开源监控体系Prometheus Thanos Grafana Alertmanager
目录
一. 简介
二. 组件介绍
Prometheus:监控的核心采集与存储引擎
Prometheus Exporter:监控数据的“出口”
Thanos:让 Prometheus 拥有“云原生大脑”
Alertmanager:智能告警与聚合管理
Alertmanager Webhook:告警的自动化中转站
Grafana:监控数据的可视化前端
三.部署及配置
Prometheus & Thanos Sidecar
Thanos Query & Thanos Store的代理
Prometheus Exporters
Grafana
Alertmanager
Alertmanager Webhook
Thanos Store & Thanos Compact
四.Web UI
Thanos Query Web UI
Prometheus Web UI
Alertmanager Web UI
Grafana Web UI
一. 简介
在现代云原生环境中,监控系统已成为保障服务稳定性和性能的核心基础设施。无论是Kubernetes 集群、微服务架构,还是传统应用迁移上云,Prometheus + Thanos + Grafana + Alertmanager 已成为事实上的标准组合。
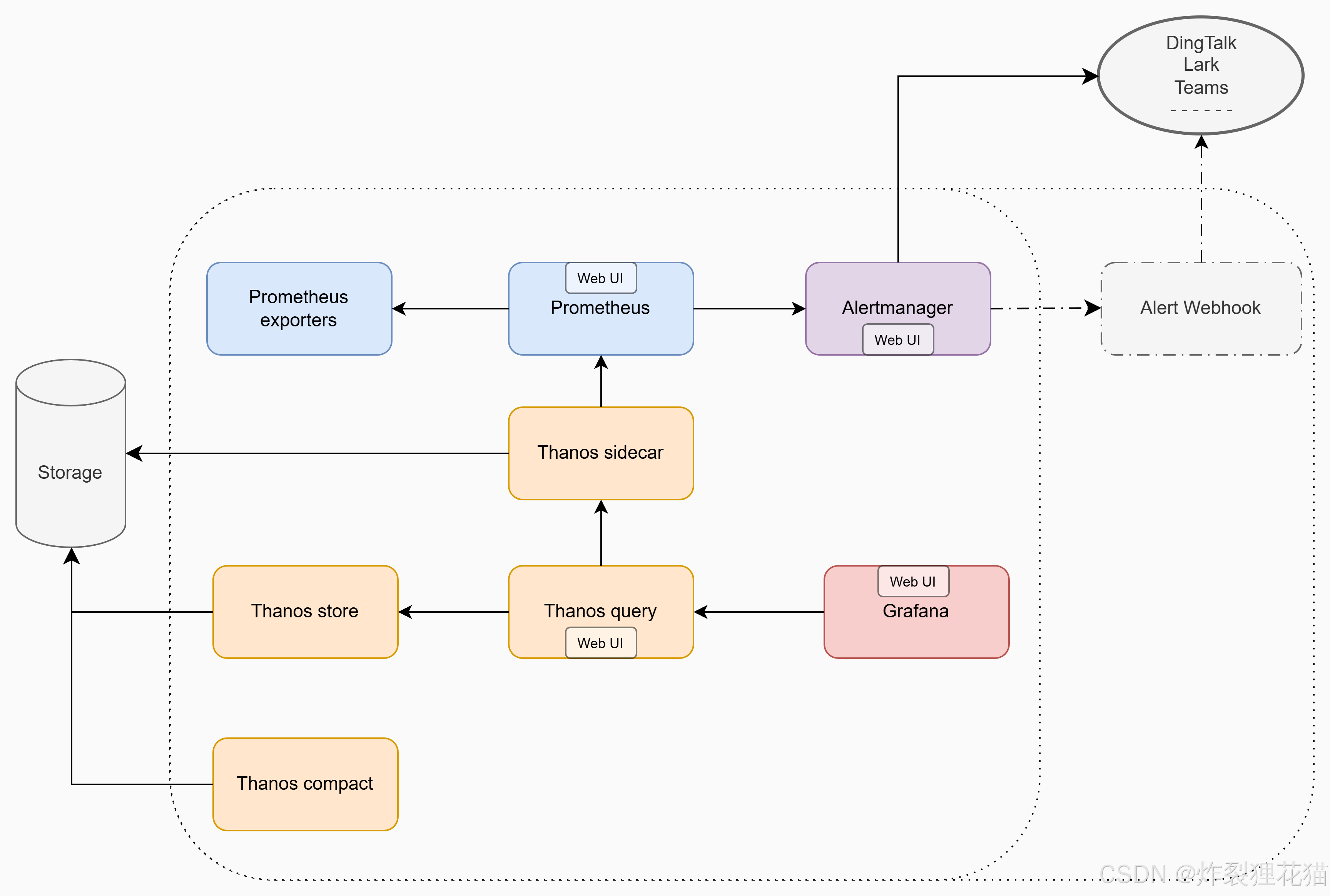
二. 组件介绍
如上图的数据访问流所示,我们围绕这一套监控体系,梳理各组件的作用、关系和常见架构思路,为大家提供一个系统性的理解。
Prometheus:监控的核心采集与存储引擎
Prometheus是整个体系的核心,主要负责:
-
周期性地拉取(Scrape)各监控目标(Targets)数据;
-
存储时间序列数据;
-
提供 PromQL 查询接口;
-
支持告警规则的评估与推送。
其特点包括:
-
Pull 模式采集:通过配置
scrape_configs定期抓取指标; -
时序数据库(TSDB):内置高性能本地存储;
-
强大的查询语言(PromQL):支持聚合、筛选、预测等多种分析;
-
无外部依赖:单个二进制文件即可运行。
Prometheus Exporter:监控数据的“出口”
Prometheus本身并不会直接采集应用程序内部指标,而是通过各种Exporter来暴露数据,由Prometheus定时通过Pull模式采集。
Prometheus Exporter常见类型包括:
-
Node Exporter:采集主机级别指标(CPU、内存、磁盘、网络);
-
Kube-State-Metrics:采集Kubernetes对象状态;
-
Blackbox Exporter:通过HTTP/ICMP等方式探测可用性;
-
自定义 Exporter:应用通过SDK或HTTP接口暴露自定义指标。
Thanos:让 Prometheus拥有“云原生大脑”
Prometheus 的一个限制是:单节点存储、无全局聚合、数据保留有限。而Thanos正是为了解决这些问题而生的。
Thanos 通过一系列组件扩展了 Prometheus 的能力:
| 组件 | 作用 |
|---|---|
| Thanos Sidecar | 部署在每个 Prometheus 旁,负责几件事: 3. |
| Thanos Store | 从对象存储读取历史数据,并提供统一查询接口。 |
| Thanos Query | 聚合多个数据源(Store + Sidecar等),实现全局查询。 |
| Thanos Compact | 对长期存储的数据进行压缩、合并、降采样,降低成本。 |
| Thanos Ruler(可选) | 支持全局层面的告警规则与录制规则执行。 |
这样,整个监控体系具备了以下能力:
-
多 Prometheus 实例统一查询
-
长期历史数据归档
-
水平扩展与多集群支持
-
云对象存储持久化
Alertmanager:智能告警与聚合管理
Alertmanager负责处理来自Prometheus的告警。其核心功能包括:
-
告警去重、分组、抑制;
-
动态路由(不同告警发送到不同的通知渠道);
-
通知集成(Email、Slack、Webhook、飞书、钉钉等);
-
与 Prometheus 联动的告警状态反馈。
通常 Prometheus会通过alerting配置将规则触发后的Alert推送给Alertmanager,后者根据路由规则执行通知。
Alertmanager Webhook:告警的自动化中转站
除了直接发送通知,Alertmanager 还可以通过Webhook将告警事件发送到外部系统。
Webhook 机制非常灵活,常用于:
-
对接自动化运维(如自动重启服务、触发脚本);
-
与告警平台对接(如企业微信、飞书机器人、自建系统);
-
记录到数据库或事件系统(如 ELK / Loki / ClickHouse)。
Webhook的核心是:“当告警发生时,调用一个外部HTTP服务,传递完整的告警内容。”
Grafana:监控数据的可视化前端
Grafana是整个体系的“展示层”。它支持直接连接Prometheus或Thanos Query,实现以下功能:
-
自定义仪表盘与多维度可视化;
-
支持 PromQL 查询与模板变量;
-
动态过滤、聚合、时间范围切换;
-
与 Alerting 集成(Grafana 8+ 内置告警功能)。
在企业中,Grafana 通常作为监控大屏、系统状态总览、运维日报的核心入口。
三.部署及配置
我们以在Kubernetes中的部署为例,把所有配置文件罗列出来,只要稍作修改即可运行。
另外,为熟悉Kubernetes的更多用法,以及分担磁盘IO压力,我们把Thanos store和Thanos compact单独部署到一台服务器上,然后用Kubernetes Service+ Endpoints做代理(当然也可以完全部署到Kubernetes中,可以自行修改部署方式)。
对Kubernetes不太熟悉的至少看完Kubernetes从零到精通(14-Storage)
Prometheus & Thanos Sidecar
apiVersion: v1
kind: ConfigMap
metadata:name: prometheus-confignamespace: thanos
data:prometheus.yaml.tmpl: |-global:scrape_interval: 30sevaluation_interval: 30sexternal_labels:cluster: oci-prometheus-haprometheus_replica: oci-$(POD_NAME)rule_files:- /etc/prometheus/rules/*rules.yamlalerting:alertmanagers:- static_configs:- targets:- alertmanager.thanos:9093alert_relabel_configs:- regex: prometheus_replicaaction: labeldropscrape_configs:- job_name: iccr-production-applications-nodes-metricsfile_sd_configs:- files:- "/etc/prometheus/targets/nodes.json"refresh_interval: 5mrelabel_configs:- target_label: providerreplacement: oci- job_name: iccr-production-kubernetes-nodes-metricskubernetes_sd_configs:- role: podrelabel_configs:- action: keepregex: truesource_labels:- __meta_kubernetes_pod_annotation_prometheus_io_scrape- action: replaceregex: (.+)source_labels:- __meta_kubernetes_pod_annotation_prometheus_io_pathtarget_label: __metrics_path__- action: replaceregex: ([^:]+)(?::\d+)?;(\d+)replacement: $1:$2source_labels:- __address__- __meta_kubernetes_pod_annotation_prometheus_io_porttarget_label: __address__- action: labelmapregex: __meta_kubernetes_pod_label_(.+)- action: replacesource_labels:- __meta_kubernetes_namespacetarget_label: kubernetes_namespace- action: replacesource_labels:- __meta_kubernetes_pod_nametarget_label: kubernetes_pod_name- target_label: providerreplacement: oci- job_name: iccr-production-kubernetes-control-plane-metricskubernetes_sd_configs:- role: nodebearer_token_file: /var/run/secrets/kubernetes.io/serviceaccount/tokenrelabel_configs:- action: labelmapregex: __meta_kubernetes_node_label_(.+)- replacement: kubernetes.default.svc:443target_label: __address__- regex: (.+)replacement: /api/v1/nodes/$1/proxy/metricssource_labels:- __meta_kubernetes_node_nametarget_label: __metrics_path__- target_label: appreplacement: iccr-production-kubernetes-nodes- target_label: providerreplacement: ocischeme: httpstls_config:ca_file: /var/run/secrets/kubernetes.io/serviceaccount/ca.crtinsecure_skip_verify: true- job_name: iccr-production-containers-metricsmetrics_path: /metrics/cadvisorscrape_interval: 10sscrape_timeout: 10sscheme: httpstls_config:insecure_skip_verify: truebearer_token_file: /var/run/secrets/kubernetes.io/serviceaccount/tokenkubernetes_sd_configs:- role: noderelabel_configs:- action: labelmapregex: __meta_kubernetes_node_label_(.+)- target_label: providerreplacement: ocimetric_relabel_configs:- source_labels: [instance]separator: ;regex: (.+)target_label: nodereplacement: $1action: replace- job_name: iccr-production-kubernetes-service-metricskubernetes_sd_configs:- role: servicemetrics_path: /probeparams:module:- tcp_connectrelabel_configs:- action: keepregex: truesource_labels:- __meta_kubernetes_service_annotation_prometheus_io_httpprobe- source_labels:- __address__target_label: __param_target- replacement: blackbox-exporter-svc:9115target_label: __address__- source_labels:- __param_targettarget_label: instance- action: labelmapregex: __meta_kubernetes_service_label_(.+)- source_labels:- __meta_kubernetes_namespacetarget_label: kubernetes_namespace- source_labels:- __meta_kubernetes_service_nametarget_label: kubernetes_name- target_label: providerreplacement: oci- job_name: iccr-production-kube-state-metricshonor_timestamps: truemetrics_path: /metricsscheme: httpstatic_configs:- targets:- kube-state-metrics:8080relabel_configs:- target_label: providerreplacement: ocimetric_relabel_configs:- target_label: clusterreplacement: iccr-production-oke- job_name: iccr-production-mysqld-metricsstatic_configs:- targets:- mysqld-exporter-svc:9104relabel_configs:- source_labels: [__address__]target_label: __param_target- source_labels: [__param_target]target_label: instance- target_label: __address__replacement: mysqld-exporter-svc:9104- target_label: providerreplacement: oci- job_name: iccr-production-redis-metricsstatic_configs:- targets:- redis://prod-redis-0:6379- redis://prod-redis-1:6379metrics_path: /scraperelabel_configs:- source_labels: [__address__]target_label: __param_target- source_labels: [__param_target]target_label: instance- target_label: __address__replacement: redis-exporter-svc:9121- target_label: providerreplacement: oci- job_name: iccr-production-kafka-metricsstatic_configs:- targets:- kafka-exporter-svc:8080relabel_configs:- target_label: providerreplacement: oci- job_name: iccr-production-zookeeper-metricsstatic_configs:- targets:- zookeeper-exporter-svc:9141relabel_configs:- target_label: providerreplacement: oci- job_name: iccr-production-nacos-metricsmetrics_path: /nacos/actuator/prometheusstatic_configs:- targets:- prod-nacos-0:8848- prod-nacos-1:8848- prod-nacos-2:8848relabel_configs:- target_label: providerreplacement: oci- job_name: blackbox-web-probescrape_interval: 1mmetrics_path: /probeparams:module:- http_2xxrelabel_configs:- source_labels:- __address__target_label: __param_target- source_labels:- __param_targettarget_label: instance- replacement: blackbox-exporter-svc.thanos:9115target_label: __address__- target_label: providerreplacement: ocistatic_configs:- targets:- https://zt.fzwtest.xyz---
apiVersion: v1
kind: ConfigMap
metadata:labels:name: prometheus-rulesname: prometheus-rulesnamespace: thanos
data:alert-rules.yaml: |-groups:- name: host_and_hardware.rulesrules:- alert: StaticInstanceTargetMissingexpr: up{instance=~".*:9100"} == 0for: 1mlabels:env: productionseverity: criticalannotations:description: "A Static Instance {{ $labels.instance }} on job {{ $labels.job }} has disappeared. Exporter might be crashed or Instance is down."- alert: HostOutOfDiskSpaceexpr: (1- node_filesystem_avail_bytes{job!="kubernetes-pods",mountpoint!~"^/(dev|proc|sys|run|var/lib/docker/|var/lib/nfs/.+)($|/).*"} / node_filesystem_size_bytes {job!="kubernetes-pods",mountpoint!~"^/(dev|proc|sys|run|var/lib/docker/|var/lib/nfs/.+)($|/).*"} ) * 100 > 80for: 5mlabels:env: productionseverity: warningannotations:description: "Node {{ $labels.instance }} on job {{ $labels.job }} disk {{ $labels.device }} is almost full (< 20% left). Current value is {{ printf \"%.0f\" $value }}%."- alert: HostOutOfMemoryexpr: node_memory_MemAvailable_bytes / node_memory_MemTotal_bytes * 100 < 10for: 1mlabels:env: productionseverity: criticalannotations:description: "Node {{ $labels.instance }} on job {{ $labels.job }} memory is filling up (< 10% left). Current value is {{ printf \"%.0f\" $value }}%."- alert: HostUnusualDiskReadRateexpr: sum by (instance,job) (rate(node_disk_read_bytes_total[2m])) / 1024 / 1024 > 50for: 5mlabels:env: productionseverity: warningannotations:description: "Node {{ $labels.instance }} on job {{ $labels.job }} disk is probably reading too much data (> 50 MB/s). Current value is {{ printf \"%.0f\" $value }}MB/s."- alert: HostUnusualDiskWriteRateexpr: sum by (instance,job) (rate(node_disk_written_bytes_total[2m])) / 1024 / 1024 > 50for: 5mlabels:env: productionseverity: warningannotations:description: "Node {{ $labels.instance }} on job {{ $labels.job }} disk is probably writing too much data (> 50 MB/s). Current value is {{ printf \"%.0f\" $value }}MB/s."- alert: HostUnusualDiskReadLatencyexpr: rate(node_disk_read_time_seconds_total{instance!="prod-monitoring-system-thanos-store-0:9100"}[1m]) / rate(node_disk_reads_completed_total{instance!="prod-monitoring-system-thanos-store-0:9100"}[1m]) > 0 and rate(node_disk_reads_completed_total{instance!="prod-monitoring-system-thanos-store-0:9100"}[1m]) > 0for: 5mlabels:env: productionseverity: warningannotations:description: "Node {{ $labels.instance }} on job {{ $labels.job }} disk latency is growing (read operations > 100ms). Current value is {{ printf \"%.0f\" $value }}."- alert: HostUnusualDiskWriteLatencyexpr: rate(node_disk_write_time_seconds_total{instance!="prod-monitoring-system-thanos-store-0:9100"}[1m]) / rate(node_disk_writes_completed_total{instance!="prod-monitoring-system-thanos-store-0:9100"}[1m]) > 0.1 and rate(node_disk_writes_completed_total{instance!="prod-monitoring-system-thanos-store-0:9100"}[1m]) > 0for: 5mlabels:env: productionseverity: warningannotations:description: "Node {{ $labels.instance }} on job {{ $labels.job }} disk latency is growing (write operations > 100ms). Current value is {{ printf \"%.0f\" $value }}."- alert: HostHighCpuLoadexpr: 100 - (avg by(instance,job) (rate(node_cpu_seconds_total{mode="idle"}[2m])) * 100) > 80for: 5mlabels:env: productionseverity: warningannotations:description: "Node {{ $labels.instance }} on job {{ $labels.job }} CPU load is > 80%. Current value is {{ printf \"%.0f\" $value }}%"- alert: HostConntrackLimitexpr: node_nf_conntrack_entries / node_nf_conntrack_entries_limit > 0.8for: 5mlabels:env: productionseverity: warningannotations:description: "The number of conntrack is approching limit on node {{ $labels.instance }} of job {{ $labels.job }}. Current value is {{ printf \"%.0f\" $value }}."- alert: HostMemoryUnderMemoryPressureexpr: rate(node_vmstat_pgmajfault[1m]) > 1000for: 5mlabels:env: productionseverity: warningannotations:description: "Node {{ $labels.instance }} on job {{ $labels.job }} is under heavy memory pressure. High rate of major page faults."- alert: HostUnusualNetworkThroughputInexpr: sum by (instance,job) (rate(node_network_receive_bytes_total[2m])) / 1024 / 1024 > 100for: 5mlabels:env: productionseverity: warningannotations:description: "Node {{ $labels.instance }} on job {{ $labels.job }} network interfaces are probably receiving too much data (> 100 MB/s). Current value is {{ printf \"%.0f\" $value }}."- alert: HostUnusualNetworkThroughputOutexpr: sum by (instance,job) (rate(node_network_transmit_bytes_total[2m])) / 1024 / 1024 > 100for: 5mlabels:env: productionseverity: warningannotations:description: "Node {{ $labels.instance }} on job {{ $labels.job }} network interfaces are probably sending too much data (> 100 MB/s). Current value is {{ printf \"%.0f\" $value }}."- alert: HostCpuStealNoisyNeighborexpr: avg by(instance,job) (rate(node_cpu_seconds_total{mode="steal"}[5m])) * 100 > 30for: 5mlabels:env: productionseverity: warningannotations:description: "Node {{ $labels.instance }} on job {{ $labels.job }} CPU steal is > 30%. A noisy neighbor is killing VM performances or a spot instance may be out of credit. Current value is {{ printf \"%.0f\" $value }}%."- alert: HostOomKillDetectedexpr: increase(node_vmstat_oom_kill[1m]) > 3for: 0mlabels:env: productionseverity: warningannotations:description: "Node {{ $labels.instance }} on job {{ $labels.job }} OOM kill detected."- alert: HostNetworkTransmitErrorsexpr: rate(node_network_transmit_errs_total{device=~"ens[3|5]"}[2m]) / rate(node_network_transmit_packets_total{device=~"ens[3|5]"}[2m]) > 0.01for: 2mlabels:env: productionseverity: warningannotations:description: "Node {{ $labels.instance }} on job {{ $labels.job }} interface {{ $labels.device }} has encountered {{ printf \"%.0f\" $value }} transmit errors in the last two minutes."- alert: WebsiteDownexpr: probe_success != 1for: 3mlabels:env: productionseverity: criticalannotations:summary: "Website {{ $labels.instance }} is unavailable"description: "Blackbox probe failed for {{ $labels.instance }} in {{ $labels.kubernetes_namespace }}"---
apiVersion: v1
kind: ConfigMap
metadata:name: prometheus-targetsnamespace: thanos
data:nodes.json: |-[{"targets": ["prod-kafka-0:9100", "prod-kafka-1:9100", "prod-kafka-2:9100"],"labels": {"app": "iccr-production-kafka-nodes"}},{"targets": ["prod-zookeeper-0:9100", "prod-zookeeper-1:9100", "prod-zookeeper-2:9100"],"labels": {"app": "iccr-production-zookeeper-nodes"}},{"targets": ["prod-nacos-0:9100", "prod-nacos-1:9100", "prod-nacos-2:9100"],"labels": {"app": "iccr-production-nacos-nodes"}},{"targets": ["prod-redis-0:9100", "prod-redis-1:9100"],"labels": {"app": "iccr-production-redis-nodes"}},{"targets": ["prod-monitoring-system-thanos-store-0:9100"],"labels": {"app": "monitoring-system-nodes"}}]---
apiVersion: v1
kind: ServiceAccount
metadata:name: prometheusnamespace: thanos---
apiVersion: rbac.authorization.k8s.io/v1
kind: ClusterRole
metadata:name: prometheusnamespace: thanos
rules:
- apiGroups: [""]resources:- nodes- nodes/proxy- nodes/metrics- services- endpoints- podsverbs: ["get", "list", "watch"]
- apiGroups: [""]resources: ["configmaps"]verbs: ["get"]
- nonResourceURLs: ["/metrics"]verbs: ["get"]---
apiVersion: rbac.authorization.k8s.io/v1
kind: ClusterRoleBinding
metadata:name: prometheus
subjects:- kind: ServiceAccountname: prometheusnamespace: thanos
roleRef:kind: ClusterRolename: prometheusapiGroup: rbac.authorization.k8s.io---
apiVersion: apps/v1
kind: StatefulSet
metadata:name: prometheusnamespace: thanoslabels:app.kubernetes.io/name: prometheus
spec:serviceName: prometheus-svcpodManagementPolicy: Parallelreplicas: 1selector:matchLabels:app.kubernetes.io/name: prometheustemplate:metadata:labels:app.kubernetes.io/name: prometheusspec:serviceAccountName: prometheussecurityContext:fsGroup: 2000runAsNonRoot: truerunAsUser: 1000affinity:podAntiAffinity:requiredDuringSchedulingIgnoredDuringExecution:- labelSelector:matchExpressions:- key: app.kubernetes.io/nameoperator: Invalues:- prometheustopologyKey: kubernetes.io/hostnamehostAliases:- ip: "10.x.x.x"hostnames:- "prod-kafka-0"- ip: "10.x.x.x"hostnames:- "prod-kafka-1"- ip: "10.x.x.x"hostnames:- "prod-kafka-2"- ip: "10.x.x.x"hostnames:- "prod-nacos-0"- ip: "10.x.x.x"hostnames:- "prod-nacos-1"- ip: "10.x.x.x"hostnames:- "prod-nacos-2"- ip: "10.x.x.x"hostnames:- "prod-redis-0"- ip: "10.x.x.x"hostnames:- "prod-redis-1"- ip: "10.x.x.x"hostnames:- "prod-zookeeper-0"- ip: "10.x.x.x"hostnames:- "prod-zookeeper-1"- ip: "10.x.x.x"hostnames:- "prod-zookeeper-2"- ip: "10.x.x.x"hostnames:- "prod-monitoring-system-thanos-store-0"containers:- name: prometheusimage: quay.io/prometheus/prometheus:v3.5.0args:- --config.file=/etc/prometheus/config_out/prometheus.yaml- --storage.tsdb.path=/prometheus- --storage.tsdb.retention.time=6h- --storage.tsdb.no-lockfile- --storage.tsdb.min-block-duration=2h- --storage.tsdb.max-block-duration=2h- --web.enable-admin-api- --web.enable-lifecycle- --web.route-prefix=/resources:requests:memory: "2Gi"cpu: "1000m"limits:memory: "4Gi"cpu: "2000m"ports:- containerPort: 9090name: webprotocol: TCPvolumeMounts:- name: prometheus-config-outmountPath: /etc/prometheus/config_out- name: prometheus-rulesmountPath: /etc/prometheus/rules- name: prometheus-targetsmountPath: /etc/prometheus/targets- name: prometheus-storagemountPath: /prometheus- name: thanos-sidecarimage: quay.io/thanos/thanos:v0.39.2args:- sidecar- --tsdb.path=/prometheus- --prometheus.url=http://127.0.0.1:9090- --objstore.config-file=/etc/thanos/objectstorage.yaml- --reloader.config-file=/etc/prometheus/config/prometheus.yaml.tmpl- --reloader.config-envsubst-file=/etc/prometheus/config_out/prometheus.yaml- --reloader.rule-dir=/etc/prometheus/rules/- --grpc-address=0.0.0.0:10901- --http-address=0.0.0.0:10902env:- name: POD_NAMEvalueFrom:fieldRef:fieldPath: metadata.nameports:- name: http-sidecarcontainerPort: 10902- name: grpccontainerPort: 10901livenessProbe:httpGet:port: 10902path: /-/healthyreadinessProbe:httpGet:port: 10902path: /-/readyvolumeMounts:- name: prometheus-config-tmplmountPath: /etc/prometheus/config- name: prometheus-config-outmountPath: /etc/prometheus/config_out- name: prometheus-targetsmountPath: /etc/prometheus/targets- name: prometheus-rulesmountPath: /etc/prometheus/rules- name: prometheus-storagemountPath: /prometheus- name: thanos-objectstorage-secretsubPath: objectstorage.yamlmountPath: /etc/thanos/objectstorage.yamlvolumes:- name: prometheus-config-tmplconfigMap:name: prometheus-config- name: prometheus-config-outemptyDir: {}- name: prometheus-rulesconfigMap:name: prometheus-rules- name: prometheus-targetsconfigMap:name: prometheus-targets- name: thanos-objectstorage-secretsecret:secretName: thanos-objectstorage-secretvolumeClaimTemplates:- metadata:name: prometheus-storagelabels:app.kubernetes.io/name: prometheusannotations:volume.beta.kubernetes.io/storage-class: oci-bvspec:accessModes:- ReadWriteOnceresources:requests:storage: 50GivolumeMode: Filesystem---
kind: Service
apiVersion: v1
metadata:name: prometheus-svcnamespace: thanoslabels:app.kubernetes.io/name: prometheus
spec:type: ClusterIPclusterIP: Noneselector:app.kubernetes.io/name: prometheusports:- name: webprotocol: TCPport: 9090targetPort: web---
kind: Service
apiVersion: v1
metadata:name: thanos-sidecar-svcnamespace: thanoslabels:app.kubernetes.io/name: prometheus
spec:selector:app.kubernetes.io/name: prometheustype: ClusterIPclusterIP: Noneports:- name: grpcport: 10901targetPort: grpc
Thanos Query & Thanos Store的代理
apiVersion: v1
kind: Secret
metadata:name: thanos-objectstorage-secretnamespace: thanos
type: Opaque
stringData:objectstorage.yaml: |type: OCIconfig:provider: "raw"bucket: "prd-monitoring-system-oci"compartment_ocid: "ocid1.compartment.oc1..xxxxxxxxx"tenancy_ocid: "ocid1.tenancy.oc1..xxxxxxxx"user_ocid: "ocid1.user.oc1..xxxxxxxx"region: "ap-singapore-1"fingerprint: "xx:xx:xx:xx:xx:xx:xx:xx:xx:xx:xx:xx:xx:xx:xx:xx"privatekey: "-----BEGIN PRIVATE KEY-----\nxxxxxxxxx\n-----END PRIVATE KEY-----\n"---
apiVersion: v1
kind: Endpoints
metadata:name: thanos-store-svcnamespace: thanos
subsets:
- addresses:- ip: 10.1.10.191ports:- name: thanos-store-grpcport: 10911protocol: TCP
---
apiVersion: v1
kind: Service
metadata:labels:app: thanos-storename: thanos-store-svcnamespace: thanos
spec:type: ClusterIPclusterIP: Noneports:- name: thanos-store-grpcport: 10911targetPort: 10911---
apiVersion: apps/v1
kind: Deployment
metadata:name: thanos-querynamespace: thanoslabels:app: thanos-query
spec:replicas: 1selector:matchLabels:app: thanos-querytemplate:metadata:labels:app: thanos-queryspec:affinity:podAntiAffinity:preferredDuringSchedulingIgnoredDuringExecution:- podAffinityTerm:labelSelector:matchExpressions:- key: appoperator: Invalues:- thanos-querytopologyKey: kubernetes.io/hostnameweight: 100containers:- name: thanos-queryimage: quay.io/thanos/thanos:v0.39.2args:- query- --query.auto-downsampling- --grpc-address=0.0.0.0:10901- --http-address=0.0.0.0:10903- --query.partial-response- --query.replica-label=prometheus_replica- --endpoint=dnssrv+_grpc._tcp.thanos-sidecar-svc.thanos:10901- --endpoint=dnssrv+_thanos-store-grpc._tcp.thanos-store-svc.thanoslivenessProbe:failureThreshold: 4httpGet:path: /-/healthyport: 10903scheme: HTTPperiodSeconds: 30ports:- containerPort: 10901name: grpc- containerPort: 10903name: httpresources:requests:memory: "1Gi"cpu: "250m"limits:memory: "2Gi"cpu: "1000m"readinessProbe:failureThreshold: 20httpGet:path: /-/readyport: 10903scheme: HTTPperiodSeconds: 5terminationMessagePolicy: FallbackToLogsOnErrorterminationGracePeriodSeconds: 120---
apiVersion: v1
kind: Service
metadata:name: thanos-query-svcnamespace: thanoslabels:app: thanos-query-svc
spec:ports:- name: grpcport: 10901targetPort: grpc- name: httpport: 10903targetPort: httpselector:app: thanos-query---
apiVersion: v1
kind: Service
metadata:name: thanos-querynamespace: thanoslabels:app: thanos-query
spec:ports:- name: grpcport: 10901targetPort: grpc- name: httpport: 10903targetPort: httpnodePort: 30090selector:app: thanos-querytype: NodePort
Prometheus Exporters
apiVersion: apps/v1
kind: DaemonSet
metadata:name: node-exporternamespace: thanoslabels:app: node-exporter
spec:selector:matchLabels:app: node-exportertemplate:metadata:labels:app: node-exporterannotations:prometheus.io/scrape: "true"prometheus.io/port: "9100"spec:hostPID: truehostIPC: truehostNetwork: truecontainers:- name: node-exporterimage: prom/node-exporter:v1.6.0args:- --path.procfs=/host/proc- --path.sysfs=/host/sys- --collector.filesystem.ignored-mount-points=^/(sys|proc|dev|run|rootfs)($|/)- --collector.filesystem.ignored-fs-types="^(autofs|binfmt_misc|cgroup|configfs|debugfs|devpts|devtmpfs|fusectl|hugetlbfs|mqueue|overlay|proc|procfs|pstore|rpc_pipefs|securityfs|sysfs|tracefs)$"- --collector.diskstats.ignored-devices="^(ram|loop|fd|nsfs|tmpfs|(h|s|v|xv)d[a-z]|nvme\\d+n\\d+p)\\d+$"ports:- containerPort: 9100protocol: TCPresources:limits:cpu: 100mmemory: 100Mirequests:cpu: 10mmemory: 100MivolumeMounts:- name: devmountPath: /host/dev- name: procmountPath: /host/proc- name: sysmountPath: /host/sys- name: rootfsmountPath: /rootfsvolumes:- name: prochostPath:path: /proc- name: devhostPath:path: /dev- name: syshostPath:path: /sys- name: rootfshostPath:path: /
---
apiVersion: v1
kind: Service
metadata:annotations:prometheus.io/scrape: "true"name: node-exporter-svcnamespace: thanoslabels:app: node-exporter
spec:ports:- name: metricsport: 9100protocol: TCPtargetPort: 9100nodePort: 31000selector:app: node-exportersessionAffinity: Nonetype: NodePort---
apiVersion: rbac.authorization.k8s.io/v1
kind: ClusterRoleBinding
metadata:name: kube-state-metrics
roleRef:apiGroup: rbac.authorization.k8s.iokind: ClusterRolename: kube-state-metrics
subjects:
- kind: ServiceAccountname: kube-state-metricsnamespace: thanos
---
apiVersion: rbac.authorization.k8s.io/v1
kind: ClusterRole
metadata:name: kube-state-metrics
rules:
- apiGroups: [""]resources:- configmaps- secrets- nodes- pods- services- resourcequotas- replicationcontrollers- limitranges- persistentvolumeclaims- persistentvolumes- namespaces- endpointsverbs: ["list", "watch"]
- apiGroups: ["extensions"]resources:- daemonsets- deployments- replicasetsverbs: ["list", "watch"]
- apiGroups: ["apps"]resources:- statefulsetsverbs: ["list", "watch"]
- apiGroups: ["batch"]resources:- cronjobs- jobsverbs: ["list", "watch"]
- apiGroups: ["autoscaling"]resources:- horizontalpodautoscalersverbs: ["list", "watch"]
---
apiVersion: rbac.authorization.k8s.io/v1
kind: RoleBinding
metadata:name: kube-state-metricsnamespace: thanos
roleRef:apiGroup: rbac.authorization.k8s.iokind: Rolename: kube-state-metrics-resizer
subjects:
- kind: ServiceAccountname: kube-state-metricsnamespace: thanos
---
apiVersion: rbac.authorization.k8s.io/v1
kind: Role
metadata:namespace: thanosname: kube-state-metrics-resizer
rules:
- apiGroups: [""]resources:- podsverbs: ["get"]
- apiGroups: ["extensions"]resources:- deploymentsresourceNames: ["kube-state-metrics"]verbs: ["get", "update"]
---
apiVersion: v1
kind: ServiceAccount
metadata:name: kube-state-metricsnamespace: thanos
---
apiVersion: apps/v1
kind: Deployment
metadata:name: kube-state-metricsnamespace: thanos
spec:selector:matchLabels:app: kube-state-metricsreplicas: 1template:metadata:labels:app: kube-state-metricsspec:serviceAccountName: kube-state-metricscontainers:- name: kube-state-metricsimage: registry.k8s.io/kube-state-metrics/kube-state-metrics:v2.9.2ports:- name: http-metricscontainerPort: 8080- name: telemetrycontainerPort: 8081readinessProbe:httpGet:path: /healthzport: 8080initialDelaySeconds: 5timeoutSeconds: 5---
apiVersion: v1
kind: Service
metadata:name: kube-state-metricsnamespace: thanoslabels:app: kube-state-metricsannotations:prometheus.io/scrape: 'true'
spec:ports:- name: http-metricsport: 8080targetPort: http-metricsprotocol: TCP- name: telemetryport: 8081targetPort: telemetryprotocol: TCPselector:app: kube-state-metrics---
apiVersion: v1
kind: ConfigMap
metadata:name: blackbox-exporter-configmapnamespace: thanoslabels:app: blackbox-exporter-configmap
data:config.yml: |modules:http_2xx:prober: httptimeout: 30shttp:valid_http_versions: ["HTTP/1.1", "HTTP/2.0"]valid_status_codes: [] # Defaults to 2xxmethod: GETno_follow_redirects: falsefail_if_ssl: falsefail_if_not_ssl: falsepreferred_ip_protocol: "ip4" # defaults to "ip6"tcp_connect:prober: tcptimeout: 30sdns:prober: dnsdns:transport_protocol: "tcp" # 默认是 udppreferred_ip_protocol: "ip4" # 默认是 ip6query_name: "kubernetes.default.svc.cluster.local"http_actuator:prober: httptimeout: 30shttp:valid_http_versions: ["HTTP/1.1", "HTTP/2.0"]valid_status_codes: [] # Defaults to 2xxmethod: GETno_follow_redirects: falsefail_if_ssl: falsefail_if_not_ssl: falsepreferred_ip_protocol: "ip4" # defaults to "ip6"fail_if_body_not_matches_regexp:- "UP"
---
apiVersion: apps/v1
kind: Deployment
metadata:name: blackbox-exporternamespace: thanoslabels:app: blackbox-exporter
spec:replicas: 1selector:matchLabels:app: blackbox-exportertemplate:metadata:labels:app: blackbox-exporterspec:containers:- name: blackbox-exporterimage: prom/blackbox-exporterimagePullPolicy: IfNotPresentvolumeMounts:- name: blackbox-exporter-configmountPath: /etc/blackbox_exporter/ports:- name: httpcontainerPort: 9115volumes:- name: blackbox-exporter-configconfigMap:name: blackbox-exporter-configmap---
apiVersion: v1
kind: Service
metadata:name: blackbox-exporter-svcnamespace: thanoslabels:app: blackbox-exporter-svc
spec:ports:- name: httpport: 9115protocol: TCPtargetPort: 9115selector:app: blackbox-exporter---
apiVersion: apps/v1
kind: Deployment
metadata:name: kafka-exporternamespace: thanoslabels:app: kafka-exporter
spec:replicas: 1selector:matchLabels:app: kafka-exportertemplate:metadata:labels:app: kafka-exporterspec:hostAliases:- hostnames:- prod-kafka-0ip: 10.x.x.x- hostnames:- prod-kafka-1ip: 10.x.x.x- hostnames:- prod-kafka-2ip: 10.x.x.xcontainers:- image: redpandadata/kminion:v2.2.3imagePullPolicy: IfNotPresentname: kafka-exporterports:- containerPort: 8080env:- name: KAFKA_BROKERSvalue: prod-kafka-0:9092restartPolicy: Always---
apiVersion: v1
kind: Service
metadata:name: kafka-exporter-svcnamespace: thanoslabels:app: kafka-exporter-svc
spec:ports:- port: 8080targetPort: 8080selector:app: kafka-exporter---
apiVersion: apps/v1
kind: Deployment
metadata:name: mysqld-exporternamespace: thanoslabels:app: mysqld-exporter
spec:replicas: 1selector:matchLabels:app: mysqld-exportertemplate:metadata:labels:app: mysqld-exporterspec:securityContext:fsGroup: 2000runAsNonRoot: truerunAsUser: 1000containers:- name: mysqld-exporterimage: prom/mysqld-exporter:v0.12.1imagePullPolicy: IfNotPresentargs:- --collect.info_schema.tables- --collect.info_schema.innodb_metrics- --collect.global_status- --collect.global_variables- --collect.slave_status- --collect.info_schema.processlist- --collect.perf_schema.tablelocks- --collect.perf_schema.eventsstatements- --collect.perf_schema.eventsstatementssum- --collect.perf_schema.eventswaits- --collect.auto_increment.columns- --collect.binlog_size- --collect.perf_schema.tableiowaits- --collect.perf_schema.indexiowaits- --collect.info_schema.userstats- --collect.info_schema.clientstats- --collect.info_schema.tablestats- --collect.info_schema.schemastats- --collect.perf_schema.file_events- --collect.perf_schema.file_instances- --collect.info_schema.innodb_cmp- --collect.info_schema.innodb_cmpmem- --collect.info_schema.query_response_time- --collect.engine_innodb_statusenv:- name: DATA_SOURCE_NAMEvalue: "exporter:xxxxx@@(10.x.x.x:3306)/"ports:- containerPort: 9104name: httpprotocol: TCP
---
apiVersion: v1
kind: Service
metadata:name: mysqld-exporter-svcnamespace: thanoslabels:app: mysqld-exporter-svc
spec:selector:app: mysqld-exporterports:- name: httpport: 9104targetPort: http---
apiVersion: apps/v1
kind: Deployment
metadata:name: zookeeper-exporternamespace: thanoslabels:app: zookeeper-exporter
spec:replicas: 1selector:matchLabels:app: zookeeper-exportertemplate:metadata:labels:app: zookeeper-exporterspec:hostAliases:- hostnames:- prod-zookeeper-0ip: 10.x.x.x- hostnames:- prod-zookeeper-1ip: 10.x.x.x- hostnames:- prod-zookeeper-2ip: 10.x.x.xcontainers:- name: zookeeper-exporterimage: dabealu/zookeeper-exporter:latestimagePullPolicy: IfNotPresentports:- containerPort: 9141args: ["-zk-hosts","prod-zookeeper-0:2181,prod-zookeeper-1:2181,prod-zookeeper-2:2181"]restartPolicy: Always---
apiVersion: v1
kind: Service
metadata:name: zookeeper-exporter-svcnamespace: thanoslabels:app: zookeeper-exporter-svc
spec:ports:- port: 9141targetPort: 9141selector:app: zookeeper-exporter
---
apiVersion: apps/v1
kind: Deployment
metadata:name: redis-exporternamespace: thanoslabels:app: redis-exporter
spec:replicas: 1selector:matchLabels:app: redis-exportertemplate:metadata:labels:app: redis-exporterspec:hostAliases:- hostnames: - "prod-redis-0"ip: "10.x.x.x"- hostnames:- "prod-redis-1"ip: "10.x.x.x"containers:- name: redis-exporterimage: oliver006/redis_exporter:latestports:- name: httpprotocol: TCPcontainerPort: 9121securityContext:runAsUser: 1000runAsGroup: 2000allowPrivilegeEscalation: false---
apiVersion: v1
kind: Service
metadata:name: redis-exporter-svcnamespace: thanoslabels:app: redis-exporter-svc
spec:selector:app: redis-exporterports:- name: httpport: 9121targetPort: httpGrafana
apiVersion: v1
kind: ConfigMap
metadata:labels:app: grafananame: grafana-cmnamespace: thanos
data:dashboardproviders.yaml: |apiVersion: 1providers:- disableDeletion: falseeditable: truefolder: ""name: defaultoptions:path: /var/lib/grafana/dashboards/defaultorgId: 1type: filegrafana.ini: |[analytics]check_for_updates = true[log]mode = console[paths]data = /var/lib/grafana/logs = /var/log/grafanaplugins = /var/lib/grafana/pluginsprovisioning = /etc/grafana/provisioningplugins: digrich-bubblechart-panel,grafana-clock-panel---
apiVersion: v1
kind: PersistentVolumeClaim
metadata:labels:app: grafananame: grafana-pvcnamespace: thanos
spec:accessModes:- ReadWriteOnceresources:requests:storage: 50GistorageClassName: oci-bv---
apiVersion: v1
kind: Secret
metadata:labels:app: grafananame: grafana-secretnamespace: thanos
type: Opaque
data:admin-password: xxxxxxxxxadmin-user: YWRtaW4=---
apiVersion: apps/v1
kind: Deployment
metadata:name: grafananamespace: thanoslabels:app: grafana
spec:replicas: 1selector:matchLabels:app: grafanatemplate:metadata:labels:app: grafanaspec:containers:- name: grafanaimage: grafana/grafana:10.0.0imagePullPolicy: IfNotPresentenv:- name: GF_SECURITY_ADMIN_USERvalueFrom:secretKeyRef:name: grafana-secretkey: admin-user- name: GF_SECURITY_ADMIN_PASSWORDvalueFrom:secretKeyRef:name: grafana-secretkey: admin-password- name: GF_INSTALL_PLUGINSvalueFrom:configMapKeyRef:name: grafana-cmkey: plugins- name: GF_PATHS_DATAvalue: /var/lib/grafana/- name: GF_PATHS_LOGSvalue: /var/log/grafana- name: GF_PATHS_PLUGINSvalue: /var/lib/grafana/plugins- name: GF_PATHS_PROVISIONINGvalue: /etc/grafana/provisioninglivenessProbe:failureThreshold: 10httpGet:path: /api/healthport: 3000scheme: HTTPinitialDelaySeconds: 60periodSeconds: 10successThreshold: 1timeoutSeconds: 30ports:- containerPort: 80name: serviceprotocol: TCP- containerPort: 3000name: grafanaprotocol: TCPreadinessProbe:failureThreshold: 3httpGet:path: /api/healthport: 3000scheme: HTTPperiodSeconds: 10successThreshold: 1timeoutSeconds: 1resources:requests:cpu: 100mmemory: 128MiterminationMessagePath: /dev/termination-logvolumeMounts:- name: grafana-configmountPath: /etc/grafana/grafana.inisubPath: grafana.ini- name: grafana-config mountPath: /etc/grafana/provisioning/dashboards/dashboardproviders.yamlsubPath: dashboardproviders.yaml- name: storagemountPath: /var/lib/grafana initContainers:- command:- chown- -R- 472:472- /var/lib/grafanaimage: busybox:1.31.1imagePullPolicy: IfNotPresentname: init-chown-dataterminationMessagePath: /dev/termination-logvolumeMounts:- name: storagemountPath: /var/lib/grafanavolumes:- name: grafana-configconfigMap:name: grafana-cmdefaultMode: 420- name: storagepersistentVolumeClaim:claimName: grafana-pvc---
apiVersion: v1
kind: Service
metadata:labels:app: grafananame: grafana-svcnamespace: thanos
spec:selector:app: grafanaports:- name: serviceport: 80protocol: TCPtargetPort: 3000Alertmanager
apiVersion: v1
kind: Secret
metadata:name: alertmanager-confignamespace: thanos
type: Opaque
stringData:alertmanager.yaml: |global:resolve_timeout: 5mroute:receiver: "lark"group_by: ['alertname', 'instance']group_wait: 30sgroup_interval: 5mrepeat_interval: 3hreceivers:- name: "lark"webhook_configs:- url: "http://alertmanager-lark-relay.thanos:5001/"send_resolved: true---
apiVersion: apps/v1
kind: Deployment
metadata:name: alertmanager-lark-relaynamespace: thanos
spec:replicas: 1selector:matchLabels:app: alertmanager-lark-relaytemplate:metadata:labels:app: alertmanager-lark-relayspec:imagePullSecrets:- name: oci-container-registrycontainers:- name: relayimage: ap-singapore-1.ocir.io/ax3k1k204hy5/ctx-infra-images:1.2-29.alertmanager-lark-relayimagePullPolicy: IfNotPresentports:- containerPort: 5001env:- name: LARK_WEBHOOKvalue: "https://open.larksuite.com/open-apis/bot/v2/hook/xxxxxxxx"
---
apiVersion: v1
kind: Service
metadata:name: alertmanager-lark-relaynamespace: thanos
spec:selector:app: alertmanager-lark-relayports:- protocol: TCPport: 5001targetPort: 5001
---
apiVersion: apps/v1
kind: Deployment
metadata:name: alertmanagernamespace: thanoslabels:app: alertmanager
spec:replicas: 1selector:matchLabels:app: alertmanagertemplate:metadata:labels:app: alertmanagerspec:containers:- name: alertmanagerimage: prom/alertmanager:v0.27.0args:- "--config.file=/etc/alertmanager/alertmanager.yaml"- "--storage.path=/alertmanager"- "--web.listen-address=:9093"ports:- name: webcontainerPort: 9093volumeMounts:- name: configmountPath: /etc/alertmanager- name: storagemountPath: /alertmanagervolumes:- name: configsecret:secretName: alertmanager-config- name: storageemptyDir: {}
---
apiVersion: v1
kind: Service
metadata:name: alertmanagernamespace: thanoslabels:app: alertmanager
spec:type: ClusterIPports:- name: webport: 9093targetPort: 9093selector:app: alertmanager
Alertmanager Webhook
由于Alertmanager的告警JSON格式跟Lark的Webhook的接口格式不匹配,所以我们自己写一个Webhook来中转告警数据:
1.Python示例app.py:
from flask import Flask, request
import requests
import datetimeapp = Flask(__name__)# ✅ 替换成你的Lark机器人Webhook
LARK_WEBHOOK = "https://open.larksuite.com/open-apis/bot/v2/hook/xxxxxx"@app.route("/", methods=["POST"])
def relay():data = request.json or {}alerts = data.get("alerts", [])messages = []for a in alerts:status = a.get("status", "unknown").upper()labels = a.get("labels", {})annotations = a.get("annotations", {})# 颜色区分if status == "FIRING":color = "red"emoji = "🚨"elif status == "RESOLVED":color = "green"emoji = "✅"else:color = "gray"emoji = "⚪️"alertname = labels.get("alertname", "-")namespace = labels.get("namespace", "-")instance = labels.get("instance", "") or labels.get("pod", "-")severity = labels.get("severity", "none").upper()summary = annotations.get("summary", "")description = annotations.get("description", "")startsAt = a.get("startsAt", "")endsAt = a.get("endsAt", "")# 飞书卡片消息card_content = {"config": {"wide_screen_mode": True},"elements": [{"tag": "div","text": {"content": f"**{emoji} {status} - {alertname}**\n","tag": "lark_md"}},{"tag": "hr"},{"tag": "div","text": {"content": (f"📦 **命名空间**:{namespace}\n"f"🖥️ **实例**:{instance}\n"f"⚙️ **严重级别**:{severity}\n"f"🕐 **开始时间**:{startsAt}\n"f"🕓 **结束时间**:{endsAt or '-'}\n"),"tag": "lark_md"}},{"tag": "hr"},{"tag": "div","text": {"content": f"📄 **摘要**:{summary or '-'}\n📝 **描述**:{description or '-'}","tag": "lark_md"}},{"tag": "hr"},{"tag": "action","actions": [{"tag": "button","text": {"content": "🔍 打开 Prometheus", "tag": "lark_md"},"url": "https://prometheus.xxxxx","type": "default"}]}],"header": {"title": {"content": f"{emoji} {alertname}", "tag": "plain_text"},"template": color}}payload = {"msg_type": "interactive", "card": card_content}# 发送到 Larkresp = requests.post(LARK_WEBHOOK, json=payload)print(f"[{datetime.datetime.now()}] Sent {status} alert {alertname}, resp={resp.status_code} {resp.text}")return "OK", 200if __name__ == "__main__":app.run(host="0.0.0.0", port=5001)
2.Dockerfile打包成容器镜像:
FROM python:3.9-slim
WORKDIR /app
COPY app.py /app/app.py
RUN pip install flask requests aiohttp
CMD ["python3", "/app/app.py"]3.在Kubernetes中部署Webhook:
apiVersion: apps/v1
kind: Deployment
metadata:name: alertmanager-lark-relaynamespace: thanos
spec:replicas: 1selector:matchLabels:app: alertmanager-lark-relaytemplate:metadata:labels:app: alertmanager-lark-relayspec:imagePullSecrets:- name: oci-container-registrycontainers:- name: relayimage: ap-singapore-1.ocir.io/xxxxxx/xxxxxx:TAGimagePullPolicy: IfNotPresentports:- containerPort: 5001env:- name: LARK_WEBHOOKvalue: "https://open.larksuite.com/open-apis/bot/v2/hook/xxxxxx"
---
apiVersion: v1
kind: Service
metadata:name: alertmanager-lark-relaynamespace: thanos
spec:selector:app: alertmanager-lark-relayports:- protocol: TCPport: 5001targetPort: 5001Thanos Store & Thanos Compact
最后我们在一台单独的服务器上部署这两个组件,以下是相关配置文件:
# /etc/systemd/system/thanos-store-oci.service
[Unit]
Description=Thanos Store Daemon
After=network.target[Service]
Type=simple
User=mvgx
Group=mvgx
Restart=on-failure
ExecStart=/usr/local/thanos0392/thanos store \--data-dir=/data/thanos/store-oci \--grpc-address=0.0.0.0:10911 \--http-address=0.0.0.0:10914 \--objstore.config-file=/usr/local/thanos0392/objectstorage-oci.yaml \--chunk-pool-size=1GB \--block-sync-concurrency=20 \--log.level=info
LimitNOFILE=65535
StandardOutput=file:/data/thanos/log/thanos-store-oci.log
StandardOutput=file:/data/thanos/log/thanos-error-oci.log[Install]
WantedBy=multi-user.target# /etc/systemd/system/thanos-compact-oci.service
[Unit]
Description=Thanos Compact Daemon
After=network.target[Service]
Type=simple
User=mvgx
Group=mvgx
Restart=on-failure
ExecStart=/usr/local/thanos0392/thanos compact \--wait \--consistency-delay=1h \--objstore.config-file=/usr/local/thanos0392/objectstorage-oci.yaml \--data-dir=/data/thanos/compact-oci \--http-address=0.0.0.0:19193 \--retention.resolution-raw=90d \--retention.resolution-5m=30d \--retention.resolution-1h=60d \--log.level=info
StandardOutput=file:/data/thanos/log/thanos-store-oci.log
StandardOutput=file:/data/thanos/log/thanos-error-oci.log[Install]
WantedBy=multi-user.target# /usr/local/thanos0392/objectstorage-oci.yaml
type: OCI
config:provider: "default"bucket: "prd-monitoring-system-oci"compartment_ocid: "ocid1.compartment.oc1..xxxxxxx"四.Web UI
Thanos Query Web UI
可以看到我们配置的两个数据源,一个是Thanos Sidecar代理的Prometheus本地6小时内的监控数据,一个是Thanos Store从存储中缓存的历史监控数据。

Prometheus Web UI
可以看到告警规则和监控数据来源的运行状态。由于我们环境中基本达到了稳定运行(每天出现的告警信息很少),所以之前Alertmanager的部署采用了Deployment而不是StatefulSet。
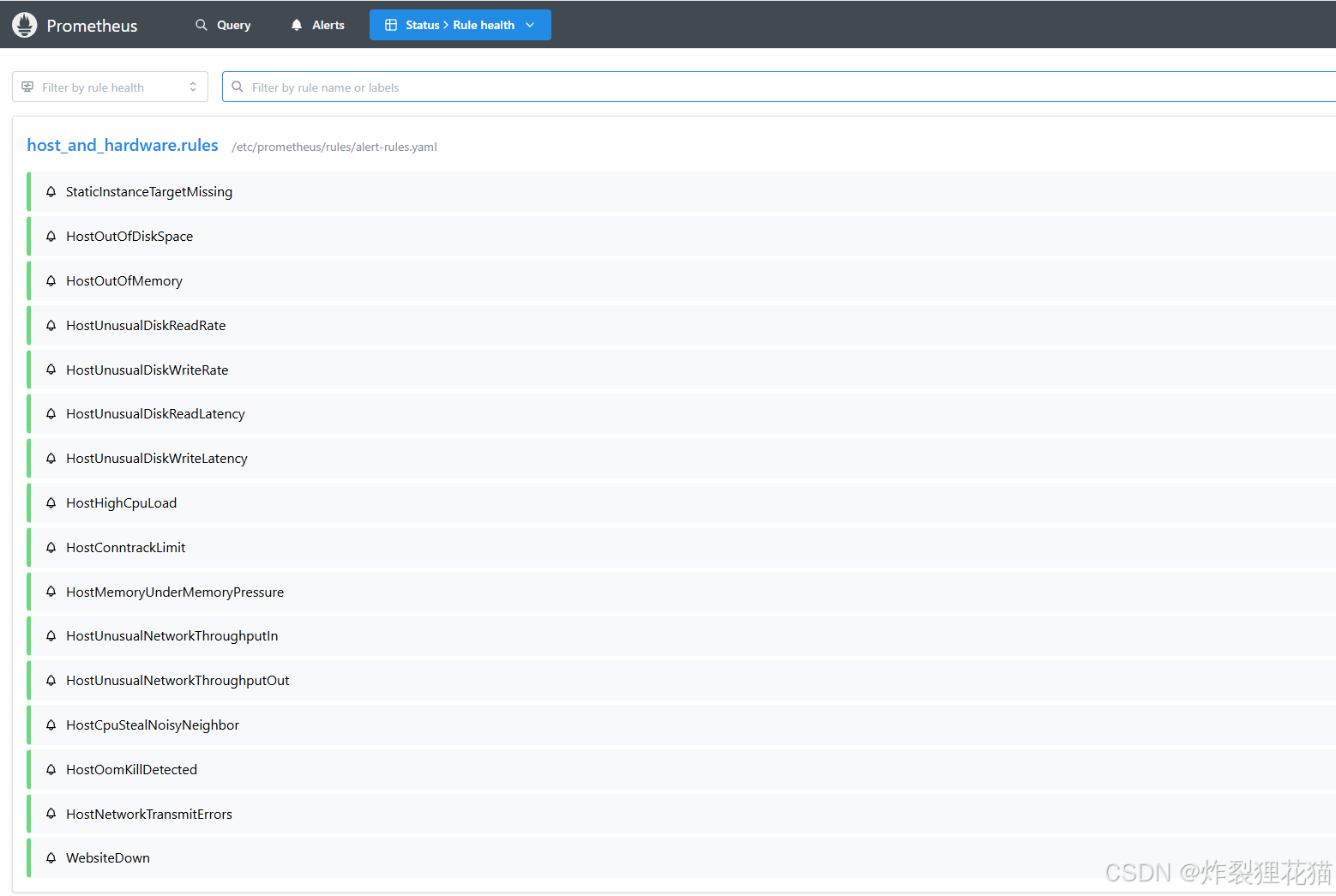
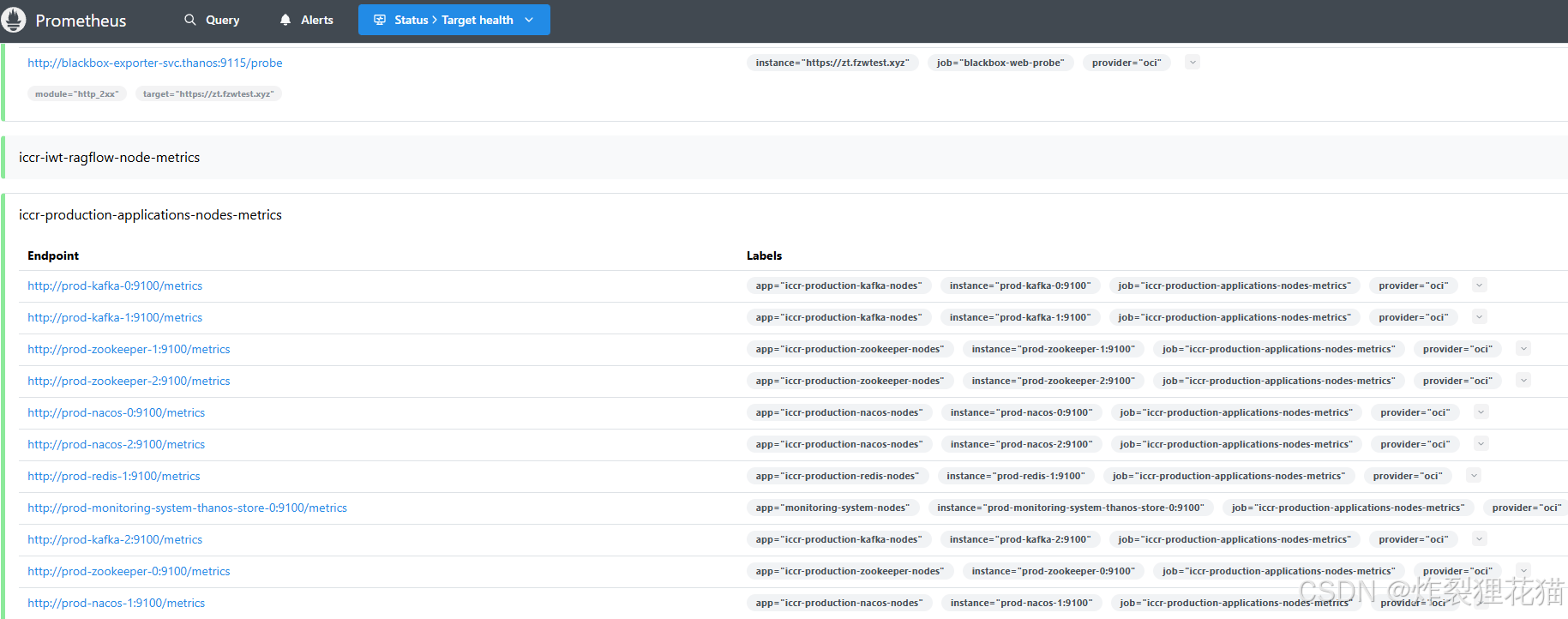
Alertmanager Web UI
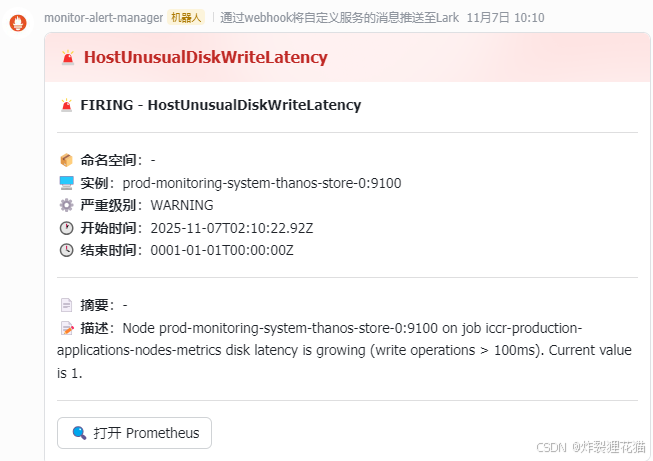
如果有告警信息会显示在上图的Alerts中,也会自动调用Webhook发送到接收平台,例如下图的Lark中:
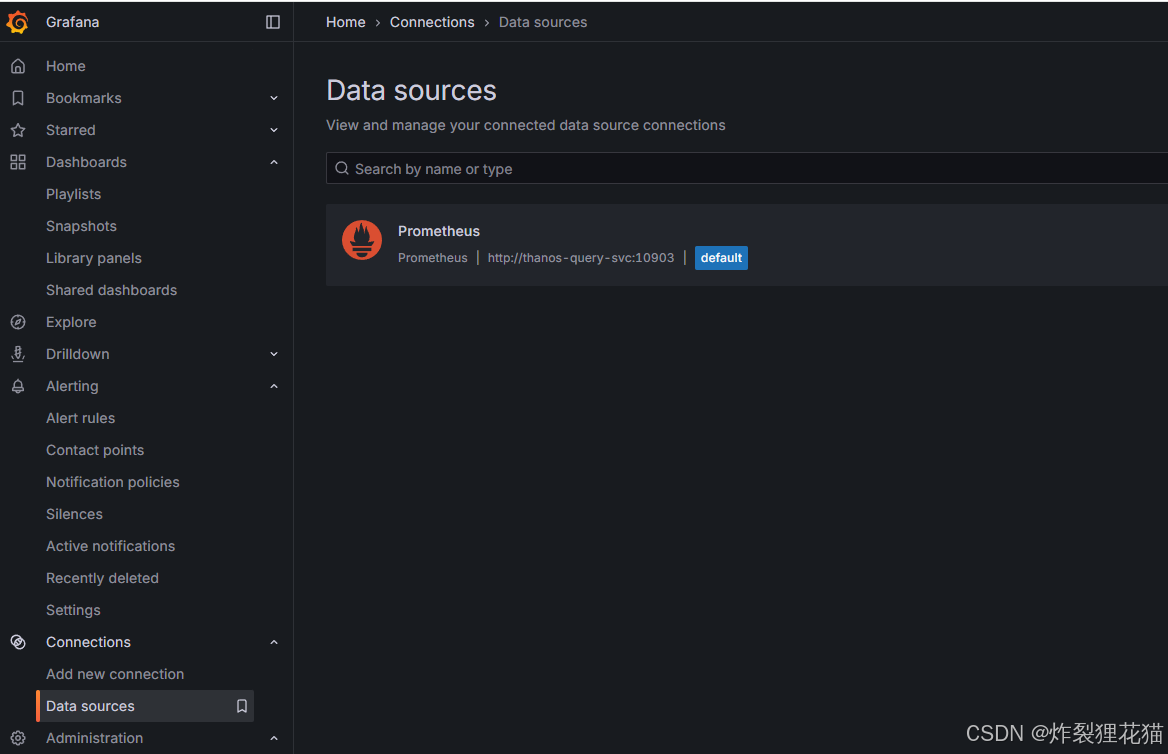
Grafana Web UI
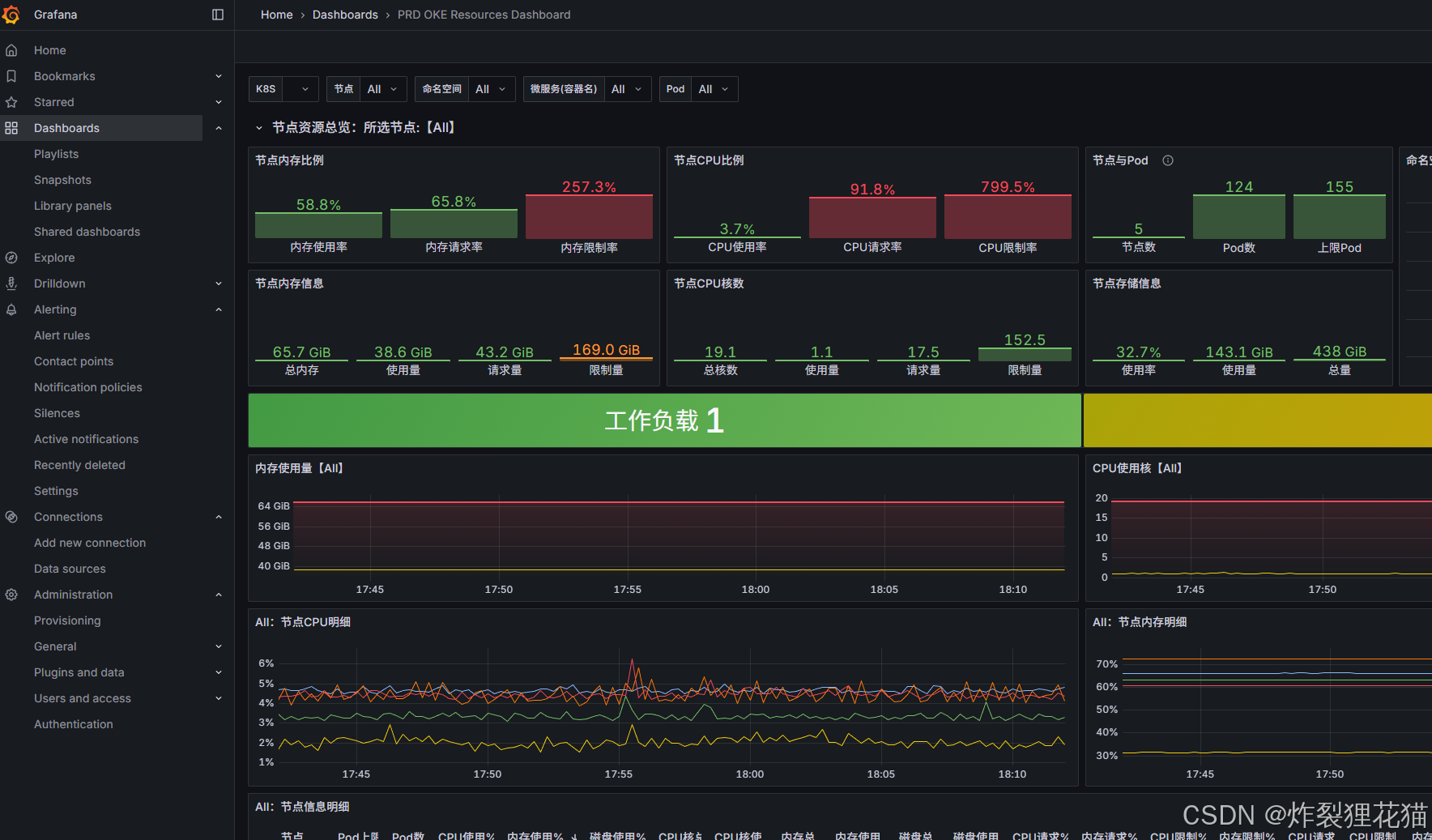
Grafana数据源采用聚合所有数据的Thanos Query:
从Grafana社区加载一些Dashboard模板,然后稍作修改即可: