万物互联时代,如何选择合适的时序数据库?
目录
前言:物联网时代为何需要专用的时序数据库?
一、时序数据库选型核心四要素
1.1 性能与可扩展性
1.2 存储成本与数据压缩
1.3 生态系统与集成
1.4 易用性与数据模型
二、实践指南:为何 Apache IoTDB 值得重点关注?
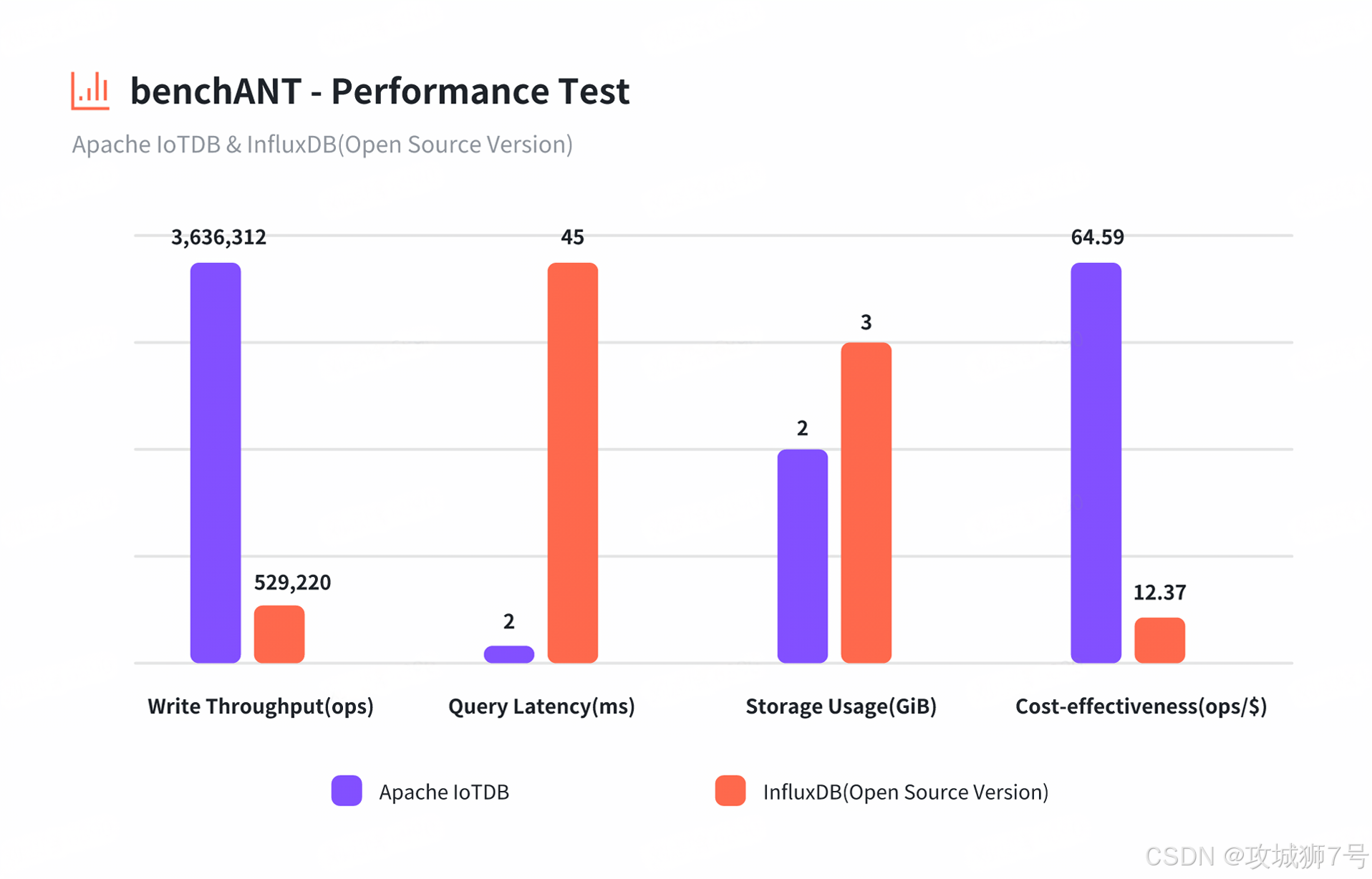
2.1 工业级性能与原生分布式架构
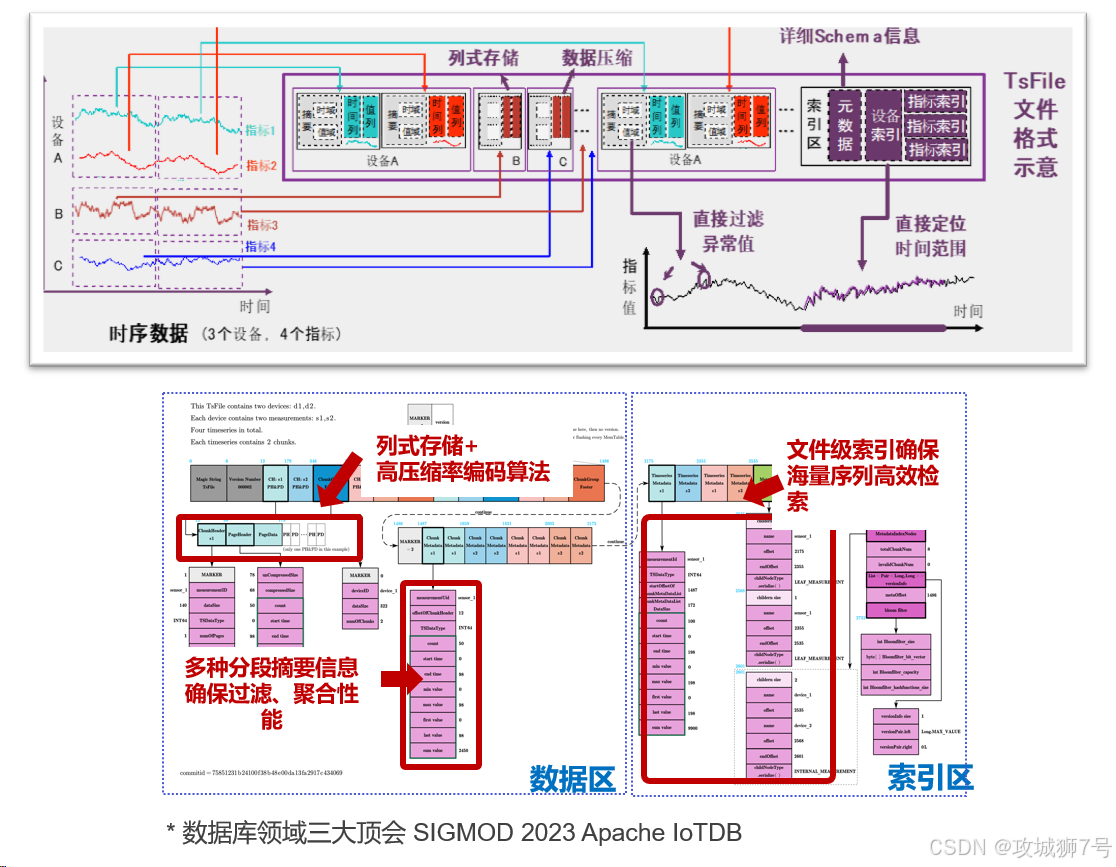
2.2 极致的存储优化
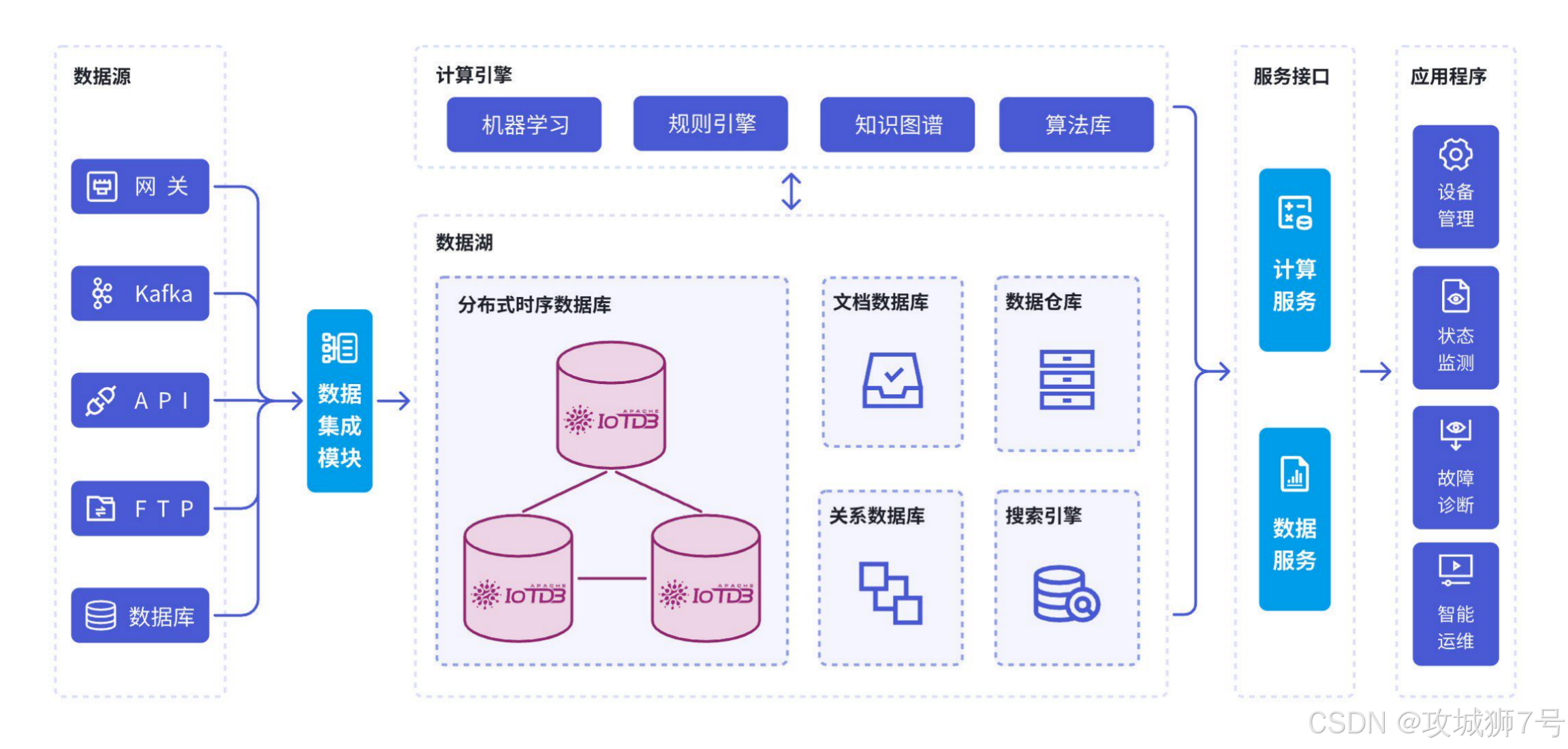
2.3 开放共融的生态
2.4 独特的“树表双模型”与开发者友好性
三、面向未来的“杀手锏”:原生支持 AI,让数据库“听懂人话”
结论:如何做出最终选择?
前言:物联网时代为何需要专用的时序数据库?
在万物互联的时代,来自传感器、智能设备和工业系统的时序数据正以前所未有的速度汇集。面对这股数据洪流,许多团队发现,他们熟悉的MySQL、PostgreSQL等传统关系型数据库(RDBMS)开始力不从心。
RDBMS为事务而生,但在处理高并发写入、海量存储和高效聚合分析等典型的时序场景时,会遭遇严重的写入瓶颈、存储膨胀和查询性能噩梦。
为此,专为处理时间戳数据而设计的时序数据库(Time-Series Database, TSDB)应运而生,成为物联网和监控应用的基石。然而,市面上的TSDB产品众多,如何选择一款能满足当下、支撑未来的产品?本指南将提供一个清晰的选型框架。
一、时序数据库选型核心四要素
选择一款合适的时序数据库,就像为数据帝国选择地基,直接决定了业务的稳定性和未来的发展空间。我们建议从以下四个核心维度进行考量:
1.1 性能与可扩展性
这是选型的基石,直接决定了业务的天花板。
(1)高写入吞吐:能否应对海量设备的高并发数据上报?是否支持高效的批量写入和乱序数据处理?
(2)快查询分析:针对时间范围聚合、降采样、最新值等典型查询,响应速度是毫秒级还是分钟级?
(3)水平扩展能力:当单机无法支撑时,能否通过增加节点平滑地扩展为分布式集群,线性提升系统容量和性能?
1.2 存储成本与数据压缩
时序数据量巨大,存储成本是长期运营中不可忽视的一环。TSDB的核心竞争力之一就在于其极致的数据压缩能力。
(1)专用压缩算法:是否内置针对不同数据类型(整型、浮点、布尔)的专用编码和压缩算法?
(2)高压缩比:对真实业务数据的压缩效果如何?一款成熟的TSDB通常能达到10:1甚至更高的压缩比,极大节约硬件成本。
1.3 生态系统与集成
数据库并非孤立存在,它需要与数据采集、流处理、可视化、AI分析等各种上下游组件协同工作。
(1)连接器与API:是否提供对主流数据集成工具(如Kafka、MQTT)、计算框架(如Spark、Flink)和可视化工具(如Grafana)的官方支持?
(2)多语言客户端:是否提供Java、Python、Go等多种语言的客户端SDK,方便不同技术栈的团队快速接入?
(3)社区开放性:项目是否开源?一个活跃的开源社区,意味着更快的迭代、更及时的Bug修复和更丰富的社区解决方案。
1.4 易用性与数据模型
复杂的系统会增加开发者的学习成本和运维团队的管理负担。
(1)查询语言:是否提供类SQL的查询语言?这能极大降低有关系型数据库背景的开发者的学习成本。
(2)数据模型:模型是否足够灵活,既能清晰地描述物理世界的层级关系,又能满足多维度的标签化查询?
(3)部署与管理:部署和扩容流程是否足够简单?是否提供清晰的监控指标和管理工具?
二、实践指南:为何 Apache IoTDB 值得重点关注?
基于上述选型框架,我们来深入剖析在工业物联网领域备受瞩目的顶级开源项目——Apache IoTDB。它不仅在四个核心维度上表现出色,更在与AI技术的融合上,展现出了远超同侪的前瞻性。
2.1 工业级性能与原生分布式架构
IoTDB 为严苛的工业物联网(IIoT)场景而生。其优化的 `TsFile` 文件结构支持单节点千万点/秒的高通量写入。列式存储和丰富的聚合函数确保了无论是历史数据聚合还是最新值拉取,都能达到毫秒级响应。更重要的是,IoTDB 从设计之初就具备原生分布式能力,其元数据与数据节点分离的架构,让集群的水平扩展简单可靠,足以管理万亿级数据点。
2.2 极致的存储优化
IoTDB 内置了一套智能的数据编码和压缩策略,它会根据数据类型自动选择最优的编码方式(如对时间戳使用 `TS_2DIFF`,对浮点数使用 `Gorilla`),再结合 `Snappy` 等通用压缩算法,能够实现极高的压缩比,显著降低用户的长期存储成本。

比如使用 java 简单接入例子如下:
(1)创建一个maven项目,并在pom.xml文件中添加以下依赖
<dependencies><dependency><groupId>org.apache.iotdb</groupId><artifactId>iotdb-session</artifactId><!-- 版本号与数据库版本号相同 --><version>${project.version}</version></dependency>
</dependencies>(2)创建连接池实例
import java.util.ArrayList;
import java.util.List;
import org.apache.iotdb.session.pool.SessionPool;public class IoTDBSessionPoolExample {private static SessionPool sessionPool;public static void main(String[] args) {// Using nodeUrls ensures that when one node goes down, other nodes are automatically connected to retryList<String> nodeUrls = new ArrayList<>();nodeUrls.add("127.0.0.1:6667");nodeUrls.add("127.0.0.1:6668");sessionPool =new SessionPool.Builder().nodeUrls(nodeUrls).user("root").password("root").maxSize(3).build();}
}2.3 开放共融的生态
作为Apache软件基金会的顶级项目,IoTDB拥有健康、活跃的全球化开源社区,并天然具备强大的生态整合能力。它提供了与Spark、Flink的原生连接器,与Grafana的官方可视化插件,以及覆盖Java、Python、Go、C++等主流语言的全功能客户端,能轻松融入各类技术栈。
2.4 独特的“树表双模型”与开发者友好性
IoTDB在数据模型上提供了极具特色的“双引擎”支持:树形模型完美匹配物联网设备的物理层级关系,直观易管理;表模型则为习惯了关系型数据库的开发者提供了熟悉的视图,并支持灵活的标签(Tag)多维查询。同时支持两种模型,加上其高度兼容标准SQL的查询语言,使得上手和迁移成本极低。
三、面向未来的“杀手锏”:原生支持 AI,让数据库“听懂人话”
如果说以上特性让 IoTDB 成为了一款优秀的TSDB,那么其对 MCP(Model Context Protocol)的原生支持,则让它在AI时代占得了先机。
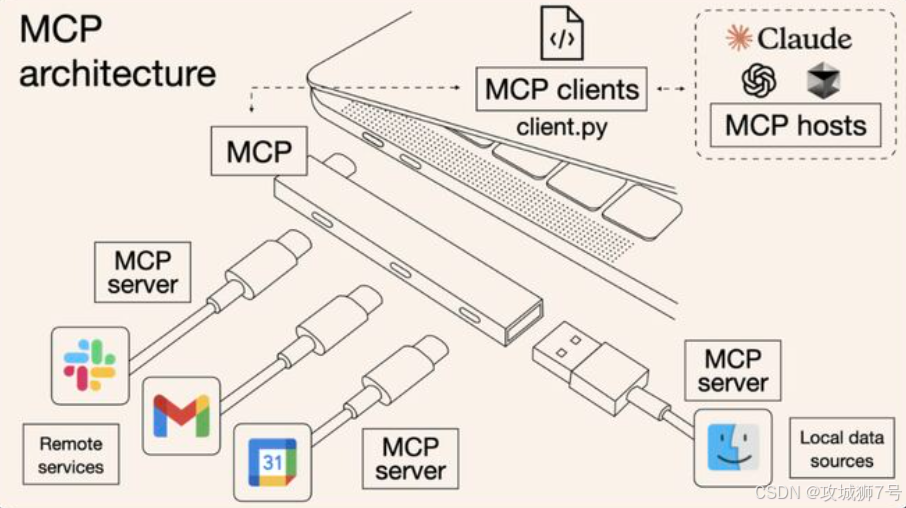
MCP是由知名AI公司Anthropic开源的一套标准协议,它相当于一个“AI的标准插座”,能让大模型(LLM)安全、便捷地调用外部工具和数据源。
Apache IoTDB是业界最早实现并开源MCP Server的数据库之一。这带来的体验是颠覆性的:用户不再需要编写SQL,只需用自然语言提问(例如:“查询昨天所有基站的平均电流”),集成了IoTDB的大模型就能通过MCP协议,自动生成并执行SQL查询,然后以通俗易懂的方式返回分析结果。
这一功能彻底打破了数据使用的技术壁垒,让时序数据库从一个被动存储的“数据仓库”,进化为能与AI直接对话、主动提供业务洞察的“智能数据中枢”。
结论:如何做出最终选择?
时序数据库的选型,是一个需要综合考量性能、成本、生态和未来发展方向的战略决策。
* 对于起步阶段的业务,一个易于部署、拥有活跃社区的开源TSDB是理想选择。
* 当业务面临数据量激增的挑战时,一个具备原生分布式、高扩展性的TSDB将是“定心丸”。
* 若希望降低开发和使用门槛,支持类SQL语言、提供灵活数据模型的TSDB会事半功倍。
* 如果不仅着眼于当下,更希望在AI浪潮中抢占先机,那么像Apache IoTDB这样,已构建起从数据存储到AI应用无缝衔接能力的数据库,无疑是更具前瞻性的选择。
Apache IoTDB凭借其久经考验的稳定性和性能、开放的生态以及在AI集成上的独特创新,为万物互联时代的数据管理提供了一份几近完美的答卷。
Apache IoTDB 官方下载地址:
[https://iotdb.apache.org/zh/Download/]
寻求企业级支持与更强功能?了解由 Apache IoTDB 核心团队打造的商业版
[https://timecho.com]
看到这里了还不给博主点一个:
⛳️ 点赞☀️收藏 ⭐️ 关注!
💛 💙 💜 ❤️ 💚💓 💗 💕 💞 💘 💖
再次感谢大家的支持!
你们的点赞就是博主更新最大的动力!