Prim 与 Kruskal 算法在最小生成树中的应用
欢迎来到我的算法探索博客,在这里,我将通过解析精选的LeetCode题目,与您分享深刻的解题思路、多元化的解决方案以及宝贵的实战经验,旨在帮助每一位读者提升编程技能,领略算法之美。
👉更多高频有趣LeetCode算法题
👉LeetCode高频面试题题单
最小生成树:用最少的代价连接整个世界
掌握了MST,你就拥有了一把解决"连接问题"的万能钥匙。从城市规划到数据分析,从游戏开发到网络设计,这棵"树"能帮你在复杂世界中找到最优路径。
一、为什么要了解最小生成树?
想象一下,你是一家电信公司的工程师,需要在10个城市之间铺设光纤网络。每两个城市之间铺设光纤的成本各不相同,有的需要穿山越岭,有的只需平原铺设。你的任务是:用最少的钱让所有城市都能互相通信。
这就是最小生成树(Minimum Spanning Tree, MST)要解决的经典问题。
简单来说,最小生成树就是在一个连通图中,找到一组边,它们能:
- 连接所有的节点(城市)
- 不形成环路(不绕圈子浪费)
- 总权重(成本)最小
在图论中,有两种经典算法可以完美解决这个问题:Prim算法和Kruskal算法。它们就像两位不同风格的建筑师,用各自的方式搭建起最经济的网络。
二、最小生成树到底是什么?
用人话说
假设你有一张地图,上面标着若干城市和它们之间的道路(每条路都有修建成本)。最小生成树就是选出一些道路,确保:
- 所有城市都连通(从任意城市能到达任意其他城市)
- 没有多余的路(恰好n-1条路连接n个城市)
- 总修建成本最低
一个简单例子
城市A、B、C、D之间的道路成本:
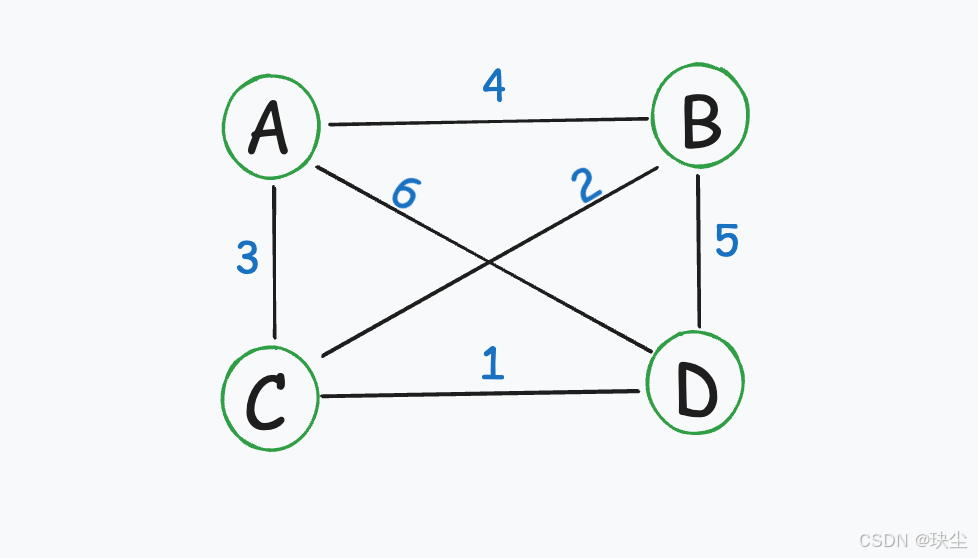
最小生成树的选择:
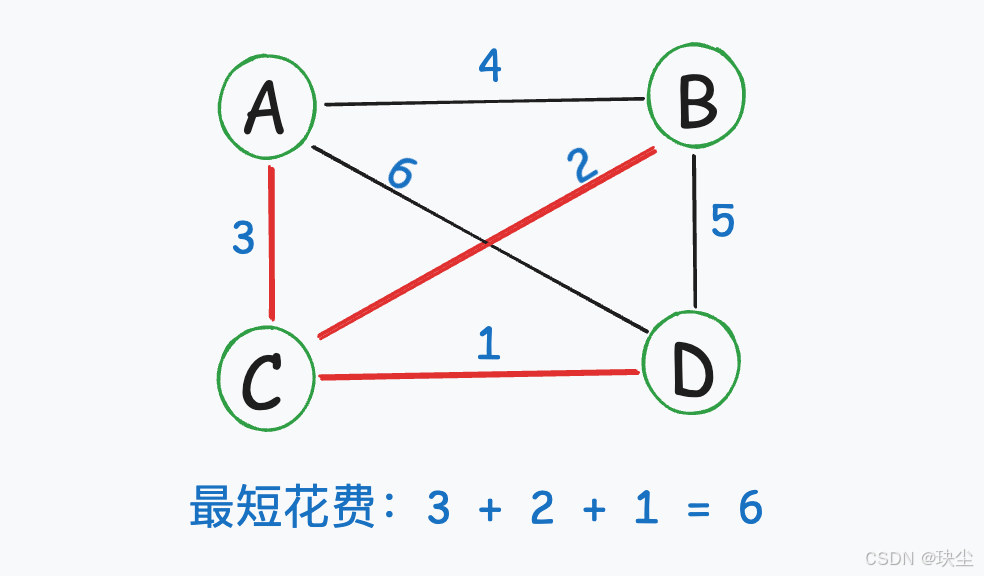
这样4个城市就都连通了,且成本最低!
三、Prim算法:像滚雪球一样长大
卡码网:53. 寻宝
力扣:1584. 连接所有点的最小费用
1135. 最低成本连通所有城市

算法直觉
想象你是城市规划师,手里有一块已经开发好的区域。每次你都选择一条最便宜的道路,把一个新城市纳入你的版图。 就像滚雪球一样,你的"连通区域"越滚越大,直到覆盖所有城市。
在理解 Prim 算法之前,先记住一句话:
Prim 算法的核心目标是——让生成树一点点“长大”,每次选一条连接树内与树外节点的最便宜的边。
要想把这件事做好,就必须理解 Prim 的三个重要步骤。
Prim三部曲
在 Prim 算法中,我们维护一个关键数组:minDist。
它的作用是——记录每一个节点距离当前生成树的最近距离。
可以这么理解:
对于每个还没加入生成树的节点,我们都要知道:
“它离生成树有多近?最短那条边的代价是多少?”
而这些最短距离,全部存在minDist数组里。
Prim 算法每次迭代就是围绕 minDist 进行更新的,因此我们称它的核心流程为 Prim 三部曲:
1️⃣ 选距离生成树最近的节点
遍历 minDist 数组,找到距离最小的那个节点(还没在生成树里)。
2️⃣ 最近节点加入生成树
把刚刚找到的节点标记为已加入(即成为生成树的一部分)。
3️⃣ 更新非生成树节点到生成树的距离
也就是更新 minDist 数组——
看看有没有更短的边可以让其他节点更便宜地连接进来。
这三步循环执行,直到所有节点都被纳入生成树中。
很多人第一次看 Prim 代码时一头雾水,其实只要抓住这三步,整个算法就清晰多了。
模拟过程
在算法开始时,我们会先把 minDist 数组中所有节点的距离初始化为一个很大的数。
为什么要这样做呢?
因为在最初阶段,还没有任何节点被加入最小生成树,也就是说——每个节点到生成树的“最近距离”是未知的。为了后续更新方便,我们先假设这些距离都“无限远”。这样,当我们在遍历边时,只要发现有比当前记录更小的距离,就可以立即更新对应节点在 minDist 数组中的值。
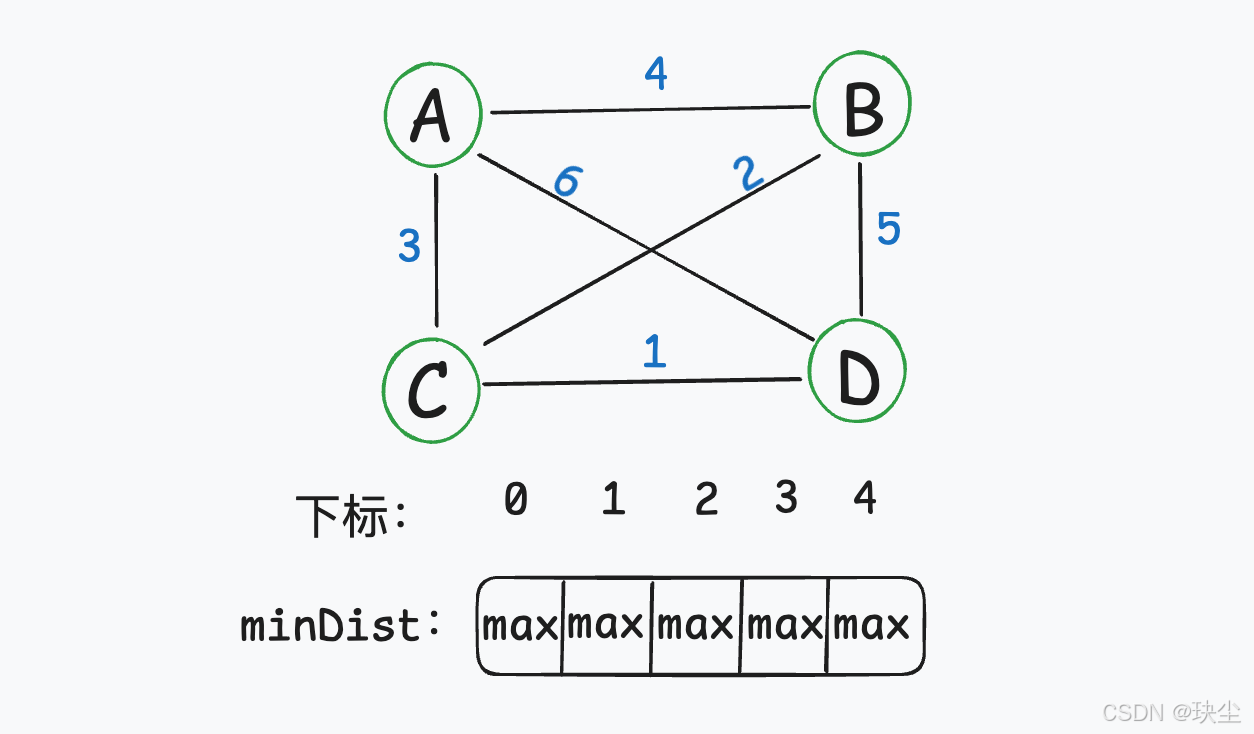
下面开始构造最小生成树。
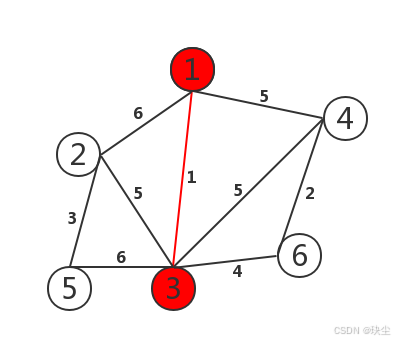
第一轮:
(1) 找距离当前生成树最近的城市
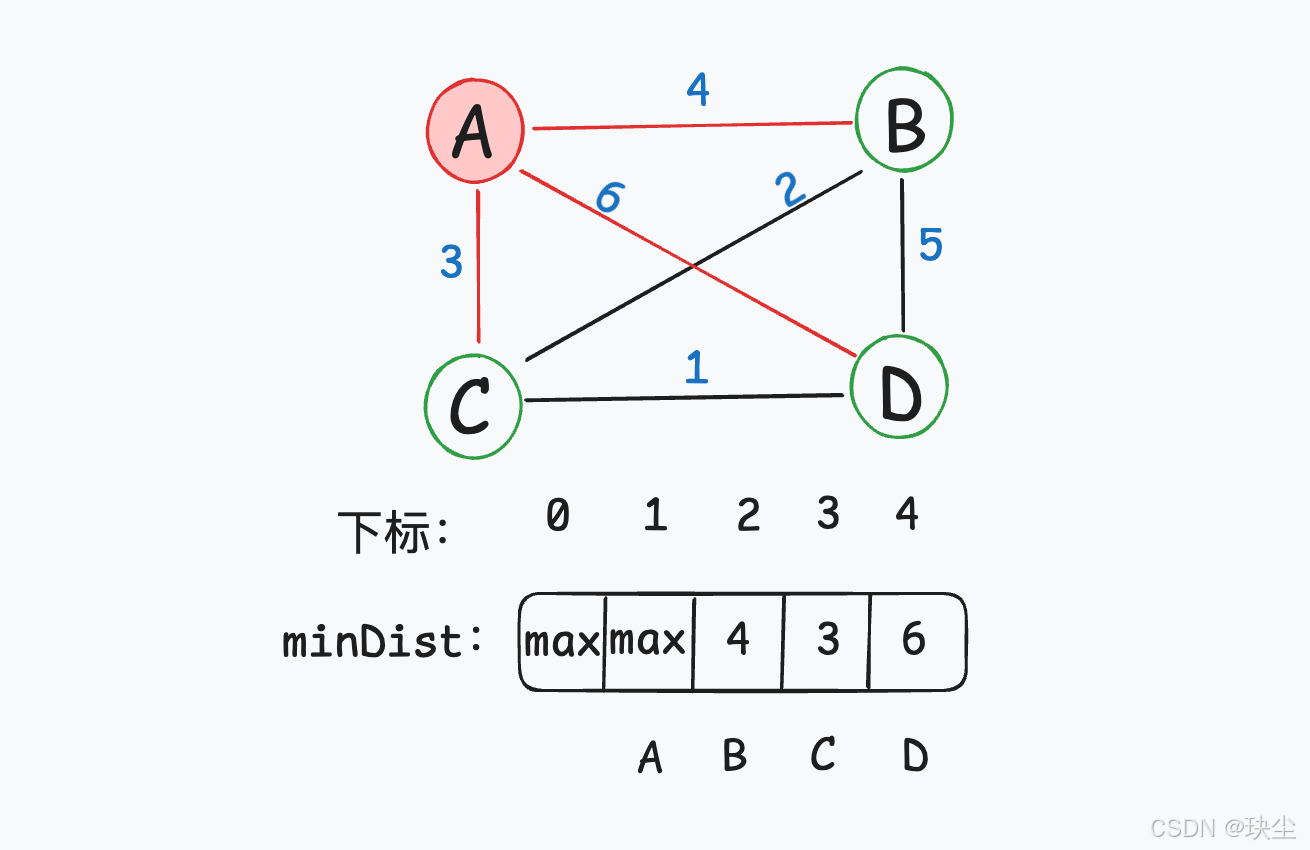
因为刚开始还没有最小生成树,所以随便选择一个节点加入最小生成树。在第一部中,选择节点1(符合遍历数组的习惯,第一个遍历的是A,看作1)作为距离最小生成树最近的节点。
(2) 把它加入生成树
此时节点1已经是最小生成树中的节点。
(3) 更新其他城市到生成树的最短距离(更新 minDist 数组)
第二轮:
(1) 找距离当前生成树最近的城市
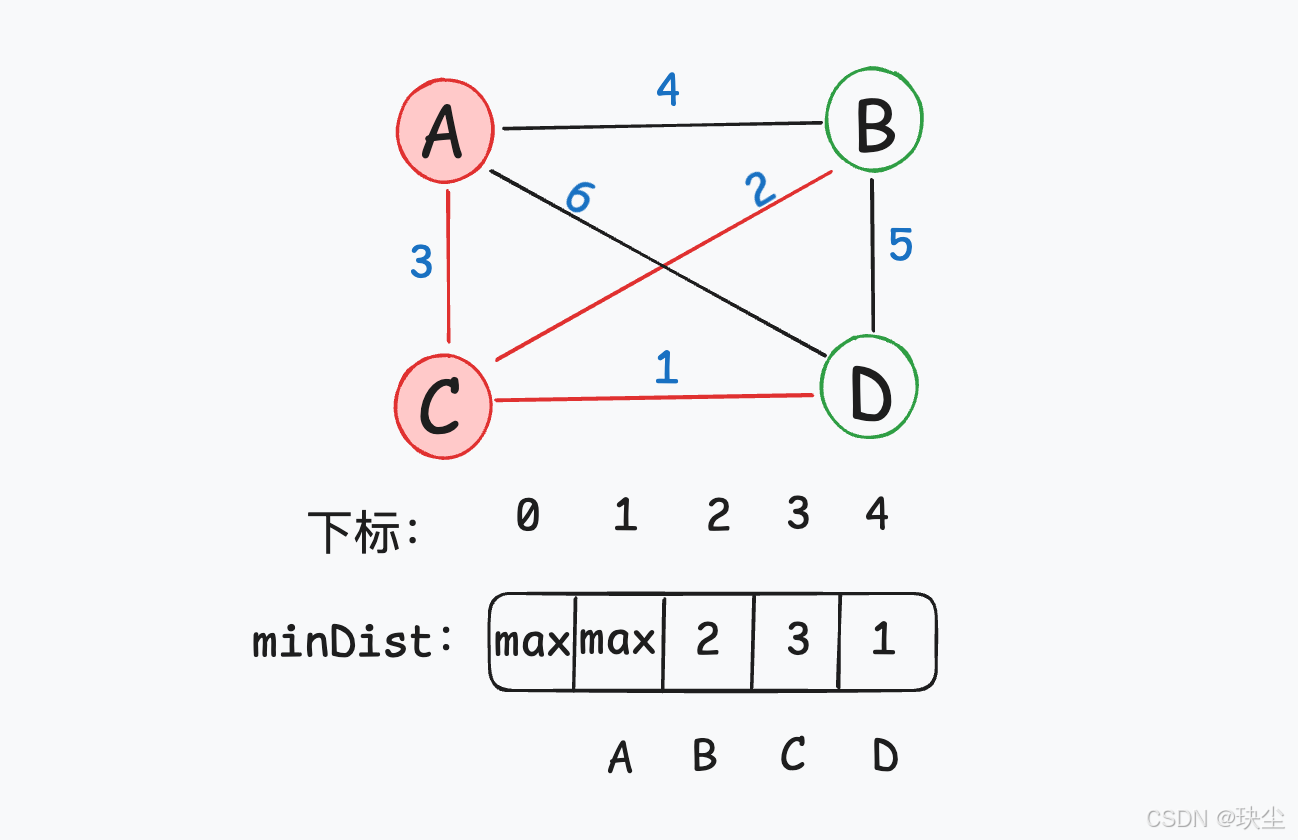
选择一个距离最小生成树(节点1)最近的非最小生成树中的节点,节点3距离最小生成树(节点1)最近,加入最小生成树。
(2) 把它加入生成树
此时节点1和节点3已经是最小生成树中的节点。
(3) 更新其他城市到生成树的最短距离(更新 minDist 数组)
第三轮:
(1) 找距离当前生成树最近的城市
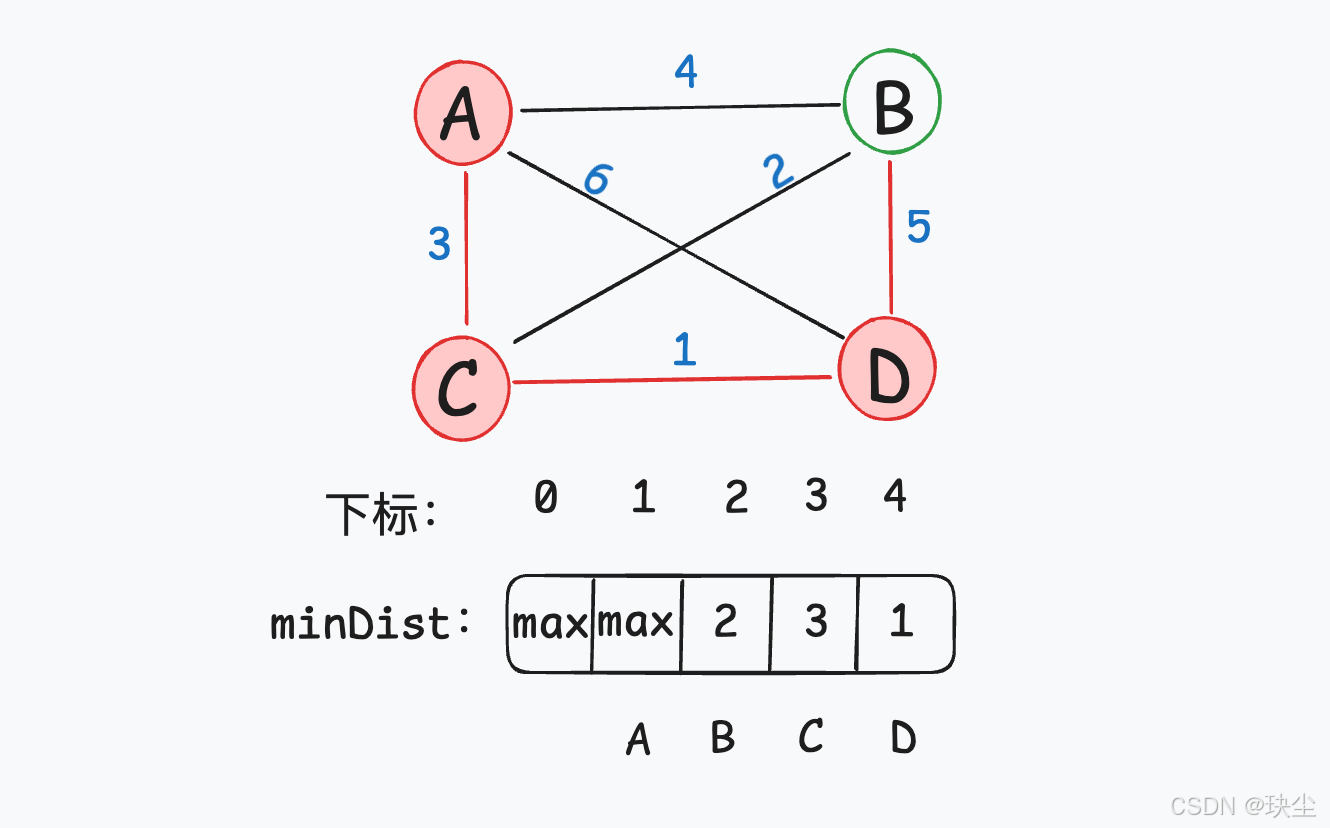
选择一个距离最小生成树(节点1、节点3)最近的非最小生成树中的节点,节点4距离最小生成树(节点1、节点3)最近,加入最小生成树。
(2) 把它加入生成树
此时节点1、节点3、节点4已经是最小生成树中的节点。
(3) 更新其他城市到生成树的最短距离(更新 minDist 数组)
这里节点4到节点2的距离为5,比原先的距离值2大,所以不更新。
第四轮:
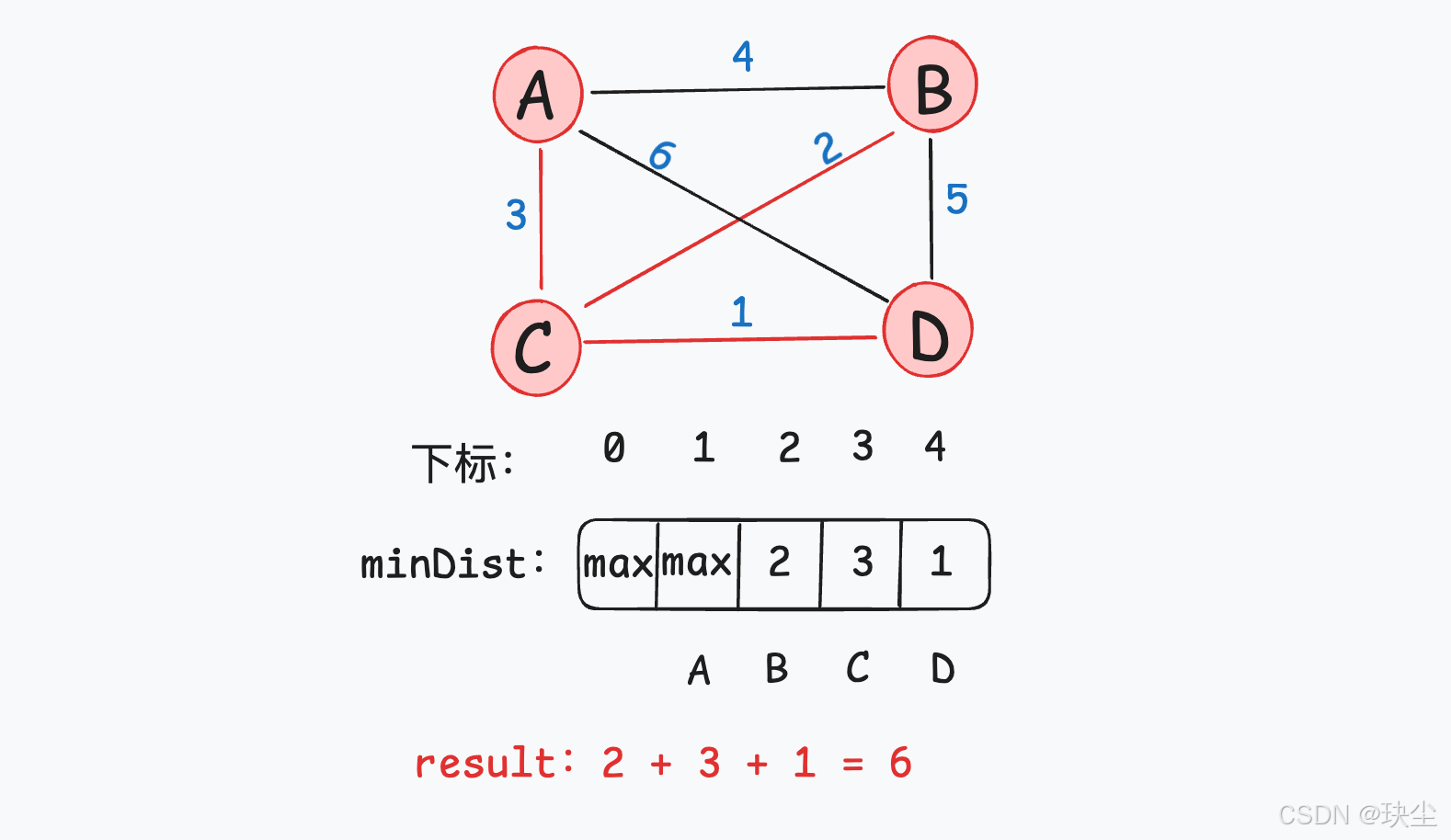
(1) 找距离当前生成树最近的城市
此时唯未加入节点为 2,选入。
(2) 把它加入生成树
现在所有节点被包含。
(3) 更新其他城市到生成树的最短距离(更新 minDist 数组)
无剩余节点,算法结束。
你会发现,每一次选边的过程,其实都是在执行 “Prim 三部曲”:
选最近节点 → 加入生成树 → 更新距离。
实现代码(Java、C++)
Java版
class Solution{public int minDistResult(int v,int[][] grid) {// 所有节点到最小生成树的最短距离(默认为最大值)// v 表示节点数int[] minDist = new int[v + 1];Arrays.fill(minDist, Integer.MAX_VALUE);// 这个节点是否在树中boolean[] isInTree = new boolean[v + 1];// 只需要循环 n - 1 次,建立 n - 1 条边for(int i = 1;i < v;i++) {int cur = 1;int minVal = Integer.MAX_VALUE;// 1.prim第一步:选择 非生成树节点 距离 最小生成树 最近的节点for(int j = 1;j <= v;j++) {if(!isInTree[j] && minDist[j] < minVal) {minVal = minDist[j];cur = j;}}// 2.prim第二步:将最近的节点加入最小生成树isInTree[cur] = true;// 3.prim第三步:更新 所有非生成树节点 到 最小生成树 的距离for(int j = 1;j <= v;j++) {if(!isInTree[j] && grid[cur][j] < minDist[j]) {minDist[j] = grid[cur][j];}}}int result = 0;// 不统计第一个顶点for(int i = 2;i <= v;i++) {result += minDist[i];}return result;}
}
C++版
class Solution {
public:int minDistResult(int v, vector<vector<int>>& grid) {// 1. 所有节点到最小生成树的最短距离(初始化为最大值)vector<int> minDist(v + 1, INT_MAX);// 2. 记录节点是否已加入最小生成树vector<bool> isInTree(v + 1, false);// Prim 三部曲循环 v - 1 次(建立 v - 1 条边)for (int i = 1; i < v; i++) {// --- Prim 第一步:选择距离最小生成树最近的非树节点 ---int cur = 1; // 默认起点为节点1int minVal = INT_MAX;for (int j = 1; j <= v; j++) {if (!isInTree[j] && minDist[j] < minVal) {minVal = minDist[j];cur = j;}}// --- Prim 第二步:将最近的节点加入最小生成树 ---isInTree[cur] = true;// --- Prim 第三步:更新所有非生成树节点到最小生成树的最短距离 ---for (int j = 1; j <= v; j++) {if (!isInTree[j] && grid[cur][j] < minDist[j]) {minDist[j] = grid[cur][j];}}}// 计算最小生成树总权值(不统计起点)int result = 0;for (int i = 2; i <= v; i++) {result += minDist[i];}return result;}
};
以上代码的整体时间复杂度为O(n²),其中n为节点的数量。
四、Kruskal算法:挑拣最划算的边
卡码网:53. 寻宝
力扣:1584. 连接所有点的最小费用
1135. 最低成本连通所有城市

算法直觉
现在换个角度想:你是采购员,面前有一堆道路建设报价单。你的策略是:先把所有报价从低到高排序,然后从最便宜的开始选。
prim 算法是维护节点的集合,而 Kruskal 是维护边的集合。
Kruskal思路
kruskal的思路:
- 边的权值排序,因为要优先选最小的边加入到生成树里
- 遍历排序后的边
- 如果边首尾的两个节点在同一个集合,说明如果连上这条边图中会出现环
- 如果边首尾的两个节点不在同一个集合,加入到最小生成树,并把两个节点加入同一个集合
模拟过程
首先要将图中的边按照权值从小到大排序,这样从贪心的角度来说,优先选择将权值小的边加入最小生成树。
排序后的边的顺序为[(3,4),(2,3),(1,3),(1,2),(2,4),(1,4)]。
注:先后顺序不影响结果,无向图
第一轮:
选择边(3,4),节点3和节点4不在同一个集合中,所以可以将边(3,4)加入最小生成树,并将节点3、节点4放到同一集合中。
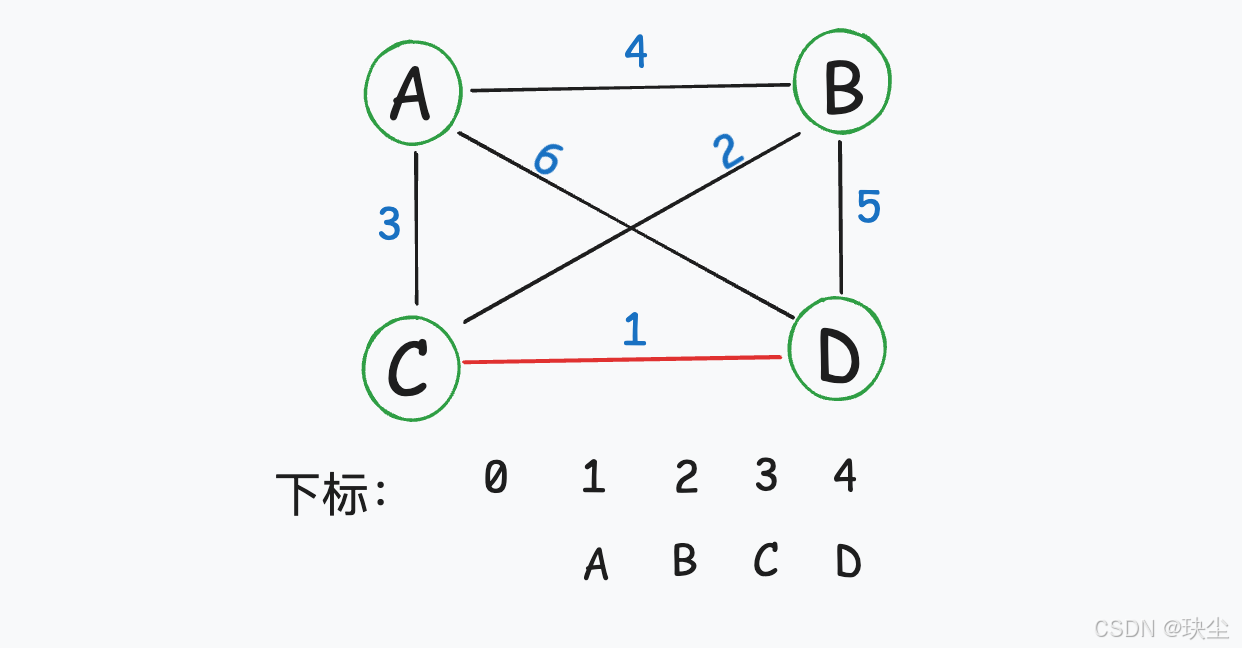
第二轮:
选择边(2,3),节点2和节点3不在同一个集合中,所以可以将边(2,3)加入最小生成树,并将节点2、节点3放到同一集合中。
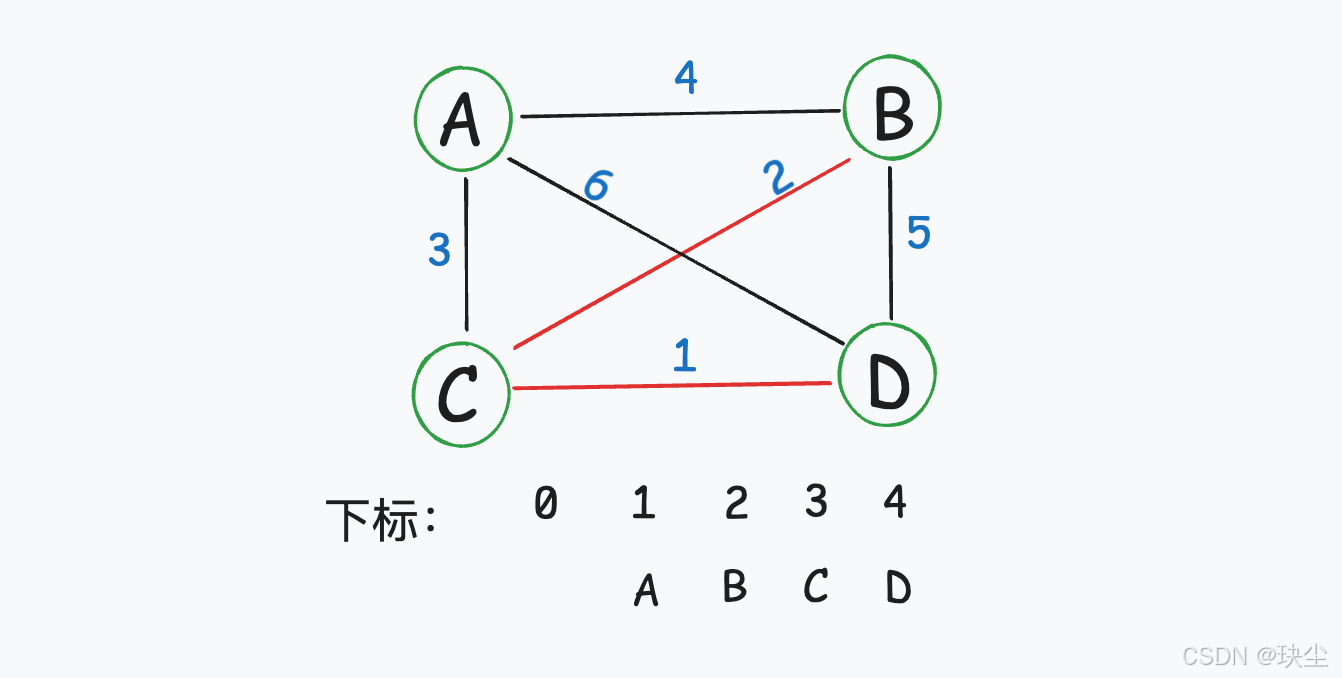
第三轮:
选择边(1,3),节点1和节点3不在同一个集合中,所以可以将边(1,3)加入最小生成树,并将节点1、节点3放到同一集合中。
此时已经生成了一个最小生成树。
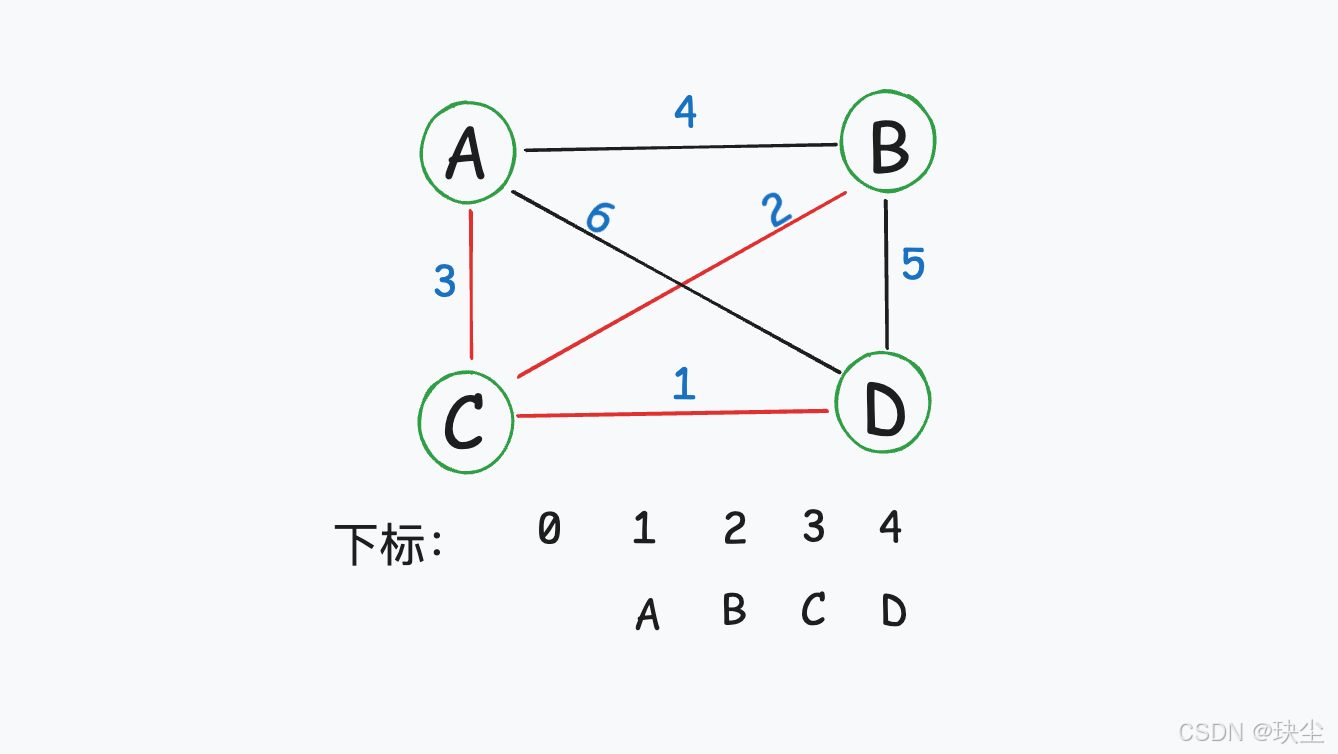
第四轮:
选择边(1,2),节点1和节点2在同一个集合中,不做计算。后续(2,4),(1,4)同理。
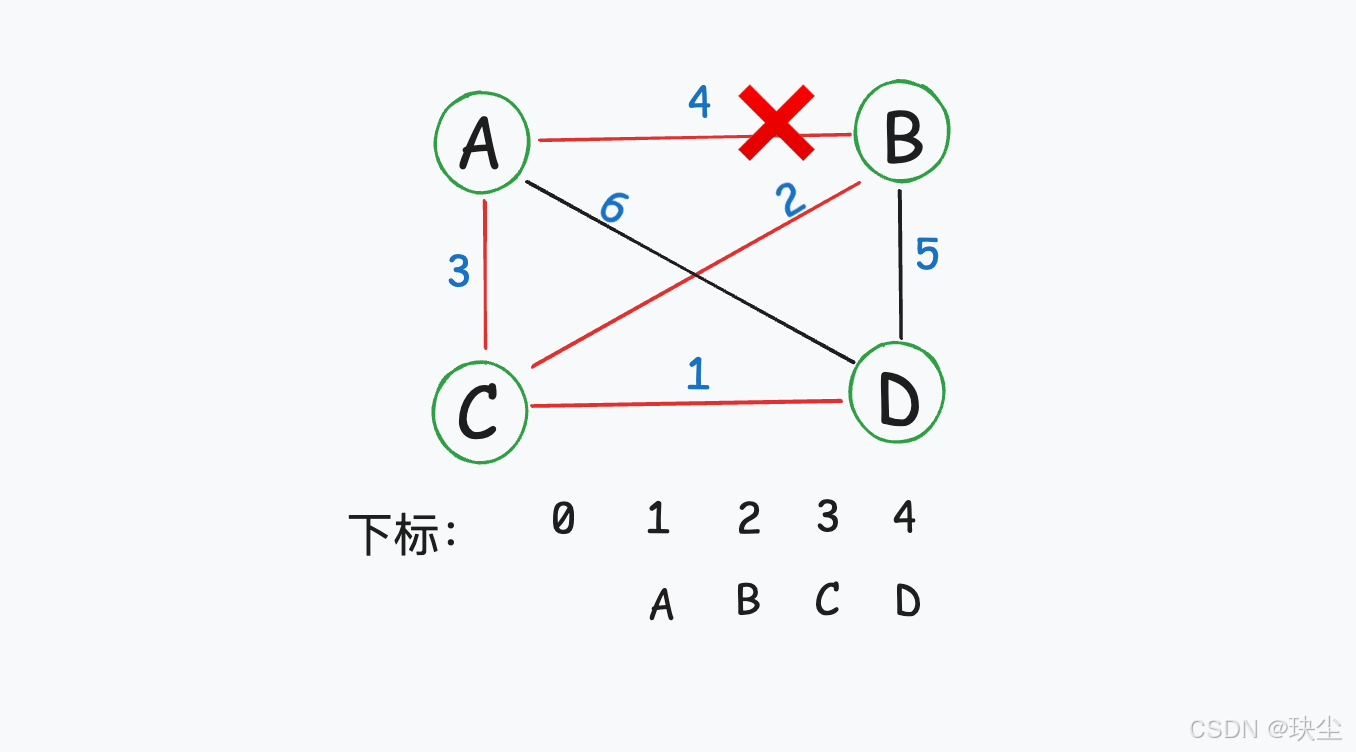
关键技术:并查集
怎么快速判断"两个城市是否已经连通"?
用一种叫 并查集(Union-Find) 的数据结构,它能:
- 快速判断两个节点是否在同一连通分量(connected)
- 快速合并两个连通分量(union)
实现代码(Java、C++)
依据力扣1584. 连接所有点的最小费用撰写
Java版
class Solution {public int minCostConnectPoints(int[][] points) {int n = points.length;List<Edge> edges = new ArrayList<>();// 构造完整图的所有边for (int i = 0; i < n; i++) {for (int j = i + 1; j < n; j++) {int dist = Math.abs(points[i][0] - points[j][0]) + Math.abs(points[i][1] - points[j][1]);edges.add(new Edge(i, j, dist));}}// 按边权从小到大排序edges.sort(Comparator.comparingInt(e -> e.val));UF uf = new UF(n);int result = 0;// Kruskal 主循环for (Edge edge : edges) {if (!uf.connected(edge.u, edge.v)) {uf.union(edge.u, edge.v);result += edge.val;}}return result;}
}class Edge {int u, v, val;Edge(int u, int v, int val) {this.u = u;this.v = v;this.val = val;}
}class UF {private int count;private int[] parent;public UF(int n) {this.count = n;parent = new int[n];for (int i = 0; i < n; i++) {parent[i] = i;}}public void union(int p, int q) {int rootP = find(p);int rootQ = find(q);if (rootP == rootQ) {return;}parent[rootP] = rootQ;count--;}public boolean connected(int p, int q) {int rootP = find(p);int rootQ = find(q);return rootP == rootQ;}public int find(int x) {if (parent[x] != x) {parent[x] = find(parent[x]);}return parent[x];}
}
C++版
class Solution {
public:struct Edge {int u, v, val;Edge(int u, int v, int val) : u(u), v(v), val(val) {}};class UF {public:vector<int> parent;UF(int n) : parent(n) {for (int i = 0; i < n; i++) parent[i] = i;}int find(int x) {if (parent[x] != x) parent[x] = find(parent[x]);return parent[x];}bool connected(int x, int y) {return find(x) == find(y);}void unite(int x, int y) {int px = find(x), py = find(y);if (px != py) parent[px] = py;}};int minCostConnectPoints(vector<vector<int>>& points) {int n = points.size();vector<Edge> edges;// 构造完全图的所有边for (int i = 0; i < n; i++) {for (int j = i + 1; j < n; j++) {int dist = abs(points[i][0] - points[j][0]) + abs(points[i][1] - points[j][1]);edges.emplace_back(i, j, dist);}}// 按权值从小到大排序sort(edges.begin(), edges.end(), [](const Edge &a, const Edge &b) {return a.val < b.val;});UF uf(n);int result = 0;// Kruskal 主循环for (auto &edge : edges) {if (!uf.connected(edge.u, edge.v)) {uf.unite(edge.u, edge.v);result += edge.val;}}return result;}
};
以上代码的整体时间复杂度为O(nlogn),时间复杂度:nlogn (快排) + logn (并查集) ,n为边的数量。
五、Prim vs Kruskal:该选谁?
到这里,我们已经介绍了 Kruskal 和 Prim 两种最小生成树的算法。那么,什么时候该选择哪一种算法呢?
两者的 关键区别 在于:
- Prim 维护的是节点集合,每次从生成树中选择与未加入节点距离最近的节点;
- Kruskal 维护的是边集合,每次选择权值最小的边,并判断加入后是否形成环。
因此在不同图的结构下,性能表现有所差异:
-
稀疏图(节点较多,边相对较少):
- Kruskal 更适合,因为它只对边进行排序和遍历。
- 边少意味着排序和遍历的开销较小,算法效率更高。
-
稠密图(节点数量固定,边接近完全图):
- Prim 更适合,因为它操作的是节点,而与边的数量关系不大。
- 即使边很多,Prim 只需维护每个节点到生成树的最短距离。
简单总结一句话:
稀疏图用 Kruskal,稠密图用 Prim。
下次当你在规划旅行路线、设计网络拓扑、或者只是在地图上连点成线时,不妨想想:这背后是不是也藏着一棵最小生成树呢?