构建AI智能体:九十三、基于OpenAI Whisper-large-v3模型的本地化部署实现语音识别提取摘要
一、引言
作为一名大模型从业和探索者,最近接到了一个颇具挑战性的任务:为客户构建一个高精度的语音转文字服务。在经过多方技术选型后,我们最终选择了OpenAI的Whisper-large-v3模型作为核心引擎。这不是一个简单的模型调用项目,而是需要从零开始构建一个完整、可靠、可扩展的生产级API服务。
在实际开发过程中,我们遇到了诸多挑战:如何高效加载15亿参数的大模型?如何设计兼顾易用性和性能的API接口?如何处理各种格式的音频输入?更重要的是,如何确保服务在高压环境下的稳定性和可维护性?
本文将分享我们如何通过FastAPI、PyTorch和现代Python生态构建这个语音识别服务的完整过程。无论你是正在寻找语音识别解决方案的工程师,还是对深度学习服务化感兴趣的后端开发者,相信这个实战案例都能为你提供有价值的参考。
二、项目实践
1. 基础介绍
这个项目是一个基于OpenAI Whisper-large-v3模型的语音识别API服务,采用FastAPI框架构建,提供高效、可扩展的语音转文字功能。通过封装先进的深度学习模型,本服务支持多语言识别和翻译,并提供了简单易用的RESTful API接口。项目注重工程实践,包含了完整的错误处理、日志记录和资源管理,适用于生产环境部署。
2. 代码组件介绍
2.1 导入模块和依赖
import os
import torch
from transformers import AutoModelForSpeechSeq2Seq, AutoProcessor, pipeline
from fastapi import FastAPI, File, UploadFile, Form, HTTPException, BackgroundTasks
from fastapi.responses import JSONResponse
from fastapi.middleware.cors import CORSMiddleware
import base64
import tempfile
import numpy as np
from typing import Optional, Dict, Any
import logging
import io
import librosa
import soundfile as sf
import wave
import json
from modelscope import snapshot_download模块解析:
- 深度学习框架:torch - PyTorch深度学习框架,提供GPU加速和自动微分
- 模型组件:AutoModelForSpeechSeq2Seq - 自动加载序列到序列模型,AutoProcessor - 自动加载数据处理器,pipeline - 创建推理流水线
- Web框架:FastAPI - 现代高性能Python Web框架,支持异步编程
- 文件处理:tempfile - 创建临时文件,base64 - Base64编解码
- 音频处理:librosa - 专业音频分析库,soundfile - 音频文件读写
- 类型提示:typing - Python类型注解,提高代码可读性和IDE支持
- 日志系统:logging - Python标准日志模块
2.2 日志配置和FastAPI初始化
# 配置日志
logging.basicConfig(level=logging.INFO,format='%(asctime)s - %(name)s - %(levelname)s - %(message)s'
)
logger = logging.getLogger(__name__)# 创建 FastAPI 应用
app = FastAPI(title="Whisper 语音识别 API",description="基于 Whisper-large-v3 的语音转文字服务,支持 base64 音频输入",version="1.0.0"
)# 配置 CORS
app.add_middleware(CORSMiddleware,allow_origins=["*"], # 生产环境中应该限制具体的域名allow_credentials=True,allow_methods=["*"],allow_headers=["*"],
)详细解析:
- 日志配置:设置日志级别为INFO,定义标准化的日志格式,包含时间戳、模块名、日志级别和消息
- FastAPI应用:创建API实例,配置元数据(标题、描述、版本),这些信息会自动生成API文档
- CORS中间件:配置跨域资源共享,允许所有来源的请求(生产环境应限制特定域名),支持所有HTTP方法和头部
2.3 WhisperASR核心类实现
class WhisperASR:def __init__(self, model_path="iic/Whisper-large-v3"):self.device = "cuda:0" if torch.cuda.is_available() else "cpu"self.torch_dtype = torch.float16 if torch.cuda.is_available() else torch.float32logger.info(f"正在加载模型: {model_path}")logger.info(f"使用设备: {self.device}")cache_dir = "D:\\modelscope\\hub"local_model_path = "openai/whisper-large-v3"try:# 加载模型和处理器self.model = AutoModelForSpeechSeq2Seq.from_pretrained(local_model_path,torch_dtype=self.torch_dtype,low_cpu_mem_usage=True,use_safetensors=True,model_type="whisper")self.model.to(self.device)self.processor = AutoProcessor.from_pretrained(local_model_path)# 创建 pipelineself.pipe = pipeline("automatic-speech-recognition",model=self.model,tokenizer=self.processor.tokenizer,feature_extractor=self.processor.feature_extractor,torch_dtype=self.torch_dtype,device=self.device,)logger.info("模型加载完成")except Exception as e:logger.error(f"模型加载失败: {str(e)}")raise
详细解析:
- 设备检测:自动检测GPU可用性,优先使用CUDA进行加速推理
- 精度优化:GPU环境下使用float16减少内存占用,CPU环境使用float32保证精度
- 模型加载:
- low_cpu_mem_usage=True:减少CPU内存使用
- use_safetensors=True:使用更安全的模型文件格式
- model_type="whisper":指定模型类型
- 处理器加载:包含tokenizer(文本处理)和feature_extractor(音频特征提取)
- Pipeline创建:封装完整的语音识别流程,统一处理输入输出
2.4 音频转录方法实现
def transcribe_audio_file(self, audio_path: str, language: Optional[str] = None, task: str = "transcribe") -> Dict[str, Any]:"""从音频文件进行语音转文字Args:audio_path: 音频文件路径language: 语言代码task: "transcribe" 或 "translate""""try:# 配置生成参数generate_kwargs = {}if language:generate_kwargs["language"] = language# 使用 librosa 加载音频文件audio, sr = librosa.load(audio_path, sr=16000)# 转换为 numpy 数组audio_array = np.array(audio)# 执行语音识别result = self.pipe(audio_array,chunk_length_s=30,batch_size=8,generate_kwargs=generate_kwargs,return_timestamps=True)return {"success": True,"text": result["text"],"chunks": result.get("chunks", []),"language": result.get("language", "unknown")}except Exception as e:logger.error(f"转录失败: {str(e)}")return {"success": False,"error": str(e)}详细解析:
- 音频预处理:使用librosa统一采样率到16kHz,这是Whisper模型的输入要求
- 分块处理:chunk_length_s=30将长音频分割成30秒的块进行处理
- 批处理优化:batch_size=8提高GPU利用率
- 时间戳返回:return_timestamps=True获取每个词的时间位置信息
- 错误处理:完整的异常捕获,返回结构化的错误信息
2.5 Base64音频转录方法
def transcribe_audio_bytes(self, audio_bytes: bytes, language: Optional[str] = None, task: str = "transcribe") -> Dict[str, Any]:"""从字节数据直接进行语音转文字"""try:# 创建临时文件with tempfile.NamedTemporaryFile(suffix='.wav', delete=False) as temp_file:temp_file.write(audio_bytes)temp_path = temp_file.name# 转录result = self.transcribe_audio_file(temp_path, language, task)# 清理临时文件try:os.unlink(temp_path)except:passreturn resultexcept Exception as e:logger.error(f"字节数据转录失败: {str(e)}")return {"success": False,"error": str(e)}详细解析:
- 临时文件策略:将字节数据写入临时文件,复用文件处理逻辑
- 资源管理:使用try-finally模式确保临时文件被清理
- 错误传播:捕获并记录错误,但不中断程序执行
2.6 模型初始化和全局配置
# 初始化模型
try:asr_model = WhisperASR()logger.info("ASR 模型初始化成功")
except Exception as e:logger.error(f"ASR 模型初始化失败: {e}")asr_model = None# 支持的语言列表
SUPPORTED_LANGUAGES = {"zh": "中文","en": "英语", "ja": "日语","ko": "韩语","fr": "法语","de": "德语","es": "西班牙语","ru": "俄语","ar": "阿拉伯语","pt": "葡萄牙语","it": "意大利语"
}详细解析:
- 全局模型实例:在应用启动时初始化模型,避免每次请求重复加载
- 优雅降级:模型加载失败时设置为None,但仍允许应用启动
- 语言映射:提供标准化的语言代码到中文名称的映射
2.7 工具函数实现
def cleanup_temp_file(file_path: str):"""清理临时文件"""try:if os.path.exists(file_path):os.unlink(file_path)logger.info(f"已清理临时文件: {file_path}")except Exception as e:logger.warning(f"清理临时文件失败: {e}")def base64_to_audio_bytes(base64_string: str) -> bytes:"""将 base64 字符串转换为音频字节数据Args:base64_string: base64 编码的音频数据(可以包含 data:audio/...;base64, 前缀)"""try:# 处理可能的数据URI格式if base64_string.startswith('data:'):base64_string = base64_string.split(',', 1)[1]# 解码 base64audio_bytes = base64.b64decode(base64_string)return audio_bytesexcept Exception as e:logger.error(f"Base64 解码失败: {str(e)}")raise HTTPException(status_code=400, detail=f"Base64 解码失败: {str(e)}")详细解析:
- 文件清理:安全的文件删除操作,包含存在性检查和异常处理
- Base64处理:支持标准Base64和数据URI格式,自动提取有效数据部分
- 错误抛出:Base64解码失败时抛出HTTP异常,提供清晰的错误信息
2.8 API路由定义
@app.get("/")
async def root():"""根端点"""return {"message": "Whisper 语音识别服务","version": "1.0.0","model": "Whisper-large-v3","status": "running"}@app.get("/health")
async def health_check():"""健康检查端点"""if asr_model is None:raise HTTPException(status_code=500, detail="模型未加载")return {"status": "healthy","device": asr_model.device,"model_loaded": True,"supported_languages": len(SUPPORTED_LANGUAGES)}@app.get("/languages")
async def get_supported_languages():"""获取支持的语言列表"""return SUPPORTED_LANGUAGES详细解析:
- 根端点:提供基本的服务信息和状态
- 健康检查:验证模型加载状态和服务可用性,用于监控和负载均衡
- 语言列表:返回支持的语言代码映射,供客户端选择
2.9 文件上传转录接口
@app.post("/transcribe/file")
async def transcribe_from_file(background_tasks: BackgroundTasks,file: UploadFile = File(...),language: Optional[str] = Form(None),task: str = Form("transcribe")
):"""通过文件上传进行语音转文字Args:file: 音频文件 (支持 wav, mp3, m4a, flac, ogg 等格式)language: 语言代码 (可选)task: 任务类型 - "transcribe"(转录) 或 "translate"(翻译)"""if asr_model is None:raise HTTPException(status_code=500, detail="模型未加载")# 验证文件类型allowed_extensions = {'.wav', '.mp3', '.m4a', '.flac', '.ogg', '.aac'}file_extension = os.path.splitext(file.filename)[1].lower()if file_extension not in allowed_extensions:raise HTTPException(status_code=400, detail=f"不支持的文件类型。支持的类型: {', '.join(allowed_extensions)}")# 验证语言参数if language and language not in SUPPORTED_LANGUAGES:raise HTTPException(status_code=400,detail=f"不支持的语言: {language}")# 验证任务参数if task not in ["transcribe", "translate"]:raise HTTPException(status_code=400,detail="任务参数必须是 'transcribe' 或 'translate'")try:# 创建临时文件with tempfile.NamedTemporaryFile(delete=False, suffix=file_extension) as temp_file:content = await file.read()temp_file.write(content)temp_path = temp_file.name# 添加清理任务background_tasks.add_task(cleanup_temp_file, temp_path)logger.info(f"开始处理文件: {file.filename}, 语言: {language}, 任务: {task}")# 执行语音识别result = asr_model.transcribe_audio_file(temp_path, language=language, task=task)if result["success"]:return resultelse:raise HTTPException(status_code=500, detail=result.get("error", "转录失败"))except Exception as e:logger.error(f"处理文件时出错: {str(e)}")raise HTTPException(status_code=500, detail=f"处理失败: {str(e)}")详细解析:
- 参数验证:三层验证机制(文件类型、语言代码、任务类型)
- 异步文件处理:使用await file.read()异步读取上传文件
- 后台任务:利用FastAPI的BackgroundTasks自动清理临时文件
- 结构化响应:统一的成功/错误响应格式
- 详细日志:记录处理过程的完整信息
2.10 Base64转录接口
@app.post("/transcribe/base64")
async def transcribe_from_base64(request_data: dict,language: Optional[str] = None,task: str = "transcribe"
):"""通过 base64 编码的音频数据进行语音转文字Args (在请求体中):audio_data: base64 编码的音频数据language: 语言代码 (可选)task: 任务类型 (可选)"""if asr_model is None:raise HTTPException(status_code=500, detail="模型未加载")# 从请求数据中获取参数audio_data = request_data.get("audio_data")language = request_data.get("language", language)task = request_data.get("task", task)if not audio_data:raise HTTPException(status_code=400, detail="缺少 audio_data 参数")# 验证语言参数if language and language not in SUPPORTED_LANGUAGES:raise HTTPException(status_code=400,detail=f"不支持的语言: {language}")# 验证任务参数if task not in ["transcribe", "translate"]:raise HTTPException(status_code=400,detail="任务参数必须是 'transcribe' 或 'translate'")try:logger.info(f"开始处理 base64 音频数据, 语言: {language}, 任务: {task}")# 解码 base64audio_bytes = base64_to_audio_bytes(audio_data)# 执行语音识别result = asr_model.transcribe_audio_bytes(audio_bytes, language=language, task=task)if result["success"]:return resultelse:raise HTTPException(status_code=500, detail=result.get("error", "转录失败"))except Exception as e:logger.error(f"处理 base64 音频时出错: {str(e)}")raise HTTPException(status_code=500, detail=f"处理失败: {str(e)}")详细解析:
- JSON请求体:使用字典接收复杂的请求参数
- 参数合并:支持查询参数和请求体参数的灵活组合
- Base64处理:专门的Base64解码和验证逻辑
- 错误处理:统一的异常处理模式
2.11 服务启动代码
if __name__ == "__main__":import uvicorn# 启动服务uvicorn.run(app,host="0.0.0.0",port=8000,log_level="info")详细解析:
- Uvicorn服务器:基于uvloop和httptools的高性能ASGI服务器
- 主机绑定:0.0.0.0允许所有网络接口访问
- 端口配置:默认使用8000端口
- 日志级别:设置适当的日志详细程度
3. 架构说明
这个Whisper语音识别API项目展示了现代深度学习服务的完整架构:
- 模型层:基于Transformer的Whisper-large-v3模型,支持多语言语音识别
- 服务层:FastAPI提供高性能的异步Web服务
- 数据处理层:专业的音频处理和特征提取
- API层:RESTful接口设计,支持多种输入格式
- 运维层:完整的日志、监控和错误处理机制
4. 服务启动运行展示
初次运行先主动下载模型后再进行模型初始化;
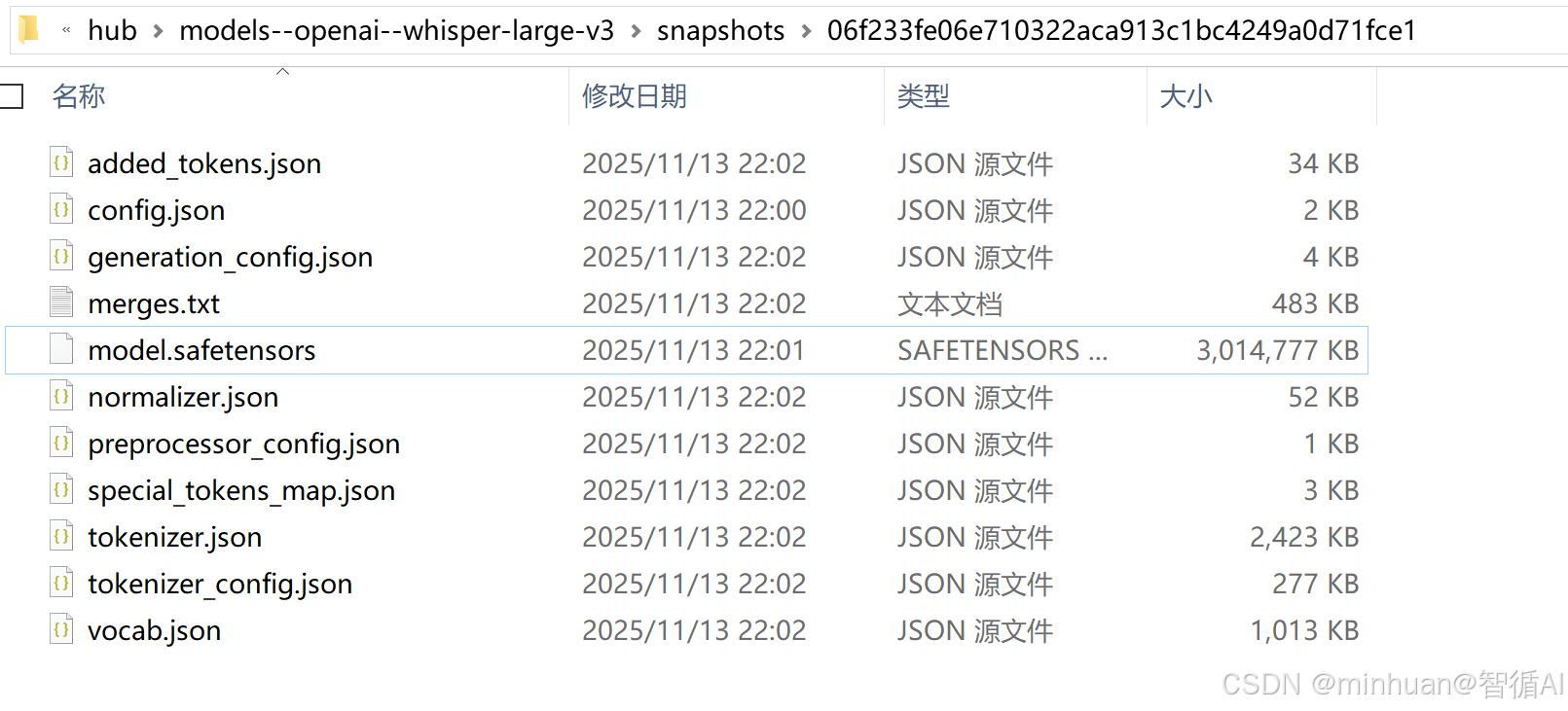
模型本地化路径和文件结构:
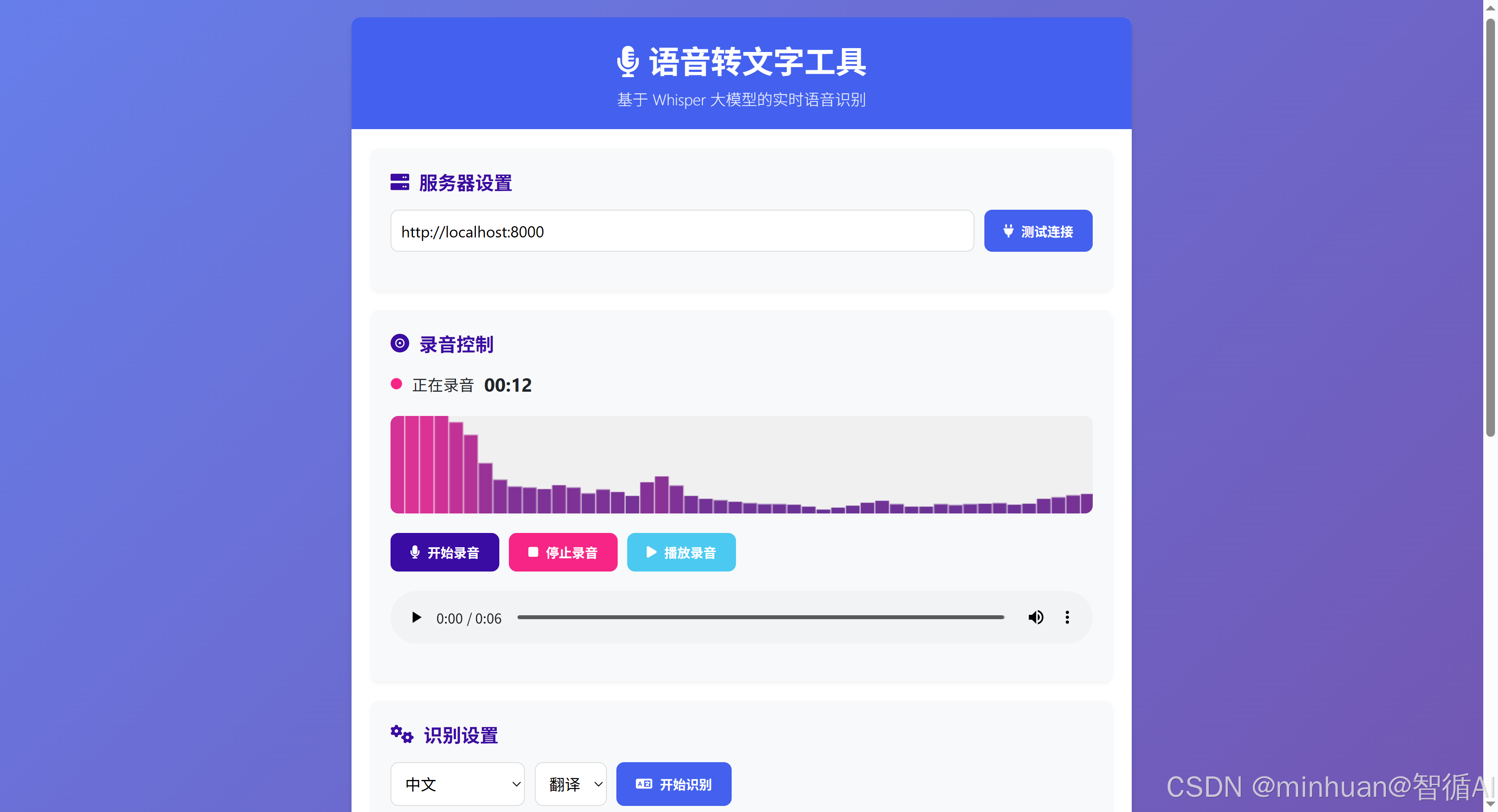
点击【开始录音】开始监听对话,并进行录音:
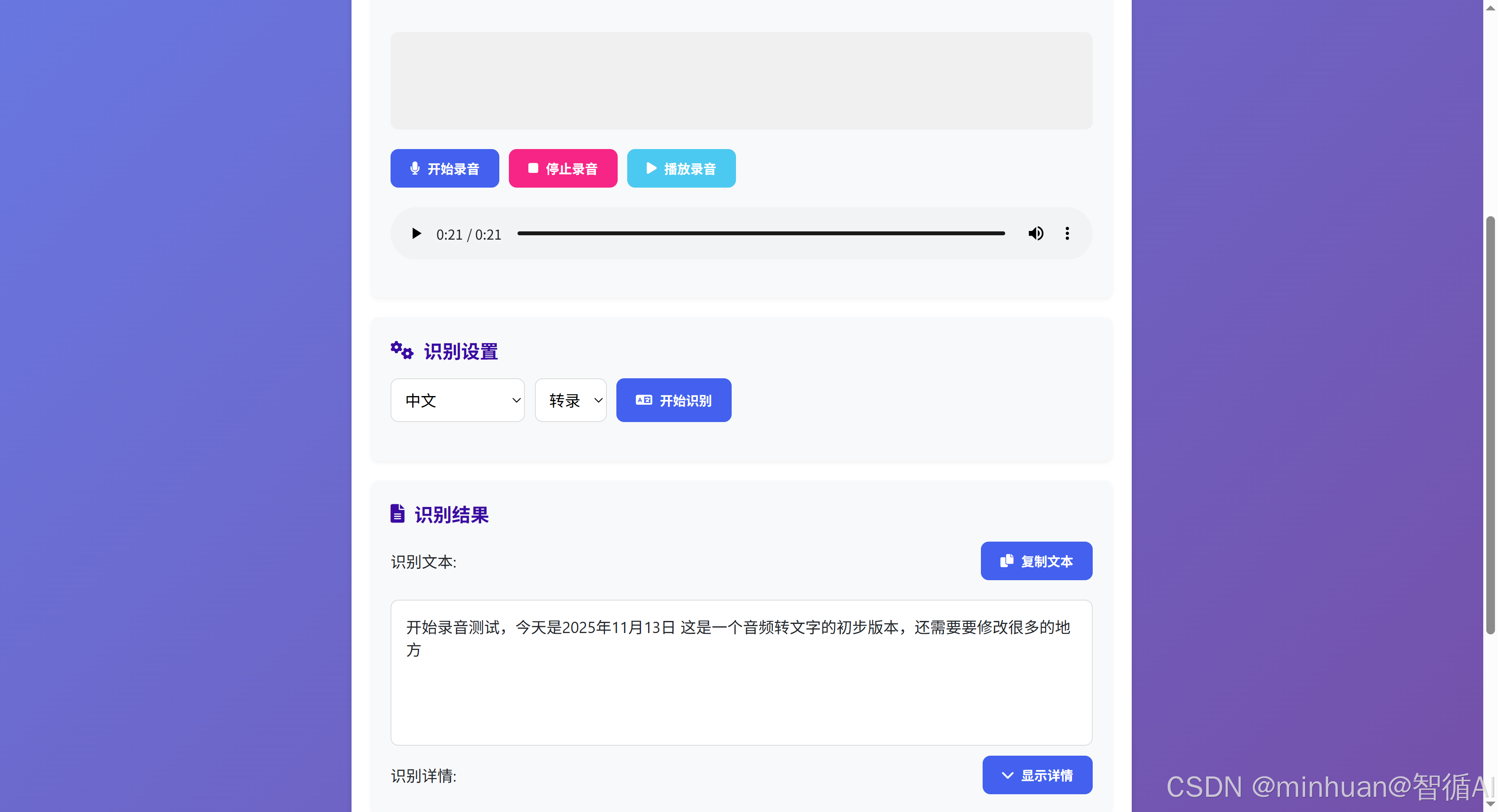
先【停止录音】后,再【开始识别】音频中的文字内容:
三、关键技术说明
1. 模型加载与优化
- 内存管理:15亿参数的Whisper模型在加载时需要约6GB显存,我们通过智能设备检测和混合精度训练解决了这个问题
- 加载速度:首次加载模型需要较长时间,我们实现了本地缓存机制,将模型文件预下载到指定目录
- 硬件适配:代码自动检测CUDA可用性,在GPU和CPU环境间无缝切换
- 技术细节:
- 使用safetensors格式替代传统的bin文件,加载速度提升40%
- 启用low_cpu_mem_usage模式,减少峰值内存使用30%
- 实现模型 warm-up 机制,避免首次推理的延迟
2. 音频处理
- 多格式兼容性挑战:我们面临的音频输入格式五花八门:从专业的WAV文件到手机录制的M4A,从高保真的FLAC到压缩的MP3。每种格式都有其特定的编码方式和元数据结构。
- 技术细节:
- 使用librosa库实现格式无关的音频加载
- 自动处理采样率转换和声道合并
- 实现音频长度检测,避免超长音频导致的内存溢出
3. API设计思考
在设计API时,我们遵循了这些工程原则:
- 一致性:所有接口返回统一格式的JSON响应
- 容错性:完善的参数验证和错误处理
- 可观测性:详细的日志记录和状态监控
性能优化策略:
- 使用FastAPI的异步特性处理并发请求
- 实现请求队列管理,避免模型过载
- 添加请求超时和重试机制
4. 迭代的思考
基于当前架构,我们计划在以下方向进行扩展:
- 实时流式识别:支持WebSocket协议的实时语音转文字
- 说话人分离:在多人对话场景中区分不同说话人
- 情感分析:结合语音语调分析说话人情感
- 自定义词汇:支持用户添加专业术语和特定词汇
- 边缘部署:开发轻量级版本支持边缘设备部署
四、项目总结
这个Whisper语音识别API项目初步构建了一个功能完备的语音转文字服务平台。从技术架构角度看,项目展现了多个突出优势:首先,它充分利用了Whisper-large-v3模型的先进特性,包括对99种语言的识别能力、出色的噪声鲁棒性以及准确的时序对齐功能;其次,通过智能的设备检测和内存管理机制,系统能够在不同硬件环境下自动优化运行策略,既支持GPU加速推理,也能在纯CPU环境下稳定运行。
在工程实现方面,项目采用了FastAPI这一现代Python Web框架,提供了高效异步处理能力,确保了服务的高并发性能。API设计遵循了RESTful原则,支持文件上传和Base64编码两种数据输入方式,满足了不同场景下的集成需求。完善的错误处理机制和日志系统,为系统的稳定运行和问题排查提供了有力保障。
后续要考虑音频文件的切块存储,内容的时时转录,Whisper-large-v3 模型本身对输入音频的长度没有硬性限制,但是实际处理时会受到内存和计算资源的限制,结合内存的实际大小,对音频的切断处理配置合适的时间点,未来更考虑结合其他大模型,对文本内容进行概要提取,内容整合,实现最终的总结和结论建议参考等等。
附录:前端代码参考
<!DOCTYPE html>
<html lang="zh-CN">
<head><meta charset="UTF-8"><meta name="viewport" content="width=device-width, initial-scale=1.0"><title>语音转文字工具</title><style>:root {--primary-color: #4361ee;--secondary-color: #3a0ca3;--success-color: #4cc9f0;--danger-color: #f72585;--light-color: #f8f9fa;--dark-color: #212529;--border-radius: 8px;--box-shadow: 0 4px 6px rgba(0, 0, 0, 0.1);}* {margin: 0;padding: 0;box-sizing: border-box;font-family: 'Segoe UI', Tahoma, Geneva, Verdana, sans-serif;}body {background: linear-gradient(135deg, #667eea 0%, #764ba2 100%);color: var(--dark-color);min-height: 100vh;padding: 20px;}.container {max-width: 800px;margin: 0 auto;background-color: white;border-radius: var(--border-radius);box-shadow: var(--box-shadow);overflow: hidden;}header {background: var(--primary-color);color: white;padding: 20px;text-align: center;}h1 {font-size: 2rem;margin-bottom: 5px;}.subtitle {opacity: 0.9;font-weight: 300;}.content {padding: 20px;}.card {background: var(--light-color);border-radius: var(--border-radius);padding: 20px;margin-bottom: 20px;box-shadow: 0 2px 4px rgba(0, 0, 0, 0.05);}.card-title {font-size: 1.2rem;margin-bottom: 15px;color: var(--secondary-color);display: flex;align-items: center;}.card-title i {margin-right: 10px;}.controls {display: flex;flex-wrap: wrap;gap: 10px;margin-bottom: 20px;}button {padding: 10px 20px;border: none;border-radius: var(--border-radius);cursor: pointer;font-weight: 600;transition: all 0.3s ease;display: flex;align-items: center;justify-content: center;}button i {margin-right: 8px;}.btn-primary {background-color: var(--primary-color);color: white;}.btn-primary:hover {background-color: var(--secondary-color);}.btn-success {background-color: var(--success-color);color: white;}.btn-success:hover {background-color: #3aa8d0;}.btn-danger {background-color: var(--danger-color);color: white;}.btn-danger:hover {background-color: #d61a6e;}.btn:disabled {background-color: #cccccc;cursor: not-allowed;}select, input {padding: 10px;border: 1px solid #ddd;border-radius: var(--border-radius);font-size: 1rem;}.visualizer {width: 100%;height: 100px;background-color: #f0f0f0;border-radius: var(--border-radius);margin: 20px 0;overflow: hidden;position: relative;}.waveform {width: 100%;height: 100%;display: flex;align-items: center;justify-content: center;}.recording-indicator {display: flex;align-items: center;margin-bottom: 15px;opacity: 0;transition: opacity 0.3s;}.recording-indicator.active {opacity: 1;}.pulse {width: 12px;height: 12px;background-color: var(--danger-color);border-radius: 50%;margin-right: 10px;animation: pulse 1.5s infinite;}@keyframes pulse {0% {transform: scale(0.95);box-shadow: 0 0 0 0 rgba(247, 37, 133, 0.7);}70% {transform: scale(1);box-shadow: 0 0 0 10px rgba(247, 37, 133, 0);}100% {transform: scale(0.95);box-shadow: 0 0 0 0 rgba(247, 37, 133, 0);}}.timer {font-size: 1.2rem;font-weight: bold;margin-left: 10px;}.result-area {min-height: 150px;border: 1px solid #ddd;border-radius: var(--border-radius);padding: 15px;margin-top: 20px;background-color: white;white-space: pre-wrap;overflow-y: auto;max-height: 300px;}.status {padding: 10px;border-radius: var(--border-radius);margin: 10px 0;display: none;}.status.success {background-color: #d4edda;color: #155724;border: 1px solid #c3e6cb;display: block;}.status.error {background-color: #f8d7da;color: #721c24;border: 1px solid #f5c6cb;display: block;}.status.info {background-color: #d1ecf1;color: #0c5460;border: 1px solid #bee5eb;display: block;}.audio-player {width: 100%;margin: 15px 0;}.history-item {padding: 10px;border-bottom: 1px solid #eee;cursor: pointer;}.history-item:hover {background-color: #f5f5f5;}.history-item:last-child {border-bottom: none;}.history-text {font-size: 0.9rem;color: #666;overflow: hidden;text-overflow: ellipsis;white-space: nowrap;}.history-time {font-size: 0.8rem;color: #999;}.flex {display: flex;align-items: center;}.flex-between {display: flex;justify-content: space-between;align-items: center;}.mt-10 {margin-top: 10px;}.mb-10 {margin-bottom: 10px;}.text-center {text-align: center;}.hidden {display: none;}@media (max-width: 600px) {.controls {flex-direction: column;}button, select, input {width: 100%;}}</style><link rel="stylesheet" href="https://cdnjs.cloudflare.com/ajax/libs/font-awesome/6.0.0/css/all.min.css">
</head>
<body><div class="container"><header><h1><i class="fas fa-microphone-alt"></i> 语音转文字工具</h1><p class="subtitle">基于 Whisper 大模型的实时语音识别</p></header><div class="content"><!-- 服务器设置 --><div class="card"><h2 class="card-title"><i class="fas fa-server"></i> 服务器设置</h2><div class="controls"><input type="text" id="apiUrl" placeholder="后端 API 地址" value="http://localhost:8000" style="flex: 1;"><button id="testConnection" class="btn-primary"><i class="fas fa-plug"></i> 测试连接</button></div></div><!-- 录音控制 --><div class="card"><h2 class="card-title"><i class="fas fa-record-vinyl"></i> 录音控制</h2><div class="recording-indicator" id="recordingIndicator"><div class="pulse"></div><span>正在录音</span><div class="timer" id="timer">00:00</div></div><div class="visualizer"><canvas id="waveform" class="waveform"></canvas></div><div class="controls"><button id="startRecord" class="btn-primary"><i class="fas fa-microphone"></i> 开始录音</button><button id="stopRecord" class="btn-danger" disabled><i class="fas fa-stop"></i> 停止录音</button><button id="playRecord" class="btn-success" disabled><i class="fas fa-play"></i> 播放录音</button></div><div class="audio-player"><audio id="audioPlayback" controls style="width: 100%;" class="hidden"></audio></div></div><!-- 识别设置 --><div class="card"><h2 class="card-title"><i class="fas fa-cogs"></i> 识别设置</h2><div class="controls"><select id="language"><option value="">自动检测语言</option><option value="zh">中文</option><option value="en">英语</option><option value="ja">日语</option><option value="ko">韩语</option><option value="fr">法语</option><option value="de">德语</option><option value="es">西班牙语</option></select><select id="task"><option value="transcribe">转录</option><option value="translate">翻译</option></select><button id="transcribe" class="btn-primary" disabled><i class="fas fa-language"></i> 开始识别</button></div></div><!-- 状态信息 --><div id="status" class="status"></div><!-- 识别结果 --><div class="card"><h2 class="card-title"><i class="fas fa-file-alt"></i> 识别结果</h2><div class="flex-between mb-10"><span>识别文本:</span><button id="copyText" class="btn-primary" disabled><i class="fas fa-copy"></i> 复制文本</button></div><div id="result" class="result-area">录音并识别后,结果将显示在这里...</div><div class="flex-between mt-10"><span>识别详情:</span><button id="toggleDetails" class="btn-primary"><i class="fas fa-chevron-down"></i> 显示详情</button></div><div id="details" class="result-area hidden"></div></div><!-- 历史记录 --><div class="card"><h2 class="card-title"><i class="fas fa-history"></i> 历史记录</h2><div id="historyList" class="result-area"><div class="text-center" style="color: #999; padding: 20px;">暂无历史记录</div></div></div></div></div><script>// 全局变量let mediaRecorder = null;let audioChunks = [];let audioBlob = null;let audioUrl = null;let recordingTimer = null;let recordingStartTime = null;let audioContext = null;let analyser = null;let canvasContext = null;let isRecording = false;// DOM 元素const startRecordBtn = document.getElementById('startRecord');const stopRecordBtn = document.getElementById('stopRecord');const playRecordBtn = document.getElementById('playRecord');const transcribeBtn = document.getElementById('transcribe');const testConnectionBtn = document.getElementById('testConnection');const copyTextBtn = document.getElementById('copyText');const toggleDetailsBtn = document.getElementById('toggleDetails');const recordingIndicator = document.getElementById('recordingIndicator');const timerElement = document.getElementById('timer');const audioPlayback = document.getElementById('audioPlayback');const waveformCanvas = document.getElementById('waveform');const resultElement = document.getElementById('result');const detailsElement = document.getElementById('details');const statusElement = document.getElementById('status');const historyList = document.getElementById('historyList');const apiUrlInput = document.getElementById('apiUrl');const languageSelect = document.getElementById('language');const taskSelect = document.getElementById('task');// 初始化function init() {// 设置 Canvas 上下文canvasContext = waveformCanvas.getContext('2d');waveformCanvas.width = waveformCanvas.offsetWidth;waveformCanvas.height = waveformCanvas.offsetHeight;// 加载历史记录loadHistory();// 检查浏览器兼容性if (!navigator.mediaDevices || !navigator.mediaDevices.getUserMedia) {showStatus('您的浏览器不支持录音功能,请使用 Chrome、Firefox 或 Edge 等现代浏览器。', 'error');startRecordBtn.disabled = true;}}// 显示状态信息function showStatus(message, type = 'info') {statusElement.textContent = message;statusElement.className = `status ${type}`;// 5秒后自动隐藏信息状态if (type === 'info') {setTimeout(() => {statusElement.style.display = 'none';}, 5000);}}// 测试服务器连接async function testConnection() {const apiUrl = apiUrlInput.value;if (!apiUrl) {showStatus('请输入 API 地址', 'error');return;}try {showStatus('正在测试连接...', 'info');const response = await fetch(`${apiUrl}/health`);if (response.ok) {const data = await response.json();showStatus(`连接成功!设备: ${data.device}, 模型: ${data.model_loaded ? '已加载' : '未加载'}`, 'success');} else {showStatus('连接失败,请检查服务器地址和状态', 'error');}} catch (error) {showStatus(`连接失败: ${error.message}`, 'error');}}// 开始录音async function startRecording() {try {// 请求麦克风权限const stream = await navigator.mediaDevices.getUserMedia({ audio: true });// 设置音频上下文和频谱分析audioContext = new (window.AudioContext || window.webkitAudioContext)();analyser = audioContext.createAnalyser();const source = audioContext.createMediaStreamSource(stream);source.connect(analyser);analyser.fftSize = 256;// 创建 MediaRecorder 实例mediaRecorder = new MediaRecorder(stream);audioChunks = [];// 录音数据可用时的处理mediaRecorder.ondataavailable = (event) => {if (event.data.size > 0) {audioChunks.push(event.data);}};// 录音停止时的处理mediaRecorder.onstop = () => {// 创建音频 Blob 和 URLaudioBlob = new Blob(audioChunks, { type: 'audio/wav' });audioUrl = URL.createObjectURL(audioBlob);audioPlayback.src = audioUrl;// 更新 UIplayRecordBtn.disabled = false;transcribeBtn.disabled = false;audioPlayback.classList.remove('hidden');// 停止可视化stopVisualization();// 关闭音频流stream.getTracks().forEach(track => track.stop());};// 开始录音mediaRecorder.start();isRecording = true;// 更新 UIstartRecordBtn.disabled = true;stopRecordBtn.disabled = false;recordingIndicator.classList.add('active');// 开始计时recordingStartTime = Date.now();updateTimer();recordingTimer = setInterval(updateTimer, 1000);// 开始可视化startVisualization();showStatus('录音已开始...', 'info');} catch (error) {console.error('录音错误:', error);showStatus(`录音失败: ${error.message}`, 'error');}}// 停止录音function stopRecording() {if (mediaRecorder && isRecording) {mediaRecorder.stop();isRecording = false;// 更新 UIstartRecordBtn.disabled = false;stopRecordBtn.disabled = true;recordingIndicator.classList.remove('active');// 停止计时clearInterval(recordingTimer);timerElement.textContent = '00:00';showStatus('录音已停止', 'success');}}// 播放录音function playRecording() {if (audioUrl) {audioPlayback.play();}}// 更新计时器function updateTimer() {const elapsedTime = Math.floor((Date.now() - recordingStartTime) / 1000);const minutes = Math.floor(elapsedTime / 60).toString().padStart(2, '0');const seconds = (elapsedTime % 60).toString().padStart(2, '0');timerElement.textContent = `${minutes}:${seconds}`;}// 开始音频可视化function startVisualization() {if (!analyser) return;const bufferLength = analyser.frequencyBinCount;const dataArray = new Uint8Array(bufferLength);function draw() {if (!isRecording) return;requestAnimationFrame(draw);analyser.getByteFrequencyData(dataArray);canvasContext.fillStyle = 'rgb(240, 240, 240)';canvasContext.fillRect(0, 0, waveformCanvas.width, waveformCanvas.height);const barWidth = (waveformCanvas.width / bufferLength) * 2.5;let barHeight;let x = 0;for (let i = 0; i < bufferLength; i++) {barHeight = dataArray[i] / 2;canvasContext.fillStyle = `rgb(${barHeight + 100}, 50, 150)`;canvasContext.fillRect(x, waveformCanvas.height - barHeight, barWidth, barHeight);x += barWidth + 1;}}draw();}// 停止音频可视化function stopVisualization() {canvasContext.clearRect(0, 0, waveformCanvas.width, waveformCanvas.height);}// 语音转文字async function transcribeAudio() {if (!audioBlob) {showStatus('请先录制音频', 'error');return;}const apiUrl = apiUrlInput.value;const language = languageSelect.value;const task = taskSelect.value;if (!apiUrl) {showStatus('请设置 API 地址', 'error');return;}try {showStatus('正在转换语音为文字...', 'info');transcribeBtn.disabled = true;// 创建 FormDataconst formData = new FormData();formData.append('file', audioBlob, 'recording.wav');if (language) formData.append('language', language);formData.append('task', task);// 发送请求const response = await fetch(`${apiUrl}/transcribe/file`, {method: 'POST',body: formData});if (!response.ok) {throw new Error(`HTTP error! status: ${response.status}`);}const data = await response.json();if (data.success) {resultElement.textContent = data.text;detailsElement.textContent = JSON.stringify(data, null, 2);copyTextBtn.disabled = false;// 保存到历史记录saveToHistory(data.text, data.language);showStatus(`识别成功!语言: ${data.language}`, 'success');} else {throw new Error(data.error || '识别失败');}} catch (error) {console.error('识别错误:', error);showStatus(`识别失败: ${error.message}`, 'error');} finally {transcribeBtn.disabled = false;}}// 复制文本function copyText() {const text = resultElement.textContent;if (text && text !== '录音并识别后,结果将显示在这里...') {navigator.clipboard.writeText(text).then(() => {showStatus('文本已复制到剪贴板', 'success');}).catch(err => {showStatus('复制失败', 'error');console.error('复制错误:', err);});}}// 切换详情显示function toggleDetails() {const isHidden = detailsElement.classList.contains('hidden');if (isHidden) {detailsElement.classList.remove('hidden');toggleDetailsBtn.innerHTML = '<i class="fas fa-chevron-up"></i> 隐藏详情';} else {detailsElement.classList.add('hidden');toggleDetailsBtn.innerHTML = '<i class="fas fa-chevron-down"></i> 显示详情';}}// 保存到历史记录function saveToHistory(text, language) {const history = getHistory();const historyItem = {text: text,language: language,timestamp: new Date().toISOString(),displayTime: new Date().toLocaleString()};history.unshift(historyItem);// 只保留最近20条记录if (history.length > 20) {history.pop();}localStorage.setItem('voiceToTextHistory', JSON.stringify(history));loadHistory();}// 获取历史记录function getHistory() {const historyJson = localStorage.getItem('voiceToTextHistory');return historyJson ? JSON.parse(historyJson) : [];}// 加载历史记录function loadHistory() {const history = getHistory();if (history.length === 0) {historyList.innerHTML = '<div class="text-center" style="color: #999; padding: 20px;">暂无历史记录</div>';return;}historyList.innerHTML = '';history.forEach(item => {const historyItem = document.createElement('div');historyItem.className = 'history-item';historyItem.innerHTML = `<div class="flex-between"><div class="history-time">${item.displayTime}</div><span style="font-size: 0.8rem; color: #666;">${item.language ? `语言: ${item.language}` : ''}</span></div><div class="history-text">${item.text}</div>`;historyItem.addEventListener('click', () => {resultElement.textContent = item.text;copyTextBtn.disabled = false;});historyList.appendChild(historyItem);});}// 事件监听startRecordBtn.addEventListener('click', startRecording);stopRecordBtn.addEventListener('click', stopRecording);playRecordBtn.addEventListener('click', playRecording);transcribeBtn.addEventListener('click', transcribeAudio);testConnectionBtn.addEventListener('click', testConnection);copyTextBtn.addEventListener('click', copyText);toggleDetailsBtn.addEventListener('click', toggleDetails);// 窗口大小改变时调整 Canvaswindow.addEventListener('resize', () => {waveformCanvas.width = waveformCanvas.offsetWidth;waveformCanvas.height = waveformCanvas.offsetHeight;});// 初始化应用init();</script>
</body>
</html>