SpringBoot+openGauss DataVec构建高效RAG知识库实践
目录
- 🦁一. 写在前面
- 🦁二. 背景与动机
- 2.1 实现逻辑
- 2.2 项目结构
- 🦁三. 业务实现逻辑
- 3.1 初始化与索引
- 3.2 生成向量
- 3.3 数据写入与检索
- 3.4 演示效果
- 🦁四. openGauss扮演的重要作用

🦁一. 写在前面
RAG(检索增强生成)技术采用“检索外部知识结合大模型生成”的混合架构,在企业问答系统、智能文档助手及研发知识库等实际应用中有效提升了回答的准确性和结果可解释性。该技术通过将权威数据集中存储在可控的数据库内,避免了传统方案依赖模型自身记忆的局限性。以openGauss的DataVec向量引擎为例,其实现了高效且可治理的向量数据管理,从技术层面解决了黑盒向量库常见的数据孤岛问题。

🦁二. 背景与动机
企业需要统一的数据治理、事务一致性与权限控制,同时希望利用向量检索的语义能力,但传统“关系库+独立向量库”双栈方案存在两套运维与一致性问题。openGauss DataVec通过将向量能力融入关系数据库内核,允许用户使用熟悉的SQL操作向量数据,既保留ACID事务特性,又提供高维向量检索功能,成为构建企业级RAG(检索增强生成)应用的理想底座,有效解决了多系统协同的复杂性。现在基于SpringBoot+openGauss DataVec 构建高效 RAG知识库实战。
2.1 实现逻辑
- 嵌入:将文本转成向量(可用 OpenAI 或内部模型,文中示例默认用 mock 便于演示)。
- 存储:在 openGauss 建表,使用 VECTOR(dim) 列保存嵌入。
- 索引:为向量列创建 IVFFLAT 索引提升近似最近邻检索性能。
- 检索:按距离操作符排序( <-> L2、 <=> Cosine、 <#> Inner Product)取 TopK。
- 生成(可选):把检索到的上下文喂给大模型进行答案生成;本文只做检索演示。
2.2 项目结构
- Application.java :应用入口。
- RagProperties + RagConfig :RAG 配置与嵌入服务装配。
- DatabaseInitializer :初始化 DataVec 扩展、建表与索引。
- EmbeddingService :抽象嵌入; MockEmbeddingService 、 OpenAIEmbeddingService 两种实现。
- DocumentRepository :插入与相似度检索。
- RagService :业务封装。
- RagConsoleRunner :控制台演示 Runner。
- application.yml :数据库与 RAG 行为配置。
🦁三. 业务实现逻辑
3.1 初始化与索引
在初始化过程中,先创建 datavec 扩展,这是一个 PostgreSQL 扩展,支持向量数据类型的处理,确保数据库具备进行向量计算的能力。接着,创建一个documents的表,用于存储文档内容及其对应的向量嵌入,表结构包含一个自动递增的主键 id,存储文本文档的 content,以及存储向量表示的 embedding,后者的维度由 props.getEmbeddingDim() 确定。最后,根据配置的距离度量(如 L2、内积、余弦相似度)创建一个 IVFFLAT 索引,以支持高维向量的快速检索,使用 jdbcTemplate 执行 SQL 语句的同时,将距离度量参数传入索引创建语句中,lists = 100 则表示在索引创建时将数据分割成 100 个“列表”,这有助于提升检索性能,需根据实际数据集和需求进行调整。
@PostConstruct
public void init() {// 1) 创建 datavec 扩展(需权限)try {jdbcTemplate.execute("CREATE EXTENSION IF NOT EXISTS datavec");} catch (Exception ignored) {}// 2) 建表:文本 + 向量String createTable = "CREATE TABLE IF NOT EXISTS documents (" +"id BIGSERIAL PRIMARY KEY," +"content TEXT NOT NULL," +"embedding VECTOR(" + props.getEmbeddingDim() + ") NOT NULL)";jdbcTemplate.execute(createTable);// 3) 建 IVFFLAT 索引(按距离选择 ops)String ops = switch (props.getDistance().toLowerCase()) {case "l2" -> "vector_l2_ops";case "ip" -> "vector_ip_ops";default -> "vector_cosine_ops";};String createIndex = "CREATE INDEX IF NOT EXISTS idx_documents_embedding " +"ON documents USING ivfflat (embedding " + ops + ") WITH (lists = 100)";jdbcTemplate.execute(createIndex);
}
- DataVec 语法要点:
-- 列类型:VECTOR(1536)
-- 距离操作符:
-- L2: <->
-- Cosine: <=>
-- InnerProd:<#>
3.2 生成向量
-
伪随机性: 利用文本内容生成随机种子,使得同样的输入文本在多次调用时返回一致的随机向量。这通过 seedFrom(text) 实现,确保了随机性与输入文本的关联性。
-
向量生成: 使用高斯分布生成指定维度的随机数,将其作为向量的初步表示。每个维度的值是通过 nextGaussian() 方法生成的,符合正态分布。
-
归一化: 计算向量的范数,并将向量归一化,使得向量的长度(或模)为 1。这一步确保生成的向量在后续计算中不会因规模差异而影响结果,适合做相似度计算或插值。
@Override
public float[] embed(String text) {Random r = new Random(seedFrom(text));float[] v = new float[dim];double norm = 0;for (int i = 0; i < dim; i++) { v[i] = (float) r.nextGaussian(); norm += v[i]*v[i]; }norm = Math.sqrt(norm);if (norm > 0) for (int i = 0; i < dim; i++) v[i] /= (float) norm;return v;
}
3.3 数据写入与检索
-
文档存储: 通过 insert 方法,系统可以将用户上传的文本及其向量表示存储在数据库中,便于后续检索。
-
相似性检索: 通过 searchByEmbedding 方法,用户能够根据给定的文本向量快速找到内容相似的文档,支持信息检索和推荐系统的实现。
public int insert(String content, float[] embedding) {String sql = "INSERT INTO documents(content, embedding) VALUES (?, ?)";return jdbcTemplate.update(sql, content, toVectorLiteral(embedding));
}public List<String> searchByEmbedding(float[] query, int topK) {String op = switch (props.getDistance().toLowerCase()) {case "l2" -> "<->"; case "ip" -> "<#>"; default -> "<=>";};String sql = "SELECT content FROM documents ORDER BY embedding " + op + " ? LIMIT ?";return jdbcTemplate.query(sql, new Object[]{toVectorLiteral(query), topK},(rs, rowNum) -> rs.getString(1));
}
通过结合嵌入向量的处理与数据库的存储与检索,实现了文档的管理,使得用户能够有效地添加和查找相关信息:
public void addDocument(String content) {float[] v = embeddingService.embed(content);repository.insert(content, v);
}
public List<String> retrieve(String query) {float[] q = embeddingService.embed(query);return repository.searchByEmbedding(q, props.getSearchTopK());
}
3.4 演示效果
先往rag库中插入一段向量数据,我这里使用Qwen/Qwen3-Embedding-0.6B模型生成向量:

再通过openGauss的DataVec的“向量相似度”排序完成,返回前k个最相似的语句:
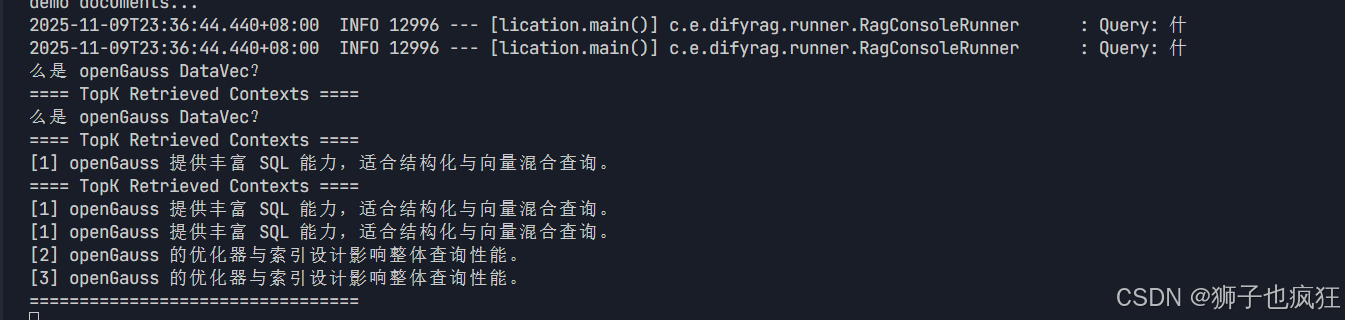
我们在提问问题:什么是openGauss DataVec?
到数据库进行向量检索,openGauss数据库用DataVec的距离操作符进行排序返回前k个相似度最高的答案,根据输出内容,我们能判断出其返回的答案是相对正确的。
🦁四. openGauss扮演的重要作用
本项目利用了openGauss强大的DataVec核心搭建了高效的RAG知识库实战。 DataVec具备强大的向量内核特性,支持 VECTOR 类型、距离操作符和向量索引,使其在性能和稳定性方面表现可靠。通过 SQL First 方法,用户可以轻松使用纯 SQL 语句操作向量和结构化数据,例如使用 ORDER BY embedding <=> ? 一条语句即可完成相似度检索。同时,DataVec 支持在同一条 SQL 查询中融合向量检索与结构化过滤,满足复杂业务场景的需求,如分类过滤、时间窗口和租户隔离。此外,IVFFLAT 等近似索引能够显著提升检索性能,并可以根据具体场景灵活调整 lists 和 probes 等参数。最后,DataVec 兼容性强,支持 JDBC 接入,降低迁移成本,并能与 Spring Boot、ORM 以及 BI 工具等生态系统良好配合。

🦁 其它优质专栏推荐 🦁
🌟《Java核心系列(修炼内功,无上心法)》: 主要是JDK源码的核心讲解,几乎每篇文章都过万字,让你详细掌握每一个知识点!
🌟 《springBoot 源码剥析核心系列》:一些场景的Springboot源码剥析以及常用Springboot相关知识点解读
欢迎加入狮子的社区:『Lion-编程进阶之路』,日常收录优质好文
更多文章可持续关注上方🦁的博客,2025咱们顶峰相见!