逻辑回归在个性化推荐中的原理与应用
我们用一个“智能媒人”的故事来理解逻辑回归在个性化推荐中的原理和使用。
第一部分:原理篇 —— “智能媒人”是如何工作的?
想象一下,你有一个非常聪明的“智能媒人”,她的任务就是预测:“你会不会喜欢电影A?” 她的回答不是“喜欢”就是“不喜欢”,这是一个二分类问题。
逻辑回归就是这个“智能媒人”的大脑算法。她的工作分为三步:
第1步:收集信息(特征工程)
媒人不能凭空猜测,她需要了解你和电影A的各方面信息。这些信息在模型里叫做 “特征”。
- 你的特征: 年龄、性别、历史观影记录(比如看过10部科幻片)、最近的搜索关键词(比如“漫威”)。
- 电影A的特征: 类型(科幻/爱情)、导演、主演、上映年份、评分。
- 你和电影A的交互特征: 电影标题里是否包含你搜索过的关键词?主演是不是你常看的演员?
媒人会把这些所有信息(比如20个)都量化成数字,组成一个关于电影A的“信息档案”。
第2步:综合打分(线性计算)
媒人拿到这个“信息档案”后,开始给这个组合打分。但她不是拍脑袋决定,而是有一个科学的打分公式:
综合分数 Z = w1 * 年龄 + w2 * 性别 + w3 * 科幻片权重 + w4 * 漫威关键词 + ... + b
- w1, w2, w3… (权重): 这是媒人通过大量学习(训练)得到的“经验值”。它代表了每个特征的重要性。
- 比如,
w3(科幻片权重)可能是一个很大的正数,因为你爱看科幻片。 - 比如,
w_爱情可能是一个负数,因为你不爱看爱情片。 b (偏置项): 可以理解为一个基础分,比如这个媒人天生就比较乐观,倾向于认为大家都爱看电影。
- 比如,
- 结果: 这个
Z分数可以是从负无穷到正无穷的任何一个数。分数越高,说明你喜欢的可能性越大。
第3步:做出预测(逻辑函数转换)
现在有个问题:媒人最终需要给出一个明确的 “概率”,比如“你喜欢电影A的可能性是85%”。但上一步的分数Z的范围太广了,无法直接变成概率。
这时,逻辑回归的核心武器—— “Sigmoid函数” 就出场了!你可以把它想象成一个 “概率压缩器”。
这个函数的神奇之处在于:
- 它能把任何分数
Z(从负无穷到正无穷)都压缩到 0 到 1 之间。 - 当
Z非常大(正数)时,输出概率接近 1(100%喜欢)。 - 当
Z非常小(负数)时,输出概率接近 0(0%喜欢)。 - 当
Z=0时,输出概率是 0.5(一半一半)。
所以,最终输出是:
P(你喜欢电影A) = Sigmoid(综合分数 Z)
媒人设定一个阈值,比如0.5。如果算出来概率 P > 0.5,她就推荐给你;如果 P < 0.5,她就不推荐。
小结一下原理:
逻辑回归通过 “赋予权重进行打分 -> 用Sigmoid函数将分数转化为概率” 的方式,来预测一个二分类事件(点击/不点击,喜欢/不喜欢)发生的可能性。
第二部分:使用案例篇 —— 电商平台的“猜你喜欢”
现在,我们看一个真实的场景:电商平台的商品点击率预测。
目标: 预测某个用户在看到某个商品时,点击 这个商品的概率有多大。
流程如下:
-
准备训练数据:
- 平台收集海量的历史数据,每条数据包括:
- 特征: 用户ID、商品ID、用户历史行为(点击、购买、浏览)、商品类别、价格、当时的时间段等。
- 标签: 用户当时是否点击了(是=1, 否=0)。这是模型学习的目标。
- 平台收集海量的历史数据,每条数据包括:
-
特征工程(精细化):
- 用户特征: 用户年龄、性别、消费等级、常驻城市。
- 商品特征: 商品品类、品牌、价格、历史销量、好评率。
- 上下文特征: 当前是周末还是工作日?用户是用手机APP还是电脑网页?
- 交叉特征(非常关键!): 比如“用户过去30天对该品类商品的点击次数”、“用户所在城市是否是该品牌的热门销售区”。这些特征结合了用户和商品的信息,威力巨大。
-
模型训练:
- 将准备好的大量“特征-标签”数据喂给逻辑回归模型。
- 模型通过算法(如梯度下降)不断地自我调整,找到那一组最合适的 权重(w1, w2, w3…) 和 偏置项(b)。调整的目标是:让模型对历史数据的预测结果与实际发生的情况(点击or未点击)尽可能一致。
-
线上预测(推荐):
- 当你登录APP时,系统会为你和首页的1000个待选商品分别生成“特征档案”。
- 训练好的逻辑回归模型会快速地为每一个“你-商品”组合计算一个点击概率。
- 排序与展示: 系统按照点击概率从高到低对这1000个商品进行排序,将概率最高的前几十个商品展示在你的首页“猜你喜欢”区域。
-
代码演示
电商"猜你喜欢"推荐系统简单案例。
import numpy as np
import pandas as pd
from sklearn.linear_model import LogisticRegression
from sklearn.model_selection import train_test_split
from sklearn.metrics import accuracy_score, classification_report
import matplotlib.pyplot as plt
import seaborn as sns# 设置随机种子以确保结果可重现
np.random.seed(42)print("=== 电商平台'猜你喜欢'推荐系统演示 ===\n")# 1. 生成模拟的训练数据
print("1. 生成模拟训练数据...")# 假设我们有1000个历史用户-商品交互记录
n_samples = 1000# 创建模拟特征(这些就是我们前面提到的各种特征)
data = {# 用户特征'user_age': np.random.normal(35, 10, n_samples), # 用户年龄,均值35,标准差10'user_gender': np.random.randint(0, 2, n_samples), # 用户性别(0:女, 1:男)'user_historical_ctr': np.random.uniform(0, 0.3, n_samples), # 用户历史点击率# 商品特征 'item_price': np.random.uniform(10, 500, n_samples), # 商品价格'item_rating': np.random.uniform(3, 5, n_samples), # 商品评分'item_category_electronics': np.random.randint(0, 2, n_samples), # 是否是电子产品# 上下文特征'weekend': np.random.randint(0, 2, n_samples), # 是否是周末'mobile_app': np.random.randint(0, 2, n_samples), # 是否移动端访问# 交叉特征(用户-商品交互)'user_item_category_match': np.random.uniform(0, 1, n_samples), # 用户偏好与商品类别匹配度
}# 创建DataFrame
df = pd.DataFrame(data)# 2. 生成模拟的点击标签(基于一些规则 + 随机噪声)
print("2. 生成点击标签...")# 定义一些规则来模拟真实的点击行为
def generate_click_label(row):# 基础点击概率base_prob = 0.1# 基于特征的调整(模拟真实用户行为)if row['user_age'] < 25 and row['item_category_electronics'] == 1:base_prob += 0.3 # 年轻人更喜欢电子产品if row['user_historical_ctr'] > 0.2:base_prob += 0.2 # 高活跃用户更可能点击if row['item_rating'] > 4.5:base_prob += 0.15 # 高评分商品更可能被点击if row['weekend'] == 1 and row['mobile_app'] == 1:base_prob += 0.1 # 周末移动端使用更多if row['user_item_category_match'] > 0.7:base_prob += 0.25 # 匹配度高显著增加点击概率# 添加随机噪声base_prob += np.random.normal(0, 0.1)# 确保概率在0-1之间base_prob = max(0, min(1, base_prob))# 根据概率生成点击标签return 1 if np.random.random() < base_prob else 0# 应用函数生成标签
df['clicked'] = df.apply(generate_click_label, axis=1)print("3. 数据预览:")
print(f"数据形状: {df.shape}")
print(f"点击率: {df['clicked'].mean():.2%}")
print("\n前5行数据:")
print(df.head())print("\n特征描述:")
print(df.describe())# 3. 准备特征和标签
print("\n4. 准备特征和标签...")
X = df.drop('clicked', axis=1) # 特征:所有列除了clicked
y = df['clicked'] # 标签:是否点击print(f"特征数量: {X.shape[1]}")
print(f"特征名称: {list(X.columns)}")# 4. 划分训练集和测试集
print("\n5. 划分训练集和测试集...")
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2, random_state=42, stratify=y
)print(f"训练集大小: {X_train.shape[0]}")
print(f"测试集大小: {X_test.shape[0]}")
print(f"训练集点击率: {y_train.mean():.2%}")
print(f"测试集点击率: {y_test.mean():.2%}")# 5. 训练逻辑回归模型
print("\n6. 训练逻辑回归模型...")
model = LogisticRegression(random_state=42, max_iter=1000)
model.fit(X_train, y_train)print("模型训练完成!")# 6. 模型评估
print("\n7. 模型评估...")
y_pred = model.predict(X_test)
y_pred_proba = model.predict_proba(X_test)[:, 1] # 点击概率accuracy = accuracy_score(y_test, y_pred)
print(f"准确率: {accuracy:.4f}")
print(f"测试集点击率: {y_test.mean():.2%}")
print(f"模型预测点击率: {(y_pred == 1).mean():.2%}")print("\n分类报告:")
print(classification_report(y_test, y_pred))# 7. 查看模型学到的特征权重
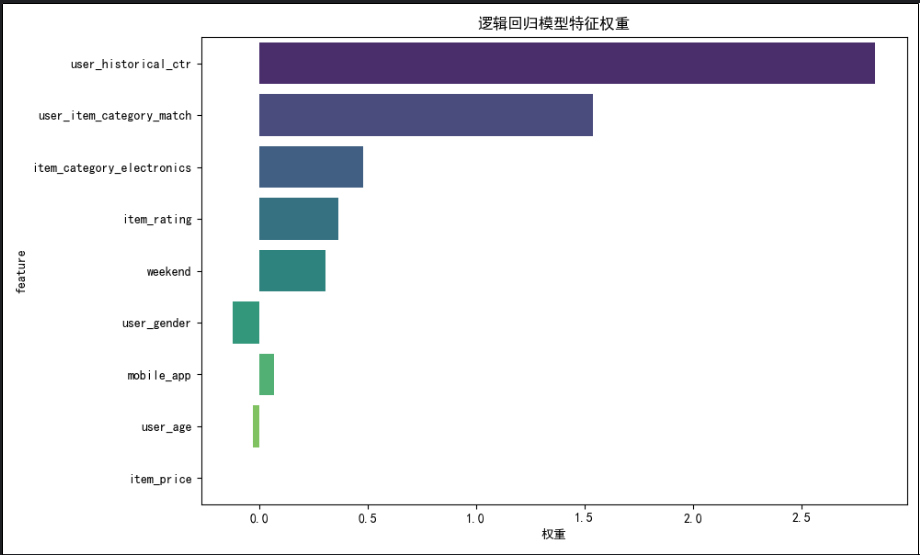
print("\n8. 模型特征权重分析:")
feature_importance = pd.DataFrame({'feature': X.columns,'weight': model.coef_[0],'abs_weight': np.abs(model.coef_[0])
}).sort_values('abs_weight', ascending=False)print("特征权重排序:")
for _, row in feature_importance.iterrows():effect = "正向" if row['weight'] > 0 else "负向"print(f" {row['feature']:25} | 权重: {row['weight']:7.3f} | {effect}影响")# 8. 模拟推荐预测
print("\n9. 模拟推荐预测演示...")# 创建几个测试用户-商品组合
test_cases = [# [user_age, user_gender, user_historical_ctr, item_price, item_rating, item_category_electronics, weekend, mobile_app, user_item_category_match][28, 1, 0.25, 299, 4.8, 1, 1, 1, 0.9], # 年轻男性,高活跃,电子产品,周末移动端,高匹配度[45, 0, 0.05, 150, 3.2, 0, 0, 0, 0.3], # 中年女性,低活跃,非电子产品,工作日网页端,低匹配度[22, 1, 0.15, 899, 4.5, 1, 1, 1, 0.6], # 年轻男性,中等活跃,高价电子产品
]case_descriptions = ["理想用户-商品组合","不太可能点击的组合", "中等概率组合"
]print("预测结果:")
for i, (case, desc) in enumerate(zip(test_cases, case_descriptions)):probability = model.predict_proba([case])[0, 1]prediction = model.predict([case])[0]action = "推荐" if prediction == 1 else "不推荐"print(f"\n案例 {i+1} ({desc}):")print(f" 点击概率: {probability:.1%}")print(f" 预测结果: {prediction} ({action})")# 9. 可视化特征重要性
print("\n10. 生成特征重要性图表...")
plt.figure(figsize=(10, 6))
sns.barplot(data=feature_importance, x='weight', y='feature', palette='viridis')
plt.title('逻辑回归模型特征权重')
plt.xlabel('权重')
plt.tight_layout()
plt.show()print("\n=== 演示完成 ===")
print("总结:")
print("- 逻辑回归通过学习每个特征的权重来预测点击概率")
print("- 权重为正表示特征增加点击可能性,为负表示减少点击可能性")
print("- 模型输出0-1的概率值,可用于排序推荐")
print("- 在实际系统中,会对数百万用户-商品组合计算点击概率并排序")
运行这个代码,你会看到以下输出效果:
-
数据格式说明:训练数据包含:
- 用户特征:年龄、性别、历史点击率
- 商品特征:价格、评分、类别
- 上下文特征:是否周末、是否移动端
- 交叉特征:用户-商品匹配度
- 标签:是否点击(0/1)
-
运行结果包括:
- 数据统计信息
- 模型准确率评估
- 特征权重分析(可解释性!)
- 实际预测案例演示
- 特征重要性可视化
-
关键洞察:
- 可以看到哪些特征对点击率影响最大
- 模型如何为不同用户-商品组合计算点击概率
- 如何基于概率进行推荐决策
-
运行结果如下
这个案例完整展示了从数据准备到模型训练、评估和预测的整个流程,特别突出了逻辑回归在推荐系统中的实际应用方式和优势。
逻辑回归的优缺点(为什么它如此流行?)
-
优点:
- 简单高效: 计算速度快,适合处理海量数据的在线推荐场景。
- 可解释性强: 我们可以查看每个特征的权重。比如发现“科幻片”特征的权重很高,我们就知道模型认为“喜欢科幻片”是推荐的一个强信号。这对于业务分析非常重要。
- 输出概率: 输出的直接是概率值,非常便于排序。
- 工程成熟: 业界有非常成熟的优化和线上部署方案。
-
缺点:
- 无法自动捕捉特征组合: 它无法像深度学习模型那样自动学习特征之间的复杂交互关系(比如“周末”且“使用手机”且“价格在100-200元”这个复杂组合),需要人工进行特征交叉才能弥补,非常依赖数据工程师的经验。
总结
你可以把逻辑回归想象成推荐系统的 “基石”或“老黄牛”。
它可能不像一些最新、最酷的AI模型那么“智能”,但它因其稳定、高效、可解释的特点,在工业界(尤其是超大规模推荐场景,如抖音、淘宝、亚马逊)中占据了不可动摇的地位。很多复杂的推荐系统,最初都是从逻辑回归起步,或者至今仍将其作为核心组件之一。