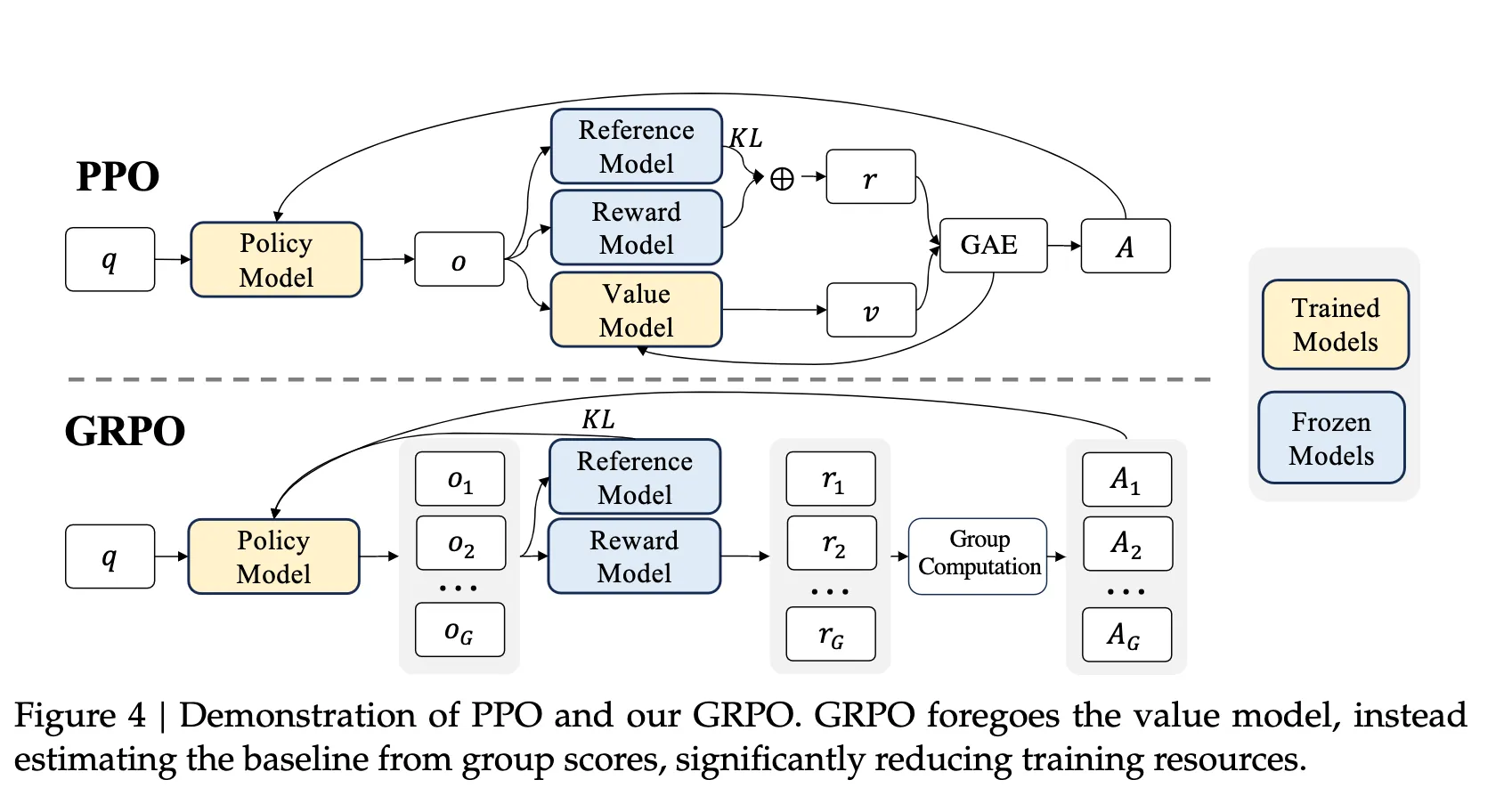
GRPO(Group Relative Policy Optimization)
GRPO(Group Relative Policy Optimization)是一种近年来在大语言模型(LLM)微调、尤其是数学推理/链式思考任务中提出的强化学习算法。
其设计目标包括:
减少训练开销 — 相比传统的如 Proximal Policy Optimization(PPO)算法,GRPO 取消(或弱化)了价值函数(critic)网络,从而减少了模型参数和内存消耗。
适应高复杂任务 — 在数学、编程、链式推理等任务中,由于奖励函数或反馈机制可能较为稀疏、且传统价值估计困难,GRPO 提出用“组”样本比较的方式来估计优势(advantage)。
稳定更新 — 与 PPO 一样保留“比例裁剪 (clipping)”和 KL 限制等机制,以防模型更新过猛导致策略崩溃。
对应原理可以从下图看出,GRPO取消了价值模型,