杂记-日常未整理
随记
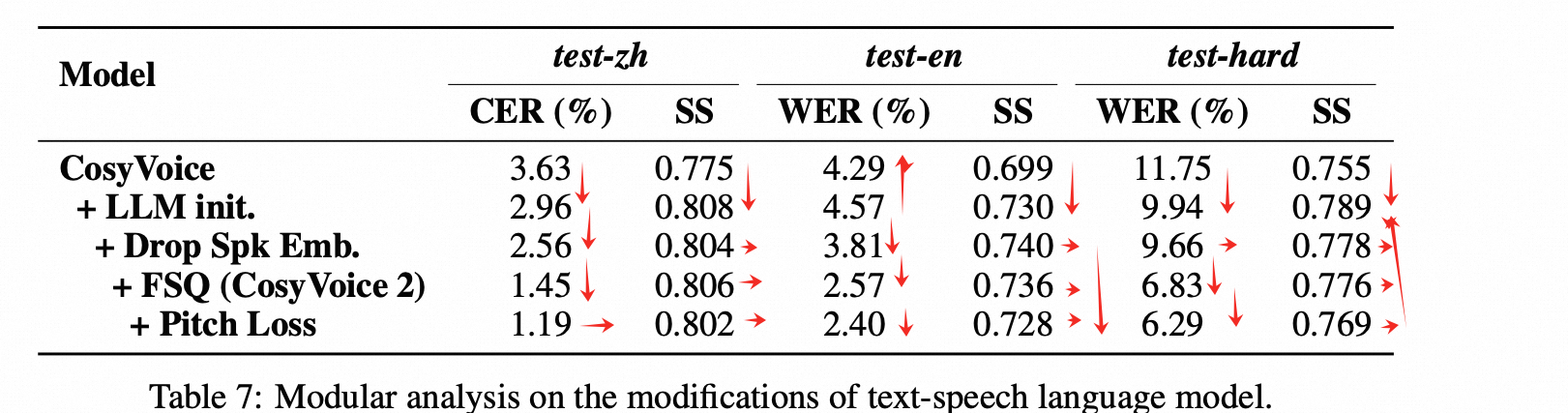
cosy 需要使用预训练文本模型吗
1. cosy2 论文里面说,使用的LM 时预训练的文本qwen 模型,并且做了对比实验,效果更好。但是在实际应用中,有的会把预训练模型取消,改为随机初始化,使用自己的模型从头训练。这种方法在大部分的测试中,客观指标/主观指标不会有很大的差距。
好处:
- 更加灵活,可以根据自己的需要调整模型参数量的大小、层数、宽度,调整模型结构等等。
- 方便上线的需求,参数量大小等等;方便做实验,更小的模型更快迭代结果。
- 实际使用中,如果场景受限,可以和使用预训练模型取得接近的表现。(比如知识TTS, 训练数据比较干净,没有复杂的断句需求等)
坏处:
- 预训练的模型能更好的理解文本token, 韵律更好
- 预训练模型有助于在理解文本串的基础上,减少部分cornercase, 比如一些极端的断句等。
- 后续训练 instruct TTS时,使用预训练模型,能更好的理解 需求,有利于训练和推理效果。
diffusion 与 flowmatching 有区别吗
是一样的: Diffusion Meets Flow Matching
AR / NAR / FM 模型有哪些:
- AR:
- 离散特征:
- Vall-e(token-token-wav),
- cosyvoice, CosyVoice , BASE-TTS , FireRed() TTS , and Seed-TTS(token-token-mel-wav)
- 连续特征:MELLE, ARDiT, DiTAR, FELLE, SALAD
- 离散特征:
- FM : F5-TTS, E2-TTS, E3-TTS, NaturalSpeech1/2/3
一种减少 duffision 步数的方法: 蒸馏
3. Distribution Matching Distillation(分布匹配蒸馏)
定义:
这是一种知识蒸馏(Knowledge Distillation) 方法,旨在让一个小模型(学生)模仿一个大模型(教师)的输出分布。
核心思想:
- 传统蒸馏通常最小化学生与教师输出 logits 之间的 KL 散度。
- Distribution Matching Distillation 更广义:目标是让学生生成的数据分布 pS(x)pS(x) 接近教师模型的分布 pT(x)pT(x)。
- 这可以通过多种方式进行,例如:
- 直接在潜在空间或像素空间匹配样本分布。
- 使用对抗训练、MMD(最大均值差异)、flow matching 等手段实现分布对齐。
与 Flow Matching 的结合:
- 最近的工作(如 DFM: Distribution-Following Matching for Diffusion Distillation)提出使用 Flow Matching 技术来进行高效的扩散模型蒸馏。
- 思路:训练一个快速的学生扩散模型,使其反向过程的向量场匹配教师模型的向量场。
- 即:使用 Flow Matching 目标来对齐学生和教师的生成动态。
📌 举例:
假设教师是一个需要 1000 步采样的扩散模型,学生希望只用 5–10 步完成采样。通过 Distribution Matching Distillation,可以让学生的每一步“跳跃”模拟教师多步的效果,从而保持生成质量。
三者的联系总结
| 概念 | 核心目标 | 方法 | 关系 |
|---|---|---|---|
| Flow Matching | 学习一个向量场,连接先验与数据分布 | 回归预定义路径上的理想向量场 | 基础方法论 |
| Diffusion Flow Matching | 将扩散模型的反向过程建模为向量场 | 使用 flow matching 学习扩散反向 ODE/SDE 的 drift | 是 Flow Matching 在扩散模型中的应用 |
| Distribution Matching Distillation | 让学生模型匹配教师模型的输出分布 | 多种方式,包括 KL、MMD、GAN、flow matching 等 | 可以利用 Flow Matching 作为匹配工具 |
flow
mean-flow
https://zhuanlan.zhihu.com/p/1909361718452257189 : Mean Flows:流模型一步到位,何恺明论文进一步理论优化流模型收敛效率
int-mean-flow
TTS
- MOSS-TTSD(tokenizer 创新,对话)
- Llasa: Scaling Train/Inference-Time forTTS (单层码本+LLM): https://arxiv.org/pdf/2502.04128
- YourTTS :
- 基于 VITS, 加入languageID, speakerENCODER, 实现多语种,多语言。
- 提出了 SCL loss: 就是【生成出来的语音】和【原始语音】过一个speaker encoder出来的speaker embedding的余弦相似度。根据论文的说法,这个speaker encoder应该是pre-train出来的,在计算SCL损失的过程中,encoder的参数应该是固定不动的。
- https://github.com/coqui-ai/tts
- MegaTTS 系列, 1/2/3
- https://arxiv.org/abs/2306.03509
- https://arxiv.org/html/2502.18924v4
TTS 指标对比
https://zhuanlan.zhihu.com/p/1949607668424630686
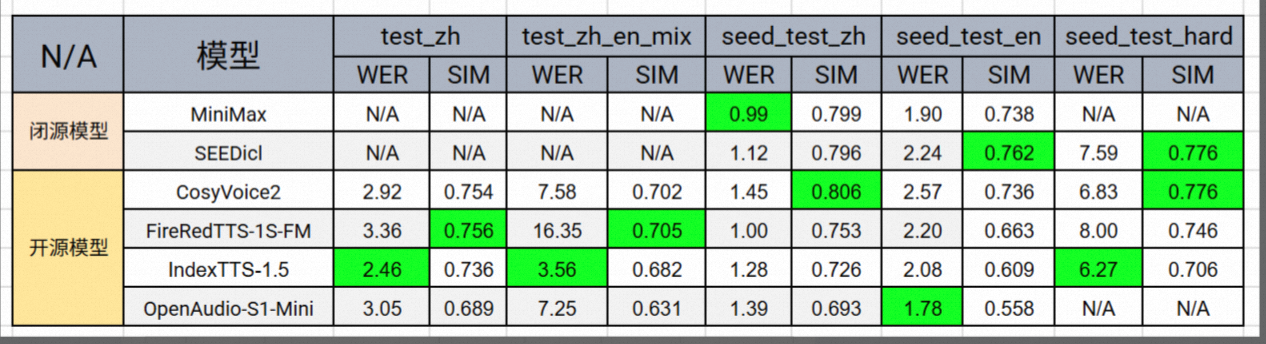
WER 指标
- IndexTTS-1.5 在各个测试集上表现最为均衡。但在音色相似度上稍有不足这可能与其未集成 Flow Matching 模型有关。
- 综合 WER 与相似度(SIM) 两方面,CosyVoice2 无疑是整体表现最突出的模型。除在 test_zh_en_mix 测试集上略显劣势外,其余测试集的性能与最佳结果差距都不大。
- 聆听合成音频,OpenAudio-S1-Mini 的音质尤为出色。它不仅提供了高达 44.1kHz 的采样率,而且其采用的 10 层音频 tokenizer 也为音质提升提供了坚实的支撑。

- 大部分模型的技术结构采用的是 “LLM + FLOW” 组合,这似乎已经成为当前市面上的主流配置。
- 文本 Tokenizer 方面,中文几乎都基于汉字建模,英文则普遍使用 subword;其中 IndexTTS 额外引入了 拼音建模单元,在实际业务中具有较强的实用价值。
- 音频 Tokenizer 的帧率普遍在 25Hz 左右,至于是 semantic token 还是 acoustic token,整体上保持了相对的平衡。
- 高采样率音频数据的获取成本较高,同时对训练算力要求更大。因此,开源模型普遍采用 24kHz 采样率,而闭源模型则更倾向于提供更高的采样率。
- 在训练数据规模方面,目前 OpenAudio-S1-Mini 遥遥领先,达到 200+ 万小时,显著超过其他开源模型。
CLEAR : 连续特征合成
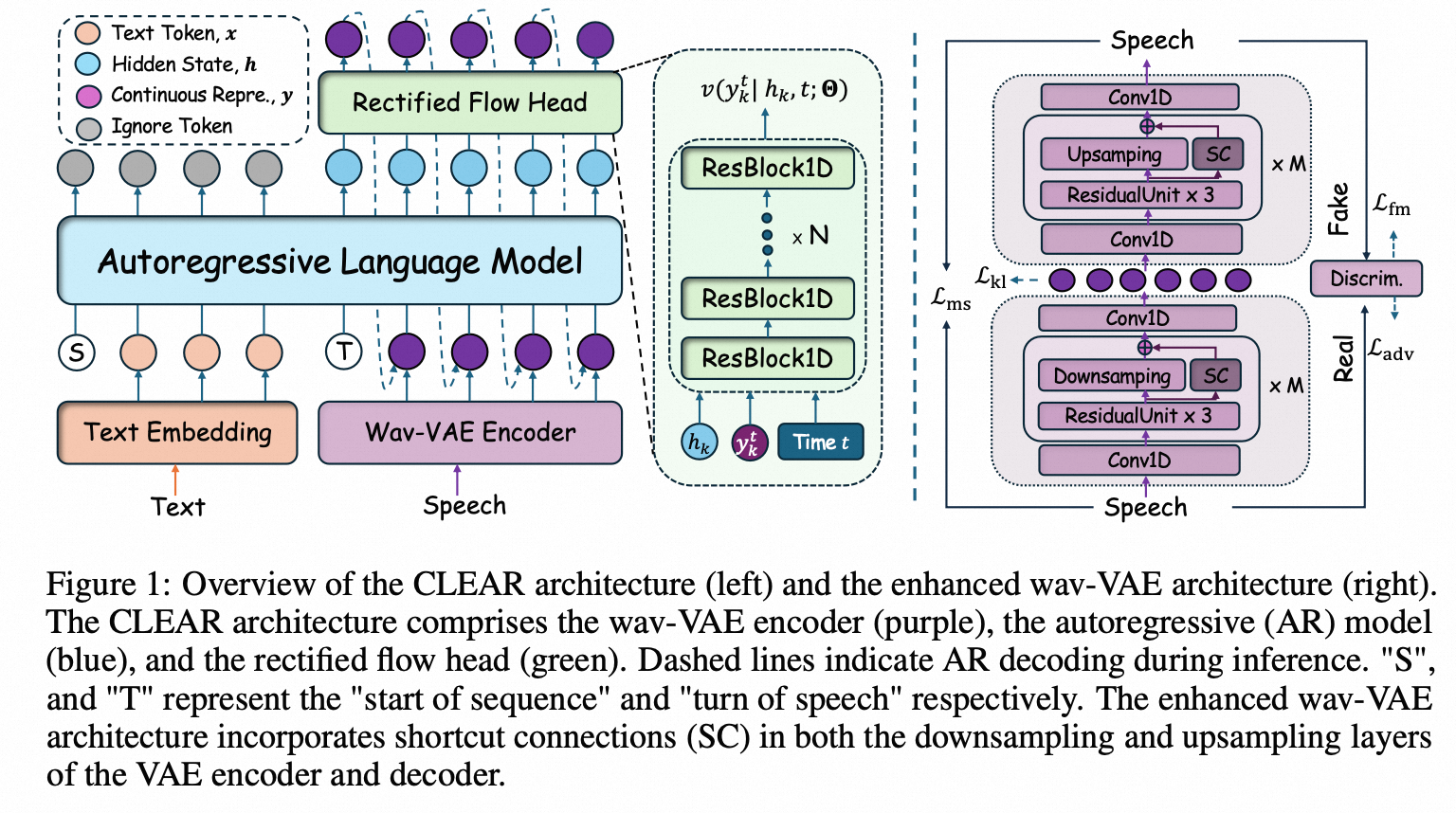 Continuous Latent Autoregressive Modeling for High-quality and Low-latency Speech Synthesis, 20250826, 港中文&华为。
Continuous Latent Autoregressive Modeling for High-quality and Low-latency Speech Synthesis, 20250826, 港中文&华为。
背景依据:
- 认为离散token 是有损的, 重建质量低。
- 码本训练困难。
- 需要较长的离散token序列才能获取背后的隐藏信息。
- 长序列会带来高延迟。
- 较低的重建质量,需要两阶段模型对更多细节进行重建,弥补信息损失。但是两阶段会带来误差累计等问题。
特点:
- 统一架构,联合训练
- 使用连续特征(带快捷连接的增强型变分自动编码器),
- 使用 MLP-based flow head(rectified-flow-head: 一步生成 https://zhuanlan.zhihu.com/p/15125790338)。
- 结果是 低延迟(RTF=0.29, 首包=96ms)
FNH-TTS: VITS + MOE
FNH-TTS: A Fast, Natural, and Human-Like Speech Synthesis System with advanced prosodic modeling based on Mixture of Experts, https://arxiv.org/pdf/2508.12001

语音编辑
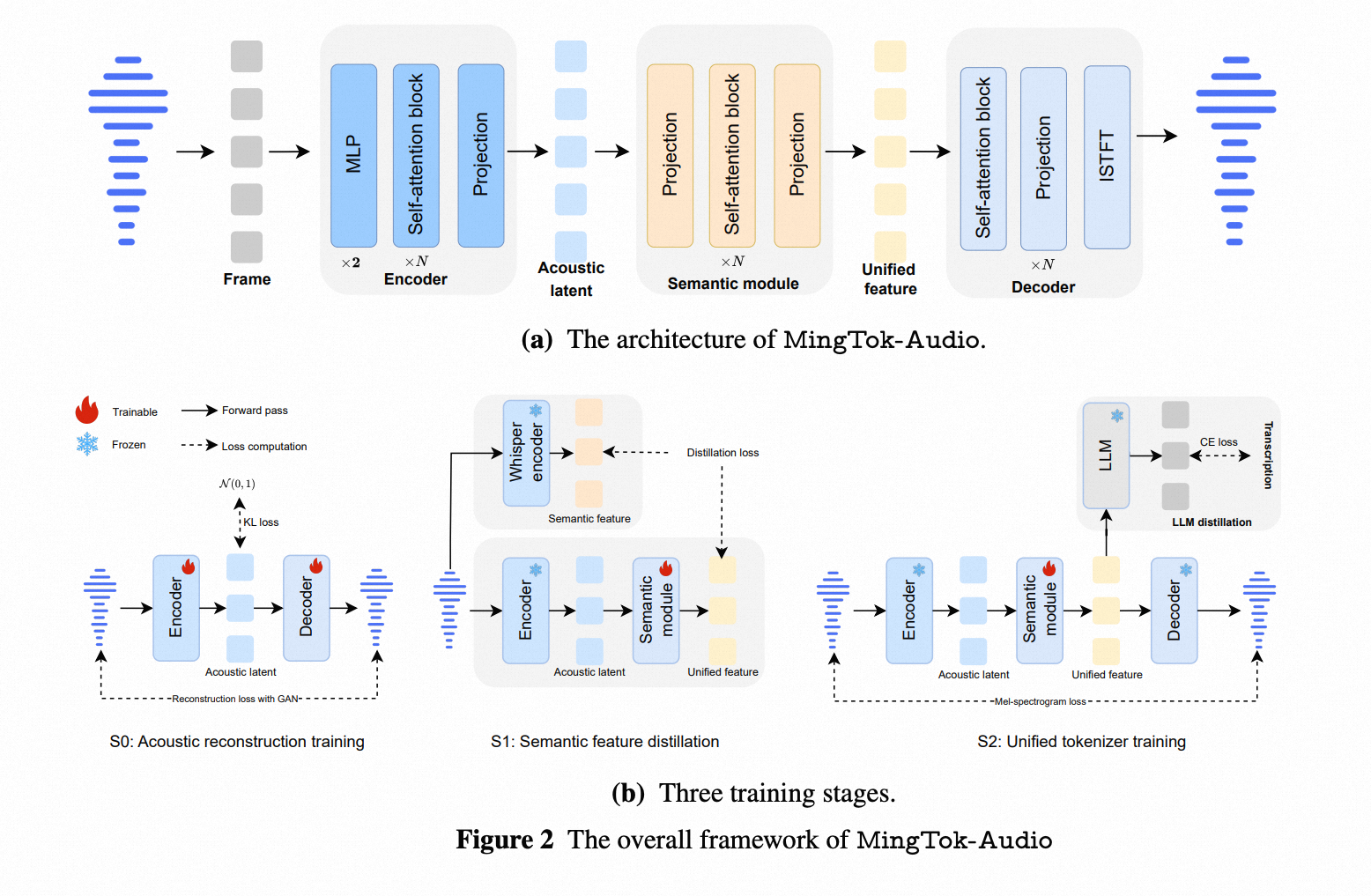
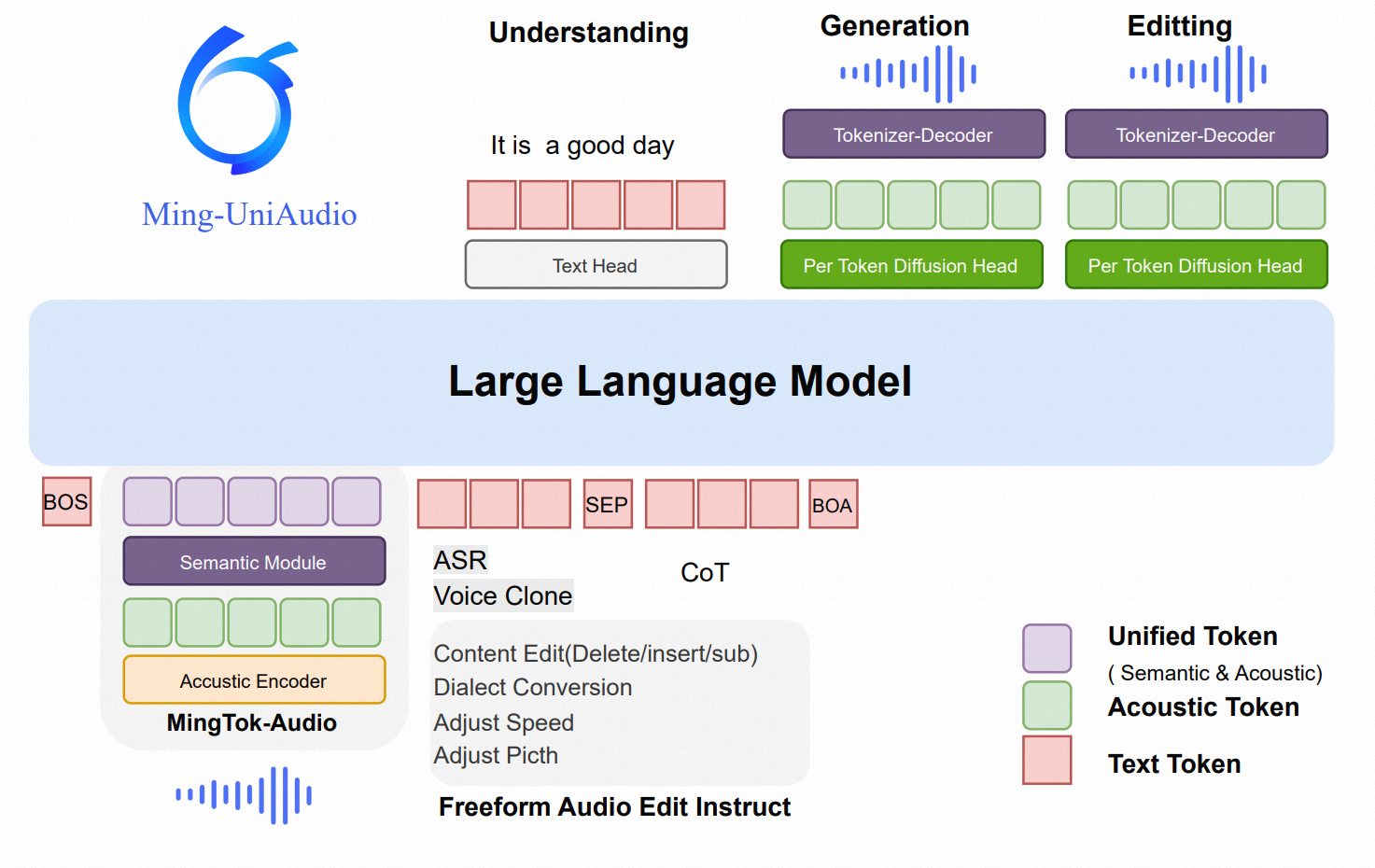
理解+生成+编辑:MingAudio-蚂蚁
https://arxiv.org/pdf/2511.05516
Project Homepage: Link
Code: https://github.com/inclusionAI/Ming-UniAudio
Model: https://huggingface.co/inclusionAI
speechLM/Omini
Qwen2.5-Omini - qwen
[2503.20215] Qwen2.5-Omni Technical Report
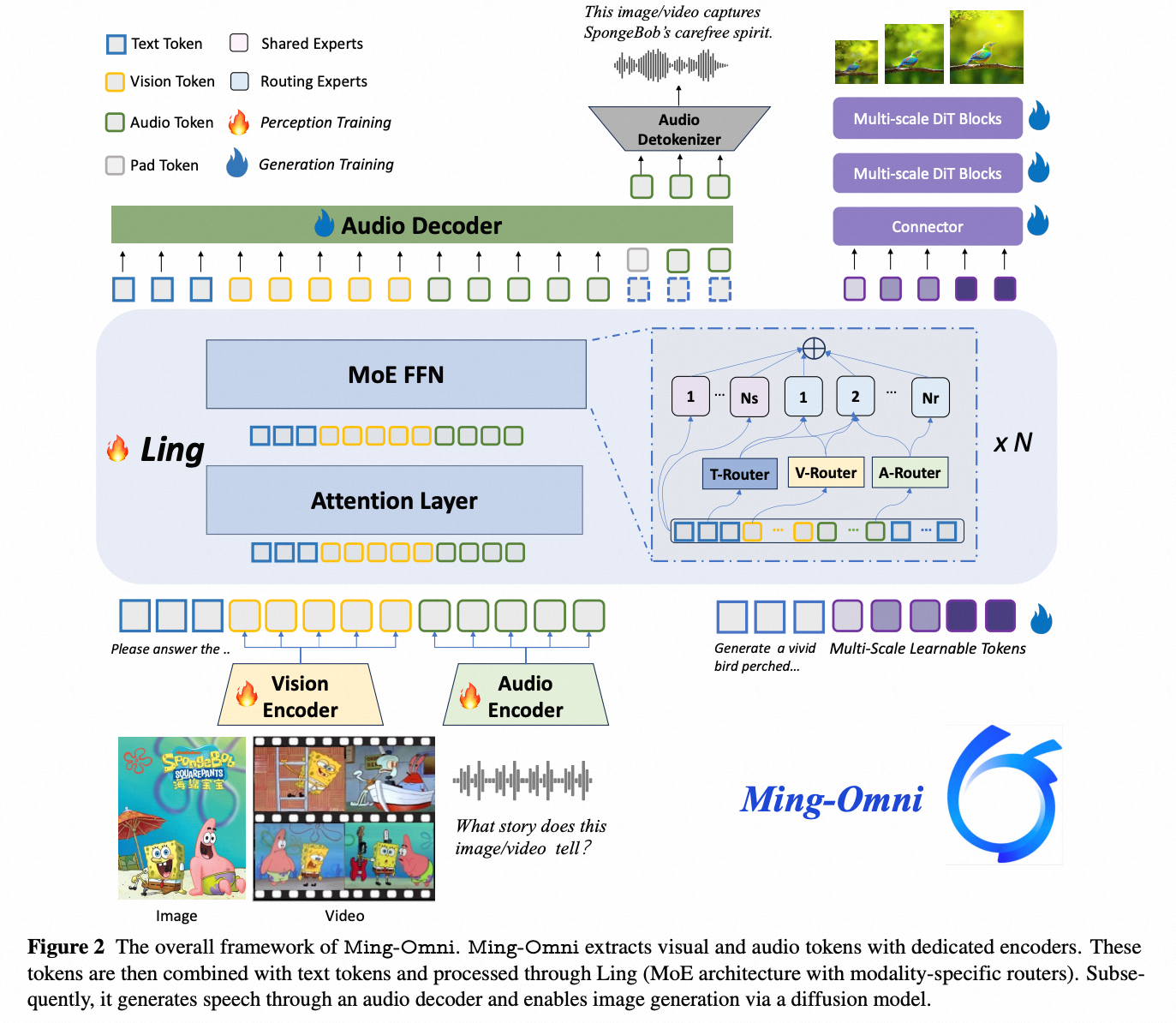
Ming-Omni - ant-group
https://arxiv.org/pdf/2506.09344
2025.03.21
LLM for ASR/SU
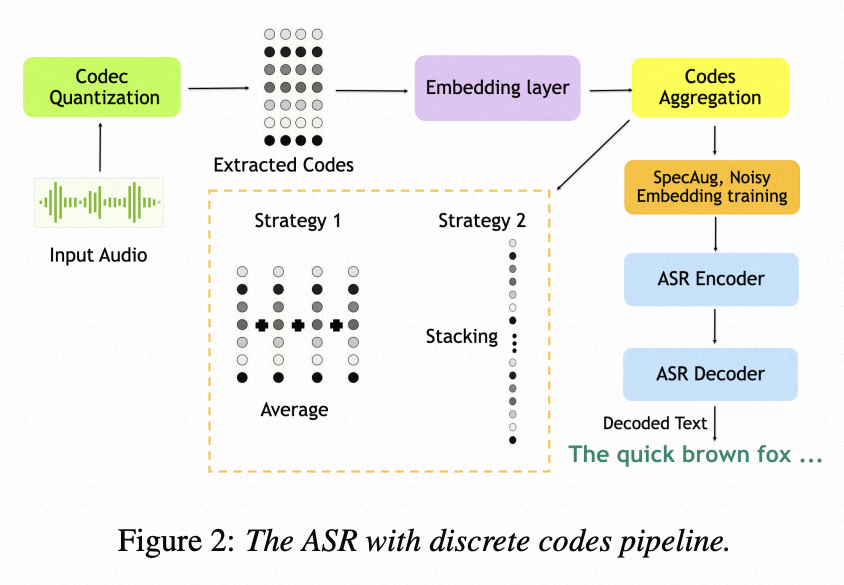
Codec-ASR (离散+LLM):
2024. Nvidia, https://arxiv.org/pdf/2407.03495
https://github.com/NVIDIA/NeMo
- 时域NAC(TD-NAC)结合残差向量量化(RVQ) 在ASR任务中表现最佳。
- 码本初始化(Codebook Initialization) 和 合理的代码聚合策略(如平均聚合) 极大提升了模型收敛性与识别准确率。
- 引入 谱图增强(SpecAug) 和 噪声嵌入训练(Noisy Embedding Training) 后,在干净语音上提升性能, 在嘈杂环境下显著增强鲁棒性
对如何使用离散语音code(discrete codes)来构建ASR系统进行了全面分析。深入研究整个流程的设计选择。
- 研究了不同语音编解码器(codec)的训练方法,包括:
- 量化方案(quantization schemes):比如VQ-VAE中的向量量化、残差量化等,影响离散码的质量;(用VQ, 还是RVQ)
- 使用 FSQ 的NAC系统在所有 ASR 测试集上表现均弱于RVQ;
- FSQ 具有计算轻量、延迟低等优点,在 TTS 中表现良好;
- ASR 这类需要高语义保真和噪声鲁棒性的任务中,RVQ 显著更优
- 输入特征类型:是直接在时域波形(time-domain)上编码(比如Encodec),还是在频谱特征(spectral features,如梅尔频谱)上编码(比如使用HiFi-GA)。
- TD-NAC 在 ASR 上表现优于 Mel-NAC。(尽管其比特率(6.4 kbps)高于 Mel-NAC(5 kbps))
- 在文本转语音(TTS)任务中,Mel-NAC 表现更优
- 量化方案(quantization schemes):比如VQ-VAE中的向量量化、残差量化等,影响离散码的质量;(用VQ, 还是RVQ)
- 这些设计会影响最终生成的离散语音表示的质量和信息保留程度。
- Embedding 初始化选择:随机初始化;码本训练结果初始化。
- 将嵌入层权重用预训练NAC的码本进行初始化, 而非随机初始化:在所有测试集上实现 超过10%的绝对WER降低
- 码本聚合策略:堆叠(维度增加);平均。
- RVQ 的 平均聚合(Averaging)显著优于堆叠(Stacking)
- 在所有测试集上均取得更低的词错误率(WER)
- 表明简单平均能更有效地融合多码本信息,避免高维输入带来的建模负担或冗余。
- RVQ码本“协同编码”,适合平均;FSQ码本“分工编码”,适合保留独立性(堆叠)。
- 探究传统增强方法(时间mask, 评率mask, 时间扭曲)在离散表示训练框架下的有效性。
- 在含噪的
'other'测试集上带来 超过6%的绝对WER改善
- 在含噪的
- 增强模型对输入扰动(在潜入向量中加入噪声)的鲁棒性,防止过拟合。
- 进一步提升噪声鲁棒性,尤其在复杂声学条件下表现更优。
尽管平均法在RVQ系统中表现更好,但在使用 FSQ量化器 的NAC系统中,本文仍选择 堆叠(stack)作为默认聚合方式,原因如下:
FSQ的码本语义不同:
- FSQ将潜向量的不同维度分组并独立量化(如每组用不同级别[8,5,5,5]);
- 每个码本代表原始信号的不同特征子空间;
- 因此各码本具有互补性,直接平均会丢失结构信息。
RVQ的码本是残差关系:
- 后续码本编码前一级的残差;
- 所有码本共同逼近同一向量;
- 更适合整体表示 → 平均更合理。
LLM 结构:FastConformer Transducer large architecture [34] with 114 M parameters.
UniVoice : 连续特征+LLM for TTS&ASR
https://arxiv.org/pdf/2510.04593
在两个任务中均采用连续表征:在ASR中使用自回归建模(AR),以利用其在序列预测中的优势;在TTS中则采用流匹配(FM),以发挥其高质量语音生成的能力。
为解决AR所需的因果掩码与FM非自回归特性之间的固有冲突,作者设计了双注意力掩码机制,可在识别时使用因果掩码、合成时切换为双向注意力。
DualSpeech : 离散特征+LLM for understand&TTS
https://arxiv.org/pdf/2508.08961
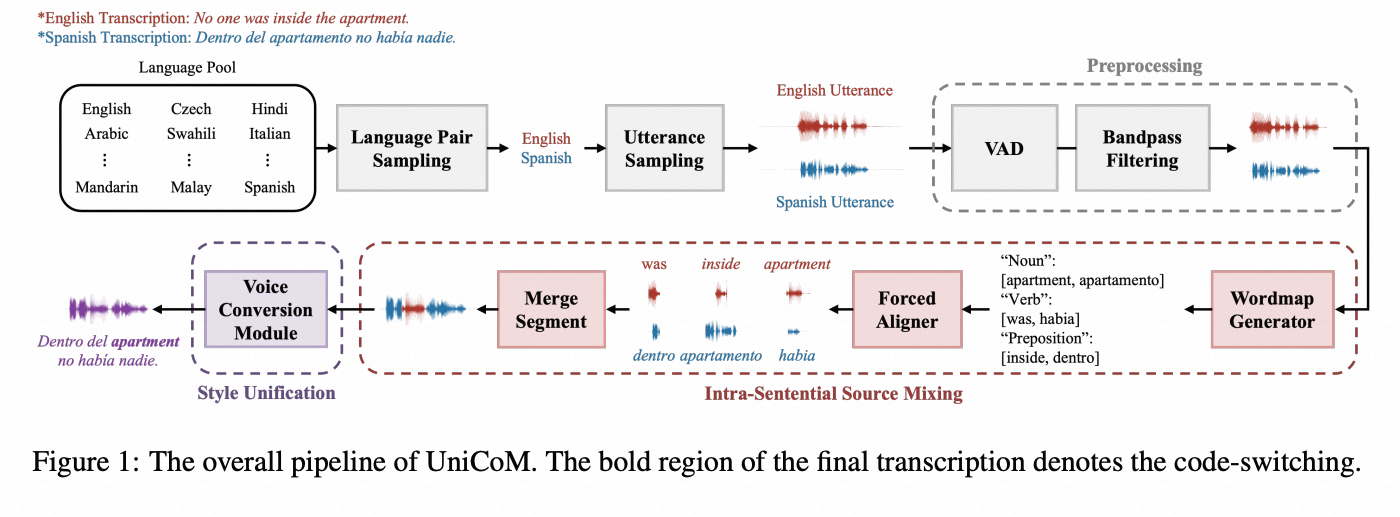
code-switch
CS数据生成器:
* UniCoM: A Universal Code-Switching Speech Generator https://arxiv.org/pdf/2508.15244
Large audio language model
Qwen2-audio, audio flamingo, salmonn,
long-context TTS
- Long-Context Speech Synthesis with Context-Aware Memory https://arxiv.org/pdf/2508.14713

Instruct/Description-based TTS
PromptTTS, SpeechCraft, ParaspeechCaps, TextrolSpeech
MOE_TTS
Enhancing Out-of-Domain Text Understanding for Description-based TTS via Mixture-of-Experts https://arxiv.org/pdf/2508.11326
参考多模态大模型的方法,整合MOE 技术到TTS, FFN 使用两个模块,一个编码文本,一个编码音频,并且使用的是预训练的文本大模型, 这个大模型会被冻结参数。


多模态
多模态+MOE
Vlmo: Unified visionlanguage pre-training with mixture-of-modality-experts
Evev2: Improved baselines for encoder-free visionlanguage models
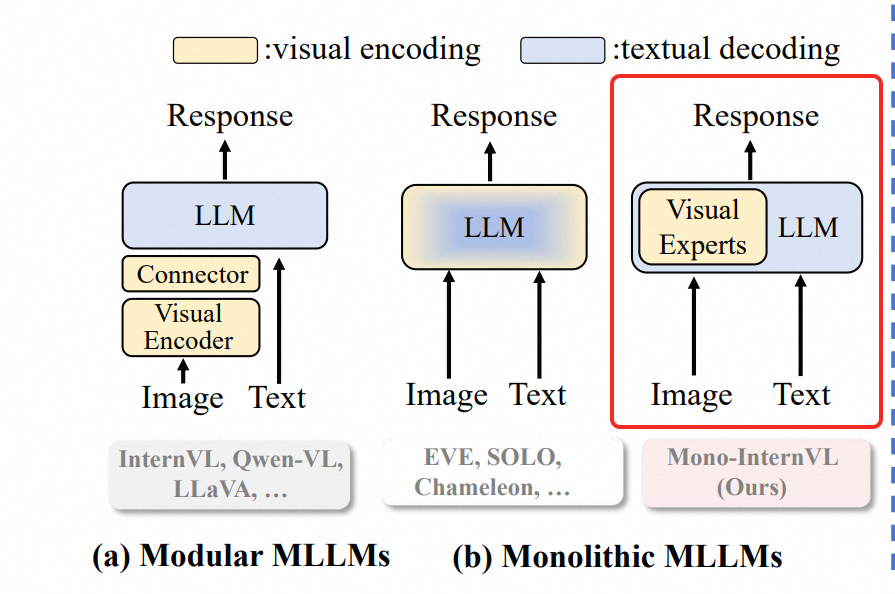
Mono-internvl: Pushing the boundaries of monolithic multimodal large language models with endogenous visual pre-training https://arxiv.org/pdf/2410.08202
Mono-internvl


Audio model with Reasoning:
Mellow, Audio-CoT, Audio-Reasoner, R1-AQA, SARI, Omini-R1, Audio-Thinker
* Audio Flamingo Sound-CoT Technical Report: Improving Chain-of-Thought Reasoning in Sound Understanding , Nvidia, 20250815, https://arxiv.org/pdf/2508.11818
codec
笔记链接: https://mp.csdn.net/mp_blog/creation/success/153876970
深度学习的可解释性
语音中的重音是可结构话吗
How Does a Deep Neural Network Look at Lexical Stress? https://arxiv.org/pdf/2508.07229
本文探讨神经网络在语音处理中的可解释性问题,尤其关注英语双音节词重音位置的预测。研究自动构建了包含朗读和自发语音的英语双音节词数据集,训练了多种卷积神经网络(CNN)架构,通过词的声谱图预测重音位置,测试集准确率达到92%。利用Layerwise Relevance Propagation(LRP)可视化分析发现,模型预测时主要关注重读和非重读音节的信息,尤其是重读元音的声谱特征(如一、二共振峰),同时对词的整体信息也有关注。进一步的特征相关性分析显示,模型最依赖于重读元音的一、二共振峰,对基音和三共振峰也有一定敏感性。综上,深度学习能够从自然数据中获取分布式的重音线索,丰富和拓展了传统基于受控材料的语音研究。
一句话总结:
本文通过深度学习和可解释性分析揭示了神经网络能从真实自然语音中学习到细粒度的重音线索,推动了对稀疏可控实验之外语音现象的理解。
语音模型是否会把“韵律重音”有结构的编到其表示空间中。
Emphasis Sensitivity in Speech Representations https://arxiv.org/pdf/2508.11566
本研究探讨了现代语音模型是否会把“韵律重音”(即说话时的强调)作为一种有结构的变换方式编到其表示空间中。
本研究设计了一种创新的残差分析方法,把不用参数的几何指标(parameter-free geometric metrics)和一些轻量级的测试任务结合起来,结果发现:S3L等自监督语音模型(S3L models),以及经过ASR(自动语音识别)定制的模型(ASR-tuned models),都对重音有明显的敏感性。
残差向量(也就是强调和中性词向量之差。残差表示(R,也就是强调词与中性词的表示之差)只用较少的主成分(即低维表示),就能非常好地重建出时长变化)有以下特点:
- 有明确的方向性(不同残差在空间上方向接近),
- 维度很低(信息集中,冗余少),
- 并且能够很好地预测语音时长变化(说明残差捕捉到重音的信息)。
针对ASR任务微调模型后,这种特性更加明显:
- 重音的编码变得更一致(更有规律了),
- 和词本身的信息(词汇身份)区分得更开,彼此“纠缠”更少。
这些发现说明了:
- 重音信息不仅能被模型“读出来”,
- 而且它在语音特征空间里本身就是有结构、有规律、可分离的。
这给“考虑韵律信息的语音建模、语音分析和语音控制”等方向提供了新思路和科研基础。
speaker Emb 可解释性
https://arxiv.org/pdf/2510.16489
- 本研究通过主成分分析(PCA)探索了说话人嵌入空间的内在结构,发现不同训练方法得到的嵌入在主要维度上具有一致性,揭示了嵌入空间存在可解释的潜在结构。
- 研究识别出9个具有可解释性的声学维度,其预测能力接近前7个主成分,可用于语音转换中的目标说话人控制。
- PC1主要反映性别相关特征(如基频和声道长度),呈双峰分布,而后续主成分多为单峰,暗示男女共用部分声学空间,但嵌入仍隐含性别信息。
- 年龄未在嵌入空间中有效体现,令人意外。
- 当前用于描述声音质量(如粗哑、气息声)的参数(PPQ、GNE)不够理想,有待改进。此外,Globe数据集的性别标签可能存在标注错误。相关语音转换应用已在文献[18]中展示。
探讨了说话人嵌入空间各维度的特性。结果表明,经过不同方式训练得到的嵌入向量,在经过主成分分析(PCA)后具有相似的主要维度(至少前几个维度如此),说明说话人嵌入空间存在某种潜在结构,具备可解释的潜力。
某些主成分在男女群体中表现不同,说明嵌入向量隐式地编码了性别信息。
年龄在嵌入空间中并未得到良好体现,也不是主成分维度的有效预测变量。这一点令人意外,因为年龄作为说话人的固定特征,理论上应有助于说话人验证任务。
空间音频:spatial audio
ASAudio: A Survey of Advanced Spatial Audio Research https://arxiv.org/pdf/2508.10924\
语音评价指标
自动化MOS评测
Towards Frame-level Quality Predictions of Synthetic Speech
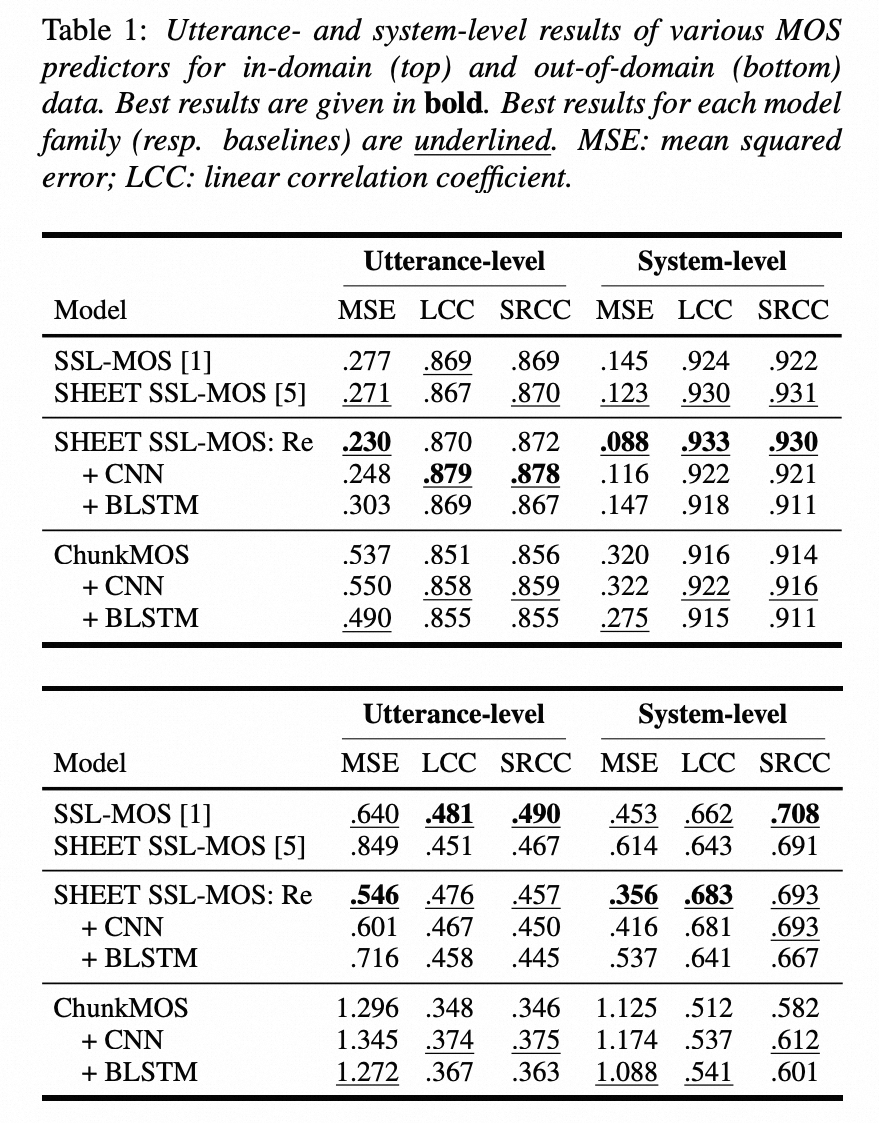
预训练模型特征预测MOS 的分层分析
https://arxiv.org/pdf/2509.04830 Layer-wise Analysis for Quality of Multilingual Synthesized Speech
主要发现:
- 早期层与自然度相关: 通过计算合成语音和自然语音分布之间的W2距离,并将其与平均主观意见分数(MOS)进行关联,研究发现预训练模型的早期层与听众对整体自然度的意见高度相关。这意味着,无需额外的MOS特定训练,早期层的特征可以作为预测MOS的替代。
- 非神经TTS系统的例外: 对于非神经TTS系统,此方法需谨慎使用,因为这类数据集表现出不同的趋势,通常是后期层能产生更好的相关性。
- 采样率限制: 该方法可能不适用于评估采样率高于16 kHz的合成语音,因为所选的预训练模型仅支持该采样率。在法语数据中,降采样导致听众意见中的显著信息丢失。
局限性:
- 匹配参考数据的重要性与可获得性: 研究发现使用匹配的参考数据效果更好,但其主要局限性在于匹配的参考数据并非总是可用,例如在语言或风格迁移的TTS应用中,可能不存在特定语言、目标说话人或说话风格的真实数据。
- 语言覆盖: 研究中使用的数据集语言都包含在三个大型语音模型的预训练数据中。
未来工作:
- 选择最佳层: 未来重要的工作是探索如何在实际预测场景中,有原则地选择最佳层(或层组合),以便利用本研究获得的知识开发无监督的多语言质量预测器。
- 低资源语言: 调查模型对完全未见的低资源语言的层级预测能力。
简而言之,这段话探讨了预训练多语言语音模型在无监督语音质量评估中的应用,揭示了早期层与自然度的高相关性,但也指出了对非神经TTS系统和高采样率数据的局限性。未来工作将聚焦于优化最佳层选择以及扩展到低资源语言的评估。
python
错误码
异常类 说明 常见触发场景
Exception 所有内置非系统退出异常的基类 通常用于 except Exception: 捕获一般异常
ValueError 值不合适(类型正确但值非法) int("abc"), list.remove(x) 找不到元素
TypeError 类型错误 len(5), "hello" + 5
KeyError 字典中找不到键 d['nonexistent']
IndexError 序列索引越界 lst[100]
AttributeError 对象没有该属性 obj.nonexist_attr
NameError 名称未定义 使用未定义变量 x
FileNotFoundError 文件未找到 open("missing.txt")
OSError / IOError 操作系统相关错误(如文件、权限) 文件读写、网络、磁盘错误(Python 3 中 IOError 是 OSError 的别名)
ImportError 导入模块失败 import nonexistent_module
ModuleNotFoundError 模块未找到(ImportError 的子类) import unknown_package
NotImplementedError 尚未实现的功能 在抽象方法中抛出
RuntimeError 一般运行时错误 不属于其他类别的错误
StopIteration 迭代器结束(内部使用) 手动控制迭代器时
KeyboardInterrupt 用户按下 Ctrl+C 程序中断
SystemExit sys.exit() 被调用 程序正常退出
ZeroDivisionError 除以零 1 / 0
AssertionError assert 条件失败 assert x > 0 失败
LookupError 查找错误的基类 KeyError, IndexError 的父类
UnicodeError Unicode 编码/解码错误 b'\xff'.decode('utf-8')