视频+教程 | 三位一体:MOI 数据源 + MO 向量存储 + Dify 应用层,构建企业级 RAG
视频+教程 | 三位一体:MOI 数据源 + MO 向量存储 + Dify 应用层,构建企业级 RAG
概述
本教程将详细引导您完成一个完整的数据处理与应用流程:首先,我们将 Dify 平台与 MatrixOne (MO) 数据库进行集成,使用 MatrixOne 作为 Dify 的向量存储后端;然后,演示了如何从 MatrixOne Intelligence (MOI) 平台将处理好的分段数据(Chunks)导出到 Dify 中新建的知识库;最终,利用这些导入的数据快速构建一个智能聊天应用。
通过本教程,您将掌握:
- 如何配置 Dify 以使用 MatrixOne 作为其向量数据库。
- 如何在 MOI 和 Dify 之间建立数据连接。
- 如何将 MOI 的数据导出到 Dify 知识库。
- 如何基于导入的知识库数据构建一个可用的 AI 智能体。
Part 1: 环境准备与 Dify-MO 集成
在开始之前,请确保您的本地开发环境已经准备就绪。
1.1 安装 Git
Git 是用于版本控制的必备工具,我们将用它来克隆 Dify 的源代码。
1. 安装 Git
请参考 Git 官方文档 Git - Downloading Package 根据您的操作系统进行安装。
2. 验证安装
打开终端,运行以下命令检查 Git 是否安装成功:
git --version
如果看到类似 git version 2.40.0 的输出,则表示安装成功。
1.2 安装 Docker
Docker Get Docker | Docker Docs 用于创建和管理容器化的应用环境,Dify 的部署依赖于 Docker。
1. 安装 Docker Desktop
访问 Get Docker 官方页面,根据您的操作系统下载并安装 Docker Desktop。推荐 Docker 版本不低于 20.10.18。
2. 验证安装
安装完成后,在终端中运行以下命令来验证 Docker 版本:
docker --version
如果看到类似 Docker version 20.10.18, build 100c701 的输出,则表示安装成功。
3. 启动 Docker
请确保 Docker Desktop 应用程序已经启动并在后台运行。
1.3 配置并启动 Dify
接下来,我们将获取 Dify 源码,并将其配置为使用 MatrixOne 数据库。
1. 获取 Dify 源代码
克隆 Dify 最新的源代码到您的本地:
git clone https://github.com/langgenius/dify.git
cd dify
2. 构建支持 MatrixOne 的 Docker 镜像
我们需要构建一个特殊的 Docker 镜像,该镜像包含了与 MatrixOne 连接所需的依赖:
docker build -f docker/Dockerfile.mo -t langgenius/dify-api:mo .
注意:此步骤可能需要一些时间,因为它会下载依赖并构建镜像。
3. 配置环境变量
进入 docker 目录,并从模板文件复制一份新的环境变量配置文件:
cd docker
cp .env.example .env
4. 编辑 .env 文件
使用您常用的文本编辑器(如 VS Code, Vim)打开 .env 文件,找到并修改以下配置,以连接到您的 MatrixOne 实例:
# 向量数据库配置
VECTOR_STORE=matrixone# MatrixOne 数据库配置
DB_USERNAME=your_matrixone_username
DB_PASSWORD=your_matrixone_password
DB_HOST=your_matrixone_host
DB_PORT=6001
DB_DATABASE=dify
5. 修改 Docker Compose 配置
编辑 docker-compose.yaml 文件,将其中 api 和 worker 服务的镜像替换为我们刚刚构建的 langgenius/dify-api:mo。
找到以下两个部分并修改 image 字段:
services:api:image: langgenius/dify-api:mo # 修改这里# ... 其他配置保持不变worker:image: langgenius/dify-api:mo # 修改这里# ... 其他配置保持不变
6. 启动 Dify 服务
一切准备就绪,现在可以启动 Dify 平台了:
docker compose up -d
服务启动需要一些时间。您可以使用以下命令查看实时日志:
docker compose logs -f
7. 初始化 Dify 平台
- 在浏览器中访问
http://localhost/install,根据页面提示完成管理员账户的初始化设置。 - 登录后,进入 设置 -> 模型提供商,配置您的大语言模型(LLM)和向量模型的 API Key,例如 Ollama, OpenAI, Anthropic 等。
至此,您的 Dify 平台已经成功搭建并与 MatrixOne 集成。
Part 2: 核心流程:从 MOI 导出数据至 Dify
现在,我们将数据从 MOI 平台导出到 Dify。
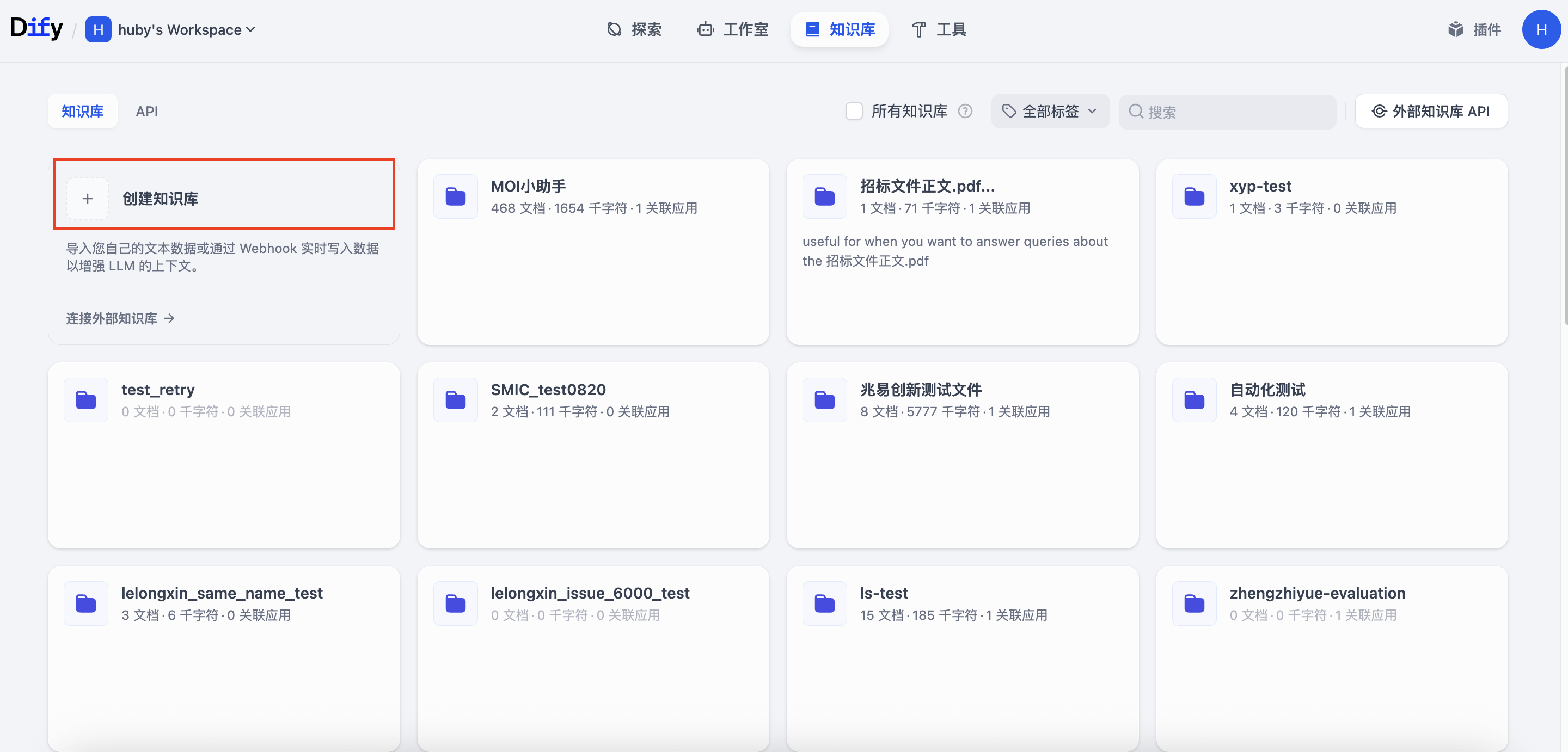
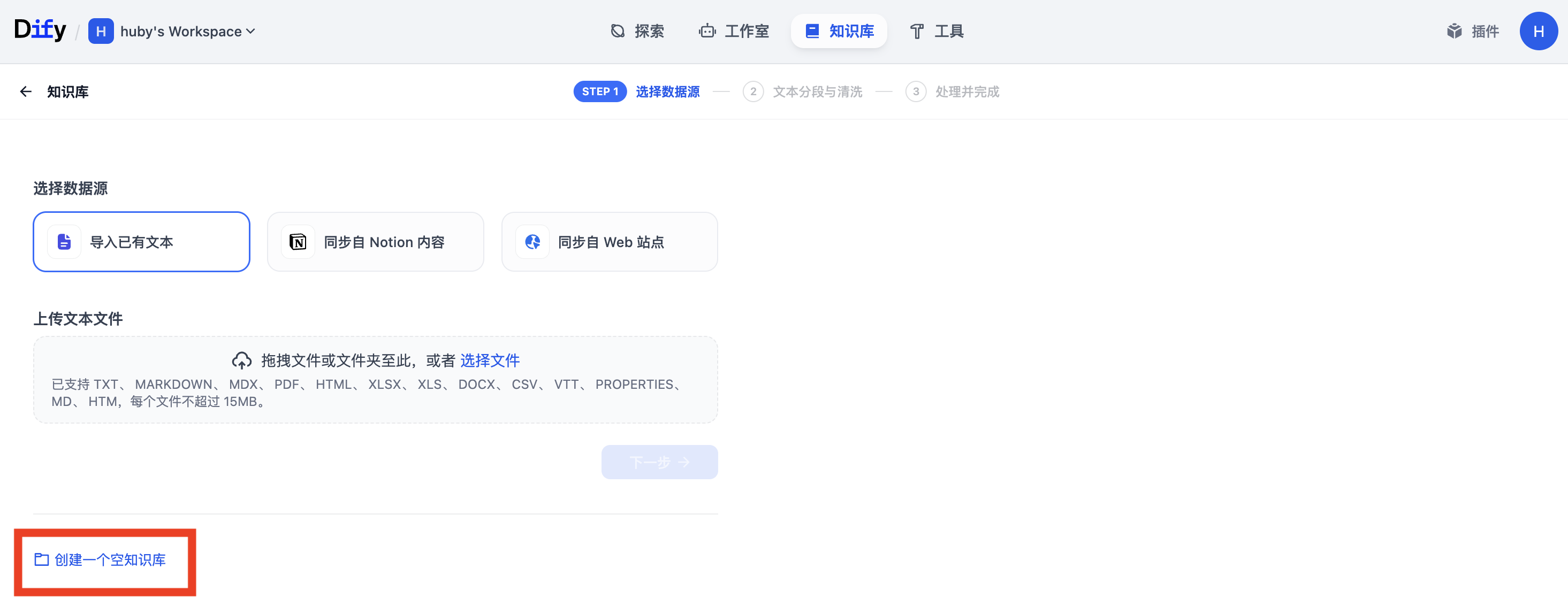
2.1 在 Dify 中准备知识库
首先,我们需要在 Dify 中创建一个空的知识库,作为数据的接收容器。
- 登录 Dify 平台。
- 进入"知识库"模块。
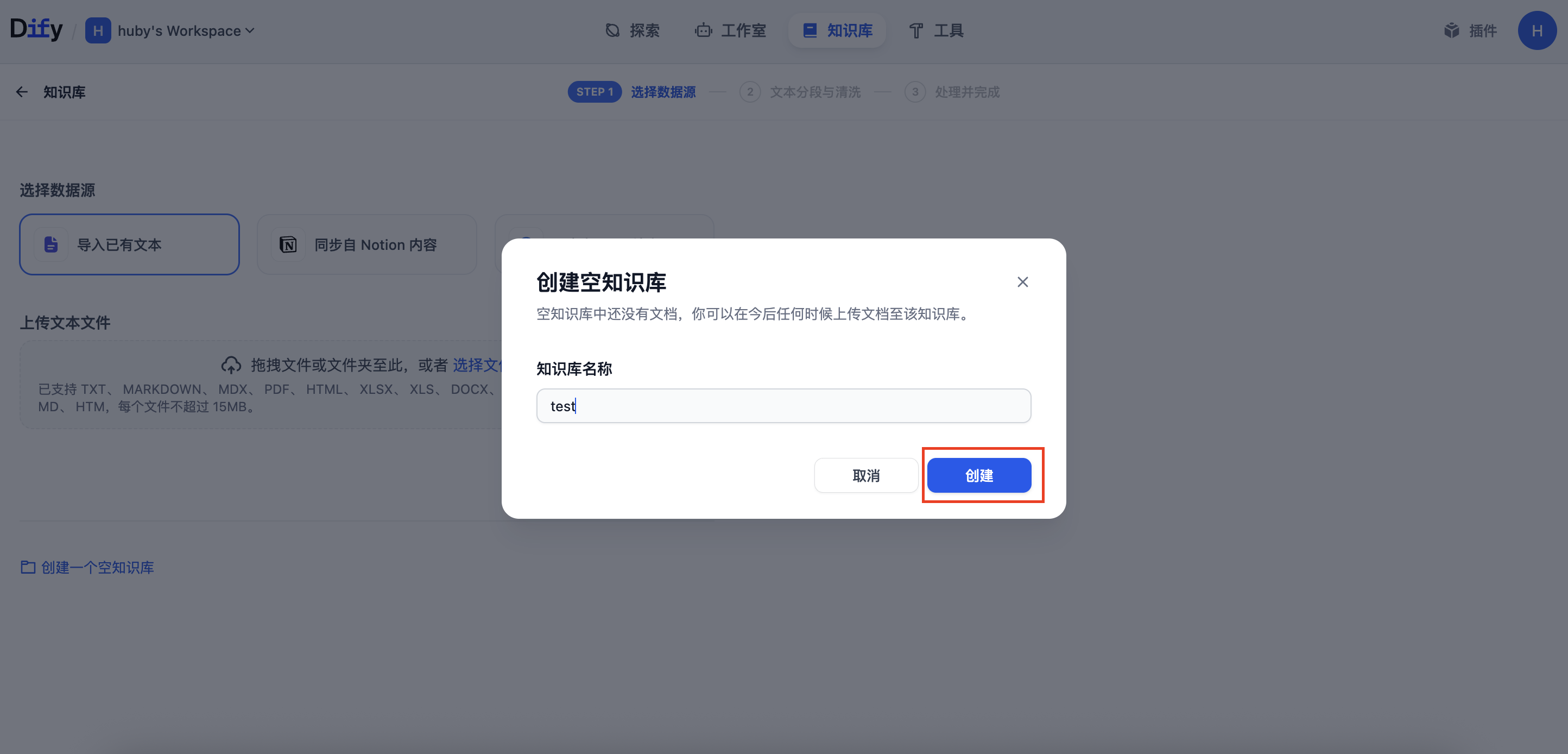
- 点击"创建知识库",输入一个名称(例如
moi_data_repository),然后点击"创建"。
2.2 在 MOI 中配置 Dify 连接器
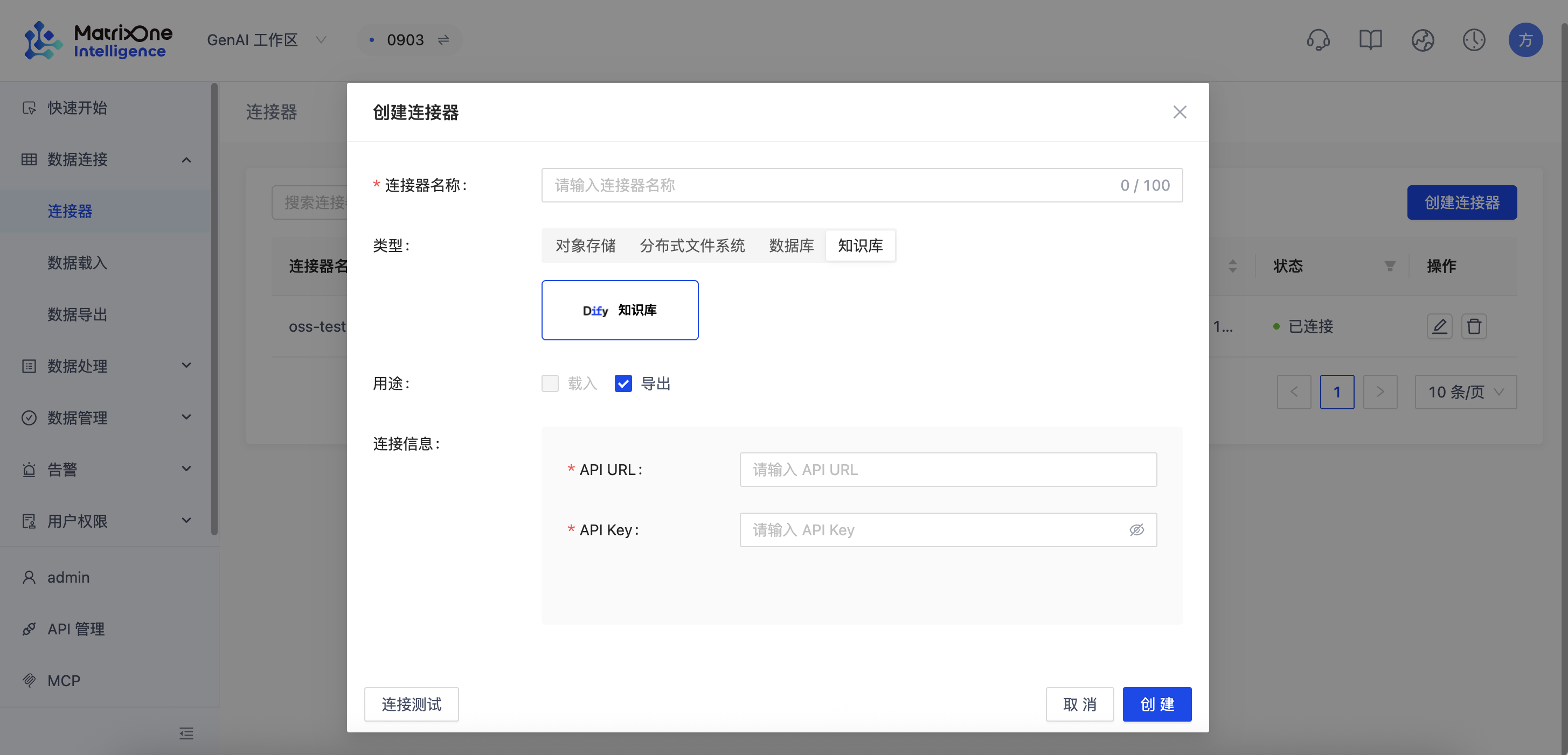
为了让 MOI 能够将数据发送到 Dify,需要配置一个连接器。
-
登录 MOI 平台。
-
进入 数据连接 -> 连接器 页面。
-
点击"新建连接器",类型选择为 Dify。
-
填写以下配置信息:
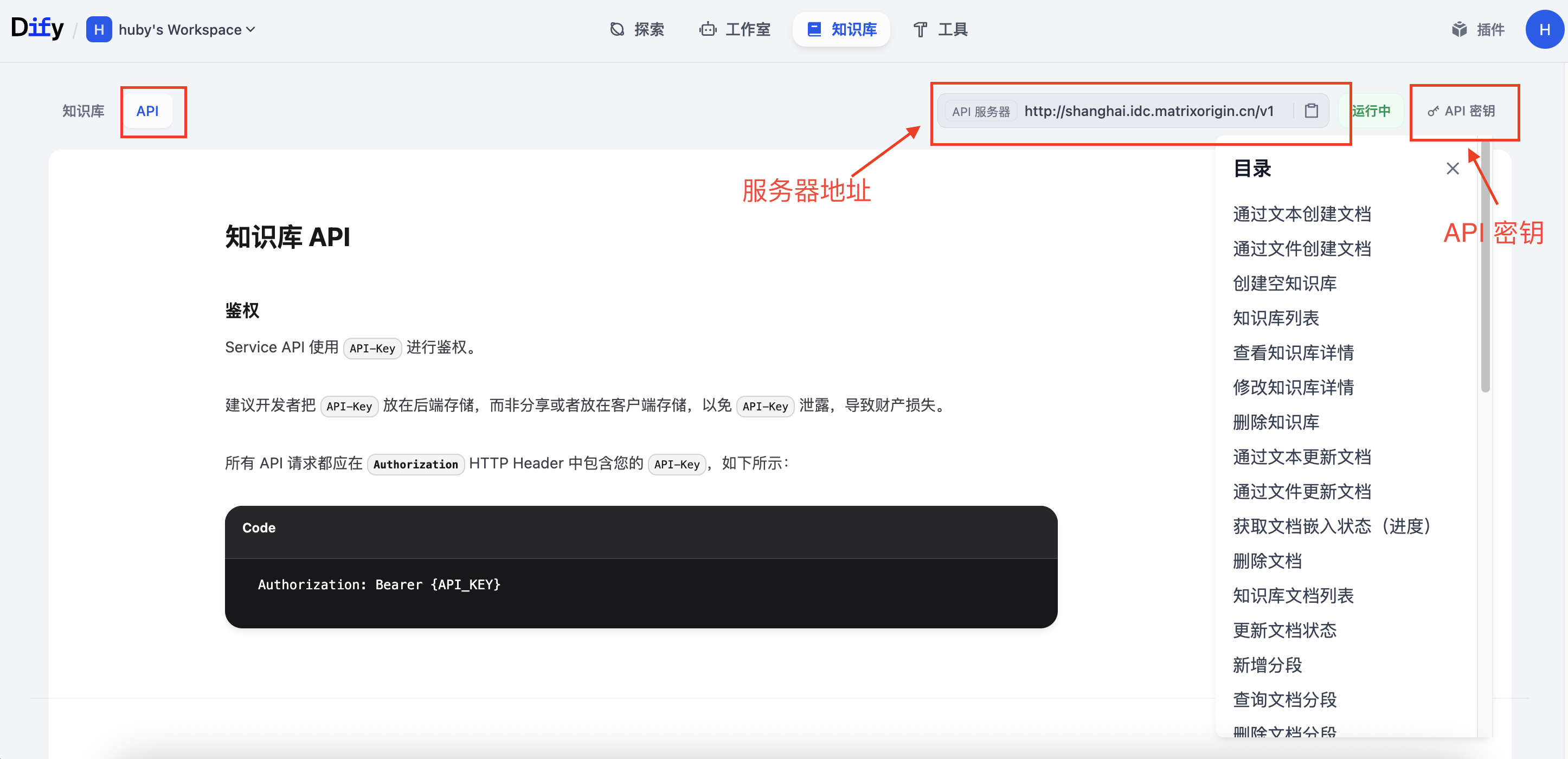
a. API 服务器地址:
- 回到 Dify 平台,进入"知识库"模块。
- 点击页面右上角的"API 访问"。
- 复制"API 服务器地址",并确保其为公网可访问的 HTTPS 协议地址。若协议非 HTTPS,请手动补充(例如:
https://...)。
b. API 密钥:
- 在 Dify 的同一"API 访问"页面中,复制"个人 API Token"(访问令牌)。
-
保存连接器。
2.3 在 MOI 中创建并执行导出任务
连接器配置好后,我们就可以创建导出任务了。
-
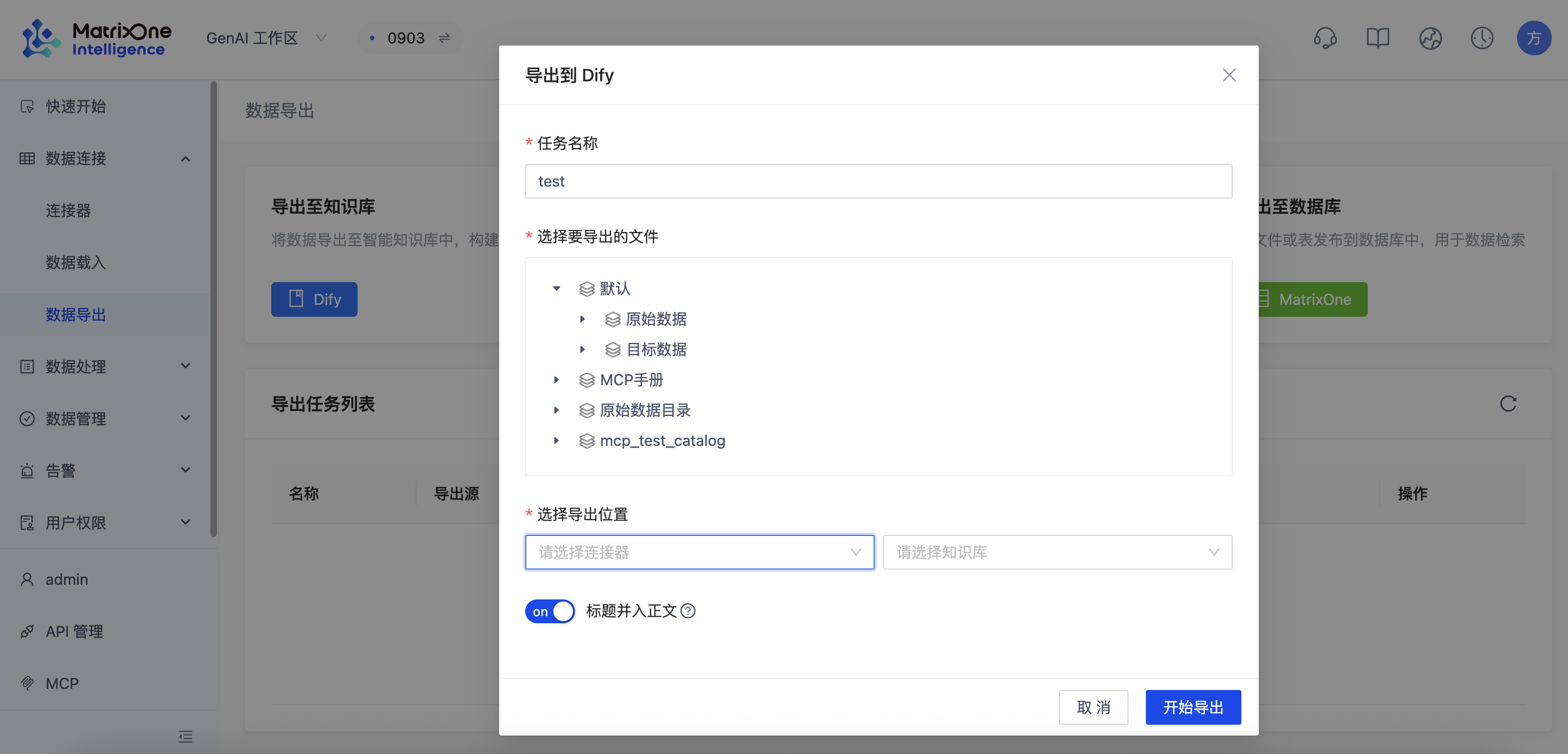
在 MOI 平台,进入 数据连接 -> 数据导出 页面。
-
点击"新建导出",并配置以下选项:
- 任务名称:自定义一个任务名称。
- 选择文件:选择一个经过工作流处理后、包含分段(chunks)数据的文件。这是导出到向量数据库的必要条件。
- 选择连接器:选择上一步创建的 Dify 连接器。
- 选择知识库:系统会自动加载 Dify 中的知识库列表,选择我们刚刚创建的空知识库(例如
moi_data_repository)。 - 向量模型:如果是首次向这个知识库导出,您需要选择一个向量化模型。请确保该模型与您 Dify 中配置的 Embedding 模型一致或兼容。
-
点击"创建"后,导出任务开始执行。等待任务状态从"进行中"变为"完成"。
2.4 验证数据导入成功
导出完成后,我们需要验证数据是否已成功写入 Dify 的知识库中。
方法一:通过 Dify UI 验证(推荐)
- 回到 Dify 平台,进入您创建的知识库。
- 点击"文档"标签页。您应该能看到从 MOI 导出的文档列表。
- 点击"分段"标签页,您可以看到文档被切分成的具体数据条目,这表明数据已成功向量化并存储。
方法二:通过数据库验证(可选,高级)
如果您想深入后台确认,可以直接连接到 MatrixOne 数据库进行检查。
- 使用 MySQL 客户端连接到 MatrixOne 实例:
mysql -h your_matrixone_host -P 6001 -u your_username -p
- 切换到 Dify 数据库并查看其中的数据表:
USE dify;
SHOW TABLES;
- 查看表结构和数据行数,确认数据已写入:
SELECT COUNT(*) FROM document_segments;
如果 COUNT(*) 的结果大于 0,则表明数据已成功写入数据库。
Part 3: 应用实践:基于导入数据构建智能体
数据成功导入 Dify 知识库后,即可利用其构建智能聊天助手,让 AI 能够基于您上传的知识进行问答。
3.1 创建聊天助手应用
- 在 Dify 首页,点击"创建应用"。
- 选择应用类型为"聊天助手"。
- 为您的应用命名(例如"MOI 知识问答助手"),然后点击"创建"。
3.2 编排应用并关联知识库
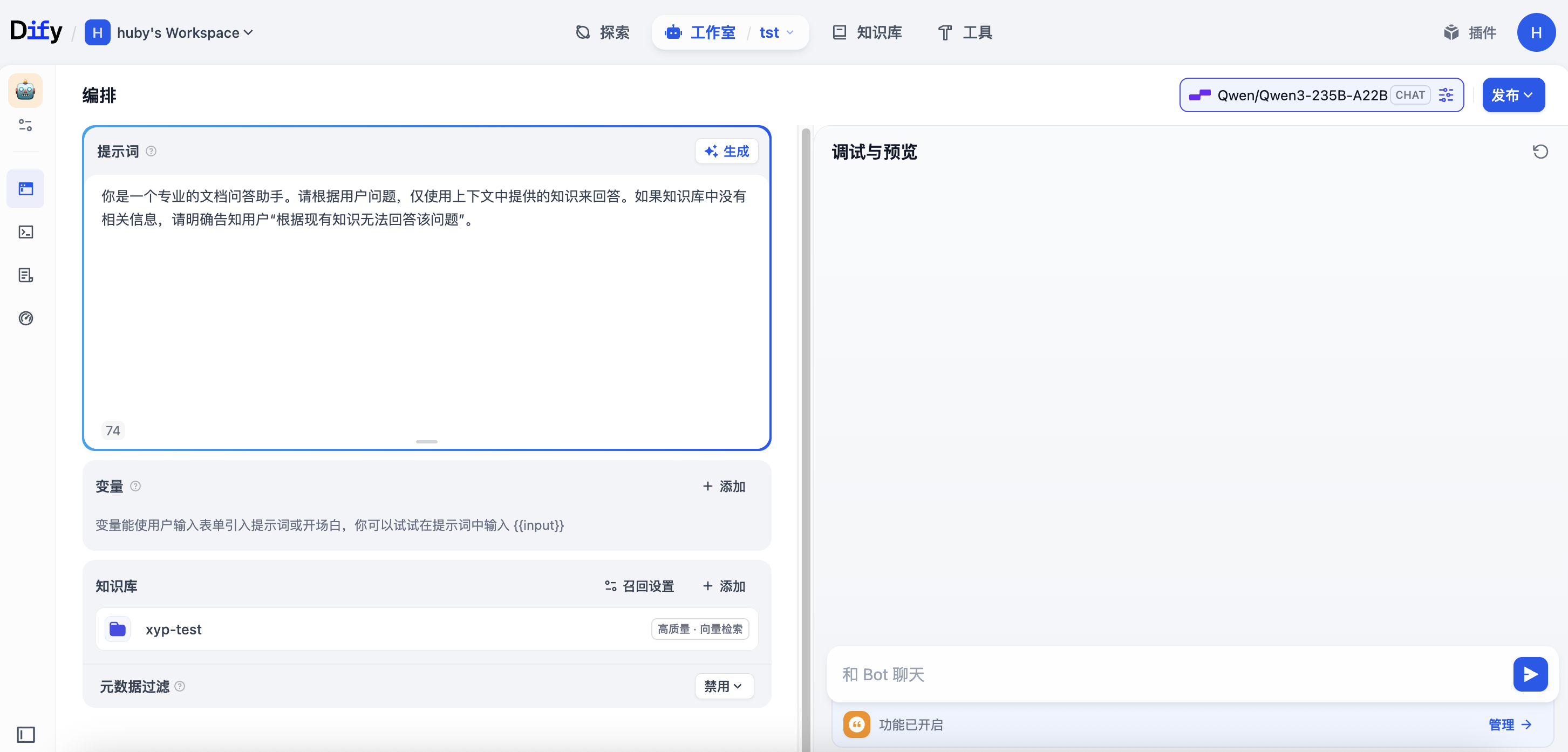
创建后,您将进入应用的"编排"页面。这是配置 AI 行为的核心区域。
1. 填写提示词 (Prompt):
在"提示词"部分,定义助手的角色和任务。例如:
你是一个专业的知识助手,能够基于提供的知识库内容回答用户的问题。
请使用友好、专业的语气,并在回答时引用相关的知识片段。
如果知识库中没有相关信息,请诚实告知用户。
2. 关联知识库(关键步骤):
在"上下文"模块,点击"添加",然后选择我们之前创建并导入了数据的知识库(moi_data_repository)。这将使 AI 在回答问题时,能够检索和引用该知识库中的内容。
3. 配置开场白(可选):
在页面底部"添加功能"中,可以启用"对话开场白",为用户提供一个友好的欢迎语和一些示例问题。
3.3 调试和发布
- 在页面右侧的"预览与调试"窗口中,输入与您知识库相关的问题,测试助手的回答效果。
- 如果对结果满意,点击右上角的"发布"按钮。
- 发布后,您可以获得一个公开的 WebApp 链接,或使用 API 将其集成到您自己的产品中。
有关更详细的应用编排技巧,例如变量、工具调用等,请参阅 Dify 官方文档:聊天助手。
至此,您已完成从环境搭建、数据导出到智能体构建的完整流程。
观看直播回放,获取更详尽的实战演示与内容解析
观看直播回放,获取更详尽的实战演示与内容解析
直播 Q&A 环节
Q:与其他开源方案 (如 LangChain + Chroma) 相比有什么优势?
A: 核心差异在于两者的定位:LangChain + Chroma 是一个"开发者工具集",而我们的方案是一个"一体化的企业级平台"。基于工具集,开发者仍需编写大量代码来粘合数据处理、存储与应用逻辑,开发与维护成本高昂。在实际项目中,非结构化数据处理往往是复杂度最高、最耗费精力的环节,而这正是 MOI 旨在解决的核心问题。
Q:Dify 和 MOI 之间的连接是实时的吗?
A: 在此次演示中,我们展示的是一个"数据导出任务"。然而,MOI 的核心优势在于其"自动化工作流":该任务可配置为定时触发(如每5分钟一次),或由外部API事件(如新文件上传)触发。这种机制虽非毫秒级的流式同步,但其"准实时"特性足以满足企业级 RAG 的知识更新需求,能有效解决常见的"知识更新延迟"痛点。
Q:MOI 的多模态处理具体支持哪些格式?
A: MOI 平台具备强大的多模态数据处理能力,原生支持文档、图片、音频、视频等各类非结构化数据。