DeepSeekV3-MOE
目录
DeepSeek-V3-Multi-Head Latent Attention
DeepSeekMoE
Complementary Sequence-Wise Auxiliary Loss.
专家激活次数(公式 18)
专家总贡献(公式 20)
整体逻辑与目标
DeepSeek-V3-Multi-Head Latent Attention
DeepSeek-V3对keys和values采用了low-raw联合压缩来降低Key-Value缓存(在推理侧):
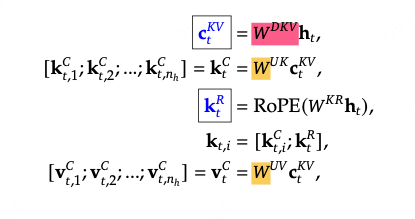
是下采样矩阵,其中
是对k和v的压缩latent vectors,其中dc远小于dn*nh,
是上采样矩阵。
这样只需要缓存蓝色的向量,来降低缓存cache。
同理,对query也进行下采样,
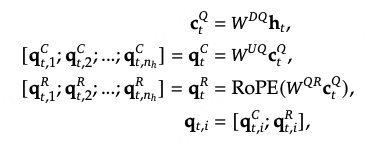
可以降低训练时的激活内存(通过低秩投影减少了中间特征向量的维度,从而降低了存储这些临时激活值所需的内存开销)。
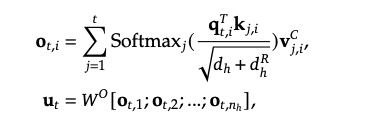
DeepSeekMoE
其中是共享塔的数量,
是专家塔的数量。
每个token选择分数最高的K个。
与DeepSeek-V2相比,DeepSeek-V3先归一化再使用sigmoid函数来计算affinity scores。
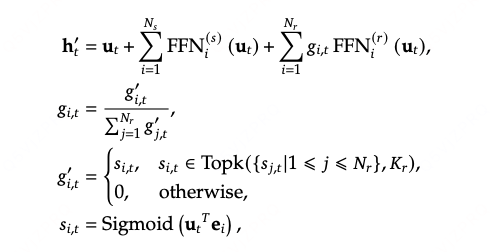
Complementary Sequence-Wise Auxiliary Loss.
序列级别的负载均衡,:尽管 DeepSeek-V3 主要依赖无辅助损失策略实现负载均衡,但为防止单个序列内出现极端不平衡,我们还采用了一种互补的序列级平衡损失:

专家激活次数(公式 18)
- 作用:统计第i个专家在当前序列中被选入 “Top-K 激活集” 的总次数。
专家总贡献(公式 20)
- 作用:计算第i个专家在当前序列中所有令牌上的 “归一化贡献总和”,反映该专家对整个序列的累计影响。
整体逻辑与目标
序列级平衡损失通过计算
(激活次数)与
(总贡献)的乘积之和,实现两个目标:
- 若某专家
(激活次数)过高,且
(总贡献)也过高,会导致
增大,损失上升,倒逼模型减少对该专家的依赖。
- 反之,若专家被激活次数少