AI 十大论文精讲(三):RLHF 范式奠基 ——InstructGPT 如何让大模型 “听懂人话”
系列文章前言
在人工智能技术从理论突破走向工程落地的进程中,一篇篇里程碑式的论文如同灯塔,照亮了技术演进的关键路径。为帮助大家吃透 AI 核心技术的底层逻辑、理清行业发展脉络,博主推出「AI 十大核心论文解读系列」,每篇聚焦一篇关键论文的问题背景、核心创新与行业影响。本篇博客解读AI领域十大论文的第二篇——《Training Language Models to Follow Instructions with Human Feedback》论文。
文章目录
- 系列文章前言
- 前言
- 一、研究背景与核心问题
- 二、论文深度解读
- 1、核心方法:RLHF三步对齐法
- 2、关键实验结果与核心发现
- 3、研究局限与后续进展
- 4、研究意义与行业影响
- 总结
前言
2022 年,OpenAI 发表的《Training Language Models to Follow Instructions with Human Feedback》堪称大模型从 “能做事” 走向 “会做事” 的分水岭 —— 在此之前,即便像 GPT-3 这样参数规模达 175B 的 “巨无霸” 模型,也常因 “捏造事实、偏离指令、生成有害内容” 让用户头疼;这篇论文首次用 “人类反馈强化学习(RLHF)” 构建了一套可复现的技术框架,让模型真正对齐 “听懂指令、诚实输出” 的人类需求。本篇博客会给予论文详细拆解 RLHF 的技术细节、实验设计与学术逻辑,满足研究者与开发者对技术原理的需求。
一、研究背景与核心问题
大型语言模型(LMs)的预训练目标多为“预测互联网文本的下一个token”,这与用户核心需求“安全、诚实地遵循指令”存在本质错位。论文指出,即使是175B参数的GPT-3,也常出现捏造事实、生成有毒内容或偏离指令的行为。该研究的核心目标是通过“人类反馈强化学习(RLHF)”技术,实现模型与人类意图的对齐,定义对齐的三大标准:helpful(辅助用户完成任务)、honest(不编造信息)、harmless(不造成物理/心理/社会伤害)。
二、论文深度解读
1、核心方法:RLHF三步对齐法
论文提出的RLHF(Reinforcement Learning from Human Feedback)框架包含三个关键步骤,形成闭环优化:
- 有监督微调(SFT):收集13k条包含人类示范的prompt数据(含OpenAI API用户提交和标签员编写的prompt),对GPT-3进行有监督训练,让模型学习“符合人类期望的输出模式”。标签员需通过筛选测试(评估敏感内容识别能力和标注一致性),确保示范数据质量,训练采用余弦学习率衰减和0.2的残差dropout,迭代16个epoch。
- 奖励模型训练(RM):收集33k条prompt对应的模型输出排名数据(标签员对4-9个模型输出按偏好排序),基于对比学习训练6B参数的奖励模型。损失函数采用交叉熵损失,优化目标为预测人类偏好的输出对,即最大化
σ(rθ(x,yw) - rθ(x,yl))(yw为偏好输出,yl为非偏好输出),训练时将同一prompt的所有输出对作为单个batch元素,避免过拟合。 - 强化学习优化(PPO):以SFT模型为初始化,利用PPO算法最大化奖励模型的得分,同时引入KL惩罚(控制与SFT模型的输出差异)避免过度优化。为缓解“对齐税”(alignment tax,即对齐后公共NLP任务性能退化),提出PPO-ptx变体,在优化中融入预训练数据的梯度更新,目标函数为
objective(φ) = E[rθ(x,y) - βlog(πφ^RL/π^SFT)] + γE[logπφ^RL(x)]。
从通俗易懂的角度来讲,这三个流程可以类比于“教模型学做事”的完整流程
- 第一步:跟着老师学示范:找40个专业“人类老师”,让他们针对各种需求(写故事、改文案、答问题)做正确示范,比如用户问“怎么重拾工作热情”,老师就给出5个靠谱想法。模型像学生一样,照着13000多个示范案例反复学,先摸清“正确做法”的门道。
- 第二步:学会给作业评好坏:让老师给模型的“作业”打分——同一个问题让模型输出4-9个答案,老师排个名次(最好到最差)。模型从这些排名里学规律:比如“实事求是”的答案排前面,“胡编乱造”的排后面,慢慢练就“自我评判”的能力。
- 第三步:反复练习拿高分:让模型不断做题(处理新prompt),每次输出后对照自己的“评判标准”(奖励模型)改答案,争取拿更高分。同时还要注意:不能为了拿高分就忘了自己原来的知识(KL惩罚),也不能因为学了新技能就搞砸老任务(比如做阅读理解),所以还要偶尔复习“课本”(预训练数据),避免偏科。
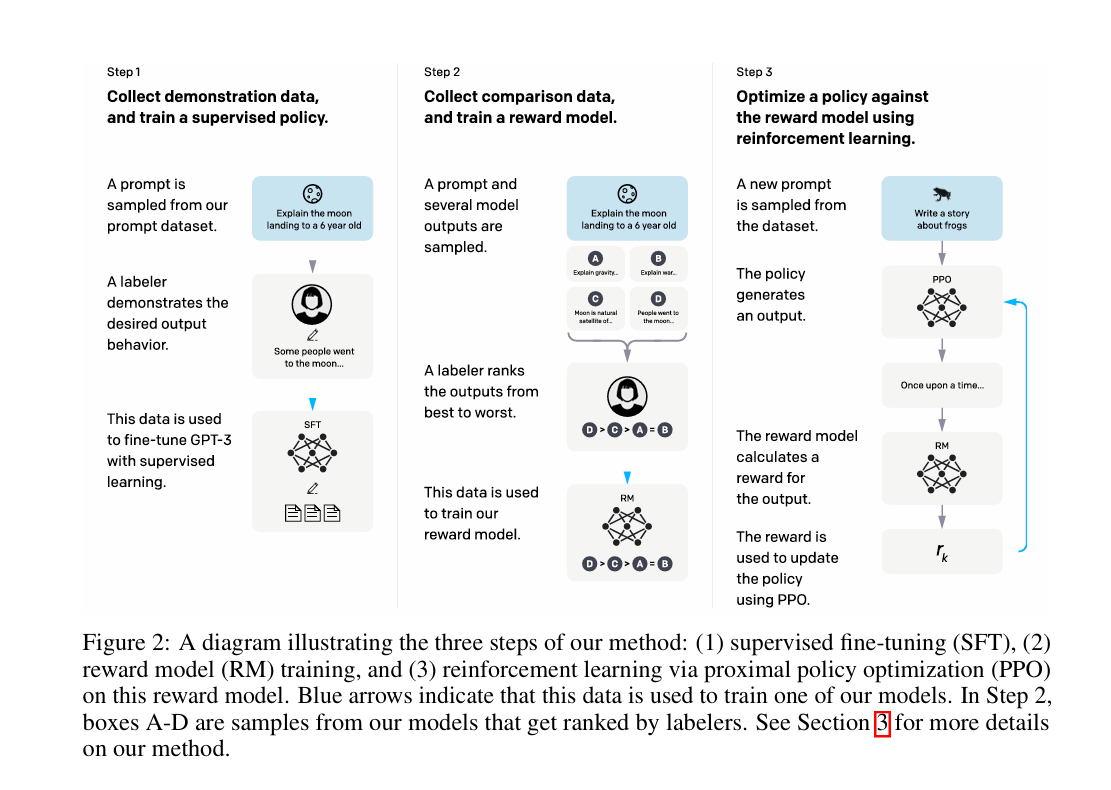
图 2:展示我们方法三个步骤的示意图:(1)监督微调(SFT)、(2)奖励模型(RM)训练、(3)基于该奖励模型的近端策略优化(PPO)强化学习。蓝色箭头表示该数据用于训练我们的某个模型。步骤 2 中,方框 A-D 是来自我们模型的样本,标注人员会对这些样本进行排序。关于我们方法的更多细节,请参见第 3 节。
2、关键实验结果与核心发现
-
模型偏好性优势:在人类评估中,1.3B参数的InstructGPT(PPO-ptx)输出被偏好的概率高于175B GPT-3,175B InstructGPT对175B GPT-3的胜率达85±3%,对少量提示(few-shot)的GPT-3胜率达71±4%,验证了“小规模对齐模型优于大规模未对齐模型”的核心假设。
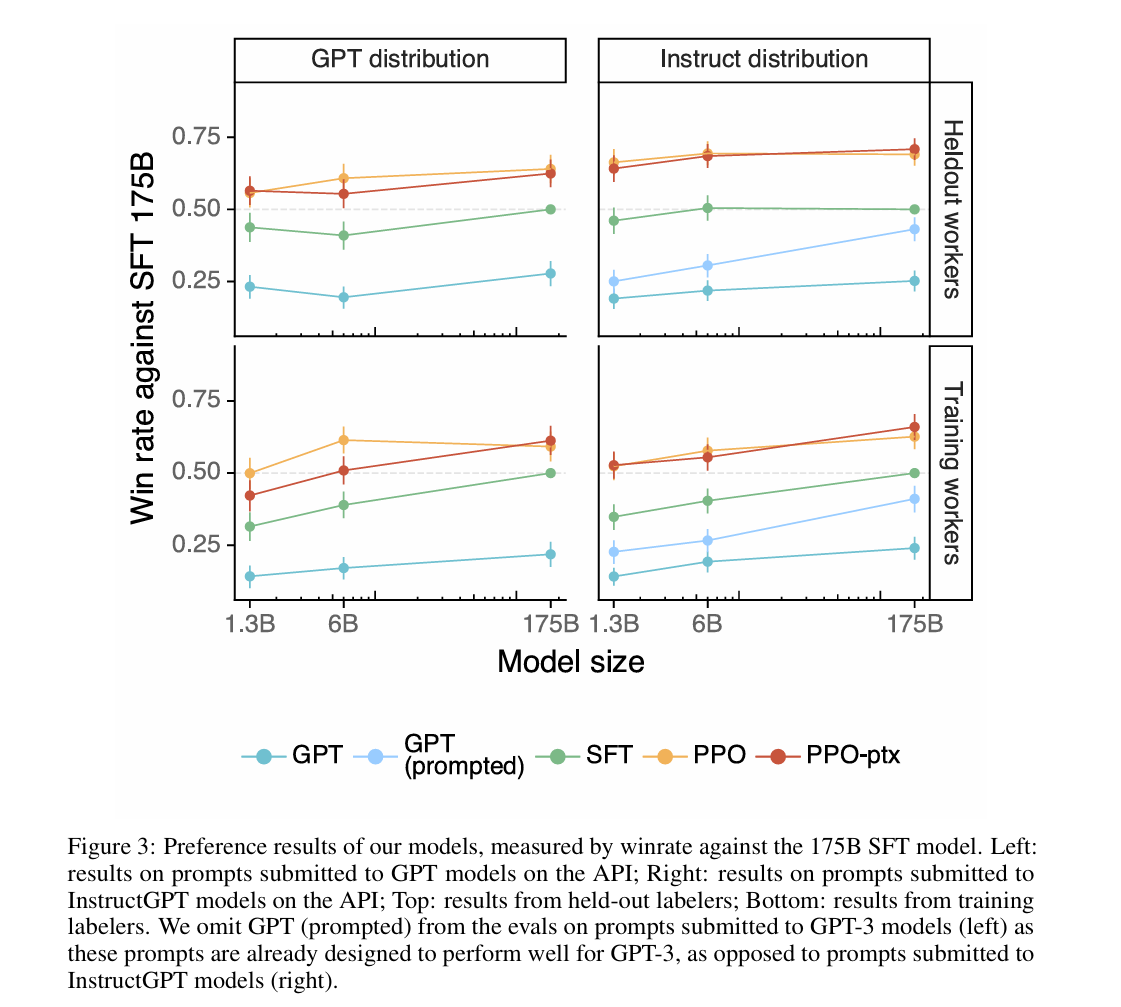
图 3:我们模型的偏好结果,以相对于 1750 亿参数 SFT 模型的胜率衡量。左图:提交至 API 上 GPT 模型的提示词的结果;右图:提交至 API 上 InstructGPT 模型的提示词的结果;上图:预留标注人员的结果;下图:训练标注人员的结果。在针对提交至 GPT-3 模型的提示词的评估中(左图),我们省略了 GPT(带提示词的),因为这些提示词原本就被设计为在 GPT-3 上表现良好,这与提交至 InstructGPT 模型的提示词(右图)不同。 -
对齐指标提升:在TruthfulQA基准中,InstructGPT生成真实且有信息量答案的概率是GPT-3的两倍;封闭域任务(如摘要、闭卷问答)中,幻觉率从GPT-3的41%降至21%;在RealToxicityPrompts数据集上,受“尊重指令”提示时,有毒输出减少25%。换句话说,就是模型变老实、变文明了:以前GPT-3爱编瞎话(比如没依据的事实),现在InstructGPT说真话的概率翻倍;以前可能冒出脏话,现在受提醒后脏话少了四分之一;写摘要时乱加信息的情况也少了一半。
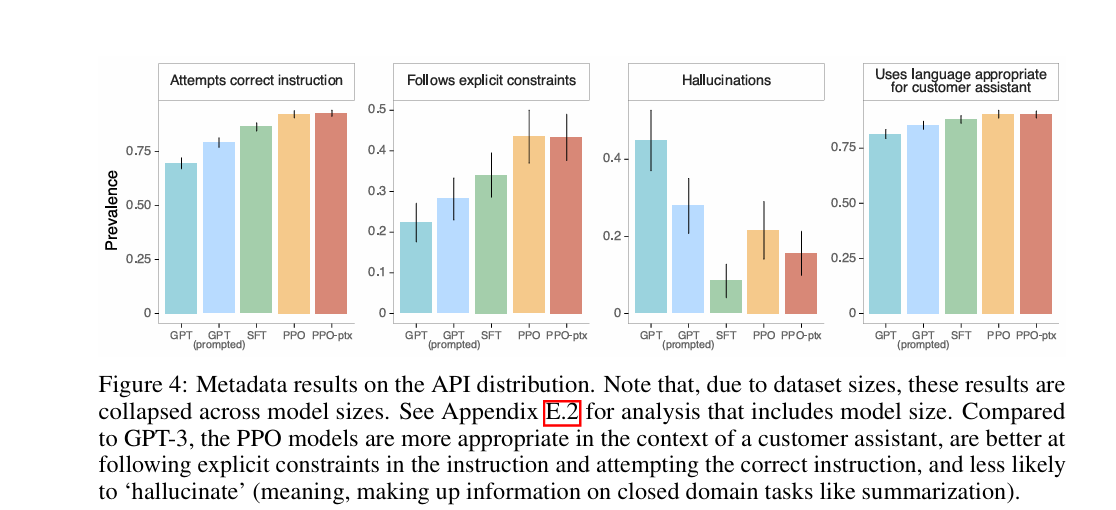
图 4:API 分布上的元数据结果。注意,由于数据集大小的原因,这些结果是跨模型大小合并的。有关包含模型大小的分析,请参见附录 E.2。与 GPT-3 相比,PPO 模型在客户助手场景中更合适,更擅长遵循指令中的明确约束并尝试执行正确的指令,且更少出现 “幻觉”(即,在总结等封闭域任务中编造信息)。
- 性能退化缓解:PPO-ptx模型通过融入预训练梯度,在SQuAD、DROP、HellaSwag等公共NLP数据集上的性能退化显著缓解,部分任务(如HellaSwag)甚至超过GPT-3。性能退化可以理解为遗忘自己的预训练数据,用通俗易懂的话来说就是,刚开始优化后,模型可能在做阅读理解、翻译等老任务时表现变差(就像学了新技能忘了老本事),但后来加了“复习课本”的步骤,不仅没忘老本事,有些任务还比以前做得好。
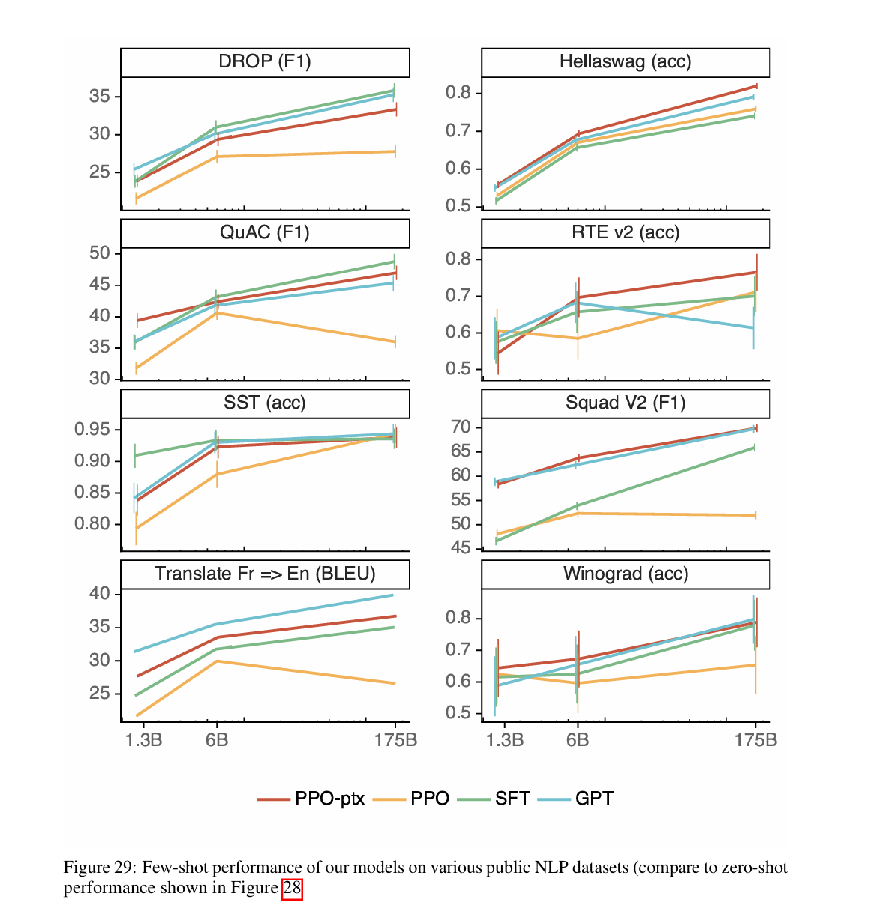
图 29:我们的模型在各种公开自然语言处理(NLP)数据集上的少样本性能(与图 28 所示的零样本性能相比)
- 泛化能力:未参与训练的“独立标签员”对InstructGPT的偏好率与训练标签员接近;模型能泛化到非英语指令、代码相关任务(尽管这些数据在训练集中占比极低)。
3、研究局限与后续进展
InstructGPT仍存在显著局限:对虚假前提的指令易盲从、简单问题过度犹豫(hedging)、多约束指令执行能力弱;在Winogender和CrowSPairs数据集上,偏见缓解效果不显著;对齐目标依赖标签员(以英语母语者为主)和API用户的偏好,缺乏更广泛人群的代表性。
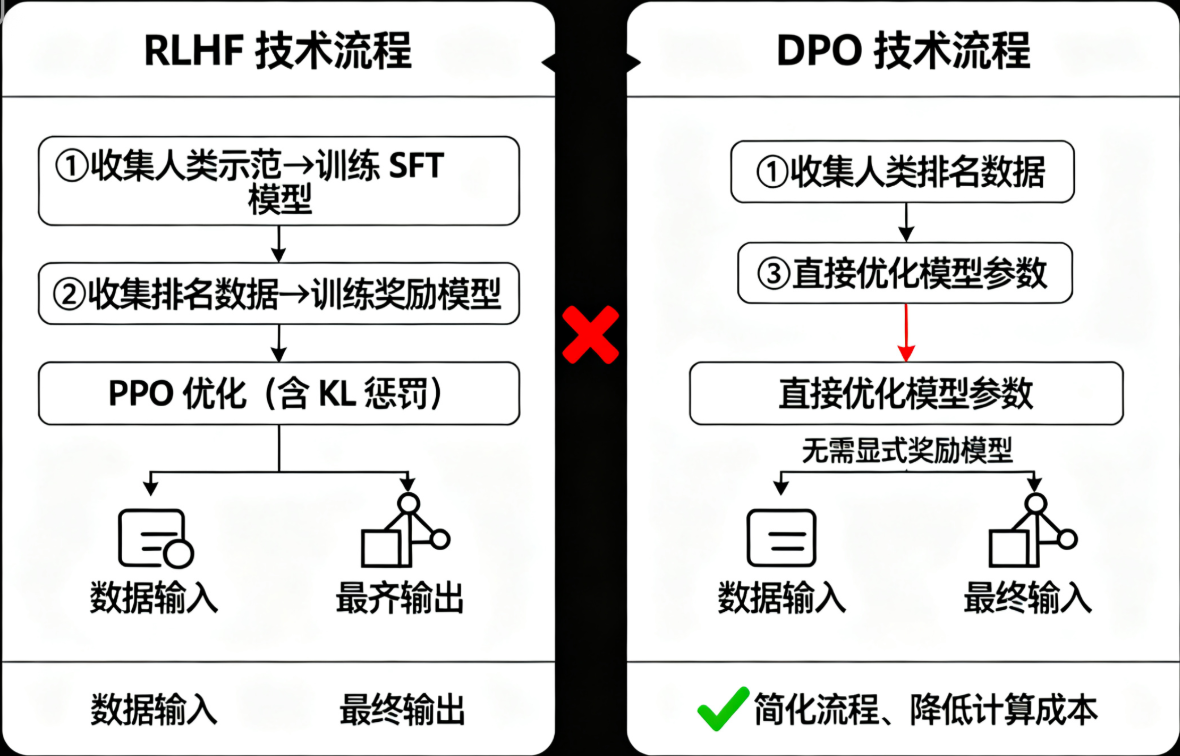
后续领域进展中,Direct Preference Optimization(DPO)技术成为关键突破:无需构建显式奖励模型,直接通过偏好数据(人类排名)优化模型参数,将RLHF的三步流程简化为两步,降低计算成本的同时保持对齐效果,其核心是通过极大似然估计直接建模偏好数据的概率分布,避免PPO的复杂优化过程。
4、研究意义与行业影响
InstructGPT论文奠定了“模型对齐”领域的技术范式,首次系统性验证了RLHF在大规模语言模型上的有效性,证明“对齐人类意图”可独立于模型规模成为核心优化目标。其提出的“helpful-honest-harmless”对齐框架,成为后续模型安全评估的核心标准;PPO-ptx缓解对齐税的思路,为平衡模型对齐性与任务性能提供了关键参考;而标签员筛选、数据收集的方法论,为后续偏好学习研究提供了可复现的实验范式。后来的ChatGPT、Claude等模型,都沿用了这种“让人类教、让人类评、让模型练”的思路;我们现在用AI写东西、查资料时,它能准确理解需求、不胡说八道,背后都有这篇论文的功劳——它开启了“大模型从‘博学’到‘好用’”的新时代。
总结
InstructGPT的核心贡献,是用严谨的RLHF框架证明了**“对齐优先于规模**”的核心逻辑,为大模型从“能力强大”走向“可靠可用”提供了可落地的技术路径。专业视角下,它是偏好学习与模型对齐的里程碑;通俗视角下,它是让AI“听懂人话、办对事”的关键一步。而后续DPO等技术的涌现,正是对这一核心思路的优化与延伸——模型对齐的终极目标,始终是让AI成为真正尊重人类意图、安全可靠的助手。\