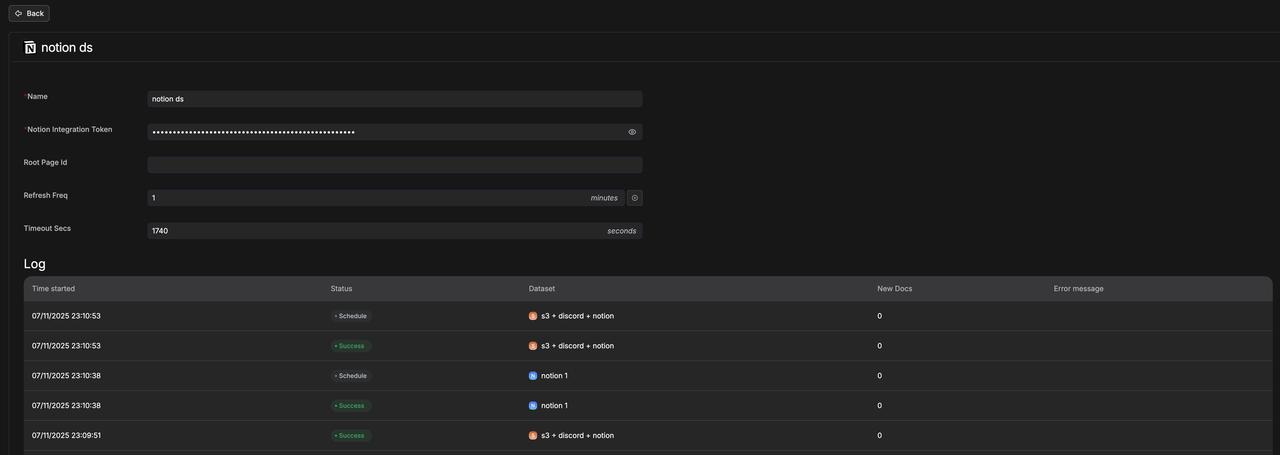
从 Notion 传输文件,并解析成功。

Google Drive
Google Drive 数据源详情:
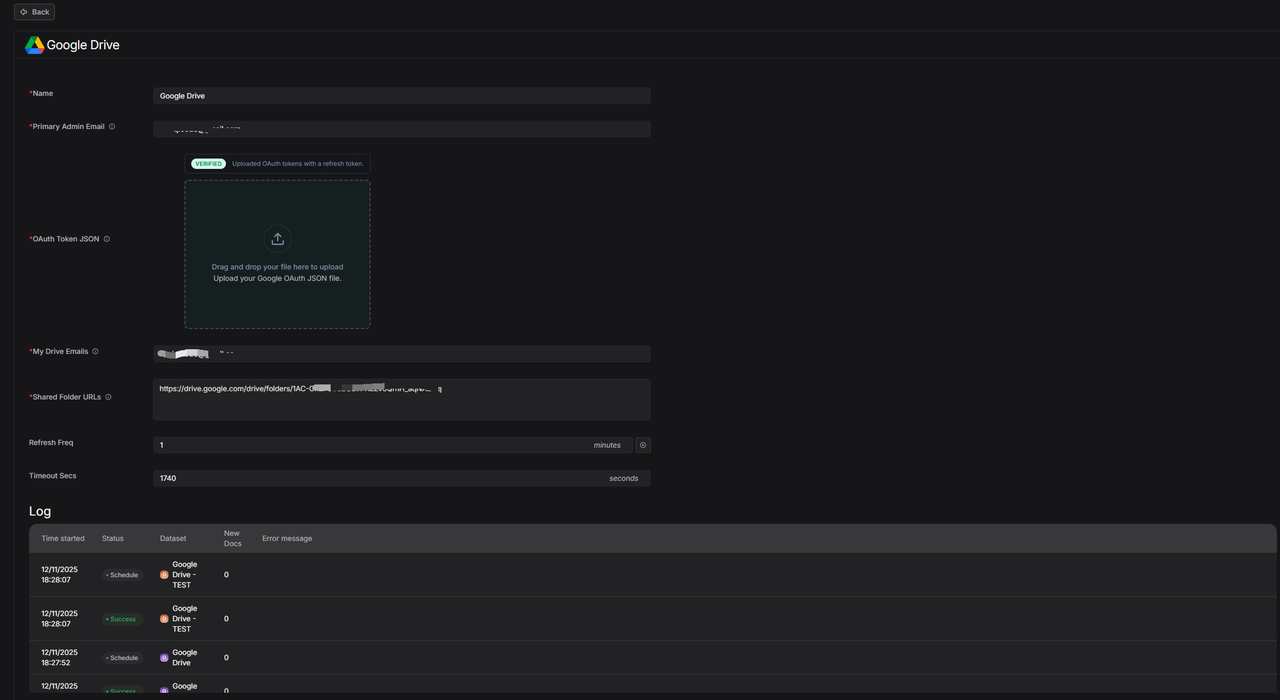
从 Google Drive 传输文件,解析文件。
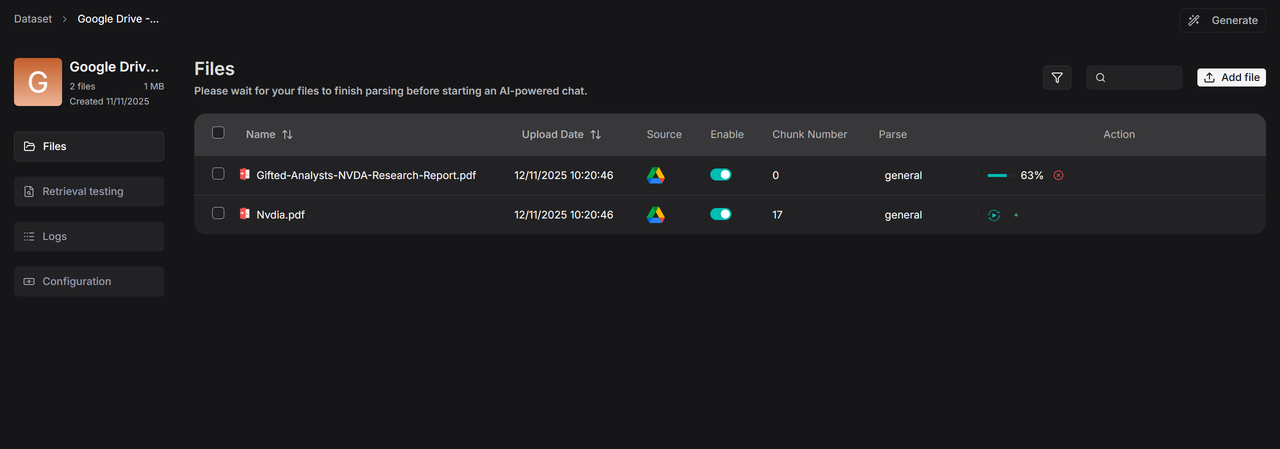
下面链接展示如何为 RAGFlow 添加 Google Drive 数据源,指导开发者完成配置:
https://ragflow.io/blog/2025/11/12/ragflow-google-drive-data-source-guide
完善 Parser
MinerU
RAGFlow 现已支持 MinerU 2.6.3 作为可选的 PDF 解析器,兼容 pipeline、vlm-transformers、vlm-vllm-engine 以及 http-client 等多种后端。具体配置方法可参考【文献 1】。
该设计的核心理念是让 RAGFlow 作为客户端调用 MinerU 执行文件解析操作,随后读取 MinerU 的输出文件,并将解析结果无缝融入 RAGFlow 的知识库体系中,从而实现灵活且高质量的文档解析流程。
开发者需关注的环境变量:
| 环境变量 | 解释 | 默认值 | 示例 |
|
| 本地MinerU可执行文件 |
|
|
|
| 是否删除MinerU输出目录 |
|
|
|
| MinerU 输出文件目录 | 系统决定的临时文件目录 |
|
|
| MinerU backend |
|
|
启动时可以注意:
-
当使用
vlm-http-client作为后端时,需要使用环境变量MINERU_SERVER_URL指定服务器的地址。 -
当希望连接到远程的 MinerU 作为 parse r而不是本地的 MinerU 的时候,需要使用环境变量
MINERU_APISERVER来指定远程 MinerU 的地址。
RAGFlow 提供两种启动方式。
-
从源码启动:
因为 MinerU 的依赖与 RAGFlow 不兼容,所以需要在系统或任意目录安装 MinerU 。
以在$HOME/uv_tools安装为例:
$ mkdir -p "$HOME/uv_tools"
$ cd "$HOME/uv_tools"
$ uv venv .venv
$ source .venv/bin/activate
$ uv pip install -U "mineru[core]" -i https://mirrors.aliyun.com/pypi/simple
# or
# uv pip install -U "mineru[all]" -i https://mirrors.aliyun.com/pypi/simple接着指定环境变量并启动 RAGFlow server:
# in RAGFlow repo
$ export MINERU_EXECUTABLE="$HOME/uv_tools/.venv/bin/mineru"
$ export MINERU_DELETE_OUTPUT=0 # keep output directory
$ export MINERU_BACKEND=vlm-transformers $ source .venv/bin/activate
$ export PYTHONPATH=$(pwd)
$ bash docker/launch_backend_service.sh-
使用 docker 启动:
先在docker/.env开启相关选项:
# docker/.env ... USE_MINERU=true ...
接着重新启动相关容器:
# in RAGFlow repo
$ docker compose -f docker/docker-compose.yml restartDocling
RAGFlow 也已支持 Docling 作为可选的 PDF parser,保持与 MinerU 一致的“客户端调用外部解析器→读取输出→融合入 RAGFlow 文档流”的设计思路。
Docling 负责解析版面/段落/公式/表格与图像位置;RAGFlow 仅作为客户端调用并消费解析结果。
核心能力包括:
-
文本片段提取:正文、标题、列表等(
TEXT) -
公式提取:
EQUATION -
表格与图片裁切:输出表格 HTML 与图片(
TABLE/PICTURE) -
位置标注
启动步骤:
先在docker/.env开启相关选项:
# docker/.env ... USE_DOCLING=true ...
接着再重新启动相关容器:
# in RAGFlow repo
$ docker compose -f docker/docker-compose.yml restartAgent 优化
Retrieval 引入 Metadata
RAGFlow 在知识库层面提供了 Metadata 配置能力,使用户可以为知识库中的文件定义多个标签。这些标签可在检索召回阶段作为过滤条件使用,帮助用户仅基于特定文件集而非整个知识库进行搜索与问答,从而实现更精准的知识检索体验。
例如下图案例中,知识库中存放的都是 AI 相关的论文。
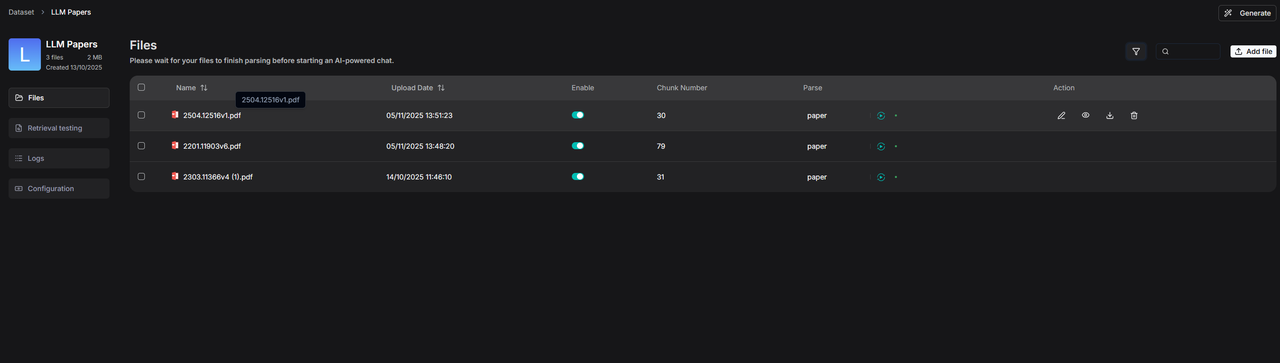
一部分话题和智能体相关。
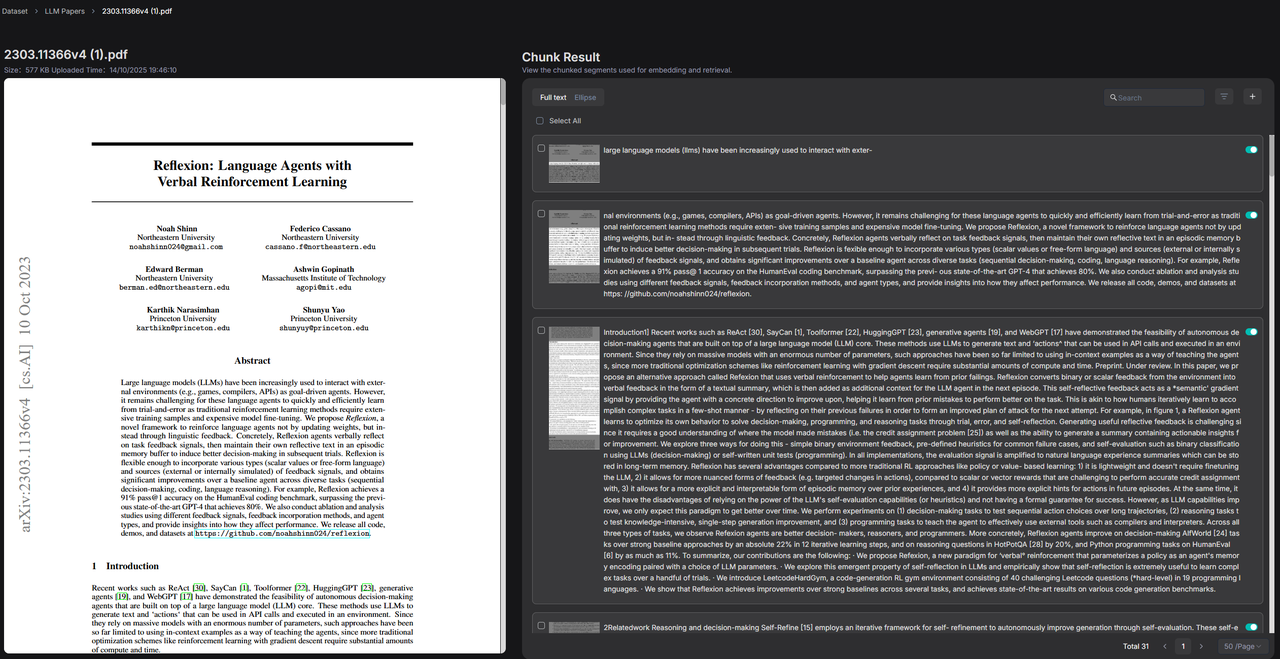
另一部分则和智能体评测有关。
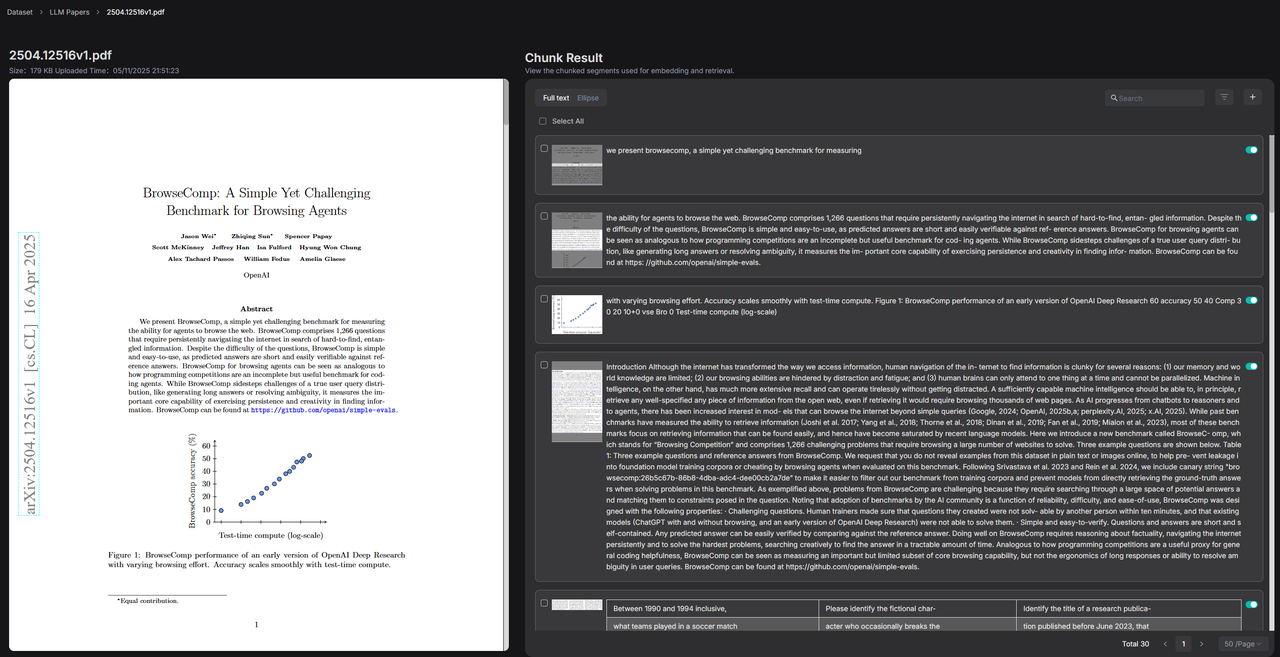
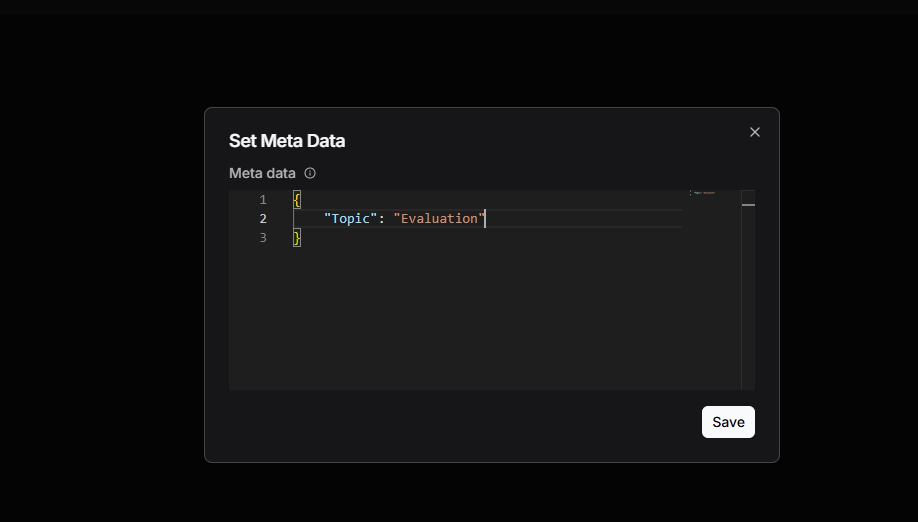
如果开发者希望基于该知识库构建面向大模型测评方向的智能问答助手,那么在不拆分知识库的前提下,可以为其中的论文 2504.12516v1.pdf 添加标签 "Topic": "Evaluation"。
通过这种方式,Agent 在检索阶段即可基于标签过滤,只聚焦于与模型评测相关的内容,实现更高效、更聚焦的问答体验。
过去我们只能在 Chat 应用里使用这个特性:
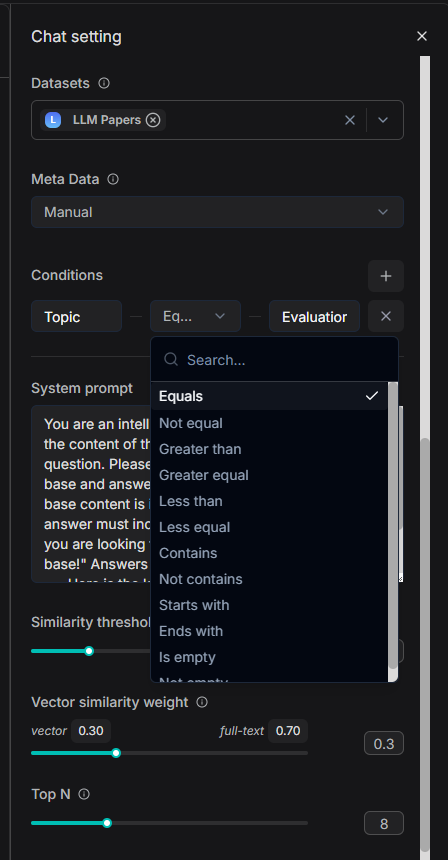
本版本之后 Agent 的 Retrieval 节点也支持了此特性。
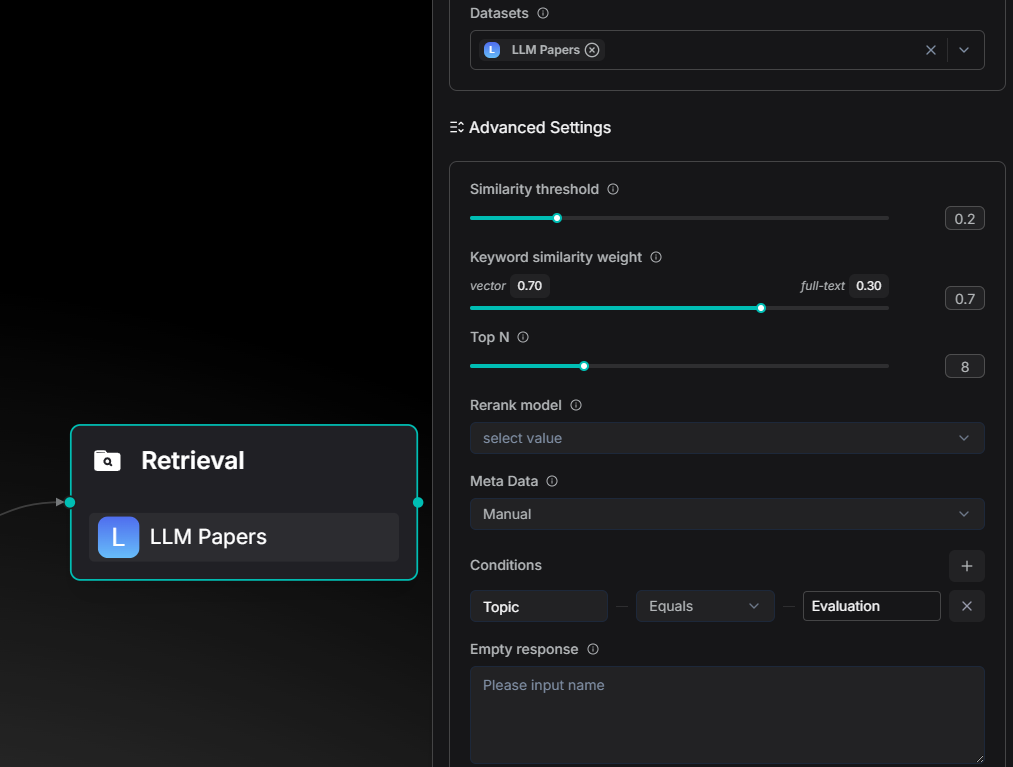
没有加上 Metadata 筛选之前,智能体检索的过程中会覆盖到智能体话题的知识库文件。
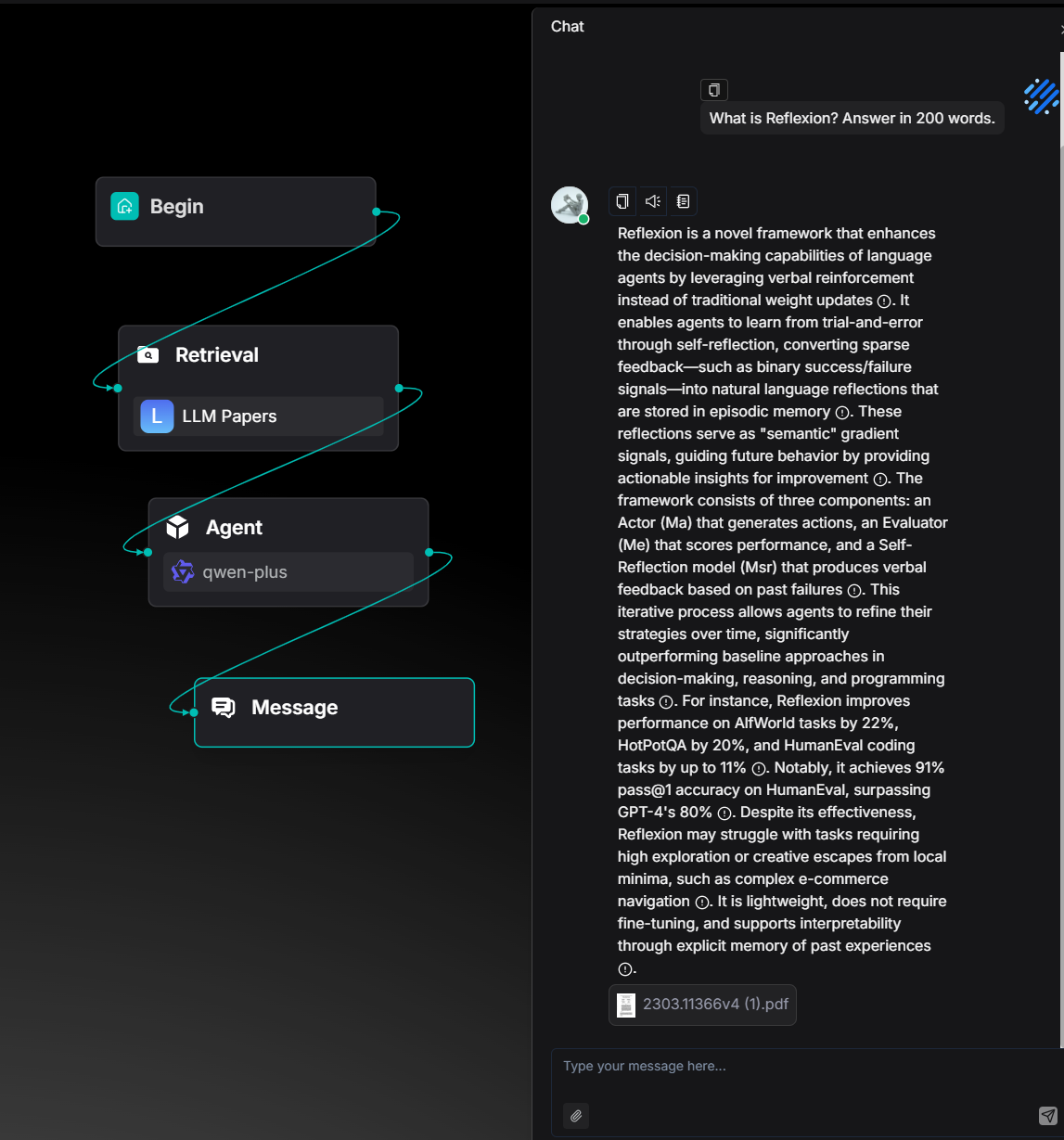
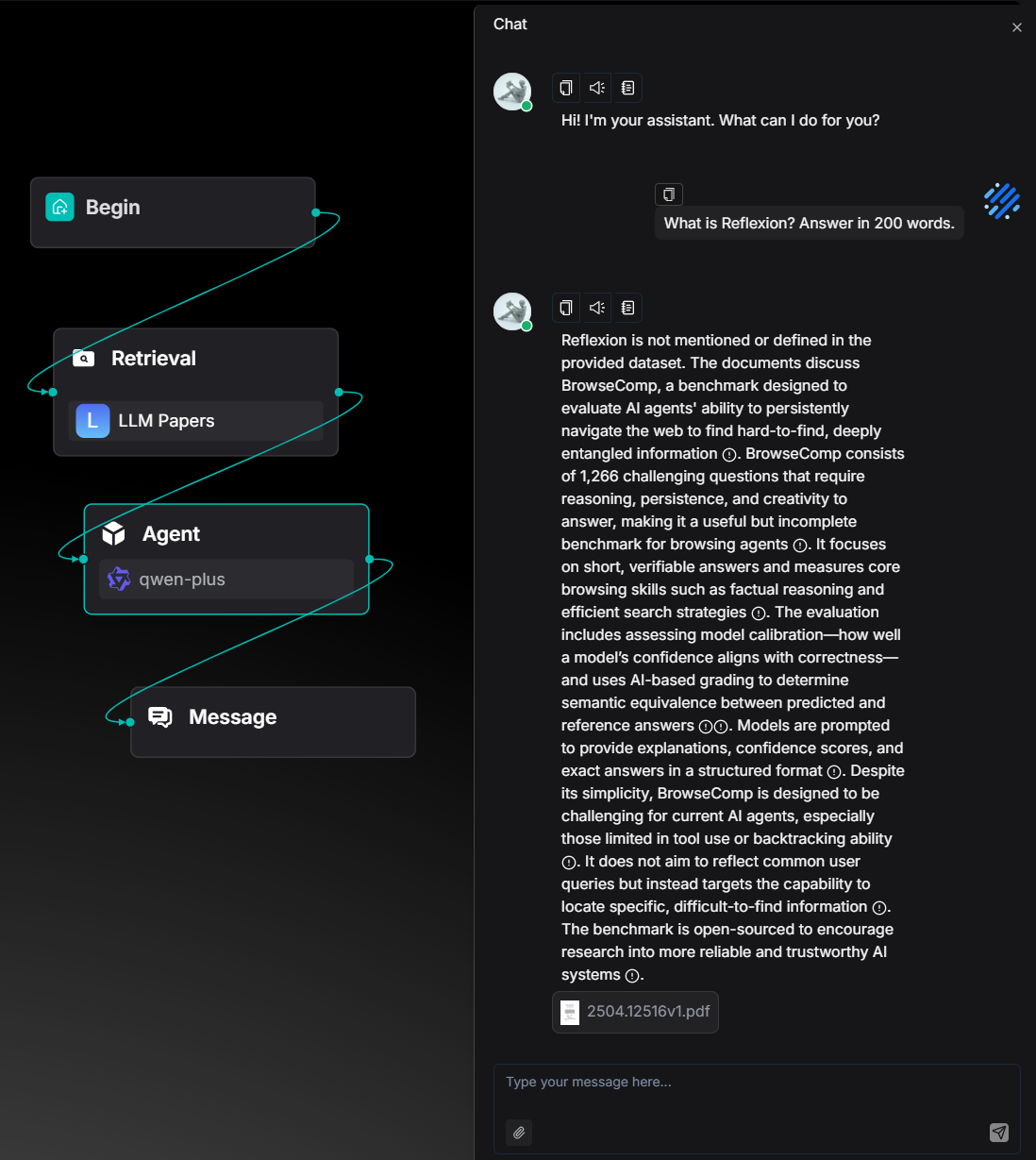
在添加 Metadata 过滤条件后,系统会将知识库的检索范围限定在带有 "Topic": "Evaluation" 标签的文件中。在本案例中,这意味着检索结果将仅来自论文 2504.12516v1.pdf,从而实现针对特定主题内容的精准问答与分析。
Agent 流程协作
我们还收到了多条诸如下图的 Feature Request,开发者期待能够在 Await Response 节点内展示上游 Agent 节点的输出。
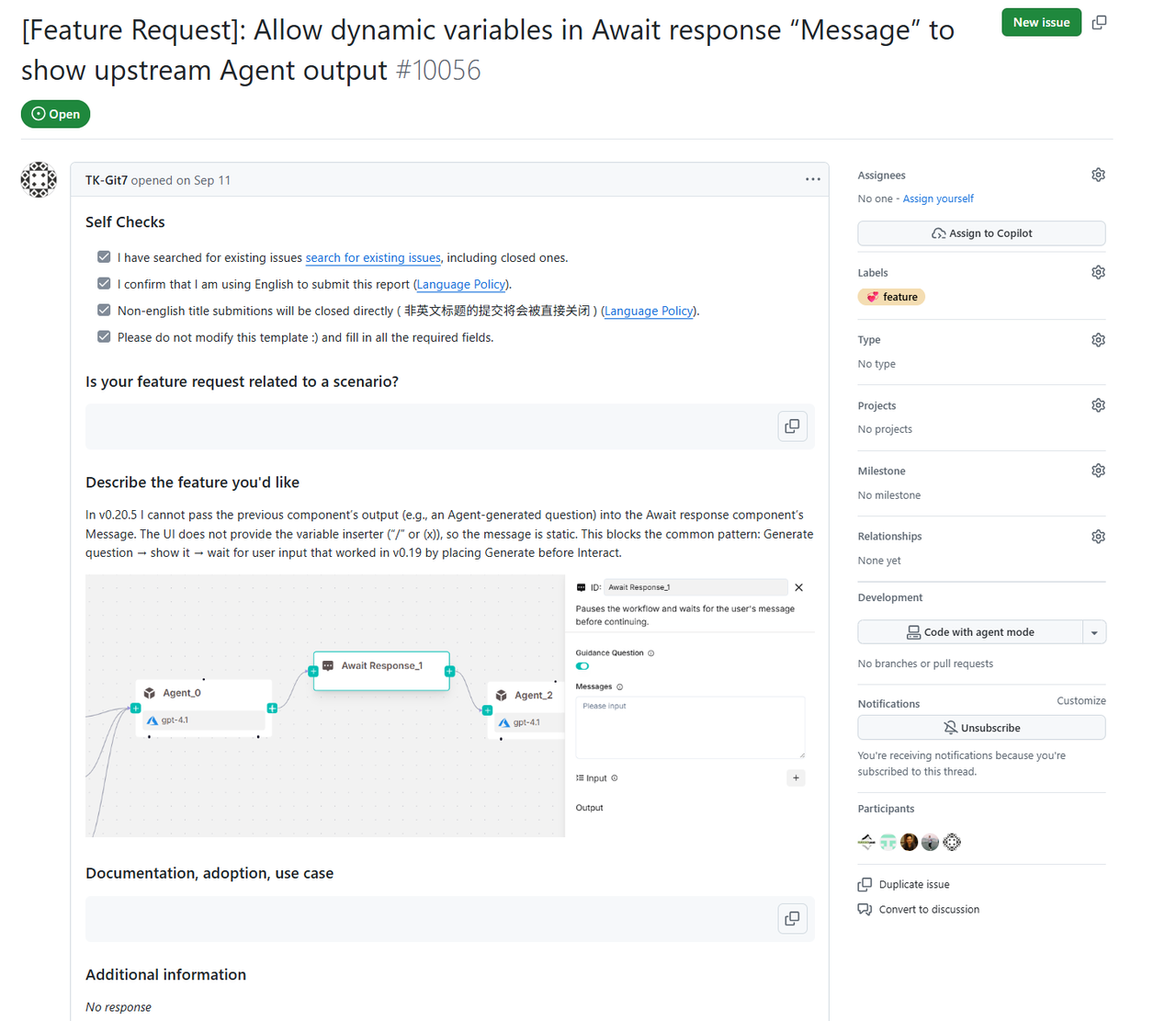
过去我们只能在 Await Response 的 Message 字段里写静态文本作为引导。
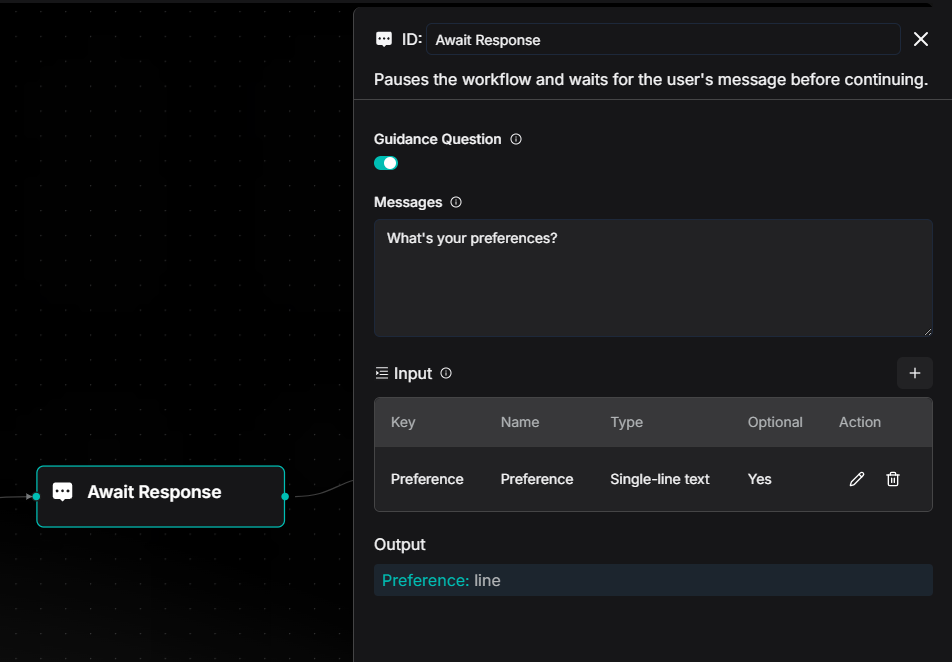
本次更新之后支持能够在引导对话里插入上游节点的输出变量。
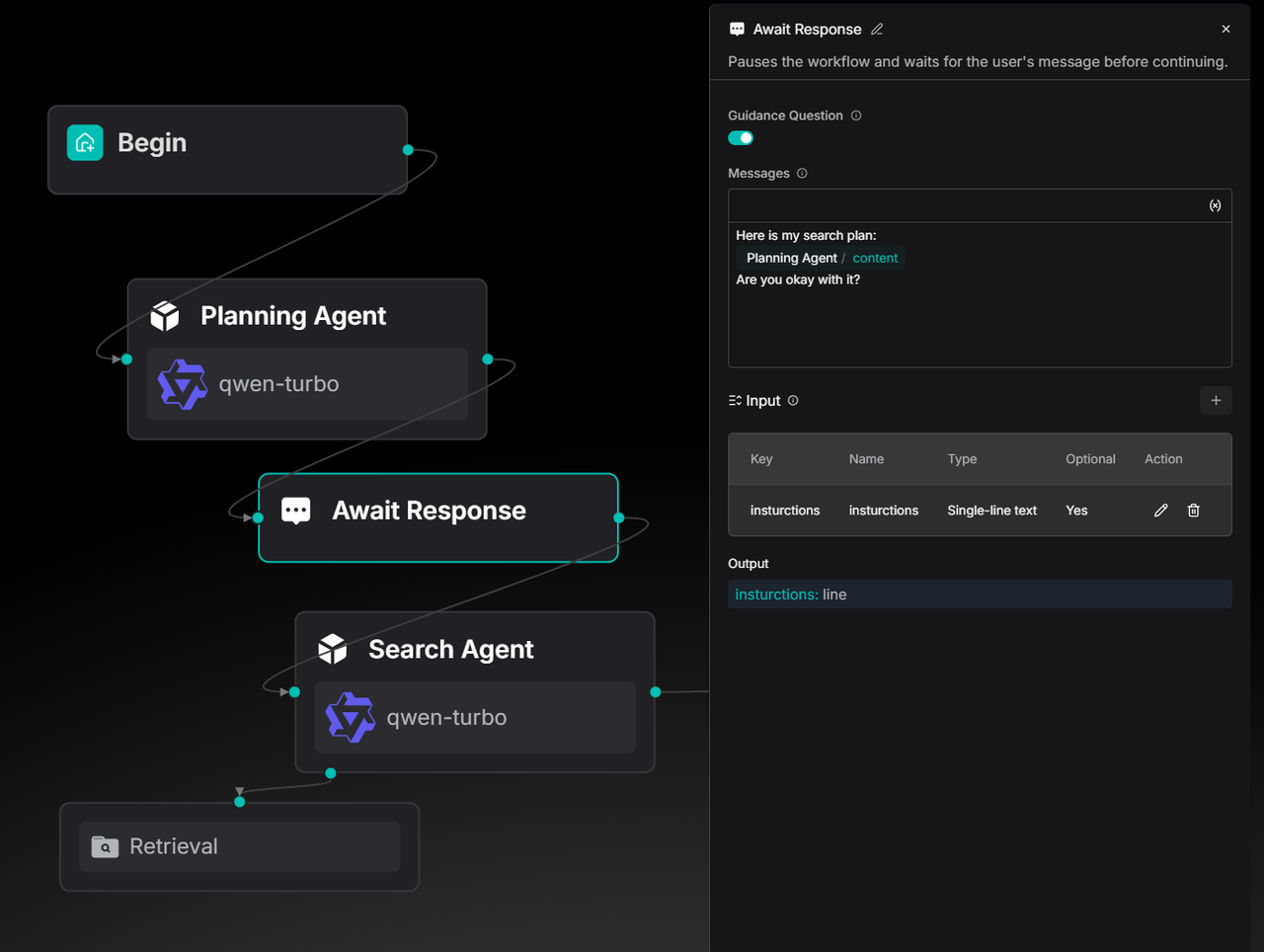
这对 Deep Research 类型的智能体以及需要人工参与决定工作流走向的场景十分有帮助,也是后续 Ingestion Pipeline 增强 Transformer 能力所依赖的基石。
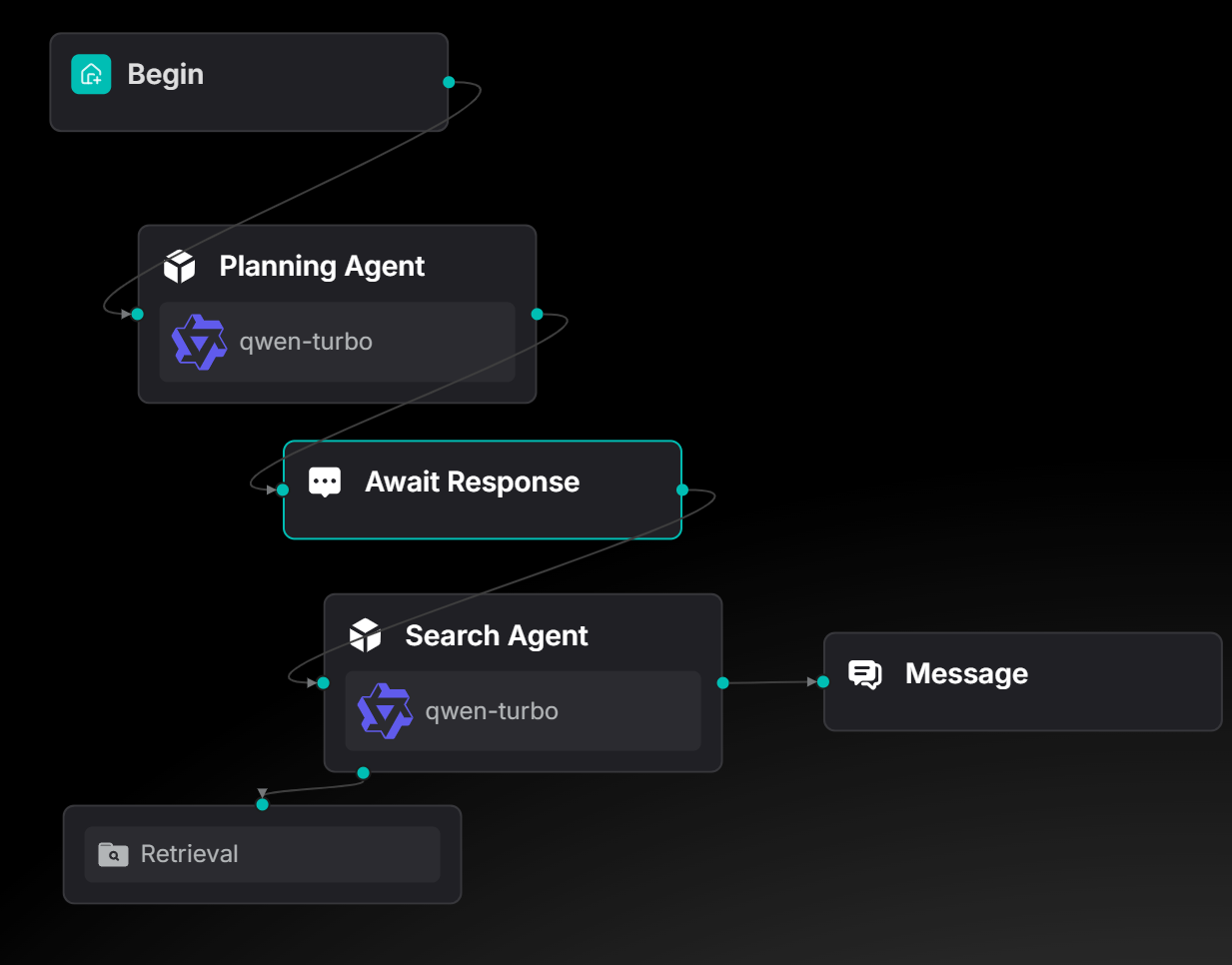
Agent 运作流程中可以让使用者介入给出自己对 Agent 的反馈。
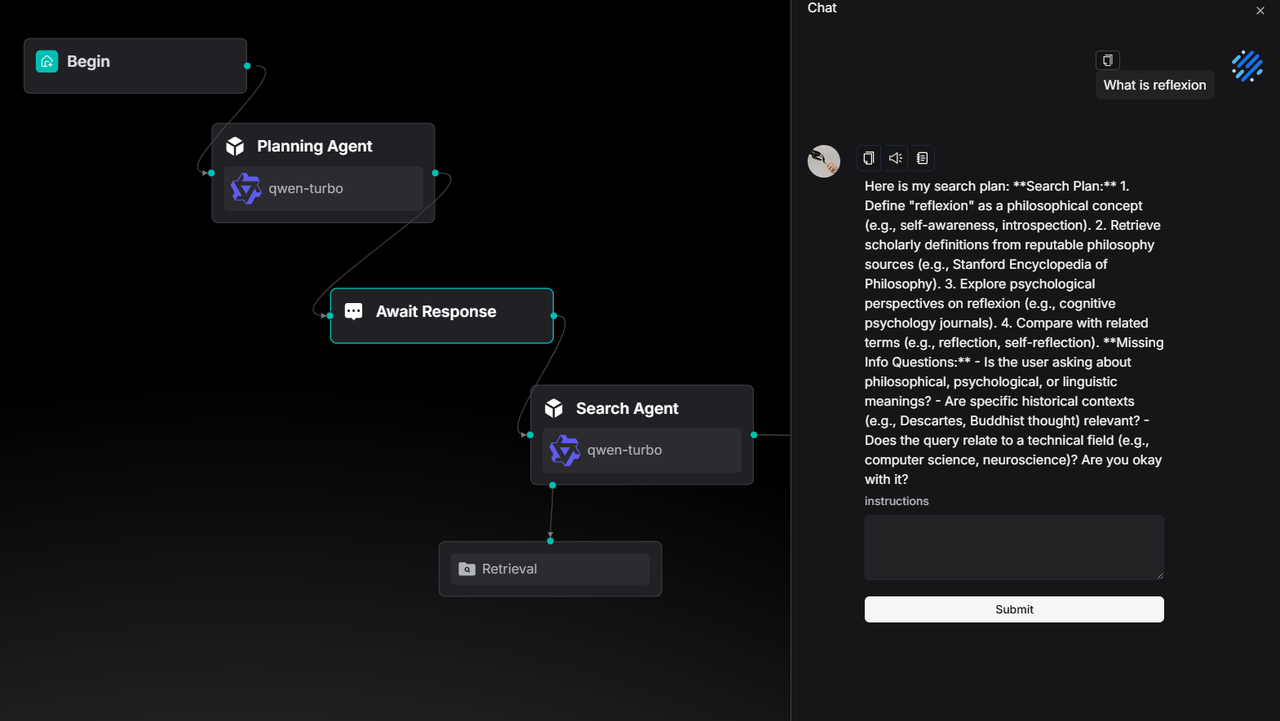
用户输入的反馈会调整智能体的输出或者工作流的进程。
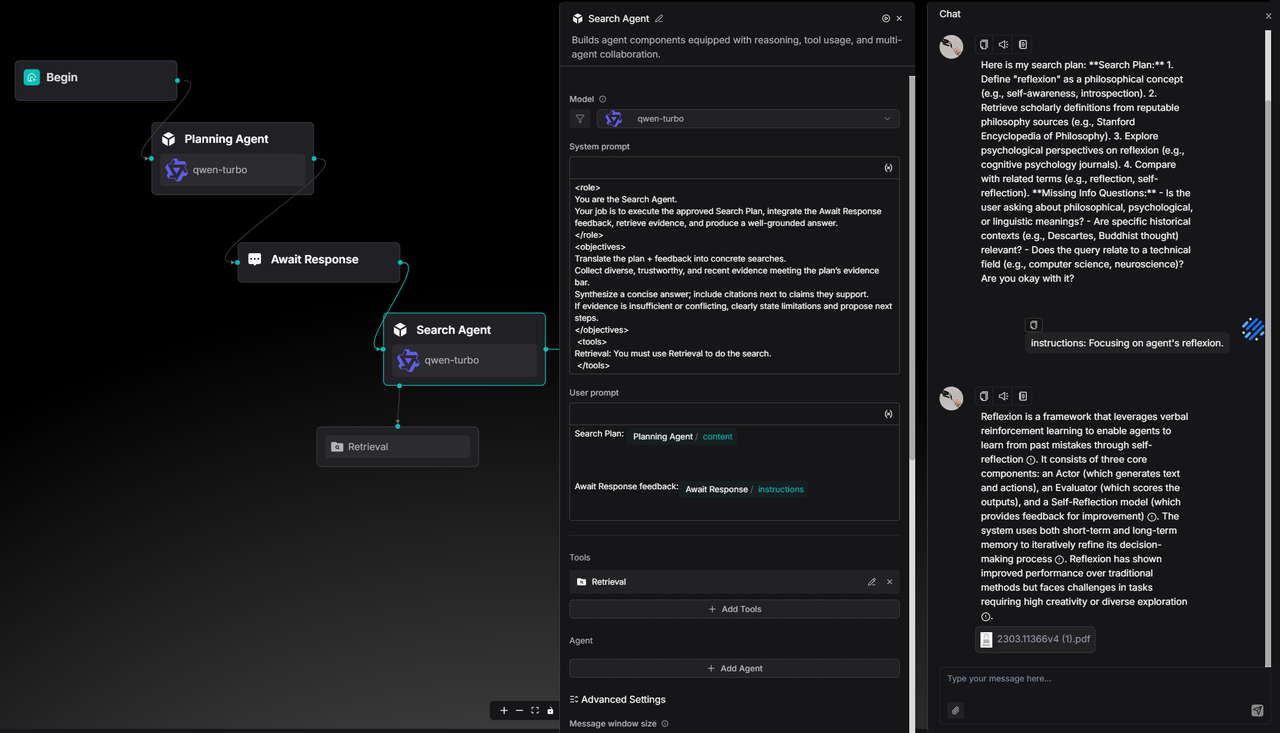
本案例已经在本期作为开源模板上架至智能体模板库。
Admin UI
本版本为 RAGFlow 带来了全新的Admin UI(管理员界面),这是一个专为系统管理员设计的可视化操作中心。
它将之前需要通过命令行完成的繁杂管理任务图形化、集中化,极大地提升了运维效率和用户体验。
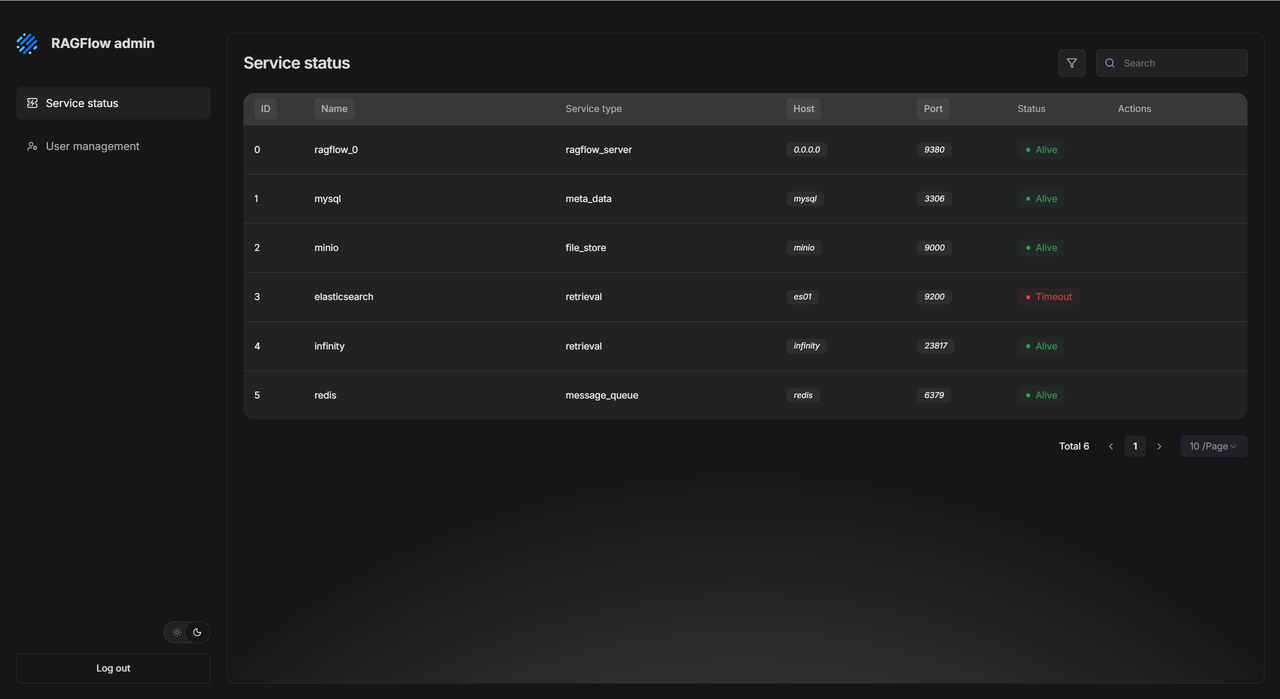
实时掌控系统状态
Admin UI 提供 Service status 看板,集中展示所有核心服务的运行状态,包括服务名称、类型、主机地址、端口和实时状态。一旦出现异常(如 Elasticsearch 或 MinIO 服务超时),管理员可快速定位问题,直接复制地址进行网络测试,再也不用在多台服务器间手动排查。
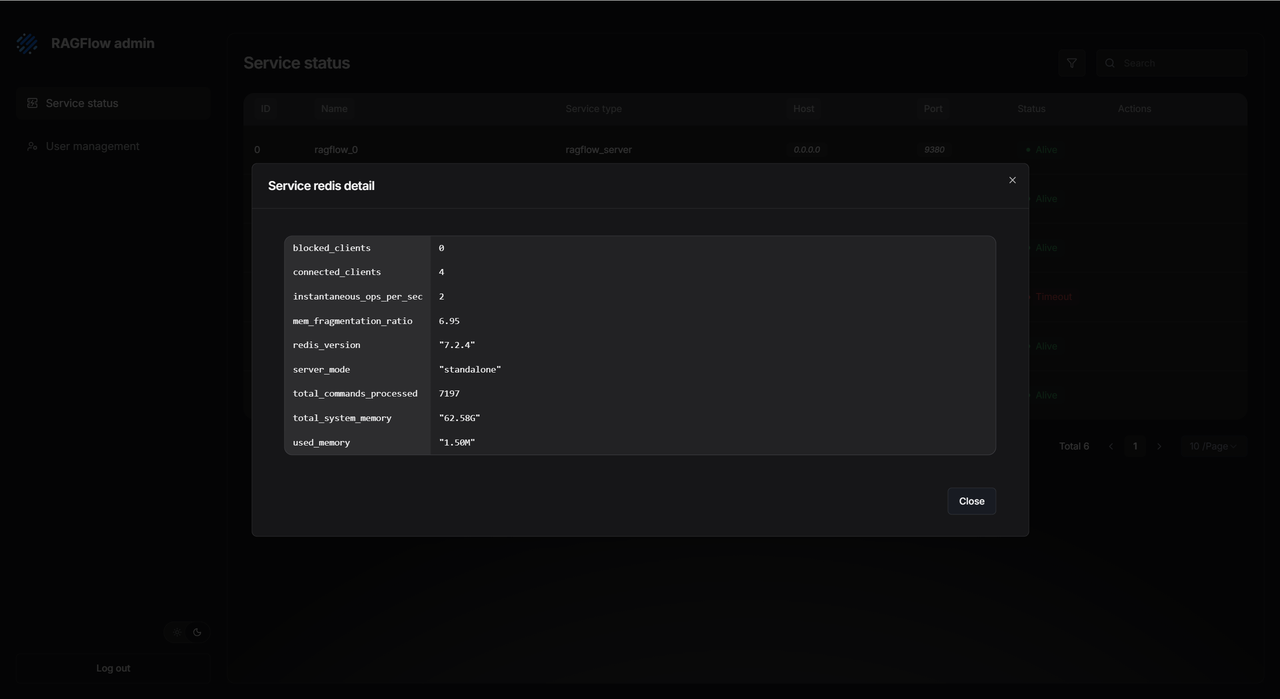
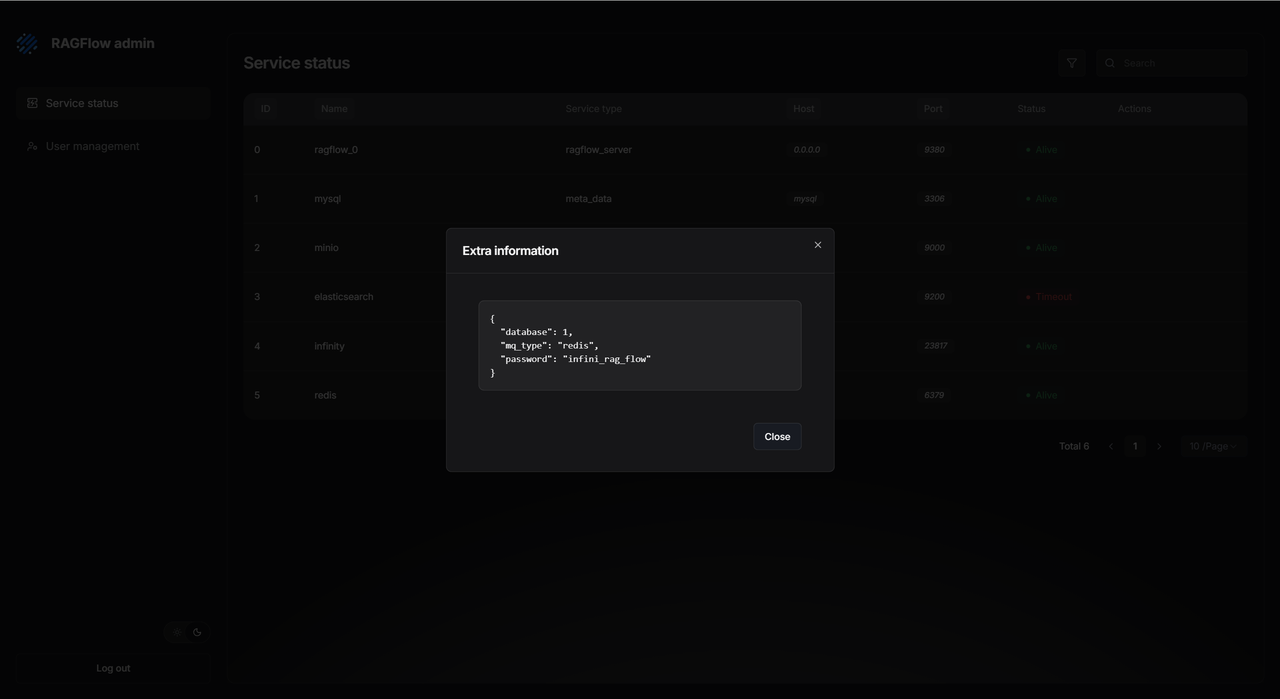
Admin UI 还可以提供服务的相关详情。无需登录服务器,即可查看服务详细日志与核心连接配置(如数据库地址、密码等),极大加速故障根因分析,提升系统透明度与安全性。
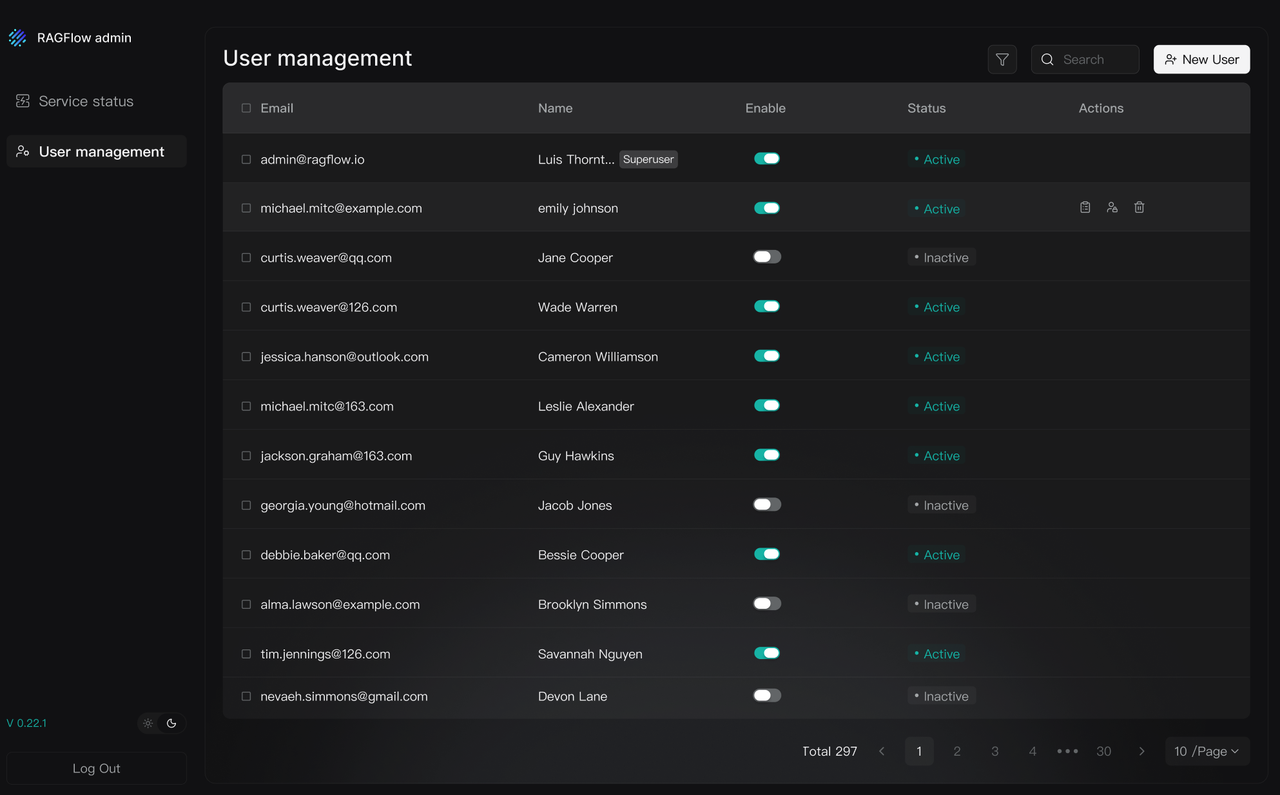
精细化用户管理
在 User management 模块中,管理员可完成用户的创建、启用/禁用、密码重置、删除等操作。支持按邮箱、昵称快速筛选用户,并直接查看每位用户名下的知识库与智能体。
写在最后
如果说 RAGFlow 0.21.0 所引入的 Ingestion pipeline 为企业非结构化数据的 ETL 提供了标准化工具体系,那么 RAGFlow 0.22.0 则进一步实现了对多种数据源的广泛接入,并支持数据源类型的灵活扩展。两者的协同配合,有效助力企业破解内部“数据孤岛”难题,将分散的数字资产统一汇聚至 RAGFlow 平台,为 LLM 提供高质量的数据支持。这些关键能力的构建,标志着 RAGFlow 作为面向 LLM 的一体化数据基座,已初步成型。
与此同时,我们在 Agent 协作机制上也迈出了关键一步,用户现在可以深度参与 Agent 的运作流程,与 Agent 协同完成任务,而非完全依赖全自动执行,从而获得更精准、更高质量的结果。而我们探索的脚步不止于此,未来,RAGFlow 将通过引入“Human-in-the-loop” 的协作机制,用户就可以深度介入 Agent 的思考与行动流程,在其关键决策点上给予指导、亲自校准。这种人与 Agent 的紧密协作,将超越全自动执行的不确定性,共同产出更精准、更高质量的可信成果。
未来,RAGFlow 将携手社区持续扩展更多数据源,进一步打通企业的各类数据资产;接入更多高质量 Parser 模型,全面提升文件解析效果;同时不断强化 Ingestion Pipeline 的能力,为企业级 Agent 提供更丰富、更可靠的 Context 能力支持,助力业务创新与价值增长。
欢迎您持续关注并 Star 我们的项目,一同见证 RAGFlow 的成长。
**GitHub: ** https://github.com/infiniflow/ragflow
参考文献:
-
https://ragflow.io/docs/dev/faq#how-to-use-mineru-to-parse-pdf-documents