高并发内存池9 —— Page Cache 回收
文章目录
- 前言
- 向前向后合并
- 怎么做
- 空闲的span?
- 详解流程
- 总结
前言
\qquad在上一文的Central Cache介绍中,当 Central Cache 里某一个哈希桶里的span链表里的_useCount为0了,此时就说明要将span还回去给 Page Cache。
\qquad但是呢,在 Page Cache 拿到了 Span 之后,我们的最终目标是要减少内存碎片的,所以我们可以考虑将还回来的Span与其他空闲的Span进行合并。
向前向后合并
怎么做
\qquad当我们获得了一个空闲的Span时,我们自然而然的,也就获得了这个Span所管理的页数,以及起始页号。
\qquad因为在上一文中,存在了对每一个页和span进行[[8️⃣ Central Cache 回收内存#解决措施|映射建立]]。
而假设我们通过Span获得了一个起始页号num,那么num - 1就是对应的上一页,而通过映射关系,自然而然的也就知道了这个页是属于哪一个Span管理的。
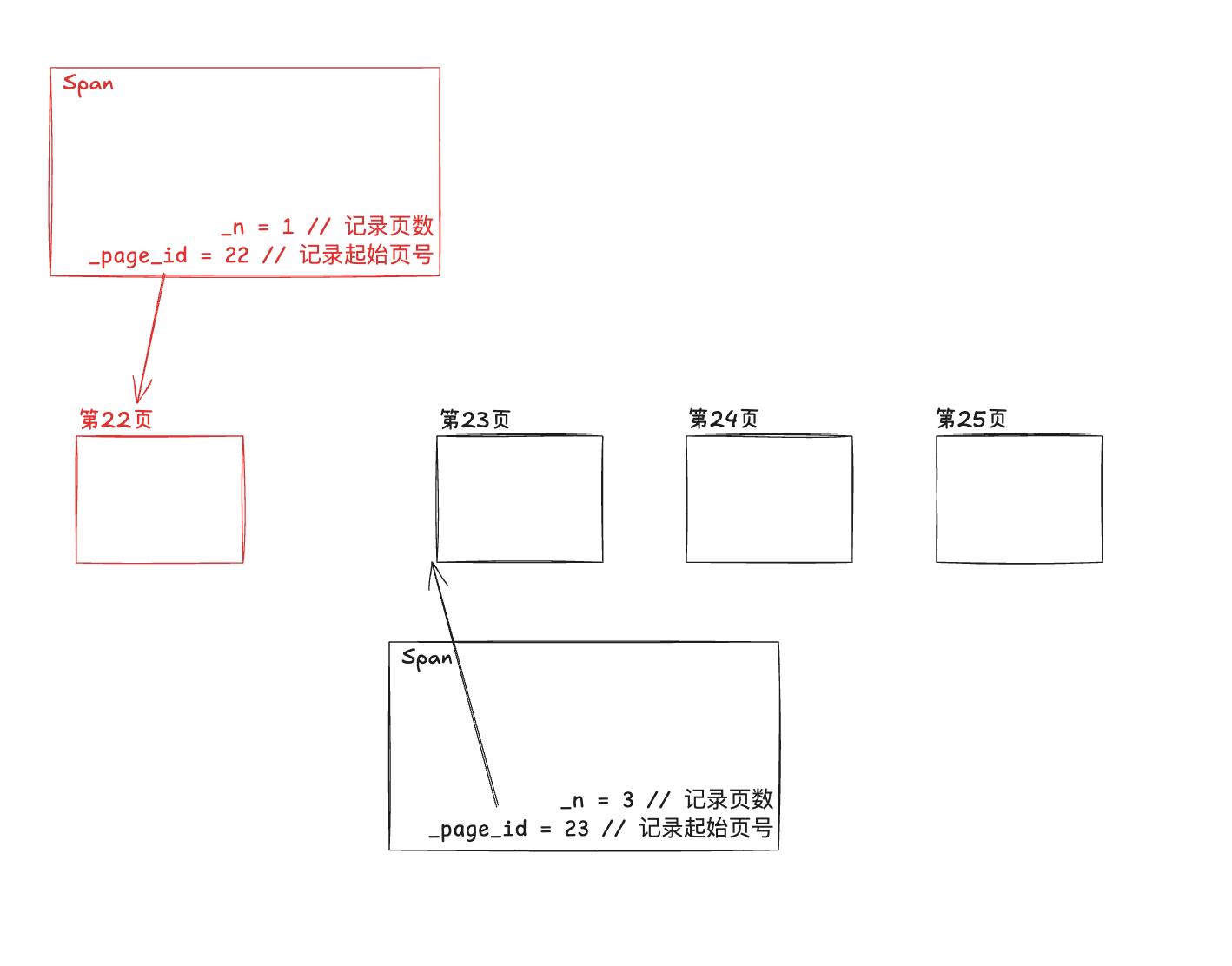
如图所示的结构,所以,在未来,我们找到了页号我们就一定能够找到这个Span的起始页号,再通过这个起始页号再往前面不断地寻找。
空闲的span?
\qquad现在,你已经学会了怎么找前一个页的页号,也能找到对应的Span了,但是你得明确一点,这个Span很有可能现在还在Central Cache上喔,他并不是一个空闲的Span,这个Span现在还在切割空间给予Thread Cache使用呢!
\qquad所以,这也就是为什么我们在设置[[4️⃣ Central Cache#Span 的结构|Span]]的时候,存在一个成员变量_isUse,用它来标记某一个Span目前的状态。所以接下来我要对代码进行补充。
- 第一个要补充的就是Central Cache在从Page Cache拿到Span的时候
// 在对应哈希桶中获取一个非空的 spanSpan* CentralCache::GetOneSpan(SpanList &list, size_t byte_size)
{ // 1. 遍历一遍 Span* it = list.Begin(); while (it != list.End()) { if (it->_freeList != nullptr) return it; it = it->_next; } // 2. 没有找到非空的 Span,只能向 page cache 申请 list._mtx.unlock(); // 桶锁:解锁 🔓 PageCache::GetInstance()->Get_pageMtx().lock(); // 大锁:加锁 🔒 Span* span = PageCache::GetInstance()->NewSpan(SizeClass::NumMovePage(byte_size)); span->_isUse = true; // 标记->正在使用 PageCache::GetInstance()->Get_pageMtx().unlock(); // 大锁:解锁 🔓- 第二个就是在咱们上一文中,释放的时候
void CentralCache::ReleaseListToSpans(void* start, size_t byte_size)
{ assert(start); size_t index = SizeClass::Index(byte_size); _spanLists[index]._mtx.lock(); // 加锁 while (start) { void* next = NextObj(start); Span* span = PageCache::GetInstance()->MapObjectToSpan(start); // 获得当前对象 对应的 span NextObj(start) = span->_freeList; span->_freeList = start; span->_useCount--; // 更新被分配给 Thread Cache 的计数 if (span->_useCount == 0) { // 此时这个 span 就可以再回收给 Page Cache,Page Cache可以再尝试去做前后页的合并 _spanLists[index].Erase(span); span->_freeList = nullptr; span->_next = nullptr; span->_prev = nullptr; // 释放 span 给 Page Cache 时,使用 Page Cache 的锁就可以了,这时把桶锁解掉 _spanLists[index]._mtx.unlock(); PageCache::GetInstance()->Get_pageMtx().lock(); // 加大锁 span->_isUse = false; // 标记->没在使用了 PageCache::GetInstance()->ReleaseSpanToPageCache(span); // 交给 Page Cache PageCache::GetInstance()->Get_pageMtx().unlock(); // 解大锁
详解流程
void PageCache::ReleaseSpanToPageCache(Span*& span)
{ assert(span); //=================== // 1. 向前合并 //=================== while (true) { if (span->_pageId == 0) break; // 防止溢出,可选 PAGE_ID prevId = span->_pageId - 1; auto it = _idSpanMap.find(prevId); if (it == _idSpanMap.end()) break; Span* prevSpan = it->second; // 前面的 span 还在被 Central Cache 使用,不能合并 if (prevSpan->_isUse) break; // 页面总数不能超过上限 if (prevSpan->_n + span->_n > NPAGES - 1) break; // 从自由链表中移除 _spanLists[prevSpan->_n].Erase(prevSpan); // 向前扩展:新的起始页是 prevSpan 的起始页 span->_pageId = prevSpan->_pageId; span->_n += prevSpan->_n; delete prevSpan; } //=================== // 2. 向后合并 //=================== while (true) { PAGE_ID nextId = span->_pageId + span->_n; // 当前区间之后的第一页 auto it = _idSpanMap.find(nextId); if (it == _idSpanMap.end()) break; Span* nextSpan = it->second; // 后面的 span 还在被 Central Cache 使用,不能合并 if (nextSpan->_isUse) break; if (nextSpan->_n + span->_n > NPAGES - 1) break; _spanLists[nextSpan->_n].Erase(nextSpan); // 向后扩展:起始页不变,只增加长度 span->_n += nextSpan->_n; delete nextSpan; } //=================== // 3. 把合并后的 span 当成空闲 span 挂回 PageCache //=================== // 清理一下小块信息(保险起见) span->_objSize = 0; span->_useCount = 0; span->_freeList = nullptr; span->_isUse = false; _spanLists[span->_n].PushFront(span); //=================== // 4. 重新建立“每一页 → span”的映射 //=================== for (size_t i = 0; i < span->_n; ++i) { PAGE_ID pid = span->_pageId + i; _idSpanMap[pid] = span; // 直接覆盖旧值即可 }
}
在这里有许多东西需要提前处理清楚,其实合并并不困难,本质就是对span的成员变量进行修改。
而真正要注意的则是细节,比如要记住不能超过最大空间,以及不要忘记再重新建立映射。
总结
\qquad至此,我们的高并发内存池项目的整体框架已经全部实现完毕,后续的我也并不打算再继续了。虽然说要有头有尾吧,但是我现在必须要进行下一个项目了,而且这一是我的第一个C++项目,我也学会了应该如何去学习一个项目的编写!