个人网站趋向网站建设客户怎么找
RAG学习
参考文档:香港科技大学/LightRAG:「LightRAG:简单快速的检索增强生成」
感谢前辈们百忙中抽空做的ppt
文章目录
- RAG学习
- 1. 概念
- 2. lightRAG
- 1. 介绍
- 2. 自行小尝试
- 3. 原项目部署
- 参考
1. 概念
检索增强生成(Retrieval-augmented Generation)简称RAG,是当下热门的大模型前沿技术之一。2020年,Facebook Al Research(FAIR)团队发表名为《Retrieval–Augmented Generation for Knowledge-Intensive NLP Tasks》的论文该篇论文首次提出了RAG概念。
检索增强生成模型结合了语言模型和信息检索技术。具体来说,当模型需要生成文本或者回答问题时,它会先从一个庞大的文档集合中检索出相关的信息,然后利用这些检索到的信息来指导文本的生成,从而提高预测的质量和准确性。
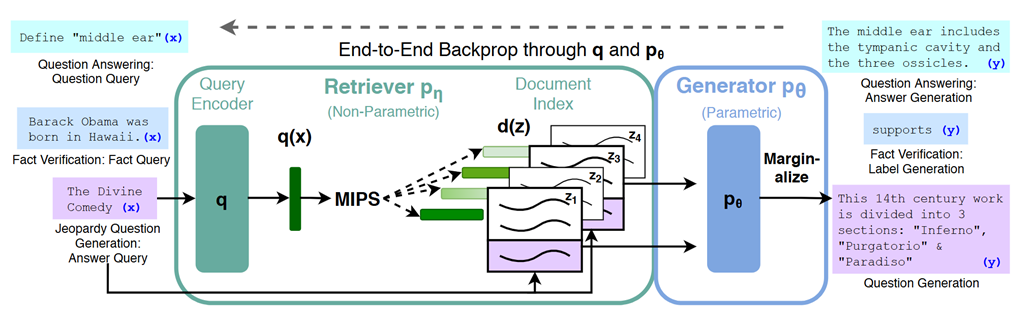
RAG 的技术优势
**外部知识的利用:**RAG模型可以有效地利用外部知识库,它可以引用大量的信息,以提供更深入、准确且有价值的答案,这提高了生成文本的可靠性。
**数据更新及时性:**RAG模型具备检索库的更新机制,可以实现知识的即时更新,无需重新训练模型。说明RAG模型可以提供与最新信息相关的回答,高度适配要求及时性的应用。
**回复具有解释性:**由于RAG模型的答案直接来自检索库它的回复具有很强的可解释性,减少大模型的幻觉。用户可以核实答案的准确性,从信息来源中获取支持。
**高度定制能力:**RAG模型可以根据特定领域的知识库和的领域和prompt进行定制,使其快速具备该领域的能力。说明RAG模型广泛适用于应用,比如虚拟伴侣、虚拟宠物等应用。
**安全和隐私管理:**RAG模型可以通过限制知识库的权限来实现安全控制,确保敏感信息不被泄露,提高了数据安全性。
**减少训练成本:**RAG模型在数据上具有很强的可拓展性可以将大量数据直接更新到知识库,以实现模型的知识更新。这一过程的实现不需要重新训练模型,更经济实惠。
RAG 相比于微调
**任务特定vs通用性:**微调通常是为特定任务进行优化,RAG是通用的,可以用于多种任务。微调对于特定任务的完成效果好但在通用性问题上不够灵活。
**知识引用vs学习:**RAG模型通过引用知识库来生成答案而微调是通过学习任务特定的数据生成答案。RAG的答案直接来自外部知识,更容易核实。
**即时性vs训练:**RAG模型可以实现即时的知识更新,无重新训练,在及时性要求高的应用中占优势。微调通常需要重新训练型,时间成本较高。
**可解释性vs难以解释性:**RAG的答案可解释性强,因为它们来自知识库。微调模型的内部学习可能难以解释。
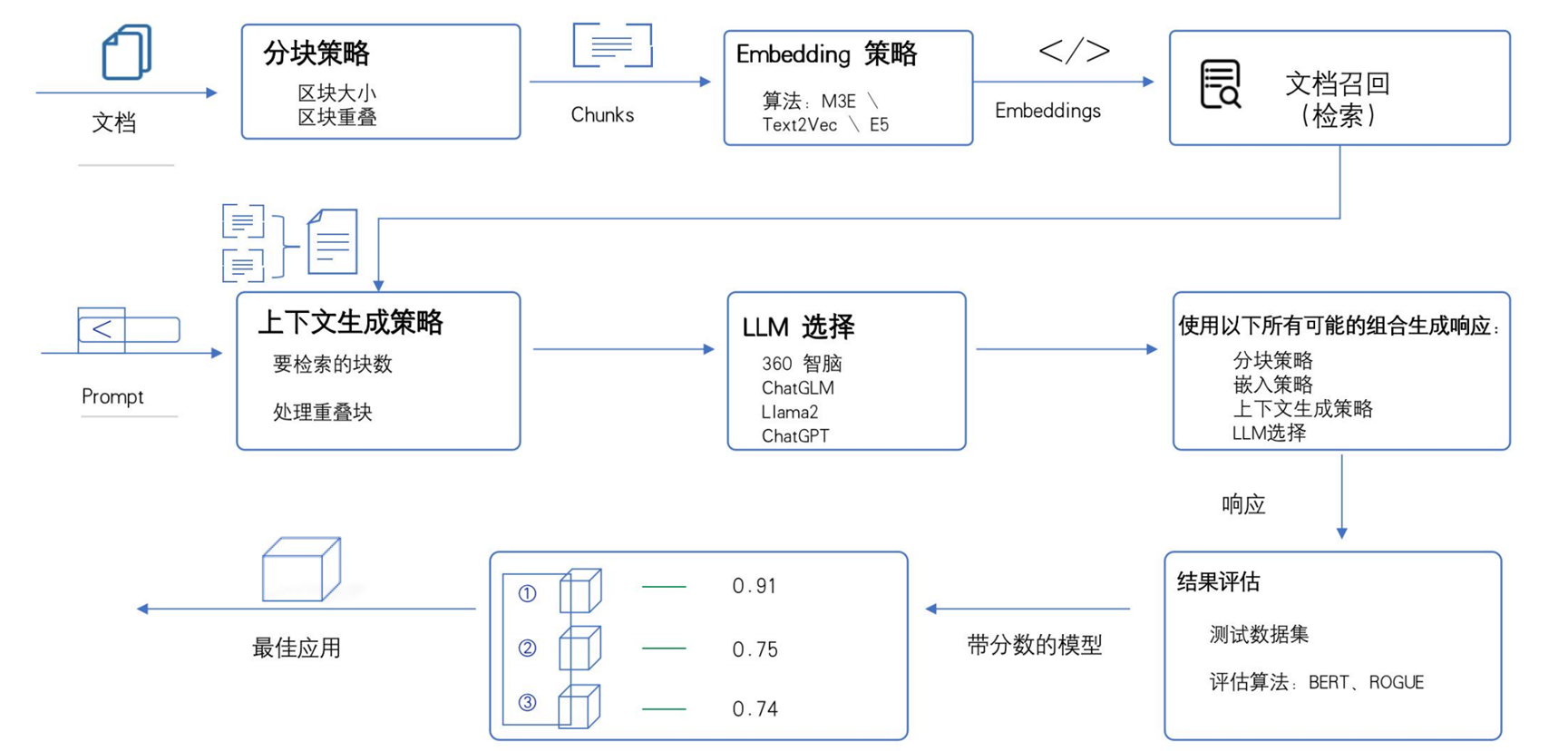
RAG技术的基本流程如下,
第一步:**文档收集与清洗:**收集领域相关的原始文档(如 PDF、网页、手册等),去除重复、无效信息(如广告、格式乱码)。
第二步:**文档分块:**将长文档拆分为语义连贯的短文本块(避免超过模型上下文限制),通常保留部分重叠内容(增强语义连贯性)。
第三步:**生成嵌入向量:**通过 Embedding 模型(如 OpenAI 的 text-embedding、开源的 sentence-transformers)将每个文本块转换为数值向量。
第四步:**向量存储:**将文本块及其对应的向量存入向量数据库(如 Pinecone、Milvus、FAISS),便于后续快速检索。
在接受用户提问后:用与文档分块步骤相同的 Embedding 模型,将用户问题转换为向量。在向量数据库中,通过计算 “问题向量” 与 “文档块向量” 的相似度(如余弦相似度),召回最相关的 Top N 个文本块。将检索到的文本块作为 “上下文”,与用户问题、指令(如 “基于以下信息回答”)组合成完整提示词。将提示词输入 LLM(如 GPT-3.5、ChatGLM、Llama2),模型基于上下文生成准确、相关的回答。
2. lightRAG
1. 介绍
我们来了解一下具体实施RAG功能的一些框架,LightRAG 是一个轻量级的检索增强生成(Retrieval-Augmented Generation, RAG)框架。通过结合向量检索和知识图谱的优势,它能够提供更准确和可解释的问答结果。
LightRAG 的架构,分为两个主要部分:
**第一部分:**基于图的索引阶段。将文档信息(建设索引流程)。
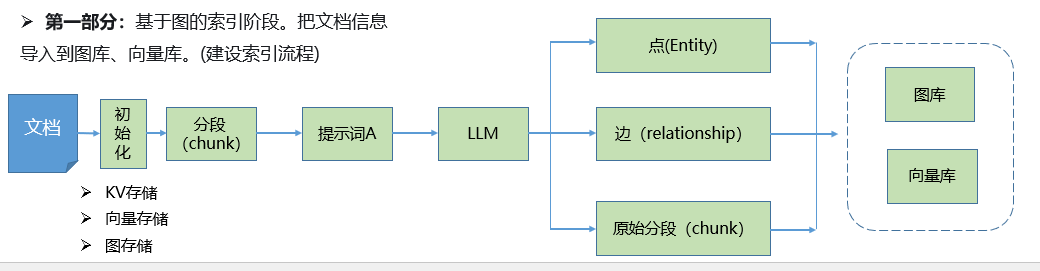
第二部分:根据用户的查询,对向量库中存储的信息进行检索。LightRAG提供了四种检索方式,分别为:Naive Search、Local Search、Hybrid Search以及Global Search。
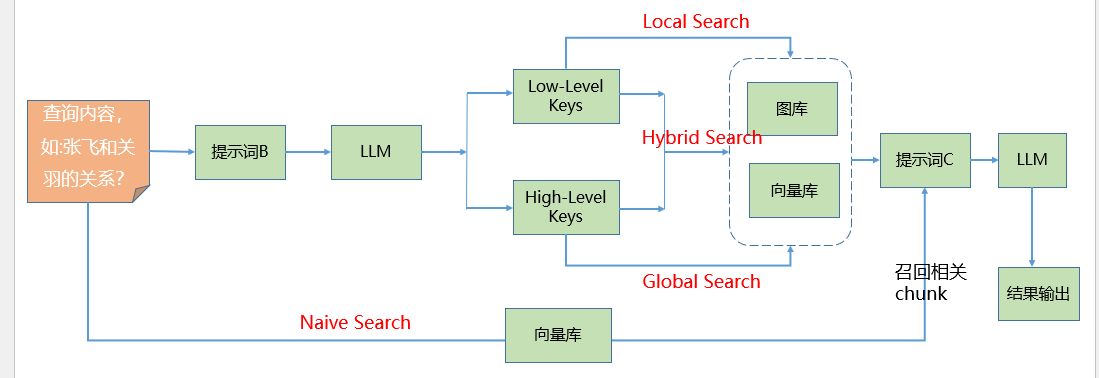
| 模式 | 检索方式 | 依赖数据 | 优点 | 缺点 | 适用场景 |
|---|---|---|---|---|---|
| Naive | 关键字匹配或简单向量搜索 | 文本分片(kv_store_text_chunks.json) | 速度快,计算开销低 | 缺乏语义和全局上下文 | 简单查询,快速检索 |
| Local | 基于嵌入向量的语义搜索 | 嵌入向量(vdb_chunks.json) | 语义理解强,精确检索 | 忽略全局关系 | 语义相关性高的查询 |
| Global | 基于知识图谱的全局检索 | 图谱(graph_chunk_entity_relation.graphml) | 捕捉复杂关系,适合全局分析 | 计算复杂,依赖图谱质量 | 复杂问题,需要实体关系推理 |
| Hybrid | 语义搜索 + 图谱检索 | 嵌入向量 + 图谱 | 综合局部和全局信息,答案全面 | 计算开销高,依赖数据完整性 | 复杂查询,需要高准确度 |
2. 自行小尝试
下载原版 LightRAG Core 大概率会卡住
pip install lightrag -i https://mirrors.aliyun.com/pypi/simple/
换这个
pip install "lightrag-hku[api]"
pip install httpx
pip install lightrag-hku
pip install --upgrade pyvis
下载ollama
https://ollama.com/download
打开cmd命令行
ollama pull gemma2:2b
ollama pull nomic-embed-text
#下载模型C:\Users\21609>ollama run gemma2:2b
>>> /set parameter num_ctx 32000
Set parameter 'num_ctx' to '32000'
>>> /bye
#调整上下文长度ollama serve
# ollama run gemma2:2b
ollama ps
#可以启动多个终端输入命令# ollama list
# 查看模型# ollama run xxx --temp <value> --max-tokens <value>
# 启动模型或者下载并运行模型
# 设置温度 设置最大输出长度# ollama stop xxx
# 停止模型# ollama ps
# 查看运行状态# ollama serve
# 启动服务
以下指令没什么返回也是正常的

它会在当前目录下新建一个 rag_storage 目录,这个目录名似乎不能改其他的,不然检索时找不到。
import os
import asyncio
import logging
from lightrag import LightRAG, QueryParam
from lightrag.llm.ollama import ollama_model_complete, ollama_embed
from lightrag.utils import EmbeddingFunc
from lightrag.kg.shared_storage import initialize_pipeline_status# 设置日志
logging.basicConfig(format="%(levelname)s:%(message)s", level=logging.INFO)# 初始化 LightRAG
WORKING_DIR = "./rag_storage"
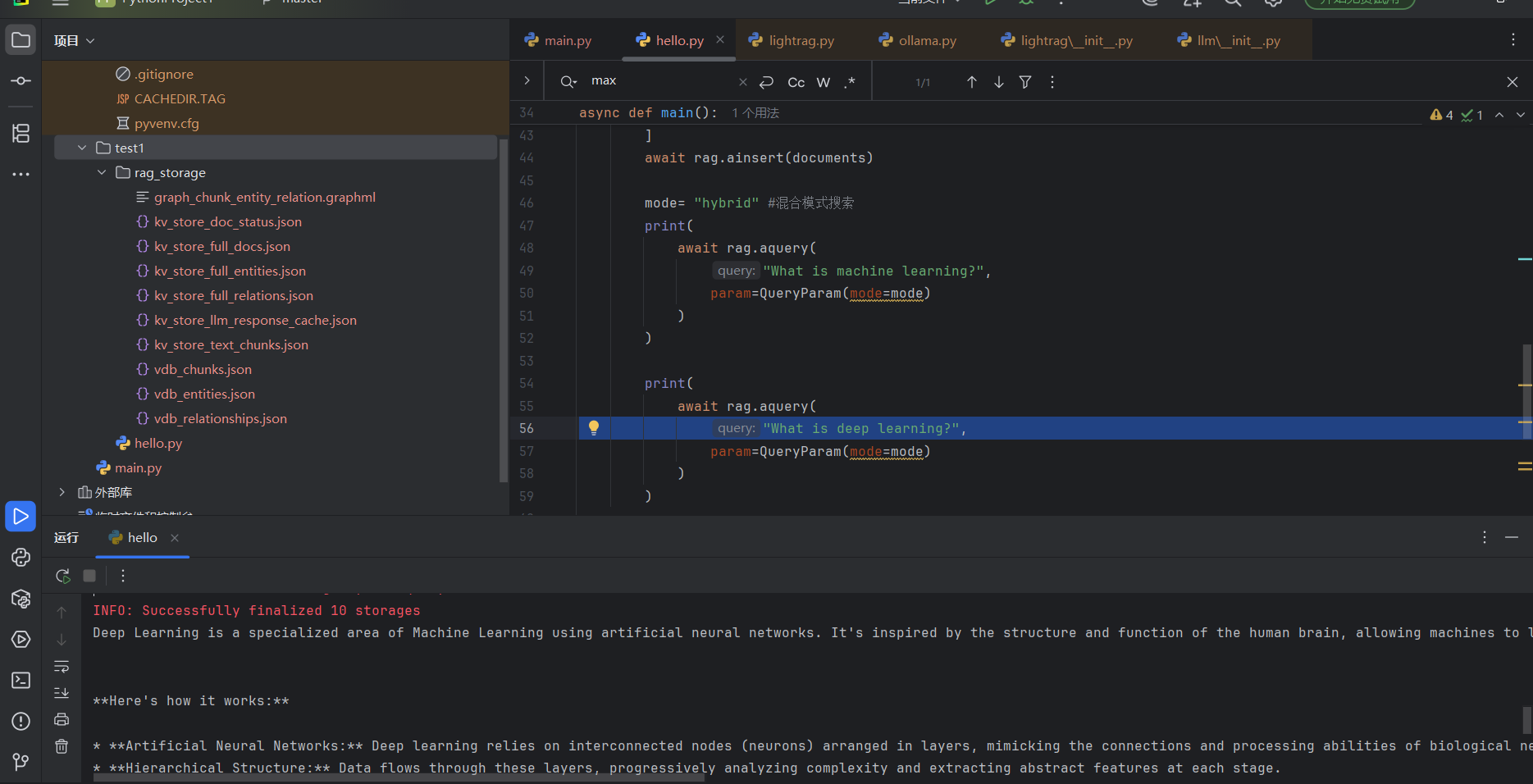
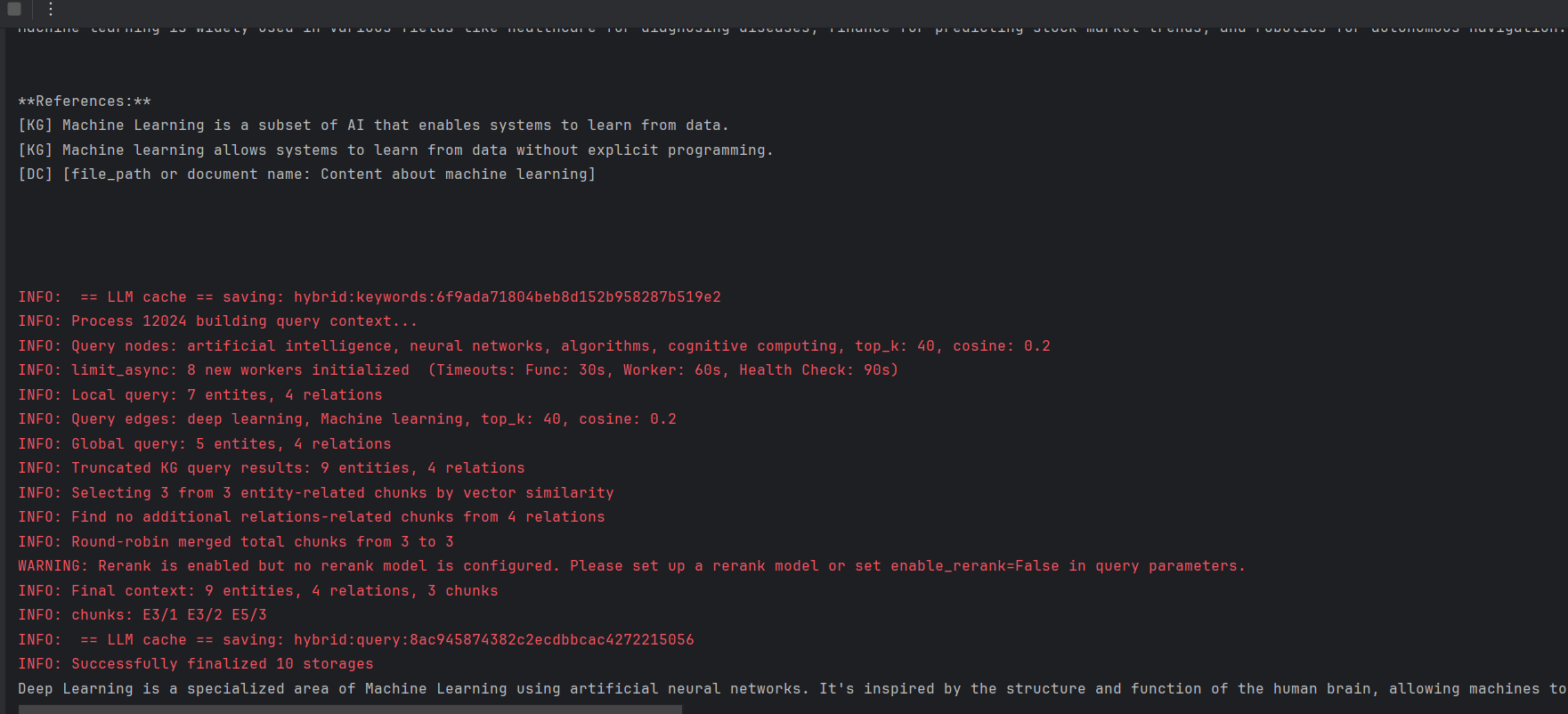
if not os.path.exists(WORKING_DIR):os.mkdir(WORKING_DIR)async def init_rag():rag = LightRAG(working_dir=WORKING_DIR,llm_model_func=ollama_model_complete,llm_model_name="gemma2:2b",llm_model_kwargs={"options": {"num_ctx": 32768}}, # ollama默认8k,但lightRAG要求上下文至少32k个令牌embedding_func=EmbeddingFunc(embedding_dim=768,max_token_size=8192,func=lambda texts: ollama_embed(texts, embed_model="nomic-embed-text")),)await rag.initialize_storages() # 初始化所有存储后端await initialize_pipeline_status() # 初始化处理管道return ragasync def main():try:rag = await init_rag()#运行初始化# 插入样本文档documents = ["Machine Learning is a subset of AI that enables systems to learn from data.","Deep Learning is a specialized area of Machine Learning using neural networks.","AI includes applications like natural language processing and robotics."]await rag.ainsert(documents)mode= "hybrid" #混合模式搜索print(await rag.aquery("What is machine learning?",param=QueryParam(mode=mode)))print(await rag.aquery("What is deep learning?",param=QueryParam(mode=mode)))except Exception as e:print(f"发生错误:{e}")finally:if rag:await rag.finalize_storages()if __name__ == "__main__":asyncio.run(main())
3. 原项目部署
确保上面的两个模型已安装并且ollama serve启动
确保上述python的依赖下载好
安装并启动LightRAG服务器
C:\Users\21609\Desktop\code\lightRag>git clone https://github.com/HKUDS/LightRAG.git
cd LightRAG
# create a Python virtual enviroment if neccesary
# Install in editable mode with API support
pip install -e ".[api]"
copy env.example .env
# cp env.example .env
lightrag-server
可以看到原项目采用 gpt-4o + bge-m3 的组合。
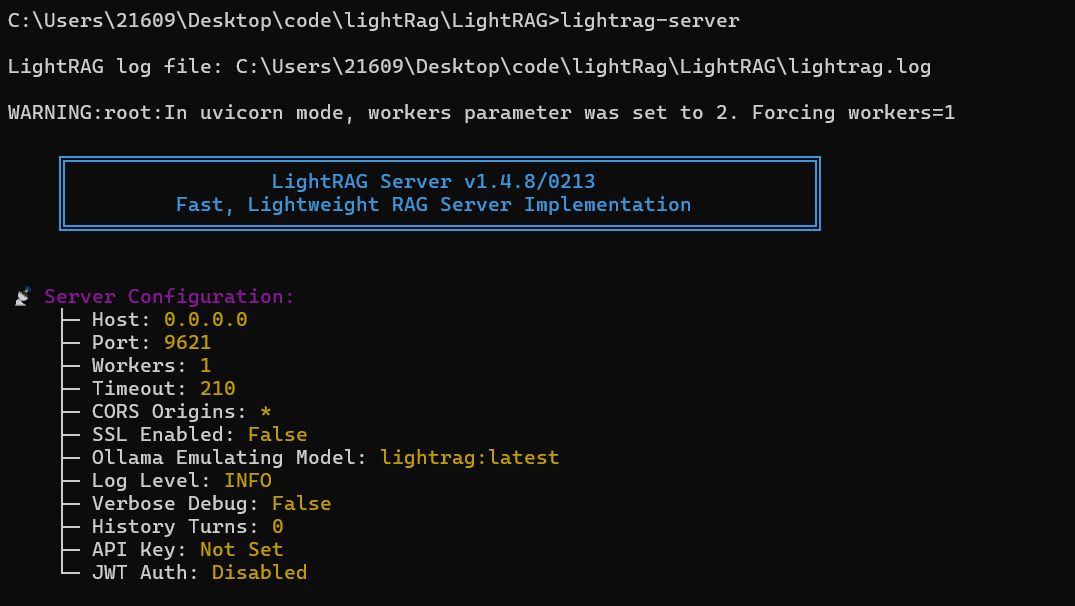
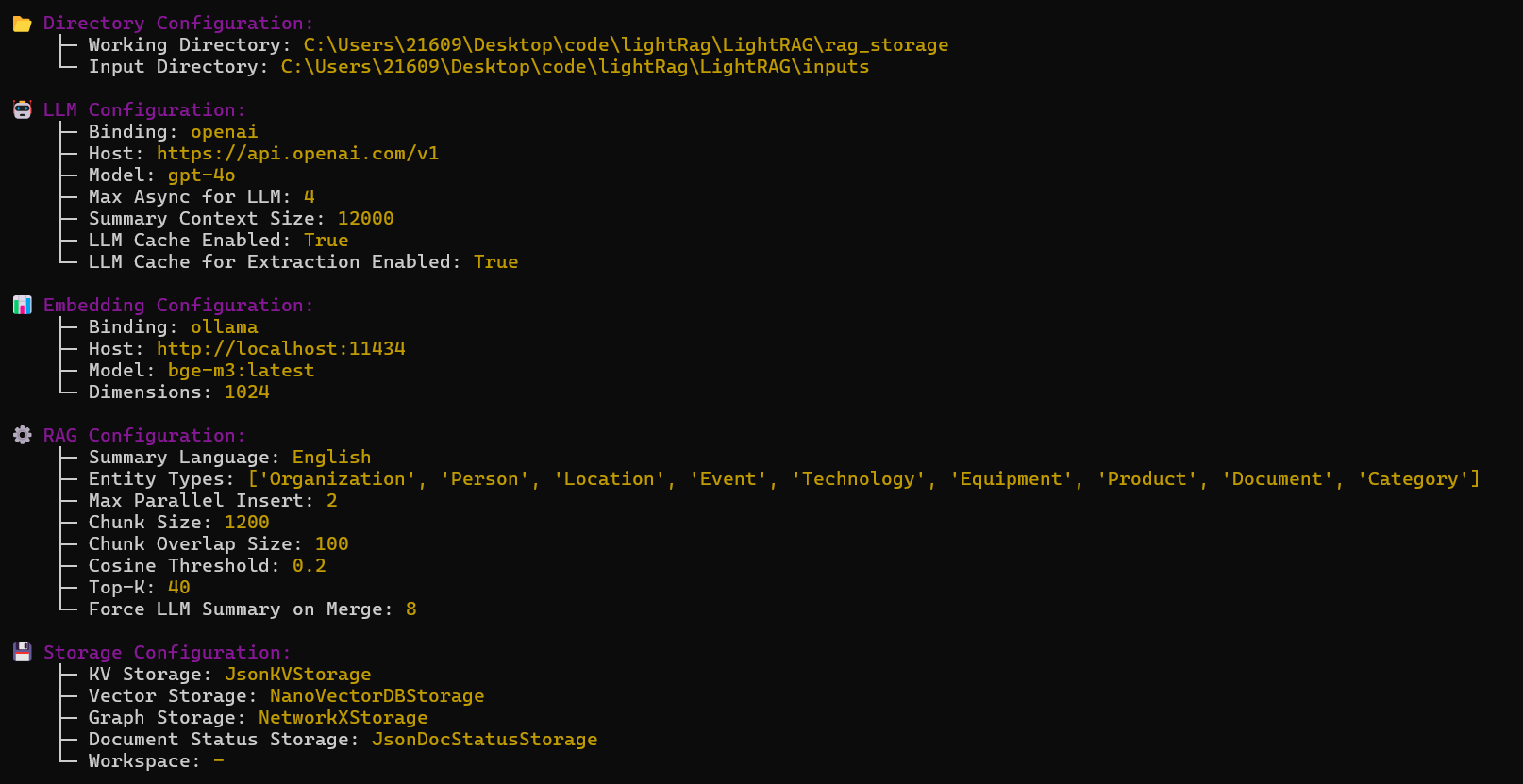
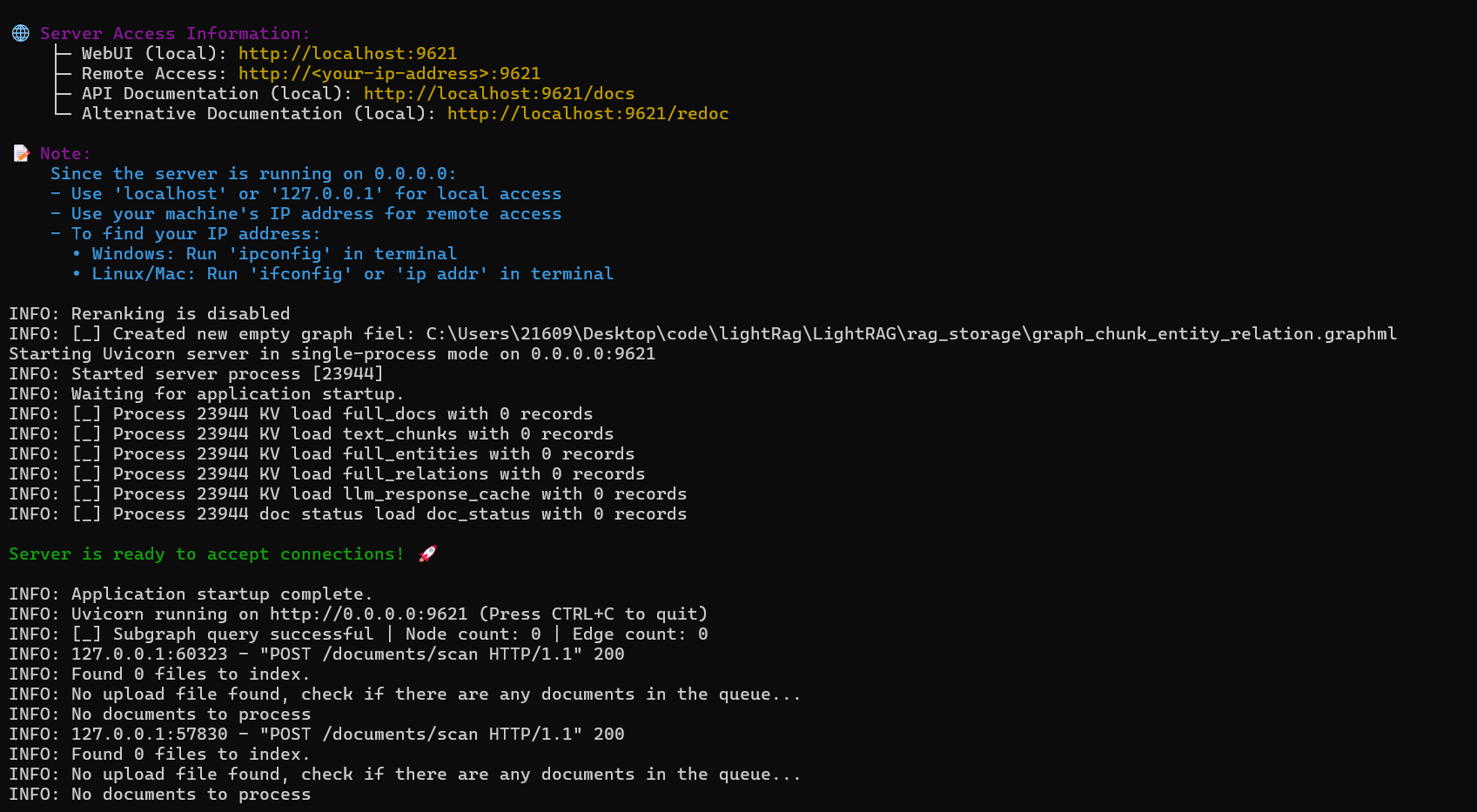
访问:http://localhost:9621/webui/
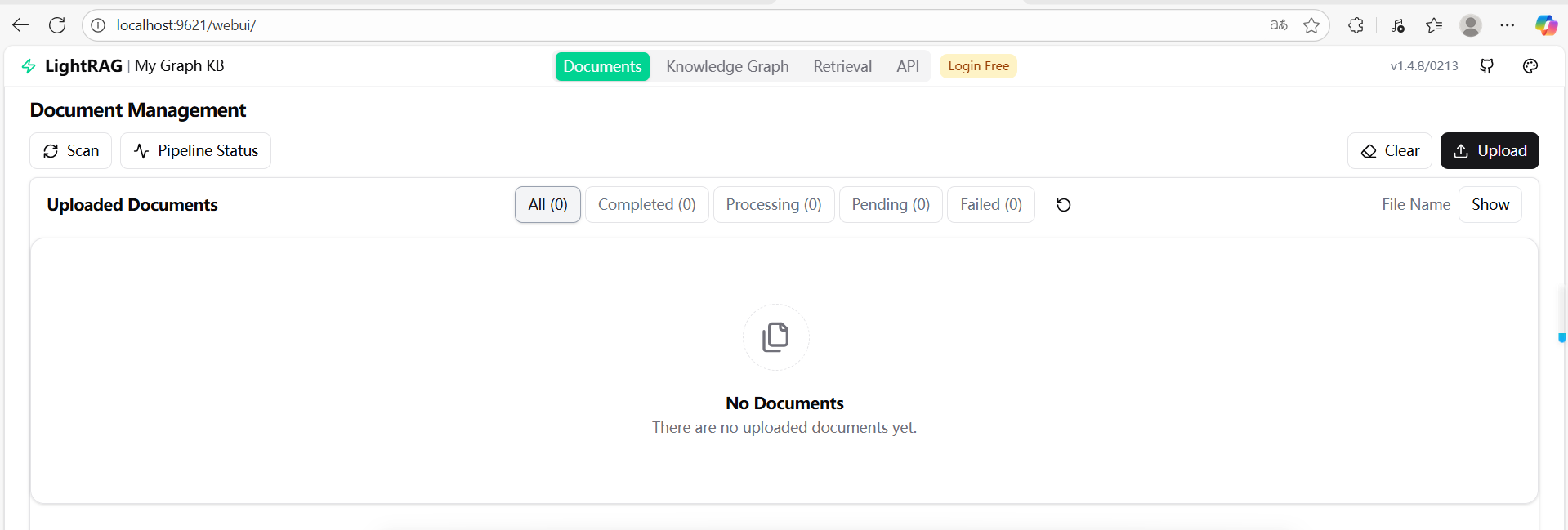
测试一下项目里的一个example
新建文本C:\Users\21609\Desktop\code\lightRag\LightRAG\examples\book.txt
The Guardian of the Forgotten Library
In the heart of Eldermere, where cobblestone streets wound like ancient vines, stood a library no one remembered. Its doors were locked with rusted chains, and its windows were fogged with decades of dust. The townsfolk whispered that it held not books, but dreams—those that people had abandoned.
One rainy autumn, a curious girl named Elara discovered a loose brick behind the ivy. She pressed it, and with a groan, the library swallowed her whole.
Inside, floating lanterns lit shelves of books with shifting titles: The Lullaby You Stopped Singing, The Apology You Never Wrote. A spectral librarian, clad in robes of stardust, handed her a blank book. "Write your forgotten dream," he murmured.
Elara hesitated, then scribbled: To fly without wings. Instantly, the library trembled. The books around her fluttered like doves, and through the ceiling, she glimpsed a sky of swirling stories—some joyful, some sorrowful, all yearning to be remembered.
As dawn broke, Elara returned home, clutching a single silver feather. The villagers still spoke of the forgotten library, but now, when children played near its ivy-covered walls, they listened closely... and sometimes, they heard whispers of wings.
新建C:\Users\21609\Desktop\code\lightRag\LightRAG\examples\hello.py,魔改自\examples\lightrag_ollama_demo.py
import asyncio
import os
import inspect
import logging
import logging.config
from lightrag import LightRAG, QueryParam
from lightrag.llm.ollama import ollama_model_complete, ollama_embed
from lightrag.utils import EmbeddingFunc, logger, set_verbose_debug
from lightrag.kg.shared_storage import initialize_pipeline_statusfrom dotenv import load_dotenvload_dotenv(dotenv_path=".env", override=False)WORKING_DIR = "./dickens"def configure_logging():"""Configure logging for the application"""# Reset any existing handlers to ensure clean configurationfor logger_name in ["uvicorn", "uvicorn.access", "uvicorn.error", "lightrag"]:logger_instance = logging.getLogger(logger_name)logger_instance.handlers = []logger_instance.filters = []# Get log directory path from environment variable or use current directorylog_dir = os.getenv("LOG_DIR", os.getcwd())log_file_path = os.path.abspath(os.path.join(log_dir, "lightrag_ollama_demo.log"))print(f"\nLightRAG compatible demo log file: {log_file_path}\n")os.makedirs(os.path.dirname(log_file_path), exist_ok=True)# Get log file max size and backup count from environment variableslog_max_bytes = int(os.getenv("LOG_MAX_BYTES", 10485760)) # Default 10MBlog_backup_count = int(os.getenv("LOG_BACKUP_COUNT", 5)) # Default 5 backupslogging.config.dictConfig({"version": 1,"disable_existing_loggers": False,"formatters": {"default": {"format": "%(levelname)s: %(message)s",},"detailed": {"format": "%(asctime)s - %(name)s - %(levelname)s - %(message)s",},},"handlers": {"console": {"formatter": "default","class": "logging.StreamHandler","stream": "ext://sys.stderr",},"file": {"formatter": "detailed","class": "logging.handlers.RotatingFileHandler","filename": log_file_path,"maxBytes": log_max_bytes,"backupCount": log_backup_count,"encoding": "utf-8",},},"loggers": {"lightrag": {"handlers": ["console", "file"],"level": "DEBUG","propagate": False,},},})# Set the logger level to INFOlogger.setLevel(logging.DEBUG)# Enable verbose debug if neededset_verbose_debug(os.getenv("VERBOSE_DEBUG", "false").lower() == "true")if not os.path.exists(WORKING_DIR):os.mkdir(WORKING_DIR)async def initialize_rag():rag = LightRAG(working_dir=WORKING_DIR,llm_model_func=ollama_model_complete,llm_model_name= "gemma2:2b",llm_model_kwargs={"host": "http://localhost:11434","options": {"num_ctx": 32768},"timeout": int("600"),},embedding_func=EmbeddingFunc(embedding_dim=768,max_token_size=8192,func=lambda texts: ollama_embed(texts,embed_model="nomic-embed-text",host="http://localhost:11434",),),)await rag.initialize_storages()await initialize_pipeline_status()return ragasync def print_stream(stream):async for chunk in stream:print(chunk, end="", flush=True)async def main():try:# Clear old data filesfiles_to_delete = ["graph_chunk_entity_relation.graphml","kv_store_doc_status.json","kv_store_full_docs.json","kv_store_text_chunks.json","vdb_chunks.json","vdb_entities.json","vdb_relationships.json",]for file in files_to_delete:file_path = os.path.join(WORKING_DIR, file)if os.path.exists(file_path):os.remove(file_path)print(f"Deleting old file:: {file_path}")# Initialize RAG instancerag = await initialize_rag()# Test embedding functiontest_text = ["This is a test string for embedding."]embedding = await rag.embedding_func(test_text)embedding_dim = embedding.shape[1]print("\n=======================")print("Test embedding function")print("========================")print(f"Test dict: {test_text}")print(f"Detected embedding dimension: {embedding_dim}\n\n")with open("C:\\Users\\21609\\Desktop\\code\\lightRag\\LightRAG\\examples\\book.txt", "r", encoding="utf-8") as f:await rag.ainsert(f.read())# Perform naive searchprint("\n=====================")print("Query mode: naive")print("=====================")resp = await rag.aquery("What are the top themes in this story?",param=QueryParam(mode="naive", stream=True),)if inspect.isasyncgen(resp):await print_stream(resp)else:print(resp)# Perform local searchprint("\n=====================")print("Query mode: local")print("=====================")resp = await rag.aquery("What are the top themes in this story?",param=QueryParam(mode="local", stream=True),)if inspect.isasyncgen(resp):await print_stream(resp)else:print(resp)# Perform global searchprint("\n=====================")print("Query mode: global")print("=====================")resp = await rag.aquery("What are the top themes in this story?",param=QueryParam(mode="global", stream=True),)if inspect.isasyncgen(resp):await print_stream(resp)else:print(resp)# Perform hybrid searchprint("\n=====================")print("Query mode: hybrid")print("=====================")resp = await rag.aquery("What are the top themes in this story?",param=QueryParam(mode="hybrid", stream=True),)if inspect.isasyncgen(resp):await print_stream(resp)else:print(resp)except Exception as e:print(f"An error occurred: {e}")finally:if rag:await rag.llm_response_cache.index_done_callback()await rag.finalize_storages()if __name__ == "__main__":# Configure logging before running the main functionconfigure_logging()asyncio.run(main())print("\nDone!")功能:
- 删除旧数据:删除 WORKING_DIR 中的旧数据文件(如 graph_chunk_entity_relation.graphml 等),确保从干净状态开始。
- 初始化 RAG:调用 initialize_rag 创建 RAG 实例。
- 测试嵌入函数:对测试文本生成嵌入向量,验证嵌入维度(应为 768)。
- 插入文本:读取 book.txt 文件内容并插入 RAG 系统,用于后续查询。
- 执行查询:
- 使用四种模式(naive、local、global、hybrid)查询“故事的顶级主题是什么?”。
- 每种模式通过 rag.aquery 调用,启用流式输出(stream=True)。
- 如果响应是异步生成器(asyncgen),调用 print_stream 流式打印;否则直接打印。
- 错误处理:捕获并打印异常。
- 清理:在 finally 块中关闭缓存和存储。
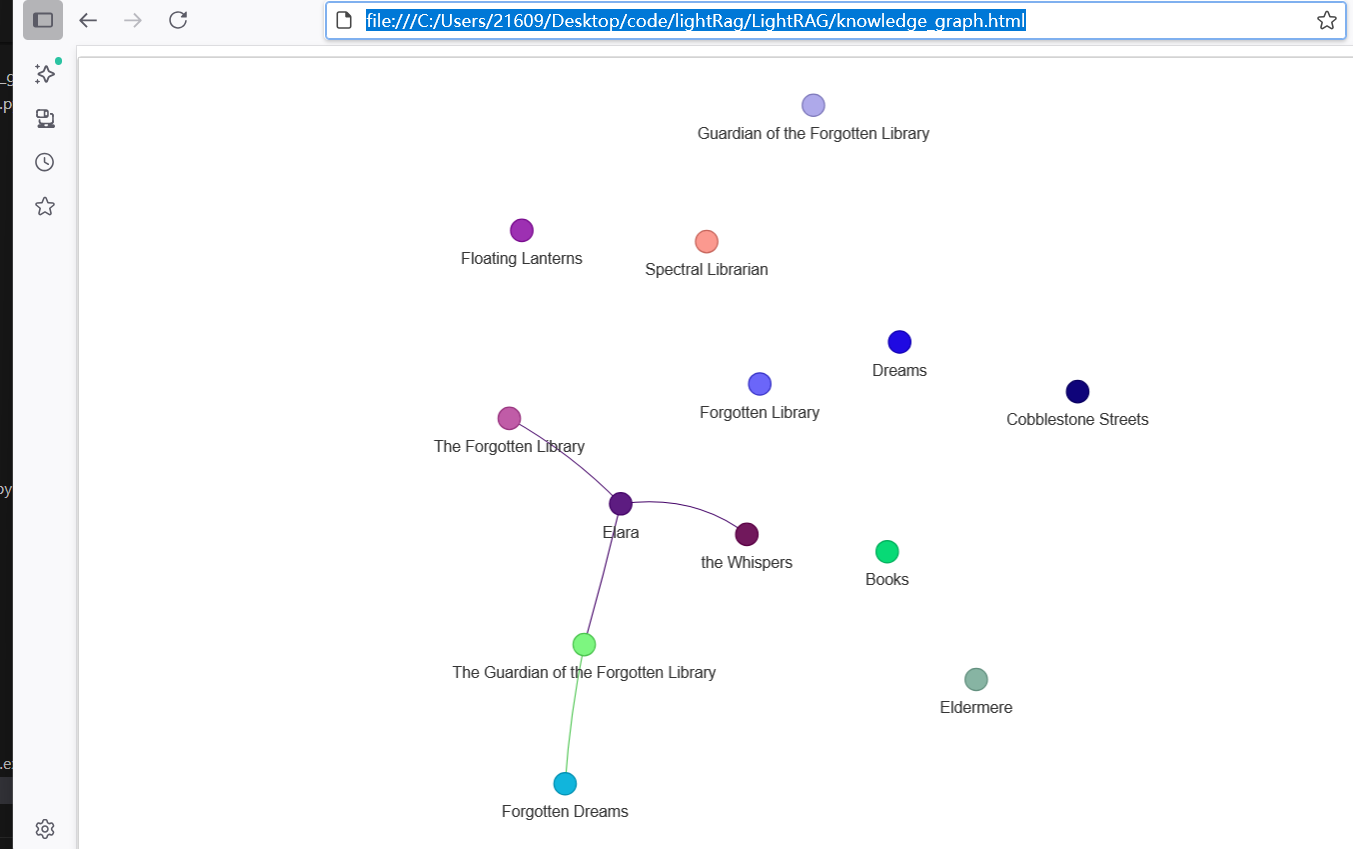
然后运行 examples\graph_visual_with_html.py 读取一个 GraphML 格式的知识图谱文件(./dickens/graph_chunk_entity_relation.graphml),使用 networkx 和 pyvis 库将其可视化为一个交互式的网络图,并保存为 HTML 文件(knowledge_graph.html)。
访问:file:///C:/Users/21609/Desktop/code/lightRag/LightRAG/knowledge_graph.html
参考
ppt
香港科技大学/LightRAG:「LightRAG:简单快速的检索增强生成」
Local LightRAG: A GraphRAG Alternative but Fully Local with Ollama