08-微服务原理篇(Canal-Redis)
学习目标
- 能够说出ES索引同步的常用方案
- 能够说出Canal+MQ数据同步的方案
- 能够说出Canal是怎么伪装成 MySQL slave
- 能够测试通过Canal+MQ数据同步流程
- 能够说出MySQL和Redis如何保证双写一致性
- 能够说出分布式锁Redis原生、Redisson应用场景
- 能够说出缓存三剑客问题和解决方案
- 能够说出Redis持久化两种方案
- 能够说出Redis集群三种模式、哨兵选举流程
- 能够说出Redis过期策略、淘汰策略
1 多数据源数据同步方案
1.1. 技术方案分析
1.1.1 同步方式
管理员在商城的后台维护商品信息,数据存储在MySQL。
用户在商城搜索商品信息,从Elasticsearch搜索商品信息。
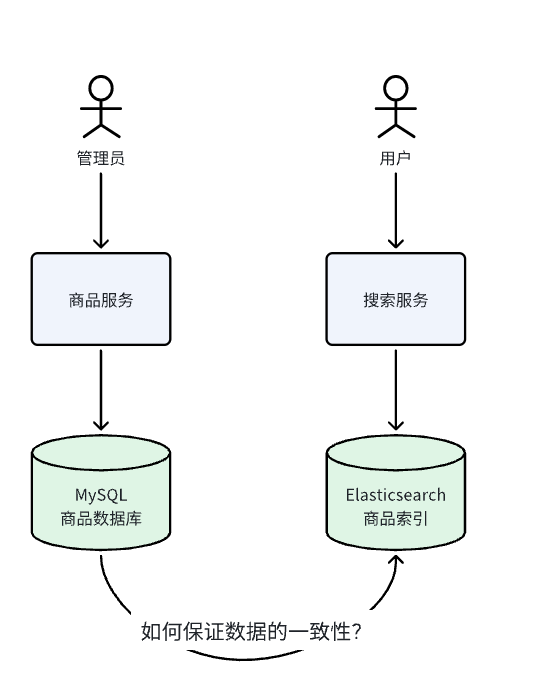
如果Elasticsearch的索引数据与MySQL的商品数据不一致会导致什么问题?
用户搜索到的商品信息并非商品最新的信息,比如:价格不同,搜索到的商品价格与实际价格不同,商品下架但是用户仍然可以搜索到商品信息,这些问题都会严重影响用户的体验。
我们需要一种方案,当管理员修改商品信息后及时的修改商品索引信息,使MySQL中的商品数据与ES中的商品数据保持一致。
常见的索引数据同步方案有两种:同步方式和异步方式。
首先说同步方式
在修改商品信息的方法中加入操作Elasticsearch索引的代码,即在原有业务方式的基础上添加索引同步的代码,CRUD操作MySQL的同时CRUD操作ES索引。如下代码,是在添加商品信息的时候向ES索引添加文档。
public void insert(Item item){//向本地数据库Item表添加记录//向ES的Item索引添加文档
}此方式会在很多业务方法中加入操作ES索引的代码,增加代码的复杂度不方便维护,扩展性差。
其次,上边的代码存在分布式事务,操作Item表会访问数据库,向索引添加文档会访问ES,使用数据库本地事务是无法控制整个方法的一致性的,比如:向ES写成功了由于网络超时导致异常,最终写数据库操作回滚了而写ES操作没有回滚,数据库的数据和ES中的索引不一致。
1.1.2 异步方式
异步方式是通过引入MQ实现,修改商品信息时向MQ发送修改的商品信息,然后监听MQ的程序请求ES向索引写入,流程如下:
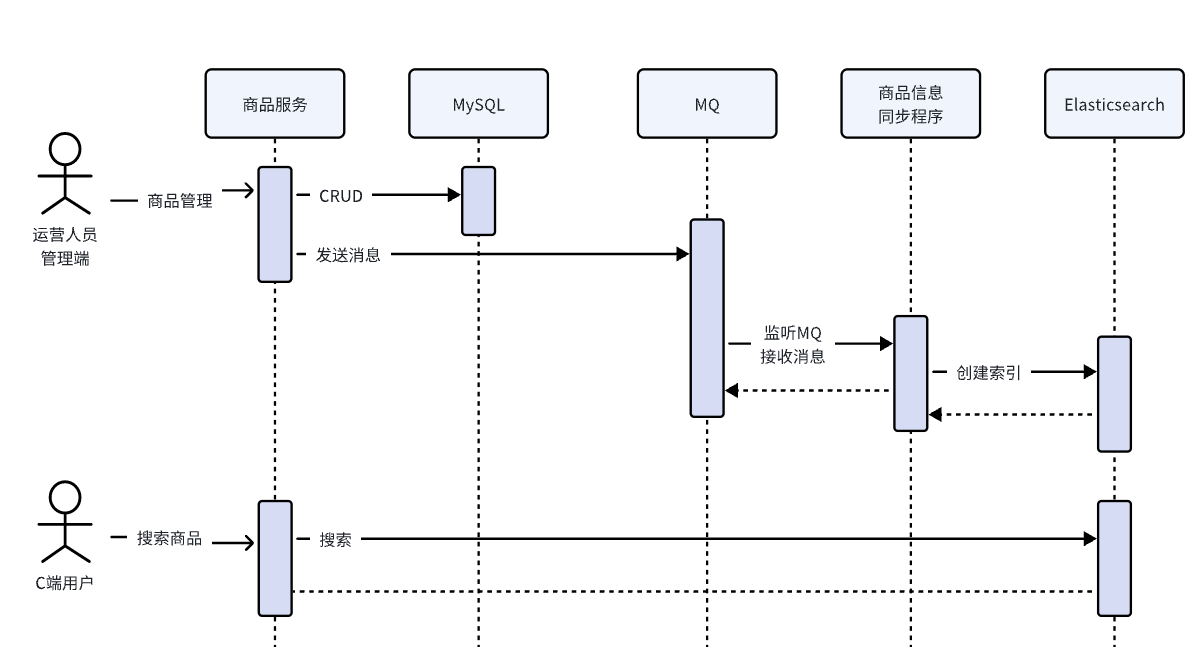
此方案的好处:
- 商品服务不用直接访问ES,通过MQ将商品服务和ES解耦合。
缺点:
- 在商品的CRUD方法中仍然需要加入向MQ发送消息的代码,如下:
public void insert(Item item){//向Item表添加记录//向MQ发送添加商品消息
}此方式仍然增加代码的复杂度不方便维护,扩展性差
这种方案不少公司是有采用的,下述Canal方案较重量级,大家自行取舍不以HM为准,以实际业务为准
有没有一种方法不用对商品的CRUD方法进行侵入,商品的CRUD方法就是对商品的增删改查,不会存在向ES同步数据相关的代码。
此时我们要借助一个神器就是Canal [kə'næl],先看下Canal在整个流程中的位置,如下图:
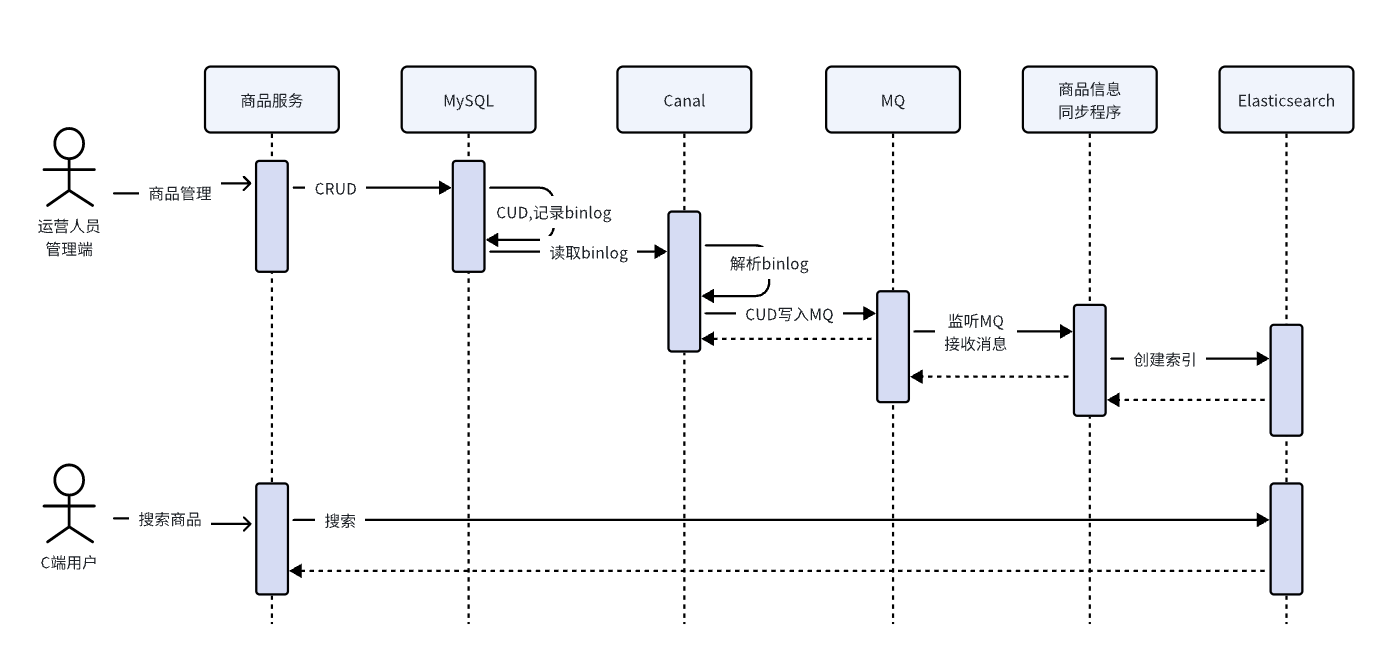
从图中可以看出,商品管理的CRUD方式仅仅包括对商品表的CRUD业务操作(下图红色框内部分),不再有操作MQ的相关逻辑。
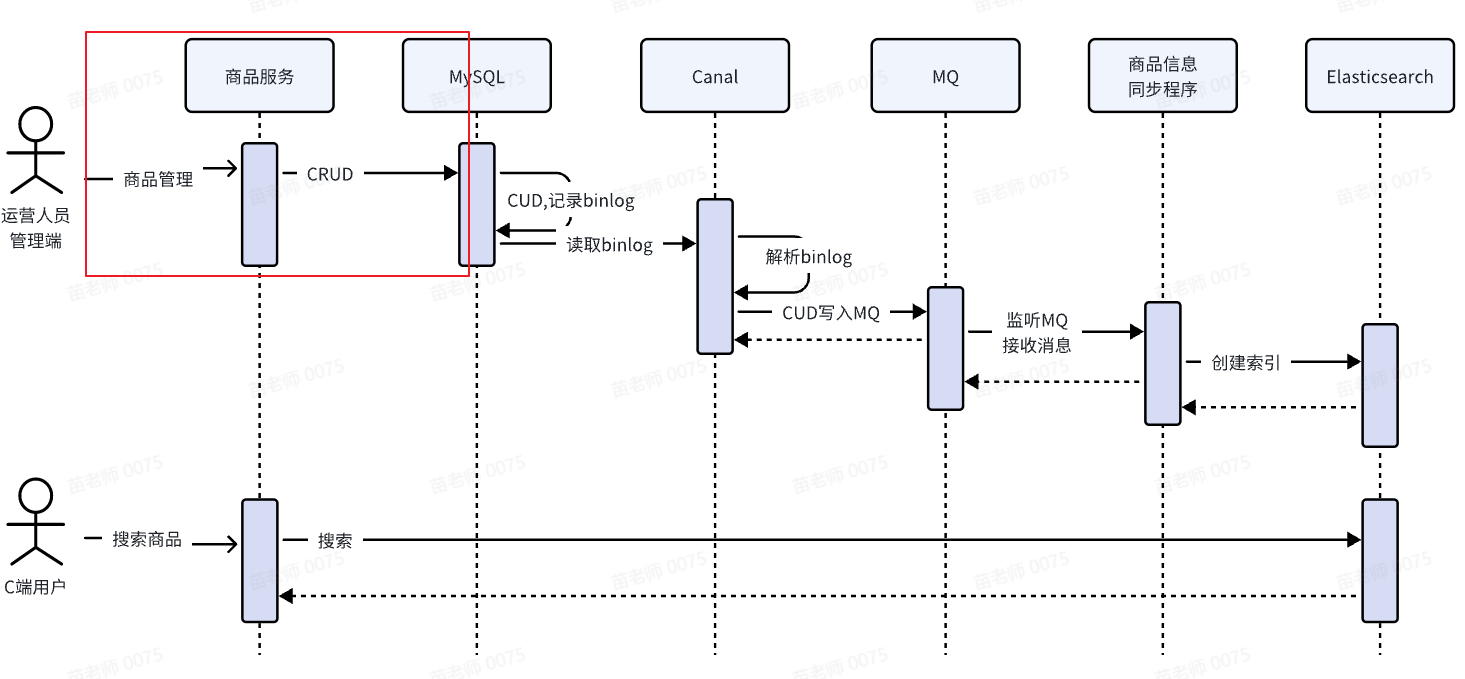
Canal是和MySQL存在联系,并且Canal负责和MQ交互,这种方案就是借助了Canal和MQ实现的。
1.2 Canal+MQ数据同步
1.2.1. MySQL主从复制
要理解Canal的工作原理需要首先要知道MySQL主从数据同步的原理。
首先我们要知道,平时我们在学习时只用MySQL单机即可,但是生产环境中MySQL部署为主从集群模式,MySQL主从集群由MySQL主服务器(master)和MySQL从服务器(slave)组成,主数据库提供写服务,从数据库提供读服务,主从之间进行数据复制保证数据同步,如下图:
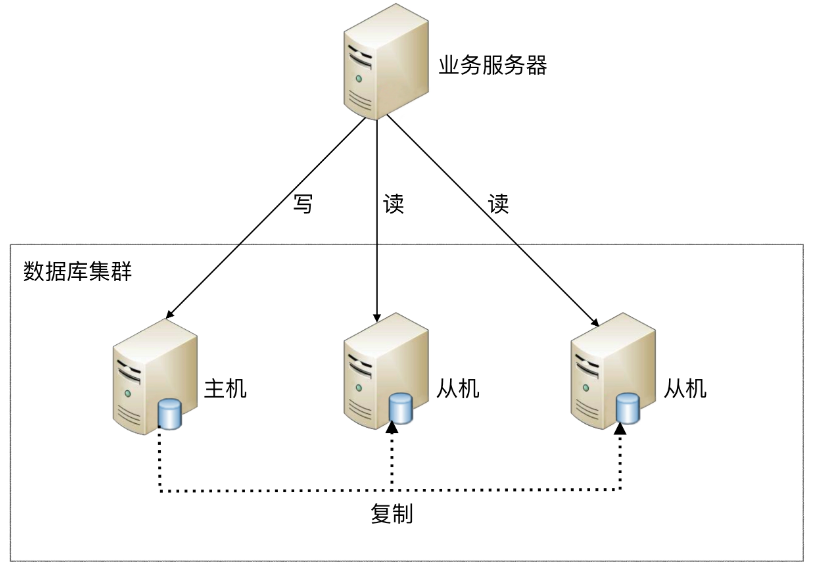
MySQL主从之间是如何同步的呢?
MySQL主从数据同步是一种数据库复制技术,进行写数据会先向主服务器写,写成功后通过binlog日志将数据同步到从数据库。
具体流程如下图:
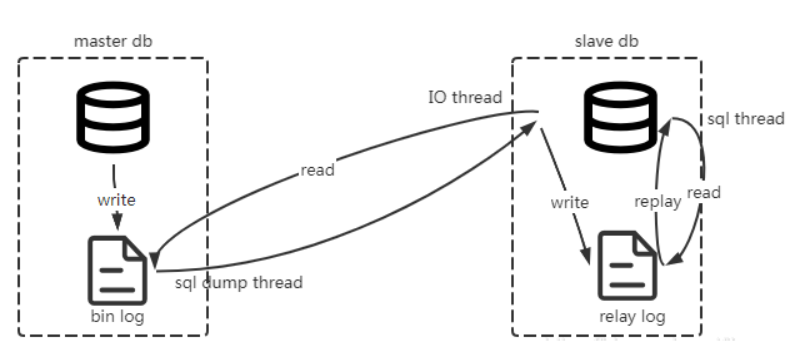
1、主服务器将所有写操作(INSERT、UPDATE、DELETE)以二进制日志(binlog)的形式记录下来。
2、从服务器连接到主服务器,发送dump 协议,请求获取主服务器上的binlog日志。
MySQL的dump协议是MySQL复制协议中的一部分。
3、MySQL master 收到 dump 请求,开始推送 binary log 给 slave
4、从服务器解析binlog日志,根据日志内容更新从服务器的数据库,完成从服务器的数据保持与主服务器同步。
1.2.1.1 binlog
binlog日志是什么?
MySQL的binlog(二进制日志)是一种记录数据库服务器上所有修改数据的日志文件。它主要用于数据复制和数据恢复。binlog的主要作用是记录数据库的DDL(数据定义语言)操作和DML(数据操作语言)操作,以便在数据库发生故障时进行恢复。
binlog长什么样?
类似下边这样:
binlog的主要特点如下:
- 事务级别的记录:
-
- Binlog 以事务为单位记录数据更改,这意味着每个事务的开始和结束都会被记录下来。
- 这种记录方式有助于保证数据的一致性和事务的完整性。
- 支持多种格式:
-
- STATEMENT:记录每条 SQL 语句,适用于大多数情况,但有些 SQL 语句的结果依赖于会话状态,可能导致复制问题。
- ROW:记录每行数据的更改,精确度高,但会增加日志文件的大小。
- MIXED:默认模式,结合了 STATEMENT 和 ROW 的优点,大部分情况下采用 STATEMENT 模式,但在 STATEMENT 模式可能引起问题时自动切换到 ROW 模式。
- 非阻塞性:
-
- Binlog 的写入操作是非阻塞的,即写入 Binlog 不会阻塞客户端的事务提交。
- 这意味着应用程序可以在无需等待日志写入完成的情况下继续运行,提高了性能。
- 数据恢复:
-
- Binlog 可以用于数据恢复,允许恢复到特定的时间点或事务。
- 这对于灾难恢复非常重要,可以减少数据丢失的风险。
- 主从复制:
-
- Binlog 是 MySQL 主从复制的基础。
- 通过从主服务器读取并重放 Binlog,从服务器可以保持与主服务器相同的数据状态。
在 MySQL 中启用 Binlog 需要在配置文件 (my.cnf 或 my.ini) 中进行设置。
一些关键的配置选项包括:
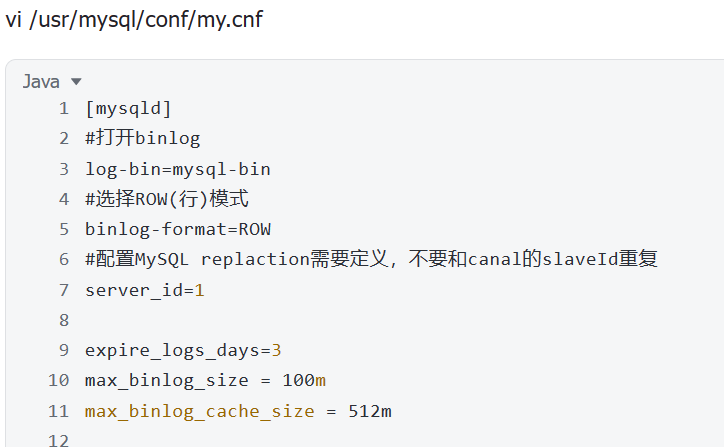
server-id:用于标识服务器的唯一 ID,这对于多服务器环境非常重要。log_bin:指定是否启用 Binlog 以及 Binlog 文件的保存位置。binlog_format:定义 Binlog 的格式,如 STATEMENT, ROW 或 MIXED。expire_logs_days:定义 Binlog 文件保留的时间,超过这个时间的文件会被自动删除。max_binlog_size:单个 Binlog 文件的最大大小,达到这个大小后会自动创建新的文件。
举例:
注意事项:
- Binlog 文件会占用磁盘空间,因此需要定期清理不再需要的旧文件。
- 使用 Binlog 进行数据恢复或复制时,要确保所有相关服务器的时间同步,否则可能会出现问题。
binlog常用命令:查看是否开启binlog日志
show variables like 'log_bin';

使用以下命令查看所有binlog日志列表:
SHOW MASTER LOGS;
要查看MySQL服务器上的binlog状态,可以使用以下命令:
SHOW MASTER STATUS;

要查看所有的binlog文件列表,可以使用以下命令:
SHOW BINARY LOGS;
查看binlog日志保存路径
SHOW VARIABLES LIKE 'datadir';
刷新log日志,立刻产生一个新编号的binlog日志文件,跟重启一个效果,可以执行以下命令:
FLUSH LOGS;
清空所有binlog日志,可以执行以下命令:
RESET MASTER;
1.2.2. Canal+MQ同步流程
Canal是什么呢?
canal [kə'næl],译意为水道/管道/沟渠,主要用途是基于 MySQL 数据库增量日志解析,对数据进行同步,如下图:
Canal可与很多数据源进行对接,将数据由MySQL同步到ES、MQ、DB等各个数据源。
Canal的意思是水道/管道/沟渠,它相当于一个数据管道,通过解析MySQL的binlog日志完成数据同步工作。
官方文档:https://github.com/alibaba/canal/wiki
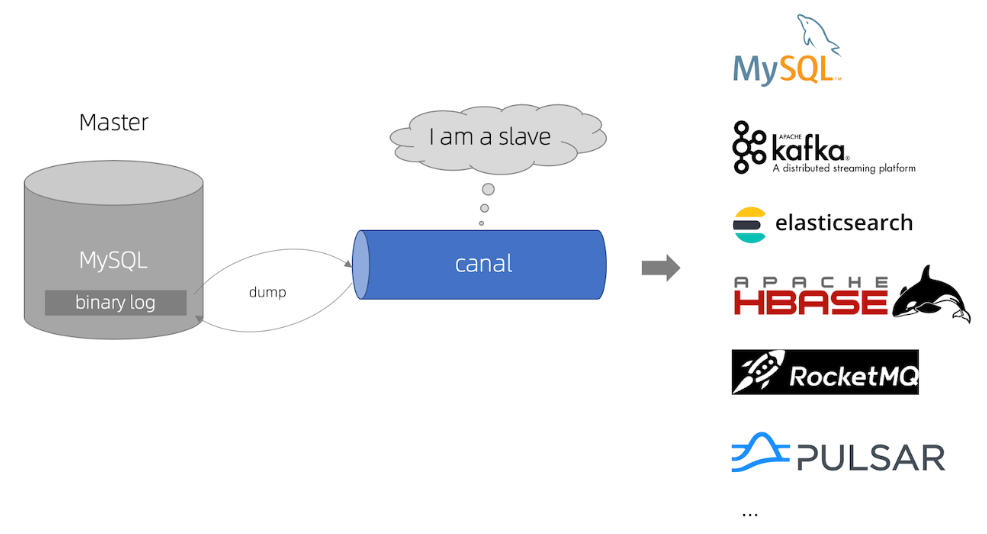
Canal数据同步的工作流程如下:
1、Canal模拟 MySQL slave 的交互协议,伪装自己为 MySQL slave ,向 MySQL master 发送dump 协议
MySQL的dump协议是MySQL复制协议中的一部分。
2、MySQL master 收到 dump 请求,开始推送 binary log 给 slave (即 canal )
。一旦连接建立成功(长连接),Canal会一直等待并监听来自MySQL主服务器的binlog事件流,当有新的数据库变更发生时MySQL master主服务器发送binlog事件流给Canal。
3、Canal会及时接收并解析这些变更事件并解析 binary log
理解了Canal的工作原理下边再看数据同步流程:
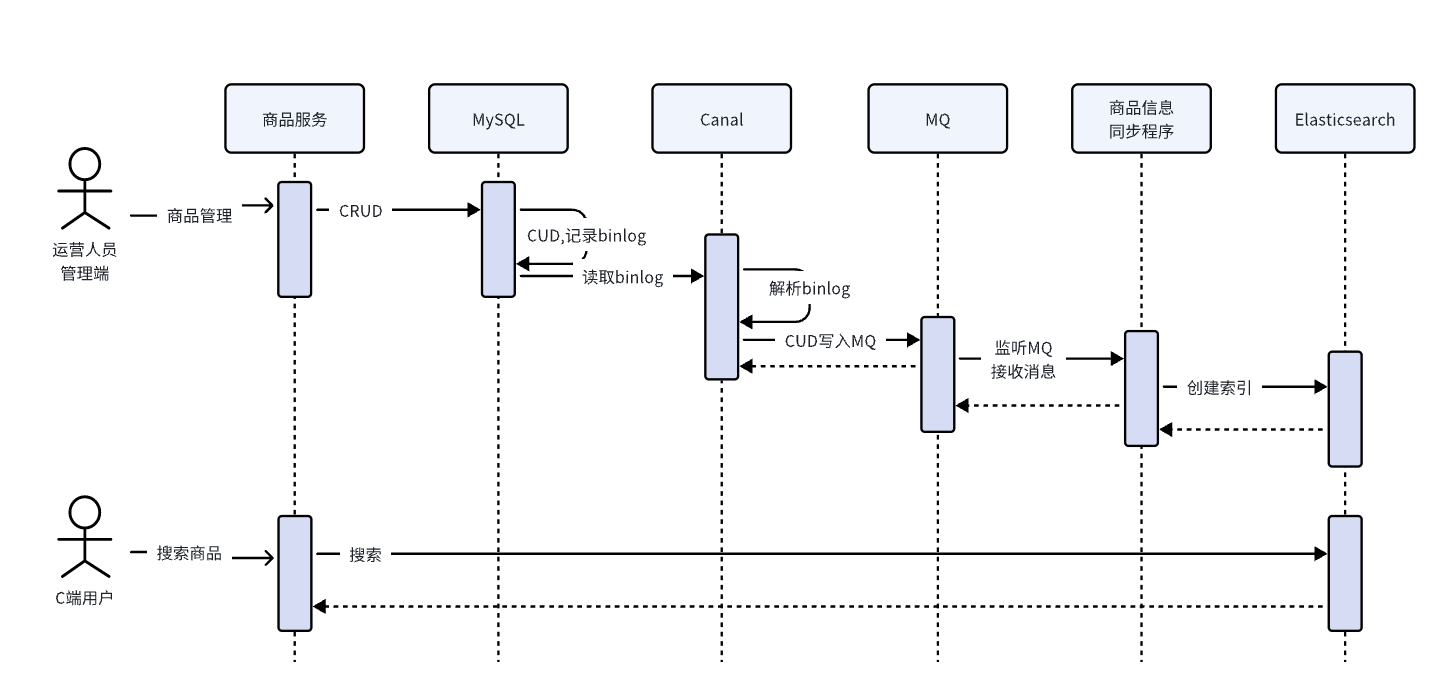
- 首先创建一张专门用于向ES同步商品信息的表item_sync,item_sync表的字段内容可能包含item表的字段,一定覆盖所有索引字段。
方法:复制item表到item_sync表。
这里为什么要单独创建一张同步表呢?
因为同步表的字段和索引是对应的,方便进行同步。
- 商品服务在对商品进行CRUD时向Item表写数据并且向item_sync写入数据,并产生binlog。
- Canal请求MySQL读取binlog,并解析出item_sync表的数据更新日志,并发送至MQ的数据同步队列。
- 异步同步程序监听MQ的数据同步队列,收到消息后解析出item_sync表的更新日志。
- 异步同步程序根据item_sync表的更新日志请求Elasticsearch添加、更新、删除索引文档。
最终实现了将MySQL中的Item表的数据同步至Elasticsearch
1.2.3. 配置数据同步环境
本节实现将MySQL的变更数据通过Canal写入MQ。
根据Canal+MQ同步流程,进行如下配置:
- 配置Mysql主从同步,开启MySQL主服务器的binlog
- 安装Canal并配置,保证Canal连接MySQL主服务器成功
- 安装RabbitMQ,并配置同步队列。
- 在Canal中配置RabbitMQ的连接信息,保证Canal收到binlog消息写入MQ
对于异步程序监听MQ通过Java程序中实现。以上四步配置详细参考“配置搜索及数据同步环境”。
1.2.4. 同步程序
前边我们实现了Canal读取binlog日志并向MQ发送消息的整个流程,下边我们需要编写同步程序监听MQ,解析出更改的数据更新ES索引数据。
在search-service工程添加依赖:
<properties><canal.version>1.1.5</canal.version>
</properties><dependency><groupId>com.alibaba.otter</groupId><artifactId>canal.client</artifactId><version>${canal.version}</version>
</dependency>
<dependency><groupId>com.alibaba.otter</groupId><artifactId>canal.protocol</artifactId><version>${canal.version}</version>
</dependency>从课程资料中拷贝"es/canal"目录到search-service工程的com.hmall.search包下。
阅读AbstractCanalRabbitMqMsgListener类parseMsg(Message message) 方法,理解同步程序的执行思路。
parseMsg(Message message) 方法实现了解析canal发送给mq的消息,并调用batchHandle或singleHandle处理数据,在这两个方法中会调用抽象方法void batchSave(List<T> data)和void batchDelete(List<Long> ids)去向数据库保存数据、删除数据。
public void parseMsg(Message message) throws Exception {try {// 1.数据格式转换CanalMqInfo canalMqInfo = JSONUtil.toBean(new String(message.getBody()), CanalMqInfo.class);// 2.过滤数据,没有数据或者非插入、修改、删除的操作均不处理if (CollUtils.isEmpty(canalMqInfo.getData()) || !(OperateType.canHandle(canalMqInfo.getType()))) {return;}if (canalMqInfo.getData().size() > 1) {// 3.多条数据处理batchHandle(canalMqInfo);} else {// 4.单条数据处理singleHandle(canalMqInfo);}} catch (Exception e) {//出现错误延迟1秒重试Thread.sleep(1000);throw new RuntimeException(e);}
}如果我们要实现商品信息同步就需要编写商品信息同步类,同步程序做两件事:
- 同步类需要监听MQ,接收canal发送给mq的消息
- 同步程序需要继承AbstractCanalRabbitMqMsgListener类,并重写void batchSave(List<T> data)和void batchDelete(List<Long> ids)这两个方法,这样就实现了将canal发送的商品信息保存或删除ES中对应的数据。
代码如下:下边的代码能读懂会用即可。
package com.hmall.search.canal.listeners;import cn.hutool.core.bean.BeanUtil;
import co.elastic.clients.elasticsearch.ElasticsearchClient;
import co.elastic.clients.elasticsearch.core.BulkRequest;
import co.elastic.clients.elasticsearch.core.BulkResponse;
import co.elastic.clients.elasticsearch.core.DeleteByQueryResponse;
import co.elastic.clients.elasticsearch.core.bulk.BulkResponseItem;
import com.hmall.search.domain.po.ItemDoc;
import com.hmall.search.domain.po.ItemSync;
import org.springframework.amqp.core.ExchangeTypes;
import org.springframework.amqp.core.Message;
import org.springframework.amqp.rabbit.annotation.Exchange;
import org.springframework.amqp.rabbit.annotation.Queue;
import org.springframework.amqp.rabbit.annotation.QueueBinding;
import org.springframework.amqp.rabbit.annotation.RabbitListener;
import org.springframework.stereotype.Component;import javax.annotation.Resource;
import java.io.IOException;
import java.util.ArrayList;
import java.util.List;
import java.util.stream.Collectors;@Component
public class ItemCanalDataSyncHandler extends AbstractCanalRabbitMqMsgListener<ItemSync> {@Resourceprivate ElasticsearchClient esClient;@RabbitListener(bindings = @QueueBinding(value = @Queue(name = "canal-mq-hmall-item"),exchange = @Exchange(name = "exchange.canal-hmall", type = ExchangeTypes.TOPIC),key = "canal-mq-hmall-item"),concurrency = "1")public void onMessage(Message message) throws Exception {parseMsg(message);}@Overridepublic void batchSave(List<ItemSync> data) {BulkRequest.Builder br = new BulkRequest.Builder();for (ItemSync itemSync : data) {br.operations(op -> op.index(idx -> idx.index("items").id(itemSync.getId().toString()).document(itemSync)));}BulkResponse result = null;try {result = esClient.bulk(br.build());} catch (IOException e) {throw new RuntimeException(e);}Boolean aBoolean = result.errors();if(aBoolean) {try {Thread.sleep(1000);} catch (InterruptedException e) {throw new RuntimeException(e);}throw new RuntimeException("同步失败");}}@Overridepublic void batchDelete(List<Long> ids) {List<String> idList = ids.stream().map(id -> id.toString()).collect(Collectors.toList());DeleteByQueryResponse response = null;try {response = esClient.deleteByQuery(dq -> dq.query(t -> t.ids(t1 -> t1.values(idList))).index("items"));boolean hasFailures = response.failures().size() > 0;if(hasFailures) {try {Thread.sleep(1000);} catch (InterruptedException e) {throw new RuntimeException(e);}throw new RuntimeException("同步失败");}} catch (IOException e) {throw new RuntimeException("同步失败");}}
}接下来测试:
- 手动修改Item_sync表的数据,断点跟踪onMessage(Message message)方法,当插入、修改数据时执行踪onMessage(Message message)方法,当删除数据时执行batchDelete(List<Long> ids)。