怎么用数据仓库来进行数据治理?
目录
一、 数据治理和数据仓库
1、数据治理
2、数据仓库
二、 如何利用数据仓库开展数据治理
第一步:定规矩
第二步:管质量
第三步:建目录
第四步:保安全
第五步:管生命周期
四、 一些必须知道的提醒
总结
在我做数据支持那段时间,一开始团队总是会出现这些情况:
- 销售团队说“活跃用户”日均十万,市场部报表上却显示十五万,两边争得面红耳赤却谁也说服不了谁;
- 要做一个重要的业务分析,发现需要的数据分散在五六个系统中,光是收集整理就要花上一周时间;
- 当你终于拿到数据时,却不敢完全相信它的准确性。
这些看似棘手的问题,其实都指向同一个根源:缺乏有效的数据治理。
那么到底该怎么解决这些问题?今天我就从数据仓库的角度来聊聊,怎么让数据从组织的负担转变为真正的资产。
一、 数据治理和数据仓库
1、数据治理
其实就是一整套关于数据的规矩和管理办法。它的核心目的,是确保组织里的数据是可信的、安全的、容易找到且能被正确理解的。
我一直强调,数据治理不是一个一次性项目,而是一个需要持续运营的过程。它就像城市的交通管理,不仅需要道路等基础设施,更需要持续的规则维护与大家的共同遵守。
2、数据仓库
你可以把它理解为一个专门为分析和决策服务的、高度组织化的“数据中央厨房”。
数据仓库就是从业务系统(比如ERP、CRM)中获取数据,进行清洗、转换、整合,最终组织成适合进行分析查询的结构,服务于报表、分析和决策支持。
那么,数据仓库和数据治理之间,究竟是怎样一种关系呢?
简单来说,数据仓库是数据治理理念最核心的承载者和实践者。 为什么这么说?
- 实现数据的物理集中:数据治理首先要打破数据孤岛。数据仓库通过ETL过程,将分散在各处的数据物理上集中到一个地方,这为后续的统一管理提供了基础。你懂我意思吗?如果数据都不在一起,你定再多的规矩,也落不了地。
这是打造数据仓库最关键的第一步,后续的行动都围绕着这些数据进行。我们可以用专门的数据集成工具来收集数据,FineDataLink就是这方面专家,它能接入多个数据源,还可以实时同步数据,此外还能帮你省去写复杂代码的时间。工具体验地址:https://s.fanruan.com/8hhzn(复制到浏览器打开)
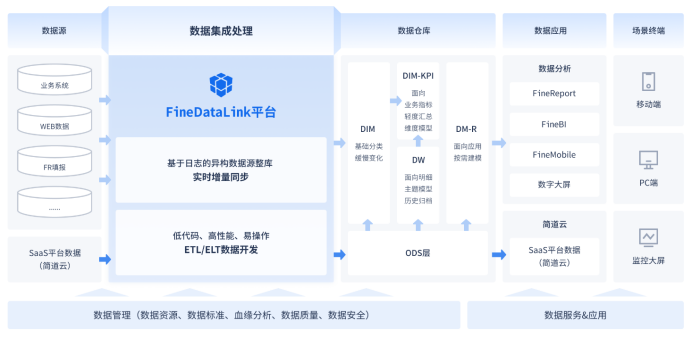
- 提供统一的加工平台:在数据仓库里,我们可以定义统一的业务规则。比如,统一客户性别、金额单位等基础数据的表示方式。这个加工过程本身,就是在执行数据治理的“标准化”要求。
- 它是数据质量的“检验场”:数据在进入仓库时,会经历严格的清洗和校验。这些检查规则,就是数据治理中数据质量管理的具体体现。
- 它是数据资产目录的基石:当数据在仓库里被整理成清晰的模型,并配有详细的说明时,一个可用的数据资产目录就自然形成了。
因此,我们必须认识到:没有数据仓库,数据治理很容易流于纸上谈兵;而没有数据治理指导的数据仓库,则会变成另一个更庞大的数据垃圾场。二者是相辅相成,缺一不可的。
明白了这个关系,接下来我们看看具体该如何操作。
二、 如何利用数据仓库开展数据治理
下面,我们进入最干的干货部分。具体怎么做?我们可以把这个过程拆解成几个关键步骤。
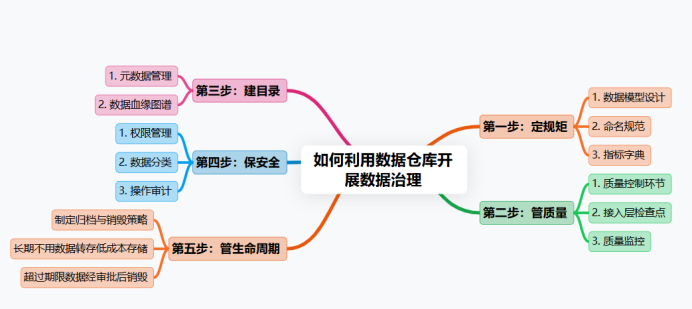
第一步:定规矩
在数据开始流入数据仓库之前,我们必须先把“规矩”定好。这包括:
- 数据模型设计:采用经典的维度建模理论,设计清晰的事实表和维度表。这个设计过程,本身就是对业务概念的一次统一和梳理。
- 命名规范:库、表、字段的命名必须有统一的规范。这样做,任何人看到表名就能大致知道它的内容。
- 指标字典:建立企业级的指标字典。明确每一个业务指标的业务定义、统计口径、计算公式、数据来源和负责人。这个字典应该被所有业务和技术人员共享和遵守。
这一步就是后续所有动作的基石。规矩定好了,但如何确保这些规矩能被忠实执行呢?
第二步:管质量
数据通过ETL/ELT流程流入数据仓库,这个环节是质量控制的黄金节点。
- 在接入层设置检查点:在数据正式进入数据仓库核心层之前,建立一个缓冲层。在这里,对数据进行全方位的检查:
- 完整性检查:关键字段不能为空。
- 一致性检查:数据格式、枚举值是否符合预期。
- 准确性检查:数值是否在合理的业务范围内。
- 唯一性检查:主键是否重复。
- 建立质量监控和告警机制:对于检查中发现的问题数据,要记录到质量日志中,并自动通知相关负责人。
这一步,是确保进入我们“中央厨房”的原材料都是合格的。
数据质量有了基本保障,但如何让这些高质量的数据真正被理解、被用好呢?
第三步:建目录
数据规整地存放在仓库里了,但如果别人看不懂,依然无法充分发挥价值。这就需要用元数据管理来激活它。
- 采集技术元数据:自动采集表的名称、字段、类型、血缘关系等信息。
- 补充业务元数据:这是最关键的一步。需要人工为核心的表和字段添加业务注释。
- 构建数据血缘图谱:通过工具可视化地展现数据的来龙去脉。当某个指标出错时,可以快速定位问题源头;当上游系统发生变更时,可以评估影响范围。
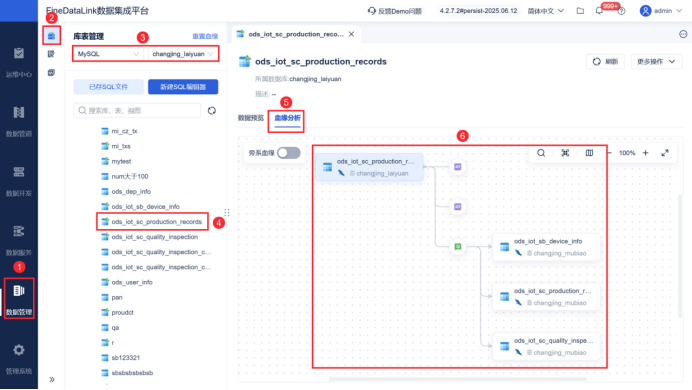
我一直强调,元数据是数据的“说明书”,没有说明书的数据,价值会随时间急剧衰减。
数据变得清晰易懂了,但问题是:如何安全地使用它们?
第四步:保安全
数据安全是数据治理的红线。在数据仓库层面,我们可以做很多事情。
- 权限分级:基于“最小权限原则”分配访问权限。可以按数据主题、按行、按列进行精细化的权限控制。
- 数据分级分类:定义数据的敏感级别,比如公开、内部、秘密、绝密。对不同级别的数据,采取不同的安全策略。
- 操作审计:记录所有对数据仓库的访问和查询操作,谁在什么时候查了什么。这既是为了安全,也是为了溯源。
安全策略保障了数据使用的合规性,但还有一个影响效率和成本的因素需要考虑。
第五步:管生命周期
数据仓库不是无底洞,需要定期清理。
制定数据归档和销毁策略:比如,将长期不用的历史数据从高速存储转移到低成本对象存储中;对超过保留期限的数据,在履行完审批流程后予以销毁。
这样做既能控制成本,也能保证核心数据的查询性能。
四、 一些必须知道的提醒
最后,这里有几点需要注意:
- 工具是辅助,人才是核心:再好的数据仓库工具和治理平台,也需要一个跨部门的数据治理委员会来制定规则、裁决争端、推动执行。技术解决不了所有的管理问题。
- 循序渐进,小处着手:不要幻想一口吃成胖子。从一个最痛的业务域开始,做出一个成功的样板,让大家看到数据治理带来的实实在在的价值,再逐步推广。
- 数据仓库是基石,但不是全部:数据湖、湖仓一体等新架构的出现,扩展了数据管理的边界。但无论架构如何演变,数据治理的核心思想:标准化、质量、安全是永恒的。数据仓库依然是实现这些目标最成熟、最稳定的载体之一。
总结
说到底,数据治理就是依托于数据仓库等一系列技术手段的持续实践。
用过来人的经验告诉你,成功的核心不在于工具多先进,而在于团队能否就数据的定义、标准和质量达成共识,并持之以恒地执行。
数据仓库提供了实施治理的理想平台,让散乱的数据变得规整、可信、可用;更重要的是,它能让你和你的团队亲眼看到数据质量提升后,为分析决策带来的巨大价值。你说是不?