Rust入门:运算符和数据类型应用
本文围绕 Rust 运算符与数据类型展开详细讲解,先介绍了算术、关系、逻辑、位运算、赋值与复合赋值及其他常见运算符,包括各自的功能、示例与使用细节,如乘方需用 pow 或 powf 方法,无 ** 运算符。接着阐述数据类型,涵盖整数型(按位长和有无符号分类,含特殊的 isize 与 usize)、浮点数型(f32 与 f64,默认 f64)、布尔型、字符型(4 字节,支持 Unicode),以及复合类型元组(可存不同类型数据)和数组(同类型数据,默认不可变)。还补充了数组安全访问(get 方法避免越界 panic)、切片使用、类型推断与标注、类型转换细节等内容,强调 Rust 注重代码安全的设计思路,建议通过实践巩固这些基础,为后续学习打牢根基。

一、Rust 运算符与数据类型详解
在 Rust 编程里,不管是简单的算个数、判断个真假,还是复杂点的模式匹配、位操作,运算符都扮演着核心角色。Rust 不仅支持咱们熟悉的 C 系语言里常见的运算符,还贴心地加了些独有的符号。要是能把这些运算符用熟,写代码时不仅能更简洁高效,还能帮你更透彻地搞懂 Rust 的语义逻辑。
1、算术运算符
算术运算符就是用来做加减乘除这些基础计算的,具体用法和效果咱们看下面这张表就清楚了:
| 运算符 | 说明 | 示例 | 结果 |
|---|---|---|---|
| + | 加法 | 5 + 2 | 7 |
| - | 减法 | 5 - 2 | 3 |
| * | 乘法 | 5 * 2 | 10 |
| / | 除法(整除) | 5 / 2 | 2 (整数) |
| % | 取余 | 5 % 2 | 1 |
咱们来写段代码实际试试:
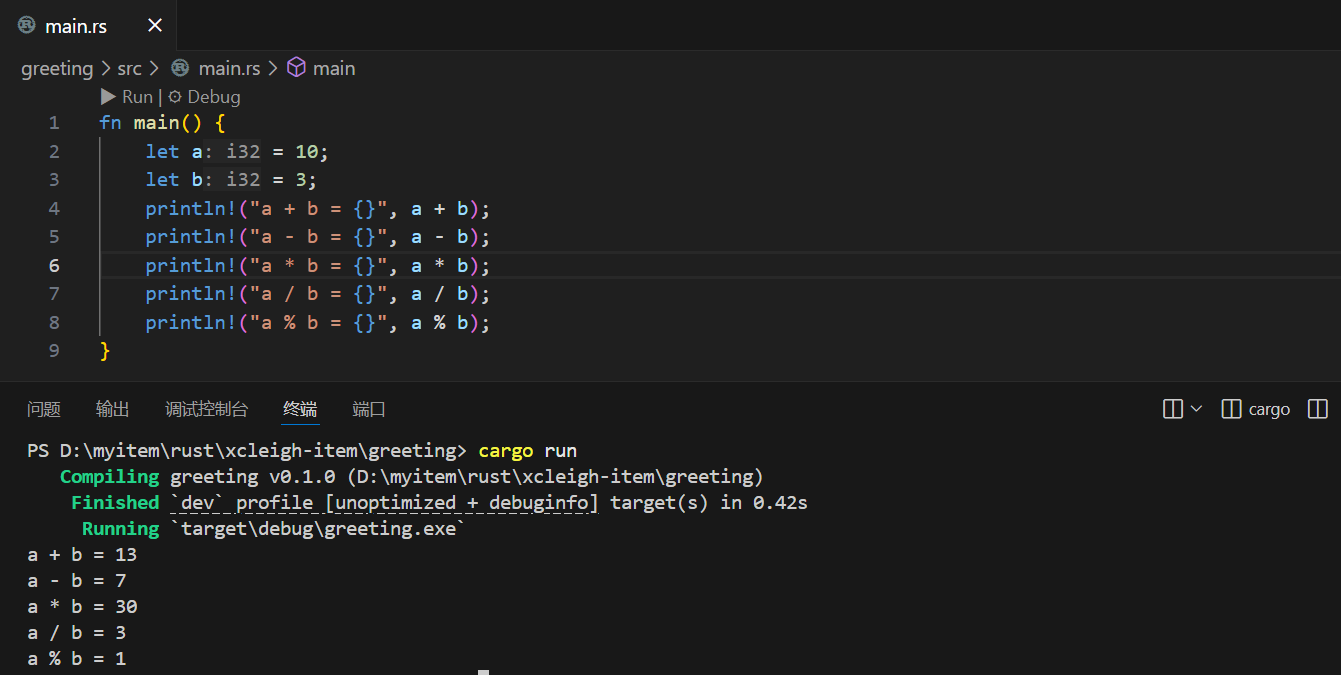
fn main() {let a = 10;let b = 3;println!("a + b = {}", a + b);println!("a - b = {}", a - b);println!("a * b = {}", a * b);println!("a / b = {}", a / b);println!("a % b = {}", a % b);
}
运行之后会输出这样的结果:
这里得提一句,Rust 里可没有 ** 或者 ^ 这种乘方运算符(别搞混了,^ 在 Rust 里是按位异或)。要是想算乘方,得用它内置的 pow 或者 powf 方法,不同类型的数字用法还不一样:
- 整数类型要用
.pow(exp: u32) - 浮点类型就得用
.powf(exp: f64)
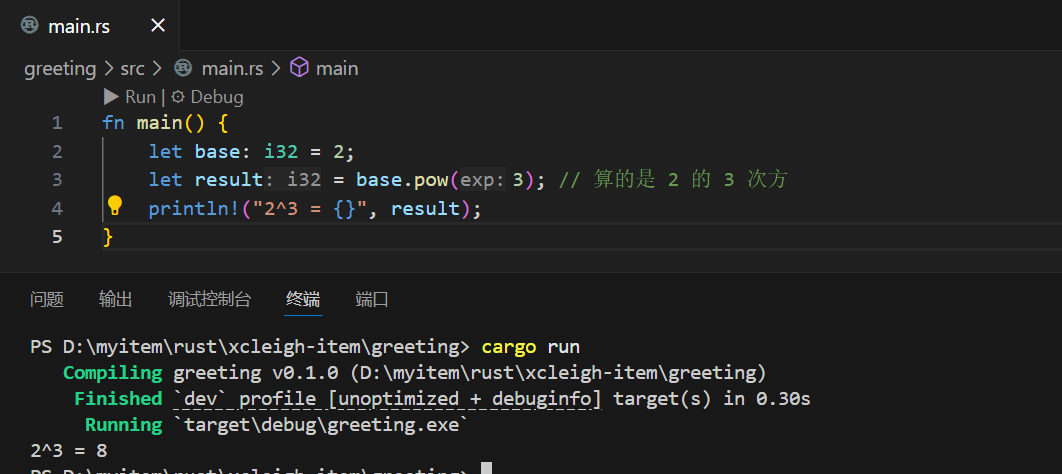
先看整数乘方的例子:
fn main() {let base: i32 = 2;let result = base.pow(3); // 算的是 2 的 3 次方println!("2^3 = {}", result);
}
输出结果很直观:
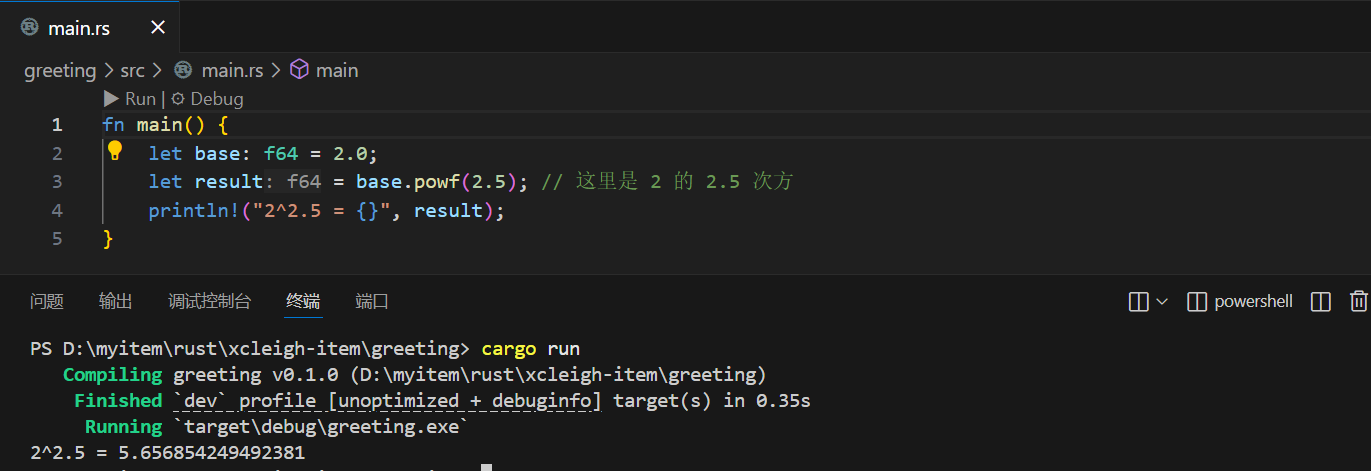
再试试浮点数乘方:
fn main() {let base: f64 = 2.0;let result = base.powf(2.5); // 这里是 2 的 2.5 次方println!("2^2.5 = {}", result);
}
运行后会得到这样的结果:
2、关系(比较)运算符
关系运算符主要用来比较两个值的关系,比如相等不相等、谁大谁小,结果都是布尔值,要么是 true,要么是 false。具体如下表:
| 运算符 | 说明 | 示例 | 结果 |
|---|---|---|---|
| == | 相等 | 5 == 5 | true |
| != | 不相等 | 5 != 2 | true |
| > | 大于 | 5 > 2 | true |
| < | 小于 | 5 < 2 | false |
| >= | 大于等于 | 5 >= 5 | true |
| <= | 小于等于 | 2 <= 5 | true |
咱们用代码实际验证下:
fn main() {let x = 5;let y = 10;println!("x == y : {}", x == y);println!("x != y : {}", x != y);println!("x > y : {}", x > y);println!("x < y : {}", x < y);println!("x >= y : {}", x >= y);println!("x <= y : {}", x <= y);
}
输出结果很容易理解:
x == y : false
x != y : true
x > y : false
x < y : true
x >= y : false
x <= y : true
3、逻辑运算符
逻辑运算符主要用于逻辑判断,经常和关系运算符一起用,来实现更复杂的条件判断。它也只有 true 和 false 两种结果,具体用法看下面:
| 运算符 | 说明 | 示例 | 结果 |
|---|---|---|---|
| && | 逻辑与(AND) | true && false | false |
| 逻辑或(OR) | |||
| ! | 逻辑非(NOT) | !true | false |
写段代码感受下:
fn main() {let a = true;let b = false;println!("a && b = {}", a && b);println!("a || b = {}", a || b);println!("!a = {}", !a);
}
运行后输出:
a && b = false
a || b = true
!a = false
4、位运算符
位运算符是直接对二进制位进行操作的,咱们平时处理底层数据或者做一些高效计算时可能会用到。具体如下表:
| 运算符 | 说明 | 示例 | 结果 |
|---|---|---|---|
| & | 按位与 | 5 & 3 | 1 |
| 按位或 | `5 | ||
| ^ | 按位异或 | 5 ^ 3 | 6 |
| ! | 按位取反 | !5 | -6 |
| << | 左移 | 5 << 1 | 10 |
| >> | 右移 | 5 >> 1 | 2 |
咱们用二进制的方式来看看实际效果,代码里用了 u8 类型,还标注了二进制值:
fn main() {let x: u8 = 0b1010; // 对应的十进制是 10let y: u8 = 0b1100; // 对应的十进制是 12println!("x & y = {:b}", x & y);println!("x | y = {:b}", x | y);println!("x ^ y = {:b}", x ^ y);println!("!x = {:b}", !x);println!("x << 1 = {:b}", x << 1);println!("x >> 1 = {:b}", x >> 1);
}
输出结果都是二进制形式,能清楚看到位运算的过程:
x & y = 1000
x | y = 1110
x ^ y = 110
!x = 11110101
x << 1 = 10100
x >> 1 = 101
5、赋值与复合赋值运算符
赋值运算符就是给变量赋值,复合赋值运算符则是把运算和赋值合在一起,写代码时能更简洁。具体如下:
| 运算符 | 说明 | 示例 | 结果 |
|---|---|---|---|
| = | 赋值 | let mut x = 5; x = 3; | x = 3 |
| += | 加并赋值 | x += 2 | x = x + 2 |
| -= | 减并赋值 | x -= 2 | x = x - 2 |
| *= | 乘并赋值 | x *= 2 | x = x * 2 |
| /= | 除并赋值 | x /= 2 | x = x / 2 |
| %= | 取余并赋值 | x %= 2 | x = x % 2 |
| &= | = ^= <<= >>= | 位运算复合赋值 | x &= 2 |
咱们用代码实际操作下:
fn main() {let mut n = 5;n += 3;println!("n += 3 -> {}", n);n *= 2;println!("n *= 2 -> {}", n);n >>= 1;println!("n >>= 1 -> {}", n);
}
输出结果能清晰看到变量 n 的变化过程:
n += 3 -> 8
n *= 2 -> 16
n >>= 1 -> 8
6、其他常见运算符
除了上面几类,Rust 里还有些常用的运算符,在不同场景下能帮咱们简化代码,具体如下:
| 运算符 | 说明 | 示例 |
|---|---|---|
| … | 范围(不含右端) | 0…5 产生 0 到 4 这些数 |
| …= | 范围(含右端) | 0…=5 产生 0 到 5 这些数 |
| as | 类型转换 | 5 as f32 把整数 5 转成浮点数 5.0 |
| ? | 错误传播(在 Result 中) | some()?; 处理可能出现的错误 |
| * | 解引用 | *ptr 获取指针指向的值 |
| & | 取引用 | &x 得到变量 x 的引用 |
| ref | 绑定为引用 | let ref y = x; 把 y 绑定为 x 的引用 |
来段代码实际用用这些运算符:
fn main() {let x = 5;let y = x as f64; // 把整数 x 转成 f64 类型的 y// 用 .. 遍历 1 到 3(不含 4)for i in 1..4 {print!("{} ", i);}println!();// 用 ..= 遍历 1 到 3(含 3)for i in 1..=3 {print!("{} ", i);}println!();let a = 10;let b = &a; // 取 a 的引用赋值给 bprintln!("*b = {}", *b); // 解引用 b,获取它指向的 a 的值
}
输出结果如下:
1 2 3
1 2 3
*b = 10
二、Rust 数据类型
了解完运算符,咱们再来看看 Rust 里的基础数据类型,这可是写代码的基础,得搞明白它们各自的特点和用法。
1、整数型(Integer)
整数型简称整型,它根据比特位长度和有没有符号,分成了好几种类型,具体如下表:
| 位长度 | 有符号 | 无符号 |
|---|---|---|
| 8-bit | i8 | u8 |
| 16-bit | i16 | u16 |
| 32-bit | i32 | u32 |
| 64-bit | i64 | u64 |
| 128-bit | i128 | u128 |
| arch | isize | usize |
这里面 isize 和 usize 这两种类型比较特殊,它们是用来衡量数据大小的,比特位长度取决于运行的目标平台。比如在 32 位架构的处理器上,它们就是 32 位的整型;到了 64 位架构的处理器,就变成 64 位的了。
而且整数还有好几种表述方法,方便咱们根据不同场景选择:
| 进制 | 例子 |
|---|---|
| 十进制 | 98_222 |
| 十六进制 | 0xff |
| 八进制 | 0o77 |
| 二进制 | 0b1111_0000 |
| 字节(只能表示 u8 型) | b’A’ |
细心的话你会发现,有的整数中间加了下划线,比如 98_222、0b1111_0000,这么设计其实是为了让咱们输入大数字时,能更容易看清数字的大小,比如 1_000_000 一眼就能看出来是一百万,比 1000000 方便多了。
2、浮点数型(Floating-Point)
和很多其他编程语言一样,Rust 也支持两种浮点数类型:32 位浮点数(f32)和 64 位浮点数(f64)。默认情况下,像 64.0 这样写的浮点数,会被当成 64 位浮点数(f64)。为啥默认是 64 位呢?因为现在的计算机处理器,计算这两种浮点数的速度差不多,但 64 位浮点数的精度更高,用着更顺手。
咱们来定义两个浮点数看看:
fn main() {let x = 2.0; // 没指定类型,默认是 f64let y: f32 = 3.0; // 明确指定成 f32 类型
}
浮点数也能进行各种数学运算,和整数运算差不多:
fn main() {let sum = 5 + 10; // 加法let difference = 95.5 - 4.3; // 减法let product = 4 * 30; // 乘法let quotient = 56.7 / 32.2; // 除法let remainder = 43 % 5; // 求余
}
之前咱们在复合赋值运算符里提到过,很多运算符后面加个 = 号,就能实现自运算,比如 sum += 1 就相当于 sum = sum + 1,用起来很方便。不过这里要注意,Rust 里可没有 ++ 和 – 这两个运算符。为啥呢?因为这两个运算符放在变量前后,很容易让代码可读性变低,还会让开发者不容易注意到变量的变化,所以 Rust 干脆就不支持了。
3、布尔型
布尔型在 Rust 里用 bool 表示,它特别简单,只有两个值:true(真)和 false(假)。平时做条件判断,比如 if 语句里的条件,用的就是布尔型。
4、字符型
字符型用 char 表示,和很多语言不一样的是,Rust 里的 char 类型大小是 4 个字节,它代表的是 Unicode 标量值。这就意味着它的功能很强,不仅能表示英文字母,像中文、日文、韩文这些非英文字符,甚至表情符号、零宽度空格,在 Rust 里都能当成有效的 char 值。
不过有个范围要注意,Unicode 值的范围是从 U+0000 到 U+D7FF,还有 U+E000 到 U+10FFFF(包括两端的数值)。另外得提醒一句,“字符”这个概念在 Unicode 里其实并不存在,所以你平时理解的“字符”,和 Rust 里 char 代表的概念可能不太一样。所以一般更推荐用字符串来存储 UTF-8 文字,尤其是非英文字符,放在字符串里会更合适。
这里还有个小坑要注意,中文文字编码有 GBK 和 UTF-8 两种,要是编程时用中文字符串,很可能会出现乱码。这一般是因为源程序和命令行的文字编码不一样导致的。所以在 Rust 里,字符串和字符都必须用 UTF-8 编码,不然编译器会报错,这点一定要记住。
5、复合类型
前面说的都是简单类型,Rust 里还有复合类型,能把多个值组合在一起用,常用的有元组和数组。
—元组
元组是用一对小括号 ( ) 把一组数据括起来,里面的数据可以是不同类型的。比如这样定义一个元组:
let tup: (i32, f64, u8) = (500, 6.4, 1);
要是想访问元组里的元素,就用“元组名.索引”的方式,索引从 0 开始。比如:
- tup.0 对应的就是 500
- tup.1 对应的就是 6.4
- tup.2 对应的就是 1
另外,还能通过模式匹配的方式,把元组里的值分别赋给变量,比如:
let (x, y, z) = tup;
这样一来,x 就等于 500,y 等于 6.4,z 等于 1,用起来很灵活。
—数组
和元组不一样,数组是用一对中括号 [ ] 括起来的,而且里面的元素必须是同一种类型。比如:
let a = [1, 2, 3, 4, 5];
// 这里 a 就是一个长度为 5 的整型数组
let b = ["January", "February", "March"];
// 这里 b 是一个长度为 3 的字符串数组
也可以在定义的时候,明确指定数组的类型和长度,像这样:
let c: [i32; 5] = [1, 2, 3, 4, 5];
// 意思就是 c 是一个长度为 5、元素类型为 i32 的数组
还有一种更简洁的定义方式,要是数组里的元素都一样,就可以写成“[元素值; 长度]”,比如:
let d = [3; 5];
// 这就等同于 let d = [3, 3, 3, 3, 3]; ,特别方便
访问数组元素的方式和元组类似,也是用“数组名.索引”:
let first = a[0]; // 取 a 数组里索引为 0 的元素,也就是 1
let second = a[1]; // 取 a 数组里索引为 1 的元素,也就是 2
不过要注意,数组默认是不可变的,要是想修改数组里的元素,得在定义的时候加个 mut 关键字,比如:
a[0] = 123; // 错误:数组 a 没加 mut,是不可变的,不能修改
let mut a = [1, 2, 3];
a[0] = 4; // 正确:加了 mut,数组变成可变的了,可以修改元素
6、数组的安全访问与切片
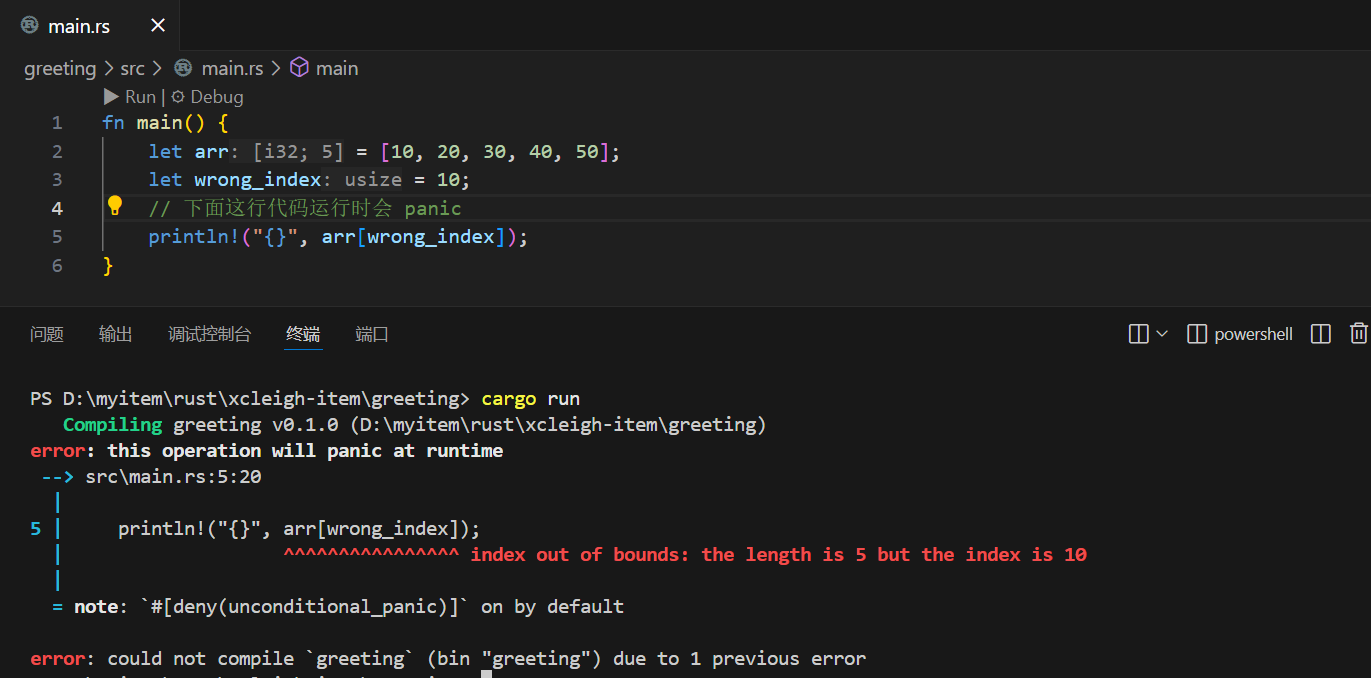
聊到数组,有个特别重要的点得跟你强调——数组的访问安全。咱们之前说过,用 数组名[索引] 能取到对应元素,但你知道吗?如果不小心用了超出数组长度的索引,比如给一个长度为 5 的数组用索引 10,Rust 可不会像有些语言那样悄悄返回个奇怪的值,而是会直接在运行时 panic(崩溃)。
举个例子看看:
fn main() {let arr = [10, 20, 30, 40, 50];let wrong_index = 10;// 下面这行代码运行时会 panicprintln!("{}", arr[wrong_index]);
}
运行后会看到类似这样的错误提示,明确告诉你索引越界了,还会标出数组长度和你用的错误索引,帮你快速定位问题。这种设计虽然看起来“严格”,但能帮咱们提前规避很多隐藏的bug,毕竟数组越界可是很多程序出问题的根源。
那有没有更安全的访问方式呢?当然有!Rust 给数组提供了 get 方法,它返回一个 Option 类型——如果索引合法,就返回 Some(元素值);如果索引越界,就返回 None,不会让程序崩溃。咱们可以用 if let 或者 match 来处理这个结果,比如:
fn main() {let arr = [10, 20, 30, 40, 50];let index = 3;// 用 if let 处理 get 方法的返回值if let Some(value) = arr.get(index) {println!("数组索引 {} 对应的元素是:{}", index, value);} else {println!("索引 {} 超出数组长度啦!", index);}let wrong_index = 10;match arr.get(wrong_index) {Some(value) => println!("数组索引 {} 对应的元素是:{}", wrong_index, value),None => println!("索引 {} 超出数组长度啦!", wrong_index),}
}
运行这段代码,不会出现 panic,而是会友好地提示索引越界的问题,输出结果是:
数组索引 3 对应的元素是:40
索引 10 超出数组长度啦!
除了直接访问数组元素,咱们还经常需要处理数组的一部分,这时候就会用到“切片”(Slice)。切片不是新的数组,而是对原数组某一段的引用,它能帮咱们更灵活地操作数组的部分数据,还不用复制额外的内存。
切片的语法是 &数组名[起始索引..结束索引],注意这里的“结束索引”是不含的,就像之前讲的范围运算符 .. 一样。比如想取数组 [10,20,30,40,50] 里从索引 1 到 3 的元素(也就是 20、30),就可以写成 &arr[1..3]。
咱们用代码试试:
fn main() {let arr = [10, 20, 30, 40, 50];// 取索引 1 到 3 的切片(不含 3),对应元素 20、30let slice1 = &arr[1..3];println!("切片 slice1 的元素:");for val in slice1 {print!("{} ", val);}println!();// 起始索引可以省略,默认从 0 开始,相当于 &arr[0..4]let slice2 = &arr[..4];println!("切片 slice2 的元素:");for val in slice2 {print!("{} ", val);}println!();// 结束索引也可以省略,默认到数组末尾,相当于 &arr[2..5]let slice3 = &arr[2..];println!("切片 slice3 的元素:");for val in slice3 {print!("{} ", val);}println!();// 起始和结束索引都省略,就是整个数组的切片,相当于 &arr[0..5]let slice4 = &arr[..];println!("切片 slice4 的元素:");for val in slice4 {print!("{} ", val);}
}
运行后输出结果:
切片 slice1 的元素:
20 30
切片 slice2 的元素:
10 20 30 40
切片 slice3 的元素:
30 40 50
切片 slice4 的元素:
10 20 30 40 50
切片还有个特点,它会“借用”原数组的所有权——如果切片是不可变的(像上面例子里那样),原数组也不能被修改;如果想创建可变切片,得先把原数组定义成可变的(加 mut),然后切片也要用 &mut 修饰,比如:
fn main() {let mut arr = [10, 20, 30, 40, 50];// 创建可变切片let mut slice = &mut arr[1..4];// 修改切片里的元素,原数组也会跟着变slice[0] = 200;slice[2] = 400;println!("修改后的切片元素:");for val in slice {print!("{} ", val);}println!();println!("修改后的原数组元素:");for val in arr {print!("{} ", val);}
}
输出结果能看到,切片和原数组的元素都被修改了:
修改后的切片元素:
200 30 400
修改后的原数组元素:
10 200 30 400 50
7、数据类型的类型推断与标注
聊到 Rust 的数据类型,还有个特别贴心的功能得提——类型推断。很多时候,咱们不用特意给变量标注类型,Rust 能根据变量的赋值和使用场景,自动推断出它的类型,这样写代码能省不少事。
比如之前写过的代码:
fn main() {let a = 10; // Rust 会推断 a 是 i32 类型(默认的整数类型)let b = 3.14; // Rust 会推断 b 是 f64 类型(默认的浮点数类型)let c = true; // Rust 会推断 c 是 bool 类型let d = 'A'; // Rust 会推断 d 是 char 类型
}
这里没给任何变量标注类型,但 Rust 能准确判断出它们的类型,运行起来完全没问题。
不过有时候,Rust 没办法单独通过赋值推断类型,比如当变量赋值是 0 或者 1 这种,既可能是整数,也可能是其他类型的时候,就需要咱们手动标注类型了。
举个例子,比如想定义一个 u8 类型的变量 num,如果只写 let num = 255;,Rust 会默认推断成 i32 类型;如果想让它是 u8,就得明确标注:
fn main() {// 手动标注 num 是 u8 类型let num: u8 = 255;println!("num 的类型是 u8,值是:{}", num);// 再比如,想让浮点数是 f32 类型,也得标注let pi: f32 = 3.14159;println!("pi 的类型是 f32,值是:{}", pi);
}
还有一种情况,当函数的参数或返回值类型不明确时,也需要手动标注。比如写一个加法函数,如果不给参数和返回值标注类型,Rust 就不知道该用哪种整数或浮点数类型,会报错:
// 错误:必须给参数和返回值标注类型
// fn add(x, y) {
// x + y
// }// 正确:标注 x 和 y 是 i32 类型,返回值也是 i32 类型
fn add(x: i32, y: i32) -> i32 {x + y
}fn main() {let result = add(10, 20);println!("10 + 20 = {}", result);
}
运行这段代码,就能正常输出 10 + 20 = 30。
类型标注不仅能帮 Rust 明确变量或函数的类型,还能让代码更易读——别人看代码时,不用费劲推断类型,直接就能知道变量是什么类型,函数接收什么参数、返回什么值。所以在关键的地方手动标注类型,是个好习惯。
8、数据类型的转换细节
之前咱们提到过用 as 关键字做类型转换,比如把整数转成浮点数 5 as f32,但类型转换里还有些细节得注意,不然很容易出问题。
首先,不同大小的整数之间转换时,要注意值是否超出目标类型的范围。比如把 i32 类型的 1000 转成 u8 类型,u8 的范围是 0-255,1000 超出了这个范围,转换后的值会“溢出”,变成一个意想不到的结果:
fn main() {let big_num: i32 = 1000;// 把 i32 类型的 1000 转成 u8 类型,会溢出let small_num: u8 = big_num as u8;println!("1000 转成 u8 后的结果:{}", small_num);
}
运行后输出 1000 转成 u8 后的结果:232,这是因为 1000 除以 256(u8 的取值范围大小)的余数是 232,所以就得到了这个结果。这种溢出在 Rust 里不会报错,而是直接截断,所以转换的时候一定要确认值在目标类型的范围内。
然后,浮点数转成整数时,会直接“截断”小数部分,而不是四舍五入。比如把 3.9 转成整数,会变成 3,而不是 4;把 5.1 转成整数,会变成 5:
fn main() {let float1: f64 = 3.9;let int1: i32 = float1 as i32;println!("3.9 转成 i32 后的结果:{}", int1); // 输出 3let float2: f64 = 5.1;let int2: i32 = float2 as i32;println!("5.1 转成 i32 后的结果:{}", int2); // 输出 5
}
如果想实现四舍五入的效果,就得用 Rust 标准库提供的方法,比如 round 方法:
fn main() {let float: f64 = 3.9;// 先调用 round 方法四舍五入,再转成 i32 类型let int: i32 = float.round() as i32;println!("3.9 四舍五入后转成 i32 的结果:{}", int); // 输出 4
}
另外,布尔类型和其他类型之间不能直接用 as 转换。比如不能把 true 转成 1,也不能把 0 转成 false,这样写会报错:
fn main() {let b = true;// 错误:布尔类型不能直接转成整数// let num = b as i32;let num = 0;// 错误:整数不能直接转成布尔类型// let b = num as bool;
}
如果想把布尔类型转成整数,可以用 if-else 判断:
fn main() {let b = true;let num = if b { 1 } else { 0 };println!("true 转成整数:{}", num); // 输出 1let num2 = 0;let b2 = num2 != 0;println!("0 转成布尔类型:{}", b2); // 输出 false
}
最后要记住,Rust 不支持自动类型转换(隐式转换),比如不能把 i32 类型的变量直接和 f64 类型的变量做运算,必须手动用 as 转成相同类型才能运算:
fn main() {let int_num: i32 = 10;let float_num: f64 = 3.5;// 错误:不同类型不能直接运算// let result = int_num + float_num;// 正确:把 int_num 转成 f64 类型,再和 float_num 相加let result = (int_num as f64) + float_num;println!("10 + 3.5 = {}", result); // 输出 13.5
}
这种“必须手动转换”的设计,虽然多写了点代码,但能避免很多因为隐式转换带来的意外错误,让代码更安全、更可控。
三、总结
到这里,咱们关于 Rust 运算符与数据类型的核心内容就梳理得差不多了。回顾下来,这两部分其实是 Rust 编程的“地基”——运算符帮咱们实现数据的计算、判断和操作逻辑,从简单的加减乘除到复杂的位运算、错误传播,每一种都有它特定的使用场景,尤其是 Rust 独有的范围运算符 ../..=、解引用 * 这些,用熟了能让代码又简洁又地道;而数据类型则决定了数据的“形态”和“能力”,不管是区分有符号/无符号的整型、精度不同的浮点数,还是支持多类型组合的元组、同类型聚合的数组,理解它们的特性(比如数组的不可变性、char 的 Unicode 支持)和安全规则(比如数组越界会 panic、类型转换需手动),才能避免踩坑。
特别要提的是 Rust 的设计思路——它不追求“写得快”,而是更看重“写得对”。比如数组越界时直接 panic 而非隐藏错误,不支持隐式类型转换、++/-- 运算符,都是为了减少开发者的“思维漏洞”;而类型推断又在严格性和便捷性之间做了平衡,让咱们不用写冗余的类型标注。这些细节看似“麻烦”,但正是它们让 Rust 写出的代码更安全、更易维护。
当然,光看懂还不够,建议你多动手试试——比如用不同的运算符组合实现一个简单的计算器,或者用数组和切片处理一组数据,在实践中感受运算符的优先级、数据类型的转换规则。等这些基础真正扎牢了,后续学习函数、结构体、所有权这些更复杂的概念时,就能更轻松地跟上节奏。 Rust 入门可能需要多花点功夫,但每一次对细节的掌握,都是在为写出更可靠的代码铺路~