2023年辽宁省数学建模竞赛-B题 数据驱动的水下导航适配区分类预测-基于支持向量机对水下导航适配区分类的研究
基于支持向量机对水下导航适配区分类的研究
摘 要
解决水下航行器的导航精度问题对于海洋经济的发展至关重要。本文采用一系列方法来提高水下航行器的导航精度。
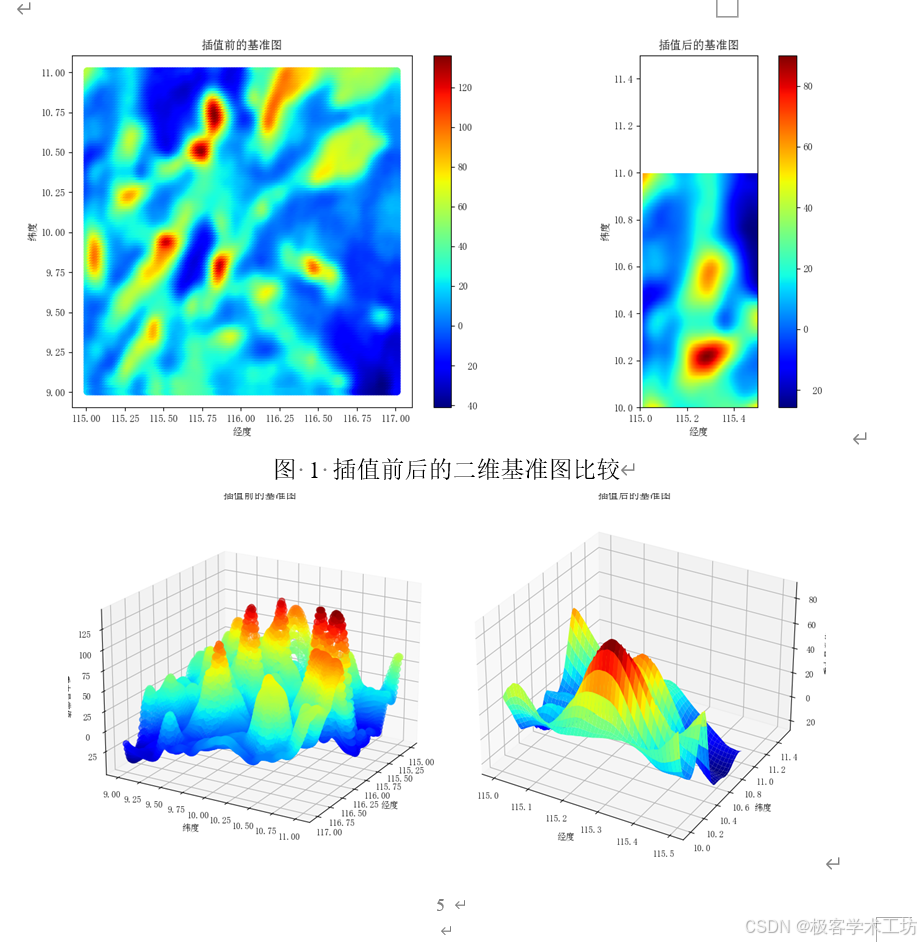
在问题1中,研究首先对附件一中的数据进行插值处理,以增加数据点的数量,并提高数据的空间分辨率,这有助于更精确地捕捉地下重力异常的变化情况。插值后的数据可视化展示了更精细的地形图。
接下来,通过量化重力波动值,研究将数据分为不同区域,并使用k-means聚类模型来确定最佳的聚类数量。这样,将数据分成了4个区域,每个区域都有不同的重力波动值,反映了不同的地质特征。这个过程有助于在不同区域内为水下航行器提供更精确的导航信息。
问题2涉及将不同区域的适配性标定问题,这对于水下航行器的导航至关重要。首先,研究将不同区域的适配性标定结果用于将坐标点进行分类,分为高精度区、精度区、中精度区和低精度区。然后,通过分析附件一中的数据,确定了13个指标,这些指标可以影响区域适配性标定。利用主成分分析法,筛选出最重要的4个指标,以提高分类的准确性。
接下来,建立决策树模型,将降维后的指标数据和二进制编码输入模型,用于分类坐标点的适配性标定。模型的准确性通过绘制ROC曲线来验证,结果表明模型的精确度为82.5%。
问题3涉及迁移性预测,需要在数据准备、特征工程、模型迁移和性能评估方面展开工作。首先,确保新数据的质量,包括数据清洗和处理缺失值。然后,将新数据映射到与系统F相同的特征格式,可能需要进行坐标转换和数据预处理。接下来,将系统F应用于新数据,获取预测结果,并使用适当的性能指标(如MSE、RMSE、准确率等)评估其性能。最后,分析系统F在新数据上的性能,讨论其适用性,如果性能不佳,考虑模型改进和特征工程,同时注意新数据与问题二数据的分布差异对性能的影响。这个过程有助于确定系统F在新数据上的适用性和提高其性能。
总而言之,本文采用了一系列数据处理、建模和分析方法来解决水下航行器的导航精度问题,从而为海洋经济的发展提供了关键的支持。这些方法包括数据插值、k-means聚类、逻辑回归模型建立和灵敏度分析,为水下航行器提供了更准确的导航信息,从而促进了海洋资源的可持续开发。
关键词 k-means聚类、插值算法、支持向量机、决策树
一、问题重述
1.1问题背景
中国正在积极推进"海洋强国"战略,特别是在辽宁省,该省拥有广阔的海域和海岸线,成为海洋经济发展的关键地区。其中,水下导航技术的创新被视为实现这一目标的关键核心技术之一。
水下航行器在执行任务时需要准确导航和定位,以实现自主、无源、高隐蔽性,并克服地理和时间上的限制。为了实现这一目标,一种主要方法是使用重力辅助导航系统。在这个系统中,选择适配区是确保导航可靠性和精度的关键步骤。适配区是指与水下任务相关的区域,其特征在于与重力异常有关。
重力异常是由于地球内部物质密度分布的不均匀性引起的,这导致实际观测到的重力值与理论上的正常重力值存在差异。为了选择适配区,需要分析海域的重力基准图,这包括插值和加密处理,以了解水下航行器将要操作的区域的重力异常变化情况。
重力异常的变化对导航系统的定位精度具有重要影响。在重力异常显著变化的区域,导航系统可以提供高精度的定位。相反,在重力异常变化平坦的区域,导航系统的定位精度较低。由于不同区域的重力异常分布不同,因此建立适配区分类预测模型对于确保水下航行器的导航精度至关重要。
为了解决这一问题,可以使用数学模型,其中X表示影响适配区匹配性的特征属性指标,Y表示描述区域适配性的输出结果,而F是一个分类预测系统,其输入为X,输出为Y。该模型将利用重力异常数据来预测和分类适配区,从而支持水下航行器的高精度导航和定位,以满足"海洋强国"战略的要求。
1.2问题重述
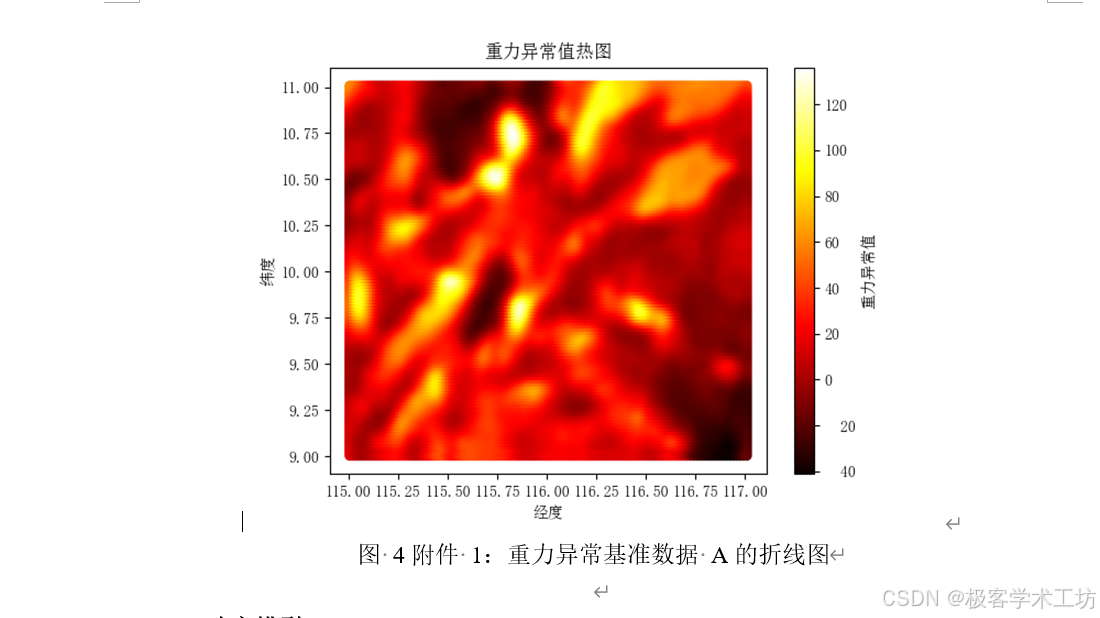
问题一:在附件1中,我们提供了一组分辨率为1'x1'的重力异常基准数据集A。您需要使用这些数据,通过精细化基准图,将海域划分成合理的区域,并为每个区域分配适配性标签Y。这将帮助确定每个区域在水下导航中的适配性程度。
问题二:基于问题一中各划分区域的适配性标定结果Y,您需要选择合适的区域特征属性指标(特征X)。然后,您将建立一个有效的分类预测模型(系统F),该模型以这些特征X作为输入,以适配性标签Y作为输出,以预测每个区域的适配性。这将有助于水下导航系统更好地选择适配区域。
问题三:现在,使用附件2中的另一组重力异常基准数据集B,您需要对问题二中建立的系统F进行迁移性预测。这意味着您要评估系统F在处理新的重力异常数据B时的性能。您需要讨论系统F对新重力异常数据的适用性,以确定它是否可以成功地预测新数据的适配性,从而支持水下导航的高精度定位。
- 问题分析
问题一涉及数据预处理、区域划分和适配性标定。首先,导入附件1的重力异常基准数据A,确保数据质量和一致性。随后,进行数据清洗以处理任何缺失或异常值。接下来,将海域划分成1'x1'的格点或单元格,然后计算每个单元格的内部重力异常均值或其他相关统计量,以描述该单元格的重力异常特征。最后,基于重力异常的统计信息,为每个单元格分配适配性标签Y,可以是离散值或连续值,具体标定方式需根据任务需求确定。
问题二涉及建立区域适配性分类预测模型。首先,使用从问题一中获得的适配性标定结果Y作为目标变量。然后,从重力异常数据A中选择一组特征属性指标X,这些指标应与适配性相关,例如内部的重力异常均值、标准差、梯度等。特征选择可以使用相关性分析、方差分析或特征重要性评估等方法确定最相关的特征。随后,使用选定的特征X和适配性标签Y来训练分类预测模型F,可以选择合适的分类算法,如决策树、随机森林、支持向量机或神经网络。最后,评估模型的性能,包括准确性、召回率、精确度等指标,进行参数调整以获得最佳性能。
问题三涉及迁移性预测和讨论模型F的适用性。首先,导入附件二中的重力异常基准数据B,并进行与问题一相似的数据预处理步骤。随后,使用已建立的模型F对新的重力异常数据B进行预测,并评估模型在新数据上的性能,了解模型是否适用于不同地理区域或时间段的数据。最后,讨论模型F在新数据上的性能表现,包括可能的误差来源,并分析新数据B与训练数据A之间的相似性和差异,以确定模型迁移性的局限性。
综上所述,解决这些问题需要进行数据预处理、适配性标定、特征选择、模型建立和模型评估。在问题三中,还需要考虑模型的迁移性和适用性,以确保水下航行器的导航精度和可靠性。
三、模型假设
对于上述建立区域适配性分类预测模型的步骤,以下是模型假设:
1.空间均质性假设:模型假设海域内的地质特征在每个1'x1'的格点内是空间均质的,即格点内的地质特征可以用单一数值(如重力异常均值)来表示。
2.相关性假设:模型假设适配性与重力异常数据中的某些特征属性之间存在相关性,这些特征属性可以被用来预测适配性。
3.数据质量假设:模型假设导入的重力异常数据是准确、完整且一致的,没有显著的错误或缺失值。
4.训练数据代表性假设:模型假设通过使用训练数据A建立的模型F可以适用于相似地理区域或时间段的新数据B。
5.特征独立性假设:如果使用多个特征属性来预测适配性,模型可能假设这些特征在预测中是相互独立的。
6.预测稳定性假设:模型假设适配性分类模型F在相似条件下(例如,相似的地质条件)的预测结果是稳定的,即在不同时间段或地点下具有一致的性能。