Step-Audio-EditX
文章目录
- abstract
- method
- data
- zero-shot TTS
- Emotion and Speaking Style Editing
- Paralinguistic Editing
- Reinforcement Learning Data
- training
- SFT
- Reinforcement Learning
- reward model
- PPO train
- eval
- QA
- 2025.11.5
- paper
- github
abstract
- 改进了对音频风格(emotion,)的可控生成能力
- method:利用large-margin synthetic data,通过加大对比,让模型学会解耦能力;3B的模型,比之前130B模型的性能更好;
method
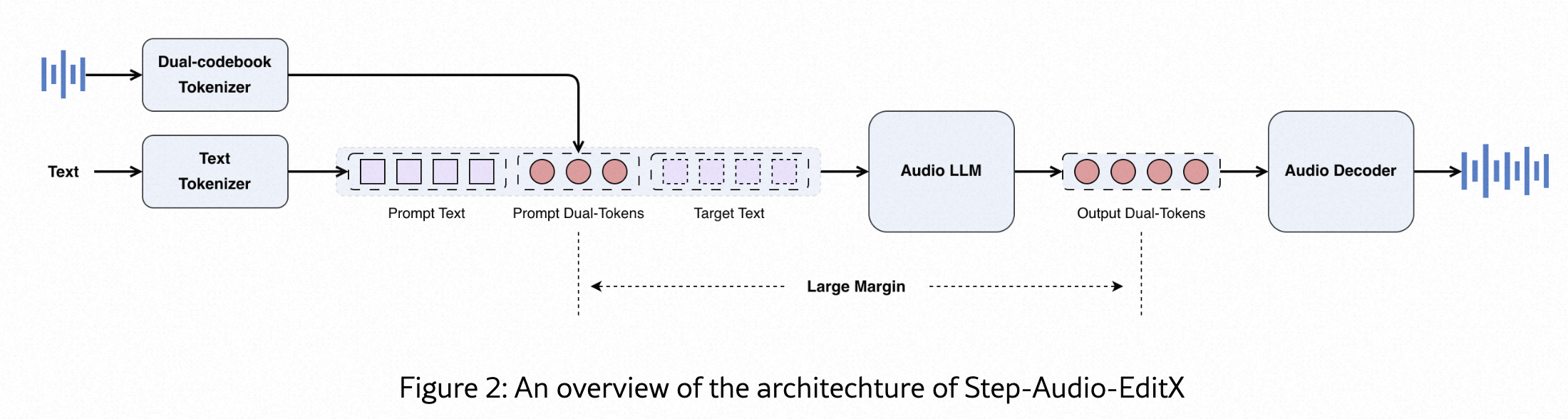
-
Audio Tokenizer:采用双码本,2:3 交错的形式送给AR模型
- parallel linguistic(语言信息),16.7 Hz, 1024-codebook
- Semantic(语义,韵律信息),25 Hz, 4096-codebook
- 作者特意指出,这个分词器在音色、情感等方面解耦并不好(suboptimal disentanglement)。这反而成了一个优点,因为它证明了模型的强大编辑能力不是来自一个完美的分词器,而是来自后续LLM的训练方法。
音频大语言模型 (Audio LLM):
-
Audio LLM:预训练好的文本LLM初始化,3B参数。加入音频能力的时候,会使用音频&文本混合的数据集,保证文本数据和音频令牌数据的比例为1:1
-
Audio Decoder:
- FM:DIT预测mel,20w高质量音频训练,可以提升音准、音质和相似度
- BigVGANv2
data
- 预训练数据和之前的方案一致,主要关注后训练数据,sft 数据分为几大类:zero-shot TTS, emotion editing, speaking style editing and paralinguistic editing。large-margin dataset 主要用于编辑任务(emotion,speaking style)
zero-shot TTS
- 要是中文和英文,用于零样本 TTS。此外,使用最少量的粤语和四川语数据来引出方言能力。
- 包含约6w speaker数据,其中也有单人多情感的数据
Emotion and Speaking Style Editing
- 配音演员录制:不同情感和说话风格音频,对于每个演员的每一种情感/风格组合,我们只采集一段约10秒的音频片段。
- zero-shot clone:择同一个说话人的情感音频和中性音频作为音色参考,使用StepTTS的语音克隆接口,并配上描述目标属性的文本指令来合成音频。每个三元组中的音频片段都是用相同的、带有情感或风格描述的文本提示生成的。
- 解读:这促使模型在SFT训练过程中,只关注情感和风格本身的变化(而不是文本内容的变化,比如文本本身也有情感倾向,相同文本的不同风格/情感演绎,更能让模型学到解耦的能力)。
- 选择large-margin 数据:为了评估生成的三元组(文本,中性音频, 情感/风格音频),我们用一个少量的人工标注数据集训练了一个打分模型。该模型以1-10分制来评估音频对(比如中性音频和情感音频)的差异程度。只保留那些差异非常大(>6分)的数据对。这样做能让模型在训练时看到非常清晰的、从A到B的转变,从而学会编辑能力。
Paralinguistic Editing
- NVSpeech的数据集带有丰富的副语言标签,比如breath,laughter,[uhmm]
- 构造一个训练的四元组⟨无标签文本, 无标签音频, 带标签的NVSpeech源文本, 带标签的NVSpeech源音频⟩ ,前两个作为编辑模型的输入,后两个作为预测的结果输出
- 将NVSpeech的数据作为prompt,使用StepTTS语音克隆生成不带副语言标签,文本内容一模一样的音频
- 模型学习的任务就是:如何从这个“干净”的音频,编辑回那个包含副语言标签的“真实”音频。
- 四元组数据不需要再通过边界计算筛选,因为“有”和“无”的差别太大了,所以天然就是“大边距”数据,不需要再用AI去打分筛选。
Reinforcement Learning Data
为了使模型输出符合人类偏好,构建了两类偏好数据集:一类基于人工标注,另一类采用“LLM-as-a-Judge”
- 人工标注:从用户那里收集真实的提示音频和相应的文本,然后用SFT模型生成20个候选音频。接着,我们让标注员根据正确性、韵律和自然度等标准,对这20个音频进行5分制打分。最后,构建chosen/rejected 数据对,但只保留那些分数差异大于3分的配对。
- 同样是“大边距”思想。只有当一个音频明确比另一个好很多时,才把它们作为训练数据,这样奖励模型才能学到清晰的偏好。
- LLM-as-a-Judge:对于情感和说话风格编辑任务,我们让一个理解模型(即另一个大语言模型)对模型的输出进行1-10分打分。然后基于这些分数生成偏好对,最终数据集中只保留分数差异大于8分的配对。 这里的“大边距”要求更加苛刻(差异>8),因为LLM打分可能不如人类精准,需要更强的信号。
training
- 主要是增强 zero-shot 能力以及音频edit能力。训练分为两个阶段:SFT和PPO
SFT
- 以对话的形式构造训练数据,模型使用从 1×10⁻⁵ 到 1×10⁻⁶ 的学习率微调了一个epoch。
- zero_shot 任务格式
System Prompt: “你是一个语音合成助手。说话人信息:[由参考音频转换来的令牌字符串]”
User Prompt: “请用这个声音朗读:今天天气真好。”
System Response: [模型生成的代表“今天天气真好”这句话的音频令牌]
这样做的好处是,整个过程完全符合LLM的“文本输入、文本输出”范式,只是这里的“文本”有一部分是代表音频的特殊字符串。
- 音频编辑任务格式
System Prompt: “你是一个音频编辑助手。”
User Prompt: “请将这段音频的情感改为‘悲伤’。原始音频:[原始音频的令牌字符串]”
System Response: [模型生成的代表编辑后悲伤音频的令牌]
这种对话格式让模型能够灵活地处理各种不同的任务,因为它学会了“阅读理解”用户的指令。
Reinforcement Learning
- 将优化任务的重点从实现语音表示特征的解耦,转移到改进大边距对的构建和奖励模型评估的有效性。
reward model
- 奖励模型(Reward Model, RM)由上边提到的SFT的3B模型初始化而来。
- 同根同源,确保Actor和RM有相同的起点和知识背景。
- 训练数据:使用人工标注和LLM当裁判生成的“大边距”偏好数据进行训练。
- 损失函数:使用Bradley-Terry损失函数进行优化(这是训练偏好模型常用的损失函数)。
- 核心特点:该模型是一个token-level的奖励模型,直接在“大边距”的双码本令牌对上进行训练。这种方法避免了在计算奖励时需要用音频解码器将令牌转换回音频波形的步骤。
训练细节:模型微调了一个周期,学习率使用余弦衰减策略,从 2×10⁻⁵ 衰减到 1×10⁻⁵。
解读: 最重要的创新点在于“令牌级别的奖励模型”。传统的RLHF需要将模型生成的文本/图像/音频先解码出来,再由奖励模型打分,这个过程非常耗时。而这里,奖励模型直接在音频的“令牌序列”上打分,大大提高了训练效率。
PPO train
训练策略:在PPO训练阶段,Critic模型会比Actor模型提前预热80步。
优化器与学习率:优化器使用 1×10⁻⁶ 的初始学习率,并遵循余弦衰减策略,最低降至 2×10⁻⁷。
PPO参数:PPO的裁剪阈值(clip threshold)ϵ 设为 0.2,KL散度惩罚项的系数 β 设为 0.05。
解读:
只用“难题”训练:这是为了提高效率。只在模型做得不好的地方进行强化学习,好比“补短板”。
其他参数:Critic预热、学习率设置、PPO裁剪和KL惩罚都是PPO算法中的标准或经验性设置,旨在稳定训练过程,防止模型为了追求高奖励而偏离原始SFT模型太远(由KL散度惩罚控制)。
eval
设计benchmark测试集,Gemini-2.5-Pro 模型评估
QA
Q: 仅用large margin 指标,是否会让模型走向一个过分夸张的风格,或者错误的方向
- 担忧是有道理的。可以完善或者论文中已经做的点
- SFT阶段的“方向性”学习是基础,强化学习阶段会用KL防止模型偏离SFT学到的基础策略太远
- 奖励模型的其打分标准:不应该仅仅是“边距大”。它需要更复杂、更符合人类偏好的评判标准。
报告中提到,工标注的打分标准包括 “正确性(correctness)”、“韵律(prosody)”和“自然度(naturalness)”。奖励模型学习到的偏好是一个综合性的指标:综合奖励 ≈ w1 * (情感正确性) + w2 * (自然度) + w3 * (与输入的差异度/边距)(这里的权重w是示意)。它会去平衡“方向对不对”、“幅度大不大”和“效果好不好听”。 - 构建RL的偏好数据时,选择的是chosen/rejected对。例如,对于指令“变悲伤”,有两个候选音频A和B。chosen的音频A,是那个既悲伤、又自然、情感表达又到位的。rejected的音频B,可能是情感不对、或者太夸张、或者变化不明显的。通过学习这些chosen和rejected之间的巨大差异(score margin > 3 or > 8),奖励模型学会了什么是“全方位的好”,而不仅仅是“差异大”。