Java-170 Neo4j 事务、索引与约束实战:语法、并发陷阱与速修清单
TL;DR
- 场景:在 Java/Cypher 构建高并发图服务,既要安全写入也要快查。
- 结论:坚持 ACID + READ_COMMITTED;死锁走“捕获→退避→重试”;索引/约束用 5.x 统一语法与 FULLTEXT。
- 产出:一份能落地的版本矩阵与错误速查卡,覆盖 3.5/4.x/5.x 常见坑位。

版本矩阵
| 版本 | 已验证 | 说明 |
|---|---|---|
| 3.5 LTS | 是 | 索引/约束旧语法:CREATE INDEX ON :Label(prop)、CREATE CONSTRAINT ON (n:Label) ASSERT n.prop IS UNIQUE;全文索引通过 db.index.fulltext.* 过程。 |
| 4.0–4.2 | 是 | 逐步引入命名索引语法(FOR … ON …),但4.2不支持CREATE FULLTEXT INDEX;全文索引仍主要用db.index.fulltext.*。 |
| 4.3–4.4 | 是 | 支持CREATE FULLTEXT INDEX;建议开始迁移至命名索引/约束风格,便于治理。 |
| 5.x(含5.16) | 是 | 统一语法:CREATE [index_type] INDEX name FOR (...) ON (...);约束:CREATE CONSTRAINT name FOR (...) REQUIRE ... IS UNIQUE;FULLTEXT支持OPTIONS与参数化创建;提供范围索引示例。 |
| 事务/并发 | 是 | 默认隔离级别READ_COMMITTED;出现死锁属可重试错误,需在应用侧实现重试与退避。 |
Neo4j 事务
为了确保数据操作的安全性和一致性,Neo4j 采用了严格的 ACID(原子性、一致性、隔离性、持久性)事务模型。以下是其事务特性的详细说明:
事务封装要求
- 所有对 Neo4j 数据库的写操作(包括创建、更新和删除节点/关系)都必须显式地封装在事务中
- 例如,在 Java API 中使用:
try (Transaction tx = graphDb.beginTx()) {// 数据库操作代码tx.success(); // 标记事务成功} // 事务自动提交或回滚
隔离级别设置
- 默认隔离级别为 READ_COMMITTED,这意味着:
- 事务只能读取已提交的数据
- 防止脏读但允许不可重复读和幻读
- 可通过配置调整隔离级别,满足不同的业务需求
死锁处理机制
Neo4j 实现了智能的死锁预防系统:
- 采用锁等待超时和死锁检测算法
- 在死锁即将发生时:
- 自动选择"牺牲者"事务
- 将该事务标记为回滚状态
- 抛出
DeadlockDetectedException异常
- 典型处理流程:
try {// 事务操作} catch (DeadlockDetectedException e) {// 等待后重试逻辑Thread.sleep(100);retryTransaction();}
- 锁释放机制确保系统不会长时间阻塞
线程安全设计
- 核心 API 已内置线程同步机制
- 开发注意事项:
- 不需要额外使用
synchronized等同步机制 - 单个事务应该在一个线程内完成
- 多个线程可以并行开启不同的事务
- 不需要额外使用
- 示例场景:Web 服务器可以安全地并行处理多个客户端请求,每个请求使用独立的事务访问数据库
这些特性共同确保了 Neo4j 在高并发环境下的数据一致性和系统稳定性,使开发者可以专注于业务逻辑而无需过度考虑底层并发控制问题。
Neo4j 索引
简介
Neo4j CQL (Cypher Query Language) 提供了强大的索引功能,允许用户在节点或关系的属性上创建索引,从而显著提升查询性能。这些索引功能是优化图形数据库操作的重要工具。
索引主要用于以下场景:
- 加速节点查找:为具有相同标签的节点属性创建索引
- 优化关系查询:在关系类型和属性上建立索引
- 提升WHERE子句性能:加速条件过滤操作
索引使用的基本原则包括:
- 为经常在WHERE、MATCH等子句中使用的属性创建索引
- 为高基数(cardinality)的属性创建索引效果更明显
- 索引会占用额外的存储空间并影响写入性能,需要权衡
在MATCH或WHERE等运算符中使用索引时,Neo4j的查询优化器会自动选择是否使用索引。例如:
CREATE INDEX ON :Person(name);
MATCH (p:Person) WHERE p.name = 'John' RETURN p;
在这个查询中,针对Person标签的name属性创建的索引会被自动使用。
索引在以下操作中特别有效:
- 精确匹配查询(=)
- 范围查询(>、<等)
- 字符串前缀匹配(STARTS WITH)
- 列表包含(IN)
需要注意的是,索引的维护是自动进行的,当相关数据被创建、更新或删除时,索引会自动同步更新。
创建单一索引
CREATE INDEX ON :LABEL
我们可以创建一个索引如下:
CREATE INDEX ON :Person(name)
创建结果如下所示:
创建复合索引
CREATE INDEX ON :Person(age, gender)
全文索引
Neo4j 全文索引是对常规索引功能的扩展和增强,它解决了传统索引在字符串搜索方面的局限性。以下是更详细的说明:
常规索引与全文索引的区别
-
常规索引(传统模式索引):
- 仅支持精确匹配(exact match)
- 有限的前缀/后缀匹配(startWith, endsWith)
- 不支持内容包含(contains)查询
- 示例:查找 name=“John Doe” 或 name STARTS WITH “John”
-
全文索引:
- 对字符串值进行标记化处理
- 支持匹配字符串中的任意位置术语
- 使用分析器(analyzer)决定如何分割字符串
- 示例:可以查找包含 “data” 或 “analysis” 的文本字段
全文索引创建方法
- 节点全文索引创建语法:
CALL db.index.fulltext.createNodeIndex("index_name", ["Label1", "Label2"], ["property1", "property2"],{analyzer: "standard"}
)
- 关系全文索引创建语法:
CALL db.index.fulltext.createRelationshipIndex("rel_index_name",["REL_TYPE1", "REL_TYPE2"],["rel_property1", "rel_property2"]
)
关键配置参数
-
索引名称:
- 必须唯一且具有描述性
- 后续通过此名称引用索引(查询/删除)
- 命名约定示例:
article_title_body_index
-
分析器配置:
- 默认使用标准分析器(standard)
- 支持的分析器类型包括:
- standard(默认)
- english(英文专用)
- whitespace(空格分隔)
- 其他语言特定分析器
-
索引范围:
- 节点索引:可指定多个标签
- 关系索引:可指定多种关系类型
- 属性列表:可索引多个属性
语法标准
语法标准如下所示:
call db.index.fulltext.createNodeIndex("索引名",[Label,Label],[属性,属性])
查看和删除索引
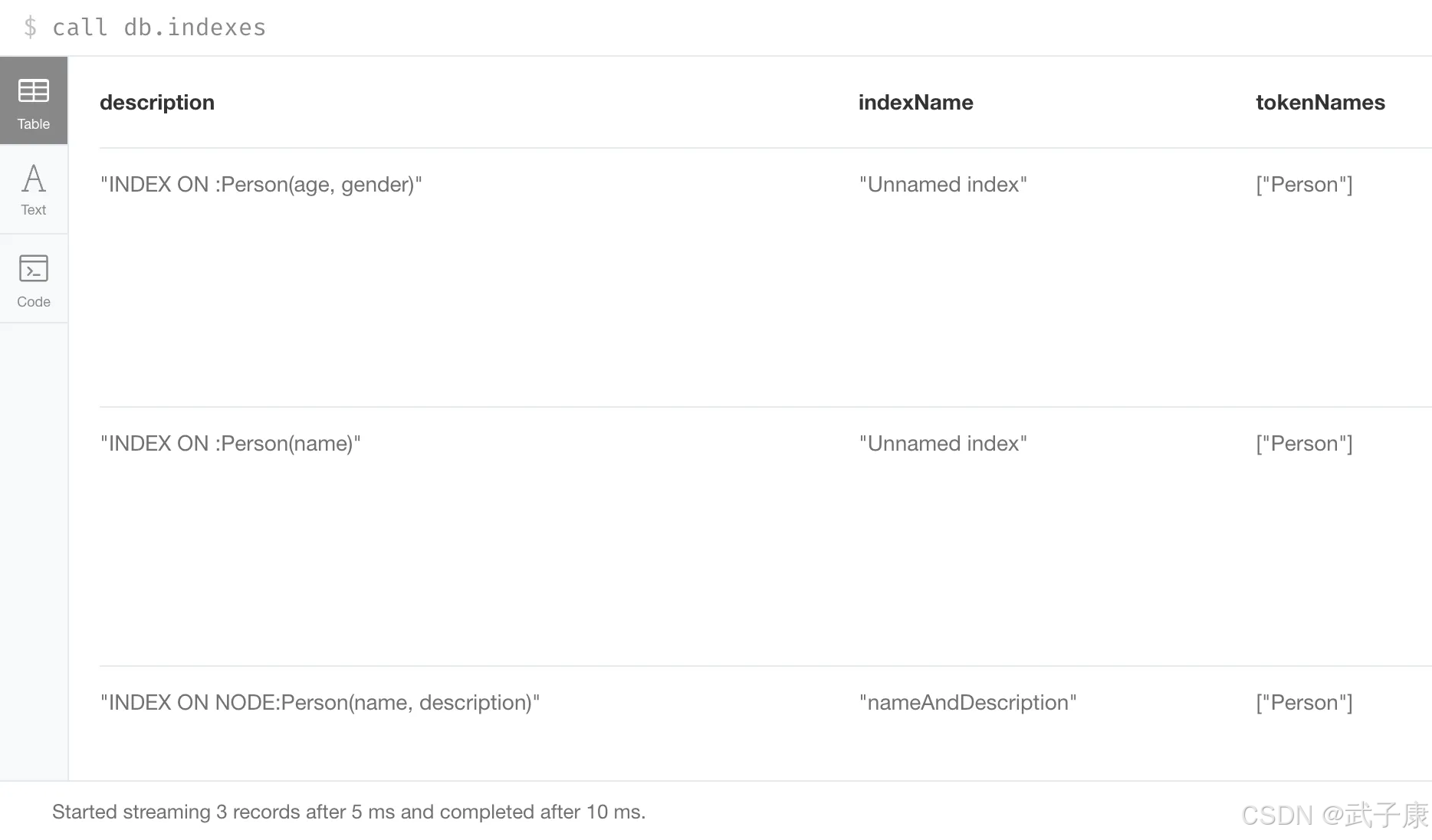
查看索引:
如果要删除掉索引的话,对应的语法如下:
DROP INDEX ON :Person(name)
DROP INDEX ON :Person(age, gender)
Neo4j 约束
唯一性约束
唯一性约束是Neo4j中用于确保数据唯一性的关键特性,它通过以下方式发挥作用:
● 避免重复记录:在指定属性上创建唯一性约束后,Neo4j会阻止在该属性上创建重复值的节点或关系。例如,在用户节点上为"email"属性创建唯一约束后,系统会确保不会有两个用户拥有相同的email地址。
● 强制执行数据完整性规则:这些约束作为数据库层面的验证机制,在数据写入时就进行校验,而不是依赖应用层验证。这能防止无效数据进入数据库,保持数据的一致性。例如,在产品目录中为"productId"创建唯一约束可确保每个产品都有唯一的标识符。
应用场景包括:
- 用户系统中确保用户名唯一
- 电商平台防止重复商品ID
- 社交网络确保用户手机号不重复
创建语法示例:
CREATE CONSTRAINT unique_user_email
FOR (user:User) REQUIRE user.email IS UNIQUE
注意事项:
- 唯一性约束会创建隐含索引提高查询性能
- 删除约束需要使用DROP CONSTRAINT命令
- 批量导入数据时需要考虑约束验证带来的性能影响
通过合理使用唯一性约束,可以显著提高数据质量和应用可靠性。
创建唯一性约束
在Neo4j图数据库中,唯一性约束用于确保特定标签节点的某个属性值是唯一的,这类似于关系型数据库中的唯一键约束。
基本语法
创建唯一性约束的基本语法如下:
CREATE CONSTRAINT ON (变量:<label_name>) ASSERT 变量.<property_name> IS UNIQUE
参数说明
<label_name>:要应用约束的节点标签名称<property_name>:要确保唯一性的属性名称变量:可选的变量名称,通常用于表示节点
示例
- 为用户节点的email属性创建唯一约束:
CREATE CONSTRAINT ON (u:User) ASSERT u.email IS UNIQUE
- 为商品节点的SKU编号创建唯一约束:
CREATE CONSTRAINT ON (p:Product) ASSERT p.sku IS UNIQUE
注意事项
- 创建约束后,尝试插入重复值会抛出异常
- 约束会在创建后自动应用到已有数据
- 约束创建是幂等操作,如果约束已存在则不会重复创建
- 删除约束使用
DROP CONSTRAINT命令
应用场景
唯一性约束常用于:
- 用户注册系统中的用户名/邮箱
- 商品管理中的商品编码
- 订单系统中的订单编号
- 身份识别系统中的身份证号
这种约束确保了业务关键数据的唯一性,防止数据重复和冲突。
PS:执行之前记得将原来的 name 索引 drop 掉:
CREATE CONSTRAINT ON (person:Person) ASSERT person.name IS UNIQUE
删除唯一性约束
DROP CONSTRAINT ON (cc:Person) ASSERT cc.name IS UNIQUE
查看约束
call db.constraints
错误速查
| 症状 | 根因定位 | 修复 |
|---|---|---|
| DeadlockDetectedException: … can’t acquire ExclusiveLock | 并发写锁冲突导致死锁 | 观察异常栈、并发写同一节点/关系的批处理;捕获后重试(指数退避)、固定写入顺序、拆小批次,必要时序列化热点更新 |
| Neo.ClientError.Statement.SyntaxError: Expected exactly one statement per query | 一次提交了多条 Cypher(分号/换行)或误把多语句拼接 | 用 EXPLAIN/PROFILE 前置检查;查看驱动打印的最终语句;将多语句拆成多次执行或用 WITH 串联为一条合法查询管线 |
| 无法创建 FULLTEXT(4.2 报错) | 版本不支持 CREATE FULLTEXT INDEX | CALL dbms.components() 查看版本;4.2 使用 db.index.fulltext.* 过程;或升级 4.3+/5.x 后改用 CREATE 语法 |
| Constraint already exists / Name already in use | 同名或同 schema 约束重复 | SHOW CONSTRAINTS / CALL db.constraints;先 DROP 再建或用 IF NOT EXISTS(5.x)并更换名称 |
| 查询走全表 / 索引未命中 | 使用 CONTAINS/正则、低基数属性、谓词不可索引 | PROFILE 看是否命中索引;用 FULLTEXT 处理模糊匹配;重写为 =/STARTS WITH/ 范围;为高基数属性建合适索引 |
| Java 写操作提示需在事务中执行 / 跨线程异常 | 未在事务中封装、单事务跨线程 | 应用日志与驱动报错;使用 try-with-resources 开启事务;单事务单线程;并发用多事务并行 |
其他系列
🚀 AI篇持续更新中(长期更新)
AI炼丹日志-29 - 字节跳动 DeerFlow 深度研究框斜体样式架 私有部署 测试上手 架构研究,持续打造实用AI工具指南!
AI-调查研究-108-具身智能 机器人模型训练全流程详解:从预训练到强化学习与人类反馈
🔗 AI模块直达链接
💻 Java篇持续更新中(长期更新)
Java-154 深入浅出 MongoDB 用Java访问 MongoDB 数据库 从环境搭建到CRUD完整示例
MyBatis 已完结,Spring 已完结,Nginx已完结,Tomcat已完结,分布式服务正在更新!深入浅出助你打牢基础!
🔗 Java模块直达链接
📊 大数据板块已完成多项干货更新(300篇):
包括 Hadoop、Hive、Kafka、Flink、ClickHouse、Elasticsearch 等二十余项核心组件,覆盖离线+实时数仓全栈!
大数据-278 Spark MLib - 基础介绍 机器学习算法 梯度提升树 GBDT案例 详解
🔗 大数据模块直达链接