合肥网站建设q479185700棒有没有做生物科技相关的网站
爬取豆瓣电影top250
需求分析
将爬取的数据导入到表格中,方便人为查看。
实现方法
三大功能
1,下载所有网页内容。
2,处理网页中的内容提取自己想要的数据
3,导入到表格中
分析网站结构需要提取的内容
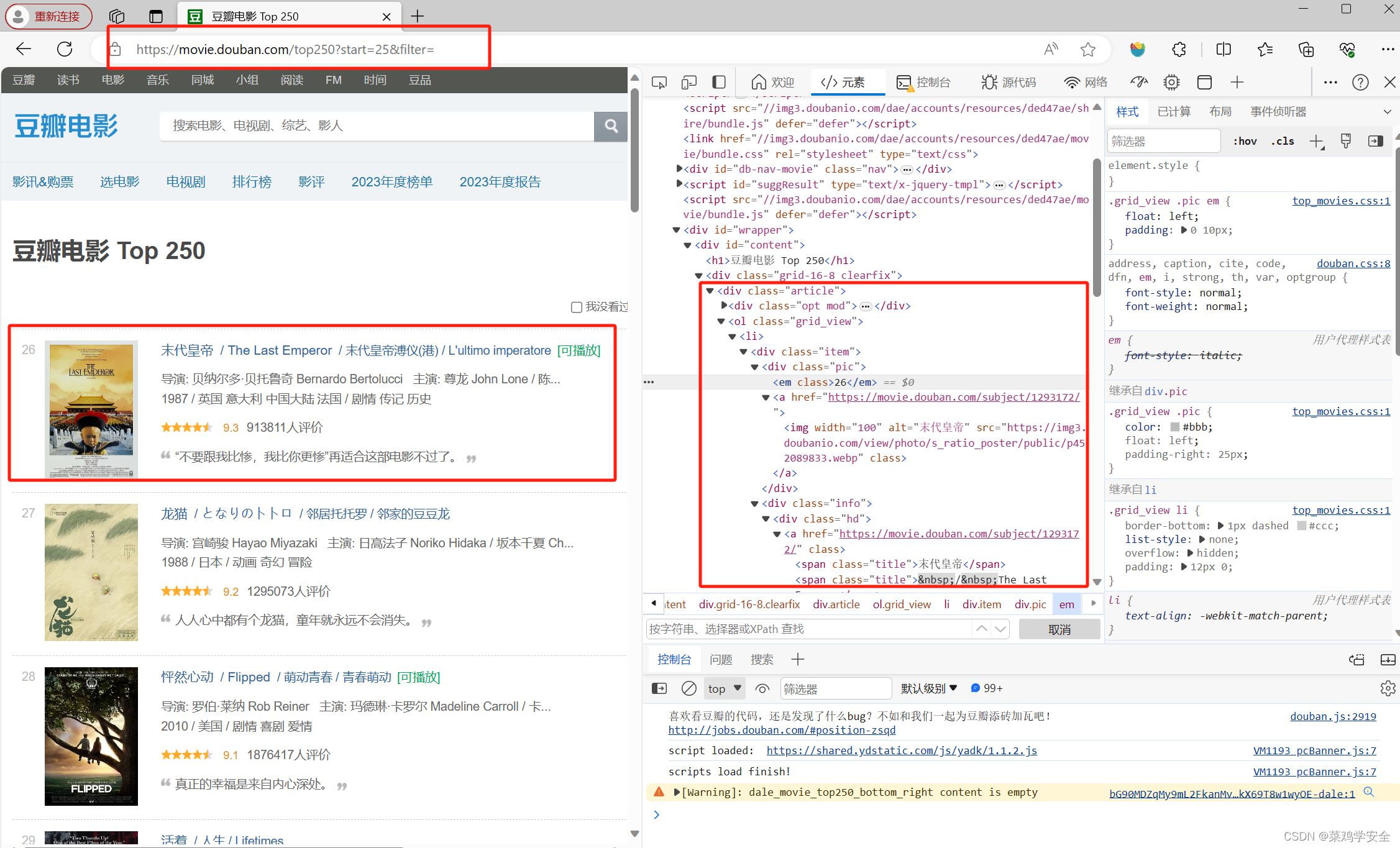
代码
import requests
from bs4 import BeautifulSoup
import pprint
import json
import pandas as pd
import time# 构造分页数字列表
page_indexs = range(0, 250, 25)
list(page_indexs)# 请求头
headers = {'User-agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/1'
}# 下载所有的网页然后交给下一个函数处理
def download_all_htmls():htmls = []for idx in page_indexs:url = "https://movie.douban.com/top250?start={}&filter=".format(idx)print("craw html", url)r = requests.get(url, headers=headers)if r.status_code != 200:raise Exception("error")htmls.append(r.text)time.sleep(0.5)return htmls# 解析HTML得到数据def parse_single_html(html):# 使用BeautifulSoup处理网页,传入参数html,使用html.parser模式处理soup = BeautifulSoup(html, 'html.parser')# 使用BeautifulSoup匹配想要的内容,使用find函数article_items = (soup.find("div", class_="article").find("ol", class_="grid_view").find_all("div", class_="item"))datas = []# 内容比较多分步提取内容for article_item in article_items:rank = article_item.find("div", class_="pic").find("em").get_text()info = article_item.find("div", class_="info")title = info.find("div", class_="hd").find("span", class_="title").get_text()stars = (info.find("div", class_="bd").find("div", class_="star").find_all("span"))rating_star = stars[0]["class"][0]rating_num = stars[1].get_text()comments = stars[3].get_text()datas.append({"rank": rank,"title": title,"rating_star": rating_star.replace("rating", "").replace("-t", ""),"rating_num": rating_num,"comments": comments.replace("人评价", "")})return dataspprint.pprint()if __name__ == '__main__':# 下载所有的网页内容htmls = download_all_htmls()# pprint.pprint(parse_single_html(htmls[0]))# 解析网页内容并追到all_datas的列表中all_datas = []for html in htmls:all_datas.extend(parse_single_html(html))# 使用pandas模块,批量导入到表格中df = pd.DataFrame(all_datas)df.to_excel("doubanTOP250.xlsx")
效果图
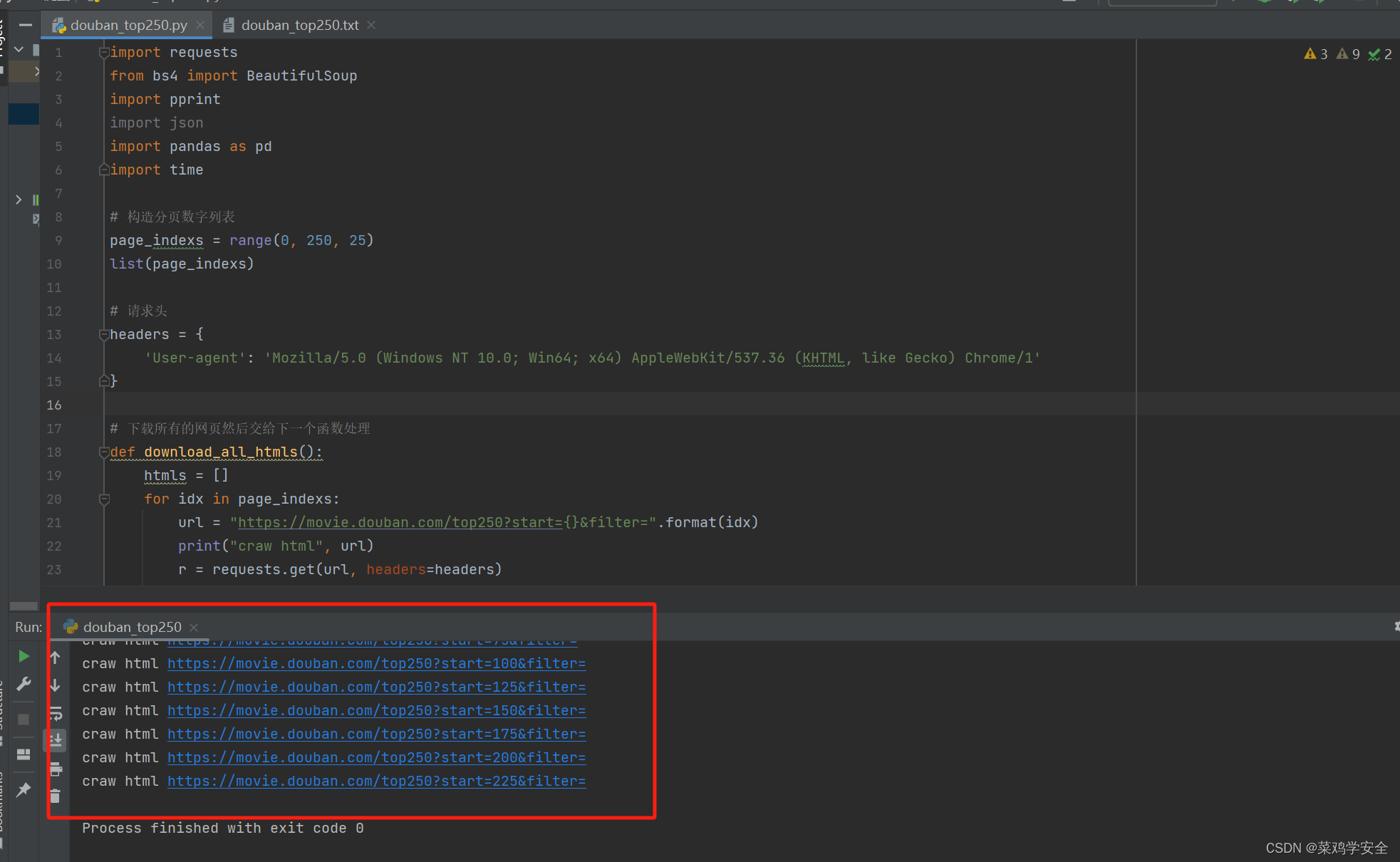
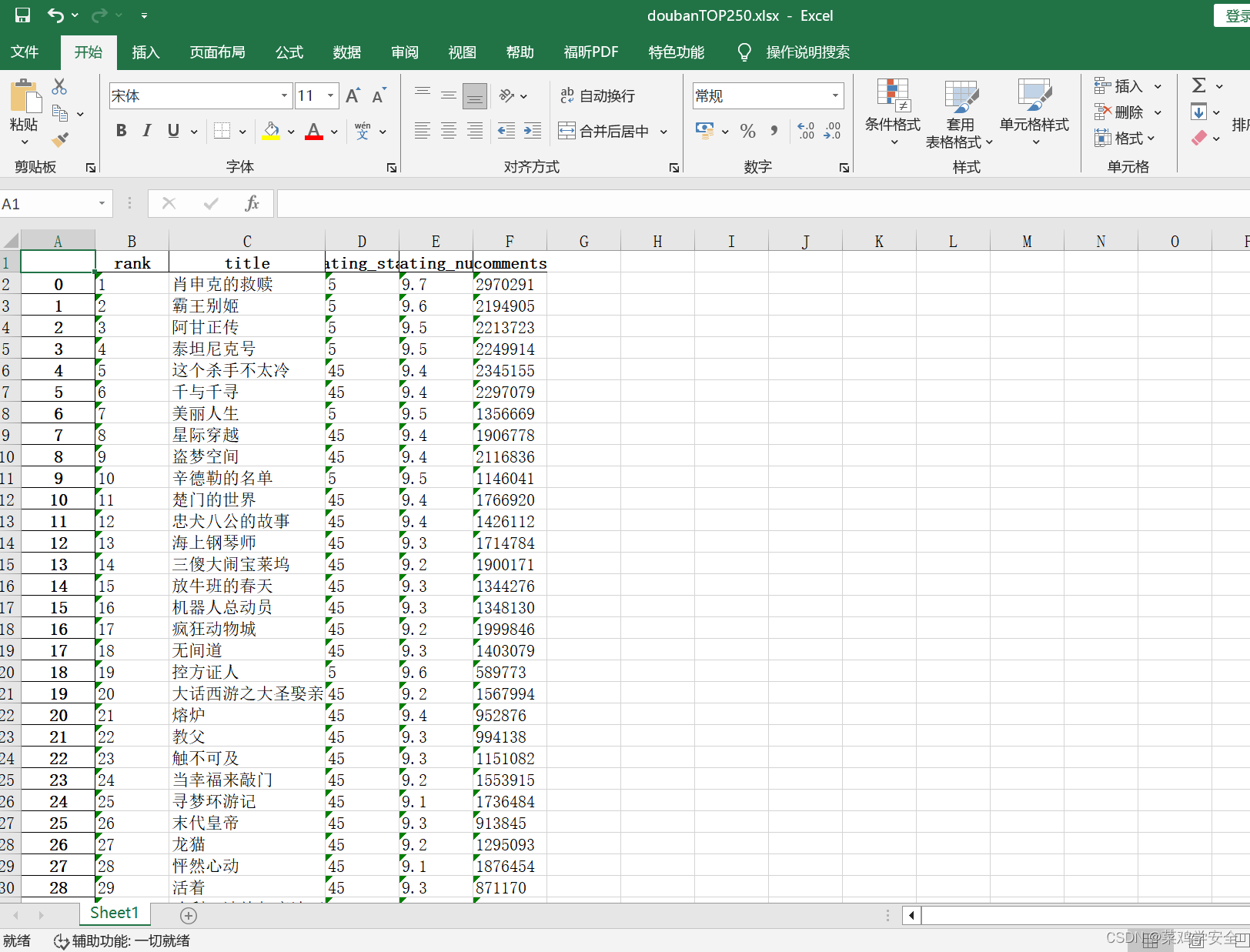
参考文章
https://www.bilibili.com/video/BV1CY411f7yh/?p=15