AI入门知识之RAG技术树全景解析:从基础架构到智能演进的演进路径
图片来源网络
文章目录
- 前言
- 一、基础架构分支:RAG的起源与核心框架
- 1. Naive RAG(朴素RAG)
- 2. Advanced RAG(高级RAG)
- 二、高级优化分支:模块化与知识结构的深化
- 1. Modular RAG(模块化RAG)
- 2. Graph RAG(图RAG)
- 三、智能演进分支:动态智能与多模态的突破
- 1. Agentic RAG(智能体RAG)
- 2. 多模态RAG(Multimodal RAG)
- 四、前沿演进方向:轻量化与工程化
- 1. LightRAG(轻量型RAG)
- 2. 工程化实践
- 总结:RAG技术树的演进逻辑
前言
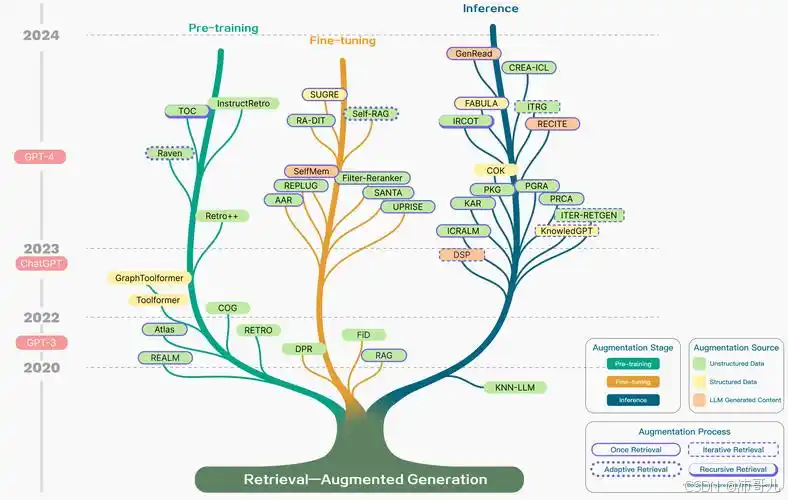
RAG(Retrieval-Augmented Generation,检索增强生成)技术树是围绕“检索与生成的协同优化”核心,通过架构升级、模块细化、智能增强逐步演进的技术体系。其发展脉络清晰呈现了从“线性流程”到“动态智能”、从“文本中心”到“多模态融合”的创新轨迹,以下从基础架构、高级优化、智能演进三大分支展开详细解析:
一、基础架构分支:RAG的起源与核心框架
基础架构是RAG技术的“根”,定义了“检索-生成”的基本流程,解决了传统大模型“知识滞后、幻觉风险”的核心问题。主要包括两类经典架构:
1. Naive RAG(朴素RAG)
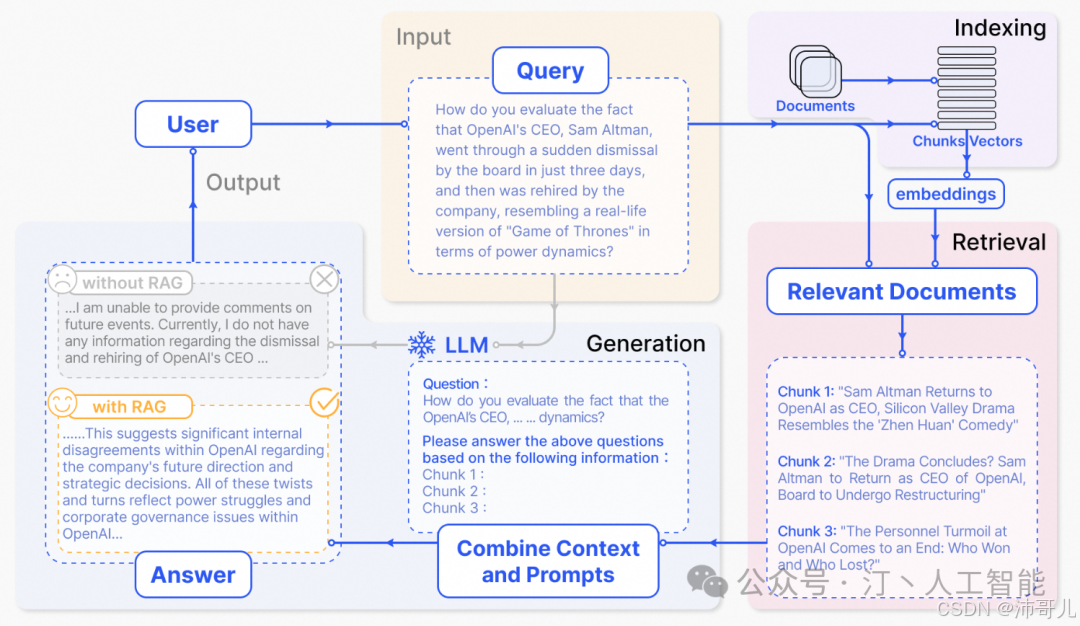
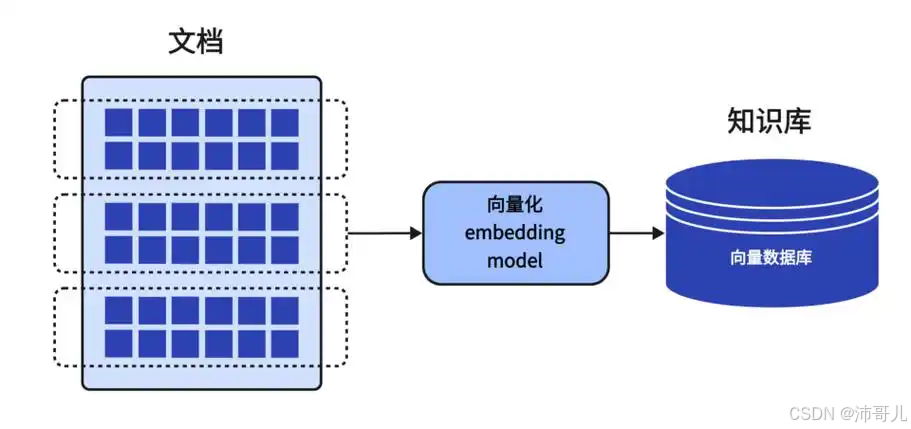
Naive RAG是RAG技术的初始形态,采用“索引→检索→生成”的线性流程,结构简单、易于实现,是理解RAG的基础框架。
- 核心流程:
① 文档预处理(分块、嵌入、存入向量数据库);② 用户查询向量化;③ 向量检索(相似性匹配Top-K文档);④ LLM结合检索结果生成回答。 - 特点:
优点是实现成本低、响应速度快;缺点是检索策略简单(仅依赖向量相似度)、生成依赖固定上下文(无法动态调整检索逻辑),难以应对复杂查询(如多跳推理、语义歧义)。 - 应用场景:早期的简单问答场景(如企业FAQ、常识性问题)。
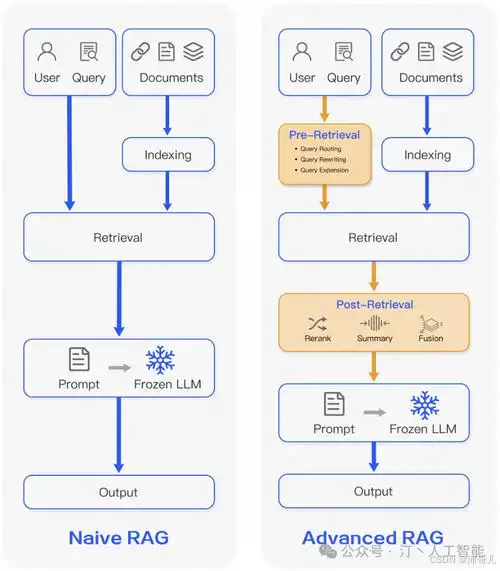
2. Advanced RAG(高级RAG)
Advanced RAG是Naive RAG的功能增强版,通过预检索优化(查询改写、扩展)和后检索优化(重排序、上下文压缩),解决Naive RAG“召回不精准、上下文冗余”的问题。
- 核心优化点:
- 预检索阶段:通过查询重写(如将“特斯拉最新车型”扩展为“特斯拉2025年发布的新车型及参数”)、查询扩展(生成多个语义相近的子查询),提高检索覆盖率;
- 后检索阶段:通过重排序模型(如BGE-Rerank、Cohere Rerank)重新排序检索结果(将与查询相关性最高的文档前置)、上下文压缩(剔除冗余信息,减小提示长度),提升生成质量。
- 特点:
保留了Naive RAG的简单性,同时通过“优化检索输入”和“优化生成上下文”,显著提高了复杂查询的处理能力。 - 应用场景:需要更高准确性的问答场景(如技术支持、产品咨询)。
二、高级优化分支:模块化与知识结构的深化
高级优化分支是RAG技术的“枝干”,通过模块化拆分(将RAG流程拆解为独立功能模块)和知识结构化(引入知识图谱),解决了Advanced RAG“模块耦合度高、语义理解浅”的问题。
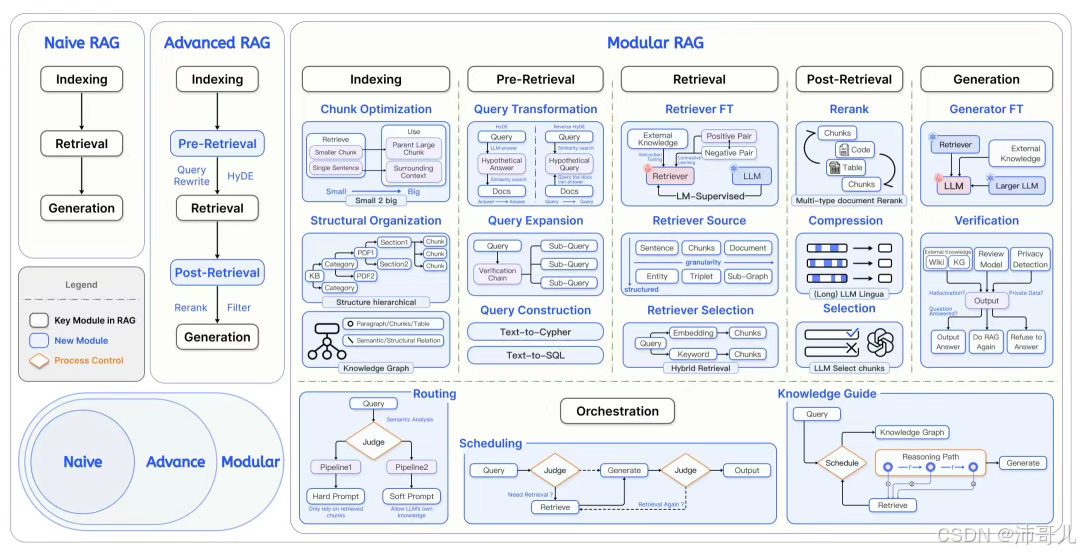
1. Modular RAG(模块化RAG)
Modular RAG是RAG技术的工程化升级,将RAG流程拆解为预检索、检索、后检索、生成四大模块,每个模块可独立优化或替换,提升了系统的灵活性和可维护性。
- 核心模块:
- 预检索模块:负责查询优化(重写、扩展)、文档预处理(分块、嵌入);
- 检索模块:支持向量检索、关键词检索(BM25)、混合检索(结合两者优势);
- 后检索模块:负责结果过滤(剔除无关文档)、重排序(提升相关性)、上下文压缩(减小提示长度);
- 生成模块:支持LLM生成(如GPT-4、Llama 3)、多模态生成(如图文结合)。
- 特点:
模块化设计使得系统可以根据不同场景(如文本问答、多模态问答)灵活组合模块,降低了维护成本。 - 应用场景:企业级复杂应用(如智能客服、数据分析)。
2. Graph RAG(图RAG)
Graph RAG是RAG技术的语义深化版,通过引入知识图谱(KG),将分散的文本片段转化为“实体-关系”网络,实现“多跳推理”和“深层语义关联”。
- 核心流程:
① 知识图谱构建(用LLM从文档中提取实体(如“苹果公司”“iPhone”)和关系(如“生产”“CEO”),形成结构化网络);② 混合索引(对实体、关系分别进行向量编码,建立“向量索引”和“图索引”);③ 智能检索(同时进行向量相似性搜索和图遍历(挖掘多跳关系,如“库克管理的公司生产哪些产品”));④ LLM结合知识子图生成回答。 - 特点:
解决了传统RAG“文本孤立”的问题,能捕捉实体间的深层语义关系,支持复杂问题的分析(如“某行业产业链上下游企业关系”)。 - 应用场景:需要深度语义理解的场景(如金融风险分析、医疗疾病关联检索、法律案例匹配)。
三、智能演进分支:动态智能与多模态的突破
智能演进分支是RAG技术的“新叶”,通过智能体(Agent)(赋予系统自主决策能力)和多模态支持(处理文本、图像、表格等多种数据),实现了从“静态流程”到“动态智能”、从“文本中心”到“多模态融合”的跨越。
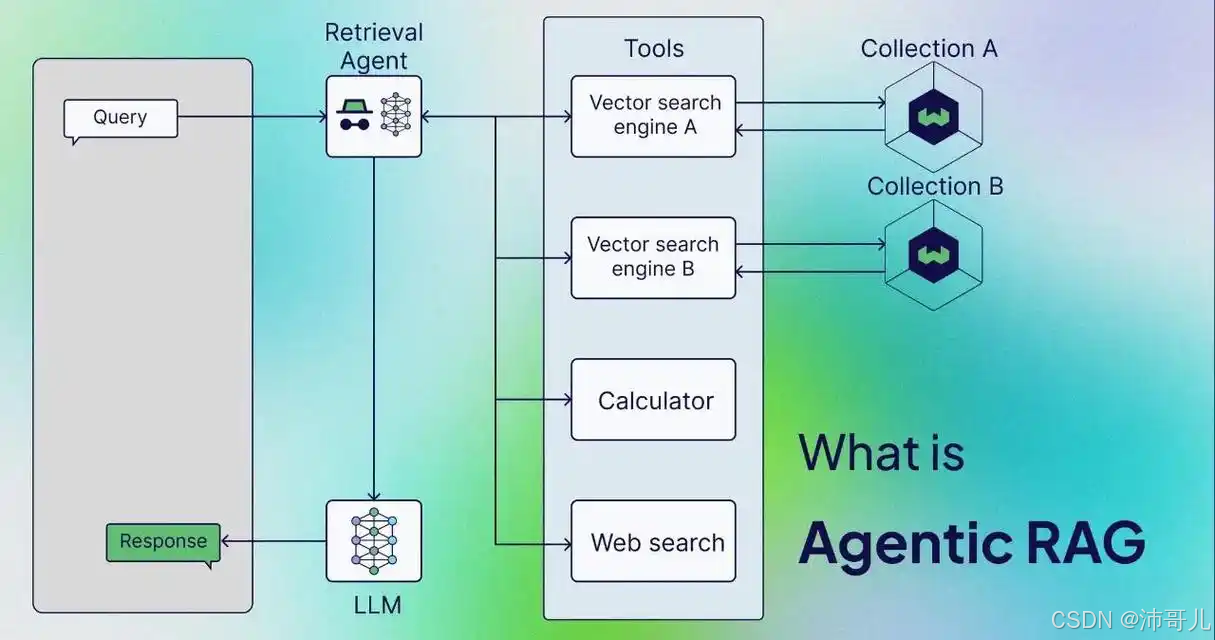
1. Agentic RAG(智能体RAG)
Agentic RAG是RAG技术的智能升级,以LLM智能体为“核心大脑”,替代传统的“固定流程”,具备自主决策、动态优化的能力。
- 核心创新:
- 任务分解:智能体将复杂查询拆解为多个子任务(如“撰写某行业竞争分析报告”拆解为“收集行业数据”“分析竞争对手”“生成报告结构”);
- 动态检索:根据子任务需求,自主选择检索策略(如调用实时API获取最新数据、检索本地知识库获取专业知识);
- 结果校验:生成回答后,通过评估智能体(如LLM-as-Judge)校验准确性、相关性,若不符合要求则重新检索或调整策略。
- 特点:
具备类人化的决策能力,能应对“多步骤、需要持续调整策略”的复杂任务(如撰写深度报告、解决跨领域问题)。 - 应用场景:需要复杂推理的场景(如战略咨询、科研辅助)。
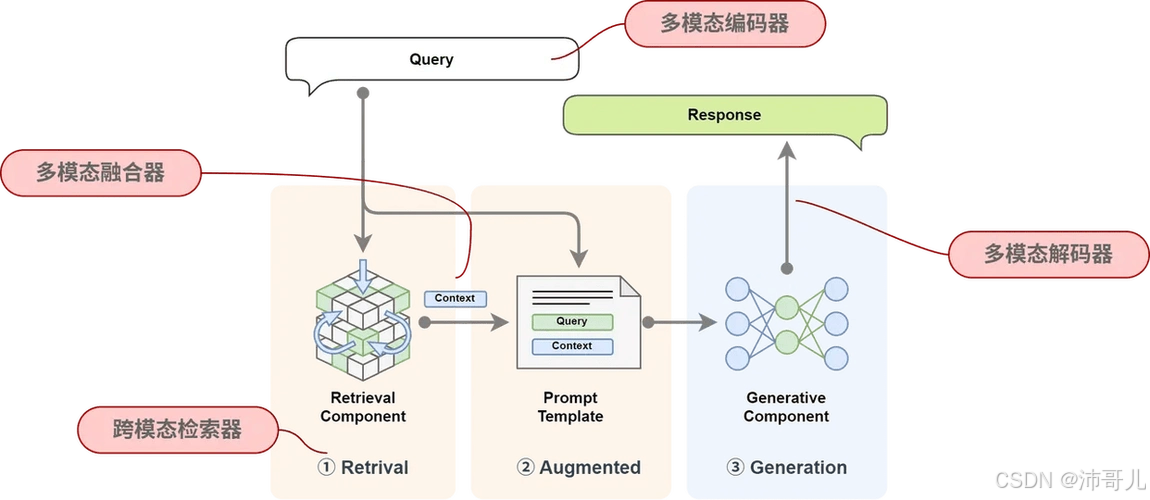
2. 多模态RAG(Multimodal RAG)
多模态RAG是RAG技术的数据类型扩展,支持文本、图像、表格、公式等多种模态的信息检索,解决了传统RAG“仅处理文本”的局限。
- 核心技术:
- 多模态嵌入:用多模态模型(如LLaVA、CLIP)将图像、表格等非文本数据转化为向量(如为图像生成字幕,再将字幕与文本一起嵌入);
- 统一检索:建立多模态向量索引,支持跨模态查询(如“找一张包含iPhone 15的图片,并提取其屏幕尺寸”)。
- 特点:
扩展了RAG的应用范围,能处理包含图像、表格等非文本内容的查询(如金融研报分析、医疗影像诊断)。 - 应用场景:多模态数据处理场景(如智能办公、数字媒体)。
四、前沿演进方向:轻量化与工程化
除了上述分支,RAG技术的演进还聚焦于轻量化(降低计算成本)和工程化(提升落地效率),主要包括:
1. LightRAG(轻量型RAG)
LightRAG是Graph RAG的轻量化优化,针对Graph RAG“构建成本高、维护难度大”的问题,通过局部更新机制(新增数据时仅需补充相关实体和关系,无需重建整个图谱)和双层协同检索(融合局部细节检索与全局主题检索),降低了图谱的维护成本,提升了响应速度。
- 应用场景:中小规模动态数据集场景(如医疗机构病例库、律所案例库)。
2. 工程化实践
随着RAG技术的普及,工程化实践成为关键,主要包括:
- 分块策略优化:通过A/B测试找到适合特定场景的分块策略(如语义分块、固定长度分块);
- 评估体系:建立RAG性能评估指标(如证据召回率、忠实度、端到端延迟),用RAGAS等工具进行量化评估;
- 可视化编排:通过腾讯云ADP3.0等工具实现RAG流程的可视化编排(如任务分解、工具调用、裁决),降低工程落地难度。
总结:RAG技术树的演进逻辑
RAG技术树的演进始终围绕“提升检索准确性、增强生成可靠性、扩展应用场景”的核心目标,从“基础架构”到“高级优化”,再到“智能演进”,逐步解决了传统RAG“检索简单、生成依赖、语义浅”的问题。未来,RAG技术将继续向“更智能(多智能体协同)、更轻量化(降低计算成本)、更融合(多模态支持)”的方向发展,成为大模型落地的核心技术之一。