【云计算】【Kubernetes】 ① K8S的架构、应用及源码解析 - 核心架构与组件全景图
📖目录
- 前言
- 1. 引言:为什么我们需要 Kubernetes?
- 2. Kubernetes 的整体架构概览
- 3. Control Plane 核心组件详解(v1.30 视角)
- 3.1 kube-apiserver:集群的唯一入口
- 3.2 etcd:集群的“大脑记忆体”
- 3.3 kube-scheduler:智能调度引擎
- 3.4 kube-controller-manager:集群的“自动驾驶仪”
- 3.5 cloud-controller-manager(CCM):云厂商解耦层
- 4. Worker Node 组件:承载业务的基石
- 4.1 kubelet:Node 的“操作系统代理”
- 4.2 kube-proxy:Service 的网络实现者
- 4.3 Container Runtime:容器的实际执行者
- 5. 核心抽象对象:Pod、Service、Ingress
- 5.1 Pod:最小调度单元
- 5.2 Service:稳定的网络抽象
- 5.3 Ingress:七层 HTTP(S) 路由网关
- 6. 扩展组件与外部工具
- 6.1 Add-ons(扩展组件):
- 6.2 kubectl:
- 7. 核心流程与数据流向
- 7.1 核心数据交互规则
- 7.2 关键流程:Pod创建与运行全链路
- 7.3 其他关键数据流
- 8. 架构核心优势总结
- 9. K8s 源码结构总览(v1.30)
- 10. K8s 的演进趋势与高级特性(v1.30+)
- 10.1 多运行时支持(Beyond Docker)
- 10.2 Gateway API:Ingress 的下一代
- 10.3 Workload APIs 演进
- 10.4 可观测性与扩展性
- 11. 结语:开启 K8s 源码之旅
- 12. 参考资料
前言
- 适用读者:具备容器化基础、熟悉 Linux 系统、有分布式系统经验的中高级开发者
- Kubernetes 版本:v1.30(2025年最新稳定版)
- 系列说明:本文为K8S源码深度解析系列首篇,后续将逐个剖析 kubelet、scheduler、apiserver、etcd 集成、Pod 生命周期、Service 实现原理等核心模块。
1. 引言:为什么我们需要 Kubernetes?
在微服务与云原生时代,单机部署早已无法满足高可用、弹性伸缩、快速迭代的需求。Docker 虽解决了“一次构建,到处运行”的问题,但当容器数量从几十增长到数千甚至上万时,编排、调度、自愈、服务发现、网络隔离、资源管理等问题便成为瓶颈。
Kubernetes(简称 K8s)正是为解决大规模容器编排而生。它不仅是一个容器编排平台,更是一个声明式、自动化、可扩展的分布式操作系统内核。其设计哲学深受 Google 内部 Borg 系统影响,兼具工程严谨性与生态开放性。
💡 关键认知:K8s 不是“另一个 Docker”,而是“容器的调度与治理层”。Docker 只是其默认的 Container Runtime 之一。
2. Kubernetes 的整体架构概览
K8s 采用经典的 Master-Worker(Control Plane + Node)架构,逻辑上分为两大平面:
- Control Plane(控制平面):负责集群全局状态管理、调度决策、API 入口。
- Worker Nodes(工作节点):运行实际业务负载(Pod),受控于 Control Plane。
架构图说明
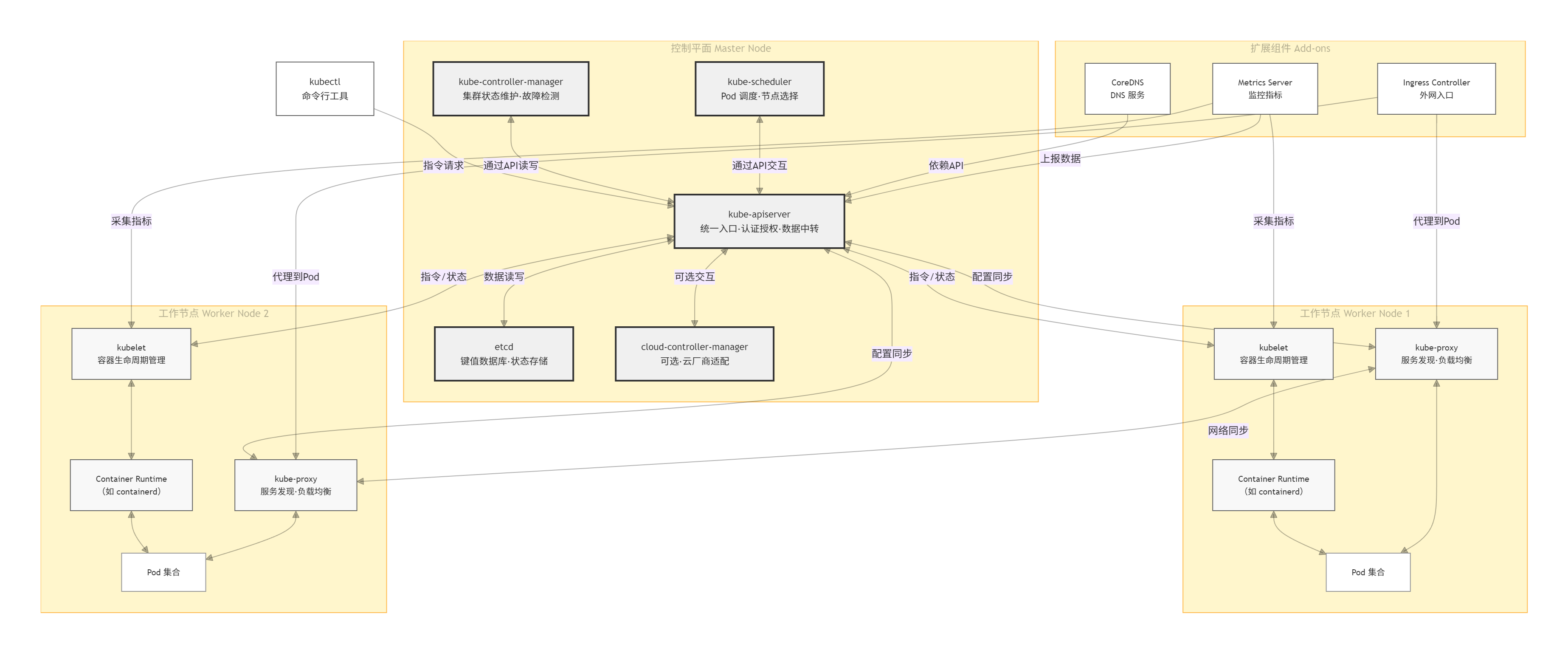
K8s架构采用“控制平面-工作节点”的经典主从模式,辅以扩展组件和外部工具,形成完整的集群管理体系,各组件功能定位清晰、协同运作。
✅ 注意:自 v1.20 起,Docker 已不再作为官方推荐的 Container Runtime(通过 dockershim 移除),取而代之的是符合 CRI(Container Runtime Interface) 标准的运行时,如 containerd、CRI-O。
3. Control Plane 核心组件详解(v1.30 视角)
3.1 kube-apiserver:集群的唯一入口
- 作用:所有组件通信的中枢,提供 RESTful API,支持认证、授权、准入控制、API 注册与发现。
- 源码位置:k8s.io/kubernetes/cmd/kube-apiserver
- 关键特性:
- 无状态设计,可水平扩展。
- 所有写操作最终持久化到 etcd。
- 支持 Webhook Admission 控制器(动态拦截请求)。
- 源码结构简析:
// pkg/master/master.go
func New(c Config) (Master, error) {// 初始化 APIGroups, RESTStorage, Admit, Authz...
}
其核心是将各类资源(Pod、Service、Deployment 等)注册为 REST 路径,并通过 storage.Interface 与 etcd 交互。
3.2 etcd:集群的“大脑记忆体”
- 作用:高可用、强一致的键值存储,保存集群所有状态(包括 spec 和 status)。
- 版本要求:K8s v1.30 推荐 etcd v3.5+。
- 关键点:
- 所有组件通过 watch 机制监听 etcd 变化,实现事件驱动。
- 性能瓶颈常出现在 etcd,需独立部署、SSD、调优 snapshot。
- 源码集成:K8s 通过 clientv3 包与 etcd 通信,封装在 k8s.io/apiserver/pkg/storage/etcd3 中。
3.3 kube-scheduler:智能调度引擎
作用:将未绑定的 Pod 分配到合适的 Node 上。
调度流程(v1.30):
- Filtering(预选):排除不满足资源、亲和性、污点容忍等条件的节点。
- Scoring(优选):对剩余节点打分(如资源均衡、拓扑分布)。
- Binding:调用 apiserver 将 Pod 绑定到目标 Node。
可扩展性:支持自定义调度器(通过 spec.schedulerName 指定)。
源码入口:k8s.io/kubernetes/cmd/kube-scheduler,核心逻辑在 pkg/scheduler。
3.4 kube-controller-manager:集群的“自动驾驶仪”
作用:运行多个控制器(Controller),确保集群实际状态趋近于用户声明的期望状态。
主要控制器:
- Node Controller:监控 Node 心跳,标记 NotReady 或驱逐 Pod。
- ReplicaSet Controller:维持 Pod 副本数。
- EndpointSlice Controller:替代旧 Endpoint,提升大规模 Service 性能。
- ServiceAccount Controller:自动创建命名空间的默认 ServiceAccount。
- 源码组织:各控制器独立实现,统一由 cmd/kube-controller-manager/app/core.go 启动。
3.5 cloud-controller-manager(CCM):云厂商解耦层
- 作用:将云平台特定逻辑(如 LoadBalancer、Route、Node 地址)从核心控制面剥离。
- 意义:使 K8s 核心代码更纯净,便于多云/混合云部署。
- 示例:AWS CCM 负责创建 ELB,GCP CCM 管理 GCE Routes。
4. Worker Node 组件:承载业务的基石
4.1 kubelet:Node 的“操作系统代理”
作用:
- 与 apiserver 通信,接收 PodSpec。
- 管理 Pod 生命周期(创建、健康检查、日志、卷挂载)。
- 上报 Node & Pod 状态。
- CRI 集成:通过 gRPC 调用 containerd/CRI-O,不再依赖 Docker Engine。
- 源码重点:pkg/kubelet/kubelet.go 是主循环,pkg/kubelet/dockershim 已移除。
4.2 kube-proxy:Service 的网络实现者
作用:实现集群内部 Service 的负载均衡与服务发现。
三种模式:
- userspace(已废弃)
- iptables(默认):基于规则链转发。
- IPVS(高性能推荐):利用内核 IP Virtual Server,支持更多调度算法。
关键限制:仅处理 ClusterIP 和 NodePort,不处理 Ingress(那是 Ingress Controller 的事)。
4.3 Container Runtime:容器的实际执行者
主流选择:
- containerd:Docker 抽离的核心运行时,轻量、稳定。
- CRI-O:专为 K8s 设计,OCI 兼容,Red Hat 主导。
- CRI 接口:定义了 RunPodSandbox、CreateContainer、StartContainer 等标准方法。
5. 核心抽象对象:Pod、Service、Ingress
5.1 Pod:最小调度单元
本质:一个或多个共享网络/存储/IPC 的容器组。
关键特性:
- 同一 Pod 内容器共享 localhost、/etc/hosts、Volume。
- 生命周期由控制器(如 Deployment)管理。
YAML 示例:
apiVersion: v1
kind: Pod
metadata:name: nginx-pod
spec:containers:- name: nginximage: nginx:alpineports:- containerPort: 80
5.2 Service:稳定的网络抽象
作用:为一组 Pod 提供固定 IP(ClusterIP)和 DNS 名称,实现服务发现与负载均衡。
类型:
- ClusterIP(默认):仅集群内访问。
- NodePort:在每个 Node 开放端口。
- LoadBalancer:云厂商自动创建外部 LB。
- ExternalName:CNAME 到外部服务。
- 底层实现:kube-proxy + iptables/IPVS 规则。
apiVersion: v1
kind: Service
metadata:name: nginx-service
spec:selector:app: nginxports:- port: 80targetPort: 80type: ClusterIP
5.3 Ingress:七层 HTTP(S) 路由网关
作用:基于 Host/Path 路由外部流量到不同 Service。
必须配合 Ingress Controller 使用(如 Nginx Ingress、Traefik、ALB Controller)。
YAML 示例:
apiVersion: networking.k8s.io/v1
kind: Ingress
metadata:name: demo-ingress
spec:rules:- host: demo.example.comhttp:paths:- path: /pathType: Prefixbackend:service:name: nginx-serviceport:number: 80
6. 扩展组件与外部工具
6.1 Add-ons(扩展组件):
增强集群功能的“插件集”,核心包括CoreDNS(提供集群内部DNS服务,实现Pod通过服务名访问资源)、Ingress Controller(作为外网访问集群的入口,实现HTTP/HTTPS路由和反向代理)、Metrics Server(采集节点和Pod的资源监控指标,为调度策略和HPA提供数据支持)。
6.2 kubectl:
K8s的“命令行工具”,是用户与集群交互的主要方式,通过向kube-apiserver发送指令,实现集群资源的创建、查询、更新、删除等操作。
7. 核心流程与数据流向
K8s集群的运作核心是“指令流转-状态反馈-调谐执行”的闭环,关键流程围绕“Pod创建与管理”展开,各组件通过kube-apiserver实现数据交互,形成有序的协同机制。
7.1 核心数据交互规则
集群内所有数据交互均遵循“以kube-apiserver为中枢、etcd为数据存储源”的原则:
- kube-controller-manager、kube-scheduler不直接操作etcd,而是通过kube-apiserver的API接口实现数据的读写,确保数据一致性和权限控制。
- 工作节点的kubelet、kube-proxy通过与kube-apiserver通信,获取指令并上报状态,不与控制平面其他组件直接交互。
- 扩展组件(如CoreDNS、Metrics Server)依赖kube-apiserver获取集群资源信息,同时将自身数据(如监控指标)上报至kube-apiserver。
7.2 关键流程:Pod创建与运行全链路
- 指令发起:用户通过kubectl执行Pod创建命令(如kubectl create pod nginx),命令被转化为API请求发送至kube-apiserver。
- 请求校验与存储:kube-apiserver对请求进行认证、授权和数据校验,通过后将Pod配置信息写入etcd,并返回“创建成功”的响应给kubectl。
- 调度决策:kube-scheduler通过监听kube-apiserver的事件,发现新创建的“未调度”Pod,结合集群节点资源状态和调度策略,为Pod选定最优工作节点(如Worker Node 1),并将调度结果通过kube-apiserver写入etcd。
- Pod启动执行:Worker Node 1上的kubelet通过定期向kube-apiserver查询,发现分配给自己的Pod,随即调用Container Runtime拉取Pod所需的镜像,创建并启动容器,同时将Pod的“运行中”状态上报至kube-apiserver,由其更新至etcd。
- 网络配置与服务发现:kube-proxy监听kube-apiserver的服务配置(若Pod关联Service),在Worker Node 1上生成网络规则,确保外部请求能通过Service转发至该Pod;同时CoreDNS同步Service信息,实现Pod通过服务名访问资源。
- 状态监控与调谐:kubelet实时监控Pod和容器的健康状态,若发现容器异常(如退出),立即上报至kube-apiserver;kube-controller-manager通过kube-apiserver获取该状态,触发调谐逻辑(如重启容器),并通过kube-apiserver下发指令给kubelet执行,确保Pod状态符合期望。
7.3 其他关键数据流
- 监控数据流转:Metrics Server定期从各节点的kubelet获取监控指标(如CPU使用率),通过kube-apiserver将数据暴露给HPA(Horizontal Pod Autoscaler)和kubectl top命令,HPA根据指标触发Pod扩缩容时,流程与“Pod创建”一致。
- 外网访问流转:用户通过外网访问集群服务时,请求首先到达Ingress Controller,Ingress Controller根据路由规则(配置存储于etcd,通过kube-apiserver获取),将请求转发至对应节点的kube-proxy,再由kube-proxy转发至后端Pod。
- 跨节点通信流转:Worker Node 1上的Pod访问Worker Node 2上的Pod时,通过两节点的kube-proxy协同实现——kube-proxy基于kube-apiserver同步的服务配置,维护跨节点网络规则,确保请求能跨节点转发至目标Pod。
8. 架构核心优势总结
- 解耦与高可用:控制平面组件分工明确,工作节点横向扩展,单个组件故障不影响集群整体运行,etcd的高可用部署确保数据安全。
- 自动化运维:通过控制器实现状态自动调谐,减少人工干预,如故障自愈、自动扩缩容等。
- 灵活扩展:Add-ons机制支持按需扩展集群功能,适配不同业务场景;Container Runtime的可替换性提升架构灵活性。
- 统一管控:kube-apiserver作为统一入口,实现集群资源的集中管理和权限控制,简化操作复杂度。
9. K8s 源码结构总览(v1.30)
K8s 源码采用 Go 编写,模块化清晰。以下是关键目录:
kubernetes/
├── cmd/ # 各组件主程序入口
│ ├── kube-apiserver/
│ ├── kube-scheduler/
│ ├── kube-controller-manager/
│ └── kubelet/
├── pkg/ # 核心逻辑包
│ ├── apis/ # API 定义(core, apps, batch...)
│ ├── client-go/ # 客户端 SDK(重要!)
│ ├── kubelet/ # kubelet 实现
│ ├── scheduler/ # 调度器框架
│ ├── controller/ # 各类控制器
│ └── master/ # apiserver 核心
├── staging/ # 供外部项目使用的库(如 client-go)
└── plugin/ # 插件(如 admission controllers)
🔍 源码阅读建议:
- 从 cmd/xxx/main.go 入手,跟踪初始化流程。
- 关注 pkg/apis/core/v1/types.go 中的资源定义。
- 使用 client-go 是开发 Operator/Controller 的基础。
10. K8s 的演进趋势与高级特性(v1.30+)
10.1 多运行时支持(Beyond Docker)
- CRI 标准化:任何符合 CRI 的运行时均可接入。
- 安全容器:如 Kata Containers、gVisor,提供更强隔离。
10.2 Gateway API:Ingress 的下一代
- 问题:Ingress 功能有限,难以表达复杂路由。
- 方案:Gateway API(gateway.networking.k8s.io)提供更灵活的模型(GatewayClass、Gateway、HTTPRoute)。
10.3 Workload APIs 演进
- Job 改进:支持 suspend、ttlSecondsAfterFinished。
- StatefulSet 增强:Pod 管理策略、滚动更新分区。
10.4 可观测性与扩展性
- Metrics Server → Prometheus Operator:标准化指标采集。
- Dynamic Admission Control:Validating/Mutating Webhook 成为扩展标配。
- CRD + Operator Pattern:构建自定义控制器的黄金组合。
11. 结语:开启 K8s 源码之旅
本文作为K8S源码深度解析系列的开篇,旨在为高级开发者勾勒出 Kubernetes 的宏观架构、核心组件职责、关键抽象对象及其在源码中的组织方式。我们强调:
- K8s 是一个声明式、事件驱动、控制器模式的系统。
- Control Plane 与 Worker 解耦,通过 apiserver 协同。
- Pod 是调度原子,Service 是网络抽象,Ingress 是流量入口。
源码阅读需结合设计文档与实际调试。
📌 下期预告:
第二章:深入 kubelet 源码 —— Pod 生命周期管理与 CRI 集成详解
我们将剖析 kubelet 如何 Watch Pod、调用 containerd、执行探针、上报状态,并解读其 syncLoop 核心逻辑。
12. 参考资料
- Kubernetes 官方文档 - Components
- Kubernetes GitHub Repository
- Kubernetes Enhancement Proposals (KEPs)
- 《Kubernetes 源码剖析》—— 郑东旭
- Borg, Omega, and Kubernetes 论文(Google)
原创声明:本文为作者原创,首发于 CSDN。转载请注明出处并保留原文链接。
互动:欢迎在评论区讨论 K8s 架构细节或提出下一期想看的组件!