03|Langgraph | 从入门到实战 | 进阶篇 | 持久化
一、简介
本系列为Langgraph文章,最终以实现企业级项目。

该系列文章,以官方文档路径撰写,深入浅出并配以自己理解,配以GIF动图演示、适当扩展延伸官方案例以及源码讲解
当然如果你需要你也可以查看官方文档
- 官方文档:https://langchain-ai.github.io/langgraph/
- 中文文档:https://www.aidoczh.com/langgraph/tutorials/
最终实战项目目标:构建一个Agents Framework(智能代理框架) 多智能体协作企业系统
本文如若有错误地方,烦请指正,另外方便的话,麻烦点个赞关注一下,谢谢
本系列文章,配套项目源码地址:
我不喜欢碎片会搬运或者讲解,都是手敲运行,并且上传了github,你的点赞关注是我更新的动力!
https://github.com/wenwenc9/langgraph-tutorial-wenwenc9
- 📊 Agent-Graph:每个业务 Agent 以状态图形式编排节点、条件边与循环边;
- 🔧 工具体系:自动发现与注册工具,支持函数调用(tool calling),可扩展MCP服务;
- 🗄️ 记忆/持久化:使用 Postgres 作为 LangGraph 的 checkpointer 与 store,Redis缓存prompt;
- 📋 统一注册中心:自动发现、注册并预编译 Agent 图与工具;
- 💪 滚动窗口摘要算法压缩上下文,用户画像,短期记忆,长期记忆混合
- 🌐 API 网关:FastAPI 路由聚合,提供通用 chat、agents、session 等接口;
- 🔄 可插拔 LLM:通过模型工厂与配置驱动,统一管理多厂商 LLM。
- 🌀 prompt缓存:redis加载prompt,prompt-web热更新管理
- 👁️🗨️ RAG 向量数据库,与工程结合,结构化,非结构化管理检索,召回
- 🥰 下一步引导功能,猜你想要功能

Langgraph系列文章
01|Langgraph | 从入门到实战 | 基础篇
02|Langgraph | 从入门到实战 | workflow与Agent
langchain的系列文章(相信我把Langchain全部学一遍,你能深入理解AI的开发)
01|LangChain | 从入门到实战-介绍
02|LangChain | 从入门到实战 -六大组件之Models IO
03|LangChain | 从入门到实战 -六大组件之Retrival
04|LangChain | 从入门到实战 -六大组件之Chain
05|LangChain | 从入门到实战 -六大组件之Memory
06|LangChain | 从入门到实战 -六大组件之Agent
二、Persistence 持久化概念

LangGraph 拥有内置的持久化层,通过检查点器实现。当你使用检查点器编译图时,检查点器会在每个超级步骤中保存图状态的 checkpoint 。这些检查点会保存到 thread 中,在图执行后可以访问。由于 threads 允许在执行后访问图的状态.
在构建企业级 AI Agent 应用时,持久化(Persistence)是不可或缺的核心能力。想象一下这些场景:
- 用户与 Agent 的对话被意外中断,如何恢复上下文?
- 长时间运行的任务(如数据分析、报告生成)中途失败,如何避免从头开始?
- 人工审核流程需要暂停,几小时甚至几天后如何继续?
LangGraph 通过 Checkpoint(检查点)、Memory Store(记忆存储) 和 Durable Execution(持久化执行) 三大机制解决了这些问题.
我将官方2个部分合并到一起作为本篇文章内容
官方文档:https://docs.langchain.com/oss/python/langgraph/persistence
官方文档:https://docs.langchain.com/oss/python/langgraph/durable-execution
三、Checkpoint 检查点机制
官方文档:https://reference.langchain.com/python/langgraph/graphs/#langgraph.graph.state.CompiledStateGraph

本小节,会用到部分方法,注意此为graph 编译后的图的方法调用
1、什么是 Checkpoint?
Checkpoint(检查点)是 LangGraph 中的"快照"机制,它在工作流的关键节点自动保存状态,确保流程可以在中断后恢复。
核心特点:
- 自动保存:每个节点执行后自动创建检查点
- 线程隔离:通过 thread_id 区分不同的会话/任务
- 状态恢复:可以从任意检查点恢复执行
这也是我们定义的短期记忆的手段,通过thread_id 一个线程,也可以理解为一个session,对话窗口,比如kimi的,就是在一个会话窗口的上下文记忆

2、基础示例
我们创建一个工作流如下,从node_a 串行运行到 node_b:

from langgraph.graph import StateGraph, START, END
from langgraph.checkpoint.memory import InMemorySaver
from langchain_core.runnables import RunnableConfig
from typing import Annotated
from typing_extensions import TypedDict
from operator import addclass State(TypedDict):foo: strbar: Annotated[list[str], add]def node_a(state: State):return {"foo": "a", "bar": ["a"]}def node_b(state: State):return {"foo": "b", "bar": ["b"]}# 构建工作流
workflow = StateGraph(State)
workflow.add_node(node_a)
workflow.add_node(node_b)
workflow.add_edge(START, "node_a")
workflow.add_edge("node_a", "node_b")
workflow.add_edge("node_b", END)# 🔥 关键:启用 Checkpointer
checkpointer = InMemorySaver()
graph = workflow.compile(checkpointer=checkpointer)# 执行时指定 thread_id
config: RunnableConfig = {"configurable": {"thread_id": "1"}}
graph.invoke({"foo": ""}, config)
只需要工作流进行编译的时候,传入checkpointer指定检查点即可
参数说明:
InMemorySaver():内存型检查点存储,适合开发测试thread_id:会话唯一标识,用于隔离不同用户/任务的状态config:运行配置,必须包含 thread_id
3、获取状态快照

假定我们设计了一个工作流,共计10个节点,从第一节点到最后一个节点,从上一个节点到一下个节点,的输入输出都进行了快照。
StateSnapshot,
https://reference.langchain.com/python/langgraph/types/#langgraph.types.StateSnapshot
官方文档有对这个类方法的返回参数进行具体说明,这里不做累赘

3.1 get_state 获取当前快照
stateSnapshot_ = graph.get_state(config)
rich.print(stateSnapshot_)输出如下:

- values :通道的当前值
- next:每个任务中此步骤要执行的节点名称
- config:用于获取此快照的配置
- metadata:与此快照关联的元数据
- created_at:快照创建的时间戳
- parent_config :用于获取父快照的配置,如果有的话
- tasks:本步骤中要执行的任务。如果已尝试执行,可能包含错误
- interrupts:本步骤中发生且待解决的中断
这个是获取运行上面基础示例 代码的最后一个最新快照,可能看起来不是很明白,下面还有一个方法可以获取全部运行状态
3.2 get_state_history 获取历史快照
stateSnapshot_history = list(graph.get_state_history(config))
rich.print(stateSnapshot_history[::-1])
我们回过头来看看,我们设计的工作流从node_a 串行运行到 node_b,可以看到共计4个节点

我们看堆栈也是显示的4个快照

3.3 快照分析
我们依托于1.3.2 节的代码 输出如下内容,共计4个snapshot
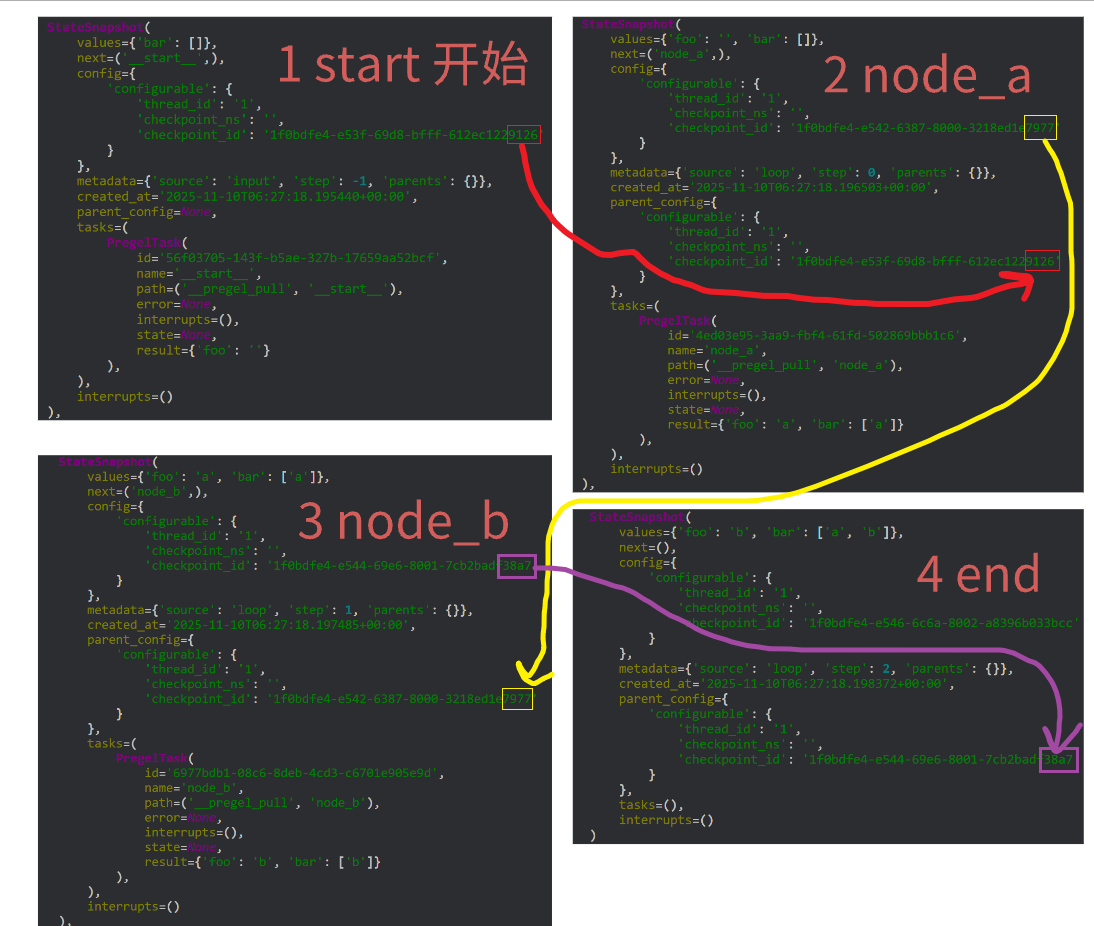
回顾一下字段内容:
- values :通道的当前值
- next:每个任务中此步骤要执行的节点名称
- config:用于获取此快照的配置
- metadata:与此快照关联的元数据
- created_at:快照创建的时间戳
- parent_config :用于获取父快照的配置,如果有的话
- tasks:本步骤中要执行的任务。如果已尝试执行,可能包含错误
- interrupts:本步骤中发生且待解决的中断
每一个config,跟parent_config都记录了当前跟上一个节点的一些配置信息,task记录了本次执行的任务内容
其余字段请,配合我上面的图观察琢磨
得益于langgraph的快照机制,我们可以实现很多内容
4、重放与更新(replay&update_state)
在前面的内容,我们学习了snapshot快照的的原理,现在我们将其具象化研究
4.1 replay 重执行
假定一个workflow是关于写研究报告的,假定有4个节点,并且是串行的工作流,分别是
- 大纲生成node
- 章节撰写node
- 章节填图node
- 文章聚合node
如果我们对于其中第3个节点的配图不满意,你说我们是让其重新执行第1节点到4个节点呢,还是单独让其从第3个节点重开始重新执行后面的步骤呢?
当然是从第3个节点开始
下面,我将用简答代码来体验一下
from langgraph.graph import StateGraph, END
from langgraph.checkpoint.memory import MemorySaver
from typing import TypedDict
from datetime import datetime
import time# 定义状态
class State(TypedDict):query: strstep1_result: strstep2_result: strstep3_result: str# 三个简单节点
def step1(state):now = datetime.now()formatted = now.strftime("%Y-%m-%d %H:%M:%S")print("执行 step1")return {"step1_result": f"步骤1: 时间{formatted}"}def step2(state):time.sleep(1)now = datetime.now()formatted = now.strftime("%Y-%m-%d %H:%M:%S")print("执行 step2")return {"step2_result": f"步骤2: 时间{formatted}"}def step3(state):time.sleep(1)now = datetime.now()formatted = now.strftime("%Y-%m-%d %H:%M:%S")print("执行 step3")return {"step3_result": f"步骤3: 时间{formatted}"}# 构建图
builder = StateGraph(State)
builder.add_node("step1", step1)
builder.add_node("step2", step2)
builder.add_node("step3", step3)
builder.set_entry_point("step1")
builder.add_edge("step1", "step2")
builder.add_edge("step2", "step3")
builder.add_edge("step3", END)app1 = builder.compile(checkpointer=MemorySaver())
app1
图例如下:

我们先简单运行
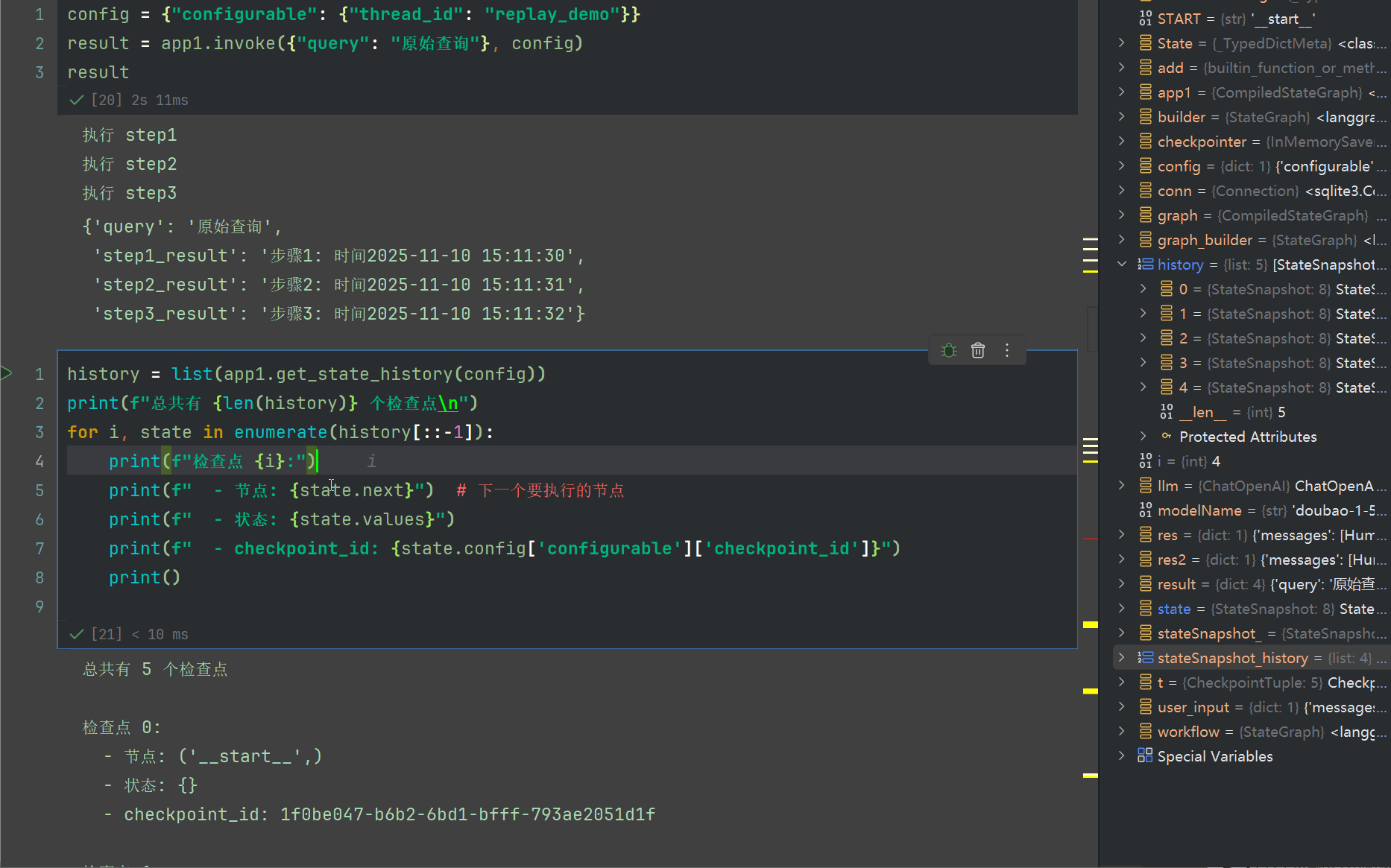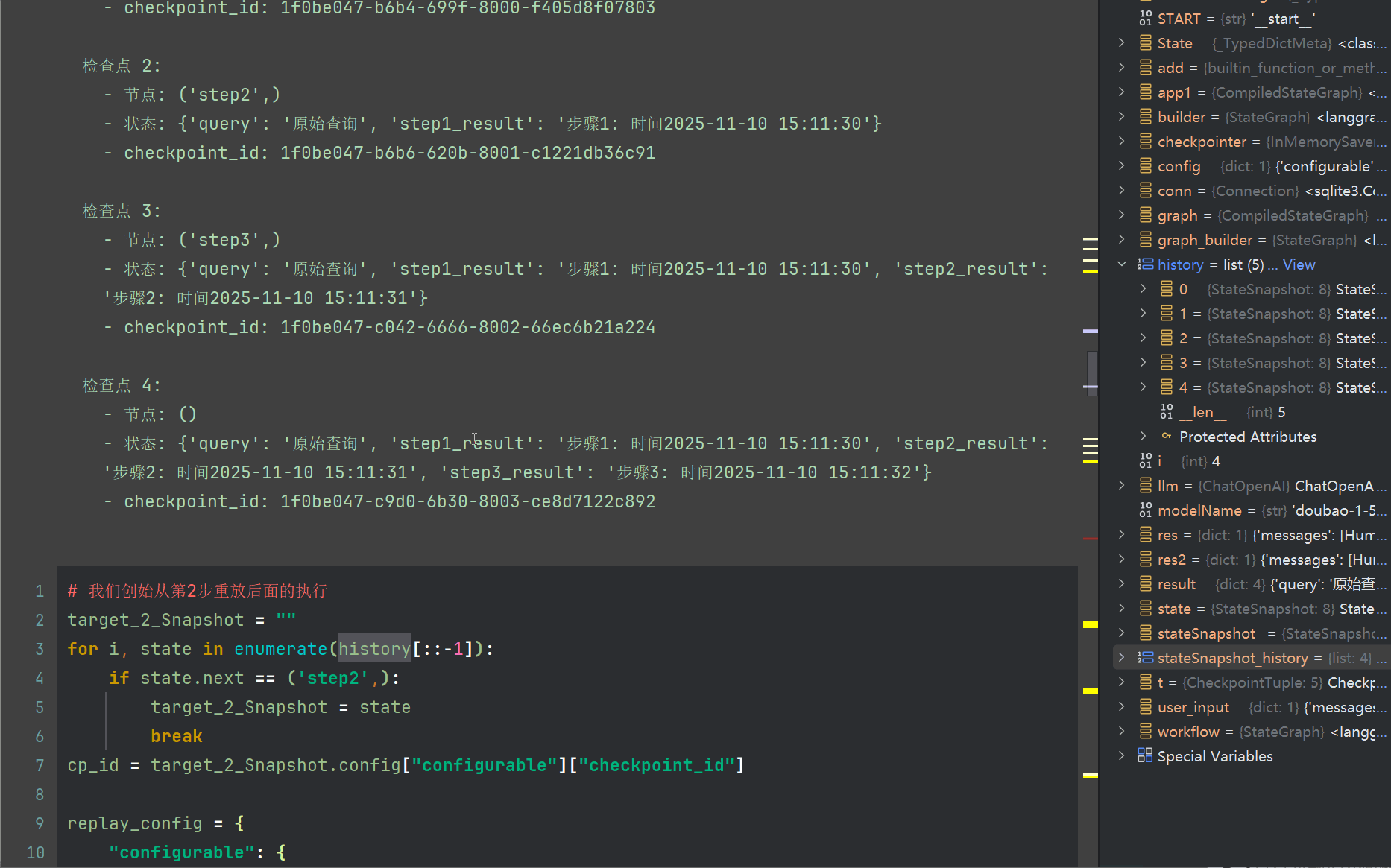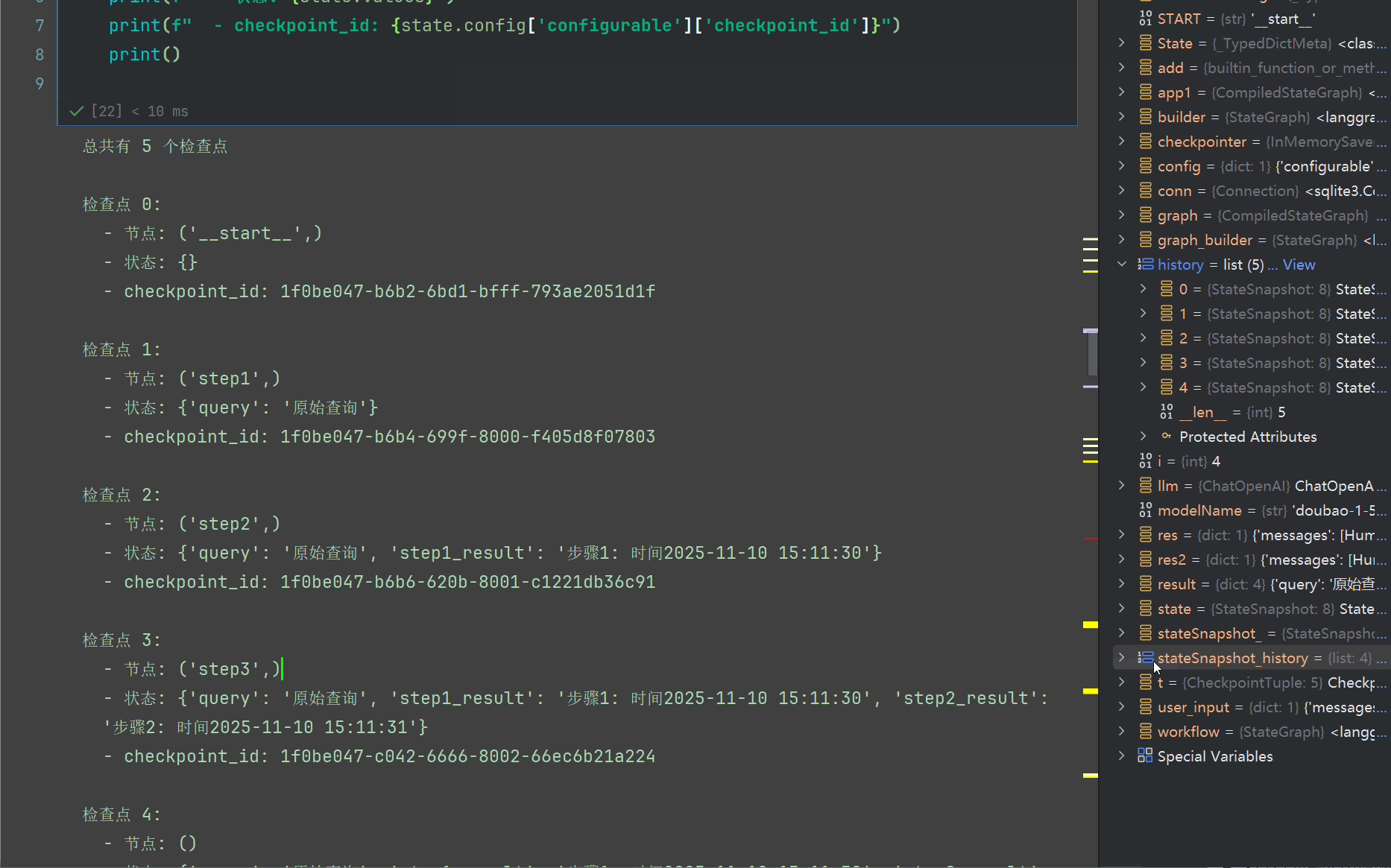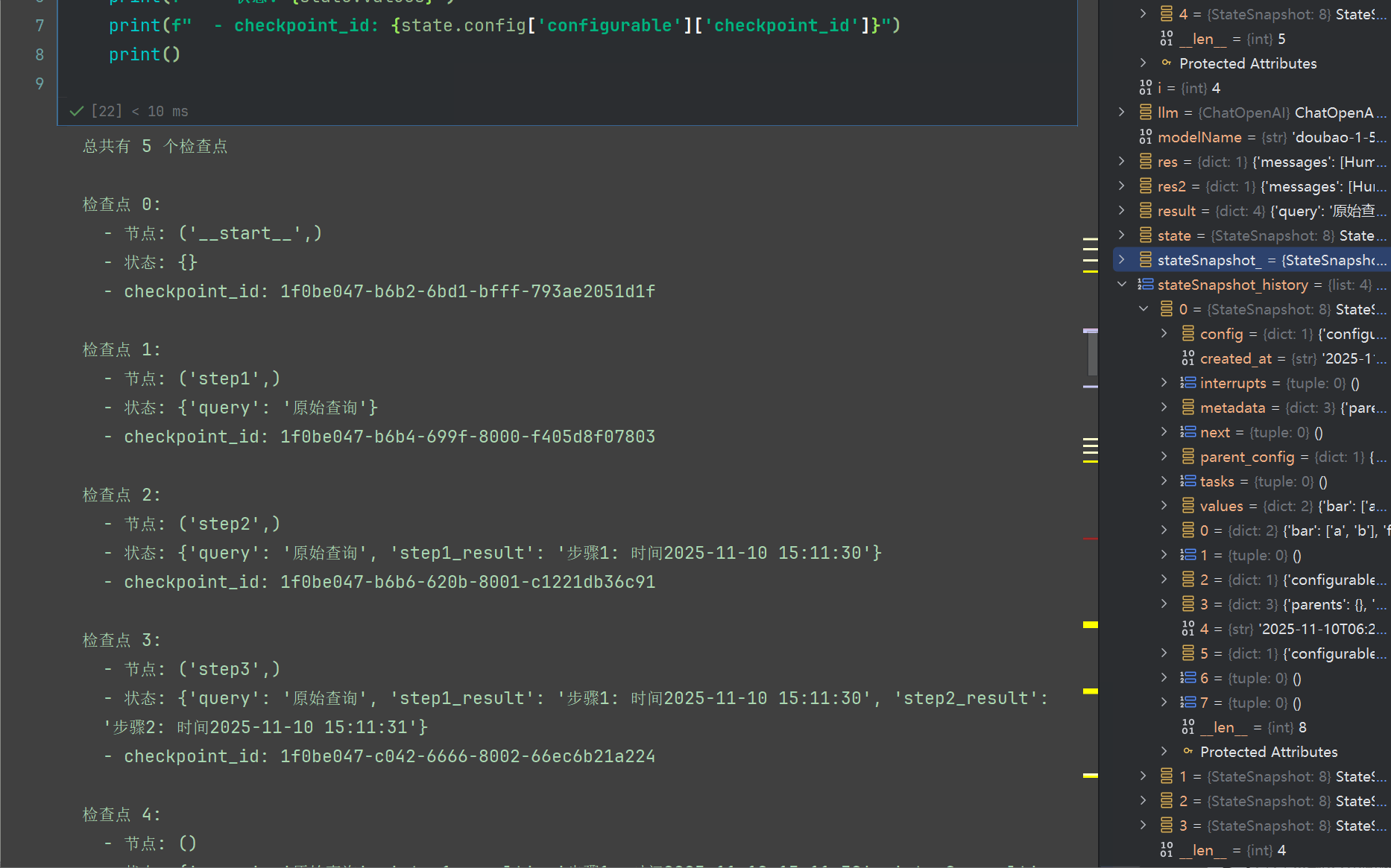
config = {"configurable": {"thread_id": "replay_demo"}}
result = app1.invoke({"query": "原始查询"}, config)
result
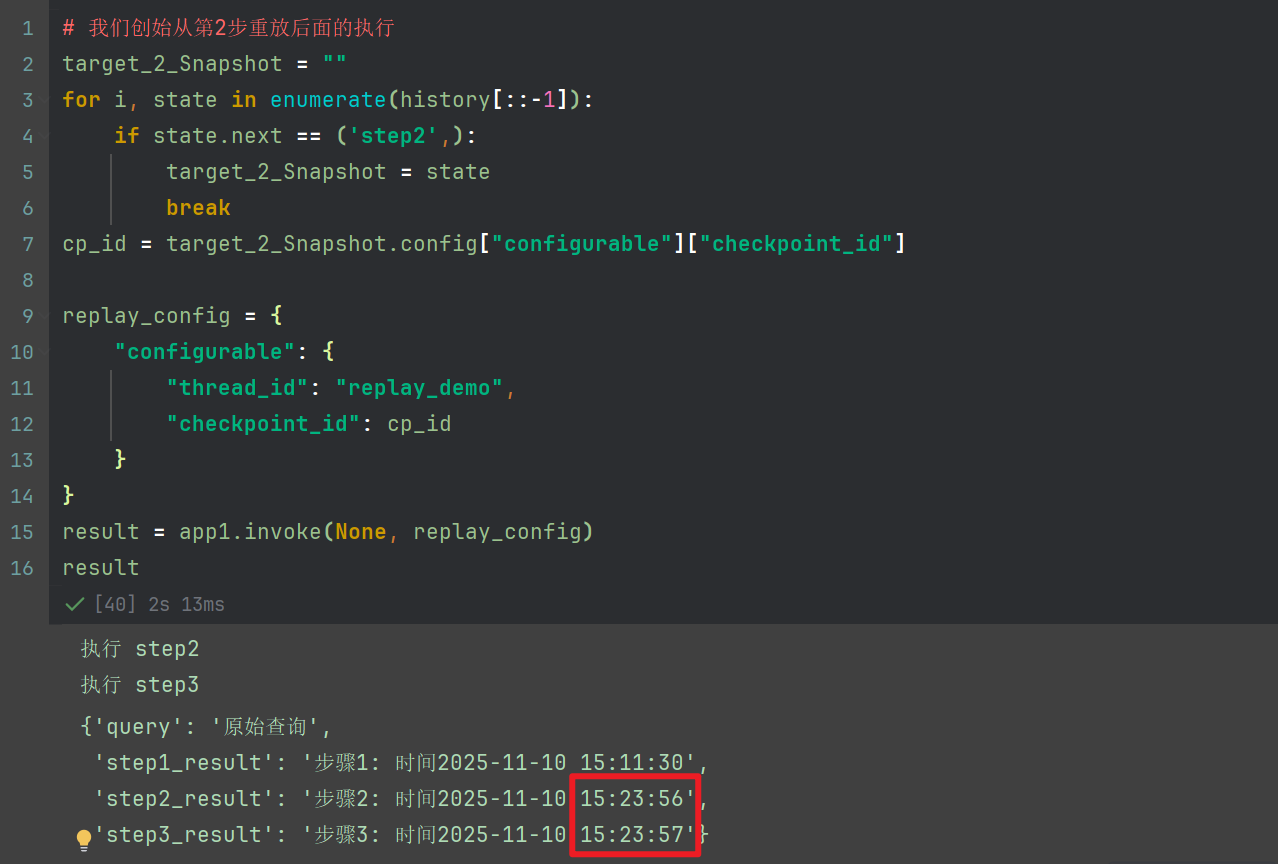
在这里,我们每个节点都打印了时间,30 31 32

我们利用前面学习的 get_state_history,查看所有的快照运行情况

现在,我们之前的输出时间是30 31 32 分别对应3个节点的输出结果,我们尝试重第二个节点重放,此时需要指定checkpoint_id 为第二个快照的
# 我们创始从第2步重放后面的执行
target_2_Snapshot = ""
for i, state in enumerate(history[::-1]):if state.next == ('step2',):target_2_Snapshot = statebreak
cp_id = target_2_Snapshot.config["configurable"]["checkpoint_id"]replay_config = {"configurable": {"thread_id": "replay_demo","checkpoint_id": cp_id}
}
result = app1.invoke(None, replay_config)
result
可以看到,运行的结果,除开第一个节点外,其它节点执行了
4.2 update_state 更新
假定你设计了一个CRM系统,小明需要报销5000大米,此时workflow的,需要State 状态机有5个字段
- 申请人姓名:小明
- 申请金额:5000
- 申请人理由:买LOL皮肤
- 财务是否通过:(待定/确认/拒绝)
- 财务拒绝理由:理由
workflow能力描述:
- 用户发起审批填写表单node
- 财务审批node
- 消息通知node
这个workflow执行完成,直接将表单存储到系统,等待财务审批,财务审批这个workflow工作流的时候,需要重新执行第1个节点吗? 那肯定是不需要的,只需要对于workflow状态进行改变,以便后续消息通知node运行即可
我们接着上面1.4.1 代码,的workflow来做一个研究学习
app2 = builder.compile(checkpointer=MemorySaver())
config = {"configurable": {"thread_id": "2"}}
app2.invoke({"query": "测试"}, config)
输出如下:
执行 step1
执行 step2
执行 step3{'query': '测试','step1_result': '步骤1: 时间2025-11-10 15:32:18','step2_result': '步骤2: 时间2025-11-10 15:32:19','step3_result': '步骤3: 时间2025-11-10 15:32:20'}
现在,我们利用 update_state 来修改状态
app2.update_state(config, {"step2_result": "步骤2被修改了"})
app2.get_state(config).values
输出如下:
{'query': '测试','step1_result': '步骤1: 时间2025-11-10 15:32:18','step2_result': '步骤2被修改了','step3_result': '步骤3: 时间2025-11-10 15:32:20'}
可以看到,第二个节点被修改了,其余 1跟3节点并没有发生改变
4.3 Replay vs Update State 对比
| 特性 | Replay | Update State |
|---|---|---|
| 执行方式 | 重新运行节点代码 | 直接修改状态值 |
| 成本 | 高(重新计算) | 低(仅更新值) |
| 值来源 | 节点函数返回 | 外部输入 |
| 适用场景 | 调试、重试API调用 | 人工干预、实时更新 |
| 时间戳变化 | 会变化 | 不变 |
选择建议:
- 使用 Replay:需要重新执行业务逻辑(如重新调用外部 API、重新计算)
- 使用 Update State:人工审核、用户输入、实时数据更新
四、memory store 记忆
官方SDK说明:https://reference.langchain.com/python/langgraph/store/#langgraph.store.base.BaseStore

本小节,我们讲述部分方法
1、Memory Store 的作用
Memory Store 用于存储跨会话的长期记忆,与 Checkpoint 的短期记忆形成互补:
| 特性 | Checkpoint | Memory Store |
|---|---|---|
| 生命周期 | 会话级(短期) | 跨会话(长期) |
| 存储内容 | 工作流状态 | 用户偏好、知识 |
| 检索方式 | thread_id | namespace + 语义搜索 |
| 应用场景 | 对话上下文恢复 | 用户画像、知识库 |
一个Agent,一个产品,我们交付给用户的时候,必然伴随着user_id,用户无论在那个thread_id下聊天,我们应当构建
一个长期的用户画像,用户A,喜欢中文回复,喜欢简单回复等等,langgraph的store机制可以帮助我们完成这个内容
2、基础示例
from langgraph.store.memory import InMemoryStore
import uuid# 创建存储实例
in_memory_store = InMemoryStore()# 定义命名空间(用于隔离不同用户的数据)
user_id = "1"
namespace_for_memory = (user_id, "memories")# 存储记忆
memory_id = str(uuid.uuid4())
memory = {"food_preference": "我喜欢汉堡"}
in_memory_store.put(namespace_for_memory, memory_id, memory)# 检索记忆
memories = in_memory_store.search(namespace_for_memory)
rich.print(memories[-1].dict())
输出如下:
{'namespace': ['1', 'memories'],'key': '8a216c0e-19fb-4bd4-ab9c-8e1f8fef15fc','value': {'food_preference': '我喜欢汉堡'},'created_at': '2025-11-10T08:02:39.451852+00:00','updated_at': '2025-11-10T08:02:39.451853+00:00','score': None
}
代码说明:
我们这里,存储了一个
参数说明:
- namespace:命名空间,通常是 (user_id, category) 元组
- key:记忆的唯一标识
- value:记忆内容(字典
3、语义检索
其实就是向量检索,假定我们有很多上下文,已经对话50轮了,再下一次对话中,即第51对话,
第51次对话,用户问:“我的姓名叫什么?”,我们有如下方案
- 将50轮对话拼接到prompt,作为history_conversation ,将面临token大量消费,甚至超标不支持
- 通过滚轮窗口算法,每10轮作为切割,通过llm压缩总结,通过50轮,会压缩5次,
第5次的压缩 = 是包含了前面4轮的压缩总结的,但是可能会存在丢失某些关键聊天信息 - 将50轮对话,作为向量存储到数据库,下次检索的时候,将用户输入的进行向量匹配出N条,最相关的内容,然后结合
滚轮窗口算法,然后再向LLM提问,或许效果会更好
3.1 利用init_embeddings
由于我用的豆包,这个方法不支持部分的,如果你跟我一样用的豆包,或者别的embeddings可以参考我3.2章节
from langchain.embeddings import init_embeddingsstore = InMemoryStore(index={"embed": init_embeddings("openai:doubao-embedding-large-text-250515"), # Embedding provider# "dims": 1536, # Embedding dimensions"fields": ["food_preference", "$"] # Fields to embed}
)
init_embeddings可以支持的可以检索如下文档:
https://docs.langchain.com/oss/python/integrations/providers/all_providers

3.2 自定义embeddings
安装 sdk uv pip install 'volcengine-python-sdk[ark]'
火山SDK对应说明文档:https://www.volcengine.com/docs/82379/1544136
from volcenginesdkarkruntime import Ark
from langchain_core.embeddings import Embeddings
from langgraph.store.memory import InMemoryStore
class VolcEmbeddings(Embeddings):def __init__(self):self.client = Ark(api_key=os.getenv("OPENAI_API_KEY"),timeout=1800,max_retries=2,)def embed_documents(self, texts: list[str]) -> list[list[float]]:"""将文本列表转换为嵌入向量列表"""embeddings = self.client.embeddings.create(model="doubao-embedding-large-text-250515",input=texts)return [embeddings.embedding for embeddings in embeddings.data]def embed_query(self, text: str) -> list[float]:"""将单个文本查询转换为嵌入向量"""return self.embed_documents([text])[0]# 测试是否成功
VolcEmbeddings().embed_documents(["你好"])
输出如下,成功输出向量

3.3 使用语义检索
# 创建支持语义搜索的 Store
store = InMemoryStore(index={"embed": VolcEmbeddings(),"fields": ["food_preference", "$"]}
)
# 存储多条记忆
store.put(namespace_for_memory, str(uuid.uuid4()),{"food_preference": "我喜欢吃川菜和火锅"})
store.put(namespace_for_memory, str(uuid.uuid4()),{"food_preference": "我喜欢打篮球"})# 语义搜索
memories = store.search(namespace_for_memory,query="用户喜欢吃啥?",limit=3
)for mem in memories:print(f"相关度: {mem.score}")print(f"内容: {mem.value}")
fields 参数说明:
- [“food_preference”]:只对 food_preference 字段向量化
- [“food_preference”, “$”]:对 food_preference 和整个文档都向量化
- [“$”]:对整个文档向量化
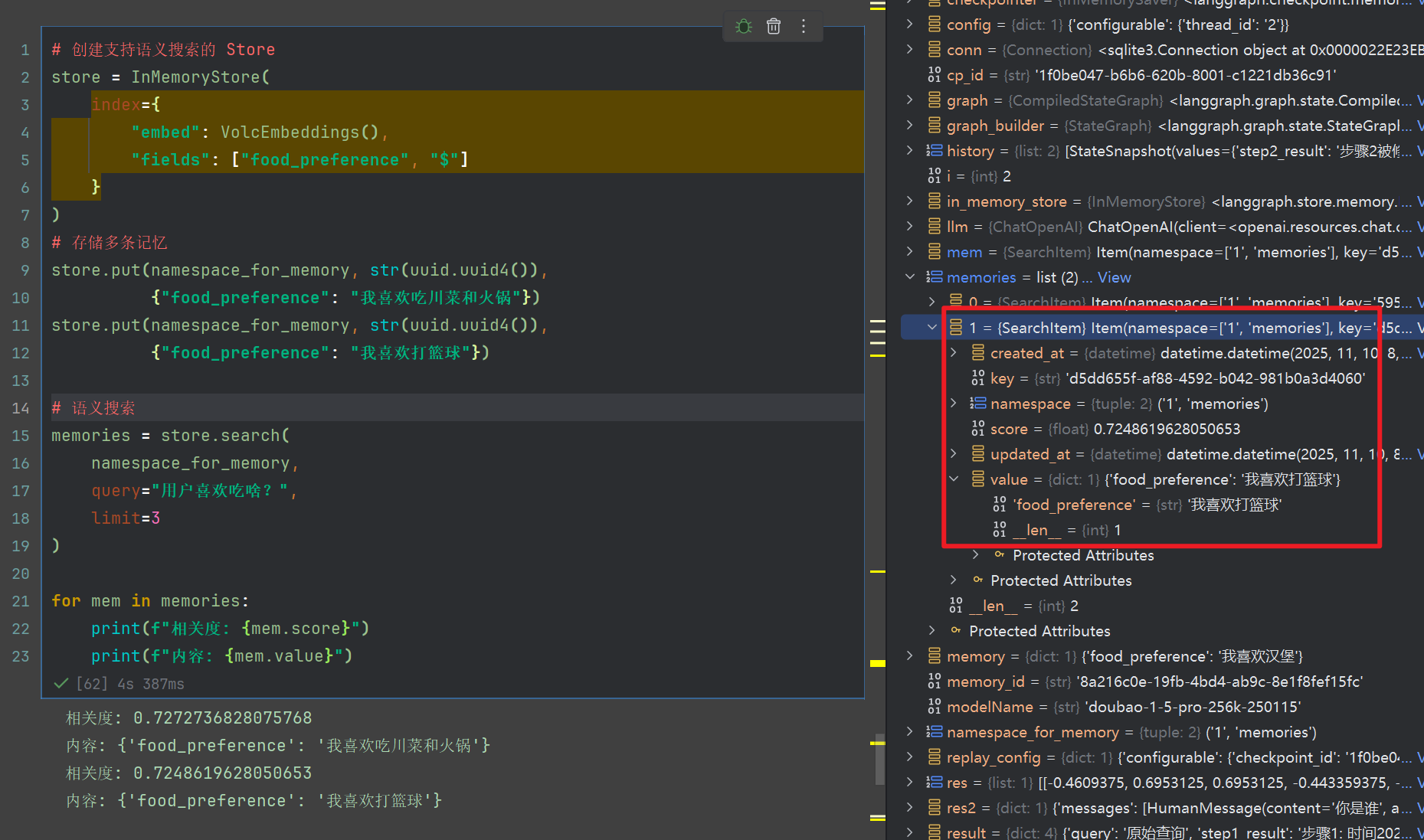
输出如下:
相关度: 0.7272736828075768
内容: {'food_preference': '我喜欢吃川菜和火锅'}
相关度: 0.7248619628050653
内容: {'food_preference': '我喜欢打篮球'}
五、Checkpoint + Store 综合案例

在前面的章节中,我们学习了,记忆,并且使用的是内存记忆,不够直观,为了将前面的知识串联起来,下面我们将构建一个综合案例。
本案例将综合运用前面学到的知识,构建一个智能客服系统,具备以下能力:
- 短期记忆(
Checkpointer): 使用 PostgreSQL 保存对话状态
长期记忆(store): 使用 PostgreSQL 向量数据库存储用户画像和历史摘要
对话压缩: 自动压缩超过 10 轮的对话,使用milvus
语义检索: 基于用户问题检索相关的历史信息,使用milvus
智能提取: 自动提取用户偏好并保存,使用milvus
在此大家不要有误区,你可以将用户画像结构化存储到store也可以,你也可以通过llm,构建摘要存储到store,完全不用milvus+embedding,向量存储摘要。
狗头保命,做法有很多,本案例,只是为了综合体验教学,设计上面并不是那么严谨。

1、配置embedding模型
我们采用豆包的向量模型(觉得麻烦的别用这个,可以跳到四章节3.1,前提你的模型刚好支持)
豆包官网向量,有对向量的维度声明,默认为2048
https://console.volcengine.com/ark/region:ark+cn-beijing/model/detail?Id=doubao-embedding-large

我们可以编写代码测试一下:
from volcenginesdkarkruntime import Ark
from langchain_core.embeddings import Embeddings
class VolcEmbeddings(Embeddings):def __init__(self):self.client = Ark(api_key=os.getenv("OPENAI_API_KEY"),timeout=1800,max_retries=2,)def embed_documents(self, texts: list[str]) -> list[list[float]]:"""将文本列表转换为嵌入向量列表"""embeddings = self.client.embeddings.create(model="doubao-embedding-large-text-250515",input=texts)return [embeddings.embedding for embeddings in embeddings.data]def embed_query(self, text: str) -> list[float]:"""将单个文本查询转换为嵌入向量"""return self.embed_documents([text])[0]# 测试是否成功
test_embedding = VolcEmbeddings().embed_query("测试")
print(f"豆包 embedding 实际维度: {len(test_embedding)}")
输出结果如下:
豆包 embedding 实际维度: 2048
2、pg作为checkpoint跟store
2.1 安装pg数据库
运行我的代码仓库的docker文件
https://github.com/wenwenc9/langgraph-tutorial-wenwenc9/tree/main/Langgraph_Learning/2-%E8%BF%9B%E9%98%B6
docker-compose -f .\docker-compose-pg.yaml up -d
看到成功启动了数据库

2.2 初始化化数据库(代码)
现在我们编写pg数据库构建代码
import psycopg
from langgraph.checkpoint.postgres import PostgresSaver
# PostgreSQL 用于 Checkpointer(短期记忆)
PG_URI = "postgresql://postgres:123456@localhost:5432/wenwenc9"
PG_DB_NAME = "langgraph-learn"
def init_postgres():"""初始化 PostgreSQL 数据库"""print("🔍 检查 PostgreSQL 数据库...")conn = psycopg.connect(PG_URI, autocommit=True)try:with conn.cursor() as cur:cur.execute("SELECT 1 FROM pg_database WHERE datname = %s",(PG_DB_NAME,))exists = cur.fetchone()if not exists:cur.execute(f'CREATE DATABASE "{PG_DB_NAME}"')print(f"✅ PostgreSQL 数据库 '{PG_DB_NAME}' 创建成功")else:print(f"✅ PostgreSQL 数据库 '{PG_DB_NAME}' 已存在")finally:conn.close()return f"postgresql://postgres:123456@localhost:5432/{PG_DB_NAME}"
FULL_PG_URI = init_postgres()checkpointer_cm = PostgresSaver.from_conn_string(FULL_PG_URI)
checkpointer = checkpointer_cm.__enter__() # 手动进入上下文模式
checkpointer.setup() # 创建postgres四张表
这段代码,创建了一个数据(不存在则创建),并且checkpointer.setup()会默认创建6张表,四张表如下

2.3 六张表说明
2.3.1 checkpoint关联的4个表
| 表名 | 用途说明 |
|---|---|
checkpoints | 存储每次图执行后的完整状态,用于会话恢复(短期记忆的核心)。 |
checkpoint_writes | 记录状态的增量更新,支持“时间旅行”(回溯到任意步骤)。 |
checkpoint_blobs | 存储大型数据(如长消息、文件),避免主表臃肿。 |
checkpoint_migrations | 管理数据库 schema 的升级,确保版本兼容。 |
checkpoint表字段说明
| 字段名 | 类型 | 说明 |
|---|---|---|
thread_id | VARCHAR | 会话标识,用于隔离不同对话或工作流实例 |
checkpoint_ns | VARCHAR | 检查点命名空间,用于区分不同的子图或执行上下文 |
checkpoint_id | VARCHAR | 检查点唯一ID,通常为 UUID 格式 |
parent_checkpoint_id | VARCHAR | 父检查点ID,用于构建执行历史树 |
type | VARCHAR | 检查点类型(如"pending"或空) |
checkpoint | JSONB | 核心元数据,包含 channel_versions 等版本信息 |
metadata | JSONB | 额外元数据,如步骤数、时间戳等 |
created_at | TIMESTAMP | 记录创建时间 |
checkpoint_blobs表
| 字段名 | 类型 | 说明 |
|---|---|---|
thread_id | VARCHAR | 关联会话标识 |
checkpoint_ns | VARCHAR | 命名空间 |
channel | VARCHAR | 状态通道名称(如 “messages”、“results”) |
version | VARCHAR | 版本号 |
type | VARCHAR | 数据类型标识 |
blob | BYTEA | 序列化后的二进制数据,实际状态内容 |
created_at | TIMESTAMP | 记录创建时间 |
checkpoint_writes表
| 字段名 | 类型 | 说明 |
|---|---|---|
thread_id | VARCHAR | 会话标识 |
checkpoint_ns | VARCHAR | 命名空间 |
checkpoint_id | VARCHAR | 关联的检查点ID |
task_id | VARCHAR | 任务标识 |
idx | INTEGER | 写入操作的序号索引 |
channel | VARCHAR | 目标状态通道 |
type | VARCHAR | 数据类型 |
blob | BYTEA | 待写入的序列化数据 |
checkpoint_migrations表
| 字段名 | 类型 | 说明 |
|---|---|---|
v | INTEGER | 版本号 |
migration | JSONB | 迁移操作记录 |
2.3.2 .store关联两张表
| 表名 | 用途说明 |
|---|---|
store | 知识库主表,存储可跨线程/会话共享的长期记忆数据(如用户画像、知识库条目)。支持命名空间隔离和高效KV查询。 |
store_migrations | 管理 store 表结构的版本升级,确保 LangGraph 版本迭代时的 schema 兼容性。 |
store 表字段详解
| 字段名 | 类型 | 说明 |
|---|---|---|
namespace | VARCHAR | 命名空间,隔离不同业务域(如 memories/user_123、kb/product) |
key | VARCHAR | 键名,在命名空间内唯一标识一条记录 |
value | JSONB | 值内容,存储任意结构化数据(自动序列化/反序列化) |
created_at | TIMESTAMP | 记录创建时间 |
updated_at | TIMESTAMP | 最后更新时间(UPDATE时自动刷新) |
thread_id | VARCHAR | (可选) 关联会话标识,用于场景化记忆 |
store_migrations 表字段详解
| 字段名 | 类型 | 说明 |
|---|---|---|
v | INTEGER | 版本号,单调递增 |
migration | JSONB | 迁移脚本元数据(含 UP/DOWN SQL 和操作记录) |
2.4 pgvector说明
官方文档:https://help.aliyun.com/zh/rds/apsaradb-rds-for-postgresql/pgvector-use-guide

还记的第1小节吗,我们输出的维度为2048,pg如果作为langgraph的sotre会出问题的。
并且,pg本身作为插件依附于postgres,在大型跟专业程度并不如milvus!
然后,langgraph当前版本没有store的内置包去链接milvus,pg就有
from langgraph.checkpoint.postgres import PostgresSaver
所以我们得手动管理,构建链接然后自己插入,更新。
3、milvus作为向量数据库
官方文档:https://milvus.io/docs/zh/overview.md

3.1 安装milvus数据库
我的代码仓库地址:https://github.com/wenwenc9/langgraph-tutorial-wenwenc9/tree/main/Langgraph_Learning/2-%E8%BF%9B%E9%98%B6
docker-compose -f docker-compose-milvus.yaml up -d
成功运行,docker容器显示如下

其中声明一下,attu为可视化插件,方便我们后面研究向量这些表
访问 http://localhost:8000/
3.2 测试数据库(代码)
运行下面代码
from langchain_milvus import Milvus
from pymilvus import Collection, connections
vector_store = Milvus(embedding_function=VolcEmbeddings(),connection_args={"host": "localhost","port": "19530","user": "root","password": "Milvus123456-123456789"},collection_name="my_collection",index_params={"index_type": "HNSW", # 🔥 支持高级索引"metric_type": "COSINE","params": {"M": 16, "efConstruction": 200}},
)
# 使用方式完全一样
vector_store.add_texts(["我的姓名叫稳稳", "我最喜欢骑行了!"])# 查询
results = vector_store.similarity_search("姓名", k=3)
results2 = vector_store.similarity_search_with_score("姓名", k=3)
for i, (doc, score) in enumerate(results2, 1):print(f"\n结果 {i}:")print(f" 内容: {doc.page_content}")print(f" 相似度: {score:.4f}") # 🔥 这就是相似度分数print(f" 元数据: {doc.metadata}")你将看到

访问可视化attu页面看看向量

更多CRUD方法请查看官方文档:
langchain_milvus:https://reference.langchain.com/python/integrations/langchain_milvus/

pymilvus:https://milvus.io/docs/zh/manage_databases.md

可选运行代码,清空这张表数据
# 清空这个表的数据
collection = Collection("my_collection")
collection.load()
result = collection.query(expr="pk >= 0", # 查询所有记录output_fields=["pk"] # pk 是主键字段名
)
if result:# 提取所有 IDids_to_delete = [item["pk"] for item in result]# 批量删除collection.delete(f"pk in {ids_to_delete}")print(f"✅ 已删除 {len(ids_to_delete)} 条记录")
else:print("⚠️ Collection 为空")
# 刷新
collection.flush()
4、构建Agent业务代码
在开始之前,我们明确一下,我们要创建什么节点

4.1 定义图状态
from langgraph.graph import MessagesState
from typing import Optional,Dict,Any
class State(MessagesState):"""继承 MessagesState 自动获得 messages 字段"""user_id: str # 用户唯一标识user_profile: Optional[Dict[str, Any]] = {} # 用户画像文本(从 PostgresStore 获取)history_context: Optional[str] = "" # 历史摘要文本(从 Milvus 检索)last_user_message: Optional[str] = "" # 最后一条用户消息,用于检索和提取4.2 公共工具函数
- get_milvus_vectorstore,该创建milvus链接对象
- format_profile_context,传入用户画像dict,返回拼接后的cotent,用于后续我们拼接到prompt里面
from langchain_milvus import Milvus
from langgraph.store.base import BaseStoredef get_milvus_vectorstore(collection_name: str) -> Milvus:"""创建 Milvus 向量存储实例Args:collection_name: Collection 名称Returns:Milvus 向量存储实例配置说明:- FLAT 索引: 精确搜索- COSINE 相似度: 余弦相似度(-1 到 1)- drop_old=False: 保留历史数据"""return Milvus(embedding_function=VolcEmbeddings(),collection_name=collection_name,connection_args={"host": "localhost","port": "19530","user": "root","password": "Milvus123456-123456789"},drop_old=False,index_params={"index_type": "FLAT","metric_type": "COSINE",})def format_profile_context(profile: dict) -> str:"""格式化用户画像上下文Args:profile: 用户画像字典Returns:格式化后的文本"""if not profile:return "暂无用户画像"lines = []if profile.get("name"):lines.append(f"姓名: {profile['name']}")if profile.get("language"):lines.append(f"语言偏好: {profile['language']}")if profile.get("preferences"):lines.append(f"回复偏好: {profile['preferences']}")if profile.get("expertise"):lines.append(f"专业领域: {profile['expertise']}")return "\n".join(lines) if lines else "暂无用户画像"
4.3 节点 1: 检索用户画像
根据user_id 获取postgres(store)中的用户画像dict
def retrieve_user_profile(state: State, *, store: BaseStore) -> dict:"""【节点1】从 PostgresStore 获取用户画像输出:user_profile: 完整画像字典"""user_id = state["user_id"]print(f"\n{'='*60}")print(f"节点1: 获取用户画像 (user_id={user_id})")print(f"{'='*60}")# namespace 隔离用户数据namespace = (user_id, "profile")# 一次性获取完整画像字典profile_item = store.get(namespace, "user_profile")if profile_item and profile_item.value:user_profile = profile_item.valueprint(f"找到用户画像:")for key, value in user_profile.items():print(f" - {key}: {value}")else:user_profile = {}print(f"暂无用户画像(新用户)")return {"user_profile": user_profile}
4.4 节点 2: 检索历史摘要
- 提取用户最后一次的输入
last_user_message - 根据user_id 获取,从向量数据库检索摘要关联的前3个
results - 将3个摘要,拼接成一个content
history_context
from langchain_core.messages import HumanMessagedef retrieve_history_summary(state: State, *, config) -> dict:"""【节点2】从 Milvus 检索历史对话摘要输出:history_context: 格式化的历史摘要文本last_user_message: 用户消息(供后续节点使用)"""user_id = state["user_id"]messages = state["messages"]print(f"\n{'='*60}")print(f"节点2: 检索历史摘要")print(f"{'='*60}")# 提取最后一条用户消息last_user_message = ""for msg in reversed(messages):if msg.type == "human":last_user_message = msg.contentbreakif not last_user_message:print(f"未找到用户消息,跳过检索")return {"history_context": "","last_user_message": ""}print(f"用户本轮输入: {last_user_message[:50]}...")# 语义检索,之前滚轮压缩的对话摘要summary_vectorstore = get_milvus_vectorstore(f"summary_{user_id}")results = summary_vectorstore.similarity_search_with_score(query=last_user_message,k=3)# 构建历史上下文history_context = ""if results:history_context = "相关历史对话:\n" + "\n".join([f"- {doc.page_content} (相关度: {score:.2f})"for doc, score in results])print(f"找到 {len(results)} 条相关摘要")print(f"最高相关度: {max(score for _, score in results):.4f}")else:print(f"暂无相关历史摘要")return {"history_context": history_context,"last_user_message": last_user_message}
4.5 节点 3: 对话压缩
当对话超过 10 轮时,自动压缩早期对话,避免 token 消耗过高或超出限制。
技术实现:
- 检查消息数量
- 超过 10 轮则保留最近 5 轮
- 前面的消息用 LLM 压缩成摘要
- 保存摘要到 Milvus,删除原始消息
关键点:
- 滚动窗口: 保留最近 5 轮保证连贯性
- LLM 压缩: 提取关键信息而非截断
- 向量化存储: 压缩后仍可被检索
- RemoveMessage: LangGraph 标记删除机制
from langchain_core.messages import SystemMessagedef generate_response(state: State, *, config) -> dict:"""【节点4】生成 AI 回复输出:messages: AI 回复消息"""messages = state["messages"]user_profile = state.get("user_profile", {})history_context = state.get("history_context", "")print(f"\n{'='*60}")print(f"节点4: 生成回复")print(f"{'='*60}")# 格式化用户画像profile_text = format_profile_context(user_profile)# 最近对话信息 (该其实为state完整的消息载体)recently_content_list = []recently_content_str = ""recently_messages = state.get("messages",[])if len(recently_messages) != 0:windows_ = recently_messages[:10][::-1] # 翻转消息,最近问的靠前for msg in windows_:if hasattr(msg, 'type') and msg.type == "human":recently_content_list.append(f"用户:{msg.content}")elif hasattr(msg, 'type') and msg.type == "ai":recently_content_list.append(f"AI:{msg.content}")recently_content_str = "\n---\n".join(recently_content_list)# 构建增强 promptsystem_prompt = f"""你是一个智能客服助手。用户画像:{profile_text}历史压缩对话信息:{history_context}最近对话信息:{recently_content_str}请基于用户画像和历史压缩对话信息和最近详细对话信息,提供个性化的回答。"""print(f"System Prompt 长度: {len(system_prompt)} 字符")print(f"当前对话轮数: {len([m for m in messages if m.type == 'human'])}")# 调用 LLMresponse = llm.invoke([SystemMessage(content=system_prompt),*messages])print(f"回复生成完成 (长度: {len(response.content)} 字符)")return {"messages": [response]}
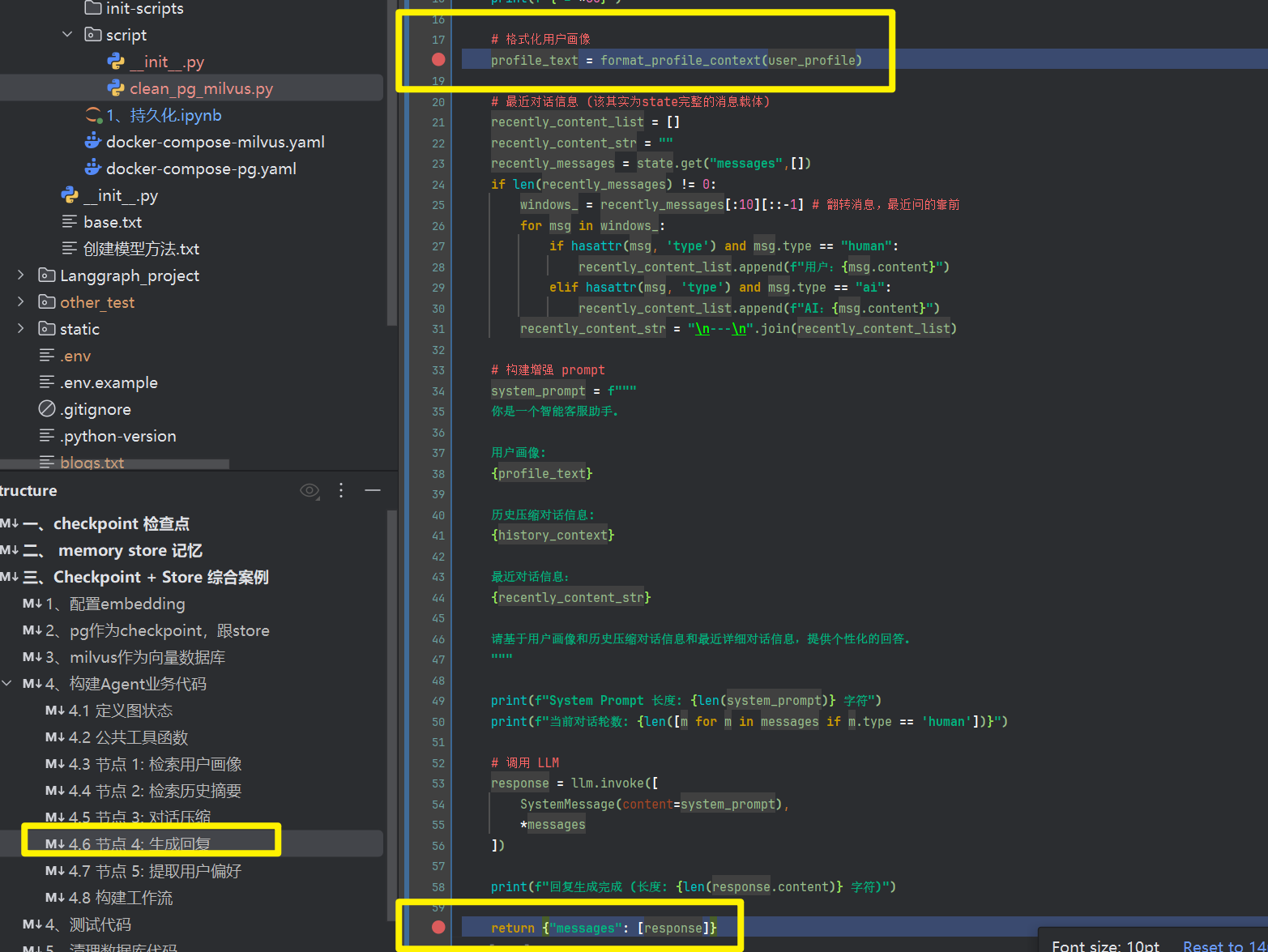
4.6 节点 4: 生成回复
基于用户画像和历史上下文,生成个性化回复。
技术实现:
- 从 state 获取画像和历史上下文
- 构建增强的 system prompt
- 调用 LLM 生成回复
关键点:
- 上下文增强: 画像 + 历史注入 prompt
- 个性化: LLM 根据画像调整风格
- 完整历史: messages 包含滚动窗口内的对话
最终 Context =结构化画像(PostgresStore)+ 最近 5 轮对话(Checkpoint自动管理) + Top-3 相关摘要(Milvus向量检索)
这个是上下文,是作为用户本轮输入问题,一同发给llm模型让其回复的
from langchain_core.messages import SystemMessagedef generate_response(state: State, *, config) -> dict:"""【节点4】生成 AI 回复输出:messages: AI 回复消息"""messages = state["messages"]user_profile = state.get("user_profile", {})history_context = state.get("history_context", "")print(f"\n{'='*60}")print(f"🤖 节点4: 生成回复")print(f"{'='*60}")# 格式化用户画像profile_text = format_profile_context(user_profile)# 构建增强 promptsystem_prompt = f"""你是一个智能客服助手。用户画像:{profile_text}历史对话信息:{history_context}请基于用户画像和历史信息,提供个性化的回答。"""print(f"System Prompt 长度: {len(system_prompt)} 字符")print(f"当前对话轮数: {len([m for m in messages if m.type == 'human'])}")# 调用 LLMresponse = llm.invoke([SystemMessage(content=system_prompt),*messages])print(f"回复生成完成 (长度: {len(response.content)} 字符)")return {"messages": [response]}
4.7 节点 5: 提取用户偏好
从用户消息中提取结构化信息
技术实现:
- 用 LLM 分析用户消息
- 提取结构化字段(name, language, preferences, expertise)
- 与现有画像合并
- 整体更新 PostgresStore
关键点:
- LLM 提取: 比正则更智能
- 字典合并: 只更新新字段,保留旧字段
- 原子性更新: 一次性写入完整字典
- 渐进式积累: 每次对话都可能添加新字段
import re
import jsondef update_user_profile(state: State, *, store: BaseStore) -> dict:"""【节点5】更新用户画像输出:无(直接保存到 PostgresStore)"""user_id = state["user_id"]last_user_message = state.get("last_user_message", "")current_profile = state.get("user_profile", {})print(f"\n{'='*60}")print(f"节点5: 更新用户画像")print(f"{'='*60}")if not last_user_message:print(f"无用户消息,跳过更新")return {}# LLM 智能提取extraction_prompt = f"""从以下用户消息中提取信息,以JSON格式返回:用户消息: {last_user_message}需要提取的字段:- name: 用户姓名(如果提到)- language: 语言偏好(如: "中文"、"English")- preferences: 回复风格偏好(如: "简洁"、"详细")- expertise: 专业领域(如: "Python工程师"、"产品经理")如果某个字段没有提到,不要包含该字段。只返回JSON,不要额外解释。示例:{{"name": "稳稳", "language":"中文","preferences": "简洁回答", "expertise": "Python工程师"}}"""extraction_result = llm.invoke([HumanMessage(content=extraction_prompt)])extracted_text = extraction_result.content.strip()# 尝试解析 JSONtry:# 提取 JSON 部分json_match = re.search(r'\{.*\}', extracted_text, re.DOTALL)if not json_match:print(f"未提取到结构化信息")return {}extracted_info = json.loads(json_match.group())if not extracted_info:print(f"未提取到有效字段")return {}# 合并画像(渐进式积累)updated_profile = {**current_profile, **extracted_info}# 整体更新 PostgresStorenamespace = (user_id, "profile")store.put(namespace, "user_profile", updated_profile)print(f"已更新用户画像:")for key, value in extracted_info.items():print(f" - {key}: {value}")print(f"\n完整画像:")for key, value in updated_profile.items():print(f" - {key}: {value}")except Exception as e:print(f"解析失败: {e}")print(f"LLM 返回: {extracted_text[:100]}...")return {}
4.8 构建langgraph工作流
from langgraph.graph import StateGraph, END# 创建工作流构建器
graph_builder = StateGraph(State)# 添加 5 个节点
graph_builder.add_node("retrieve_profile", retrieve_user_profile)
graph_builder.add_node("retrieve_history", retrieve_history_summary)
graph_builder.add_node("compress", compress_conversation)
graph_builder.add_node("generate", generate_response)
graph_builder.add_node("update_profile", update_user_profile)# 定义执行流程
graph_builder.set_entry_point("retrieve_profile")
graph_builder.add_edge("retrieve_profile", "retrieve_history")
graph_builder.add_edge("retrieve_history", "compress")
graph_builder.add_edge("compress", "generate")
graph_builder.add_edge("generate", "update_profile")
graph_builder.add_edge("update_profile", END)# 编译工作流
graph = graph_builder.compile(checkpointer=checkpointer, # PostgreSQL 短期记忆store=store # PostgreSQL 长期记忆(结构化)
)
构建后的图结构

5、项目运行
5.1 运行测试代码
import time
from langchain_core.messages import HumanMessage
coversation_list = [# 测试用户画像更新,postgres"我叫稳稳,我喜欢中文回复,我从事于python工程师", # 先更新了3个字段"我希望你简单回复我", # 再更新了一个字段,现在有4个字段"其实我不叫稳稳,我叫叼毛", # 对于名称再更新# 前面3+后面7,11轮,测试体验摘要算法"你知道太阳的体积吗?","我很疑惑,为什么骑行会变瘦","春风若有怜花意,下一句是什么?","深圳有多少个区","什么是货代呢","关于月亮的体积","你知道我的用户画像吗?"# 第12轮往后"我现在开始一讲一个故事,你直到我说`结束`,然后你回复我讲了什么故事","从前有座山,山上有座庙,庙里有个老和尚跟小和尚","老和尚说山下有母老虎","小和尚说,那我要会会这个母老虎",# 测试摘要算法"我前面讲了什么故事"
]
config = {"configurable": {"thread_id": "conversation_001"}
}# 批量测试
for i,content in enumerate(coversation_list):time.sleep(1)print("\n开始:",i,"本轮问题:",content)result1 = graph.invoke({"user_id": "user_002","messages": [HumanMessage(content=content)]}, config)print("\n=== AI 回复 ===")print(result1["messages"][-1].content)在代码仓库中我放置了一个清理pg数据库跟milvus代码,如果进行测试的时候,方便研究测试,这样你不用改user_id ,thread_id

由于CSDN上传GIF有限,这里就录制一部分,需要你自己调试研究每轮对话,

5.2 查看milvus数据库
可以看到摘要更新了,3轮摘要对应的是我们前面对话内容跟回复

发现一个好玩的

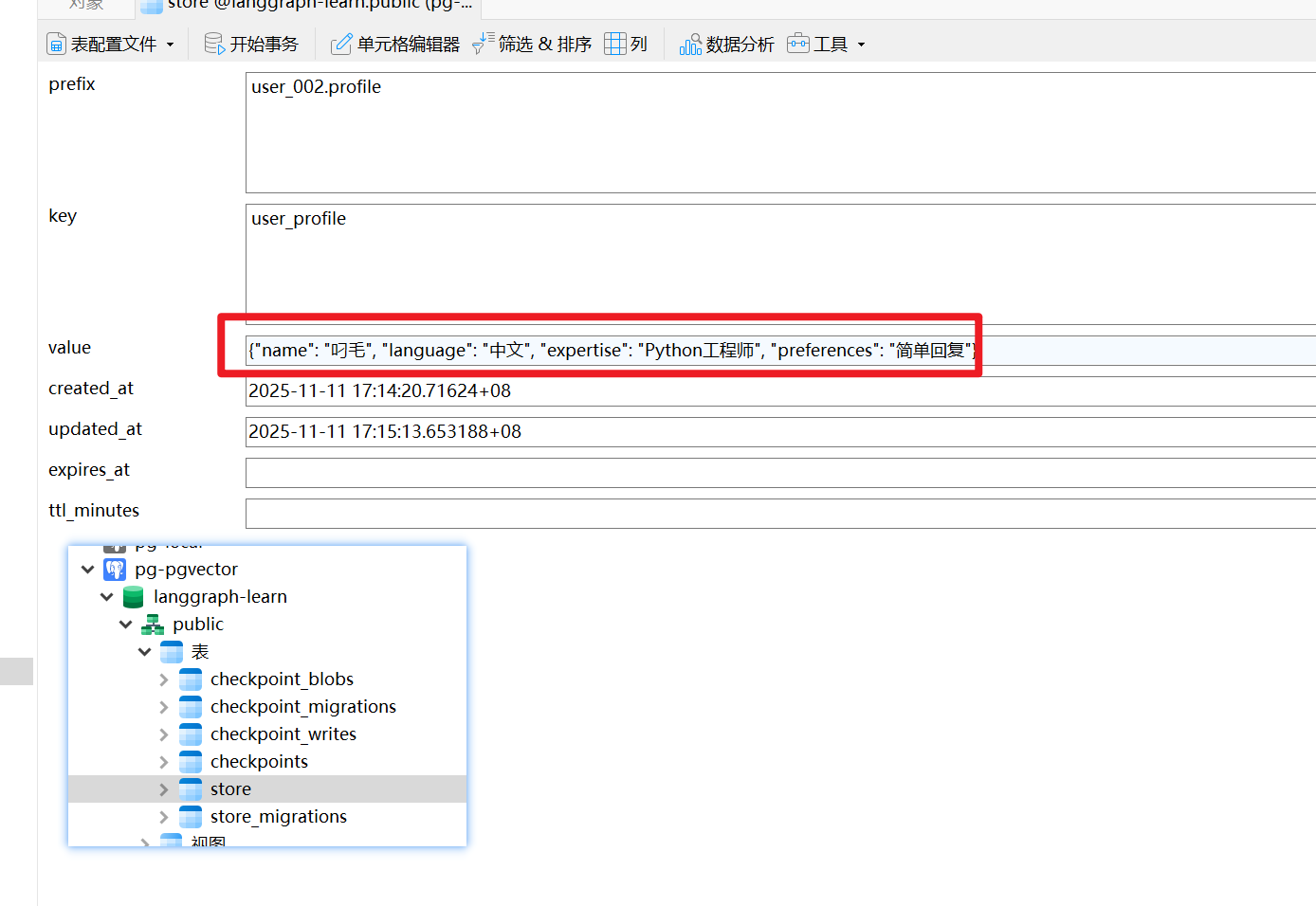
5.3 查看pg数据库
重点说store这张表,可以看到存户了我们的用户画像
6、Debugger项目研究堆栈方法
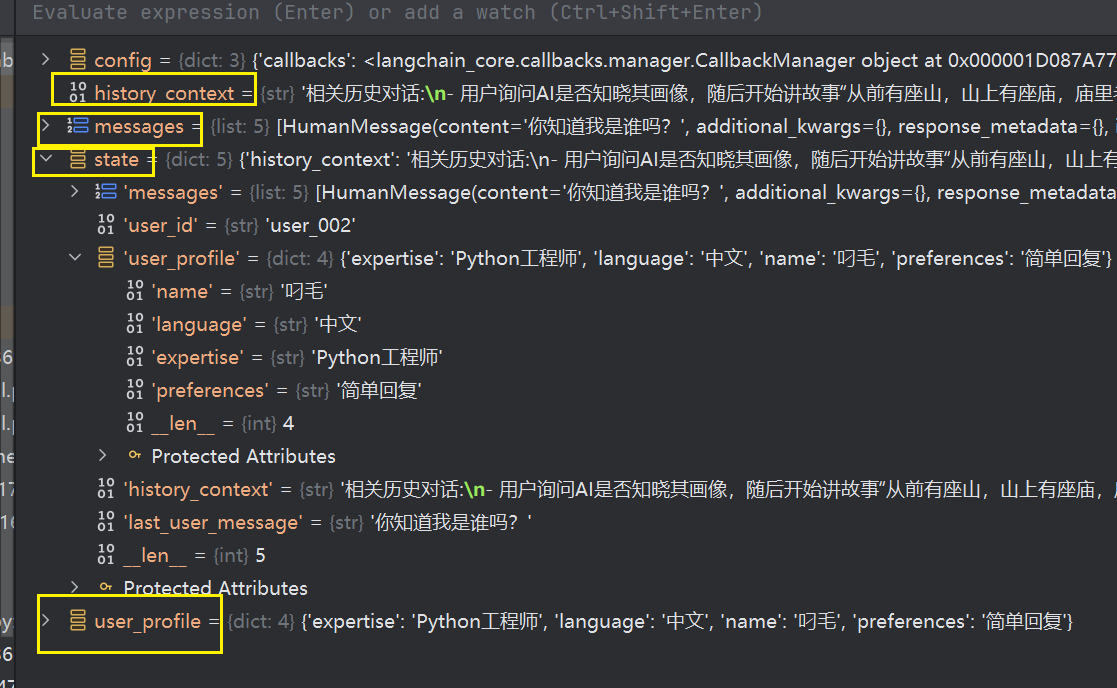
建议在5个节点的函数入口,跟return地方都加上debugger,比如下图我在生成回复节点打上2个端点
我们可以单独运行一段代码,进入堆栈(如果有需要可以运行我代码目录下clean_pg_milvus.py脚本以便重头开始研究)
这里我不清表,在之前记录上,继续一轮对话,我这里教的是如何观摩堆栈,每个节点需要自己调试理解,并且看库表,才能get到东西
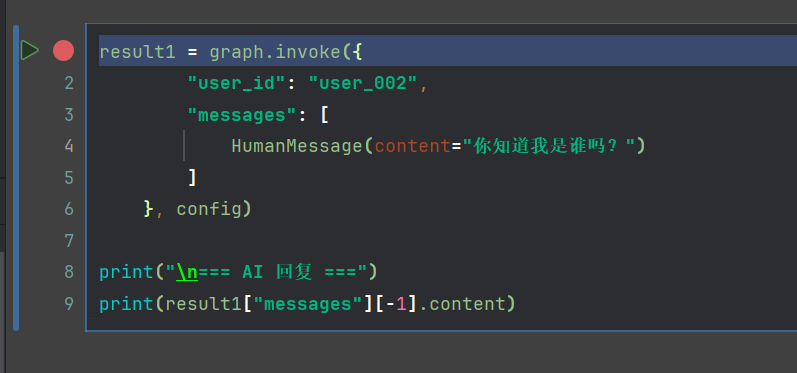
调试的时候F9,跳转到debugger点,然后看堆栈
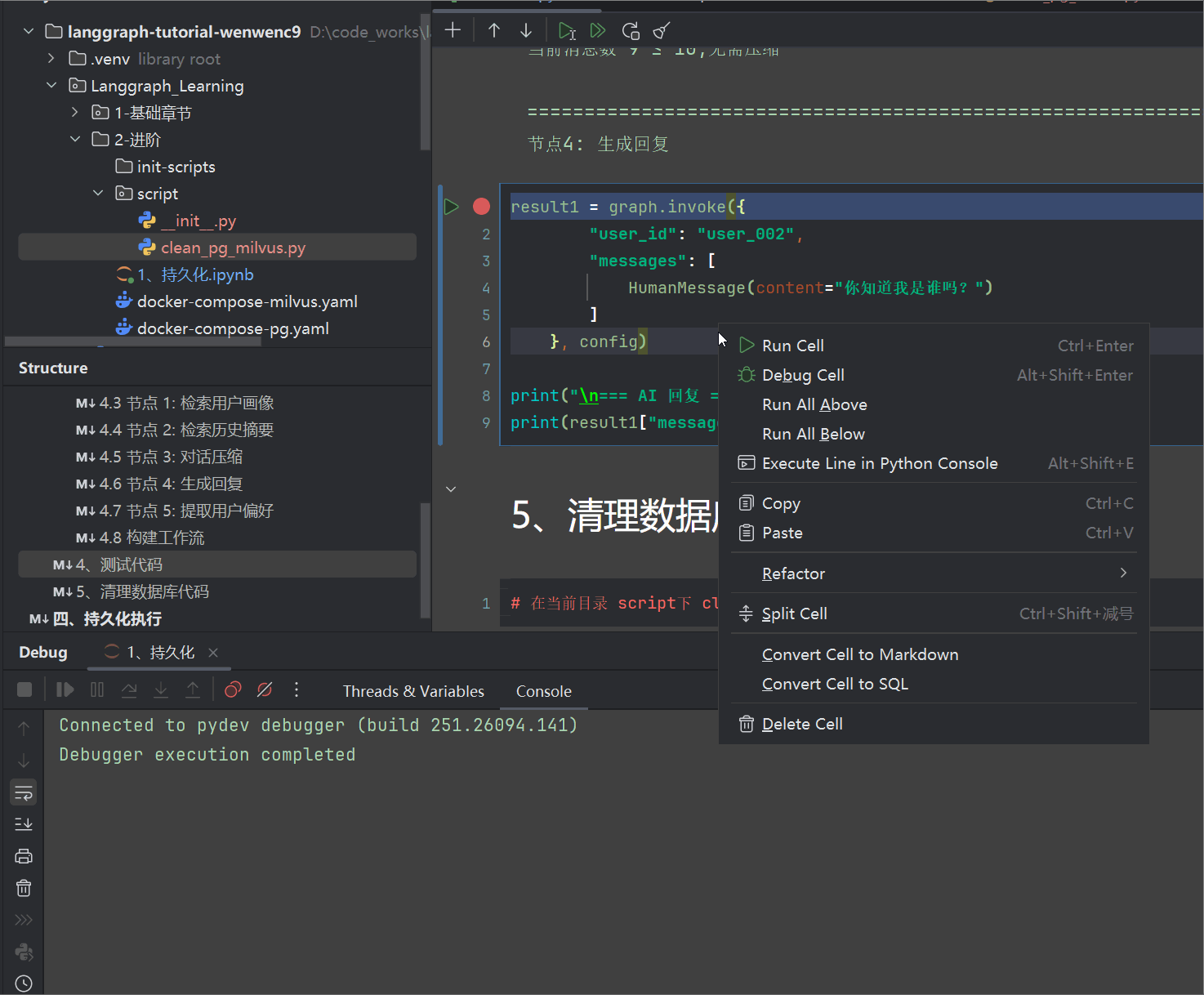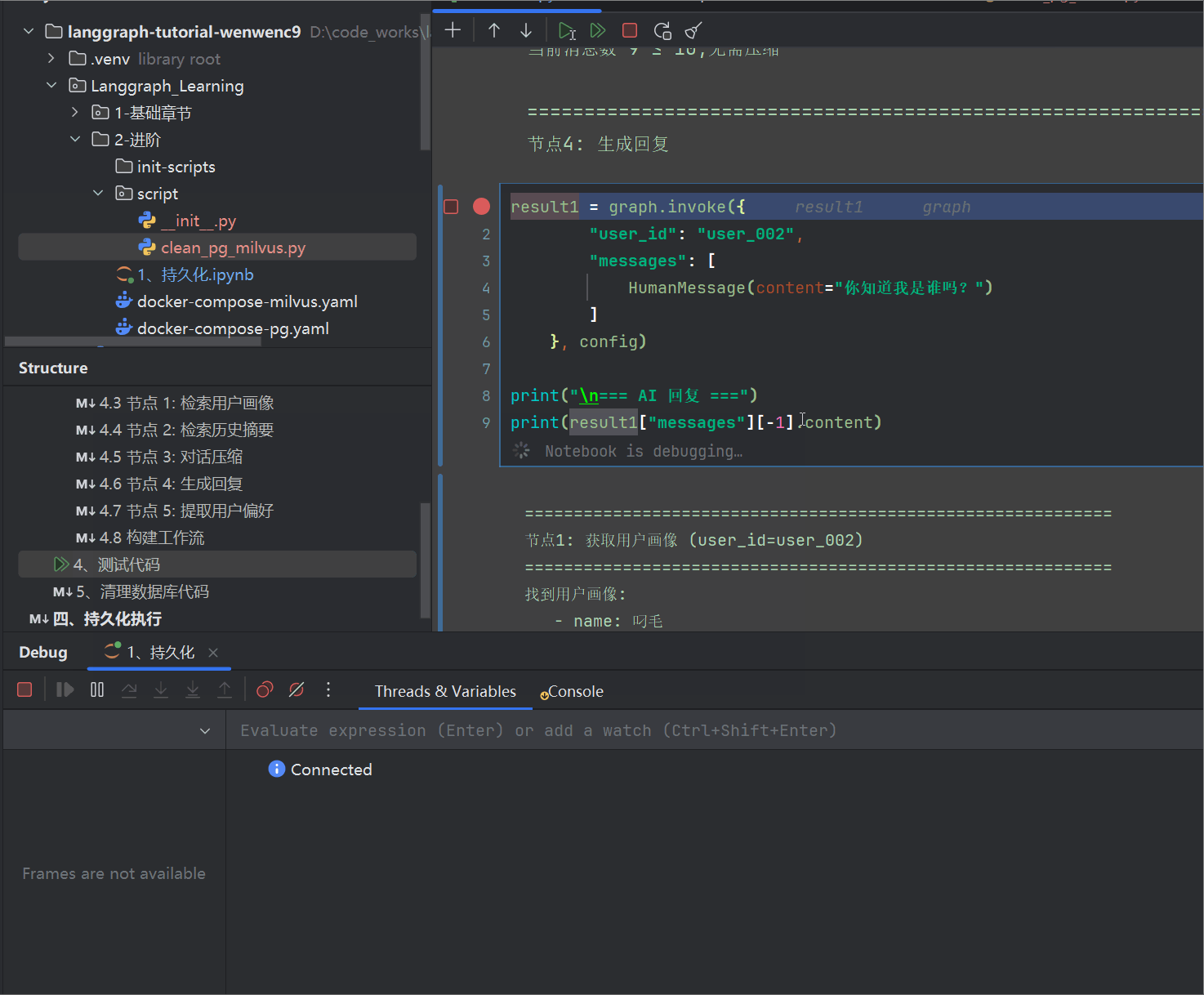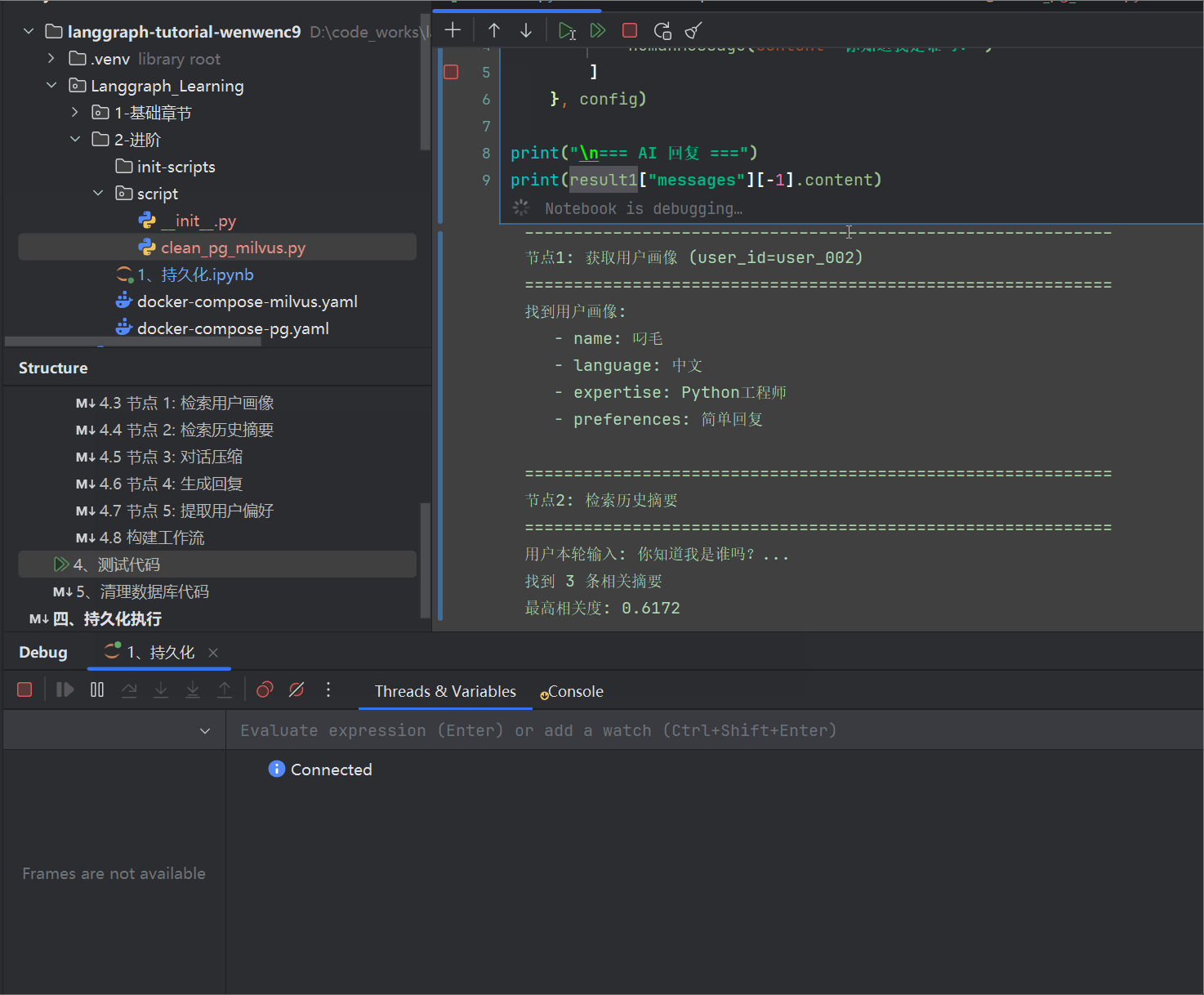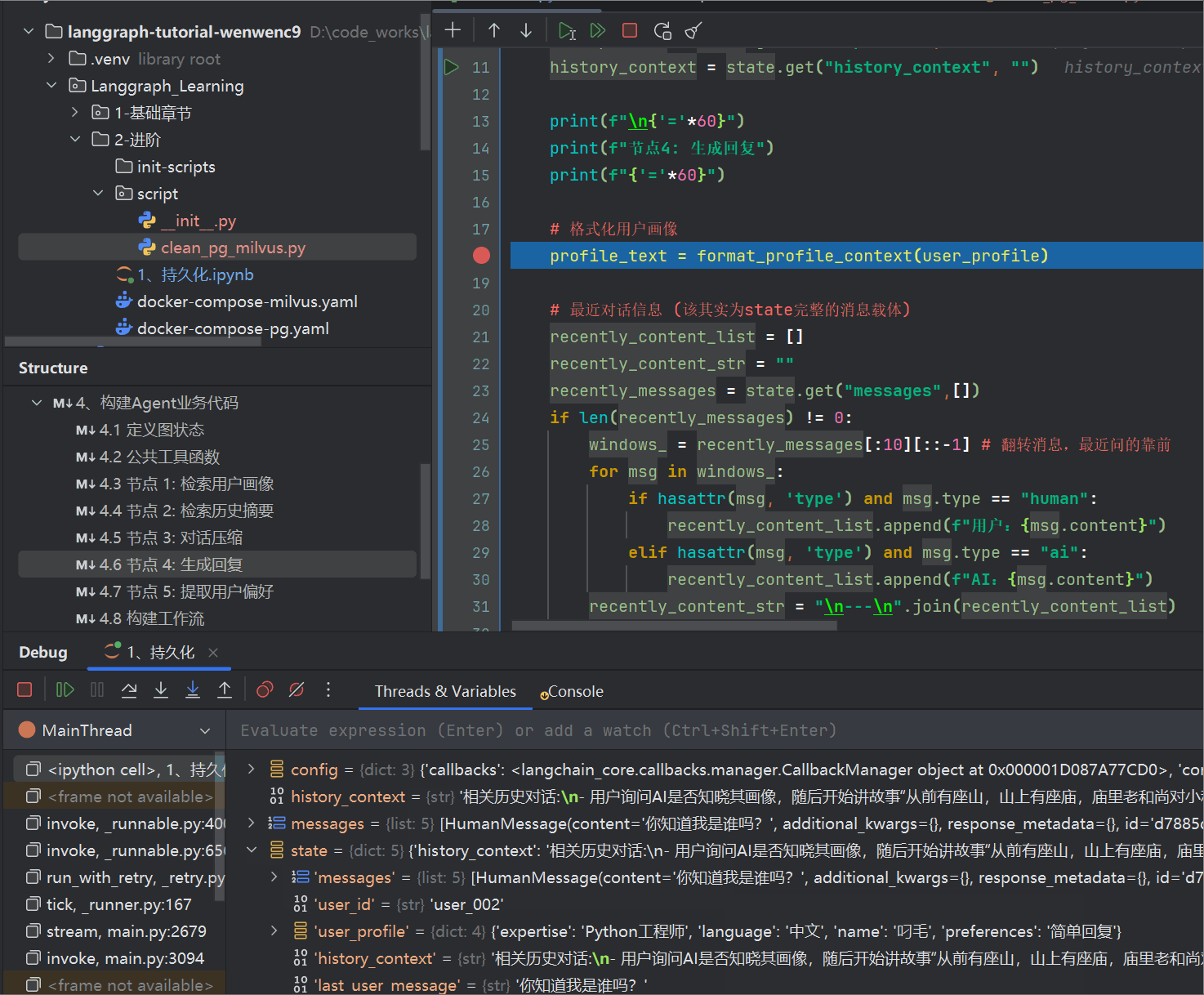
堆栈如下,你可以选择前面批量对话的时候,在所有节点入口跟出口都debugger体验每一轮对话
- 观察黄色框这些状态的变化,体验节点函数的逻辑
- 并且观察数据库pg,跟milvus

六、Durable Execution (持久化执行)
官方文档:https://docs.langchain.com/oss/python/langgraph/durable-execution
持久化执行(Durable Execution) 是一种在关键点保存工作流进度的技术,允许工作流暂停并在稍后从断点恢复。
这在以下场景特别有用:
- 人工介入场景:需要人工审核、验证或修改
- 长时间运行任务:可能遇到中断或错误
- 从失败恢复:避免重新执行已完成的步骤
LangGraph 的内置持久化层确保每个执行步骤的状态都被保存到持久化存储中,无论是系统故障还是人工介入,工作流都可以从最后记录的状态恢复。
1、Durable Execution 是什么?
1.1 核心概念
Durable Execution (持久化执行) 是一种让工作流在关键点保存进度,并能在中断后精确恢复的技术。
传统执行模式:开始 → 步骤1 → 步骤2 → [中断] → ❌ 从头开始Durable Execution:开始 → 步骤1 → 步骤2 → [中断] → ✅ 从步骤2继续
1.2 为什么需要?
| 场景 | 问题 | Durable Execution 解决方案 |
|---|---|---|
| LLM 超时 | API 调用失败,前面的工作白费 | 从失败点重试,保留已完成工作 |
| 人工审核 | 需要暂停等待审批 | 保存状态,审批后继续 |
| 长时间任务 | 系统重启,任务丢失 | 从 Checkpoint 恢复 |
| 多步骤流程 | 某一步失败,全部重来 | 只重试失败的步骤 |
1.3 与 Checkpoint 的关系
# Checkpoint: 数据持久化
checkpointer = PostgresSaver.from_conn_string(DB_URI)
graph = builder.compile(checkpointer=checkpointer)# Durable Execution: 在 Checkpoint 基础上
# + 确定性执行(同样的输入 → 同样的输出)
# + 幂等性(重复执行 → 同样的效果)
# + 副作用隔离(@task 包装)
关系:
- Checkpoint 是存储机制
- Durable Execution 是执行策略
- 两者结合实现可靠的工作流
2、核心要求
2.1 三大要求
根据 官方文档,要实现 Durable Execution 需要:
-
启用 Checkpointer
graph = builder.compile(checkpointer=checkpointer) -
指定 thread_id
config = {"configurable": {"thread_id": "task_001"}} graph.invoke(input_data, config) -
使用
@task包装副作用from langgraph.func import task@task def call_api(url: str):return requests.get(url).json()
3、确定性与一致性回放
3.1 什么是确定性?
确定性: 同样的输入 → 同样的输出
# 确定性函数
def add(a, b):return a + b# 非确定性函数
import random
def random_add(a, b):return a + b + random.randint(0, 10) # 每次结果不同
3.2 为什么需要确定性?
当工作流恢复时,LangGraph 不是从中断的代码行继续,而是:
- 找到合适的起始点
- 重放(replay)所有步骤
- 使用已保存的结果,而不是重新计算
示例:
# 工作流: 步骤1 → 步骤2 → 步骤3
# 执行到步骤2后中断# 恢复时:
# 不是从步骤2的某一行继续
# 而是从步骤1开始重放
# → 步骤1: 使用保存的结果
# → 步骤2: 继续执行
如果不确定性:
# 错误示例
def step1():x = random.randint(0, 100) # 第一次: x=42return x# 第一次执行: x=42 → 保存
# 恢复后重放: x=73 → 不一致!
4、使用 @task 包装副作用
4.1 什么是副作用?
副作用: 除了返回值外,还会影响外部状态的操作
| 类型 | 示例 | 问题 |
|---|---|---|
| 网络请求 | requests.get() | 可能超时/失败 |
| 文件操作 | open("file.txt", "w") | 重复执行会覆盖 |
| 数据库写入 | db.insert() | 重复执行会重复插入 |
| 随机数 | random.randint() | 每次结果不同 |
| 日志记录 | logger.info() | 重复执行会重复记录 |
4.2 使用 @task 包装
from langgraph.func import task
import requests# 不使用 @task (会重复执行)
def call_api_bad(url: str):response = requests.get(url) # 恢复时会重新调用!return response.json()# 使用 @task (结果会被缓存)
@task
def call_api_good(url: str):response = requests.get(url) # 只执行一次,结果被保存return response.json()
工作原理:
第一次执行:@task 执行 → API 调用 → 结果保存到 Checkpoint工作流中断并恢复:@task 检查 Checkpoint → 发现已有结果 → 直接返回 不会重新调用 API!
5、三种持久化模式
根据 官方文档,LangGraph 支持三种持久化模式:
5.1 模式对比
| 模式 | 何时保存 | 性能 | 持久性 | 适用场景 |
|---|---|---|---|---|
"exit" | 工作流结束时 | ⭐⭐⭐⭐⭐ | ⭐ | 短任务,不需要中断 |
"async" | 异步保存,下一步同时执行 | ⭐⭐⭐⭐ | ⭐⭐⭐ | 平衡性能和可靠性(默认) |
"sync" | 每步执行前同步保存 | ⭐⭐ | ⭐⭐⭐⭐⭐ | 关键任务,不能丢失数据 |
5.2 使用方法
# 方式1: 编译时指定(全局)
graph = builder.compile(checkpointer=checkpointer,durability="sync" # 所有调用都用 sync 模式
)# 方式2: 调用时指定(局部)
graph.invoke(input_data,config=config,durability="async" # 只有这次调用用 async
)
5.3 详细说明
"exit" 模式
graph.invoke(input_data, config, durability="exit")# 执行过程:
# 步骤1 → 步骤2 → 步骤3 → [保存]
#
# 如果在步骤2中断:
# ❌ 无法恢复(没有中间 Checkpoint)
适用: 快速任务,不需要中断恢复
"async" 模式 (默认)
graph.invoke(input_data, config, durability="async")# 执行过程:
# 步骤1 → [异步保存] → 步骤2 → [异步保存] → 步骤3
# ↓ 同时进行 ↓ 同时进行
# 保存中... 保存中...
#
# 小风险: 如果进程在"保存中"时崩溃,可能丢失 Checkpoint
适用: 大多数场景(平衡性能和可靠性)
"sync" 模式
graph.invoke(input_data, config, durability="sync")# 执行过程:
# 步骤1 → [等待保存完成] → 步骤2 → [等待保存完成] → 步骤3
#
# 每步都确保保存完成后才继续
适用: 关键任务,绝不能丢失进度
6、案例体验
根据官方文档改造

我们带着业务思维想象一下,理解下task
订单处理流程
业务流程:
- 验证用户信息(调用用户服务 API)
- 检查库存(调用库存服务 API)
- 创建订单(写入数据库)
- 发起支付(调用支付网关)
- 发送确认邮件
- 问题:如果在第 4 步支付时网络超时怎么办?
没有持久化执行:
- 重试时,从头开始执行
- 用户信息被重复查询
- 库存被重复检查
- 订单可能被重复创建(严重问题!)
- 支付请求被重复发送
- 用户收到多封邮件
使用持久化执行 + @task:
- 重试时,从支付步骤继续
- 前面的步骤结果从检查点恢复
- 订单只创建一次
- 只重新尝试支付
- 避免重复操作
我们其实可以在人机交互,撰写出这个案例,但是为了体验,我们可以仅用task,不结合interrupt跟command
有兴趣的可以研究一下,官方也有提及
| API | 用途 | 示例 |
|---|---|---|
interrupt("message") | 暂停工作流 | interrupt("需要审批") |
Command(update={...}) | 更新状态并恢复 | Command(update={"status": "approved"}) |
graph.invoke(None, config) | 从检查点恢复 | graph.invoke(None, config=config) |
@task | 包装副作用操作 | @task def api_call(): ... |
graph.get_state(config) | 获取当前状态 | state = graph.get_state(config) |
graph.get_state_history(config) | 获取历史记录 | history = graph.get_state_history(config) |
我们简化这个业务流程,在相同thread_id下 我们调用3次API
用户重启系统后,用一个新的thread_id 情况下,我们可以恢复已经执行完成的API调用,避免重复调用
6.1 构建工作流
from typing import NotRequired
from typing_extensions import TypedDict
import uuid
import time
from langgraph.checkpoint.memory import MemorySaver
from langgraph.func import task
from langgraph.graph import StateGraph, START, END# 定义状态类型
class State(TypedDict):urls: list[str]results: NotRequired[list[str]]# 用于追踪 API 调用次数
api_call_counter = {"count": 0}@task
def _make_request(url: str):"""使用 @task 装饰器包装的 API 请求函数关键点:- @task 确保这个函数只执行一次- 结果会被保存到检查点- 恢复时直接使用保存的结果,不会重新调用"""api_call_counter["count"] += 1print(f"正在调用 API: {url} (第 {api_call_counter['count']} 次调用)")# 模拟网络延迟time.sleep(0.5)# 这里可以用真实的 requests,为了演示我们模拟一个响应# 如果你想测试真实API,取消下面这行的注释:# import requests# return requests.get(url).text[:100]# 模拟响应response = f"Response from {url} at {time.strftime('%H:%M:%S')}"print(f" API 调用成功: {url}")return responsedef call_api(state: State):"""节点函数:调用多个 API工作流程:1. 为每个 URL 创建一个 @task 包装的请求2. 调用 .result() 获取结果3. 返回结果列表"""print(f"\n开始处理 {len(state['urls'])} 个 API 请求...")# 创建所有请求任务requests = [_make_request(url) for url in state['urls']]# 获取所有结果results = [request.result() for request in requests]print(f"所有 API 请求完成\n")return {"results": results}# 创建工作流
builder = StateGraph(State)
builder.add_node("call_api", call_api)# 连接节点
builder.add_edge(START, "call_api")
builder.add_edge("call_api", END)# 指定检查点存储器
checkpointer = MemorySaver()# 编译图
graph = builder.compile(checkpointer=checkpointer)
6.2 首次执行
# 重置计数器
api_call_counter["count"] = 0# 定义配置(包含 thread_id)
thread_id = str(uuid.uuid4())
config = {"configurable": {"thread_id": thread_id}}print(f"Thread ID: {thread_id}")# 调用图
result1 = graph.invoke({"urls": ["https://api.example.com/users","https://api.example.com/posts","https://api.example.com/comments"]
}, config)print("执行结果:")
for i, res in enumerate(result1['results'], 1):print(f" {i}. {res}")
print(f"\n总 API 调用次数: {api_call_counter['count']}")输出结果如下,可以看到我们调用了3次API
Thread ID: 670ade57-8960-4b63-9559-a7b474948d7c开始处理 3 个 API 请求...
正在调用 API: https://api.example.com/users (第 1 次调用)
正在调用 API: https://api.example.com/posts (第 2 次调用)
正在调用 API: https://api.example.com/comments (第 3 次调用)API 调用成功: https://api.example.com/users API 调用成功: https://api.example.com/commentsAPI 调用成功: https://api.example.com/posts所有 API 请求完成执行结果:1. Response from https://api.example.com/users at 18:21:352. Response from https://api.example.com/posts at 18:21:353. Response from https://api.example.com/comments at 18:21:35总 API 调用次数: 3
6.3 查看保存状态
saved_state = graph.get_state(config)
print(f"\n状态已保存到检查点:")
print(f" - URLs 数量: {len(saved_state.values['urls'])}")
print(f" - 结果数量: {len(saved_state.values.get('results', []))}")
print(f" - 工作流状态: 已完成")
输出如下
状态已保存到检查点:- URLs 数量: 3- 结果数量: 3- 工作流状态: 已完成
6.4 模拟检查点回复(进程重启后)
# 模拟创建一个新的图实例(就像进程重启后重新加载)
graph_after_restart = builder.compile(checkpointer=checkpointer)print(f"使用相同的 thread_id 恢复状态...")
print(f"Thread ID: {thread_id}")# 直接获取状态(不重新执行)
recovered_state = graph_after_restart.get_state(config)print(f"\n成功恢复状态:")
print(f" - URLs: {recovered_state.values['urls']}")
print(f" - 结果数量: {len(recovered_state.values.get('results', []))}")
print(f" - API 调用总次数: {api_call_counter['count']} (没有增加!)")
输出如下,可以看到API调用的计数器还是为3,并没有实际调用API
使用相同的 thread_id 恢复状态...
Thread ID: 670ade57-8960-4b63-9559-a7b474948d7c成功恢复状态:- URLs: ['https://api.example.com/users', 'https://api.example.com/posts', 'https://api.example.com/comments']- 结果数量: 3- API 调用总次数: 3 (没有增加!)
七、总结
langgraph官方设计的组件,API非常丰富,我们需要逐步调试理解设计模式跟内容,才能掌握,生态很多或许学不完。
但是至少过一遍,未来在企业项目中,我们也有思路跟运用策略