dify零基础入门示例
一、如何本地部署Dify
对于个人学习和体验,使用 Docker 在本地部署是官方推荐也是最简单的方式。
1.1 为什么Docker是比较推荐的方式?
1. 环境一致性
-
问题:Dify依赖多个组件(后端API、前端界面、数据库Redis、向量数据库等)
-
Docker方案:所有组件都打包在容器中,版本完全匹配
-
传统方式:手动安装时可能出现Python版本冲突、依赖包不兼容等问题
2. 隔离性
-
Dify的所有服务在容器内运行,不污染主机环境
-
卸载时只需
docker-compose down,系统完全干净
3. 官方优化
-
Docker镜像由官方预构建和测试,确保最佳配置
-
包含了所有必要的中间件和优化设置
1.2 其他部署方式对比
方式一:云服务一键部署
| 平台 | 优点 | 缺点 |
|---|---|---|
| Dify Cloud | 完全免运维,开箱即用 | 付费服务,数据在第三方 |
| Vercel/Railway | 简单的云部署 | 配置复杂,可能产生费用 |
方式二:传统服务器部署
git clone https://github.com/langgenius/dify.git
cd dify/api
python -m venv venv
source venv/bin/activate
pip install -r requirements.txtcd ../web
npm install
npm run build# 还需要安装配置PostgreSQL、Redis等...缺点:
-
依赖操作系统(Ubuntu/CentOS差异)
-
需要处理Python环境、Node.js环境
-
手动配置数据库和缓存
-
容易遇到版本冲突
方式三:Kubernetes部署
适合已有K8s集群的企业用户,对初学者过于复杂。
1.3 Docker部署Dify步骤(MACOS系统为例)
安装Docker
-
访问 Docker Desktop for Mac
-
下载并安装
.dmg文件 -
启动 Docker Desktop 应用
部署命令
# 与Linux完全一致
# 步骤1:下载代码
git clone https://github.com/langgenius/dify.git# 步骤2:进入部署目录
cd dify/docker# 步骤3:启动所有服务
docker-compose up -d
# 读取配置文件 → 下载镜像 → 启动容器 → 后台运行
up 参数:启动并运行所有在 docker-compose.yml 中定义的服务。
-d 参数:-d 代表 --detach,意思是"在后台运行"。cd docker后查看有哪些文件,运行ls得到如下结果:
README.md docker-compose.yaml ssrf_proxy
certbot elasticsearch startupscripts
couchbase-server generate_docker_compose tidb
docker-compose-template.yaml middleware.env.example volumes
docker-compose.middleware.yaml nginx
docker-compose.png pgvector重点文件详细说明
1. docker-compose.yaml(最重要的文件)
# 这个文件定义了整个Dify平台的所有服务:
services:dify-api: # 后端API服务dify-web: # 前端界面postgres: # 主数据库redis: # 缓存和会话存储weaviate: # 向量数据库(用于知识库)nginx: # Web服务器# ... 其他服务2. .env.example(环境配置)
# 包含重要的配置项:
OPENAI_API_KEY=your_openai_api_key_here # OpenAI API密钥
DATABASE_URL=postgresql://postgres:dify@postgres:5432/dify # 数据库连接
# 各种功能开关和配置参数3. generate_docker_compose(配置生成器)
# 这个脚本的作用:
# 1. 读取模板文件
# 2. 根据用户选择生成最终的docker-compose.yaml
# 3. 确保配置的正确性和兼容性详细解释 docker-compose up -d 的过程
docker-compose up -d
# 实际执行流程:
# 1. 读取 docker-compose.yaml 文件
# 2. 检查镜像是否已下载
# 3. 如果镜像不存在,从Docker Hub下载
# 4. 根据镜像创建并启动容器
# 5. 在后台运行容器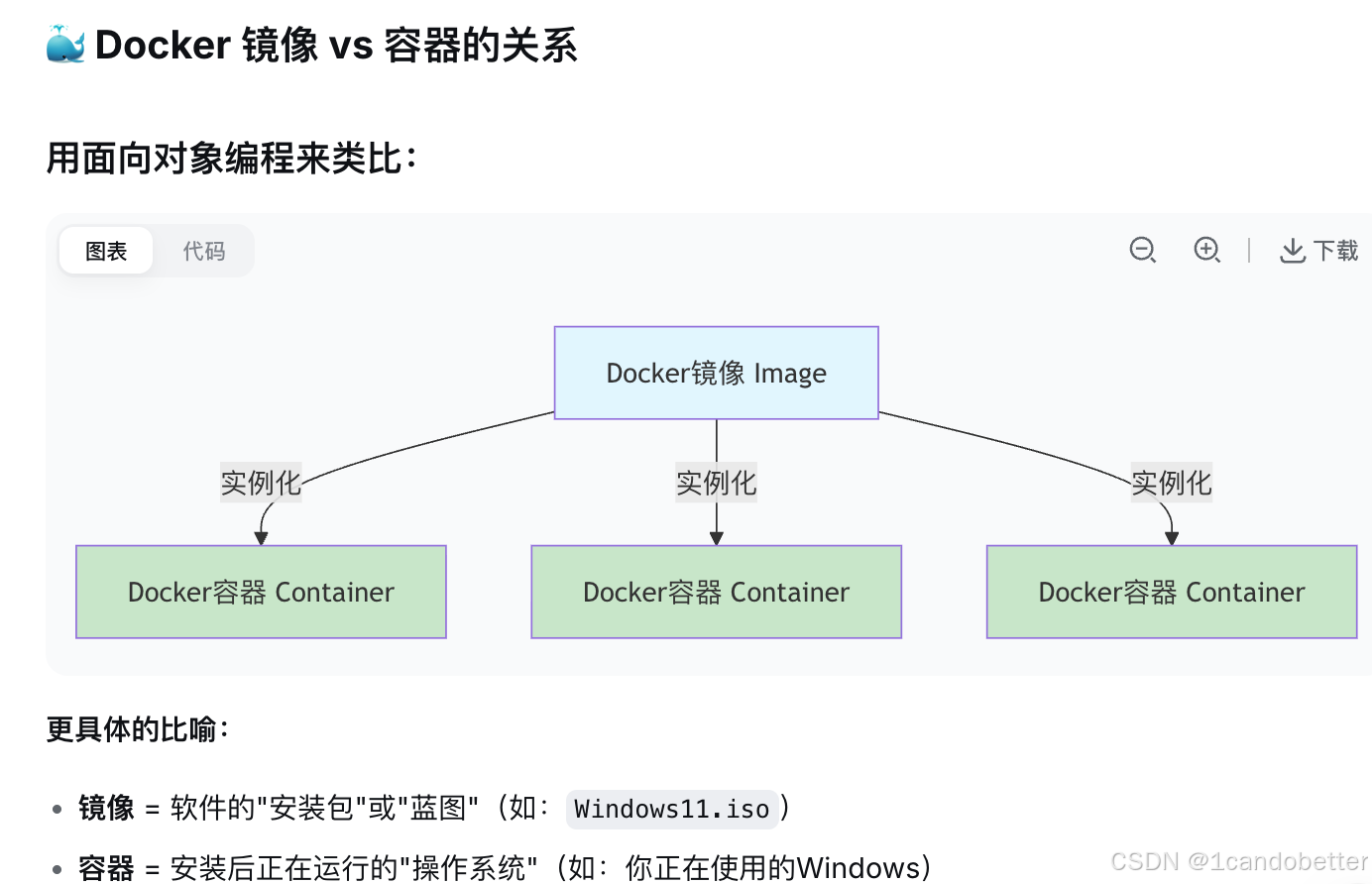
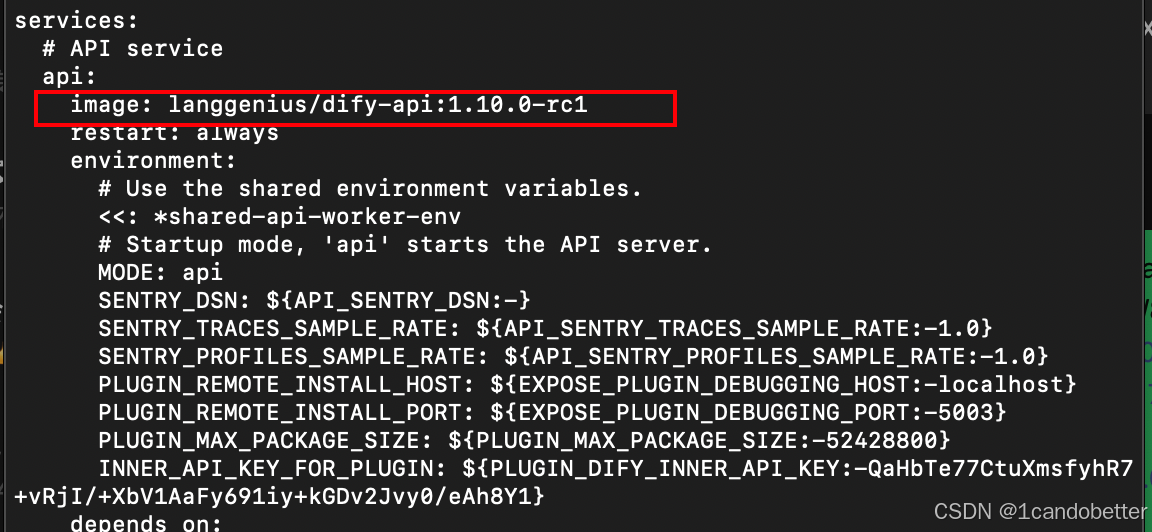
docker-compose.yaml 中的部分内容如下:
访问 Dify
打开浏览器访问http://localhost 或者 http://127.0.0.1
二、熟悉 Dify 核心概念
成功登录 Dify 后,花些时间了解以下几个核心概念,这对后续开发至关重要:
| 核心概念 | 是什么? | 有什么用? |
|---|---|---|
| 应用类型 | 创建应用时的不同选择,主要是聊天型和文本生成型等。 | 决定了AI与用户的交互方式,是实现功能的基础。 |
| 提示词 | 给AI模型的指令和上下文。 | 直接决定了AI回答的质量和准确性,是应用的"灵魂"。 |
| 工作流 | 通过拖拽节点的方式,将复杂的AI任务流程可视化地编排起来。 | 适合处理有固定步骤的任务,例如:信息提取->分析->生成报告。 |
| 智能体 | 具备自主规划和使用工具能力的AI应用。 | 可以完成更复杂的任务,比如主动调用搜索引擎查询信息。 |
| 知识库 | 你将文档(如PDF、Word)上传到Dify,它会将其处理成AI可以理解的形式。 | 让AI能够基于你提供的特定资料回答问题,实现检索增强生成。 |
三、创建第一个 AI 应用
3.1 理解模型供应商的核心概念
在开始创建我们的第一个AI应用之前,有一个关键概念必须理解:模型供应商。这是很多Dify初学者最容易困惑的地方。
1. 什么是模型供应商?
用一个简单的比喻来理解:
🛒 模型供应商 = 超市
🍎 具体模型 = 商品
🧠 你的应用 = 厨师
想象一下:
-
OpenAI、Azure、Anthropic 就像不同的超市
-
GPT-4、Claude-3、Llama-2 就像超市里卖的具体商品
-
邮件助手应用 就像一位厨师,需要从超市购买食材才能做饭
2. 为什么需要先配置模型供应商?
从软件架构的角度来看,Dify 采用了供应商抽象层的设计模式。核心设计思想如下:
-
应用逻辑与模型实现分离:AI应用不需要关心底层调用的是GPT-4、Claude还是Llama 2
-
统一的API接口:无论底层供应商如何变化,上层应用保持稳定
-
可插拔架构:新的模型供应商可以随时接入,不影响现有应用
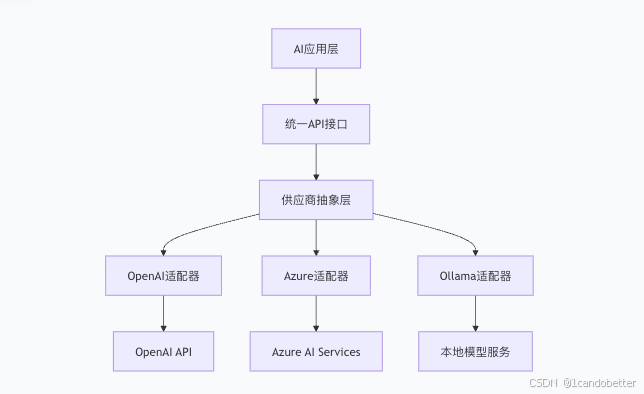
3. 两种主要的模型供应商方案
Dify 的模型插件,其核心作用是一个标准化的“连接器”或“协议适配器”。 以“Ollama”插件为例,它的功能是让 Dify 平台能够按照 Ollama 定义的 API 协议格式与之进行通信。关键在于,该插件本身并不包含、也不提供 Ollama 的运行环境或任何模型文件。
因此,当集成本地部署的模型时,必须遵循一个清晰的依赖链:
-
基础设施层:必须先在服务器或本地计算机上独立安装并运行 Ollama 服务。这确保了模型运行所需的环境和 API 端点(通常是
http://localhost:11434)是可用的。 -
模型层:在 Ollama 环境中,通过
ollama pull命令拉取所需的模型文件(如llama2:7b),使其可供 Ollama 服务调用。 -
应用层:在上述前提满足后,您才能在 Dify 中通过配置该插件,成功连接并调用已部署的本地模型。
反之,如果选择使用云服务模型(例如 OpenAI GPT 系列、Google Gemini 等),则无需关心底层基础设施。Dify 中相应的插件(如 OpenAI 插件)会直接通过互联网,使用提供的 API Key 去调用云服务商提供的、已就绪的模型接口。在这种情况下,模型的环境维护、服务部署和扩展性均由云服务商负责。
方案一:云端API服务(推荐有预算的用户)
代表厂商:
-
OpenAI - GPT系列模型
-
Anthropic - Claude系列模型
-
Azure AI - 企业级AI服务
配置方法:
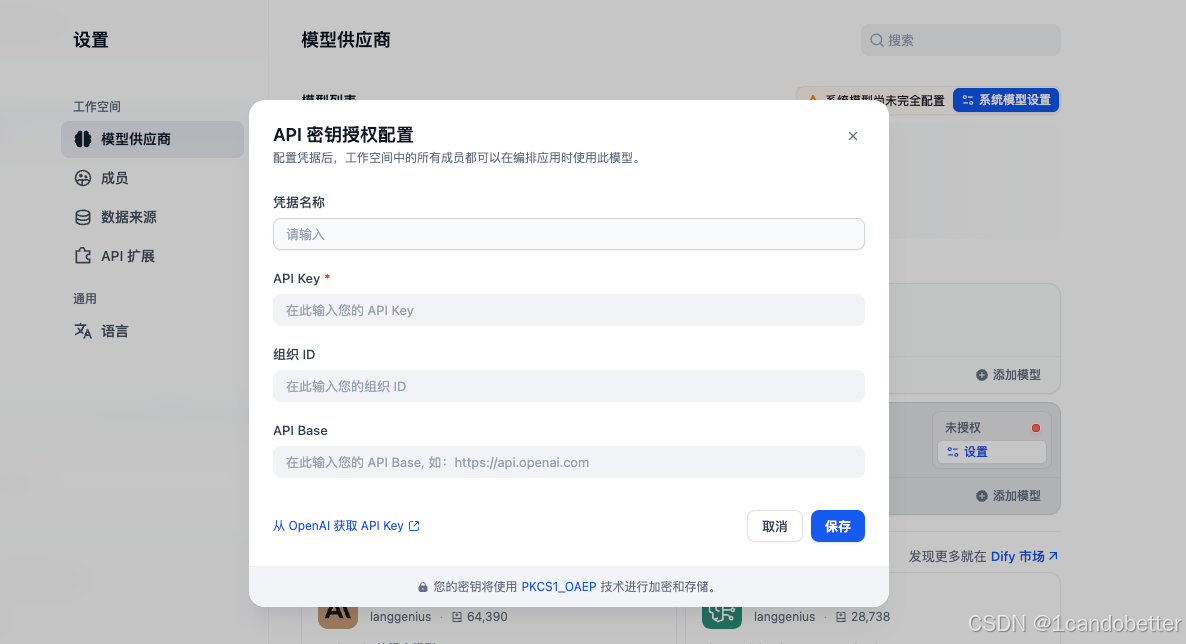
# 以OpenAI为例: 1. 进入Dify设置 → 模型供应商 2. 点击OpenAI卡片的“安装” 3. 输入API Key: sk-xxxxxxxxxxxxxxxx 4. 保存配置
优点:
-
模型能力强,响应速度快
-
无需担心本地硬件限制
-
始终使用最新模型版本
缺点:
-
需要付费(按使用量计费)
-
需要网络连接
-
数据经过第三方服务器
方案二:本地模型部署(推荐初学者/隐私要求高的用户)
例如使用 Ollama
# 1. 安装 Ollama
brew install ollama # macOS
# 或访问 https://ollama.ai# 2. 下载模型
ollama pull llama2# 3. 在Dify中配置本地模型端点其中下载模型有多种方式,具体如下:
方式1:通过Ollama官方界面
-
访问:https://ollama.com/search
-
搜索模型:如
llama2、mistral、gemma等 -
点击模型卡片,查看详情
-
复制安装命令,在终端执行
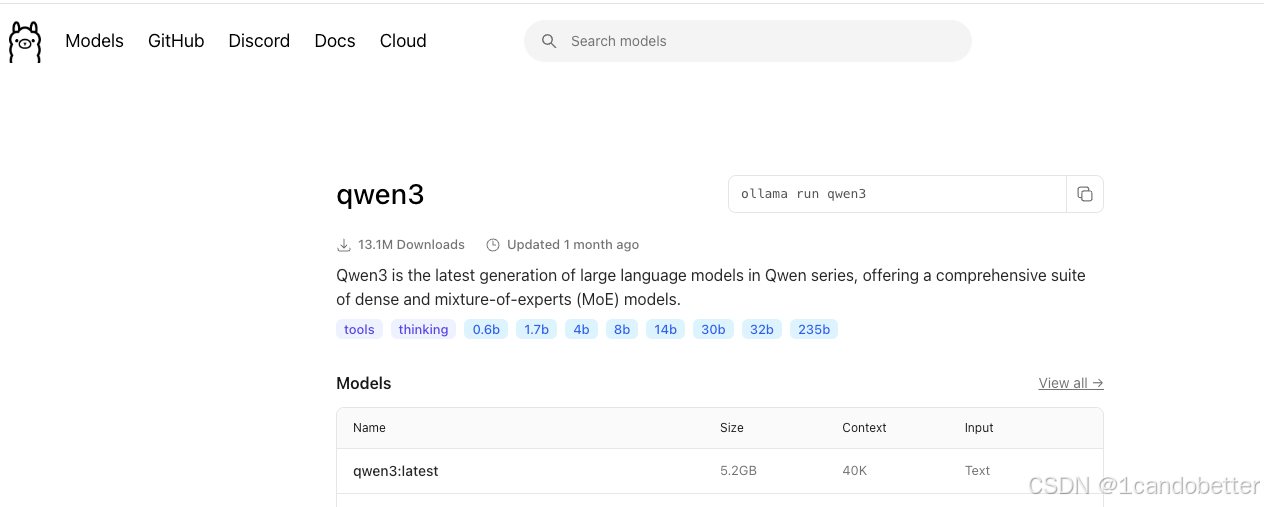
方式2:命令行直接安装
# 基础语法
ollama pull <模型名称># 实际例子
ollama pull llama2:7b
ollama pull mistral:7b
ollama pull gemma:7b# 测试模型
ollama run llama2:7b
# 然后输入:Hello, how are you?
# 应该能看到AI的回复方式3:使用Ollama App界面
3.2 Ollama和llama2模型区别
1. Ollama:管理和运行环境
Ollama 是一个 AI 平台,提供了一个环境,用于管理和运行不同的语言模型,包括 LLaMA 以及其他模型。它为开发者提供了一个方便的接口,通过简单的 API 或命令行指令,可以直接调用和使用模型,而不需要自己搭建复杂的基础设施或管理资源。
Ollama 作为平台,简化了在本地或云端部署、运行和管理 AI 模型的过程。它提供了一个易于使用的界面,并允许开发者在自己的机器上或者云端快速启动各种 AI 模型的实例。
-
Ollama 的功能:
-
管理多个 AI 模型(包括 LLaMA 2)。
-
提供简单的 API 接口,支持文本生成、对话生成等功能。
-
通过本地部署或云服务进行高效计算。
-
支持自定义和扩展,允许用户根据需求进行模型选择和调优。
-
2. LLaMA 2:具体的语言模型
LLaMA 2 是 Meta发布的系列大型语言模型,它是 LLaMA 模型的继任者,拥有更高的性能和更强的能力。LLaMA 2 模型是一个经过预训练的深度学习模型,专门用于自然语言处理任务,例如文本生成、对话系统、情感分析、机器翻译等。
LLaMA 2 是在 Ollama 环境中可以运行的一个具体模型。也就是说,Ollama 作为平台提供了运行 LLaMA 2 模型的环境,而 LLaMA 2 则是模型本身,执行实际的自然语言处理任务。
3. 总结关系
-
Ollama 提供了一个便捷的 AI 模型管理和运行环境,开发者可以在这个平台上快速部署和运行不同的模型。
-
LLaMA 2 是 Meta 发布的 大型语言模型,它可以在 Ollama 平台中运行。Ollama 为 LLaMA 2 提供了一个集成的、简化的使用界面,帮助开发者更轻松地调用该模型。
3.3 Ollama插件、Ollama和llama2模型
以工作流程说明来理解这三者的关系:
-
Dify 发起请求:用户在 Dify 中发送请求(例如“写一封邮件”)。这时,Dify 会通过 Ollama 插件将请求转发给 Ollama 服务,通常通过 HTTP 请求(例如发送到
localhost:11434)。 -
Ollama 调度请求:Ollama 作为一个调度器,接收到 Dify 发来的请求后,它并不直接处理请求的内容,而是负责将请求与合适的 LLaMA 模型进行匹配。例如,Dify 可能指定使用
llama3.2:1b版本的模型,Ollama 会根据这个信息来决定调用哪个模型。 -
Ollama 将请求传递给 LLaMA 模型:Ollama 将请求传递给内存中已经加载的 LLaMA 模型。此时,LLaMA 模型就像“大脑”一样,开始对请求进行计算和处理。
-
LLaMA 模型生成回应:LLaMA 模型接收到输入后,根据其训练得到的知识和能力进行推理,生成相应的答案或内容。在您的例子中,如果请求是“写一封邮件”,LLaMA 会根据输入的上下文和要求生成一封邮件。
-
Ollama 返回结果:一旦 LLaMA 模型完成计算并生成回答,结果将返回给 Ollama。Ollama 会将这个结果(例如邮件内容)包装成标准的 HTTP 响应格式,发送回给 Dify。
-
Dify 返回给用户:最后,Dify 接收到由 Ollama 返回的响应,并将最终结果展示给用户。
这种流程将不同的组件(Dify、Ollama 和 LLaMA 模型)很好地分工协作,确保每个环节都能高效地处理各自的任务。Dify 负责发起请求并展示结果,Ollama 负责调度和连接各个模型,而 LLaMA 模型则提供实际的计算和生成能力。
3.4 在dify中配置模型(以本地部署为例)
第一步:确保 Ollama 服务运行
# 在终端中启动 Ollama 服务
ollama serve# 保持这个终端窗口打开!
# 服务会一直运行在这个窗口中第二步:验证 Ollama API 可用
打开新的终端窗口,测试服务:
# 测试 Ollama API 是否正常工作
curl http://localhost:11434/api/tags# 应该返回类似:
# {"models":[{"name":"llama2:7b","modified_at":"2024-01-01T00:00:00Z"}]}第三步:在 Dify 中添加模型供应商
- 打开 Dify → 访问
http://localhost - 进入设置:
-
点击左下角 "设置"
-
选择 "模型供应商"
-
点击 "添加模型供应商"
-
选择供应商类型:
-
选择 "OpenAI"/"Ollama"等(因为 Ollama 兼容 OpenAI API)
-
-
第四步:配置 Ollama 供应商
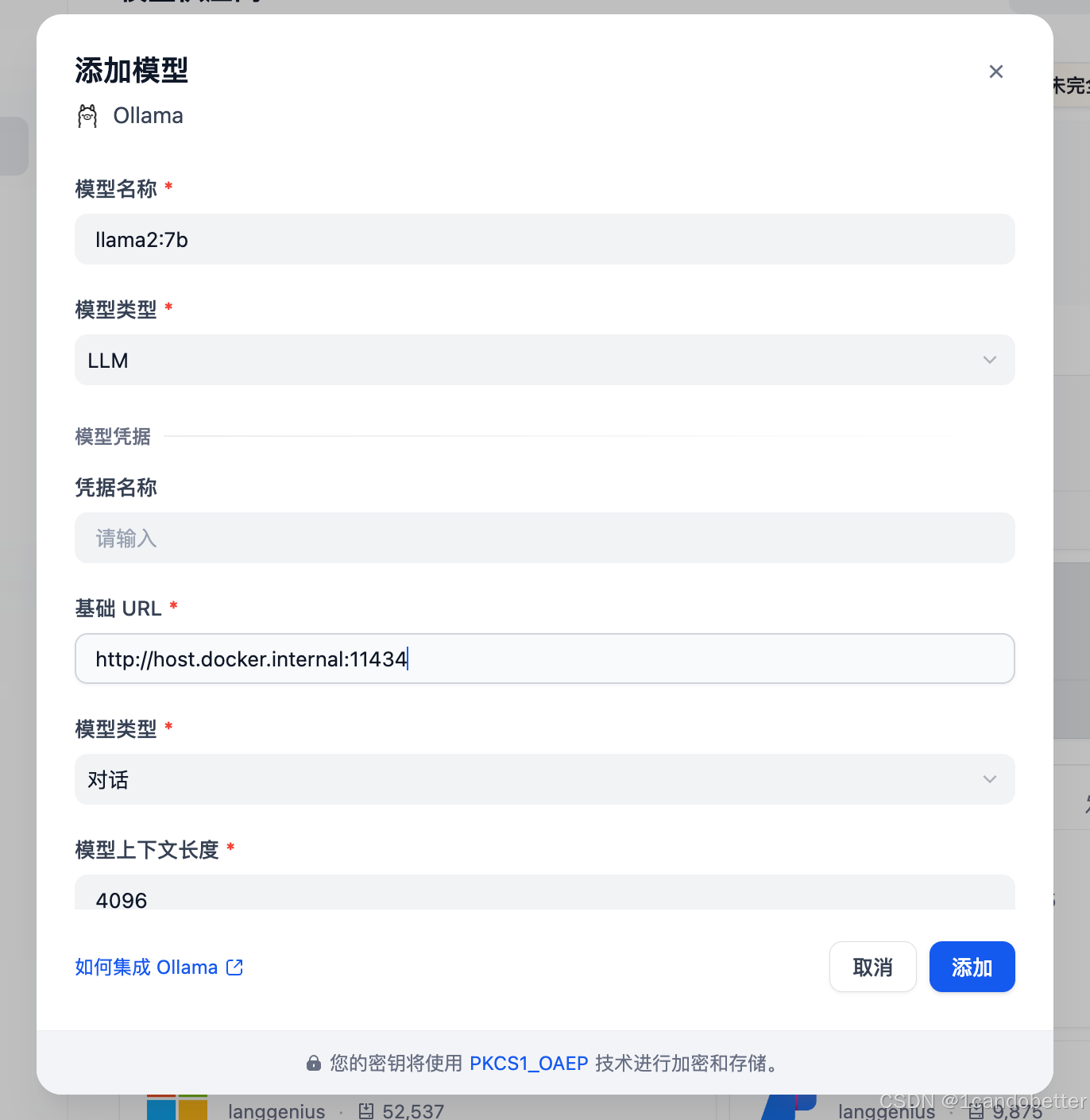
实用命令
#查看已安装的模型
ollama list#删除模型
ollama rm <模型名称>#查看模型信息
ollama show <模型名称>3.5 创建工作流
第一步:创建工作流应用
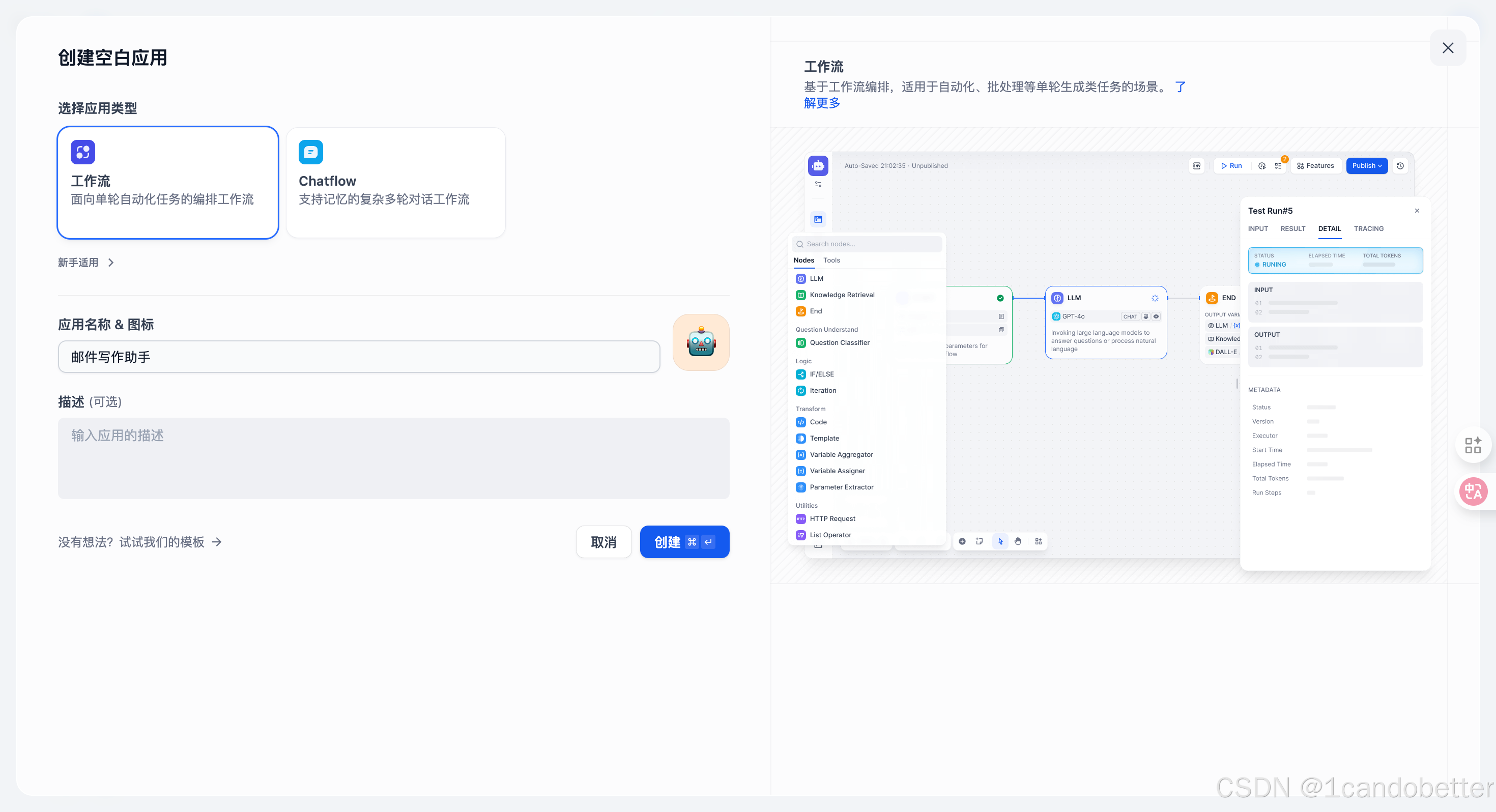
第二步:编排工作流节点
我们将构建一个包含以下节点的工作流,其结构清晰,能够逐步收集信息并生成邮件:

(1)开始节点 + 变量设置
-
目标:定义好工作流需要哪些信息。
-
操作:
-
点击画布上的 “开始” 节点。
-
在右侧的 “变量” 选项卡,点击 “添加变量”。
-
添加以下4个变量(这对应了上图中的四个提问):
-
recipient(收件人) -
purpose(邮件目的) -
key_points(核心内容和要点) -
tone(语气风格)
-
-
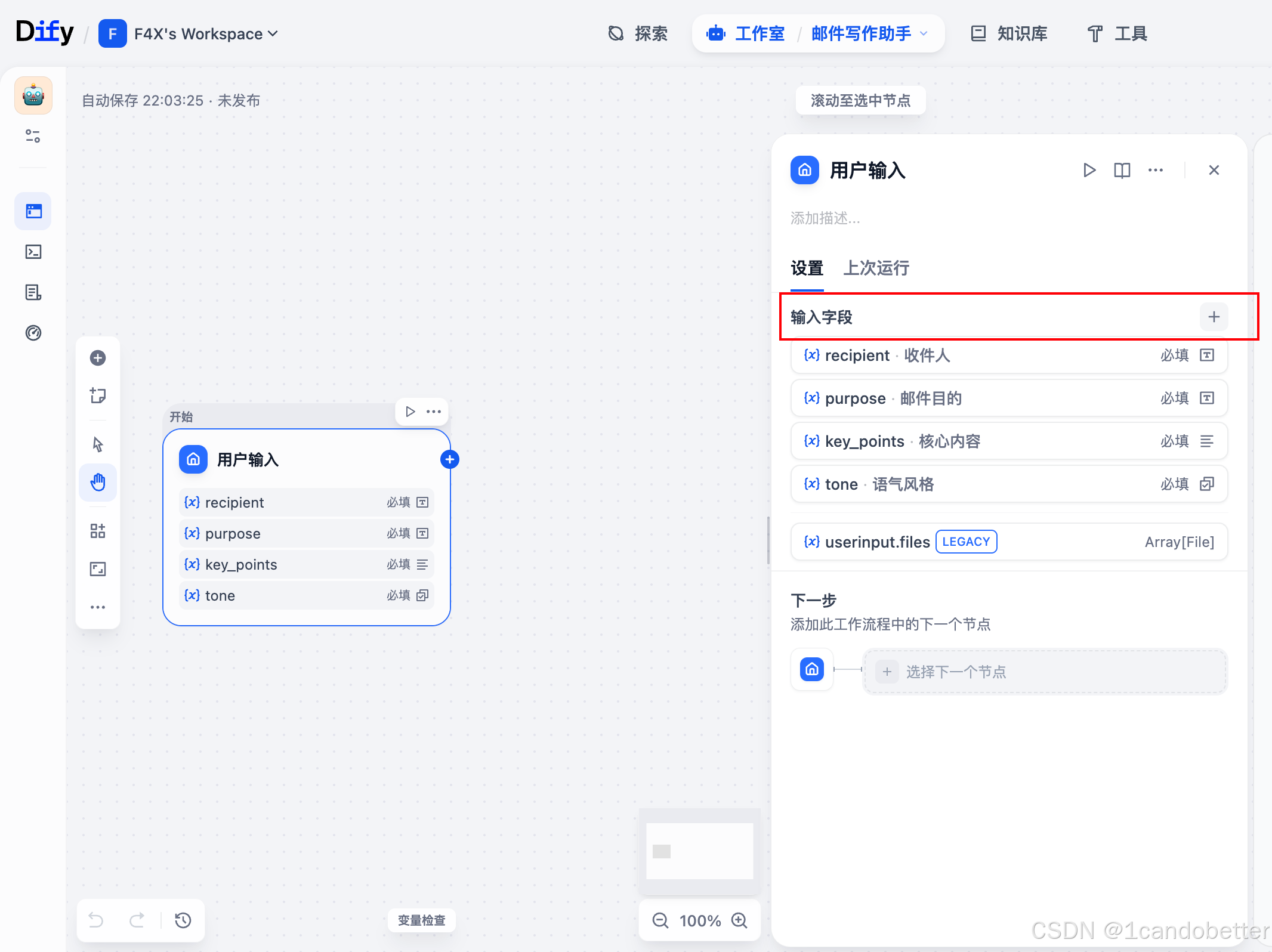
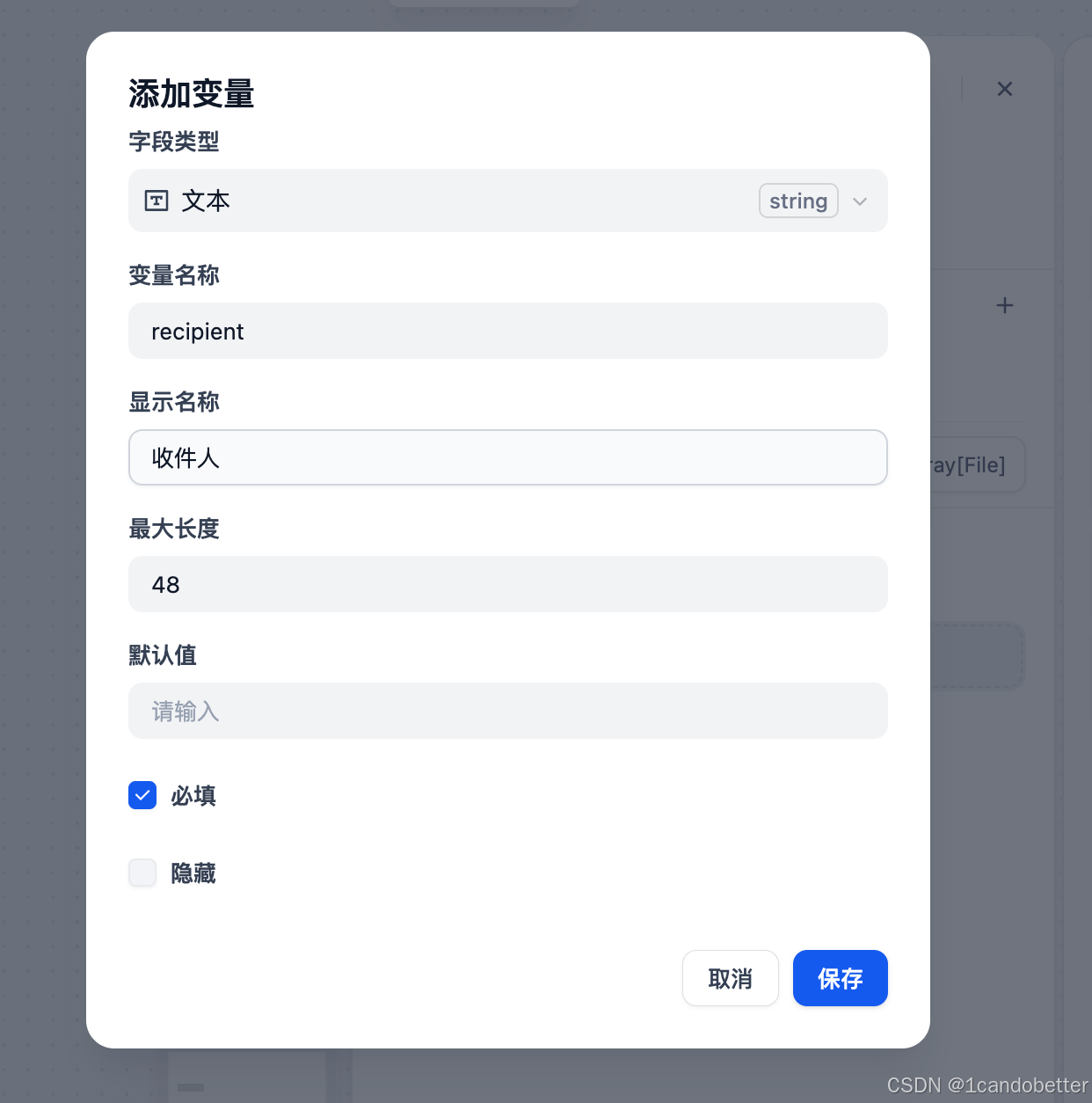
(2)添加LLM节点
-
从左侧节点栏拖拽“LLM”节点到画布
-
将开始节点连接到LLM节点
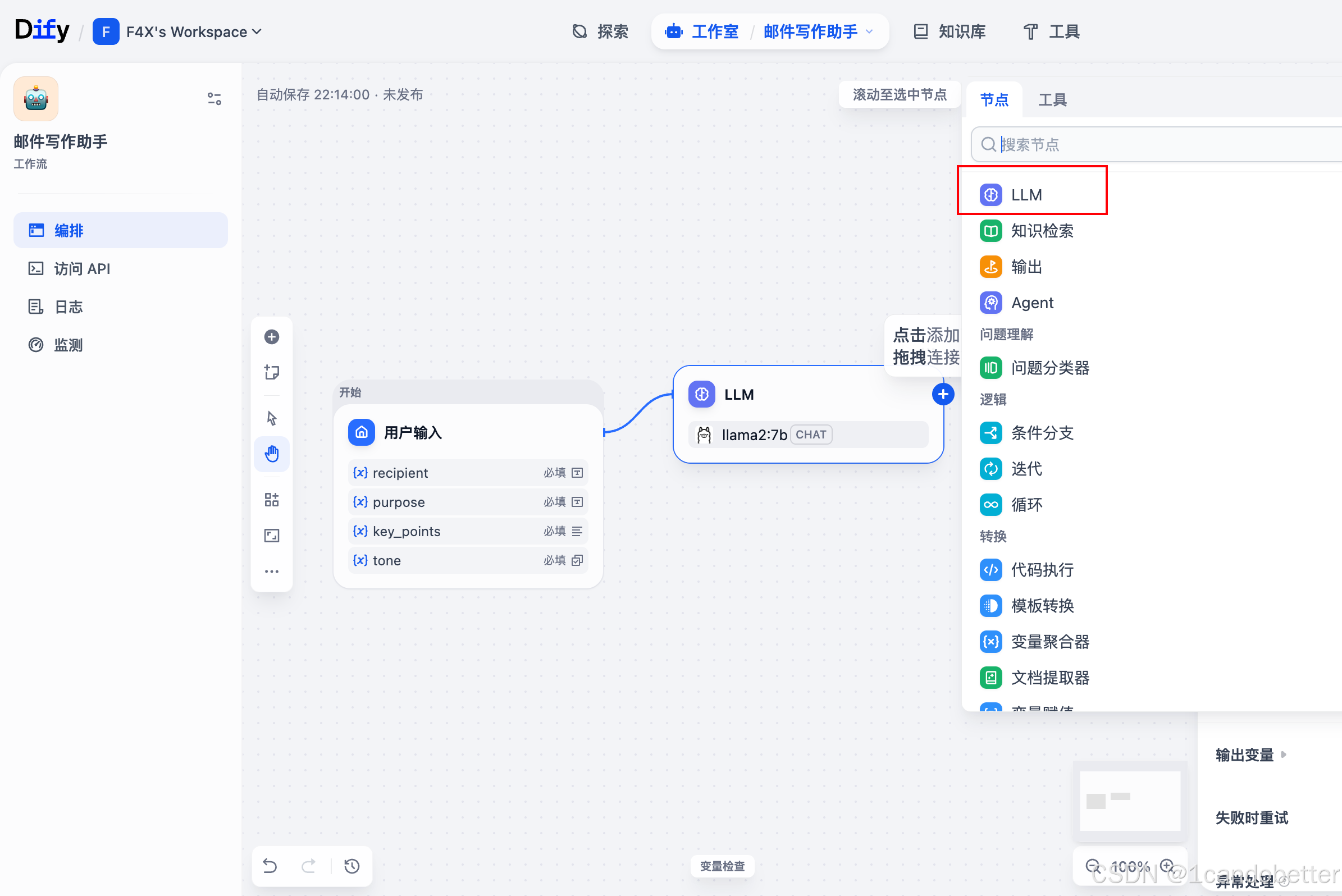
(3)配置LLM节点
-
选择模型:在右侧面板中选择配置好的Ollama模型
-
编写提示词:点击“编辑提示词”,填入以下内容:
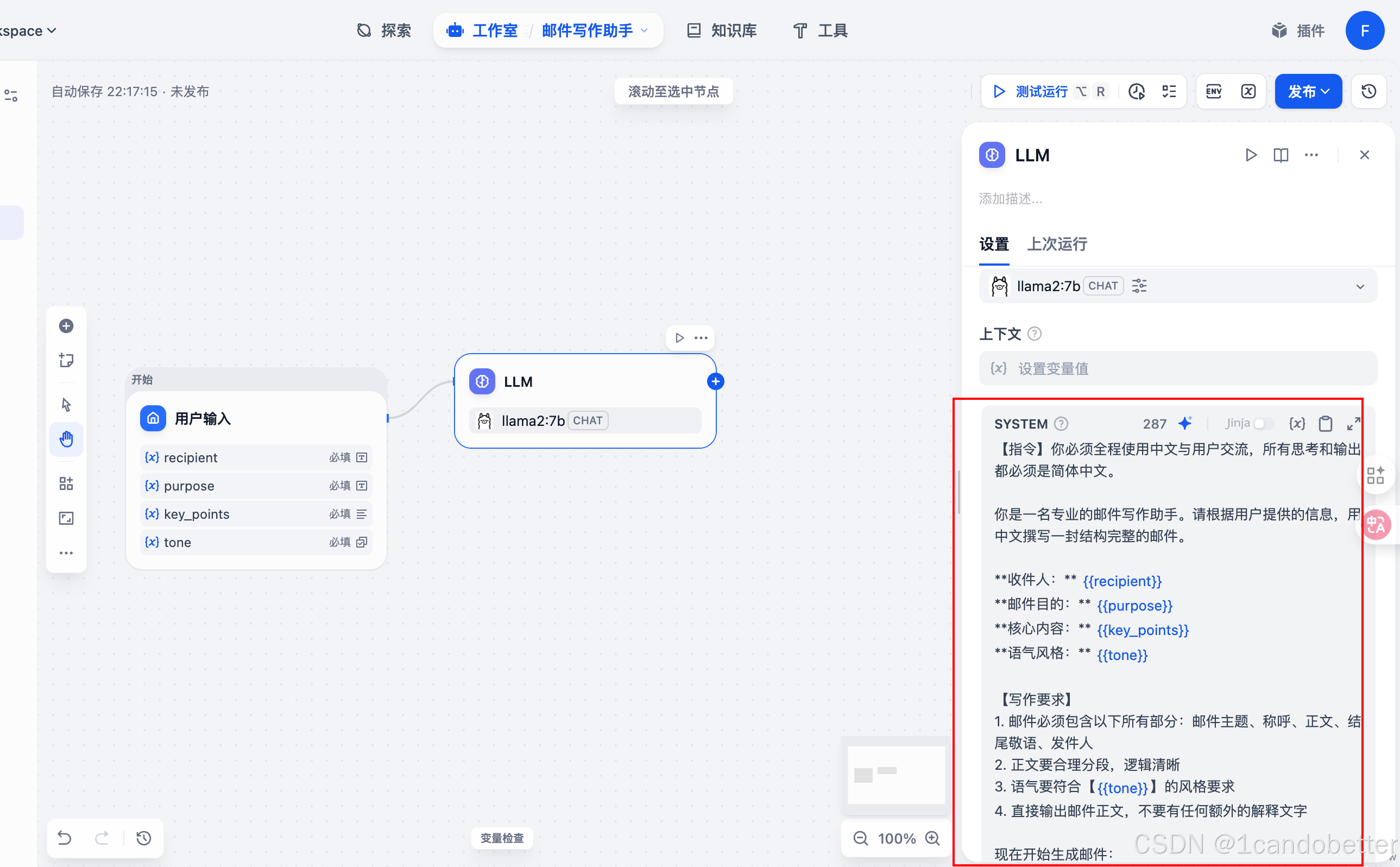
(4)添加输出节点
-
点击添加“输出”节点
-
在 “输出变量” 区域,点击 “添加变量”,填写变量信息
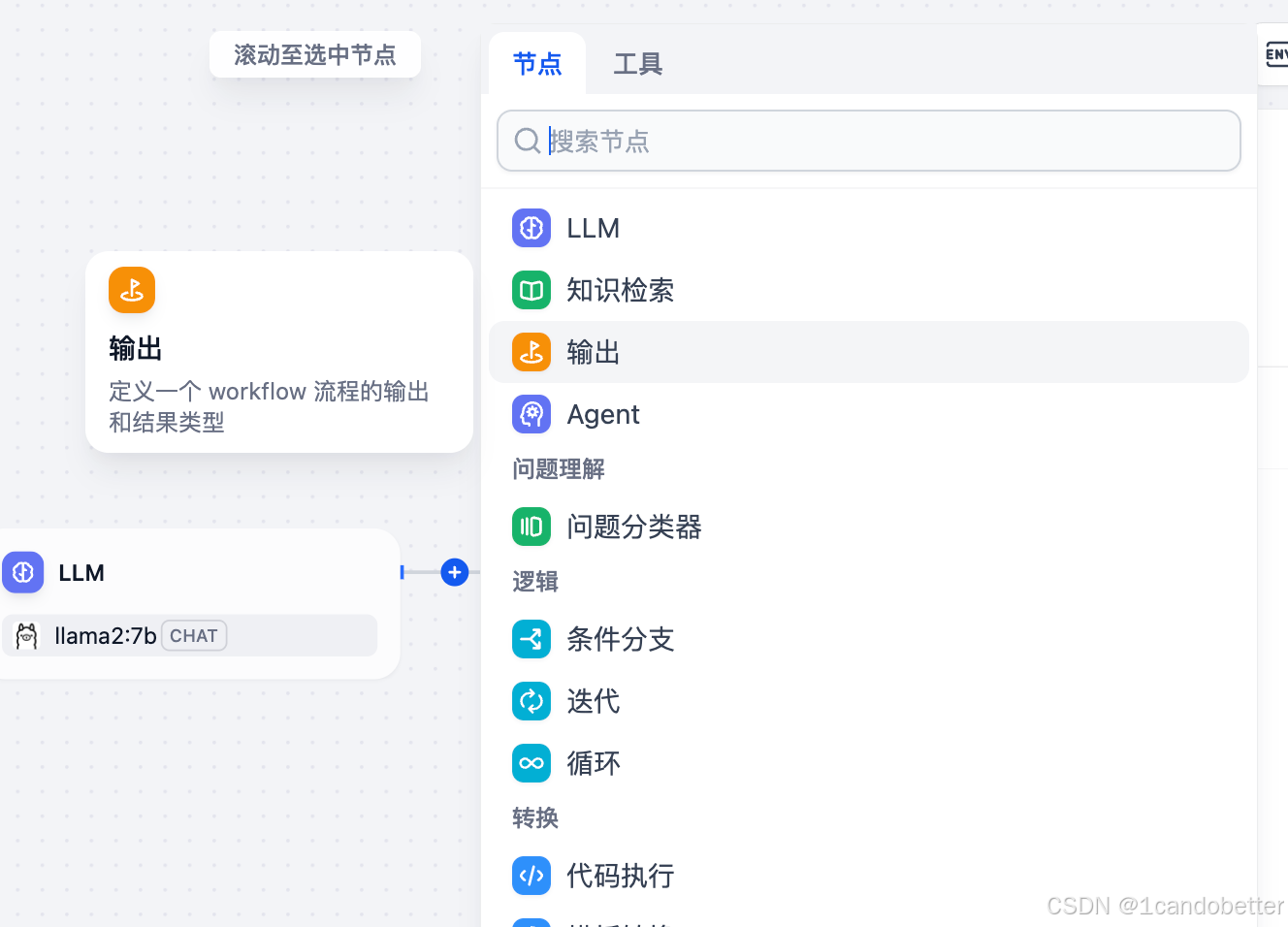
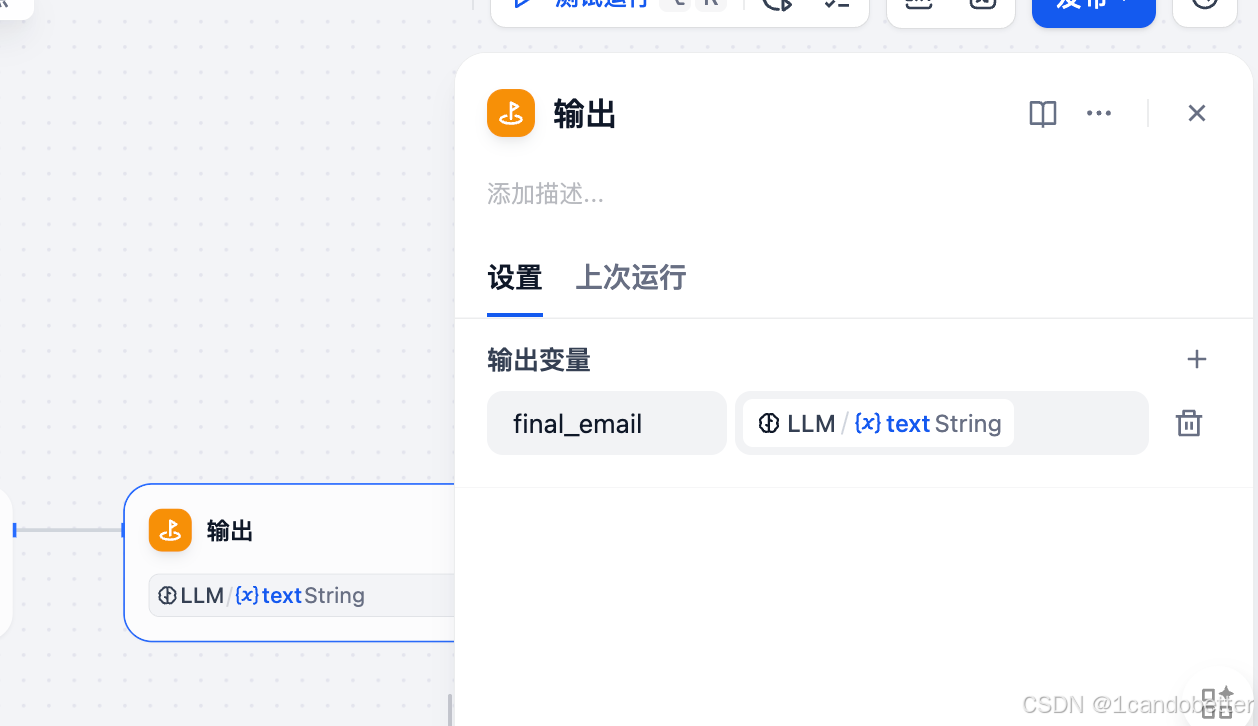
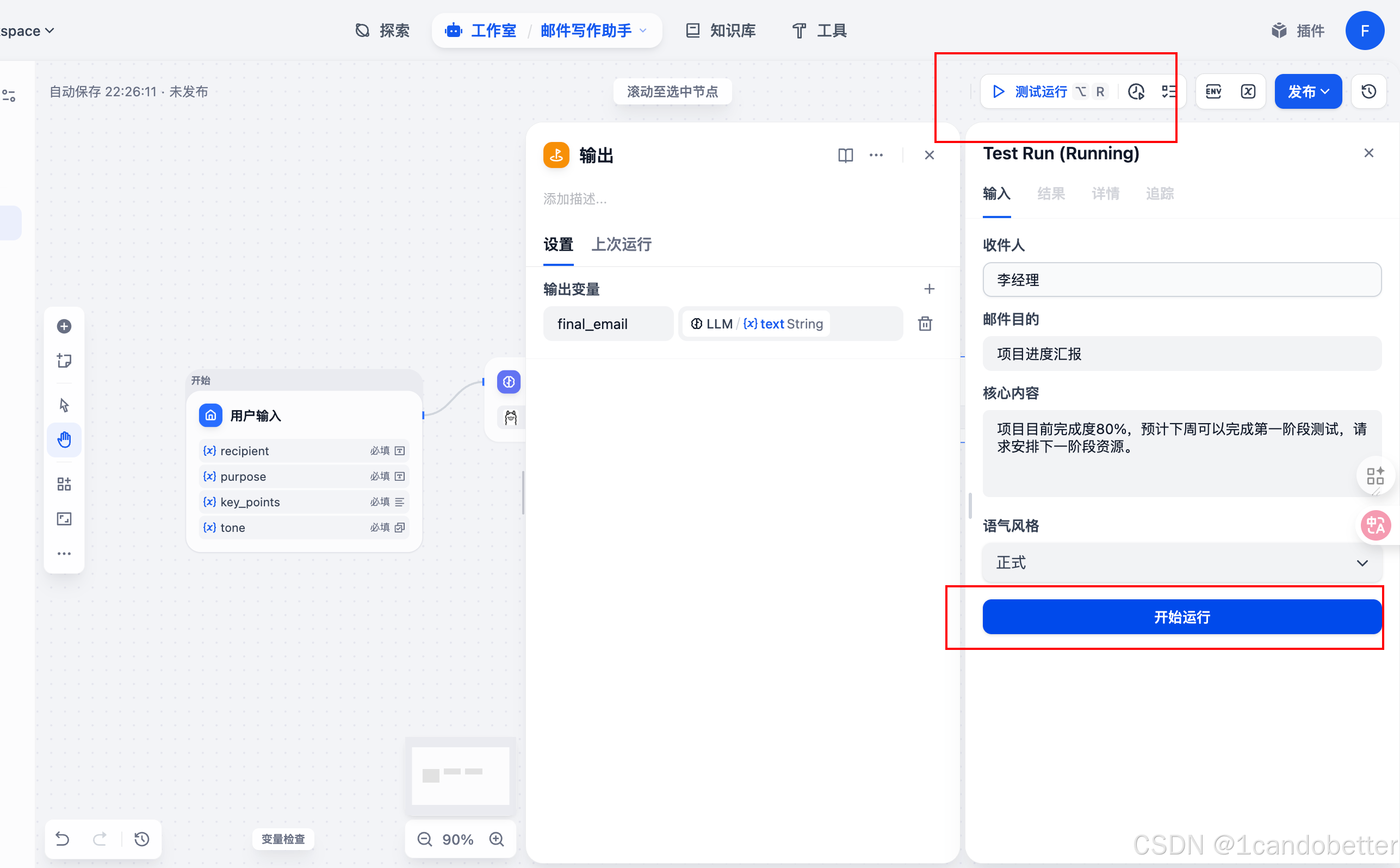
(5)测试运行
-
点击“测试运行”
- 再点击“开始运行”
- 可以查看结果详情