TR3D: Towards Real-Time Indoor 3D Object Detection论文精读
这篇论文《TR3D: Towards Real-Time Indoor 3D Object Detection》提出了一种高效的室内3D目标检测方法,并在多个标准数据集上取得了领先的性能。下面我将从问题背景、方法设计、关键改进、融合策略、实验结果等方面进行详细解析。
🧠 一、解决的问题
1. 3D目标检测的挑战
- 内存消耗大:传统体素化方法使用密集卷积,内存占用高。
- 推理速度慢:投票类方法(如VoteNet)和Transformer方法在大场景中速度下降明显。
- 小物体检测困难:传统方法容易漏检薄或小物体(如白板)。
- 多模态融合复杂:现有RGB+点云融合方法通常设计复杂、速度慢、内存占用高。
2. TR3D的目标
- 提出一个轻量、快速、高精度的纯3D检测模型(TR3D)。
- 提出一种简单有效的早期融合策略,融合RGB与点云特征(TR3D+FF)。
- 在ScanNet v2、SUN RGB-D、S3DIS等主流数据集上实现SOTA。
🛠️ 二、方法详解
1. 基础架构:基于FCAF3D
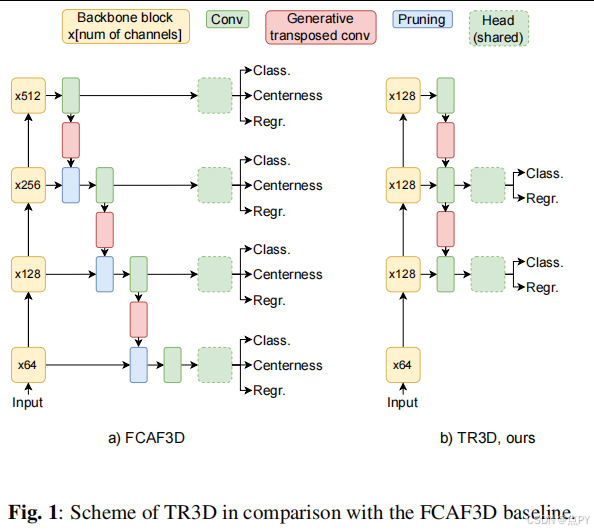
TR3D以FCAF3D为基线,采用全卷积、无锚框的3D稀疏卷积网络,具有良好的内存效率和扩展性。
2. TR3D的核心改进
✅ 效率优化(轻量化)
| 改进 | 效果 |
|---|---|
| 移除第1层检测头 | 内存↓ 1.5倍,FPS↑ 6 |
| 移除第4层检测头 | 进一步减少参数,适应室内小物体 |
| 限制backbone通道数 | 参数从68.3M → 14.7M,内存减半 |
最终:内存减少3倍,参数减少4.5倍,速度提升近2倍
✅ 精度提升
| 改进 | 说明 |
|---|---|
| 移除centerness预测 | 实验表明对精度无帮助 |
| 提出TR3D Assigner | 不仅考虑框内点,还考虑框外邻近点,提升小物体检测 |
| 使用DIoU Loss | 解决IoU=0时无法训练的问题,提升收敛稳定性 |
| 多层级分配策略 | 大物体(如床)在第3层处理,小物体(如椅子)在第2层处理 |
最终:mAP从61.5 → 74.5(S3DIS)
3. TR3D+FF:多模态早期融合
融合流程:
- 提取2D特征:使用预训练的ResNet50+FPN(冻结权重)。
- 投影到3D空间:将2D特征通过相机参数投影到3D点云空间中。
- 特征融合:将投影后的2D特征与3D特征逐元素相加。
优点:
- 简单高效:无需复杂模块或迭代优化。
- 即插即用:可嵌入其他3D检测模型(如VoteNet)。
- 效果显著:在VoteNet上提升+6.8 mAP@0.25,优于ImVoteNet。
📊 三、实验结果
1. 纯点云检测(TR3D)
| 数据集 | mAP@0.25 | mAP@0.5 | FPS |
|---|---|---|---|
| ScanNet v2 | 72.9 | 59.3 | 23.7 |
| SUN RGB-D | 67.1 | 50.4 | 27.5 |
| S3DIS | 74.5 | 51.7 | 21.0 |
在所有数据集上均超越FCAF3D及其他SOTA方法,速度更快、内存更小。
2. 多模态检测(TR3D+FF)
| 方法 | 输入 | mAP@0.25 | mAP@0.5 |
|---|---|---|---|
| VoteNet | PC | 57.7 | - |
| ImVoteNet | PC+RGB | 63.4 | - |
| VoteNet+FF | PC+RGB | 64.5 | 39.2 |
| TR3D | PC | 67.1 | 50.4 |
| TR3D+FF | PC+RGB | 69.4 | 53.4 |
TR3D+FF在SUN RGB-D上超越MMTC等现有融合方法,mAP@0.25提升4.1。
✅ 四、总结与贡献
| 贡献 | 说明 |
|---|---|
| TR3D模型 | 轻量、快速、高精度的纯3D检测模型 |
| TR3D Assigner | 改进目标分配策略,提升小物体检测 |
| 早期融合模块 | 简单有效的RGB+点云融合方法,可迁移 |
| SOTA性能 | 在三大数据集上均取得最佳精度与速度 |
| 代码开源 | 提供完整实现,便于复现与应用 |
🧩 总结一句话:
TR3D通过对FCAF3D进行轻量化改造+分配策略优化,实现了更快、更准、更省内存的3D检测;其早期融合模块则进一步利用RGB信息,以极简方式提升多模态检测性能。