Spring AI + MySQL 实现文件内容相似度的简单检测 | 含源码
目录
前言
前置工作01:使用 Apache Tika 提取文件文本
前置工作02:自定义文本分段器进行文本分段
编码实现文本分段器
在 SpringAI 中如何使用向量模型
向量模型是什么
SpringAI 配置向量模型
向量入库与出库
相似度计算
编码实现余弦相似度算法
编码实现小顶堆 TopK 检索算法
相似度报告生成实现
参考
前言
在做一个 AI 求职的比赛项目中,遇到了一个有趣的需求:用户上传自己的简历文件后,系统需要计算并返回该简历与其他用户简历之间的相似度。想要实现这样的功能,这就意味着我们经过如下的步骤:

熟悉向量检索的话可能知道,借助 Redisearch 可以将 Redis 用作向量数据库;然而,考虑到这只是一个学生比赛项目,初期并未引入 Redis 。因此,我们最终选择了 Spring AI + MySQL 的方案,而且在实践过程中也可以简要学习到很多大模型的知识。为了便于讲解和演示,我将这部分功能单独抽离出来。在这篇博客中,你可以了解到:
-
SpringAI 使用向量模型的前置工作
-
在 SpringAI 中如何使用向量模型
-
如何编码实现余弦相似度检测
-
如何编码实现小顶堆 TopK 检索
由于篇幅限制,本文仅展示部分核心代码。如果你对完整实现感兴趣,欢迎访问我的 Gitee 仓库(gitee.com/nanqq/nanq-coding)获取全部示例代码,运行效果如下:
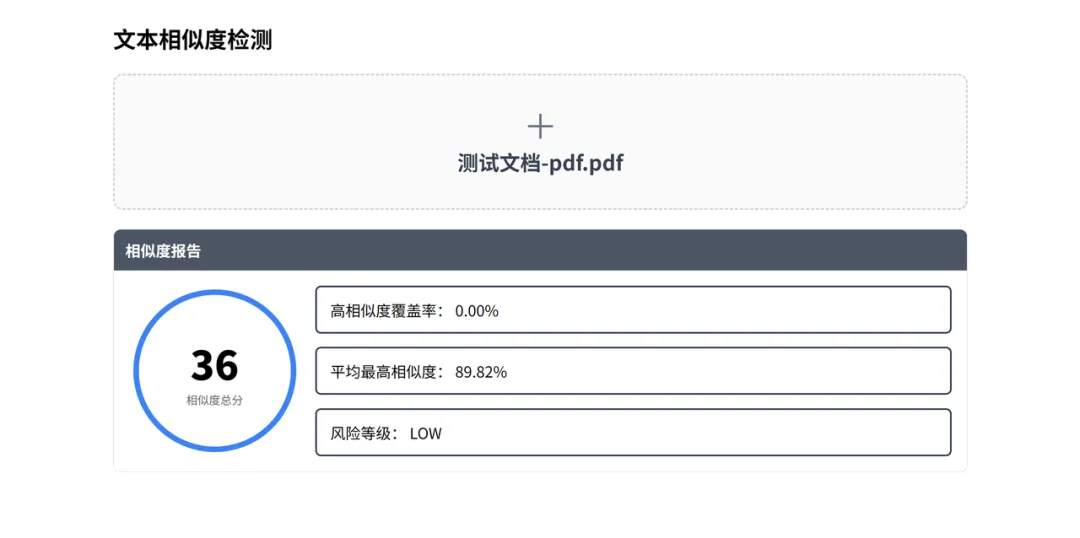
接下来就依次拆解搭建步骤。
前置工作01:使用 Apache Tika 提取文件文本
Apache Tika 是用于自动识别文件类型并提取文本与元数据的开源工具包,通过 Tika ,我们可以将 非结构化文档转为可处理的文本 ,为后续的向量化和相似度检索提供输入。首先需要引入依赖:
<!-- Apache Tika 核心功能 -->
<dependency><groupId>org.apache.tika</groupId><artifactId>tika-core</artifactId><version>2.9.2</version>
</dependency><!-- Apache Tika 标准解析器包,支持多种文件格式(PDF、Word、Excel、PPT 等) -->
<dependency><groupId>org.apache.tika</groupId><artifactId>tika-parsers-standard-package</artifactId><version>2.9.2</version>
</dependency>想要上传文件给 TiKa 处理,就需要文件上传的接口,接收上传文件并从文件输入流提取文本。
/**
* 上传文件,抽取可读文本内容
*/
@PostMapping(value = "/{textId}/upload", consumes = MediaType.MULTIPART_FORM_DATA_VALUE)public UploadResp uploadAndVectorize(@PathVariable Long textId, @RequestPart("file") MultipartFile file) throws Exception {String mime = file.getContentType();String name = file.getOriginalFilename();// 通过 Tika 抽取文本String content = tika.parseToString(file.getInputStream());// ...
}通过这里的代码就可以发现,Tika 是很简单易用的,仅需一行代码 就可以完成文本提取。而且还 支持多种格式 ,比如PDF、Word、Excel、PPT、TXT 等。
前置工作02:自定义文本分段器进行文本分段
因为 Tika 只负责文本提取,并不负责分段,所以我们就需要自定义分段的逻辑。那么为什么 Tika 做了文本解析的工作,还需要文本分段呢?主要有以下几点原因:
-
向量化需要合适长度的文本,将整个文档作为单个向量会丢失很多细节
-
模型对文本长度有限制,过长文本可能被截断
-
计算相似度是按片段以定位具体相似部分,文档粒度太大,就无法定位到具体相似段落
接下来我们就继续实现 自定义文本分段器 。
编码实现文本分段器
首先,我们将 Tika 提取出的文本与句子按照一定的规则进行 规范化 :
// 规范化并按句末标点分句:将句末标点后插入换行,再按空行切分
String[] raw = text.replace('\r', '\n') // 换行符.replaceAll("[。!?!?]", "$0\n") // 在句末标点后插入换行,保留原标点.split("\n+"); // 按连续换行分割这段代码比较生硬,在这里举一个被这段代码处理后的例子:
输入: "这是第一句。这是第二句!这是第三句?"
代码处理后: ["这是第一句。", "这是第二句!", "这是第三句?"]然后 清洗文本 ,以得到可用的句子列表:
// 清洗:去空白、移除空串
List<String> cleaned = Arrays.stream(raw).map(String::trim).filter(s -> !s.isEmpty()).collect(Collectors.toList());最后 控制片段的长度 ,分段规则与代码实现如下:
| 场景 | 句子长度 | 处理方式 | 原因 |
|---|---|---|---|
| 正常句子 | < 500字 | 聚合段(缓冲区累积) | 可以累积多个短句,达到300字目标。没有缓冲区,有的向量片段过短,导致向量效果差 |
| 超长句子 | ≥ 500字 | 硬切(直接切分) | 单个句子就超过限制,必须硬切,不能累积 |
List<String> result = new ArrayList<>();StringBuilder buf = new StringBuilder();for (String s : cleaned) {// 聚合段:控制单段最大到 300 字,超过则先输出缓冲区if (buf.length() + s.length() > 300) {if (buf.length() > 0) {result.add(buf.toString());buf.setLength(0);}}// 超长句子:按 500 字硬切,保证不会出现过长片段if (s.length() > 500) {for (int i = 0; i < s.length(); i += 500) {result.add(s.substring(i, Math.min(s.length(), i + 500)));}} else {if (buf.length() > 0) buf.append('\n');buf.append(s);}}在 SpringAI 中如何使用向量模型
向量模型是什么
向量模型(Embedding Model)将文本转换为 数值向量(数值向量就是浮点数数组),将语义信息编码为可计算的数值。语义相近的文本,其向量在空间中更接近 。 例如:
-
文本:"我喜欢编程" → 向量:[0.23, -0.45, 0.67, ..., 0.12]
-
文本:"我爱写代码" → 向量:[0.25, -0.43, 0.65, ..., 0.11]
那为什么需要向量模型呢?传统文本只能做字面匹配,无法理解语义。例如:"汽车" 和 "车辆" 在传统方法中不匹配,但语义相近。向量模型能捕捉 语义相似性 ,以及进行向量相似度的 快速计算 ,适合在海量文档中查找相似内容。
SpringAI 配置向量模型
完成了对于文件处理的前置工作,以及了解简单的概念后,就可以使用向量模型了。想要在 SpringAI 中使用向量模型,首先需要 引入 SpringAI 依赖 :
<!-- SpringAI DashScope -->
<dependency><groupId>com.alibaba.cloud.ai</groupId><artifactId>spring-ai-alibaba-starter-dashscope</artifactId><version>1.0.0.4</version>
</dependency>在配置文件里,也需要配置我们想要使用的 向量模型 :
ai:dashscope:api-key: your-api-keyembedding:options:model: text-embedding-v2与普通的对话大模型不同,text-embedding-v2 是专门用于文本向量化的模型。Spring AI 提供了一个 EmbeddingModel 接口,用于将 文本或文档转换为向量 。SpringAI 可以根据配置自动创建 Bean,在这里,我们通过构造函数注入使用:
private final EmbeddingModel embeddingModel;向量入库与出库
首先需要对文件进行 文本分段处理 。使用我们之前自定义的自定义文本分段器即可:
private final TextSegmenter textSegmenter;// ...List<String> segments = textSegmenter.segment(fullText);
if (segments.isEmpty()) return 0;文本分段完成后,就需要调用向量模型 计算向量 :
// 计算嵌入向量
float[] vectorArray = embeddingModel.embed(seg); 在控制台的输出中,我们可以发现 文本片段被转换为浮点数数组 :

随后将 向量序列化 以方便入库:
// 向量序列化与存储
String segmentId = segmentIdGenerator.idFor(seg);
String content = seg;
if (content != null && content.length() > 500) content = content.substring(0, 500);
DocumentVector dv = new DocumentVector();
dv.setTextId(textId);
dv.setSegmentId(segmentId);
dv.setContent(content);
dv.setEmbeddingVector(vectorCodec.serialize(vectorArray));序列化的具体实现使用 JSON 格式 ,便于存储与读取:
private final ObjectMapper objectMapper;// ...@Override
public String serialize(float[] vector) {try {// 以 JSON 数组形式持久化return objectMapper.writeValueAsString(vector);} catch (Exception e) {throw new IllegalStateException("序列化嵌入向量失败", e);}
}相反地,在从数据库读取时也需要 反序列化 ,便于进行后续的相似度计算:
// 反序列化向量,构建便于计算的数据结构
Map<String, double[]> segVec = new HashMap<>();
for (var s : segments) {segVec.put(s.getSegmentId(), vectorCodec.deserialize(s.getEmbeddingVector()));
}
Map<DocumentVector, double[]> corpusMap = new HashMap<>();
for (var c : corpus) {corpusMap.put(c, vectorCodec.deserialize(c.getEmbeddingVector()));
}反序列化的具体实现也是将 JSON 字符串还原为数组 :
public double[] deserialize(String json) {//...try {// 直接反序列化为 double[],配合后续相似度计算的双精度实现double[] arr = objectMapper.readValue(json, double[].class);return arr == null ? new double[0] : arr;} catch (Exception e) {throw new IllegalArgumentException("反序列化嵌入向量失败", e);}
}相似度计算
在相似度计算中,我们采用 小顶堆检索与余弦相似度相结合 的方案。
大致而言,小顶堆作为一种高效的 TopK 检索算法,专注于从大量候选中快速找出 最相似的 K 个结果 ;而余弦相似度则作为衡量向量间相似程度的度量标准,负责计算 样本之间的相似性 。
在该方案中,小顶堆以余弦相似度作为比较依据,动态维护当前最优的 TopK 结果集 ,从而高效完成相似度检索任务。
编码实现余弦相似度算法
/*** 余弦相似度计算工具*/
public class CosineSimilarityUtils {/*** 计算两个向量的余弦相似度** @param a 向量A* @param b 向量B* @return 余弦相似度 [-1, 1]*/public static double cosine(double[] a, double[] b) {// 参数为空/维度不一致直接返回0if (a == null || b == null || a.length == 0 || b.length == 0 || a.length != b.length) return 0.0;double dot = 0.0;double na = 0.0;double nb = 0.0;// 累计点积与各自范数平方for (int i = 0; i < a.length; i++) {dot += a[i] * b[i];na += a[i] * a[i];nb += b[i] * b[i];}// 任一向量为零向量:相似度定义为0,避免除零if (na == 0.0 || nb == 0.0) return 0.0;return dot / (Math.sqrt(na) * Math.sqrt(nb));}
}然后我们需要进行进一步的 封装 ,以便在 TopK 检索中使用:
/*** 相似度度量接口* 定义两向量之间的相似度计算方式*/
public interface SimilarityMetric {/*** 计算两个同维度向量的相似度值。* @param a 向量A* @param b 向量B* @return 相似度(数值越大越相似)*/double similarity(double[] a, double[] b);
}编码实现小顶堆 TopK 检索算法
小顶堆是一种满足“父节点值 ≤ 子节点值”的完全二叉树结构,其堆顶元素即为当前堆中的最小值。
那么,为何在 TopK 检索中选用小顶堆呢?原因在于:当我们维护一个大小固定为 K 的小顶堆时,堆顶始终代表当前选中的 K 个元素中的最小值 。对于新到来的元素,只需将其与堆顶比较——若其值大于堆顶,则说明它有资格进入当前 TopK,此时可将堆顶替换并重新调整堆结构;反之,若小于或等于堆顶,则可直接忽略。这种机制既能高效维护 TopK 结果,又避免了对全部数据进行排序的高开销。
那么接下来就尝试逐步实现。首先,使用优先队列 初始化小顶堆 :
PriorityQueue<Map.Entry<T, Double>> heap = new PriorityQueue<>(Map.Entry.comparingByValue());而后,遍历语料以 计算相似度 :
for (Map.Entry<T, double[]> e : corpus.entrySet()) {double[] v = e.getValue();// 维度不一致直接跳过if (v == null || v.length != query.length) continue;double sim = metric.similarity(query, v); // 使用余弦相似度// ...}以及实现 维护小顶堆 的编码逻辑:
if (heap.size() < k) {// 未满K,直接入堆heap.offer(Map.entry(e.getKey(), sim));} else if (heap.peek().getValue() < sim) {// 比堆顶大:弹出最小,再加入heap.poll();heap.offer(Map.entry(e.getKey(), sim));
}最后 排序输出 。将堆转为列表,并按相似度降序排序,最后返回 TopK 结果:
// 结果按相似度降序输出
List<Map.Entry<T, Double>> top = new ArrayList<>(heap);
top.sort((a, b) -> Double.compare(b.getValue(), a.getValue()));
return top;在项目中,两者相互配合,找出 最相近的候选片段 :
for (var s : segments) {double[] v = segVec.get(s.getSegmentId());if (v == null || v.length == 0) continue;// 使用 TopK 检索策略 + 相似度度量,获取最相近候选List<Map.Entry<DocumentVector, Double>> top = topKSearcher.topK(v, corpusMap, k, similarityMetric);
}相似度报告生成实现
至此,最核心的处理流程实际上已经完成。然而,直接向客户展示一堆原始数据或数值显然不够友好,因此还需对结果进行进一步加工与组织,最终生成清晰、易读的报告,以便用户直观理解。
在调用相似度计算接口时,首先对用户输入的参数进行合法性校验:
public SimilarityReportDTO computeSimilarityReport(Long textId, Integer topK, Double threshold) {// TopK 合法化:限制在 [1, 20],默认为 5int k = topK == null ? 5 : Math.max(1, Math.min(20, topK));// 阈值夹取:限制在 [0.5, 0.99],默认为 0.90double tau = threshold == null ? 0.90 : Math.max(0.5, Math.min(0.99, threshold));// ...
} 接下来,分别加载待检测文本的片段向量和用于比对的语料库:
// segments:当前文本(textId)的所有片段向量
List<DocumentVector> segments = documentVectorMapper.selectByTextId(textId);
if (segments == null || segments.isEmpty()) {throw new RuntimeException("该文本尚未向量化");
}
// corpus:排除当前文本后的其他文档片段
List<DocumentVector> corpus = documentVectorMapper.selectCorpusForSimilarity(textId);
if (corpus == null || corpus.isEmpty()) {throw new RuntimeException("对比语料为空");
}对应的 SQL 查询如下,最多取 2000 条作为比对语料:
<select id="selectCorpusForSimilarity" parameterType="long" resultMap="DocumentVectorMap">SELECT * FROM document_vectorWHERE text_id != #{excludeTextId}LIMIT 2000
</select>对每个待检片段,在语料库中执行 TopK 相似片段检索,并记录关键指标:
int highSimCount = 0;
double sumTopSim = 0.0;for (var s : segments) {double[] v = segVec.get(s.getSegmentId());if (v == null || v.length == 0) continue;List<Map.Entry<DocumentVector, Double>> top = topKSearcher.topK(v, corpusMap, k, similarityMetric);if (top.isEmpty()) continue;double bestSim = top.get(0).getValue(); // 取 Top1 相似度sumTopSim += bestSim;if (bestSim >= tau) highSimCount++;
}基于结果,聚合生成全局的评估指标。具体规则与代码实现如下:
| 指标 | 计算方式 |
|---|---|
| 覆盖率(Coverage) | 达到阈值(≥τ)的片段数 / 总片段数 |
| 平均 Top1 相似度(AvgTopSim) | 所有片段最高相似度的算术平均值 |
| 综合评分(Overall Score) | 100 × (0.6 × Coverage + 0.4 × AvgTopSim) |
| 风险等级(Risk Level) | HIGH(≥70)、MEDIUM(40–69)、LOW(<40) |
double coverage = segments.isEmpty() ? 0 : (double) highSimCount / segments.size(); // 达阈值片段占比
double avgTopSim = segments.isEmpty() ? 0 : (sumTopSim / segments.size()); // 平均最高相似度
double overall = 100.0 * (0.6 * coverage + 0.4 * avgTopSim); // 加权综合评分
String risk = overall >= 70 ? "HIGH" : (overall >= 40 ? "MEDIUM" : "LOW"); // 风险等级判定最后生成报告 DTO ,将计算结果封装为标准化的报告对象,便于前端展示:
SimilarityReportDTO report = new SimilarityReportDTO();
report.setTextId(textId);
report.setCoverage(coverage);
report.setAvgTopSim(avgTopSim);
report.setOverallScore(Math.round(overall * 10.0) / 10.0); // 保留一位小数
report.setRiskLevel(risk);
report.setGeneratedAt(LocalDateTime.now());
return report;参考
-
Spring AI 文档:spring.io/projects/spring-ai