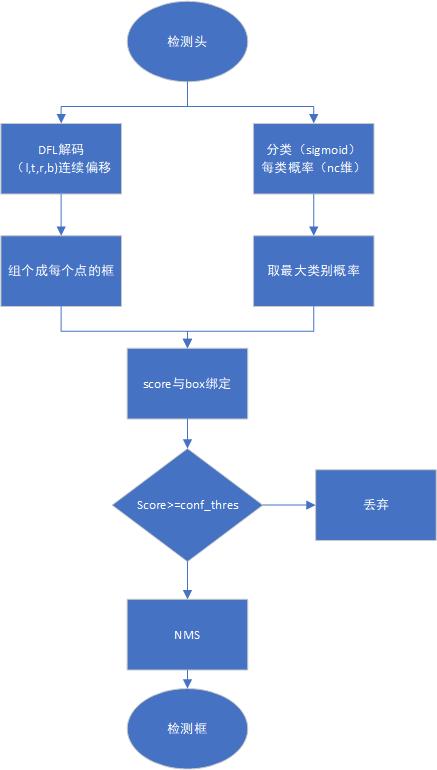
Yolo中的检测头
目录
一、检测头是什么
二、检测头的 “一行代码” 是什么意思?
三、检测头的输入
四、检测头的核心任务
4.1. 成员与构造参数
4.2. 中间通道的设定
4.3. 回归头cv2(每层一套)
4.4. 分类头cv3(每层一套)
4.5. DFL(Distribution Focal Loss)解码器
4.6. One-to-one 蒸馏/对齐(可选)
4.7. 举例说明
五、流程捋顺
在上一章中,我们学习了yolo的特征融合,并扩展到了多模态,现在我们要学习最后一块,检测头。
基于Yolo的图像识别中的特征融合-CSDN博客
一、检测头是什么
在 Backbone 和 Neck 提取出三种尺度的特征后(P3,P4,P5),检测头负责:
把每个尺度的特征图映射成:
(类别预测 + 位置预测 + 分布式回归)。最终生成我们看到的检测框。
Backbone/Neck 做的是“特征加工”。检测头做的是“框的计算”和“结果输出”。
二、检测头的 “一行代码” 是什么意思?
不知道代码怎么找参考:
笔记:对yolov8网络代码的学习_yolov8s 如何获取yolov8s.yaml配置-CSDN博客
基于Yolo的图像识别中的特征融合-CSDN博客
..\ultralytics\nn\modules\head.pyYAML 中通常是这一行:
[[P3, P4, P5], 1, Detect, [nc]]
或者 YOLOv11-RGBT 中:
[[26, 29, 32, 42, 45, 48], 1, DetectAux, [nc]]
含义很简单:
把这些多尺度特征输入检测头,生成最终检测结果。
但内部逻辑远远不止一句话。
三、检测头的输入
YOLOv8/YOLOv11 都使用三个(或更多)尺度:
| Feature | Shape(通常) |
|---|---|
| P3 | (B, 256, 80, 80) |
| P4 | (B, 512, 40, 40) |
| P5 | (B,1024,20,20) |
每个尺度包含不同数量的语义:
P3 专注于小目标
P4 中目标
P5 大目标
检测头需要从这些特征图中为每个网格 cell 预测:
边界框
目标置信度
类别概率
(YOLOv8/11)DFL 边界分布
四、检测头的核心任务
结合Yolo官方给出的Detect组件进行分析:
4.1. 成员与构造参数
class Detect(nn.Module):dynamic = False # 动态重建网格(导出相关)export = Falseformat = Noneend2end = Falsemax_det = 300shape = Noneanchors = torch.empty(0)strides = torch.empty(0)legacy = False # 兼容旧版头(v3/v5/v8/v9)xyxy = False # 输出坐标格式(训练多用 xywh,推理通常转 xyxy)
def __init__(self, nc: int = 80, ch: tuple = ()):super().__init__()self.nc = nc # 类别数self.nl = len(ch) # 检测层数(通常 3 个:P3/P4/P5)self.reg_max = 16 # DFL 的 bins(=每个边的离散分布长度)self.no = nc + self.reg_max * 4 # 每个点的输出通道:4*reg_max(回归分布) + nc(分类)self.stride = torch.zeros(self.nl) # 各层步幅,build 时自动填
4.2. 中间通道的设定
c2 = max((16, ch[0] // 4, self.reg_max * 4))
c3 = max(ch[0], min(self.nc, 100))
回归:保证足够容量去拟合
4*reg_max = 64的分布输出。分类:给到不低于输入通道的中间维度(并封顶 100),兼顾表示力与轻量化。
4.3. 回归头cv2(每层一套)
self.cv2 = nn.ModuleList(nn.Sequential(Conv(x, c2, 3), # 3×3Conv(c2, c2, 3), # 3×3nn.Conv2d(c2, 4 * self.reg_max, 1) # → 4*16=64 通道(DFL)) for x in ch
)
其中 c2 的关键作用是:
把 backbone/neck 原始特征映射到回归友好的语义空间
4.4. 分类头cv3(每层一套)
如果 legacy=True:用两层标准 Conv + 1×1 输出。
否则(默认、与你代码一致):Depthwise 轻量头(DWConv + 1×1 的两段堆叠)再接 1×1 输出到 nc。
self.cv3 = nn.ModuleList(nn.Sequential(nn.Sequential(DWConv(x, x, 3), Conv(x, c3, 1)),nn.Sequential(DWConv(c3, c3, 3), Conv(c3, c3, 1)),nn.Conv2d(c3, self.nc, 1),) for x in ch
)
4.5. DFL(Distribution Focal Loss)解码器
self.dfl = DFL(self.reg_max) if self.reg_max > 1 else nn.Identity()
训练/推理时把 64 通道的离散分布解成 4 个连续距离(l,t,r,b 或左/上/右/下偏移)
4.6. One-to-one 蒸馏/对齐(可选)
if self.end2end:self.one2one_cv2 = copy.deepcopy(self.cv2)self.one2one_cv3 = copy.deepcopy(self.cv3)
4.7. 举例说明
我们来举例演示Detect是如何构造的,以官方yaml为例:
- [[16, 19, 22], 1, Detect, [nc]] # Detect(P3, P4, P5)明确这条代码的含义:接收16,19,22层的输出,重复一次,调用Detect,传参类别数。
1) 先解析出
ch(各输入尺度的通道数)收集第 16、19、22 层的通道,形成元组:
ch = (channels_of_layer_16, channels_of_layer_19, channels_of_layer_22) # 常见是 (256, 512, 1024)2) 用
nc和ch去初始化 Detect实例化:
head = Detect(nc=nc, ch=(256, 512, 1024)) # 以常见配置举例3) Detect 内部如何用到
ch
self.nl = len(ch)→ 检测层数 = 3(P3/P4/P5)按
for x in ch分别给每个尺度建一套回归头和分类头:# 回归(DFL)头:x→c2→c2→(4*reg_max) self.cv2 = ModuleList(Sequential(Conv(x, c2, 3), Conv(c2, c2, 3), Conv1x1(c2, 4*reg_max)) for x in ch ) # 分类头(轻量DW):x→c3→c3→nc self.cv3 = ModuleList(Sequential( DWConv+Conv(x→c3), DWConv+Conv(c3→c3), Conv1x1(c3→nc) ) for x in ch )
c2,c3的定义:c2 = max(16, ch[0] // 4, 4*reg_max) # 回归分支中间通道,常见等于 64 c3 = max(ch[0], min(nc, 100)) # 分类分支中间通道,常见等于 ch[0]
前向(训练与推理)的输入/输出是什么?
x = [x16, x19, x22] # 分别对应 P3, P4, P5 # 形状类似: # x16: (B, 256, 80, 80) # x19: (B, 512, 40, 40) # x22: (B, 1024, 20, 20)训练时(不做解码,直接监督 DFL 与分类):
对每个尺度:
reg = cv2[i](x[i]) # (B, 4*reg_max, H_i, W_i) # 64 通道(reg_max=16) cls = cv3[i](x[i]) # (B, nc, H_i, W_i) out_i = cat([reg, cls], dim=1) # (B, 64+nc, H_i, W_i)返回列表:
[out_P3, out_P4, out_P5]给损失函数,损失里会对 64 通道做 DFL 分布监督,对
nc通道做分类监督
推理时(拼接 → DFL 解码 → 网格/步幅解码):
展平并拼接三个尺度:
x_cat = cat([out_i.view(B, 64+nc, -1) for out_i in outs], dim=2) # (B, 64+nc, N), N=Σ(H_i*W_i)切分回归/分类:
box_distr = x_cat[:, :4*reg_max, :] # (B, 64, N) cls_logit = x_cat[:, 4*reg_max:, :] # (B, nc, N) → sigmoidDFL 把 64 通道分布解成 4 个连续距离:
box = self.dfl(box_distr) # (B, 4, N)结合网格中心与 stride 解到像素坐标(anchor-free):
centers, strides = make_anchors(...) boxes = dist2bbox(centers, box) * strides # (B, 4, N) → xywh/xyxy转置为常用输出:
boxes -> (B, N, 4) scores -> (B, N, nc)
五、流程捋顺
一句话总括:
YOLO =(预处理)→ Backbone 抽语义 → Neck 多尺度(可多模态)融合 → Detect 头:解耦回归(DFL) + 分类 → DFL 解码 + 网格/步幅还原 → 分数阈值 → NMS → 框。
为什么 Detect 头要先把框进行编码(DFL 分布),然后在推理时再解码(DFL→连续偏移→stride 网格还原)?这种先编码再解码的意义是什么?
YOLO 头部采用“编码 → 解码”的方式,是为了让训练阶段在分布空间学习更稳定的梯度与边界不确定性,而推理阶段则将学到的离散边界分布通过期望值解码为连续坐标,实现低噪声、高精度的边界预测。这种方式在多模态场景中尤其适合处理模态间对齐误差与弱边界问题。
分数阈值如何得出?
YOLOv5 输出三个分支:
objectness 作为“目标存在概率”,减少 FP。
分支 输出 意义 回归 head 4个数 box objectness 1个通道 点是否包含目标 分类 head nc个通道 类别概率 score = sigmoid(obj) * sigmoid(class[k])
YOLOv8(含 v11)采用了解耦头:
回归 → 4×reg_max(DFL)
分类 → nc 通道
分类分支不再输出 objectness。
final score = 分类概率 = sigmoid(cls[k])
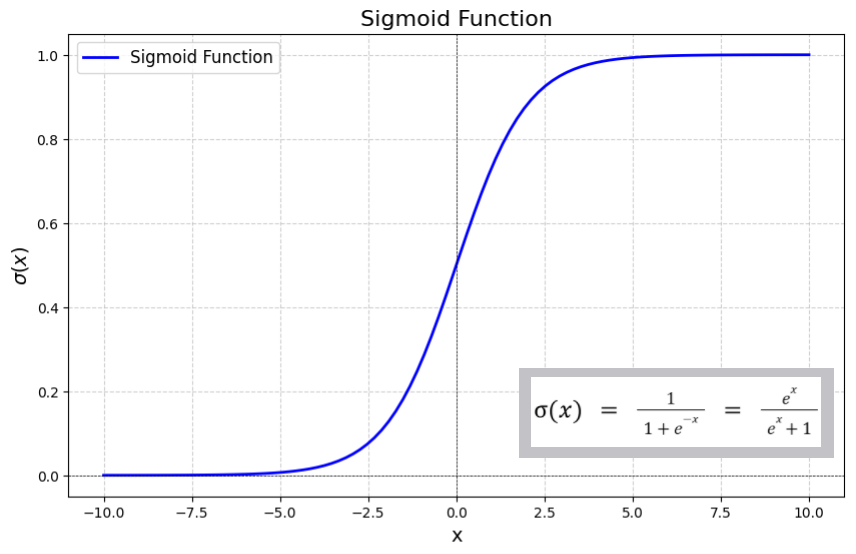
scores = cls_prob.max(dim=2) # 每个点的最高类别概率在多类别场景下,对于每个预测框:
取所有类别
cls_prob的最大值作为分数对应的类别索引作为
class_id模型输出分类概率 = “每个点有某种类别的置信度”
人为设定 score_threshold
conf_thres = 0.25
因此:YOLO 的最终检测分数由分类分支的 sigmoid 输出决定,是对每个位置的类别置信度;在 YOLOv8/11 中不再使用单独的 objectness 通道。推理时根据 score ≥ threshold 过滤候选,配合 NMS 得到最终框。阈值由经验与任务需求确定,而模型输出的概率决定框的可信度排序。
模型预测出了 score(分类概率),score 阈值是怎么一步一步“筛选出最终框”的?score 是怎么跟 box 对应的?最后是怎么从一堆点变成一组框?
1. Detect 头输出了什么?
YOLOv8/11(默认流程)输出三件东西:
1)box_distr(4×16 的分布)
→ 通过 DFL 解码成
(l,t,r,b)连续偏移量2)cls_logit(nc 通道的 logits)
→ sigmoid → 分类概率
cls_prob3)每个点都有一个 中心点坐标(由 grid 决定)
也就是说,在特征图上的 每个点都对应一个候选框。
例如总共 8400 个点:
P3: 80×80 = 6400 P4: 40×40 = 1600 P5: 20×20 = 400 ------------------- 总共 N = 6400 + 1600 + 400 = 8400 个潜在框
2.每个点产生一个候选框
对每个点执行:
(步骤 1)分类概率
cls_prob = sigmoid(cls_logit) # (nc,) score = max(cls_prob) # 单个分数 class_id = argmax(cls_prob) # 类别ID(步骤2)坐标解码
把(l,t,r,b)通过:
x1 = cx - l*stride y1 = cy - t*stride x2 = cx + r*stride y2 = cy + b*stride得到候选框:
box = [x1, y1, x2, y2]注意:每个点都对应一个候选框。
每个候选框都有一个 score 和一个 class_id。
符号 全称 解释 l left 从当前特征点中心往“左边界”方向的距离 t top 从当前特征点中心往“上边界”方向的距离 r right 从当前特征点中心往“右边界”方向的距离 b bottom 从当前特征点中心往“下边界”方向的距离 关键点:特征点中心 ≠ 目标中心
YOLO 的 anchor-free 预测是以 特征图上的每一个点(cell center) 为中心,而不是以目标中心为中心。
也就是说:
每个特征点都会产生一个框,框是相对于“该特征点的中心”预测的,而不是相对于物体中心。
3. 分数阈值:筛掉垃圾框(关键步骤!)
比如设定:
conf_thres = 0.25对每个点的 score 判断:
if score >= 0.25:保留 else:丢弃经过阈值筛选:
原来是 8400 个候选框
保留可能只有 ~300~1000 个(取决于场景)
这一步就像“预过滤”,只保留可信度高的框让 NMS 处理。
4. 阈值后的框如何变成最终框?(NMS)
剩下的框会进入 NMS:
1)按照 score 从大到小排序
2)从最大 score 框开始
3)过滤与其 IoU 过大的框
(比如 IoU > 0.5 则认为重叠太多,是重复检测)
4)保留不重叠的框
5)继续直到所有框处理完
最终得到:
少量高质量的、不重复的框。
5. 所以整个“分数阈值到框”的链条是
1)每个特征点预测
一个框(通过 DFL 解码)
一个 score(分类最高概率)
2)score 阈值筛选
- score < 阈值 → 丢弃
- score >= 阈值 → 保留
3)保留下来的框进入 NMS(去重)
4)NMS 输出最终框列表
[x1,y1,x2,y2, score, class_id]
流程如图所示: