网站制作中企动力优上海小企业网站建设
一、爬虫
1.1 爬虫解释
爬虫简单的说就是模拟人的浏览器行为,简单的爬虫是request请求网页信息,然后对html数据进行解析得到自己需要的数据信息保存在本地。
1.2 爬虫的思路
# 1.发送请求
# 2.获取数据
# 3.解析数据
# 4.保存数据
1.3 爬虫工具
DrissionPage的个人空间-DrissionPage个人主页-哔哩哔哩视频
DrissionPage® 是一个基于 Python 的网页自动化工具。
既能控制浏览器,也能收发数据包,还能把两者合而为一。
可兼顾浏览器自动化的便利性和 requests 的高效率。
功能强大,语法简洁优雅,代码量少,对新手友好。
可以参考官网视频学习基本概念。
二、爬虫实战
2.1 爬虫需求
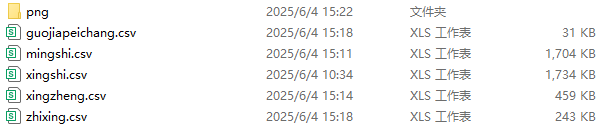
对首页 - 人民法院案例库的4884条法律案件信息进行csv保存。
2.2 爬虫效果
爬虫后的效果图:

2.3 爬虫实现过程
2.3.1 环境配置
最好先再本地安装好anaconda,然后创建虚拟环境和安装这个包。如何安装anaconda可以参考我之前的博客手把手教你使用云服务器和部署相关环境!!!-CSDN博客
conda create -n pachong python=3.10.16 -y
conda activate pachong
pip install DrissionPage==4.1.0.18
DrissionPage 4.1.0.18
python 3.10.16
2.3.2 学习DrissionPage的基本操作
设置好DrissionPage的默认浏览器启动路径,找到自己的chrome浏览器或者edge浏览器,得到路径,注意是需要.exe的执行文件路径,运行下面的代码就设置好了浏览器的启动环境。
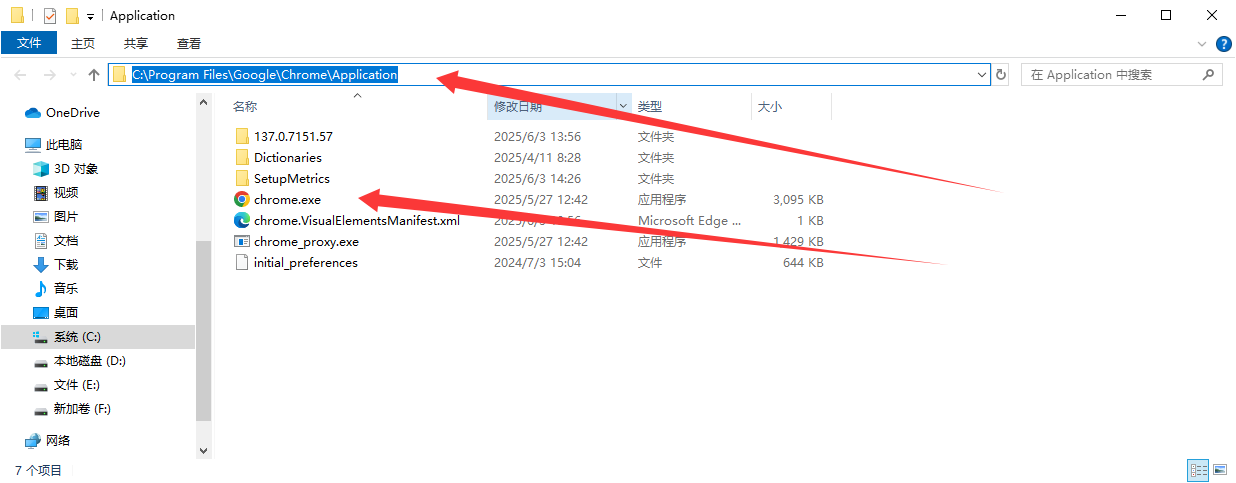
from DrissionPage import ChromiumOptions
path = r'C:\Program Files\Google\Chrome\Application\Chrome.exe' # 请改为你电脑内Chrome可执行文件路径
ChromiumOptions().set_browser_path(path).save()
实例化浏览器对象和关闭浏览器对象操作
# 浏览器对象,标签页对象,页面元素对象
from DrissionPage import Chromium
# 链接浏览器
browser = Chromium()
browser.set.retry_interval(5)# 设置重试间隔
tab = browser.latest_tab
# 关闭浏览器
browser.quit()
标签页的相关函数
# 浏览器对象,标签页对象,页面元素对象
from DrissionPage import Chromium
# 链接浏览器
browser = Chromium()
browser.set.retry_interval(5)# 设置重试间隔
tab = browser.latest_tab
tab.get('http://DrissionPage.cn') # 使用标签页访问url函数
tab2 = browser.new_tab("http://www.baidu.com") # 新建标签页函数
tab3 = browser.get_tab(title="DrissionPage") # 访问标签页函数
# 关闭标签页对象
tab.close()
# 标签页的后退前进与刷新
tab.back(2) # 后退2次
tab.forward(1) # 前进
tab.refresh() # 刷新
# 关闭浏览器
browser.quit()
html元素对象的相关函数,元素可以使用Xpath语法进行定位
from DrissionPage import Chromium
# 链接浏览器
browser = Chromium()
browser.set.retry_interval(5)# 设置重试间隔
tab = browser.latest_tab
tab.get('http://DrissionPage.cn')
# 获取页面元素
# tab对象中直接查找
ele = tab.ele('使用文档') # 获取文本中包含“使用文档”的元素
ele.check() # 点击元素
# 相对位置查找
ele2 = ele.next() # 获取ele的下一个兄弟元素
ele2.click() # 点击元素
# 关闭浏览器
# browser.quit()
一个实例
from DrissionPage import Chromium
# 链接浏览器
browser = Chromium()
browser.set.retry_interval(5)# 设置重试间隔
tab2 = browser.new_tab("http://www.baidu.com")
# 定位一个元素,输入按钮 , x表示xpath语法
input_btn = tab2.ele('x://*[@id="kw"]')
print(input_btn.html)
# 输入搜索内容
input_btn.input("python")
# 定位一个搜索按钮
search_btn = tab2.ele('x://*[@id="su"]')
search_btn.click()
2.3.3 获取目标网页的数据
2.3.3.1 抓包分析得到数据,需要先监听标识符
按F12进入开发者模式,刷新页面,再network中可以搜索相关的数据包
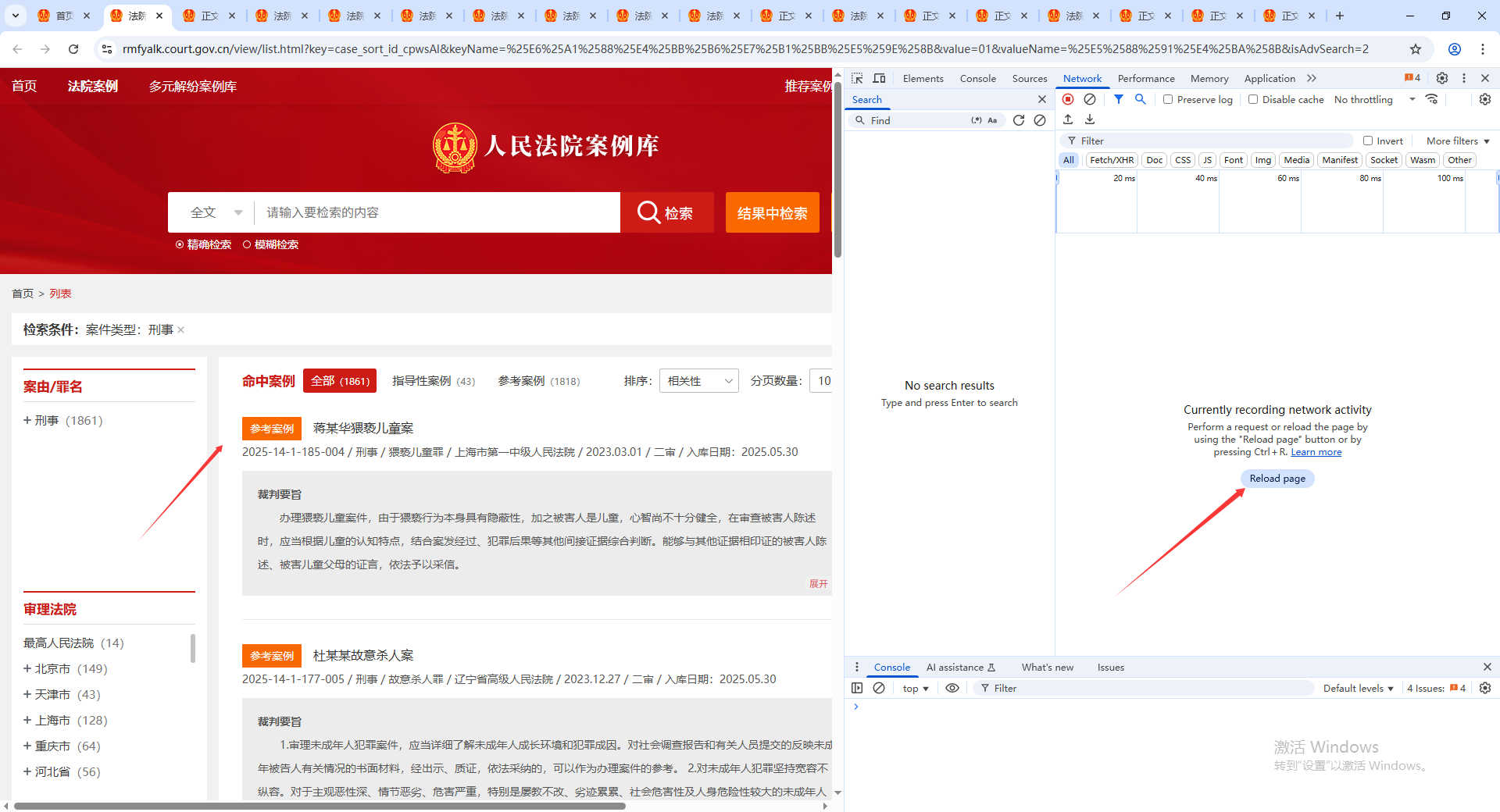
比如我们搜索,蒋某华猥亵儿童案。只有一个搜索结果,headers是前端请求后端的信息,preview是请求结果的预览信息,response是请求结果的详细信息。我们对数据抓包主要是看这三部分信息。
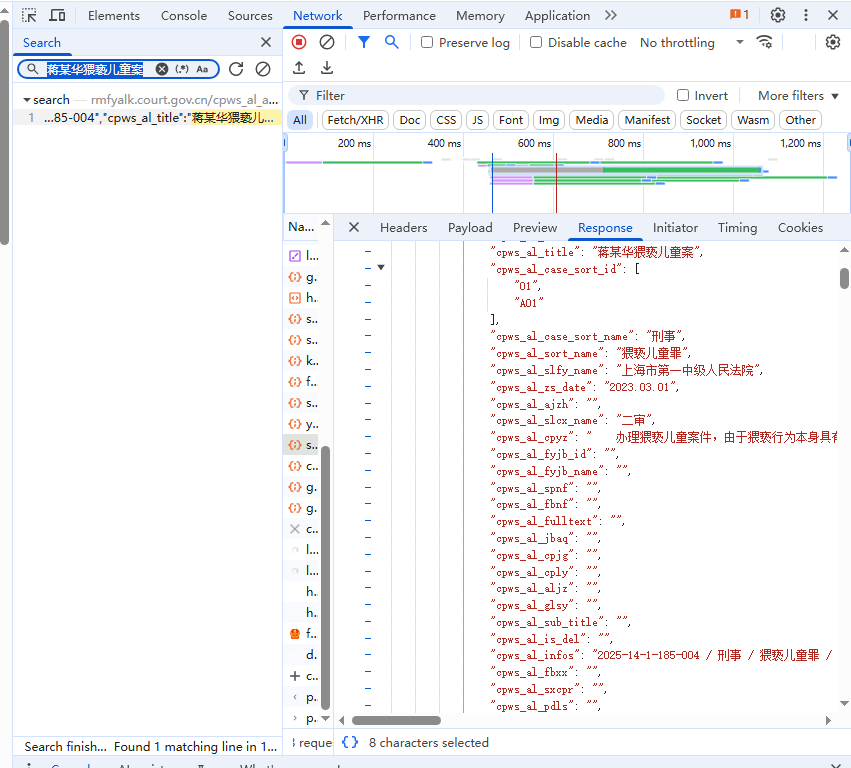 我们再preview中可以看到数据包中的['data']['datas']刚好有这页的10个案件信息,我们对这个信息中抽取我们需要的信息再保存再本地就行。
我们再preview中可以看到数据包中的['data']['datas']刚好有这页的10个案件信息,我们对这个信息中抽取我们需要的信息再保存再本地就行。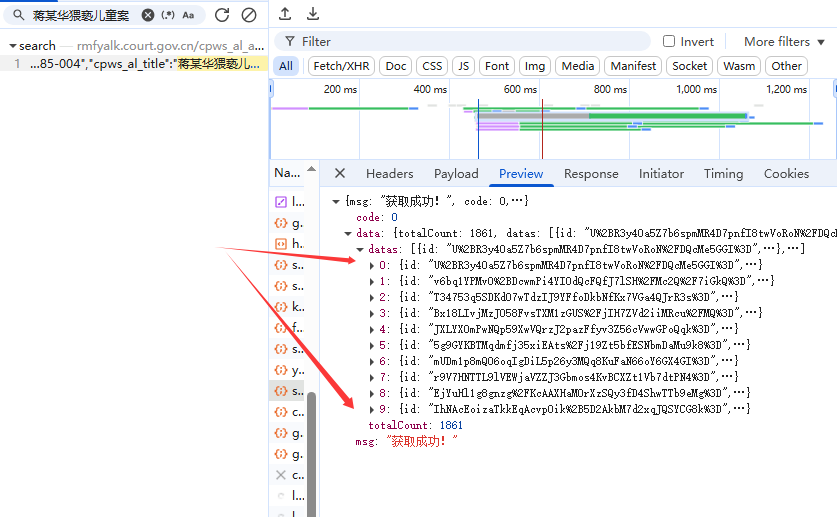
我们此时监听的是:蒋某华猥亵儿童案,虽然也可以用,但是我们一般选择监听请求头的信息,一般是“?”前面的https(如果有的话),复制一下,检索一下看一下是不是唯一值。
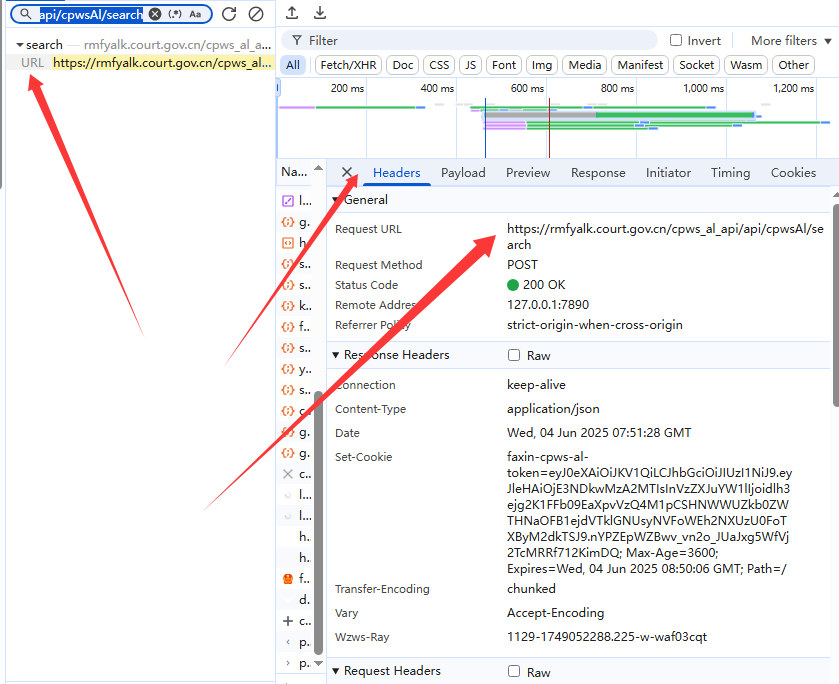
2.3.3.2 html元素定位xpath得到html元素,得到数据
DrissionPage非常好的功能是通过xpath语法定位到html元素,就可以使用元素.text 、元素.html等获得相关数据,定位元素过程,F12打开开发者工具,最左边的定位标识符选择你想定位的网页元素,比如我定位的是下一页的按钮元素,得到位置后,右键选择copy,XPath,然后按ctrl+f进行搜索模式,就可以看到你的这个XPath语法定位的元素再当前标签页中有几个了。
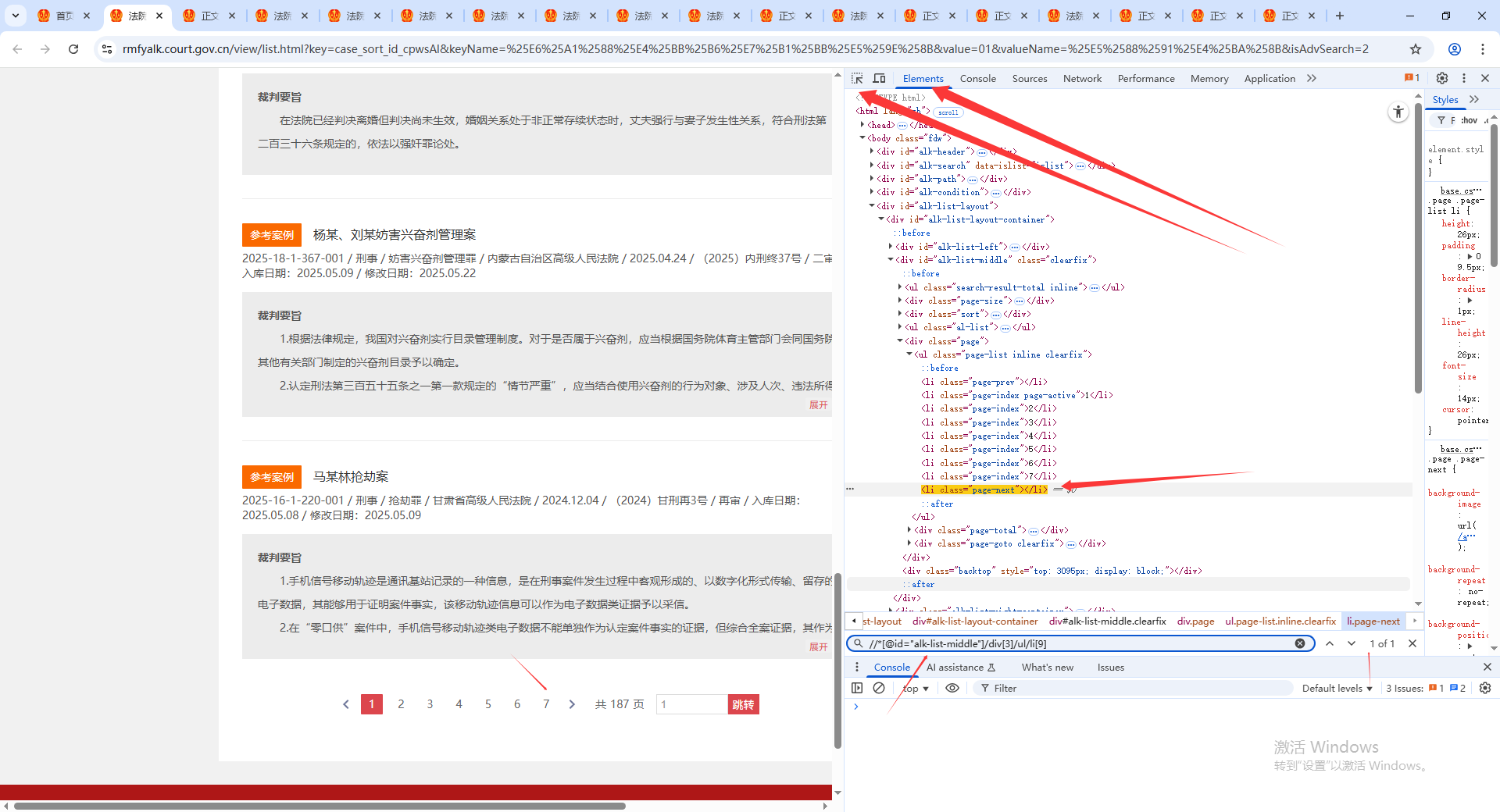
2..3.4 爬取全部信息
我们平时怎么操作浏览器,就怎么写代码。
思路: 打开浏览器,新建标签页,搜索目标url,通过监听唯一的标识符:“https://rmfyalk.court.gov.cn/cpws_al_api/api/cpwsAl/search”得到当前页面的10个案件的数据包,对数据包列表的每个数据进行抽取我们需要的信息,再保存到csv表格中。下滑,点击下一页,重复上述操作。
from DrissionPage import Chromium
from pprint import pprint
import csv
# 打来浏览器
tab = Chromium().latest_tab
# 监听数据包
tab.listen.start("https://rmfyalk.court.gov.cn/cpws_al_api/api/cpwsAl/search")
# 访问页面
url = "https://rmfyalk.court.gov.cn/view/list.html?key=case_sort_id_cpwsAl&keyName=%25E6%25A1%2588%25E4%25BB%25B6%25E7%25B1%25BB%25E5%259E%258B&value=05&valueName=%25E6%2589%25A7%25E8%25A1%258C&isAdvSearch=2"
tab.get(url)
f = open(r'E:\gdzd_hb\pachoong\zhixing.csv', 'w', encoding='utf-8', newline='')
# 字典写入方法
csv_writer = csv.DictWriter(f, fieldnames=['案件名称', '案件标签', '裁判要旨'])
# 写入表头
csv_writer.writeheader()
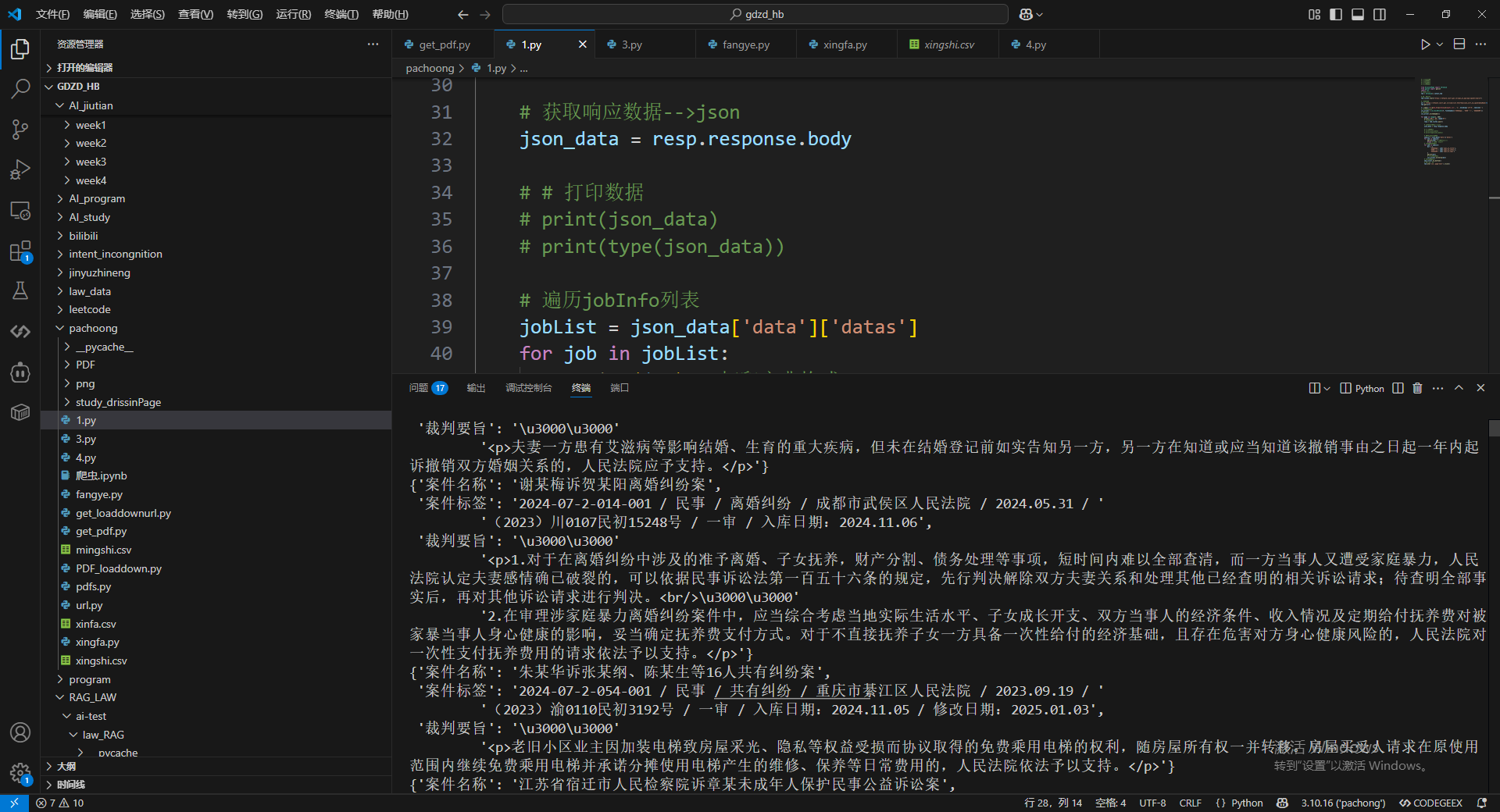
for page in range(1, 208):
print(f'正在爬取第{page}页')
# 等待数据包加载
resp = tab.listen.wait()
# 获取响应数据-->json
json_data = resp.response.body
# # 打印数据
# print(json_data)
# print(type(json_data))
# 遍历jobInfo列表
jobList = json_data['data']['datas']
for job in jobList:
pprint(job) # 打印字典格式
break # 打印一个结束
# 抽取需要的数据
for job in jobList:
dit = {
'案件名称': job['cpws_al_title'],
'案件标签': job['cpws_al_infos'],
'裁判要旨': job['cpws_al_cpyz']
}
pprint(dit)
# 字典写入数据
csv_writer.writerow(dit)
# 下滑到最底部
tab.scroll.to_bottom()
# 点击下一页
tab.ele('css:.page-next').click()
三、问题和小结
进阶需求:爬取每个案件的对应的详细PDF信息。
方法一:通过点击每个案件,进去后再点击下载PDF的案件到指定文件夹中实现。
存在问题:网站做了限制,每个账号下载了20个左右的PDF,就会显示下面的报错,就算是人工手动下载PDF文件也是一样的。

方法二:通过获取每个案件的详情url地址,使用元素来获取相关信息,用字典保存,再保存到csv文件中。
存在的问题:网站做了限制,我们一个账号连续访问40个左右的案件详情网页后,就会显示空的网页,从而无法获得html元素。
这两个问题我暂时没有解决办法,因为DrissionPage已经是模拟人的行为进行抓包了,但是网站对每个账号进行了限制。