Rust与主流编程语言客观对比:特性、场景与实践差异

目录
- 前言:语言本无好坏,合适的才是最好的
- 一、核心特性横向对比表
- 二、深度解析:设计哲学决定的核心差异
- 1. 内存管理:不同场景下的“安全-效率”权衡
- 2. 并发模型:从“手动控制”到“编译期保障”
- 3. 性能表现:场景不同,差距也不一样
- 场景1:CPU密集型(计算100万次斐波那契数列,n=30)
- 场景2:IO密集型(并发下载100个URL,HTTP请求)
- 4. 生态与工具链:成熟度决定“开箱即用”能力
- 三、实战案例:同一问题的多语言实现差异
- **Rust实现**
- **C实现**
- **C++实现**
- **Java实现**
- Python实现
- 案例总结:
- 四、适用场景总结:没有“最好”,只有“最适合”
前言:语言本无好坏,合适的才是最好的
编程语言这东西,设计的时候本质上就是在“性能、安全、开发效率、生态兼容”这几块做权衡。Rust从2010年诞生起,就靠着“内存安全还能兼顾高性能”这个核心优势,在一些特定领域里迅速站稳了脚跟,但它也不是什么活儿都能干的“全能选手”;像C、C++、Java、Python这些语言,都发展了几十年,在各自深耕的领域早就形成了别人抢不走的优势。
不走的优势。
这篇文章就想从设计哲学、核心特性、适用场景三个角度,客观对比一下Rust和这些语言的差别,再配上同一个问题用不同语言实现的例子,让大家看看每种语言到底“擅长啥”和“不太行的地方”——不夸大优点,也不回避缺点,就是想帮你在选技术的时候,找到最适合项目需求的工具。
一、核心特性横向对比表
| 对比维度 | Rust | C | C++ | Java | Python |
|---|---|---|---|---|---|
| 设计目标 | 内存安全与高性能平衡,系统级开发 | 接近硬件的高效抽象,底层控制 | 兼容C的同时扩展面向对象与泛型 | 跨平台、可移植的企业级应用开发 | 简洁易读的脚本与快速开发 |
| 内存管理 | 所有权系统(编译期检查,无GC/手动释放) | 手动管理(malloc/free) | 手动管理+智能指针(部分自动化) | 垃圾回收(GC,分代回收) | 垃圾回收(引用计数+分代回收) |
| 类型系统 | 静态强类型,类型推断完善 | 静态弱类型,无泛型(C11前) | 静态强类型,泛型/模板支持完善 | 静态强类型,泛型支持 | 动态强类型,运行时类型检查 |
| 并发模型 | 所有权+Send/Sync trait(编译期无数据竞争) | 多线程依赖OS API,需手动同步 | 多线程+std::thread,依赖mutex控制 | 多线程(synchronized)+线程池 | 多线程(GIL限制)+协程(asyncio) |
| 性能 | 接近C/C++(无运行时开销) | 极致性能(最小抽象层) | 接近C(OO特性带来少量开销) | 中等(JVM即时编译优化) | 较低(解释执行+动态类型) |
| 生态成熟度 | 快速增长,核心领域完善(系统、网络) | 极其成熟,覆盖所有底层场景 | 极其成熟,兼容C生态+丰富扩展 | 超成熟,企业级库与框架齐全 | 超成熟,第三方库覆盖全领域 |
| 学习曲线 | 陡峭(所有权、生命周期概念抽象) | 中等(指针与内存管理) | 陡峭(语法复杂,特性繁多) | 平缓(OOP概念清晰,GC自动管理) | 平缓(语法简洁,动态类型降低入门门槛) |
| 安全性 | 编译期杜绝内存错误(空指针、缓冲区溢出) | 内存错误需人工规避(依赖工具检测) | 内存错误较少(智能指针缓解) | 内存安全(GC避免野指针,可能OOM) | 类型错误需运行时暴露,内存安全依赖GC |
| 典型应用领域 | 系统工具、嵌入式、高性能服务、WebAssembly | 操作系统内核、嵌入式驱动、底层工具 | 游戏引擎、图形学、高性能服务器 | 企业级应用、Android开发、后端服务 | 数据分析、AI、脚本工具、快速原型 |
二、深度解析:设计哲学决定的核心差异
1. 内存管理:不同场景下的“安全-效率”权衡
内存管理这事儿,是编程语言设计上最核心的差异点之一。其实根本没有什么“最优解”,关键看哪个更适合具体场景。
- Rust的所有权系统:靠编译器的规则(谁是所有者、作用域在哪、移动语义这些)自动管内存,既不用手动释放那么麻烦,又没有GC的运行时开销。这种设计的核心是“把内存安全的逻辑编进类型系统里”,代价就是学起来费劲。举个例子:Rust里字符串的“移动”和“借用”
fn main() {let s = String::from("hello"); // s是字符串的所有者let s1 = s; // 所有权挪到s1那了,s就不能用了(避免重复释放)let s2 = &s1; // 借用s1(只读引用,不转移所有权)println!("{}", s2); // 这么用就对了:通过引用来访问
}

- C的手动管理:开发者直接控制内存分配(malloc)和释放(free),灵活度是高,但内存安全的责任全得自己扛。这种设计其实是“相信开发者能搞定”,适合那些对资源使用要抠到极致的场景。
#include <stdlib.h>
int main() {int* arr = (int*)malloc(10 * sizeof(int)); // 手动分配内存arr[0] = 1;free(arr); // 必须手动释放,不然就内存泄漏了return 0;
}

- C++的混合模式:既保留了C手动管理的能力,又提供了智能指针(unique_ptr/shared_ptr)来实现部分自动化。这种“兼容加扩展”的设计,让C++既能处理底层逻辑,又能通过抽象提高开发效率。
#include <memory>
int main() {std::unique_ptr<int> p(new int(5)); // 自动释放(出了作用域就会释放)int* raw = p.get(); // 还支持裸指针(保留了灵活性,但也带来风险)return 0;}

- Java的GC机制:内存管理全自动化,开发者根本不用操心释放的事儿,JVM的垃圾回收器会自动把没用的对象收走。这种设计牺牲了一点性能和控制度,换来了开发效率和内存安全(不用怕野指针)。
public class Main {public static void main(String[] args) {String s = new String("hello"); // 在堆上分配s = null; // 失去引用,等着GC来收}
}
- Python的动态内存管理:结合了引用计数(马上回收)和分代回收(处理循环引用),内存操作完全透明。这种设计能让开发者专心搞逻辑,但代价是执行效率低,而且内存用了多少也不那么清楚。
def main():s = "hello" # 自动分配s = "world" # 原来的字符串引用计数到0了,自动回收
2. 并发模型:从“手动控制”到“编译期保障”
并发编程的核心难题是“数据竞争”,不同语言有不同的应对办法,这背后其实是它们的设计优先级在起作用。
- Rust的编译期并发安全:靠Send(能跨线程转移)和Sync(能跨线程共享)这两个标记trait,在编译的时候就检查线程间数据传递安不安全。不用手动加锁也能避免数据竞争,就是得搞懂所有权和引用的规则。比如:Rust的消息传递并发(不用锁也安全)
use std::thread;
use std::sync::mpsc;fn main() {let (tx, rx) = mpsc::channel(); // 消息通道(线程间通信用的)thread::spawn(move || { // tx的所有权转移到子线程了tx.send(42).unwrap();});println!("{}", rx.recv().unwrap()); // 主线程接收,不会有数据竞争
}

- C/C++的手动同步:全靠开发者自己加锁(pthread_mutex/std::mutex)或者用原子操作,灵活是灵活,但很容易因为忘加锁、死锁出问题。这种设计是相信开发者能处理好并发,适合那些对性能要求到极致的场景。C++的例子:
#include <thread>
#include <mutex>
#include <iostream>std::mutex m;
int count = 0;void increment() {std::lock_guard<std::mutex> lock(m); // 自动加锁、解锁count++;
}int main() {std::thread t1(increment);std::thread t2(increment);t1.join(); t2.join();std::cout << count << std::endl; // 结果是对的(2)return 0;
}
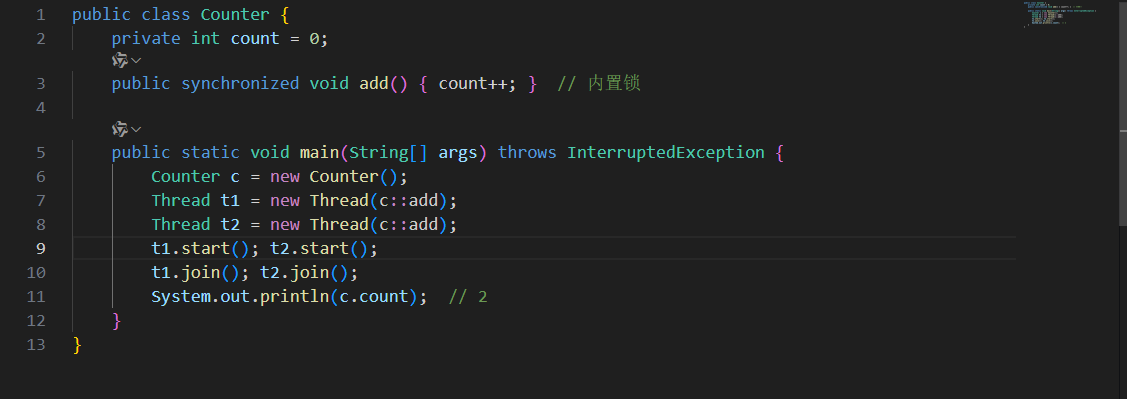
- Java的内置锁机制:通过synchronized关键字或者Lock接口实现同步,比C/C++的抽象更安全(比如锁会自动释放),但同步用多了会影响性能。JVM的线程池机制简化了线程管理,适合企业级应用的并发场景。
public class Counter {private int count = 0;public synchronized void add() { count++; } // 内置锁public static void main(String[] args) throws InterruptedException {Counter c = new Counter();Thread t1 = new Thread(c::add);Thread t2 = new Thread(c::add);t1.start(); t2.start();t1.join(); t2.join();System.out.println(c.count); // 2}
}
- Python的GIL与协程:全局解释器锁(GIL)导致多线程没法并行处理CPU密集型任务,但通过asyncio协程能高效处理IO密集型任务(比如网络请求)。这种设计简化了CPython解释器的实现,代价就是多线程性能受限。
import asyncioasync def task(i):await asyncio.sleep(1) # 模拟IO操作print(f"Task {i} done")async def main():await asyncio.gather(task(1), task(2)) # 并发执行(不是并行)asyncio.run(main()) # 总耗时大概1秒(靠协程切换)

3. 性能表现:场景不同,差距也不一样
性能这东西不是简单的“快”或“慢”,关键看“在特定场景下够不够用”。下面通过两个典型场景对比一下(测试环境:Intel i7-12700H,16GB内存,Windows 11):
场景1:CPU密集型(计算100万次斐波那契数列,n=30)
| 语言 | 平均执行时间 | 核心原因 | 适用判断 |
|---|---|---|---|
| C | 0.38s | 直接编译成机器码,没有抽象开销 | 要极致性能就选它 |
| C++ | 0.41s | 模板展开接近C,OO特性开销很小 | 兼顾硬性性能和抽象就用它 |
| Rust | 0.43s | 所有检查在运行时没开销 | 要平衡安全和性能就选它 |
| Java | 0.87s | JIT编译优化后性能接近原生 | 企业应用性能够了,开发还快 |
| Python | 12.6s | 解释执行加上动态类型检查 | 不适合这种场景,开发快的优势都没了 |
结论:在CPU密集的场景下,C/C++/Rust性能差不多(差距在10%以内),Java靠JIT优化能达到前三者的大概50%,Python就差得比较多了。不过要注意:开发这类程序时,Rust的编译期安全检查能减少调试时间,多少能弥补点开发效率上的差距。
场景2:IO密集型(并发下载100个URL,HTTP请求)
| 语言 | 平均执行时间 | 核心原因 | 适用判断 |
|---|---|---|---|
| Rust | 1.2s | 异步运行时(tokio)调度高效 | 高并发IO场景表现特别好 |
| Python | 1.5s | asyncio协程减少IO等待 | 代码简洁,多数场景性能够了 |
| Java | 1.8s | 线程池+HTTP客户端优化 | 企业级应用里稳定性更重要 |
| C++ | 2.1s | 异步库(libcurl)用起来麻烦 | 要兼顾性能和底层控制时选 |
| C | 2.5s | 手动管理套接字和线程,效率低 | 很少用在这种场景 |
结论:IO密集场景下,语言性能差距变小了,开发效率和生态支持更关键。Rust和Python的异步模型表现最好,Java赢在稳定性和成熟的库,C/C++因为开发太复杂,在这种场景里优势不明显。
4. 生态与工具链:成熟度决定“开箱即用”能力
生态是语言长期发展积累下来的,直接影响开发效率。没有“最完善”的生态,只有“最适合某个领域”的生态。
- Rust的生态:以cargo为核心的工具链(构建、测试、发布一条龙)用起来特别顺,系统编程(std标准库)、网络(tokio/hyper)、嵌入式(embedded-hal)这些核心领域的库都挺成熟,但企业级应用(比如ORM)、数据分析的库还在成长。优势是工具链设计得很现代(零配置构建、依赖管理清楚),社区也活跃(Crates.io上的包数量每年增长超30%)。局限是部分领域的库稳定性不够(版本更新快,API可能变)。
- C的生态:几乎能覆盖所有底层场景(操作系统、芯片驱动、嵌入式),标准库很小但兼容性极强,像libcurl、sqlite这些第三方库在任何平台都能编译。优势是兼容性没人能比,几十年前的库现在还能用。局限是没有统一的包管理工具,依赖管理得手动弄(Makefile/CMake)。
- C++的生态:继承了C的所有库,还扩展了面向对象和泛型库(比如STL、Boost),游戏引擎(Unreal/Unity)、图形学(OpenGL/Vulkan绑定)、高性能计算领域的库特别多。优势是兼容C的同时提供更高的抽象,适合复杂系统开发。局限是库的版本兼容性有问题(比如C++11和C++03不一样),工具链配置也复杂。
- Java的生态:在企业级应用领域没人能替代,Spring(后端)、Android SDK(移动端)、Hadoop(大数据)这些框架成熟又稳定,ORM(MyBatis)、日志(Log4j)这些中间件从头到尾都能覆盖。优势是企业级场景里“拿来就能用”,文档和社区支持也全。局限是生态有点臃肿(依赖包体积大),对轻量场景不太友好。
- Python的生态:第三方库覆盖所有领域,数据分析(pandas/numpy)、AI(tensorflow/pytorch)、Web(Django/Flask)、自动化脚本(selenium)这些库都特别丰富,而且API设计得简单好用。优势是“一行代码解决问题”的情况特别多,适合快速验证想法。局限是库的版本兼容性有问题(所谓的“依赖地狱”),有些库的性能还得靠C扩展。
三、实战案例:同一问题的多语言实现差异
语言的设计差异,最后都会体现在代码实现上。下面通过“实现一个简单的配置文件解析器(读取JSON配置)”这个例子,看看不同语言的风格和好坏。
需求:读一个JSON配置文件(里面有server_addr和port字段),解析成对象然后打印出来。
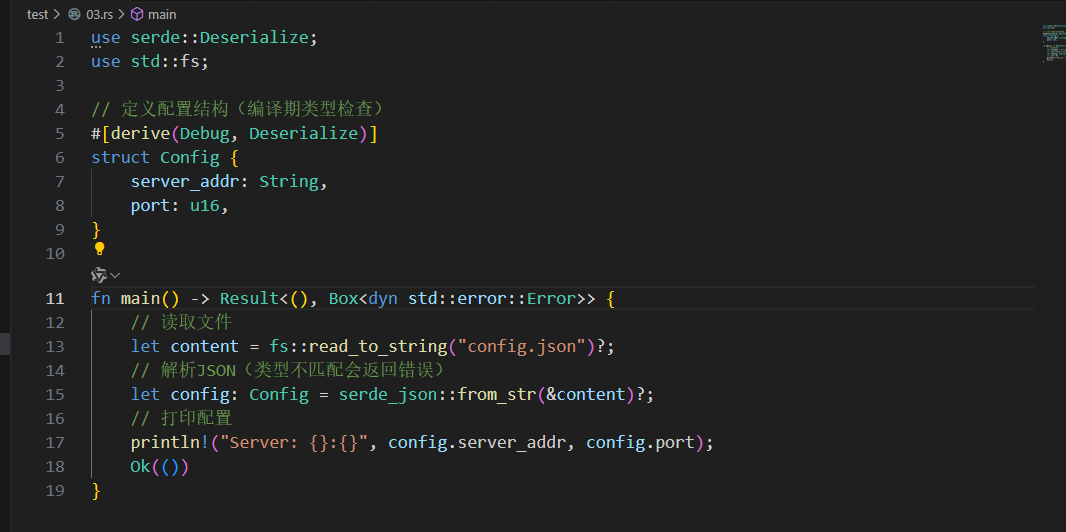
Rust实现
use serde::Deserialize;
use std::fs;// 定义配置结构(编译期类型检查)
#[derive(Debug, Deserialize)]
struct Config {server_addr: String,port: u16,
}fn main() -> Result<(), Box<dyn std::error::Error>> {// 读取文件let content = fs::read_to_string("config.json")?;// 解析JSON(类型不匹配会返回错误)let config: Config = serde_json::from_str(&content)?;// 打印配置println!("Server: {}:{}", config.server_addr, config.port);Ok(())
}
特点:
- 得显式定义Config结构体(编译期就做类型检查,避免运行时出错);
- 错误处理靠?运算符统一处理(编译期强制检查错误,不能忽略);
- 依赖serde/serde_json库(生态里标准的JSON处理方案)。
C实现
#include <stdio.h>
#include <stdlib.h>
#include <cjson/cJSON.h> // 第三方JSON库int main() {// 读取文件FILE* f = fopen("config.json", "r");fseek(f, 0, SEEK_END);long len = ftell(f);rewind(f);char* content = (char*)malloc(len + 1);fread(content, 1, len, f);content[len] = '\0';fclose(f);// 解析JSONcJSON* root = cJSON_Parse(content);cJSON* addr = cJSON_GetObjectItem(root, "server_addr");cJSON* port = cJSON_GetObjectItem(root, "port");// 手动检查字段是否存在if (addr && port && cJSON_IsString(addr) && cJSON_IsNumber(port)) {printf("Server: %s:%d\n", addr->valuestring, port->valueint);} else {printf("Invalid config\n");}// 手动释放内存cJSON_Delete(root);free(content);return 0;
}
特点:
- 得手动管文件读写、内存分配和释放(步骤麻烦,但完全可控);
- 依赖第三方库cJSON(标准库不支持);
- 得手动检查字段类型和是否存在(容易因为漏查导致崩溃)。
C++实现
#include <iostream>
#include <fstream>
#include <nlohmann/json.hpp> // 第三方JSON库using json = nlohmann::json;int main() {// 读取文件std::ifstream f("config.json");json j;f >> j; // 解析JSON(输入简化了)// 访问字段(自动类型转换,失败会抛异常)try {std::string addr = j["server_addr"];int port = j["port"];std::cout << "Server: " << addr << ":" << port << std::endl;} catch (const std::exception& e) {std::cerr << "Invalid config: " << e.what() << std::endl;}return 0;
}
特点:
- 用std::ifstream简化了文件操作(RAII自动释放资源);
- 依赖nlohmann/json库(语法接近Python,好用);
- 支持异常处理(比C的手动检查简洁),但还是得显式捕获。
Java实现
import com.fasterxml.jackson.databind.ObjectMapper; // 主流JSON库// 定义配置类
class Config {private String serverAddr; // 字段名自动映射(得符合命名规范)private int port;// 必须有getter/setter(或者用Lombok简化)public String getServerAddr() { return serverAddr; }public void setServerAddr(String addr) { this.serverAddr = addr; }public int getPort() { return port; }public void setPort(int p) { this.port = p; }
}public class Main {public static void main(String[] args) throws Exception {// 解析JSON(Jackson库自动映射)ObjectMapper mapper = new ObjectMapper();Config config = mapper.readValue(new File("config.json"), Config.class);System.out.printf("Server: %s:%d%n", config.getServerAddr(), config.getPort());}
}
特点:
- 得定义JavaBean(Config类)还得提供getter/setter(规范严,有点麻烦);
- 依赖Jackson库(企业级应用里用得多,稳定可靠);
- 异常处理靠throws声明(能简化代码,但得上层处理)。
Python实现
import json# 读取并解析JSON(一行搞定)
with open("config.json") as f:config = json.load(f)# 直接访问字段(动态类型,不用定义类)
print(f"Server: {config['server_addr']}:{config['port']}")
特点:
- 标准库自带json模块(不用第三方依赖);
- 不用定义配置类(动态类型,直接访问字典);
- 代码特别简单(开发效率高),但字段错误(比如拼错了)得运行时才能发现。
案例总结:
- Rust/C++:得显式定义类型,编译期就检查错误,适合对健壮性要求高的场景;
- C:步骤麻烦但完全可控,适合资源受限或者需要底层优化的场景;
- Java:规范严,依赖成熟的库,适合企业级团队协作;
- Python:开发效率特别高,适合快速写脚本或者对类型安全要求不高的场景。
四、适用场景总结:没有“最好”,只有“最适合”
- Rust:适合做系统工具(比如ripgrep)、嵌入式开发(内存受限还得安全)、高性能服务(比如数据库中间件)、WebAssembly(前端对性能敏感的场景)。不适合快速原型开发(开发效率不如Python)、企业级CRUD应用(生态不如Java)。
- C:适合做操作系统内核(Linux/Windows)、嵌入式驱动(芯片级编程)、对资源要极致控制的工具(比如编译器)。不适合复杂业务逻辑开发(缺乏抽象,代码长)、团队协作项目(维护成本高)。
- C++:适合做游戏引擎(Unreal)、图形学应用(要和GPU交互)、高性能服务器(兼顾抽象和性能)。不适合轻量工具开发(编译慢,配置复杂)、初学者入门项目(学起来费劲)。
- Java:适合做企业级后端服务(Spring生态)、Android应用(官方支持)、大数据处理(Hadoop/Spark)。不适合内存受限的嵌入式设备(JVM占资源多)、对性能敏感的实时系统(GC有延迟)。
- Python:适合做数据分析(Pandas)、AI模型训练(PyTorch)、自动化脚本(测试/部署)、快速原型验证。不适合高性能计算(解释执行慢)、资源受限的嵌入式设备(内存占用高)。