transformer 在 DETR当中的应用
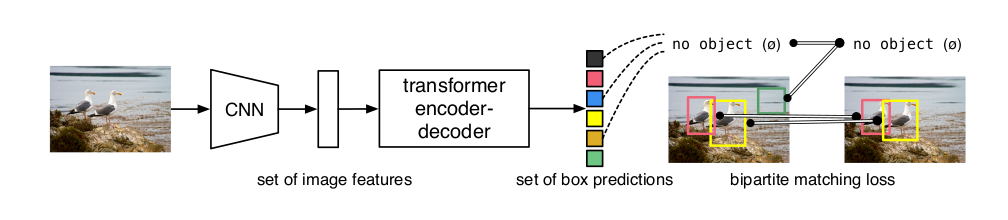 算法原理
算法原理
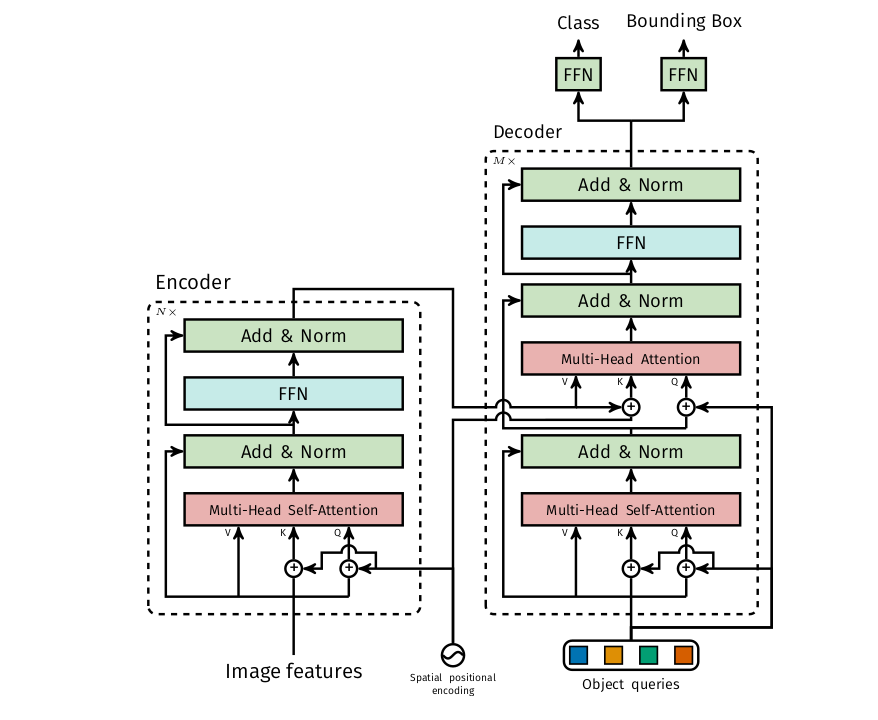
输入一张图片进行卷积操作,提取图像特征,将特征图展开成一维向量。输入图片的尺寸为800×600×3,经过卷积操作,比如下采样32倍,图像变成25×19×2048。然后将特征图展平为序列
[1,25*19,2048]。然后经过多头自注意力进行编码,经过编码器模型基本能够区分不同的实例,其中K和V作为encoder-decoder交叉注意力机制的输入。解码器的输入是一小部分固定数量学习到的位置嵌入。本质上是一组可学习的参数向量,他的作用用来学习不同检测之间的特征关系,deepseek 给出的解释非常好,
在代码中,它就是一个
torch.nn.Parameter或tf.Variable,形状是(N, d),其中:N是您设定的固定数量(比如100),代表模型最多能预测的物体个数。d是特征向量的维度(比如256),与Transformer模型的隐藏层维度一致。
这个参数矩阵会与模型的其他部分一起被随机初始化,并通过训练过程中的梯度下降来学习和更新。
编码器经过注意力机制,得到的Q阵作为编解码解码器交叉注意力机制的Q阵。
编码器基本能够学习到不同实例之间的特征,能够区分不同目标,解码器能够学习不同检测之间的关系,能够更好的进行定位。
插入一个问题,为什么transformer 设计可以不用NMS
1.loss 函数采用的是二部图匹配,一对一的匹配。
2.模型学习到的是全局特征。通过全局推理,抑制重复预测。
3.让模型自己学习。整个系统联合学习去重策略。
最后的消融实验表明:
1. 编码器的层数为6,解码器的层数为6能取得不错的效果。
2.FFN 网络对模型性能有关键的影响。
3.位置编码很重要,位置编码包括空间位置编码,输出位置编码,编码器层的空间位置编码有与否对模型性能影响不大,解码器的位置编码,包括每一曾都需要输出位置编码,这个对模型性能影响比较大,原因是编码器经过卷积神经网络后已经有了位置关系,而解码器最重要的就是位置信息,如果没有输出位置编码网络很难做到收敛。
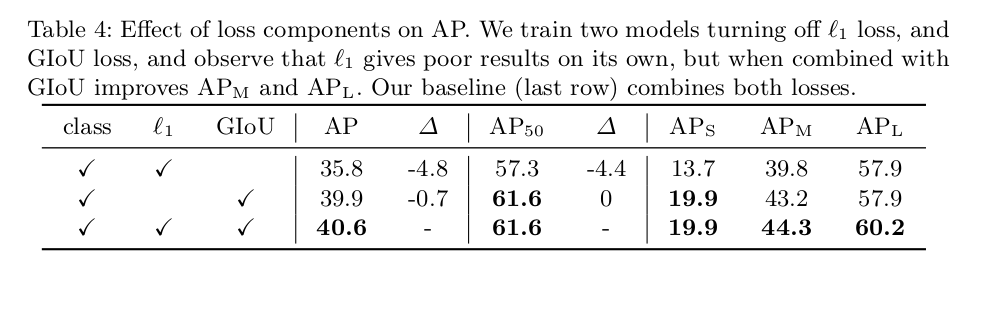
4.损失函数由三部分组成,分别是类别损失函数、L1损失函数、GIOU损失函数。做了两组实验,一组去掉L1,一组去掉GIOU,实验结论是,去掉LI的map损失较小,去掉GIOU的损失较大。
DETR 还进行了分割实验,在全景分割上也取得了很好的效果。
最后,附上一张DETR的网络结构图