【医学影像 AI】用于糖尿病视网膜病变检测的固有可解释的稀疏 BagNet模型
更多内容请关注【医学影像 AI by youcans@Xidian 专栏】
【医学影像 AI】用于糖尿病视网膜病变筛查的固有可解释的稀疏 BagNet模型
- 0. 论文简介
- 0.1 基本信息
- 0.2 论文速览
- 0.3 摘要
- 0.4 作者总结
- 1. 引言
- 2. 方法
- 2.1 数据集描述与数据预处理
- 2.2 用于糖尿病视网膜病变检测的固有可解释的深度学习模型
- 2.3 基准模型与事后可解释性
- 2.4 基于 AI 的决策支持临床用户研究
- 2.5 评估标准与统计分析
- 3. 结果
- 4. 讨论
- 5. GitHub 项目使用
- 6. 参考文献
0. 论文简介
0.1 基本信息
2025 年 德国图宾根大学 Djoumessi 等在 PLOS Digit. Health 发表论文 “用固有可解释的人工智能模型提高糖尿病视网膜病变筛查的速度和准确性(An inherently interpretable AI model improves screening speed and accuracy for early diabetic retinopathy)”。
本文针对当前糖尿病视网膜病变(DR)早期筛查中主流 AI 模型多为黑箱、事后解释方法不可靠且难以辅助临床决策的问题,开发并验证了一种固有可解释的深度学习模型(稀疏 BagNet),该模型通过在网络架构中明确建模 DR 局部证据生成可解释的类别证据图,在保持良好筛查性能的同时,为医生提供可信的决策依据,提升早期 DR 筛查的临床协作效率,推动医疗 AI 的透明化与临床落地。
论文下载: plos
项目地址: github
引用格式:
Djoumessi K, Huang Z, Kühlewein L, Rickmann A, Simon N, Koch LM, et al. (2025) An inherently interpretable AI model improves screening speed and accuracy for early diabetic retinopathy. PLOS Digit Health 4(5): e0000831. https://doi.org/10.1371/journal.pdig.0000831
0.2 论文速览
一种固有可解释的深度学习模型(稀疏 BagNet) ,用于早期糖尿病视网膜病变(DR)筛查。该模型在 34,350 张高质量眼底图像上训练,内部测试集准确率达 .906 [.900–.913] 、AUC 为 .904 [.894–.913] ,在10 个外部数据集上表现与标准黑箱模型(ResNet-50)相当;其生成的类别证据图能精准定位微动脉瘤、出血等临床相关病变,定位精度达 .960 [.941–.976] ,远超传统事后解释方法;通过包含 6 名眼科医生的回顾性读者研究发现,该模型辅助(含解释)可使早期 DR 诊断准确率提升17.5% ,筛查时间缩短约25% ,有效改善人 - AI 协作效率,为临床可信 AI 决策支持提供新方案。
解决的问题
传统 AI 解释缺陷:事后解释方法(如梯度热力图)生成的解释不反映模型真实决策过程,易受虚假关联干扰,无法有效融入临床决策流程。
研究核心目标
开发并验证一种固有可解释的深度学习模型,明确建模 DR 局部证据,在保证筛查性能的同时,提供人类可理解的决策依据,最终提升早期 DR(尤其是轻度非增殖性 DR,NPDR)筛查的速度与准确性。
核心模型:稀疏 BagNet(固有可解释架构)
架构原理:
- 图像拆分:将输入眼底图隐式拆分为33×33 像素的重叠 patches(步长 s=8,对应模型有效感受野);
- 局部证据计算:所有 patches 并行输入模型骨干网络,生成反映局部 DR 存在证据的热力图;
- 证据聚合:对热力图进行平均池化,输入 softmax 函数得到 DR 存在概率;
- 稀疏性约束:引入L₁惩罚项,鼓励生成稀疏的类别证据图,突出关键病变区域。
研究结论
- 固有可解释模型(稀疏 BagNet)可在保持SOTA 筛查性能的同时,提供可信的决策解释;
- 模型生成的类别证据图能精准定位临床关键病变,辅助医生提升早期 DR 诊断准确率、缩短筛查时间,有效改善人 - AI 协作;
- 模型在多地区外部数据集上泛化性良好,为医疗 AI 的临床落地提供可行方案。

0.3 摘要
糖尿病视网膜病变(DR)是糖尿病的常见并发症,影响着全球数百万人。基于眼底图像对该疾病进行筛查,是现代人工智能在医学领域首批成功应用案例之一。然而,当前最先进的筛查系统通常采用 “黑箱模型” 来制定转诊决策,在人机交互及临床决策支持过程中需依赖事后解释方法。
为此,本研究开发并评估了一种固有可解释的深度学习模型,该模型将 DR 的局部证据明确建模为网络架构的一部分,用于早期 DR 筛查的临床决策支持。
研究团队在一个公开数据集的 34350 张高质量眼底图像上对该网络进行训练,并在 10 个外部数据集上验证其性能,同时将该固有可解释模型与应用于标准深度神经网络(DNN)架构的事后解释技术进行对比。为实现对比分析,研究还获取了眼科医生对 65 张图像的详细病变标注,以验证模型生成的类别证据图是否能突出临床相关信息。此外,通过回顾性阅片研究测试了该模型的临床实用性 —— 在研究中,比较了无 AI 支持、有 AI 支持(含解释)及有 AI 支持(无解释)三种情况下的 DR 筛查效果。
结果显示,该固有可解释深度学习模型在内部测试集上的准确率为 0.906 [0.900–0.913](95% 置信区间),曲线下面积(AUC)为 0.904 [0.894–0.913],在外部数据集上也表现出与标准 DNN 相近的性能;从模型中直接提取的高证据区域包含微动脉瘤、出血等临床相关病变,精度高达 0.906 [0.900–0.913],优于应用于标准 DNN 的事后解释技术;该模型通过突出图像中的高证据区域提供决策支持,不仅提高了复杂决策场景下的筛查准确率,还加快了筛查速度。
上述结果表明,固有可解释深度学习模型在实现最先进性能的同时,能够提供临床决策支持,进而改善人机协作效果。
0.4 作者总结
在众多医疗应用中,用于支持临床决策的人工智能系统均采用黑箱深度学习模型,糖尿病视网膜病变(一种可致盲的糖尿病并发症)的 AI 筛查系统亦属此类。由于临床医生和患者无法验证 AI 系统的决策依据,这类方法的临床应用受到阻碍。有时,研究人员会采用事后解释方法生成热力图,以期解释 AI 系统的决策,但这些方法存在明显问题 —— 生成的解释无法反映模型实际的决策过程,且易受虚假相关性干扰。
在本文中,为构建可信赖的人工智能系统以支持糖尿病视网膜病变筛查的临床决策,研究团队迈出了关键一步:提出一种固有可解释的深度学习模型,该模型能为其决策提供人类可理解的解释。
该模型通过计算明确的证据图,将深度学习的优势与逻辑回归等简单模型的可解释性相结合,而此证据图正是模型决策的基础,从而克服了事后解释技术的局限性。
研究对该模型在改善糖尿病视网膜病变筛查方面的临床潜力进行了验证,结果表明:在临床分级过程中突出高疾病证据区域,不仅显著缩短了分级时间,还提高了对复杂临界病例的分级准确率。
1. 引言
糖尿病视网膜病变(DR)筛查是人工智能(AI)在医学领域首批成功应用案例之一 [1],即便在临床人员不足的地区,该技术也有望实现快速、经济高效的疾病筛查。目前,已有多款 AI 系统获得监管机构批准 [2,3],这些系统可有效区分无需专科诊疗的患者与存在视力威胁的 DR 患者,对提高筛查依从性具有潜在作用 [4]。
然而,当前最先进的模型仍采用黑箱深度学习方法制定转诊决策,仅能为临床医生提供 “转诊进一步检查” 或 “不转诊” 的二元化建议,信息十分有限。此外,现有系统的性能仍需一定程度的人工阅片验证 [3],而 AI 系统决策的有效解释可为人工验证提供指导。同时,若临床医生能够理解算法建议背后的逻辑依据,将更有利于该技术的临床落地 [5-7]。
通常情况下,研究人员会采用基于梯度的事后解释方法生成热力图,以解释 AI 系统的决策 [8-10]。但此类解释并不可靠:生成的热力图无法反映模型实际的决策过程,且易受虚假相关性干扰 [11]。因此,其结果难以有效融入临床决策流程 [7,12]。
针对这一问题,本研究通过回顾性阅片研究,验证了一种用于早期 DR 筛查临床决策支持的固有可解释深度学习架构。该研究采用名为 “稀疏 BagNet”(sparse BagNets)的深度学习架构 [13,14],将 DR 存在的局部证据明确建模为网络架构的一部分(图 1B)。目前,多数研究聚焦于中度非增殖性 DR(NPDR)或更晚期病变的筛查 [1],但事实上,即便对于轻度非增殖性 DR(NPDR),也建议进行密切监测并严格控制高血糖 [15,16]。
研究团队认为,在这一具有挑战性的诊断任务中,基于 AI 的解释与决策支持所发挥的作用将最为显著。研究团队在大型公开数据集上对该模型进行训练,结果显示,其在多个数据集的轻度 DR 检测中均表现出高特异性与足够的敏感性。重要的是,研究证实,模型生成的类别证据图能以高精度突出微动脉瘤、出血等临床相关病变,有助于验证 AI 系统的决策合理性。最后,研究表明,该系统可有效指导临床决策:轻度 DR 的诊断准确率提升了 17.5%,整体筛查时间缩短了约 25%。
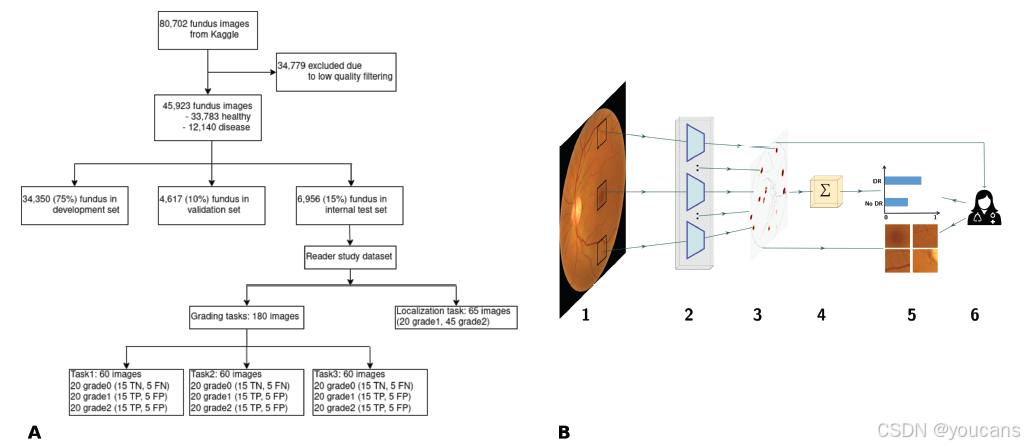
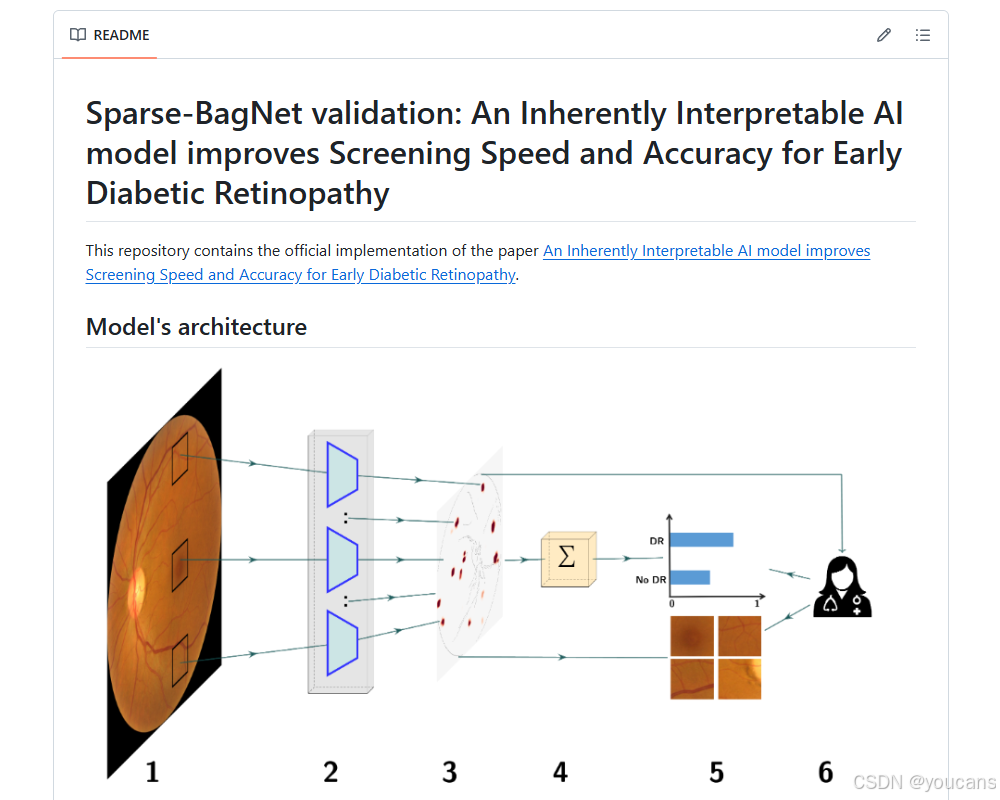
图 1. 本研究中开发数据的概述及所评估的固有可解释深度学习框架。
(A)用于构建模型的开发数据集的总结,以及在回顾性读者研究中使用的数据。
(B)稀疏 BagNet 架构。
- 作为初步步骤,视网膜眼底图像被隐式地分割成许多大小为 的重叠小块。
- 所有小块都被输入到模型的主干中,主干并行处理它们。
- BagNet 主干生成一个热图,描绘各个小块的局部疾病证据。
- 热图的值被平均,并用作最终分类的 logits。
-
- logits 被输入到 softmax 函数中,该函数提供输出的概率分布,然后根据热图可以请求并查看可疑区域的小块,以便临床医生理解分类结果。
2. 方法
2.1 数据集描述与数据预处理
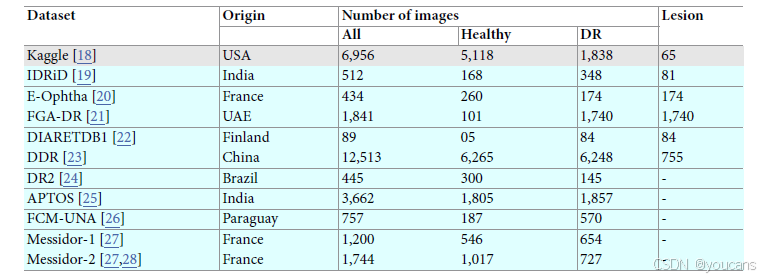
本研究采用 11 个公开可用的视网膜图像数据集(包含来自不同来源的彩色眼底图像),开发并评估用于早期糖尿病视网膜病变(DR)检测的固有可解释深度学习模型(表 1)。
所有数据集的眼底图像均依据《国际临床糖尿病视网膜病变分级标准》[17] 分配了参考等级,该标准根据 DR 严重程度将病变分为 0 级(无 DR)、1 级(轻度非增殖性 DR,NPDR)、2 级(中度非增殖性 DR,NPDR)、3 级(重度非增殖性 DR,NPDR)和 4 级(增殖性 DR)。
由于本研究旨在开发用于早期 DR 筛查的 AI 系统,因此将病变等级合并为两类进行分析,即 {0 级}(无 DR)与 {1、2、3、4 级}(有 DR)。1 级 DR(轻度非增殖性 DR)在多数情况下无明显症状,即便对于经验丰富的眼科医生而言,其检测也具有一定挑战性。由于所有眼底图像数据集均已完全匿名处理,因此本研究的该部分实验无需获得伦理委员会的批准。
表 1. 用于评估模型的内部和外部验证数据集的总结。
“Origin”指数据收集的国家。“Lesion”指数据集中有病变注释的图像数量。
Kaggle 数据集(第一行,灰色阴影)是用于评估模型的内部数据集,而其他数据集用于外部验证,以评估训练模型的泛化能力。
开发数据集
本研究用于开发固有可解释深度学习模型的数据集,来源于 Kaggle 糖尿病视网膜病变挑战赛(Kaggle Diabetic Retinopathy challenge)[18]。该数据集初始包含 44,351 名受试者的记录,涵盖 88,702 张双眼视网膜眼底图像(图 1A)。该数据集最初由美国加利福尼亚州的糖尿病筛查项目机构 EyePacs 公司(EyePacs Inc.)提供。另有一个同样来自 EyePacs 公司的可比数据集,包含种族信息,其中约 70% 的图像来自拉丁裔患者 [29]。
研究团队采用 10 个 EfficientNets 模型组成的集成模型 [30](该模型在 DeepDRiD 数据集 [31] 上训练而成),对眼底图像进行自动质量筛选。该质量筛选模型的准确率达到 87.5%[32]。经过质量筛选后,研究保留了 28,984 名受试者的 45,923 张图像用于模型训练,其中 73% 的图像属于健康类别,27% 属于糖尿病视网膜病变(DR)类别。
研究将数据集按比例划分为训练集、验证集和测试集(分别占比 75%、10% 和 15%),且确保同一受试者的所有图像均分配至同一数据子集。其中,训练集用于模型拟合,验证集用于模型选择与超参数调优,测试集用于模型内部评估。
为评估可解释稀疏 BagNet 模型(explainable sparse BagNet model)所提供解释的有效性,三名眼科医生(作者 AR、LaK 和 NS,分别拥有 5 年、9 年和 14 年临床经验)使用定制开发的标注浏览界面(图 S1),对从测试集中随机选取的 65 张眼底图像(20 张 1 级 DR 图像、45 张 2 级 DR 图像)进行 DR 相关病变定位标注。该标注界面基于 Python Web 框架 Django(4.2.1 版本)构建,配备安全的 PostgreSQL 数据库(15.3 版本)和 JavaScript 前端,相关资源可在以下链接获取:https://github.com/berenslab/retimgtools/releases/tag/v1.1.0。
标注人员需对眼底图像中可见的病变标注类型,包括 “微动脉瘤(MA)”“出血(HE)”“渗出物(EX)”“软性渗出物(SE)” 或 “其他(Other)”。研究团队将所有标注人员的标注结果整合,形成每张图像的共识标注(表 S1);同时,通过计算标注人员之间标注结果的骰子相似系数(Dice score),评估眼科医生标注结果的一致性,结果表明,全面标注 DR 相关病变是一项具有挑战性的任务(表 S2)。
外部数据集
本研究还从多个来源获取了额外的眼底图像数据集(表 1),用于对模型进行外部评估,以验证其泛化性能。除糖尿病视网膜病变(DR)参考分级外,部分外部数据集 [19-23] 还包含疾病相关病变的像素级标注。研究团队利用这些额外标注,评估了可解释深度学习模型在 DR 相关病变定位方面的性能。
预处理
原始眼底图像的预处理步骤如下:首先采用圆拟合方法 [33] 将图像裁剪为 512×512 像素的正方形;随后,根据训练集的均值和标准差对图像强度进行归一化处理。所有数据集的眼底图像均采用相同参数执行上述预处理流程。
2.2 用于糖尿病视网膜病变检测的固有可解释的深度学习模型
2.2.1 架构
研究团队训练并评估了一种用于早期 DR 检测的固有可解释深度卷积神经网络 —— 稀疏 BagNet(sparse BagNet [13,14])。该模型是一种基于局部特征袋(bag-of-local features)的隐式基于补丁(patch-based)模型,通过聚合可解释热力图中的局部证据来进行预测(图 1B)。其输入为二维眼底图像(图 1B.1),输出为二元预测结果(表示无 DR 或有 DR)及作为概率分数的置信度。
与其他深度学习模型不同,稀疏 BagNet 架构在设计上具有固有可解释性:输入图像会被隐式分割为多个重叠的小补丁(尺寸为 33×33 像素,对应模型的有效感受野大小,步长 s=8;图 1B.1),这些补丁通过并行独立处理(图 1B.2)来计算 DR 存在的局部证据。补丁级别的预测局部证据值会被整合为单一的类别证据图,该证据图对应输入图像的下采样版本(图 1B.3);随后,通过平均池化对类别证据图进行聚合,并将结果输入 softmax 函数(图 1B.4),最终输出 DR 的概率分布(图 1B.5)。关键在于,研究团队对局部证据施加了 L₁惩罚,以促使类别证据图呈现稀疏性。
在推理过程后,该模型不仅能通过最终预测结果支持筛查,还能借助类别证据图(图 1B.3)突出局部小区域对最终预测结果的贡献。为此,研究团队将证据图上采样至完整图像分辨率,并叠加在输入图像上。
与事后基于梯度的方法 [11] 不同,稀疏 BagNet 生成的类别证据图是实际决策过程的透明组成部分,能真实捕捉局部证据。此外,研究团队还通过从 DR 高证据区域提取补丁(图 1B.5),对类别证据图进行补充。
2.2.2 训练流程
研究团队在训练集上通过最小化包含 L₁惩罚的以下损失函数来训练模型:
L((X,θ),y)=CE(f(X,θ),y)+λ∑i,j,c∣Acij∣(1)L((X, \theta), y)=C E(f(X, \theta), y)+\lambda \sum_{i, j, c}\left|A_{c}^{i j}\right| (1)L((X,θ),y)=CE(f(X,θ),y)+λi,j,c∑Acij(1)
式中,X∈RH×W×CX \in \mathbb{R}^{H ×W ×C}X∈RH×W×C 表示输入图像(H、W、C 分别代表高度、宽度和通道数),CE 为交叉熵,y 为参考类别标签,f 为带有参数 θ 的模型,AcA_{c}Ac 表示类别 c 的证据图。证据图的稀疏性由超参数 λ 决定。
模型初始化时采用在 ImageNet 数据集上预训练的权重,随后在 Kaggle DR 数据集上重新训练并优化准确率,共训练 100 个 epoch。训练过程中使用随机梯度下降优化器,初始学习率设为 10⁻³,并采用裁剪余弦学习率调度器(最小学习率设为 10⁻⁴)。参考相关研究 [34],通过随机裁剪、翻转、颜色抖动、平移和旋转等方式进行数据增强。稀疏性超参数 λ 的选择基于验证集的分类准确率(图 S2)。
2.3 基准模型与事后可解释性
为进行对比,研究团队采用上述相同的训练流程,训练了一个用于早期 DR 检测的标准黑箱模型 ResNet-50 [35]。鉴于集成梯度(Integrated Gradients)和引导反向传播(Guided Backpropagation)在识别经临床验证的 DR 病变方面表现出色 [36],研究团队对这两种经典可解释性技术进行了评估。
2.4 基于 AI 的决策支持临床用户研究
- 研究数据集
该用户研究旨在评估固有可解释深度学习模型所提供的解释在临床实践中的实用性。每项分级任务(详见下文)的数据集均包含来自内部测试集的 60 张眼底图像,其中 0 级、1 级、2 级 DR 图像各 20 张。对于每个等级,网络正确分类的图像有 15 张,错误分类的图像有 5 张,这对临床医生而言是一项具有挑战性的筛查任务。因此,用户研究数据集中 DR 图像的占比为 66%,且该深度学习模型的设计准确率为 75%。图像分级仅基于眼底图像和 AI 支持,不提供额外临床数据。
- 研究设计
6 名训练有素的眼科医生(临床经验中位数为 9 年,范围 4-17 年)参与了阅片研究(包括作者 LaK、AR 和 NS)。本研究未进行正式的样本量计算,共包含三项任务:任务 1(记为 “H”)中,参与者需在无 AI 支持的情况下对眼底图像进行分级(图 S3);任务 2(“H+AI”)中,除眼底图像外,还向参与者提供深度学习模型的预测类别及其置信度(图 S4);任务 3(“H+XAI”)中,在任务 2 的基础上,额外向参与者展示模型解释 —— 以类别证据图中高证据区域为中心的至多 12 个边界框,这些边界框的尺寸与有效感受野一致,能呈现对全局类别证据贡献最大的局部图像补丁(图 S5)。
对于这三项分级任务,研究人员要求阅片者将每张眼底图像分为 “无 DR” 和 “有 DR” 两类;即使阅片者认为图像仅存在轻度非增殖性 DR(1 级)迹象,也需将其归为 “有 DR” 类。所有阅片者均无法获取图像的真实标签。针对任务 3,研究人员告知阅片者:部分边界框解释可能包含健康区域,因为对于被稀疏 BagNet 模型错误分类为 DR 的健康图像,算法同样会生成边界框。除图像类别标注外,研究团队还记录了阅片者对每张图像的分级时间,并要求其在 1-5 分的量表上对自身判断的置信度进行评分。本研究已获得图宾根大学医院伦理委员会的批准(参考编号:249/2023BO2)。
研究采用定制开发的浏览器界面开展,该界面基于 Python Web 框架 Django(4.2.1 版本)构建,配备安全的 PostgreSQL 数据库(15.3 版本)和 JavaScript 前端(图 S3、图 S4、图 S5)。该工具可显示眼底图像和响应选项,并提供数字放大镜以放大图像小区域。
2.5 评估标准与统计分析
基于以往研究 [13],研究在开始前就明确了固有可解释深度学习模型的性能评估标准,主要从以下三个方面评估模型质量:
- 模型在数据集内部及跨数据集情况下,与常规深度学习模型的 DR 筛查性能对比;
- 类别证据图及衍生边界框在病变定位方面的质量;
- 固有可解释深度学习模型及衍生边界框在决策支持方面的实用性。
-
DR 筛查性能
DR 筛查性能的主要衡量指标是模型利用参考标签进行早期 DR 检测的准确率。此外,还评估了受试者工作特征曲线下面积(AUC)、敏感性、特异性和精确率。所有指标均在内部测试集和 10 个外部数据集(表 1)上计算得出,且在评估外部数据集前,未对模型进行重新训练或微调。所有指标均使用 scikit-learn 软件包(1.0.2 版本)计算,置信区间通过 1000 次非分层重采样的自助法 [37] 计算得出。 -
类别证据图质量
为衡量类别证据图及衍生边界框在病变定位方面的质量,研究团队计算了高亮区域(边界框内区域)中包含标注病变的比例(即 “定位精确率”)。为此,研究使用了本研究中收集的测试集 65 张图像的标注,以及包含像素级标注的外部数据集(表 1)。由于研究团队未针对病变检测训练模型,且诊断支持无需全面检测所有病变,因此未评估模型检测病变的比例(即 “召回率”)。 -
决策支持的统计分析
在临床用户研究中,阅片者的表现通过其决策结果相对于参考标签的准确率来衡量。为从统计学角度评估任务类型和 DR 参考等级的影响,研究团队采用广义线性模型(R 软件,glm 函数,4.0.3 版本)对阅片结果进行拟合,模型的预测变量为任务类型,或同时包含任务类型与 DR 等级(含交互项)。若在 0.05 显著性水平下发现显著预测变量,则计算边际均值及 95% 置信区间(emmeans 软件包,1.5.3 版本),并对不同条件间的差异进行事后检验。多重比较校正采用 Tukey 法。对于分级时间和报告置信度的分析,研究团队采用相同流程,但改用线性模型(lm 函数)。
3. 结果
本研究针对早期糖尿病视网膜病变(DR)筛查,训练并评估了一种固有可解释的深度学习模型(“稀疏 BagNet”,sparse BagNet)(图 1B)。
研究首先在开发数据集的内部测试集及多个额外数据集上,将该模型的早期 DR 筛查性能与最先进的非可解释黑箱模型(“ResNet50”)进行对比(见表 2)。
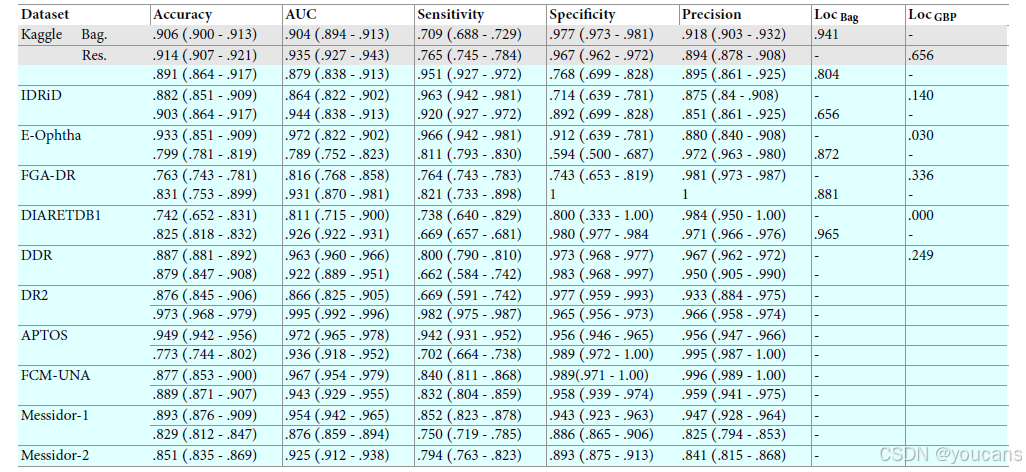
结果显示,在内部测试集上,稀疏 BagNet 表现优异,性能与最先进模型相当:准确率为 0.906(95% 置信区间 [0.900–0.913])、曲线下面积(AUC)为 0.904(95% 置信区间 [0.894–0.913])、敏感性为 0.709(95% 置信区间 [0.688–0.729])、特异性为 0.977(95% 置信区间 [0.973–0.981])、精确率为 0.918(95% 置信区间 [0.903–0.932]);且该模型在多个外部数据集上也表现出良好的泛化能力(见表 2)。
表 2. 分类性能总结,置信区间(CIs)通过 bootstrap 方法(n=1000)在 95% 水平上计算。
“AUC”指受试者工作特征曲线。“Loc Bag”和“Loc GBP”分别指稀疏 BagNet 和 ResNet-50 上的引导反向传播在定位注释图像中的病变时的定位精度。
对于每个数据集,第一行显示可解释的稀疏 BagNet 模型的性能,而第二行显示基线黑箱 ResNet-50 模型的性能。
Kaggle 数据集(第一行)是用于训练和评估模型的内部数据集,而其他数据集用于外部验证,以评估训练模型的泛化能力。
FCM-UNA 和 FGA-DR 数据集上的分类性能较低,可能是由于 FCM-UNA 数据集中大多数图像的质量相对较低,以及 FGA-DR 数据集的强度变化较大(见图 S6)。E-Ophtha 数据集上的低定位精度(0.664)可能是因为仅提供了“微血管瘤”和“渗出”病变的注释,而图像可能包含其他与糖尿病视网膜病变相关的病变。
核心优势
我们所提出的固有可解释模型,其核心优势在于局部疾病证据会在类别证据图中得到明确体现(图 1B.3、图 2B)。在模型训练过程中,我们通过设计促使类别证据图呈现稀疏性,最终的损失函数会在预测准确率与证据图的可解释性之间实现平衡。
对于本文研究的模型,我们通过启发式方法选择了用于平衡准确率与稀疏性的正则化参数 —— 在确保准确率损失最小化的前提下,最大限度地增强证据图的稀疏性(图 S2)。在类别激活图的每个位置,颜色代表模型对单个图像补丁的输出结果。我们会检测出证据值最高的区域,并围绕这些区域绘制与补丁尺寸对应的边界框(图 2A)。
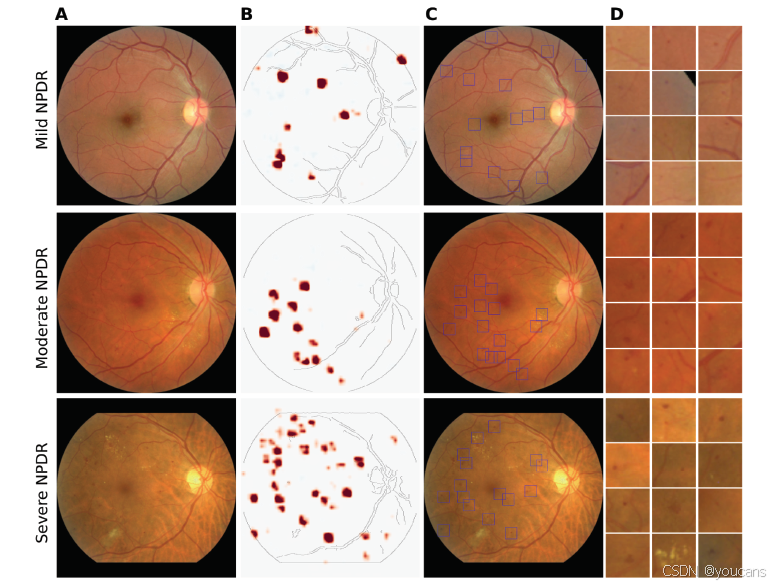
图 2. 固有可解释深度学习框架突出显示与临床相关的图像区域。
(A)来自不同糖尿病视网膜病变(DR)等级的视网膜眼底图像示例(从上到下:轻度非增殖性糖尿病视网膜病变(NPDR)、中度 NPDR 和重度 NPDR)。
(B)从固有可解释模型中提取的类别证据图,未经进一步处理。红色区域表示至少存在轻度 DR 的证据。
(C)在类别证据图中绘制的可疑区域的边界框。在某些情况下,由于颜色映射的缩放,边界框被放置在没有明显证据的区域,但这些证据值仍然是严格正的。
(D)将(C)中的可疑区域放大并按证据分数降序排列。根据图像等级,可疑区域包含各种与糖尿病视网膜病变相关的病变,如微血管瘤、出血或玻璃膜疣
尽管该模型从未接受过像素级标注训练,且除图像级糖尿病视网膜病变(DR)参考标签外无其他监督信号,但其高亮显示的区域通常包含微动脉瘤、玻璃疣或出血等 DR 相关病变,且精度较高(图 3)。
研究团队利用开发数据集测试集中的部分图像(图 3)以及带有像素级标注的外部数据集(表 1),定量评估了类别证据图对疾病相关病变位置信息的反映效果。结果显示,类别证据图能精准定位 DR 病变 —— 大多数被标记为可疑的区域确实包含标注病变(表 2,最后一列)。在开发数据集的图像中,模型定位精度达到 0.960(95% 置信区间 [0.941–0.976]),其中轻度非增殖性 DR(NPDR)与中度非增殖性 DR(NPDR)图像的定位精度略有差异(分别为 0.783 和 0.970)。值得注意的是,该模型在外部测试集上同样表现出良好的泛化能力,定位精度范围为 0.656–0.965(表 2,最后一列)。
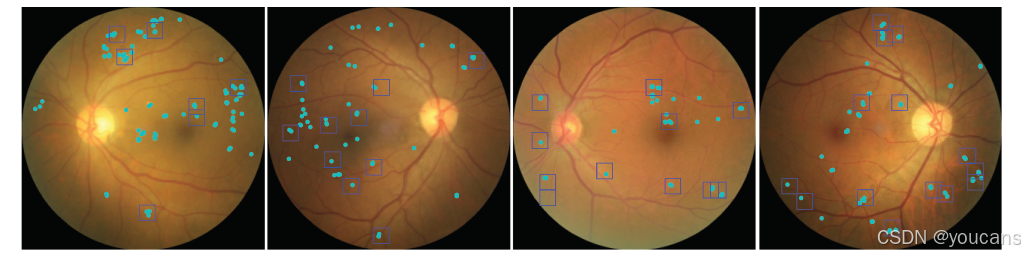
图 3. 提取的高证据图像块包含与糖尿病视网膜病变(DR)相关的病变。带有 DR 的示例眼底图像,其中 DR 病变由三位临床医生识别(青色)。基于 DR 的高证据区域从类别证据图中提取的边界框(蓝色)。请注意,所有边界框都包含注释的病变,但由于每张图像的边界框数量限制为十二个,因此并非所有病变都包含在边界框中。
研究团队还对算法高置信度(>0.75)误分类为 DR 的图像中提取的可疑区域进行了评估。为此,向两名临床医生展示了 30 张被误分类为 DR 且带有边界框的图像(图 S8)。结果显示,这些图像补丁有时会出现与 DR 无关的模糊或不明确病变,但通常包含与 DR 相关的异常(如微动脉瘤或渗出物),只是其数量或严重程度不足以达到临床 DR 诊断标准(图 S8)。
接下来,研究团队将固有可解释的稀疏 BagNet 模型的定位性能,与集成梯度(Integrated Gradients [38])、引导反向传播(Guided Backprop)等应用于最先进模型的经典事后解释方法进行对比(图 4A–4C)。选择这些方法是因为它们在 DR 事后可解释性技术的临床验证中表现优异 [36]。结果发现,从引导反向传播或集成梯度方法获得的边界框,在 DR 相关病变定位方面的精度远低于稀疏 BagNet(分别为 0.656 和 0.941,图 4D、表 2),尤其在样本外测试数据集上表现更为明显。
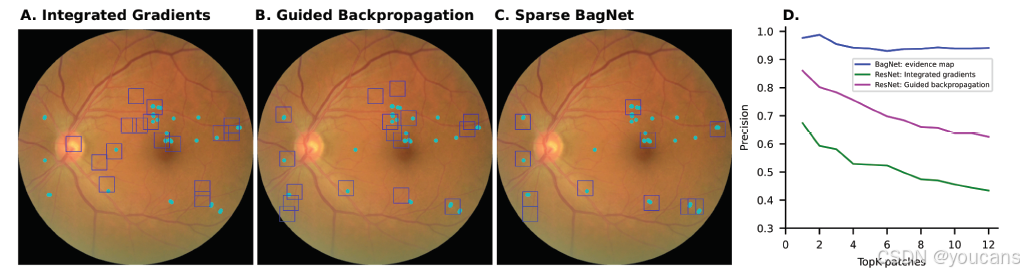
图 4. 固有可解释深度学习框架比应用于标准 DNN 的事后解释技术更精确地突出病变。
(A)通过标准 DNN 的积分梯度获得的热图提取的可疑区域(蓝色)用边界框标记。与临床相关的 DR 病变用青色标记。
(B)与(A)类似,从通过引导反向传播获得的热图中提取。
(C)作为对比,可疑区域是从稀疏 BagNet 中获得的。
(D)系统比较了考虑的图像块数量与临床注释的 DR 病变定位精度之间的关系。
随后,研究团队通过回顾性阅片研究,探究该可解释深度学习模型是否能有效协助临床医生检测 DR。6 名经验丰富的眼科医生参与了该研究,他们在不同 AI 辅助水平下对眼底图像进行早期 DR 筛查(详见 “方法” 部分)。结果显示,在无 AI 辅助(记为 “H”)的情况下,眼科医生的平均分类准确率为 0.611(95% 置信区间 [0.560–0.660];图 5A);当能获取深度学习模型的预测结果及置信度(“H+AI”)时,其准确率显著提升至 0.758(95% 置信区间 [0.711–0.800],p=0.0001,采用 Tukey 法校正多重比较的事后检验,详见 “方法” 部分);而当额外获取从类别证据图中提取的可疑区域边界框形式的 AI 解释(“H+XAI”)时,医生的准确率进一步达到 0.786(95% 置信区间 [0.741–0.825]),与 “H+AI” 组表现相近。
研究团队还进一步分析了眼科医生在不同疾病等级眼底图像上的 DR 筛查表现(图 5B)。在无 AI 辅助时,轻度 DR(1 级)图像的检测难度最大,准确率相对较低,而 AI 辅助可改善这一情况。对于健康图像,任何形式的 AI 决策支持均能显著提升筛查性能(H 组:0.567,95% 置信区间 [0.477–0.652];H+AI 组:0.842,95% 置信区间 [0.765–0.897];H+XAI 组:0.817,95% 置信区间 [0.737–0.876];H 组 vs.H+AI 组:p<0.0001;H 组 vs.H+XAI 组:p=0.0001;H+AI 组 vs.H+XAI 组:p=0.8645);而对于轻度 DR 图像,仅带有解释的 AI 辅助能显著提升筛查性能(H 组:0.483,95% 置信区间 [0.395–0.572];H+AI 组:0.617,95% 置信区间 [0.527–0.699];H+XAI 组:0.733,95% 置信区间 [0.647–0.805];H 组 vs.H+AI 组:p=0.0962;H 组 vs.H+XAI 组:p=0.0003;H+AI 组 vs.H+XAI 组:p=0.1326);对于中度 DR 图像,AI 辅助对筛查性能无显著影响。综上,这些结果表明,为眼科医生提供 AI 辅助可显著提升 DR 筛查性能,其中基于稀疏 BagNet 模型的解释对复杂诊断决策的辅助效果最为显著。
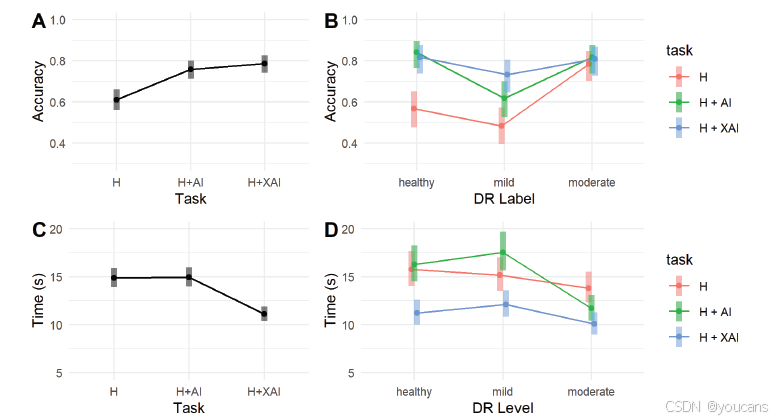
图 5. 基于固有可解释深度学习模型的 AI 辅助临床决策支持改善了糖尿病视网膜病变(DR)筛查。
(A)不同水平 AI 辅助下的筛查准确率。六位眼科医生对眼底图像进行分级,分别在没有 AI 辅助的情况下(“H”)、能够访问 AI 预测的情况下(“H+AI”)以及能够访问 AI 解释的情况下(“H+XAI”)。AI 辅助提高了筛查准确率,但访问 AI 解释的效果仅略有增加。
(B)对不同疾病等级的眼底图像进行 DR 筛查的准确率。对于健康图像,任何形式的 AI 决策支持(“H+AI”或“H+XAI”)都显著提高了准确率,而对于轻度 DR 的图像,带有解释的 AI 支持(“H+XAI”)显著提高了筛查准确率。对于中度 DR 的图像,AI 支持对筛查表现没有显著影响。
(C)在不同水平 AI 辅助下筛查 DR 的时间。与没有 AI 辅助(“H”)和仅 AI 预测(“H+AI”)的任务相比,带有解释的 AI 支持(“H+XAI”)显著减少了决策时间。
(D)在不同疾病等级的眼底图像上筛查 DR 的时间。在所有疾病阶段,筛查时间都有所减少,对于健康图像(“等级 0”)、轻度 DR(“等级 1”)和中度 DR(“等级 2”),带有解释的 AI 决策支持具有显著效果。
研究团队进一步详细分析了眼科医生在不同疾病等级眼底图像上的糖尿病视网膜病变(DR)筛查表现(图 5B)。在无人工智能(AI)辅助的情况下,轻度 DR(1 级)图像的检测难度最大,筛查性能相对较低,而 AI 辅助可改善这一情况。对于健康图像,任何形式的 AI 决策支持均能显著提升筛查性能(无 AI 辅助组(H 组):准确率 0.567,95% 置信区间 [0.477–0.652];AI 预测辅助组(H+AI 组):准确率 0.842,95% 置信区间 [0.765–0.897];AI 预测 + 解释辅助组(H+XAI 组):准确率 0.817,95% 置信区间 [0.737–0.876];H 组 vs.H+AI 组:p<0.0001;H 组 vs.H+XAI 组:p=0.0001;H+AI 组 vs.H+XAI 组:p=0.8645);而对于轻度 DR 图像,仅带有解释的 AI 辅助能显著提升筛查性能(H 组:准确率 0.483,95% 置信区间 [0.395–0.572];H+AI 组:准确率 0.617,95% 置信区间 [0.527–0.699];H+XAI 组:准确率 0.733,95% 置信区间 [0.647–0.805];H 组 vs.H+AI 组:p=0.0962;H 组 vs.H+XAI 组:p=0.0003;H+AI 组 vs.H+XAI 组:p=0.1326);对于中度 DR 图像,AI 辅助对筛查性能无显著影响。综上,这些结果表明,为眼科医生提供 AI 辅助可显著提升 DR 筛查性能,其中基于稀疏 BagNet 模型的解释对复杂诊断决策的辅助效果最为显著。
随后,研究团队探究了 AI 决策支持是否不仅能帮助眼科医生做出更准确的筛查决策,还能加快决策速度。结果显示,与其他两项任务(无 AI 辅助、仅 AI 预测辅助)相比,为眼科医生提供带有解释的 AI 辅助时,其决策时间显著缩短(图 5A,H 组:15.2 秒;H+AI 组:15.9 秒;H+XAI 组:11.7 秒;H 组 vs.H+AI 组:无显著差异;H 组 vs.H+XAI 组:p<0.0001;H+AI 组 vs.H+XAI 组:p<0.0001)。这种时间缩短在所有疾病阶段均存在,且带有解释的 AI 决策支持对不同疾病等级图像均有显著效果:对于健康图像(图 5A;H 组:15.8 秒;H+AI 组:16.3 秒;H+XAI 组:11.2 秒;H 组 vs.H+AI 组:无显著差异;H 组 vs.H+XAI 组:p<0.0001;H+AI 组 vs.H+XAI 组:p<0.0001)、轻度 DR 图像(H 组:15.2 秒;H+AI 组:17.5 秒;H+XAI 组:12.1 秒;H 组 vs.H+AI 组:p=0.1843;H 组 vs.H+XAI 组:p=0.180;H+AI 组 vs.H+XAI 组:p<0.0001)以及中度 DR 图像(H 组:13.8 秒;H+AI 组:11.7 秒;H+XAI 组:10.1 秒;H 组 vs.H+AI 组:无显著差异;H 组 vs.H+XAI 组:无显著差异;H+AI 组 vs.H+XAI 组:无显著差异)均是如此。综上,这表明稀疏 BagNet 模型提供的带有准确解释的决策支持,可缩短所有疾病等级图像的筛查时间。
研究团队还分析了 AI 决策支持是否会改变眼科医生对图像分级的置信度,但未发现 AI 辅助对此有显著影响(H 组:3.8 分;H+AI 组:3.7 分;H+XAI 组:3.6 分;各组间比较均无显著差异)。研究团队认为,与记录的决策时间相比,医生自我报告的置信度可能不是衡量其判断不确定性的可靠指标。
最后,研究团队分析了 AI 辅助对准确率的积极影响是否依赖于深度学习模型对图像分类的正确性 —— 此前有研究指出,当模型出现错误时,AI 辅助可能产生不利影响 [39]。与上述结果一致,研究发现,在深度学习模型分类正确的情况下,眼科医生的筛查性能和决策时间均显著改善(图 S5;准确率:H 组 vs.H+AI 组:p<0.0001;H 组 vs.H+XAI 组:p<0.0001;H+AI 组 vs.H+XAI 组:p<0.0001;决策时间:H 组 vs.H+AI 组:p=0.8178;H 组 vs.H+XAI 组:p<0.0001;H+AI 组 vs.H+XAI 组:p<0.0001)。而在模型分类错误的情况下,AI 辅助对准确率既无积极影响也无消极影响(H 组 vs.H+AI 组:p<0.3216;H 组 vs.H+XAI 组:p=0.4953;H+AI 组 vs.H+XAI 组:p=0.9480),但对决策时间有轻微积极影响(H 组 vs.H+AI 组:p=0.4557;H 组 vs.H+XAI 组:p=0.0941;H+AI 组 vs.H+XAI 组:p=0.0031),这意味着即便模型预测错误,决策时间仍有所缩短。
4. 讨论
本研究针对早期糖尿病视网膜病变(DR)检测,训练并评估了一种固有可解释的深度学习模型。即便对于经验丰富的眼科医生而言,早期 DR 检测也是一项具有挑战性的任务。在内部测试集及 10 个公开可用的外部数据集上,该模型的分类性能均与黑箱基准模型相当。尽管训练数据集包含大量拉丁裔患者的图像,但外部数据集来自全球不同地区,且采用不同设备采集,因此该模型在不同族群和患者群体中均表现出良好的泛化能力。不过,尽管部分数据集也包含非洲裔患者的图像,但所有数据集均未在非洲大陆采集。
除了 DR 筛查场景中常用的二元诊断决策(即 “有 DR / 无 DR”)外,本模型还能通过可解释的证据图提供决策依据 —— 这些证据图会高亮显示网络在决策过程中所依据的图像区域。研究发现,与应用于最先进深度神经网络(DNN)的事后解释技术相比,这种固有可解释框架能更精准地定位图像中的疾病相关病变,在样本外测试数据集上的优势尤为明显。即便模型依据参考标签做出错误预测,其生成的解释仍具有实用价值,能够高亮显示可疑区域。
在回顾性阅片研究中,研究团队发现,在分级过程中高亮显示这些区域,不仅有助于眼科医生提升分级性能(尤其是针对复杂病例),还能缩短其决策时间。这表明,当前 AI 筛查场景中所采用的范式若加入解释功能,或可更便于人工验证,并增强临床医生对算法决策的信任 [3,5]。此外,与早期关于临床决策支持的人机协作研究 [39,40] 不同,本研究进一步证实,AI 模型的错误并不会对眼科医生的决策产生负面影响。不过,该模型存在一项局限性:其训练数据来源于北美地区,因此若要应用于特定目标人群,可能需要基于该人群的数据进行微调 —— 尽管模型在额外 10 个数据集上的泛化结果已颇具前景。
如今,人工智能(AI)在医学图像分析领域的潜力已十分明确 [41,42],此类系统在多项任务中的性能已接近甚至超越临床专家 [43]。近年来,研究重点逐渐转向 “AI 系统辅助临床医生做出更优决策”[39]。在这一背景下,临床医生需了解 AI 模型的决策形成过程,因此医疗 AI 系统的透明度和可解释性已成为关键考量因素 [7,11,12,44]。与此一致,标准化指南中也明确指出,需构建可信赖、透明的 AI 系统并实现有效的人机协作,以推动其在临床实践中的应用 [44]。尽管在平衡高性能与可解释性方面通常面临挑战 [45],但本研究表明,若可解释模型的归纳偏置与任务相匹配(在本研究中,早期 DR 仅会在视网膜上形成局部病变,与模型归纳偏置相符),则可在实现固有可解释性的同时,无需在性能上做出显著妥协。其他固有可解释模型还包括基于原型的网络 [46],但这类模型难以应用于存在大量小型分散病变的疾病 —— 此类疾病的模型训练流程更为复杂,且可解释性的实现并非易事 [47]。
在临床场景中,这种固有可解释模型可协助临床医生应对症状前期疾病(如糖尿病视网膜病变)的早期精准诊断挑战。鉴于目前已有多款 DR 筛查 AI 系统获得批准,该模型的临床落地或相对简便。经训练后的模型可高效生成预测结果,其耗时极短(不会影响临床流程)、内存需求较低,且无需额外运行其他模型即可生成解释。此类解释可整合到商用 AI 系统现有的报告模板中,帮助筛查人员快速验证模型预测的合理性。在此基础上,未来可开展真实世界前瞻性研究,以验证本模型生成的解释对筛查质量和速度的影响,尤其针对早期 DR 患者。
本模型的另一项局限性在于:若其归纳偏置与疾病特征不匹配(例如,在晚期 DR 等病变覆盖视网膜大部分区域的情况下 [13]),模型可能无法提供良好的解释。未来的应用方向还包括:通过 “设计即具可解释性” 的深度生存模型 [49],实现对 DR 等疾病的进展时间预测 [48]。
5. GitHub 项目使用
本研究提出的稀疏 BagNet 模型(sparse BagNet model)实现代码已上传至 GitHub 平台,获取链接为:https://github.com/kdjoumessi/Sparse-BagNet_clinical-validation。
此外,本研究在选定的 Kaggle 数据库图像上完成的标注信息、研究原始数据及相关分析过程文件,均已同步存储于上述 GitHub 仓库中,可供查阅获取。
依赖项
仓库中运行代码所需的所有包均列在 requirements.txt 文件中。
数据
本仓库中的代码使用了来自糖尿病视网膜病变检测挑战赛的 Kaggle 公开数据集。
预处理
对图像的预处理方式为:精确裁剪视网膜眼底的圆形掩膜,并将其调整为 512×512 的尺寸。相关代码可参考此处:眼底预处理
我们使用了在 ISBI2020 挑战赛数据集上训练的 EfficientNets 集成模型,以过滤掉低质量图像。用于训练模型和内部评估的最终数据集(csv 文件)如下:
- training csv file
- validation csv file
- test csv file
文件 image.txt 中提供了用于生成图表的图像名称。
使用方法:训练
- 按如下结构组织数据集:
├── main_folder├── Kaggle_data├── Images├── kaggle_gradable_train.csv├── kaggle_gradable_test.csv├── kaggle_gradable_val.csv ├── Outputs├── configs├── data├── files├── utils├── modules ├── main.py├── train.py
在 configs/paths.yaml 中调整数据集路径。将以下值替换:
- root 替换为 Kaggle_data/
- img_dir 替换为 Images/
在 configs/default.yaml 中调整路径。将以下值替换:
- save_paths 替换为 xx(xx 为模型训练过程中日志文件和模型权重的保存路径)
- paths.model_dir 替换为 xx
- 更新训练配置和超参数
所有实验均由位于./configs/default.yaml 的配置文件完整指定。
训练配置(包括超参数调整)可在主配置文件中进行
更新训练配置和超参数在以下文件中更新训练配置和超参数:./configs/default.yaml
- 运行训练
(1)创建虚拟环境并安装依赖项
$ pip install requirements.txt
(2)使用先前定义的参数运行模型
$ python main.py
main.py 源程序如下:
- 监控训练进度
通过运行以下命令,在 127.0.0.1:6006 网站监控训练进度:
$ tensorborad --logdir=/path/to/your/log --port=6006
模型权重
所有实验中使用的具有最佳验证权重的最终模型如下:
ResNet 模型
稀疏 BagNet 模型
6. 参考文献
1.Gulshan V, Peng L, Coram M, Stumpe MC, Wu D, Narayanaswamy A, et al. Development and Validation of a Deep Learning Algorithm for Detection of Diabetic Retinopathy in Retinal Fundus Photographs. JAMA. 2016;316(22):2402–10. pmid:27898976
2.Food US, Administration D. Artificial Intelligence and Machine Learning (AI/ML)-Enabled Medical Devices (SaMD) Action Plan; 2021. Available from: https://www.fda.gov/medical-devices/software-medical-device-samd/artificial-intelligence-and-machine-learning-aiml-enabled-medical-devices
3.Grzybowski A, Brona P, Lim G, Ruamviboonsuk P, Tan GSW, Abramoff M, et al. Artificial intelligence for diabetic retinopathy screening: a review. Eye (Lond). 2020;34(3):451–60. pmid:31488886
4.Ipp E, Liljenquist D, Bode B, Shah VN, Silverstein S, Regillo CD, et al. Pivotal Evaluation of an Artificial Intelligence System for Autonomous Detection of Referrable and Vision-Threatening Diabetic Retinopathy. JAMA Netw Open. 2021;4(11):e2134254. pmid:34779843
5.Grauslund J. Diabetic retinopathy screening in the emerging era of artificial intelligence. Diabetologia. 2022;65(9):1415–23. pmid:35639120
6.Grote T, Berens P. On the ethics of algorithmic decision-making in healthcare. J Med Ethics. 2020;46(3):205–11. pmid:31748206
7.Rudin C. Stop Explaining Black Box Machine Learning Models for High Stakes Decisions and Use Interpretable Models Instead. Nat Mach Intell. 2019;1(5):206–15. pmid:35603010
8.Chetoui M, Akhloufi MA. Explainable Diabetic Retinopathy using EfficientNET. Annu Int Conf IEEE Eng Med Biol Soc. 2020;2020:1966–9. pmid:33018388
9.Alghamdi HS. Towards Explainable Deep Neural Networks for the Automatic Detection of Diabetic Retinopathy. Applied Sciences. 2022;12(19):9435.
10.Gonzalez-Gonzalo C, Liefers B, van Ginneken B, Sanchez CI. Iterative Augmentation of Visual Evidence for Weakly-Supervised Lesion Localization in Deep Interpretability Frameworks: Application to Color Fundus Images. IEEE Trans Med Imaging. 2020;39(11):3499–511. pmid:32746093
11.Ghassemi M, Oakden-Rayner L, Beam AL. The false hope of current approaches to explainable artificial intelligence in health care. Lancet Digit Health. 2021;3(11):e745–50. pmid:34711379
12.Grote T, Berens P. How competitors become collaborators-Bridging the gap(s) between machine learning algorithms and clinicians. Bioethics. 2022;36(2):134–42. pmid:34599834
13.Kerol D, Ilanchezian I, Kühlewein L, Faber H, Baumgartner C, Bah B. Sparse activations for interpretable disease grading. Med Imaging Deep Learn. 2023.
14.Brendel W, Bethge M. Approximating CNNs with Bag-of-local-Features models works surprisingly well on ImageNet. 2019:1–10.
15.Solomon SD, Chew E, Duh EJ, Sobrin L, Sun JK, VanderBeek BL, et al. Diabetic Retinopathy: A Position Statement by the American Diabetes Association. Diabetes Care. 2017;40(3):412–8. pmid:28223445
16.Vujosevic S, Aldington SJ, Silva P, Hernández C, Scanlon P, Peto T, et al. Screening for diabetic retinopathy: new perspectives and challenges. Lancet Diabetes Endocrinol. 2020;8(4):337–47. pmid:32113513
17.Wilkinson CP, Ferris FL 3rd, Klein RE, Lee PP, Agardh CD, Davis M, et al. Proposed international clinical diabetic retinopathy and diabetic macular edema disease severity scales. Ophthalmology. 2003;110(9):1677–82. pmid:13129861
18.Dugas E, Jared J, Cukierski W. Diabetic retinopathy detection. https://kaggle.com/competitions/diabetic-retinopathy-detection. 2015.
19.Porwal P, Pachade S, Kamble R, Kokare M, Deshmukh G, Sahasrabuddhe V, et al. Indian Diabetic Retinopathy Image Dataset (IDRiD): A Database for Diabetic Retinopathy Screening Research. Data. 2018;3(3):25.
20.Decencière E, Cazuguel G, Zhang X, Thibault G, Klein J-C, Meyer F, et al. TeleOphta: Machine learning and image processing methods for teleophthalmology. IRBM. 2013;34(2):196–203.
21.Zhou Y, Wang B, Huang L, Cui S, Shao L. A Benchmark for Studying Diabetic Retinopathy: Segmentation, Grading, and Transferability. IEEE Trans Med Imaging. 2021;40(3):818–28. pmid:33180722
22.Kauppi T, Kalesnykiene V, Kamarainen J, Lensu L, Sorri I, Raninen A. The diaretdb1 diabetic retinopathy database and evaluation protocol. In: BMVC. 2007. 10.
23.Li T, Gao Y, Wang K, Guo S, Liu H, Kang H. Diagnostic assessment of deep learning algorithms for diabetic retinopathy screening. Inf Sci. 2019;501:511–22.
24.Pires R, Jelinek HF, Wainer J, Valle E, Rocha A. Advancing bag-of-visual-words representations for lesion classification in retinal images. PLoS One. 2014;9(6):e96814. pmid:24886780
25.Karthik Sdm. Aptos 2019 blindness detection. https://kaggle.com/competitions/aptos2019-blindness-detection. 2019.
26.Castillo Benítez VE, Castro Matto I, Mello Román JC, Vázquez Noguera JL, García-Torres M, Ayala J, et al. Dataset from fundus images for the study of diabetic retinopathy. Data Brief. 2021;36:107068. pmid:34307801
27.Decencière E, Zhang X, Cazuguel G, Lay B, Cochener B, Trone C, et al. Feedback on a publicly distributed image database: the messidor database. Image Anal Stereol. 2014;33(3):231.
28.Abràmoff MD, Folk JC, Han DP, Walker JD, Williams DF, Russell SR, et al. Automated analysis of retinal images for detection of referable diabetic retinopathy. JAMA Ophthalmol. 2013;131(3):351–7. pmid:23494039
29.Koch LM, Baumgartner CF, Berens P. Distribution shift detection for the postmarket surveillance of medical AI algorithms: a retrospective simulation study. NPJ Digit Med. 2024;7(1):120. pmid:38724581
30.Tan M, Le Q. Efficientnet: rethinking model scaling for convolutional neural networks. In: Int Conf Mach Learn. 2019. 6105–14.
31.Liu R, Wang X, Wu Q, Dai L, Fang X, Yan T, et al. DeepDRiD: Diabetic Retinopathy-Grading and Image Quality Estimation Challenge. Patterns (N Y). 2022;3(6):100512. pmid:35755875
32.Boreiko V, Ilanchezian I, Ayhan M, Muller S, Koch L, Faber H. Visual explanations for the detection of diabetic retinopathy from retinal fundus images. In: Proceedings of the International Conference on Medical Image Computing and Computer-Assisted Intervention. Springer; 2022. p. 539–49.
33.Mueller S, Heidrich H, Koch LM, Berens P. Fundus circle cropping. https://github.com/berenslab/fundus_circle_cropping.
34.Huang Y, Lin L, Cheng P, Lyu J, Tang X. Identifying the key components in ResNet-50 for diabetic retinopathy grading from fundus images: a systematic investigation. 2021. https://arxiv.org/abs/2110.14160
35.He K, Zhang X, Ren S, Sun J. Deep residual learning for image recognition. In: Proceedings of the Conference on Computer Vision and Pattern Recognition. 2016.
36.Ayhan MS, Kümmerle LB, Kühlewein L, Inhoffen W, Aliyeva G, Ziemssen F, et al. Clinical validation of saliency maps for understanding deep neural networks in ophthalmology. Med Image Anal. 2022;77:102364. pmid:35101727
37.Ferrer L, Riera P. Confidence intervals for evaluation in machine learning. https://github.com/luferrer/ConfidenceIntervals.
38.Sundararajan M, Taly A, Yan Q. Axiomatic attribution for deep networks. In: Proceedings of the International Conference on Machine Learning. PMLR. 2017. 3319–28.
39.Tschandl P, Rinner C, Apalla Z, Argenziano G, Codella N, Halpern A, et al. Human-computer collaboration for skin cancer recognition. Nat Med. 2020;26(8):1229–34. pmid:32572267
40.Ng AY, Oberije CJG, Ambrózay É, Szabó E, Serfőző O, Karpati E, et al. Prospective implementation of AI-assisted screen reading to improve early detection of breast cancer. Nat Med. 2023;29(12):3044–9. pmid:37973948
41.Litjens G, Kooi T, Bejnordi BE, Setio AAA, Ciompi F, Ghafoorian M, et al. A survey on deep learning in medical image analysis. Med Image Anal. 2017;42:60–88. pmid:28778026
42.Muehlematter UJ, Daniore P, Vokinger KN. Approval of artificial intelligence and machine learning-based medical devices in the USA and Europe (2015-20): a comparative analysis. Lancet Digit Health. 2021;3(3):e195–203. pmid:33478929
43.Liu X, Faes L, Kale AU, Wagner SK, Fu DJ, Bruynseels A, et al. A comparison of deep learning performance against health-care professionals in detecting diseases from medical imaging: a systematic review and meta-analysis. Lancet Digit Health. 2019;1(6):e271–97. pmid:33323251
44.González-Gonzalo C, Thee EF, Klaver CCW, Lee AY, Schlingemann RO, Tufail A, et al. Trustworthy AI: Closing the gap between development and integration of AI systems in ophthalmic practice. Prog Retin Eye Res. 2022;90:101034. pmid:34902546
45.Frasca M, La Torre D, Pravettoni G, Cutica I. Explainable and interpretable artificial intelligence in medicine: a systematic bibliometric review. Discov Artif Intell. 2024;4(1).
46.Chen C, Li O, Tao D, Barnett A, Rudin C, Su J. This looks like that: deep learning for interpretable image recognition. Adv Neural Inf Process Syst. 32.
47.Djoumessi K, Bah B, Kühlewein L, Berens P, Koch L. This actually looks like that: proto-bagnets for local and global interpretability-by-design. In: Proceedings of the International Conference on Medical Image Computing and Computer-Assisted Intervention. Springer. 2024. 718–28.
48.Dai L, Sheng B, Chen T, Wu Q, Liu R, Cai C, et al. A deep learning system for predicting time to progression of diabetic retinopathy. Nat Med. 2024;30(2):584–94. pmid:38177850
49.Gervelmeyer J, Mueller S, Djoumessi K, Merle D, Clark S, Koch L. Interpretable-by-design deep survival analysis for disease progression modeling. In:International Conference on Medical Image Computing and Computer-Assisted Intervention. Springer; 2024. p. 502–12.
版权说明:
本文由 youcans@xidian 对论文 An inherently interpretable AI model improves screening speed and accuracy for early diabetic retinopathy 进行摘编和翻译。该论文版权属于原文期刊和作者,本译文只供研究学习使用。
引用格式:
Djoumessi K, Huang Z, Kühlewein L, Rickmann A, Simon N, Koch LM, et al. (2025) An inherently interpretable AI model improves screening speed and accuracy for early diabetic retinopathy. PLOS Digit Health 4(5): e0000831. https://doi.org/10.1371/journal.pdig.0000831
youcans@xidian 作品,转载必须标注原文链接:
【医学影像 AI】用于糖尿病视网膜病变筛查的固有可解释的稀疏 BagNet模型
(https://youcans.blog.csdn.net/article/details/154455985)
Crated:2025-11