【datawhale】RAG学习笔记
文章目录
- 介绍Introduction
- 定义definition
- 组件composition
- 优势why RAG
- 上手how to begin
- 基础工具链选择
- 四步构建最小可行系统(MVP)
- 新手友好方案
- 评估指标
基于datawhale的 all-in-rag共学
介绍Introduction
定义definition
RAG(Retrieval-Augmented Generation)是一种融合信息检索与文本生成的技术范式。
组件composition
1. **索引(Indexing)** 📑:将非格式化文档(PDF/Word等)分割为碎片,通过嵌入模型转换来支持数据。
2. **检索(Retrieval)** 🔍️:基于查询语义,从支持数据库聚合最相关的文档片段(Context)。
3. **生成(Generation)** ✨:将搜索结果作为上下文输入LLM,生成自然语言响应。
随着发展,现在不断改进,如索引分层(对高频数据启用缓存机制),多模态扩展(支持图像/表格检索)
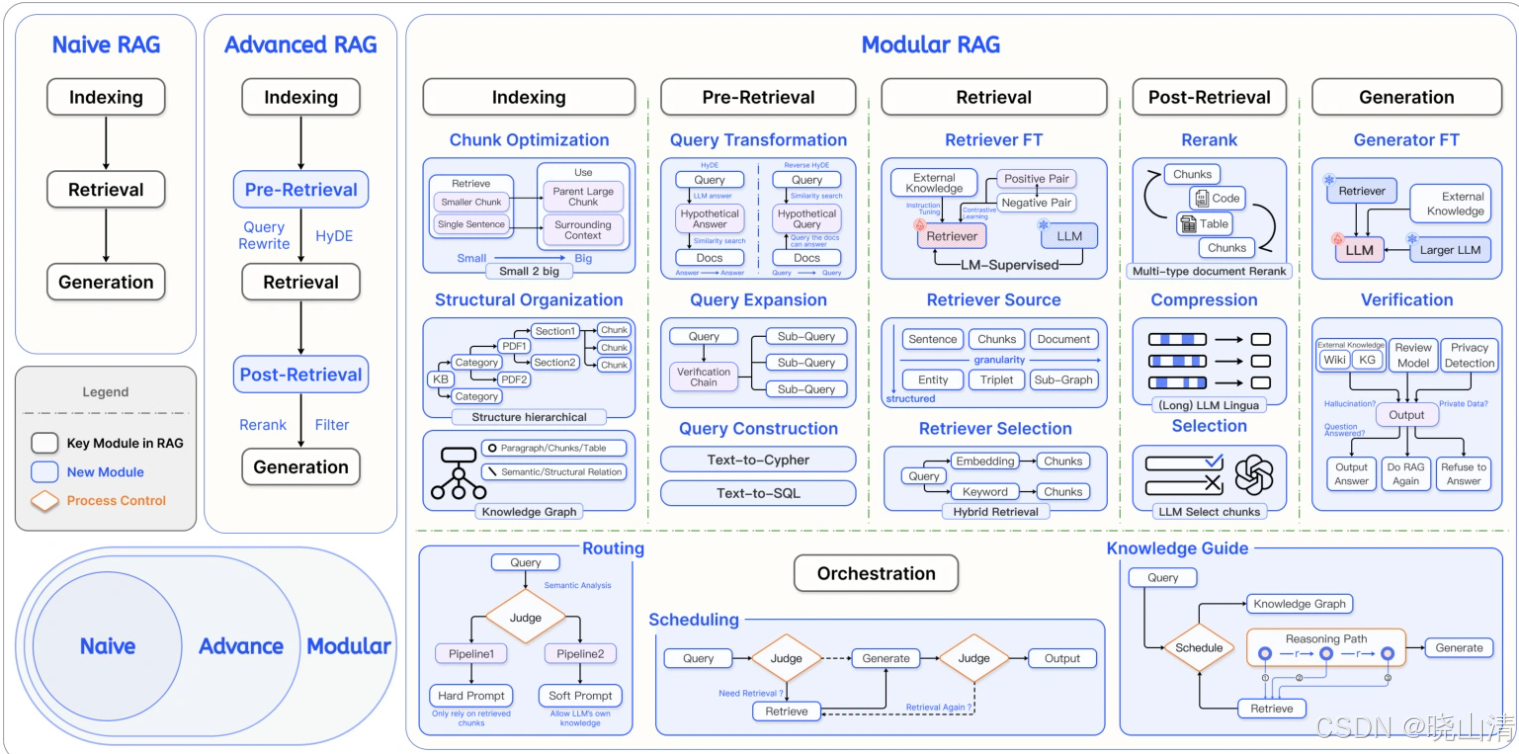
优势why RAG
静态知识→\rightarrow→实时检索外部知识库,支持动态更新
幻觉(幻觉)→\rightarrow→基于搜索内容生成,错误率降低
领域专业性不足→\rightarrow→引入领域特定知识库(如医疗/法律)
数据风险隐私→\rightarrow→本地化部署知识库,避免敏感数据泄露
上手how to begin
基础工具链选择
开发框架
LangChain:提供预置RAG链(如rag_chain),支持快速集成LLM与支持库
LlamaIndex:专为知识库索引优化,简化文档分块与嵌入流程
提供数据库
Milvus:开源高性能支撑数据库
FAISS:轻量级搜索库
Pinecone:提供数据库的云服务
四步构建最小可行系统(MVP)
- 资料准备
- 文本格式支持:PDF、Word、网页等
- 分块策略:按语义(如段落)或固定长度切分,避免信息碎片化
- 索引构建
- 嵌入模型:一些开源模型(如text-embedding-ada-002)或人工智能领域专用模型
- 支持化:将文本分块转换为支持存入数据库
- 搜索优化
- 搜索:结合关键词(BM25混合)与语义搜索(支持相似度)提升召回率
- 重排序(Rerank):用小模型筛选Top-K相关片段(如Cohere Reranker)
- 集成生成
- 提示工程:设计模板引导LLM融合搜索内容
- LLM选型:GPT、Claude、Ollama等(按成本/性能权衡)
新手友好方案
- LangChain4j Easy RAG:上传文档,自动处理索引与搜索
- FastGPT:知识库平台,可视化开源配置RAG流程
- GitHub 模板:如“TinyRAG”项目6,提供完整代码
评估指标
- 检索质量:上下文相关性(Context Relevance)
- 生成质量:答案忠实度(Faithfulness)、事实准确性