【多模态大模型面经】 BERT 专题面经

🧔 这里是九年义务漏网鲨鱼,研究生在读,主要研究方向是人脸伪造检测,长期致力于研究多模态大模型技术;国家奖学金获得者,国家级大创项目一项,发明专利一篇,多篇论文在投,蓝桥杯国家级奖项、妈妈杯一等奖。
✍ 博客主要内容为大模型技术的学习以及相关面经,本人已得到B站、百度、唯品会等多段多模态大模型的实习offer,为了能够紧跟前沿知识,决定写一个“从零学习 RL”主题的专栏。这个专栏将记录我个人的主观学习过程,因此会存在错误,若有出错,欢迎大家在评论区帮助我指出。除此之外,博客内容也会分享一些我在本科期间的一些知识以及项目经验。
🌎 Github仓库地址:Baby Awesome Reinforcement Learning for LLMs and Agentic AI
📩 有兴趣合作的研究者可以联系我:yirongzzz@163.com
前言
✍ 本专题假设读者已经具备一定的深度学习与 Transformer 基础,目标是帮助读者系统地复习 BERT 模型的核心设计思想与常见面试问法。本专题来源于本人在面试 NLP / LLM / 多模态预训练相关岗位时的真实问题与个人总结,本章的重点是为什么GPT的【MASK】设计会导致数据泄露?为什么BERT在取代【MASK】保留原词的时候就不会导致数据泄露?等比较深入的问题
文章目录
- 前言
- @[toc]
- 一、BERT 基本架构
- 🧠 1. Transformer、GPT、BERT 架构分别是什么,为什么要这么用?
- 🧠 2. 介绍一下BERT的训练过程
- 二、BERT: Pre-training
- 🧠 3. 预训练任务有哪几个任务
- 2.1 Masked Language Model (MLM)
- 🧠 4. 为什么只有80%被替换为[MASK],而不是全部
- 2.2 Next Sentence Prediction(NSP )
- 🧠 5. NSP 的作用是什么?为什么后来的模型(如 RoBERTa)去掉了 NSP?
- 🧠 6. 后续模型是如何替代 NSP 的?
- 三、BERT 手撕代码模块
- 1️⃣ Masked LM
- 2️⃣ Next Sentence Prediction
- 3️⃣ BERT Embedding
文章目录
- 前言
- @[toc]
- 一、BERT 基本架构
- 🧠 1. Transformer、GPT、BERT 架构分别是什么,为什么要这么用?
- 🧠 2. 介绍一下BERT的训练过程
- 二、BERT: Pre-training
- 🧠 3. 预训练任务有哪几个任务
- 2.1 Masked Language Model (MLM)
- 🧠 4. 为什么只有80%被替换为[MASK],而不是全部
- 2.2 Next Sentence Prediction(NSP )
- 🧠 5. NSP 的作用是什么?为什么后来的模型(如 RoBERTa)去掉了 NSP?
- 🧠 6. 后续模型是如何替代 NSP 的?
- 三、BERT 手撕代码模块
- 1️⃣ Masked LM
- 2️⃣ Next Sentence Prediction
- 3️⃣ BERT Embedding
一、BERT 基本架构
BERT 全称为 Bidirectional Encoder Representations from Transformers,由 Google AI 在 2018 年提出,奠定了后续预训练语言模型(PLM)发展的基石。
📚️ 论文地址:arxiv地址
BERT与Transformer不同,和GPT一样沿用了Transformer的基本架构, 不同的是,BERT是基于 Transformer Encoder 堆叠的模型,舍弃了 Transformer 的 Decoder,仅保留 Encoder 部分, 是一个堆叠了 LLL 层 Encoder 的纯 Transformer 编码器模型。作者提出了两个大小的BERT模型:
| 模型 | 层数 (L) | 隐层维度 (H) | 注意力头数 (A) | 参数量 | 备注 |
|---|---|---|---|---|---|
| BERT Base | 12 | 768 | 12 | ~110M | 与GPT大小相同 |
| BERT Large | 24 | 1024 | 16 | ~340M | 更高表达力,训练更慢 |
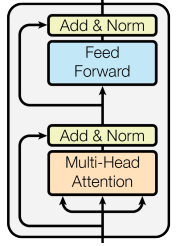
面试官很喜欢问大模型架构之间的区别,例如:
🧠 1. Transformer、GPT、BERT 架构分别是什么,为什么要这么用?
| 代表模型 | 方向 | 任务类型 | 优势 | 劣势 |
|---|---|---|---|---|
| BERT, RoBERTa | Encoder-only | 理解(分类、匹配、QA) | 双向上下文、语义表达强 | 无法生成、mask训练慢 |
| GPT serious | Decoder-only | 生成(文本生成、对话) | 自回归生成自然、训练目标简单 | 单向建模、理解弱 |
| Transformer, T5, BART | Encoder–Decoder | 理解+生成(摘要、翻译) | 二者兼顾,可用于指令模型 | 训练/推理复杂度高 |
BERT对于初学者来说,好像也是一个生成任务,但实际上,BERT是在做一个完形填空的任务。
🧩 举个例子:
输入:我爱 [MASK] 学习
→ BERT 能预测“机器”
输入:我爱学习
→ BERT 无法生成接下来的“因为我有热情”,因为它没有解码器。
因此,BERT 的 MLM 任务确实有“生成”行为,但它并不是自回归意义上的生成模型。 它预测被mask的token,而不是像GPT一样输入一个句子,依次生成一个完整的句子。
🧠 2. 介绍一下BERT的训练过程
BERT 的训练分为两个阶段:
-
预训练(Pre-training):在大规模无监督语料上进行语言建模任务学习。
-
下游微调(Fine-tuning):在下游任务(分类、问答、序列标注等)上,用任务特定的输入格式(加上
[CLS]、[SEP]标志),再加上一个小的输出层。
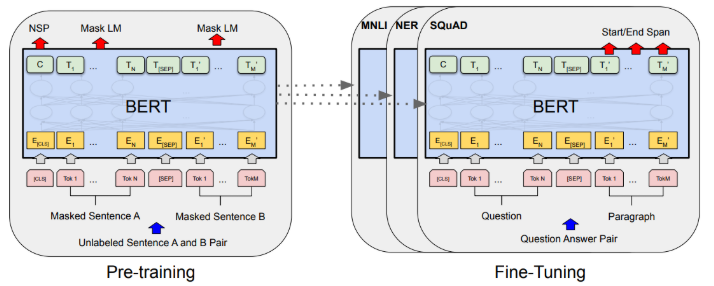
二、BERT: Pre-training
在面试过程中,只要你的简历上涉及到了BERT,BERT一定会问你一个问题:
🧠 3. 预训练任务有哪几个任务
| 任务 | 缩写 | 作用 | 举例 |
|---|---|---|---|
| Masked Language Model | MLM | 学习双向上下文 | 猜被 [MASK] 的词 |
| Next Sentence Prediction | NSP | 学习句子间关系 | 判断 B 是不是 A 的下一句 |
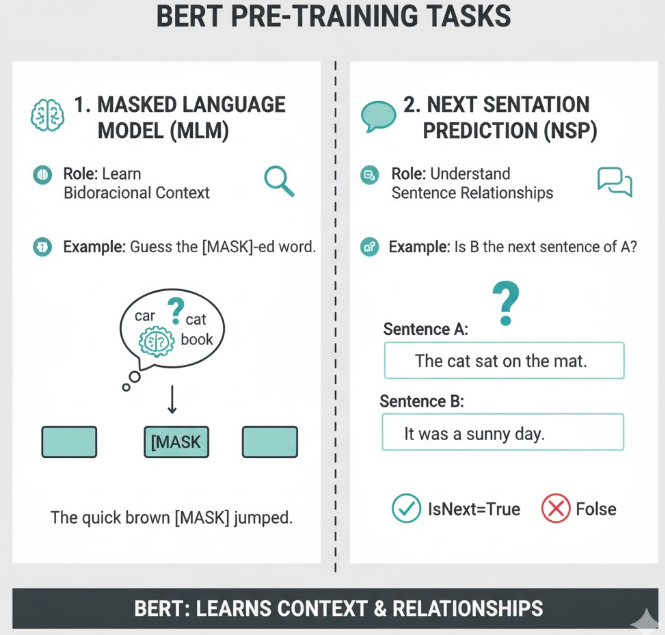
2.1 Masked Language Model (MLM)
传统的语言模型(例如 GPT)是条件概率建模,
P(x1,x2,...,xn)=∏t=1nP(xt∣x1,...,xt−1)P(x_1, x_2, ..., x_n) = \prod_{t=1}^{n} P(x_t | x_1, ..., x_{t-1})P(x1,x2,...,xn)=t=1∏nP(xt∣x1,...,xt−1)
也就是逐词预测下一个 token。这乍一看好像也可以实现双向,假设我们想让模型学:
P(xt∣x1,...,xt−1,xt+1,...,xn)P(x_t | x_1, ..., x_{t-1}, x_{t+1}, ..., x_n)P(xt∣x1,...,xt−1,xt+1,...,xn)
也就是同时看到左右上下文。但问题是:如果模型的多层 self-attention 可以访问所有位置的信息,通过其他 token 的上下文聚合,模型仍然可能在深层“绕回来”获取自己的信息, “间接地”访问到自己的真实词。
🧩 举个例子:
输入: I love NLP, 想预测 token: “love”
Layer 1: “love” attends to “I” and “NLP”
Layer 2: “NLP” attends back to “love”
这样“love”通过“间接路径”又拿到了自己的 embedding,
因此,BERT 引入了 Masked Language Modeling (MLM) 预训练目标,让模型能够同时看到 左右上下文。在预训练时,BERT会随机遮蔽输入序列中 15% 的 token. (其中有80%被替换为[MASK], 10% 替换为随机词, 10% 保留原词)任务是预测被遮蔽的词:
Input: “I love [MASK] learning.” Output: “I love deep learning.”
模型通过上下文(左右两侧)推测被 Mask 的词,因此学习到双向语义信息。
🧠 4. 为什么只有80%被替换为[MASK],而不是全部
下游任务的输入从来没有 [MASK]。但如果预训练时几乎所有预测目标都依赖 [MASK] 特征,模型就会学会“见到 [MASK] 才认真预测”,而当 fine-tune 阶段没有 [MASK] 时,它的表现会退化。这样做是为了防止模型过度依赖 [MASK] 符号,增强鲁棒性。
学到这里,可能有些读者就有些疑惑了,为什么这里就可以保留原词了呢?保留原词不就又导致数据泄露了吗?如果你有此疑问,可以继续看下去。
BERT 的整体过程是这样的:
- 先随机选出 15% 的 token → 这些位置是“潜在的预测目标”。
- loss 只计算在这 15% 的位置上。
模型虽然“输入里看到 love”,但它并不知道 “love” 是要被预测的位置。所以它的“泄露”是表层信息流的可见,而非训练信号(loss 反传)层面的泄露。
2.2 Next Sentence Prediction(NSP )
NSP任务是判断 B 是不是 A 的下一句:
| 输入A | 输入B | 标签 |
|---|---|---|
| I went to the store. | I bought some milk. | IsNext |
| I went to the store. | Penguins live in Antarctica. | NotNext |
其中50% 的样本中,B 是 A 的真实下一句;50% 是随机句子;BERT 输入由两句话拼接而成,用 [SEP] 分隔:
[CLS] Sentence A [SEP] Sentence B [SEP]
模型通过 [CLS] 向量预测是否为“下一句”。
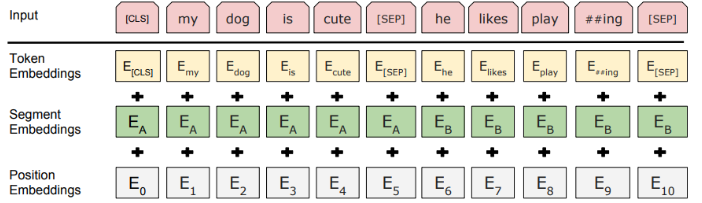
🧠 5. NSP 的作用是什么?为什么后来的模型(如 RoBERTa)去掉了 NSP?
NSP 想让模型不仅理解句内词之间的关系, 还要理解句与句之间的语义连续性(discourse-level coherence)。
后续实验(尤其是 RoBERTa 和 ALBERT)发现 NSP 的问题主要有两点:
① 任务过于简单 :随机拼句 vs. 连续句 这个二分类太容易。模型可以仅靠表面统计特征(比如主题词、长度、标点)来判断,而非真正理解上下文。
② 难以泛化到真实句间关系任务:下游任务(如 QA、NLI)要求模型理解 逻辑推理(entailment、contradiction、causality),但 NSP 学到的只是“句子 A 和句子 B 是否相邻”
🧠 6. 后续模型是如何替代 NSP 的?
| 模型 | NSP 是否保留 | 替代机制 |
|---|---|---|
| RoBERTa | ❌ 去掉 NSP | 用更长连续文本训练(512 tokens),依赖 MLM 自行捕获句间依存 |
| ALBERT | ✅ 改进 | 引入 SOP(Sentence Order Prediction):判断两句是否调换顺序,更关注语义连贯性 |
| ELECTRA | ❌ 去掉 NSP | 改为 RTD(Replaced Token Detection),更细粒度的预训练信号 |
三、BERT 手撕代码模块
1️⃣ Masked LM
import torch
import torch.nn as nn
import torch.nn.functional as Fclass MaskedLanguageModel(nn.Module):def __init__(self, vocab_size, hidden_dim):super().__init__()self.transform = nn.Linear(hidden_dim, hidden_dim)self.layer_norm = nn.LayerNorm(hidden_dim)self.decoder = nn.Linear(hidden_dim, vocab_size, bias=False)def forward(self, hidden_states, masked_positions):masked = hidden_states[torch.arange(hidden_states.size(0)), masked_positions]x = F.gelu(self.transform(masked))x = self.layer_norm(x)return self.decoder(x)
2️⃣ Next Sentence Prediction
class NextSentencePrediction(nn.Module):def __init__(self, hidden_dim):super().__init__()self.linear = nn.Linear(hidden_dim, 2)def forward(self, cls_vector):return self.linear(cls_vector)
3️⃣ BERT Embedding
class BertEmbedding(nn.Module):def __init__(self, vocab_size, hidden_dim, max_len=512, segment_size=2):super().__init__()self.word_embeddings = nn.Embedding(vocab_size, hidden_dim)self.position_embeddings = nn.Embedding(max_len, hidden_dim)self.segment_embeddings = nn.Embedding(segment_size, hidden_dim)self.layer_norm = nn.LayerNorm(hidden_dim)self.dropout = nn.Dropout(0.1)def forward(self, input_ids, segment_ids):seq_len = input_ids.size(1)position_ids = torch.arange(seq_len, device=input_ids.device).unsqueeze(0)embeddings = (self.word_embeddings(input_ids)+ self.position_embeddings(position_ids)+ self.segment_embeddings(segment_ids))return self.dropout(self.layer_norm(embeddings))