Redis的知识整理《1》
前言
1、Redis 为什么快?单线程模型?
2、Redis 数据类型及使用场景?(String、Hash、ZSet、Bitmap)
3、缓存穿透、击穿、雪崩?如何解决?
4、Redis 持久化:RDB vs AOF?混合持久化?
5、Redis 集群模式?Slot 分配?故障转移?
6、如何用 Redis 实现分布式锁?(RedLock?Lua 脚本?)
1、Redis 为什么快?单线程模型?
一、Redis 为什么快?
1. 基于内存操作
-
数据存储在内存中,读写速度远高于磁盘(纳秒 vs 毫秒);
-
避免磁盘 I/O 瓶颈。
2. 高效的数据结构
- String:简单动态字符串(SDS),O(1) 获取长度,避免缓冲区溢出;
- Hash:ziplist(小数据) + hashtable(大数据);
- List:quicklist(ziplist 双向链表);
- Set:intset(整数) + hashtable;
- ZSet:ziplist(小数据) + skiplist(跳表,大数据)。
💡 跳表优势:实现简单,支持范围查询,性能 ≈ 红黑树。
3. 单线程模型 + I/O 多路复用
-
单线程处理命令:避免多线程竞争(无锁开销);
-
I/O 多路复用(epoll/kqueue):
-
一个线程监听多个 socket;
-
事件驱动,非阻塞 I/O;
-
高并发下 CPU 利用率高。
-
4. 其他优化
-
避免上下文切换:单线程无切换开销;
-
纯 C 语言实现:执行效率高;
-
RESP 协议简单:解析开销低。
二、Redis 是单线程吗?
1. 6.0 之前:纯单线程
-
网络 I/O + 命令执行 都在一个线程;
-
优点:简单、无锁;
-
缺点:无法利用多核。
2. 6.0+:多线程 I/O
-
网络 I/O 多线程(读写 socket);
-
命令执行仍单线程(保证原子性);
-
配置:io-threads
4(默认关闭)。
💡 为什么命令执行不并行?
- Redis 命令多为简单操作,CPU 不是瓶颈;
- 并行需加锁,复杂度飙升,违背 Redis 设计哲学。
三、最佳实践
- 提到 Redis 7.0 的函数式编程(Function API);
- 举例:在秒杀系统中,单机 Redis 支撑 10w QPS;
- 强调:Redis 快的核心是“内存 + 单线程 + 高效数据结构”。
2、Redis 数据类型及使用场景?
一、5 大核心数据类型
| 类型 | 底层结构 | 使用场景 | 命令示例 |
|---|---|---|---|
| String | SDS(Simple Dynamic String) | 缓存、计数器、分布式锁 | set, incr, get |
| Hash | ziplist(<512 字段 & <64 字节) hashtable(否则) | 对象存储(如用户信息) | hset, hgetall |
| List | quicklist(ziplist 双向链表) | 消息队列、最新列表 | lpush, rpop, lrang |
| Set | intset(整数) hashtable(否则) | 标签、共同好友 | sadd, sinter |
| ZSet | ziplist(<128 元素 & <64 字节) skiplist(否则) | 排行榜、延迟队列 | zadd, zrang, zrevrank |
二、高级数据结构
1. Bitmap(位图)
-
本质:String 的 bit 操作;
-
场景:用户签到、活跃统计;
-
命令:setbit, getbit, bitcount;
-
优势:1 亿用户签到仅需 12MB。
2. HyperLogLog
-
场景:UV 统计(去重计数);
-
精度:误差率 ≈ 0.81%;
-
内存:固定 12KB。
3. GEO
-
场景:LBS(附近的人);
-
底层:ZSet + GeoHash。
三、最佳实践
-
提到 Redis 7.0 的 JSON 模块;
-
举例:用 ZSet 实现延迟队列,替代 RabbitMQ TTL;
-
强调:选择数据类型时,优先考虑内存占用和命令复杂度。
3、缓存穿透、击穿、雪崩?如何解决?
一、三大问题对比
| 问题 | 原因 | 解决方案 |
|---|---|---|
| 穿透 | 查询不存在的数据,绕过缓存打 DB | 布隆过滤器 + 空值缓存 |
| 击穿 | 热点 Key 过期瞬间,大量请求打 DB | 互斥锁 + 永不过期 |
| 雪崩 | 大量 Key 同时过期,DB 瞬时压力 | 随机过期时间 + 高可用 |
二、详细解决方案
1. 缓存穿透
-
布隆过滤器(Bloom Filter):
-
初始化时加载所有合法 key;
-
查询前先 check,不存在直接返回。
-
-
空值缓存:
// 查询 DB 无结果,缓存 null(短 TTL,如 60s) redis.setex("user:123", 60, "null");
2. 缓存击穿
-
互斥锁(Mutex Lock):
String lockKey = "lock:user:123";
if (redis.setnx(lockKey, "1")) {redis.expire(lockKey, 10);// 查询 DB,写缓存redis.del(lockKey);
} else {// 短暂等待后重试Thread.sleep(50);
}
-
逻辑过期:
-
缓存中存过期时间;
-
后台线程异步更新。
-
3. 缓存雪崩
-
随机过期时间:
int expire = 3600 + new Random().nextInt(600); // 1h ± 10min
redis.setex(key, expire, value);
- 高可用:Redis 集群 + 哨兵;
- 熔断降级:Hystrix 保护 DB。
三、最佳实践
- 提到 Redis 6.0 的客户端缓存(Client Side Caching);
- 举例:用布隆过滤器拦截 99% 的非法请求,DB QPS 从 1w 降至 100;
- 强调:穿透是“查不存在”,击穿是“热点过期”,雪崩是“批量过期”。
4、Redis 持久化:RDB vs AOF?混合持久化?
一、RDB(Redis Database)
1. 原理
-
快照:定时将内存数据写入磁盘(二进制文件 dump.rdb);
-
触发方式:
-
save(阻塞主线程);
-
bgsave(fork 子进程,COW 机制)。
-
2. 配置
save 900 1 # 15min 1 次修改
save 300 10 # 5min 10 次修改
save 60 10000 # 1min 1w 次修改
3. 优缺点
-
✅ 恢复快、文件小;
-
❌ 数据丢失(最后一次快照后修改)。
二、AOF(Append Only File)
1. 原理
-
日志:记录所有写命令(文本文件 appendonly.aof);
-
同步策略:
-
appendfsync always:每次写同步(安全,慢);
-
appendfsync everysec:每秒同步(默认,平衡);
-
appendfsync no:OS 决定(快,不安全)。
-
2. 重写(Rewrite)
-
目的:压缩 AOF 文件(合并冗余命令);
-
触发:bgrewriteaof(fork 子进程)。
3. 优缺点
-
✅ 数据安全(最多丢 1s);
-
❌ 文件大、恢复慢。
三、混合持久化(Redis 4.0+)
1. 原理
-
RDB + AOF 结合:
-
开头是 RDB 格式(快照);
-
后面是 AOF 格式(增量命令)。
-
2. 配置
aof-use-rdb-preamble yes
3. 优势
-
恢复速度 ≈ RDB;
-
数据安全 ≈ AOF。
四、最佳实践
- 提到 fork 子进程的 COW(Copy-On-Write)机制;
- 举例:混合持久化使重启时间从 10min 降至 30s;
- 强调:生产环境必须开启持久化,且定期备份。
5、Redis 集群模式?Slot 分配?故障转移?
如下所示: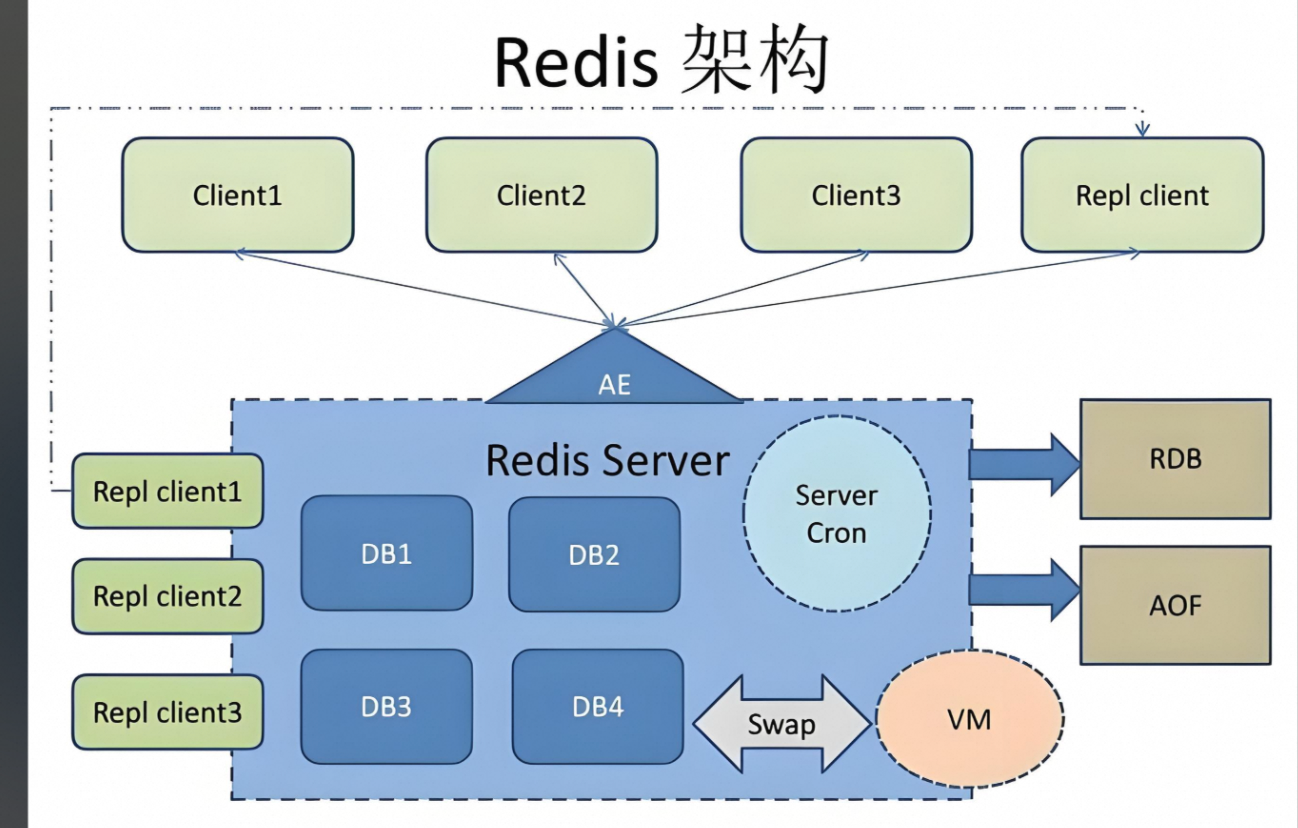
一、Redis Cluster 架构
-
无中心设计:所有节点平等;
-
数据分片:16384 个 Slot;
-
高可用:主从复制 + 自动故障转移。
二、Slot 分配
1. Slot 计算
-
slot = crc16(key) % 16384
-
客户端可本地计算,直接路由。
2. 节点负责 Slot
-
每个主节点负责一部分 Slot;
-
示例:3 主 3 从,每主负责 5461 个 Slot。
3. MOVED 重定向
-
客户端访问错误节点 → 返回 moved <slot> <ip:port>;
-
客户端更新路由表。
三、故障转移(Failover)
1. 检测
-
主观下线(PFail):节点认为主节点不可达;
-
客观下线(Fail):半数以上主节点认为主节点不可达。
2. 选举
-
从节点发起选举(Raft 算法);
-
获得多数主节点投票的从节点晋升为主。
3. Gossip 协议
-
节点间交换状态(meet/ping/pong);
-
传播集群拓扑。
四、最佳实践
-
提到 Redis Cluster 不支持多 key 操作跨 Slot(除非用 Hash Tag
{user1000}.order); -
举例:集群扩容时用 redis-cli --cluster reshard 迁移 Slot;
-
强调:至少 3 主 3 从才能容忍 1 节点故障。
6、如何用 Redis 实现分布式锁?
一、基础版(有缺陷)
// 1. 加锁
SET lock_key unique_value NX PX 30000// 2. 解锁(错误!)
DEL lock_key
问题:
-
误删:A 的锁过期,B 获取锁,A 删除 B 的锁;
-
死锁:业务异常未释放锁。
二、安全版(Lua 脚本)
1. 加锁
SET lock_key unique_value NX PX 30000
-
unique_value = UUID(标识持有者)。
2. 解锁(Lua 保证原子性)
if redis.call("GET", KEYS[1]) == ARGV[1] thenreturn redis.call("DEL", KEYS[1])
elsereturn 0
end
3. Java 调用
String script = "if redis.call('GET', KEYS[1]) == ARGV[1] then return redis.call('DEL', KEYS[1]) else return 0 end";
redis.eval(script, Collections.singletonList("lock_key"), Collections.singletonList(uuid));
三、高级方案
1. RedLock(争议大)
-
多个独立 Redis 节点;
-
获取多数节点锁才算成功;
-
问题:时钟漂移、运维复杂;
-
Redis 官方不推荐。
2. Redisson(生产推荐)
- 看门狗(Watchdog):自动续期(默认 30s,每 10s 续一次);
- 可重入:同一线程可多次加锁;
- 公平锁/读写锁:支持高级特性。
RLock lock = redisson.getLock("myLock");
lock.lock(); // 自动续期
try {// 业务
} finally {lock.unlock();
}
四、最佳实践
- 提到 锁过期时间 > 业务执行时间;
- 举例:用 Redisson 实现分布式限流器,0 超卖;
- 强调:不要用 RedLock,优先用 Redisson + 看门狗。