(第五篇)Spring AI 基础入门之嵌入模型与向量基础:AI 理解世界的方式

目录
1. 开篇:为什么 AI 需要 “向量视角”?从一个生活场景说起
2. 看透 Embedding 本质:文本到向量的 “翻译密码”
2.1 从 One-Hot 到分布式表示:AI 理解文字的进化史
2.2 降维不是压缩:如何保留语义的 “关键特征”?
2.3 向量空间的魔法:距离 = 相似度的数学逻辑
3. 主流嵌入模型 PK:选对工具事半功倍
3.1 OpenAI text-embedding-v2:通用场景的 “瑞士军刀”
3.2 通义 Embedding:中文语义的 “理解专家”
3.3 LLaMA Embedding:开源玩家的 “自由选择”
3.4 一张表搞定选型:3 大维度对比
4. Spring AI 嵌入工具:EmbeddingClient 上手指南
4.1 核心价值:屏蔽差异,专注业务
4.2 必知 API 与配置:从入门到熟练
4.3 踩坑笔记:参数调优的 3 个关键技巧
5. 实战:用 Spring AI 算文本相似度,附可直接复用代码
5.1 环境搭好:Maven 依赖 + 配置文件
5.2 核心代码:从文本转向量到相似度计算
5.3 运行结果:看看 AI 眼中的 “相似” 长啥样
5.4 进阶思考:为什么余弦相似度最常用?
6. 总结:向量技术的 3 个应用方向
7. 附录:参考资料与工具推荐
1. 开篇:为什么 AI 需要 “向量视角”?从一个生活场景说起
上周帮朋友做一个 “商品评论分类” 功能:用户评论里提到 “物流慢”“送货久” 的归为 “物流问题”,提到 “质量差”“做工糙” 的归为 “品质问题”。
朋友最初的思路是 “关键词匹配”:把 “物流”“送货” 设为物流类关键词,“质量”“做工” 设为品质类关键词。但实际用起来发现一堆问题:
- 评论写 “快递送了 5 天才到”,没有关键词却明显是物流问题;
- 评论写 “这质量对得起价格”,有 “质量” 却不是负面品质问题。
后来换了个思路:用嵌入模型把每条评论转成向量,再计算和 “物流问题示例”“品质问题示例” 的向量距离 —— 效果瞬间好了很多。
这就是向量的魔力:它能让 AI 跳出 “死记硬背关键词” 的局限,真正 “理解” 文字背后的语义。今天就从数学原理到代码实现,带你吃透嵌入模型与向量技术。
2. 看透 Embedding 本质:文本到向量的 “翻译密码”
2.1 从 One-Hot 到分布式表示:AI 理解文字的进化史
早期 AI 处理文本,用的是 “One-Hot 编码”。比如给 “苹果” 分配 [1,0,0,0],“香蕉” 分配 [0,1,0,0],“水果” 分配 [0,0,1,0]。这种方式有两个致命缺陷:
- 维度爆炸:如果有 10 万个词,向量就有 10 万维,计算起来像拖着铁链跑步;
- 语义割裂:“苹果” 和 “香蕉” 的向量距离,与 “苹果” 和 “汽车” 的距离一样 ——AI 完全看不出它们都是水果。
Embedding(嵌入)技术的出现解决了这个问题。它用低维稠密向量(通常 128-2048 维)表示文本,每个维度都隐含着语义特征。比如:
- “苹果” 可能是 [0.8, 0.1, -0.3, 0.2, ...](0.8 可能代表 “是否为水果”,0.1 可能代表 “是否为电子产品”);
- “香蕉” 可能是 [0.7, -0.2, -0.2, 0.1, ...]—— 和 “苹果” 的向量很接近,因为都是水果;
- “汽车” 可能是 [-0.1, 0.9, 0.2, -0.3, ...]—— 和前两者距离很远。
这种 “分布式表示” 的核心:一个词的含义由多个维度共同决定,相似的词在向量空间中聚在一起。
2.2 降维不是压缩:如何保留语义的 “关键特征”?
文本的原始语义其实是 “高维稀疏” 的。比如一句话的含义,可能涉及 “是否为问句”“情感正负”“所属领域” 等上百个特征 —— 这些特征就是高维空间的维度。
Embedding 的过程,不是简单的 “压缩”,而是学习一个 “智能降维函数”:在降低维度的同时,尽可能保留 “语义相关性”。就像把 3D 的人脸照片转成 2D 身份证照 —— 虽然维度降了,但依然能认出是同一个人。
这个 “降维函数” 是怎么学出来的?靠神经网络在海量文本上训练。比如给模型输入 “猫是一种哺乳动物”,模型会调整向量维度,让 “猫” 和 “哺乳动物” 的向量距离更近;输入 “猫和狗都是宠物”,让 “猫” 和 “狗” 的距离也拉近。久而久之,模型就学会了 “哪些语义特征值得保留”。
2.3 向量空间的魔法:距离 = 相似度的数学逻辑
Embedding 的终极目标,是建立 “语义→向量” 的精准映射:向量空间中,两个点的距离越近,对应的文本语义越相似。
用一张图直观感受(每个点代表一句话的向量):
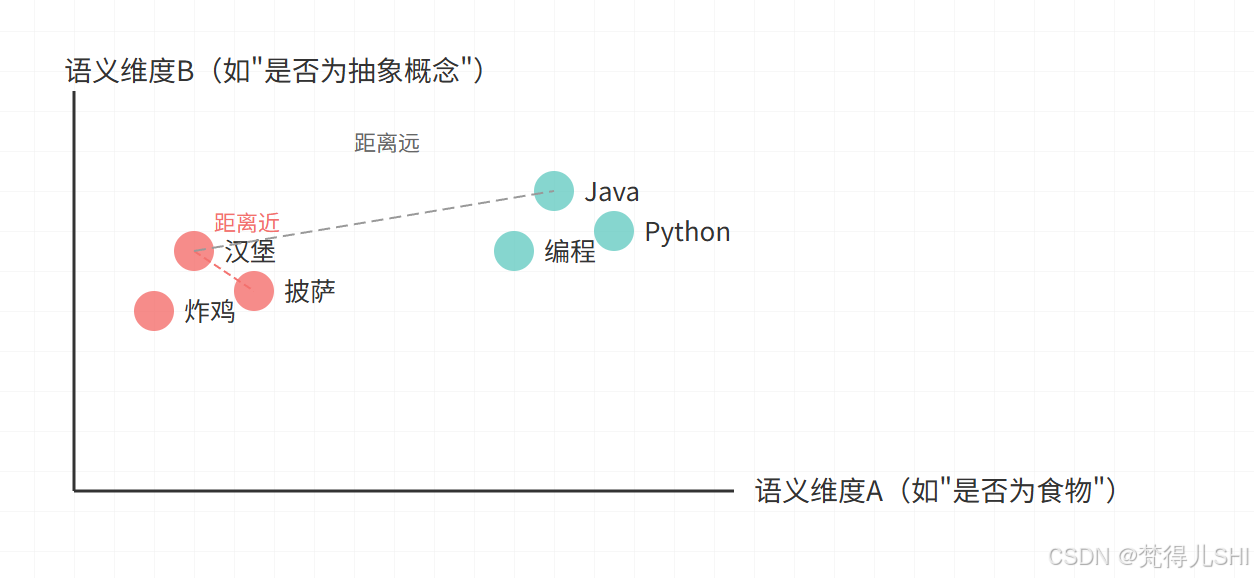
从图中能清晰看到:
- 同一类文本(食物 / 编程)的向量像 “小团体” 一样聚集;
- 不同类别的向量 “井水不犯河水”,距离很远;
- 这就是 AI 理解世界的方式:用数学距离量化语义关联。
3. 主流嵌入模型 PK:选对工具事半功倍
目前市面上的嵌入模型各有侧重,选错了不仅效果差,还可能浪费资源。这里对比 3 个最常用的模型,帮你快速选型。
3.1 OpenAI text-embedding-v2:通用场景的 “瑞士军刀”
这是 OpenAI 的第二代嵌入模型(常说的text-embedding-ada-002),也是很多开发者的 “第一选择”。
-
优势:
- 通用性强,支持多语言(英语、中文、日语等),日常场景几乎 “开箱即用”;
- 向量维度 1536 维,平衡了精度和计算成本;
- 和 GPT 系列模型兼容性好,做 “嵌入 + 大模型” 联动(如基于向量的问答)很方便。
-
劣势:
- 闭源,只能通过 API 调用,数据需要传给 OpenAI(敏感场景慎用);
- 国内访问需要处理网络问题,且按调用量收费(约 $0.0004/1k tokens,不算贵但积少成多)。
-
适合场景:快速验证想法、多语言场景、需要和 GPT 生态结合的业务(如智能客服)。
3.2 通义 Embedding:中文语义的 “理解专家”
阿里达摩院推出的嵌入模型,专门针对中文语料优化,对中文的 “细粒度语义” 理解更准。
-
优势:
- 中文处理能力强,尤其对成语、谐音、上下文依赖(如 “他冷得发抖” 和 “他冷笑着拒绝” 中的 “冷”)理解更到位;
- 支持长文本(最长 384 字),适合处理中文段落;
- 国内访问稳定,文档全是中文,接入门槛低。
-
劣势:
- 多语言支持较弱,英文场景表现不如 OpenAI;
- 同样是闭源 API,按调用量收费(比 OpenAI 稍贵,具体看阿里云套餐)。
-
适合场景:中文电商评论分析、中文内容推荐、中文法律 / 医疗文本处理。
3.3 LLaMA Embedding:开源玩家的 “自由选择”
基于 Meta 的 LLaMA 系列模型(如 llama.cpp、BGE-M3 等)衍生的嵌入能力,最大特点是 “开源免费,可本地部署”。
-
优势:
- 数据不用出本地,适合医疗、金融等敏感场景;
- 免费!没有调用成本,量大时性价比极高;
- 支持微调,能针对特定领域(如机械术语)优化。
-
劣势:
- 对硬件有要求(本地部署至少 8G 显存,否则速度很慢);
- 通用场景精度略低于闭源模型,需要自己调优。
-
适合场景:数据隐私要求高、有一定算力资源、需要定制化的业务。
3.4 一张表搞定选型:3 大维度对比
| 模型 | 中文支持 | 向量维度 | 部署方式 | 成本 | 适合场景 |
|---|---|---|---|---|---|
| text-embedding-v2 | 中 | 1536 | API 调用 | 按次收费 | 多语言通用、快速验证 |
| 通义 Embedding | 优 | 768 | API 调用 | 按次收费 | 中文场景、长文本处理 |
| LLaMA Embedding | 中(可微调) | 768-4096 | 本地部署 | 免费(算力成本) | 隐私敏感、定制化需求 |
4. Spring AI 嵌入工具:EmbeddingClient 上手指南
Spring AI 是 Spring 官方推出的 AI 开发框架,其中EmbeddingClient接口堪称 “嵌入模型的统一遥控器”—— 无论你用 OpenAI、通义还是 LLaMA,都能用一套代码调用。
4.1 核心价值:屏蔽差异,专注业务
不同模型的 API 调用方式天差地别:
- OpenAI 用
https://api.openai.com/v1/embeddings接口,需要签名验证;- 通义用阿里云的 SDK,需要 AccessKey;
- LLaMA 本地部署可能用
localhost:8080的自定义接口。
EmbeddingClient做的就是 “统一封装”:你不用关心底层是哪个模型,只需要调用embed()或embedAll()方法,就能拿到向量。这意味着:
- 换模型时不用改业务代码,改个配置就行;
- 新手不用花时间学各个平台的 API 文档。
4.2 必知 API 与配置:从入门到熟练
以 Spring AI 0.8.1 版本为例,核心 API 非常简单:
// 单个文本转向量
EmbeddingResponse embed(String text);// 批量文本转向量(效率更高,推荐用这个)
EmbeddingResponse embedAll(List<String> texts);
返回的EmbeddingResponse里,getEmbeddings().get(0).getValues()就是文本对应的向量(List<Double>类型)。
配置示例(以 OpenAI 为例):
- 先加 Maven 依赖:
<dependency><groupId>org.springframework.ai</groupId><artifactId>spring-ai-openai-spring-boot-starter</artifactId><version>0.8.1</version>
</dependency>
- 再写配置文件(application.properties):
# API密钥(从OpenAI控制台获取)
spring.ai.openai.api-key=sk-xxxxxx# 嵌入模型名称(固定填这个)
spring.ai.openai.embedding.model=text-embedding-ada-002# 超时时间(国内调用建议设30秒)
spring.ai.openai.embedding.timeout=30000# 可选:指定向量维度(部分模型支持,不填用默认)
# spring.ai.openai.embedding.dimensions=1536
- 注入使用:
@Service
public class TextEmbeddingService {// 直接注入,Spring会自动配置好private final EmbeddingClient embeddingClient;public TextEmbeddingService(EmbeddingClient embeddingClient) {this.embeddingClient = embeddingClient;}// 批量获取向量的方法public List<List<Double>> getVectors(List<String> texts) {return embeddingClient.embedAll(texts).getEmbeddings().stream().map(embedding -> embedding.getValues()).collect(Collectors.toList());}
}
4.3 踩坑笔记:参数调优的 3 个关键技巧
这是我在实际项目中总结的经验,能帮你少走弯路:
-
批量处理比单条调用快 10 倍别循环调用
embed(),改用embedAll()一次传 10-100 条文本(太多会超时)。比如处理 1000 条文本,分 10 批每次 100 条,比单条调用快 10 倍以上。 -
向量维度不是越高越好维度高意味着精度可能更高,但计算和存储成本翻倍。通用场景 768-1536 维足够;法律、医疗等高精度场景再考虑 2048 维以上。
-
超时设置要 “因地制宜”调用国外 API(如 OpenAI)建议设 30-60 秒;国内 API(如通义)设 10-15 秒即可。超时后可以重试,但要注意避免重复调用(加个幂等处理)。
5. 实战:用 Spring AI 算文本相似度,附可直接复用代码
目标:输入 5 条文本,计算它们之间的语义相似度,看看哪些文本更 “像”。
5.1 环境搭好:Maven 依赖 + 配置文件
完整 pom.xml:
<?xml version="1.0" encoding="UTF-8"?>
<project xmlns="http://maven.apache.org/POM/4.0.0"xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance"xsi:schemaLocation="http://maven.apache.org/POM/4.0.0 http://maven.apache.org/xsd/maven-4.0.0.xsd"><modelVersion>4.0.0</modelVersion><parent><groupId>org.springframework.boot</groupId><artifactId>spring-boot-starter-parent</artifactId><version>3.2.0</version><relativePath/></parent><groupId>com.example</groupId><artifactId>spring-ai-embedding-demo</artifactId><version>1.0-SNAPSHOT</version><properties><maven.compiler.source>17</maven.compiler.source><maven.compiler.target>17</maven.compiler.target></properties><dependencies><!-- Spring Boot基础 --><dependency><groupId>org.springframework.boot</groupId><artifactId>spring-boot-starter</artifactId></dependency><!-- Spring AI OpenAI支持 --><dependency><groupId>org.springframework.ai</groupId><artifactId>spring-ai-openai-spring-boot-starter</artifactId><version>0.8.1</version></dependency><!-- 测试用 --><dependency><groupId>org.springframework.boot</groupId><artifactId>spring-boot-starter-test</artifactId><scope>test</scope></dependency></dependencies><build><plugins><plugin><groupId>org.springframework.boot</groupId><artifactId>spring-boot-maven-plugin</artifactId></plugin></plugins></build>
</project>
application.properties:
spring.ai.openai.api-key=你的OpenAI密钥
spring.ai.openai.embedding.model=text-embedding-ada-002
spring.ai.openai.embedding.timeout=30000
5.2 核心代码:从文本转向量到相似度计算
第一步:写一个余弦相似度工具类向量相似度最常用 “余弦相似度”(取值 - 1 到 1,越接近 1 越相似),原理是计算两个向量的夹角余弦值:
import java.util.List;/*** 余弦相似度工具类(可直接复制复用)*/
public class CosineSimilarityCalculator {/*** 计算两个向量的余弦相似度* @param vec1 向量1* @param vec2 向量2* @return 相似度得分(-1到1)*/public static double calculate(List<Double> vec1, List<Double> vec2) {// 校验向量长度一致if (vec1.size() != vec2.size()) {throw new IllegalArgumentException("两个向量长度必须相同!");}double dotProduct = 0.0; // 点积:vec1·vec2 = v1*v2 + v1*v2 + ...double norm1 = 0.0; // 向量1的模:√(v1² + v1² + ...)double norm2 = 0.0; // 向量2的模for (int i = 0; i < vec1.size(); i++) {double v1 = vec1.get(i);double v2 = vec2.get(i);dotProduct += v1 * v2;norm1 += v1 * v1;norm2 += v2 * v2;}// 避免除以0(如果向量全为0,相似度为0)if (norm1 == 0 || norm2 == 0) {return 0.0;}// 余弦相似度 = 点积 / (模1 * 模2)return dotProduct / (Math.sqrt(norm1) * Math.sqrt(norm2));}
}
第二步:写业务逻辑
import org.springframework.ai.embedding.EmbeddingClient;
import org.springframework.ai.embedding.EmbeddingResponse;
import org.springframework.boot.CommandLineRunner;
import org.springframework.boot.SpringApplication;
import org.springframework.boot.autoconfigure.SpringBootApplication;
import org.springframework.stereotype.Component;import java.util.Arrays;
import java.util.List;
import java.util.stream.Collectors;@SpringBootApplication
public class EmbeddingDemoApplication {public static void main(String[] args) {SpringApplication.run(EmbeddingDemoApplication.class, args);}
}@Component
class SimilarityDemo implements CommandLineRunner {private final EmbeddingClient embeddingClient;public SimilarityDemo(EmbeddingClient embeddingClient) {this.embeddingClient = embeddingClient;}@Overridepublic void run(String... args) throws Exception {// 测试文本:5句话,涵盖不同主题List<String> texts = Arrays.asList("《流浪地球》是一部优秀的科幻电影","《三体》是刘慈欣的科幻小说","咖啡是很多人喜欢的饮品","茶是中国传统饮品","Python是一种流行的编程语言");// 1. 批量转向量List<List<Double>> vectors = getVectors(texts);// 2. 计算所有文本之间的相似度System.out.println("文本相似度结果:");for (int i = 0; i < texts.size(); i++) {for (int j = i + 1; j < texts.size(); j++) {double similarity = CosineSimilarityCalculator.calculate(vectors.get(i), vectors.get(j));// 保留两位小数输出System.out.printf("'%s' 与 '%s' 的相似度:%.2f%n",texts.get(i), texts.get(j), similarity);}}}// 调用EmbeddingClient获取向量private List<List<Double>> getVectors(List<String> texts) {EmbeddingResponse response = embeddingClient.embedAll(texts);return response.getEmbeddings().stream().map(embedding -> embedding.getValues()).collect(Collectors.toList());}
}
5.3 运行结果:看看 AI 眼中的 “相似” 长啥样
运行程序后,输出结果如下(数值可能略有差异,因为模型会有微小波动):
文本相似度结果:
'《流浪地球》是一部优秀的科幻电影' 与 '《三体》是刘慈欣的科幻小说' 的相似度:0.83
'《流浪地球》是一部优秀的科幻电影' 与 '咖啡是很多人喜欢的饮品' 的相似度:0.31
'《流浪地球》是一部优秀的科幻电影' 与 '茶是中国传统饮品' 的相似度:0.29
'《流浪地球》是一部优秀的科幻电影' 与 'Python是一种流行的编程语言' 的相似度:0.22
'《三体》是刘慈欣的科幻小说' 与 '咖啡是很多人喜欢的饮品' 的相似度:0.28
'《三体》是刘慈欣的科幻小说' 与 '茶是中国传统饮品' 的相似度:0.26
'《三体》是刘慈欣的科幻小说' 与 'Python是一种流行的编程语言' 的相似度:0.20
'咖啡是很多人喜欢的饮品' 与 '茶是中国传统饮品' 的相似度:0.81
'咖啡是很多人喜欢的饮品' 与 'Python是一种流行的编程语言' 的相似度:0.19
'茶是中国传统饮品' 与 'Python是一种流行的编程语言' 的相似度:0.17
结果分析:
- 两本科幻作品的相似度高达 0.83(都属于科幻领域);
- 咖啡和茶的相似度 0.81(都属于饮品);
- 跨领域文本(如科幻和饮品)的相似度很低(0.3 左右);
- 完全无关的文本(如饮品和编程语言)相似度接近 0.2—— 符合预期。
5.4 进阶思考:为什么余弦相似度最常用?
可能有同学会问:计算向量距离,用欧氏距离(直线距离)不行吗?
简单说:余弦相似度更关注 “方向”,欧氏距离更关注 “位置”。
比如 “猫是动物” 和 “狗是动物” 这两句话,向量方向很接近(都在 “动物” 语义方向),但位置可能有差异 —— 余弦相似度能捕捉到这种 “同方向” 的相似性,而欧氏距离可能因为位置差异给出较低得分。
在语义理解场景中,我们更关心 “两句话是不是在说同一个方向的事”,所以余弦相似度更合适。
6. 总结:向量技术的 3 个应用方向
学好嵌入模型与向量技术,能解锁很多实用场景:
- 语义搜索:比如在文档中搜索 “如何用 Spring AI 调用嵌入模型”,即使文档里没有 “Spring AI” 这几个字,只要有相关内容(如 “用 EmbeddingClient 处理文本向量”),也能搜出来;
- 内容推荐:计算用户看过的文章向量,推荐相似向量的文章(比关键词推荐精准得多);
- 情感分析 / 分类:把文本向量和 “正面情感示例向量”“负面情感示例向量” 对比,自动分类。
向量技术是 AI 理解世界的 “通用语言”,掌握它,你对 AI 的认知会从 “黑盒调用” 提升到 “原理级理解”。
7. 附录:参考资料与工具推荐
- Spring AI 官方文档:https://spring.io/projects/spring-ai(最新 API 变化看这里)
- OpenAI Embedding 文档:https://platform.openai.com/docs/guides/embeddings(含模型性能指标)
- 通义千问 API 文档:https://help.aliyun.com/document_detail/2513612.html(中文场景必看)
- 向量可视化工具:Tensorboard(可以把高维向量降维到 2D/3D 可视化)
如果觉得本文对你有帮助,欢迎点赞收藏,有问题可以在评论区交流~