detr目标检测+deepsort/strongsort/bytetrack/botsort算法的多目标跟踪实现
目录
DETR 是什么?
DETR 如何检测物体
DETR 是如何运作的?
DETR 的优势和劣势
DETR 的优势
DETR 指标
deepsort、strongsort、bytetrack、botsor的介绍:
4.具体代码
UI界面设计
编辑 编辑
历史记录
5.完整代码实现+UI界面
DETR 是什么?
DETR(目标检测转换器) 是一种用于目标检测的深度学习模型。DETR 利用最初为自然语言处理 (NLP) 任务设计的 Transformer 架构作为其主要组件,以独特而高效的方式解决目标检测问题。
DETR 架构的核心组件是 Transformer。Transformer 是一种神经网络架构,以其自注意力机制而闻名,该机制使其能够捕捉数据序列或数据集中元素之间复杂的关联和依赖关系。在 DETR 中,Transformer 的自注意力机制在理解图像中对象的内容和空间关系方面发挥着至关重要的作用。
DETR 如何检测物体
DETR 处理目标检测问题的方式与 Faster R-CNN 或 YOLO 等传统目标检测系统不同。下面我们将概述 DETR 的目标检测方法。
- 直接集合预测 :与传统的先使用区域提议网络(RPN)再进行目标分类的两阶段过程不同,直接集合预测(DETR)将目标检测问题转化为直接集合预测问题。它将图像中的所有目标视为一个集合,旨在一次性预测它们的类别和边界框。
- 对象查询 :DETR 引入了“对象查询”的概念。这些查询代表模型需要预测的对象。对象查询的数量通常是固定的,与图像中的对象数量无关。
- Transformer 自注意力机制 :Transformer 的自注意力机制应用于从输入图像中提取的对象查询和空间特征(称为键和值)。这种自注意力机制使 DETR 能够学习对象及其空间位置之间复杂的关联和依赖关系。
- 并行预测 :DETR 利用自注意力机制收集的信息,同时预测每个目标查询的类别和位置(边界框)。这种并行预测方式不同于传统的目标检测器,后者通常依赖于顺序处理。
- 二分图匹配 :为了确保每个预测的边界框都与图像中的真实对象相对应,DETR 使用二分图匹配将预测框与真实对象关联起来。这一步骤提高了模型在训练过程中的精度。
DETR 是如何运作的?
在本节中,我们将深入分析 DETR 的架构,并详细探讨其每个关键组件,从而解释 DETR 如何变革目标检测领域。DETR 的整体架构如下图所示。
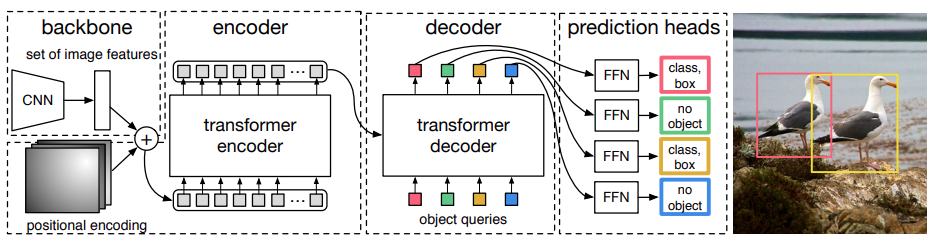
DETR 首先通过卷积神经网络 (CNN) 编码器处理输入图像。CNN 编码器的主要作用是从图像中提取高级特征表示。这些特征保留了图像中物体的空间信息,并作为后续操作的基础。众所周知,CNN 能够捕获层次化的视觉特征。
DETR 采用的 Transformer 架构如下图所示: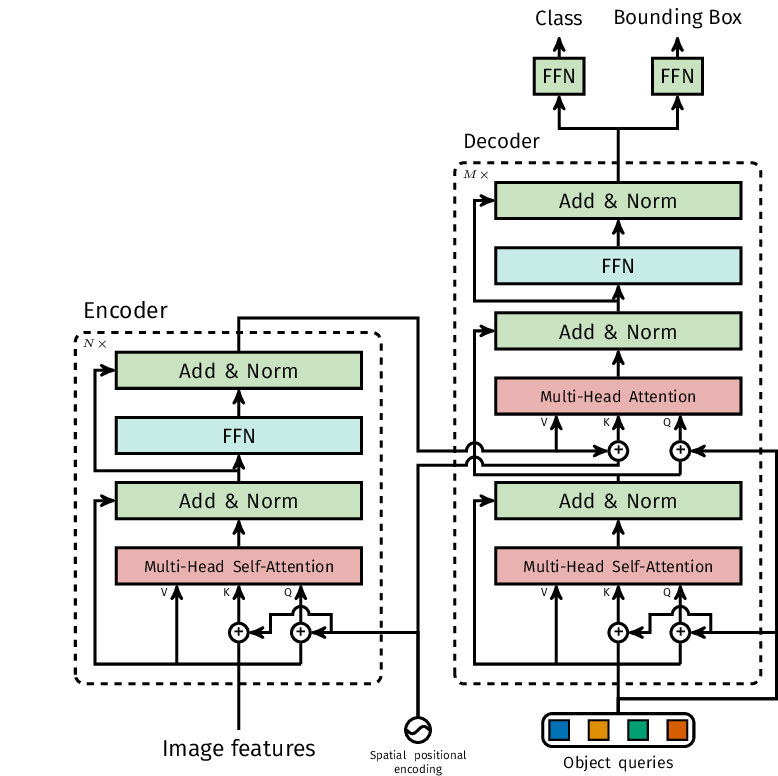
由于 Transformer 本身不具备空间理解能力,DETR 在 CNN 编码器的输出中添加了位置编码。这些位置编码能够告知模型图像不同部分之间的空间关系。这些编码对于 Transformer 理解物体的绝对位置和相对位置至关重要。
DETR 引入了“对象查询”、“键”和“值”的概念。这些组件是 Transformer 模型中自注意力机制的核心。对象查询是模型旨在预测的对象的可学习表示。
对象查询的数量通常是预先设定的,与图像中的对象数量无关。键和值对应于从卷积神经网络(CNN)编码器输出中提取的空间特征。键表示图像中的空间位置,而值包含特征信息。这些键和值用于自注意力机制,使模型能够权衡不同图像区域的重要性。
DETR 架构的核心在于其多头自注意力机制。该机制使 DETR 能够捕捉图像中物体之间复杂的关联和依赖关系。每个注意力头可以同时关注图像的不同方面和区域。多头自注意力机制使 DETR 能够理解局部和全局上下文,从而提升其目标检测能力。
为了确保每个预测的边界框都与图像中的真实对象相对应,DETR 采用了一种称为二分匹配的技术。该过程将预测的边界框与训练数据中的真实对象关联起来,从而有助于在训练过程中改进模型。
DETR 的优势和劣势
在了解了 DETR 的基本原理和运行机制之后,有必要深入分析这种广泛应用的目标检测框架的优缺点。掌握 DETR 的优势和局限性,有助于您在选择适合自身计算机视觉需求的解决方案时做出明智的决定。
DETR 的优势
以下是 DETR 架构的一些主要优势。
- 端到端目标检测 :DETR 提供端到端的目标检测解决方案,无需单独的区域提议网络和后处理步骤。这简化了整体架构并优化了目标检测流程。
- 并行处理 :得益于 Transformer 架构,DETR 能够同时预测图像中所有对象的类别和边界框。与顺序方法相比,这种并行处理方式能够显著加快推理速度。
- 有效利用自注意力机制 :DETR 中自注意力机制的使用使其能够捕捉物体及其空间环境之间复杂的关联关系。这显著提高了物体检测的准确率,尤其是在物体密集或重叠的场景下。
DETR 指标
DETR 最初发布时,作者的主要目标是超越 Faster R-CNN 基线模型。然而,在当前情况下,增强型 Faster R-CNN ResNet50 FPN V2 的性能优于 DETR 模型。
接下来,我们将更详细地分析性能对比。
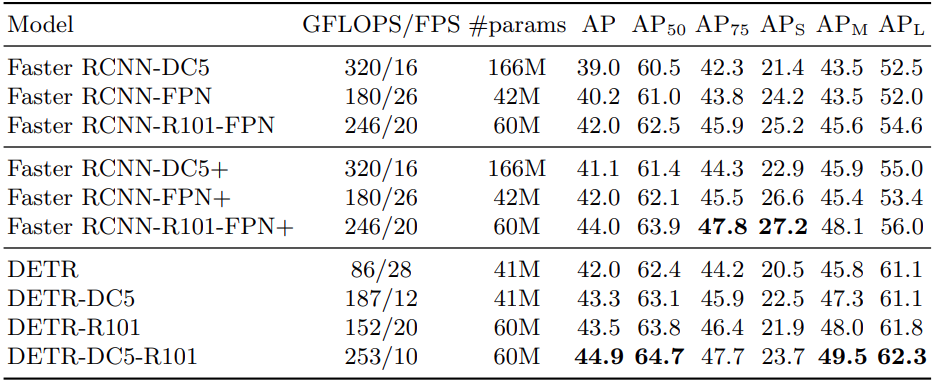
不同检测 Transformer 模型和 Faster R-CNN 模型的性能比较。 来源
从上图可以看出,这里考虑了四种不同的 DETR 模型。第一种是使用 ResNet50 骨干网络构建的基本 DETR 模型。第二种变体采用了 ResNet101 骨干网络。
“DC5”代表一种性能有所提升但速度较慢的模型。该变体采用了扩张的 C5 阶段,提高了 CNN 主干网络最后阶段特征图的分辨率。随后进行的两倍放大处理,使得对较小目标的检测更加精确。
值得注意的是,DC5 模型不会导致参数数量增加。
仔细观察后可以发现,采用 ResNet101 骨干网络的 DETR DC5 模型,其 mAP 值高达 44.9,是整个集成模型中表现最好的模型。
deepsort、strongsort、bytetrack、botsor的介绍:
https://blog.csdn.net/m0_56175815/article/details/148975319?spm=1001.2014.3001.5501
https://blog.csdn.net/m0_56175815/article/details/148975501?spm=1001.2014.3001.5501
https://blog.csdn.net/m0_56175815/article/details/148975528?spm=1001.2014.3001.5501
4.具体代码



UI界面设计


历史记录

5.完整代码实现+UI界面
视频,笔记和代码,以及注释都已经上传网盘,放在主页置顶文章