Linux 内存管理 (4):buddy 管理系统的建立
文章目录
- 1. 前言
- 2. buddy 系统的建立过程
- 2.1 建立 low memory 的线性映射
- 2.2 建立物理内存页面管理数据 `pglist_data`
- 2.3 移交 bootmem 给内存管理系统
- 3. 参考资料
1. 前言
限于作者能力水平,本文可能存在谬误,因此而给读者带来的损失,作者不做任何承诺。
2. buddy 系统的建立过程
前述篇章
Linux 内存管理 (1):内核镜像映射临时页表的建立
Linux 内存管理 (2):memblock 子系统的建立
Linux 内存管理 (3):fixmap
讲述了 Linux BOOT 早期的内存管理,即 memblock 内存管理。期间,主要做了以下内存管理相关的工作:
- 建立内核镜像的临时映射页表,目的是开启 MMU 可以让内核先运行起来
- 收集系统物理内存信息,然后纳入
memblock管理
Linux BOOT 早期用 memblock 接口分配内存,通过 fixmap 的建立映射,完成了 Linux BOOT 早期的内存管理工作。接下来,要建立 正式、完整的 Linux 内存管理体系,主要是建立 buddy 和 slab 分配器,本篇只涉及 buddy 分配器。
Linux 内存 buddy 管理系统的建立过程,主要包括:
- 建立
low memory的线性映射 - 建立物理内存页面管理数据
pglist_data - 移交 bootmem (membock 管理的内存) 给内存管理系统
本文承接前述篇章,依旧以 ARM32 架构 + Linux 4.14.x 为例,描述内存 buddy 管理系统建立的细节。先看 low memory 线性映射的过程。
2.1 建立 low memory 的线性映射
什么是 low memory?在 32-bit 硬件架构下(如本文的 ARM32),(不考虑 PAE 情形下)CPU 最大可寻址 2^32 = 4GB 地址空间;然后更进一步,4GB 的地址空间又被划分为内核和用户空间两部分,这两部分根据不同的内核配置,呈 1G/3G,2G/2G,3G/1G 3 种可能的分布。但不管选择这 3 种哪一种划分,当物理内存超过内核地址空间大小时,就只会有部分物理内存能够直接线性映射到内核地址空间,这部分物理内存就称为 low memory。与之相对的,物理内存剩余部分称为 high memory,如果内核要访问 high memory,就需要通过 kmap 接口进行临时映射。ARMv7 下,内核和用户空间两部分默认呈 1G/3G 分布,刨去 vmalloc、中断向量表、fixmap、PCI IO 等部分,low memory 的大小约为 768MB 左右,这还要刨去内核镜像、swapper_pg_dir 占据的一部分,ARMv7 架构下 Linux 4GB 虚拟地址空间分布大概如下图:
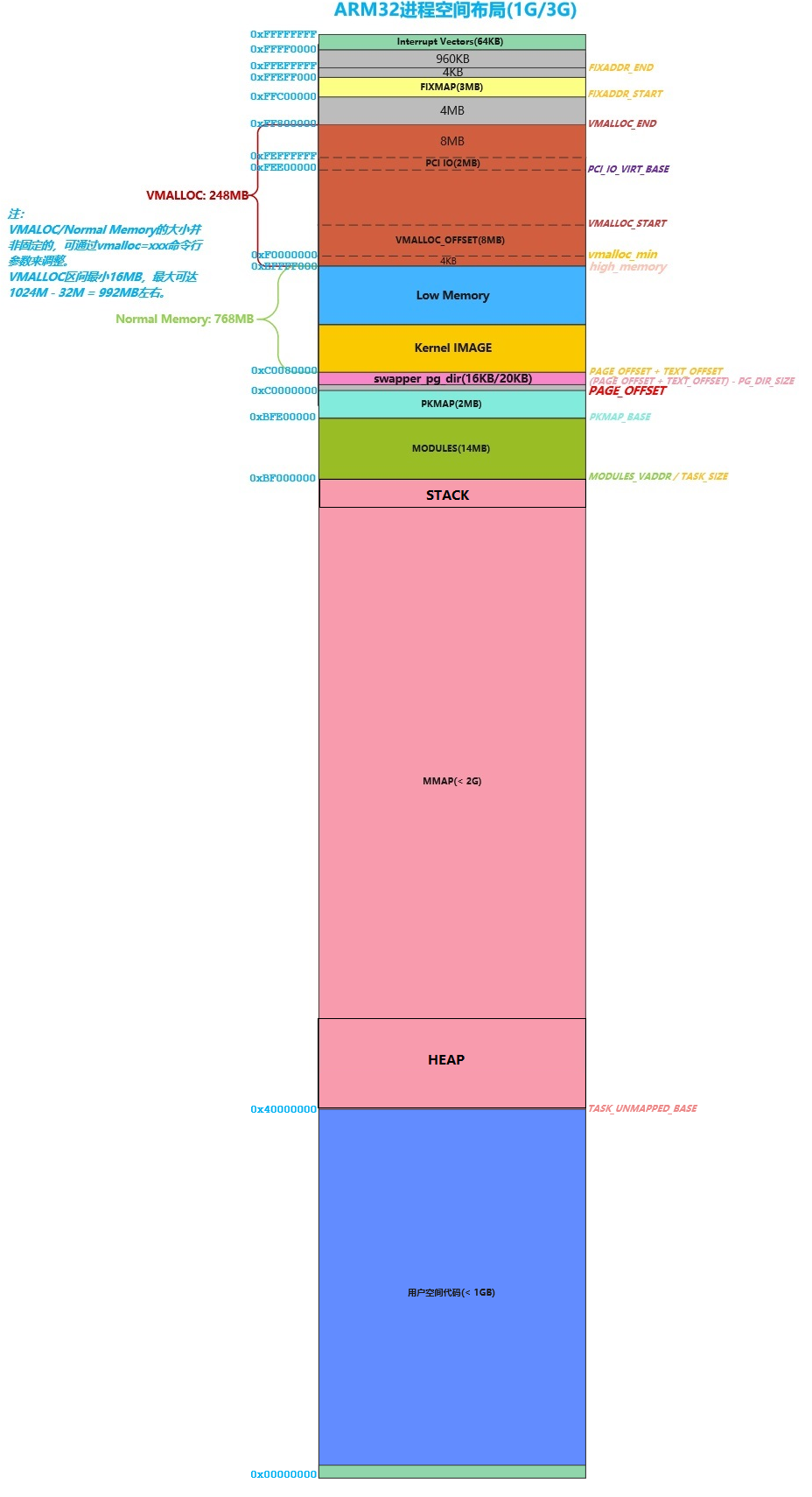
来看看建立 low memory 的线性映射的细节:
start_kernel()setup_arch()...mdesc = setup_machine_fdt(__atags_pointer); /* 将物理内存纳入 memblock 管理 */...adjust_lowmem_bounds(); /* 划分 low/high memory 分解 */arm_memblock_init(mdesc); /* 初始化 memblock */...paging_init(mdesc);...map_lowmem(); /* 建立 low memory 线性映射 */...static void __init map_lowmem(void)
{.../* Map all the lowmem memory banks. */for_each_memblock(memory, reg) {...if (end < kernel_x_start) { /* 映射 内核镜像所在区域 以下 区域 为 RWX */map.pfn = __phys_to_pfn(start);map.virtual = __phys_to_virt(start);map.length = end - start;map.type = MT_MEMORY_RWX;create_mapping(&map);} else if (start >= kernel_x_end) { /* 映射 内核镜像所在区域 以上 区域 为 RW */map.pfn = __phys_to_pfn(start);map.virtual = __phys_to_virt(start);map.length = end - start;map.type = MT_MEMORY_RW;create_mapping(&map);} else { /* 内核镜像 所在区间 (最新建立映射的内存区域: 内核应该位于第 1 块内存区域) *//** 包含 kernel 的 struct memblock_region 区域:* struct* memblock_region* -------- <- end ^ high* | area 2 | |* |........|<- kernel_x_end |* | | |* | kernel | |* | | |* |........|<- kernel_x_start |* | area 1 | |* -------- <- start | low** 例子:* 512 MB RAM, [0x60000000,0x80000000)*//* This better cover the entire kernel */if (start < kernel_x_start) { /* 映射 area 1 为 RW 属性 */map.pfn = __phys_to_pfn(start);map.virtual = __phys_to_virt(start);map.length = kernel_x_start - start;map.type = MT_MEMORY_RW;/* * 例子:* 虚拟地址空间 物理地址空间* [0x80000000,0x80100000) => [0x60000000,0x60100000) * 映射 1MB 的 area 1: 物理起始地址 和 内核起始位置 间的空隙.*/create_mapping(&map);}/** 映射内核镜像所在区域为 RWX 属性: * 此处创建的内核镜像的映射和 head.S:__create_page_tables* 创建的一致, 只是修改 section 的属性为 RWX .*//** 例子:* 虚拟地址空间 物理地址空间* [0x80100000,0x80a00000) => [0x60100000,0x60a00000) * 映射 9MB: kernel 区间.*/ map.pfn = __phys_to_pfn(kernel_x_start);map.virtual = __phys_to_virt(kernel_x_start);map.length = kernel_x_end - kernel_x_start;map.type = MT_MEMORY_RWX;create_mapping(&map);if (kernel_x_end < end) { /* 映射 area 2 为 RW 属性 */map.pfn = __phys_to_pfn(kernel_x_end);map.virtual = __phys_to_virt(kernel_x_end);map.length = end - kernel_x_end;map.type = MT_MEMORY_RW;/* * 例子:* 虚拟地址空间 物理地址空间* [0x80a00000,0xa0000000) => [0x60a00000,0x80000000) * 映射 502MB 的 area 2: 内核以上的空间.*/create_mapping(&map);}}}...
}create_mapping()__create_mapping(&init_mm, md, early_alloc, false); /* 建立的页表属于内核空间 */alloc_init_pud()alloc_init_pmd()__map_init_section() / alloc_init_pte()
在 alloc_init_pmd() 中有两种情形:一是按 section 映射,进入 __map_init_section();另一个是按 page 映射,进入 alloc_init_pte():
static void __init __map_init_section(pmd_t *pmd, unsigned long addr,unsigned long end, phys_addr_t phys,const struct mem_type *type, bool ng)
{pmd_t *p = pmd;#ifndef CONFIG_ARM_LPAE/** In classic MMU format, puds and pmds are folded in to* the pgds. pmd_offset gives the PGD entry. PGDs refer to a* group of L1 entries making up one logical pointer to* an L2 table (2MB), where as PMDs refer to the individual* L1 entries (1MB). Hence increment to get the correct* offset for odd 1MB sections.* (See arch/arm/include/asm/pgtable-2level.h)*/if (addr & SECTION_SIZE)pmd++;
#endifdo {*pmd = __pmd(phys | type->prot_sect | (ng ? PMD_SECT_nG : 0)); /* 更新 PMD 页表项 */phys += SECTION_SIZE;} while (pmd++, addr += SECTION_SIZE, addr != end);flush_pmd_entry(p); /* 刷页表项的 TLB */
}
static void __init alloc_init_pte(pmd_t *pmd, unsigned long addr,unsigned long end, unsigned long pfn,const struct mem_type *type,void *(*alloc)(unsigned long sz),bool ng)
{/* * lowmem 均按 section 建立页表映射, 如此:* . lowmem 映射完成之前, 不需要分配 PTE 页表,因为 swapper_pg_dir * 已经在编译时内置到内核镜像空间了;* . lowmem 映射完成之后, 从 lowmem 分配已经建立映射 PTE 页表空间.*/pte_t *pte = arm_pte_alloc(pmd, addr, type->prot_l1, alloc);do {set_pte_ext(pte, pfn_pte(pfn, __pgprot(type->prot_pte)),ng ? PTE_EXT_NG : 0);pfn++;} while (pte++, addr += PAGE_SIZE, addr != end);
}static pte_t * __init arm_pte_alloc(pmd_t *pmd, unsigned long addr,unsigned long prot,void *(*alloc)(unsigned long sz))
{if (pmd_none(*pmd)) { /* 如果虚拟地址 @addr 对应的 PMD 表项为空,即对应的 PTE 页表尚未分配 *//** 分配 pte 页表空间:* . 2 级分页时,包含 (Linux + ARM MMU 硬件) pte 页表空间;* . 3 级分页时,仅包含 ARM MMU 硬件页表空间。* 2,3 级分也是,分配的大小刚好是 1 个页面,而且返回空间* 的起始地址是对齐到页面的。*/pte_t *pte = alloc(PTE_HWTABLE_OFF + PTE_HWTABLE_SIZE); /* early_alloc() */__pmd_populate(pmd, __pa(pte), prot);}BUG_ON(pmd_bad(*pmd));/** . 2 级分页时,返回 @addr 的 Linux pte 表项指针;* . 3 级分页时,返回 @addr 的 ARM MMU 硬件 pte 表项指针。*/return pte_offset_kernel(pmd, addr);
}
到此,ARM32 架构下形成了如下图所示的 2 级 或 3 级分页表结构:
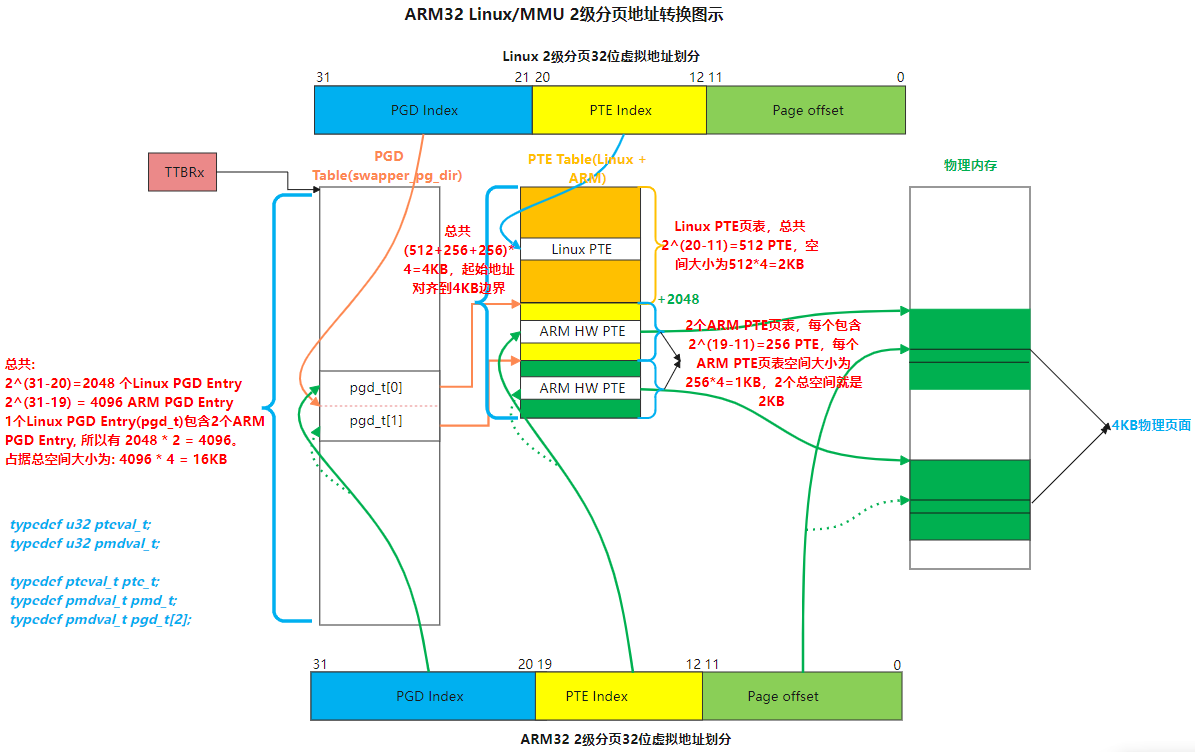
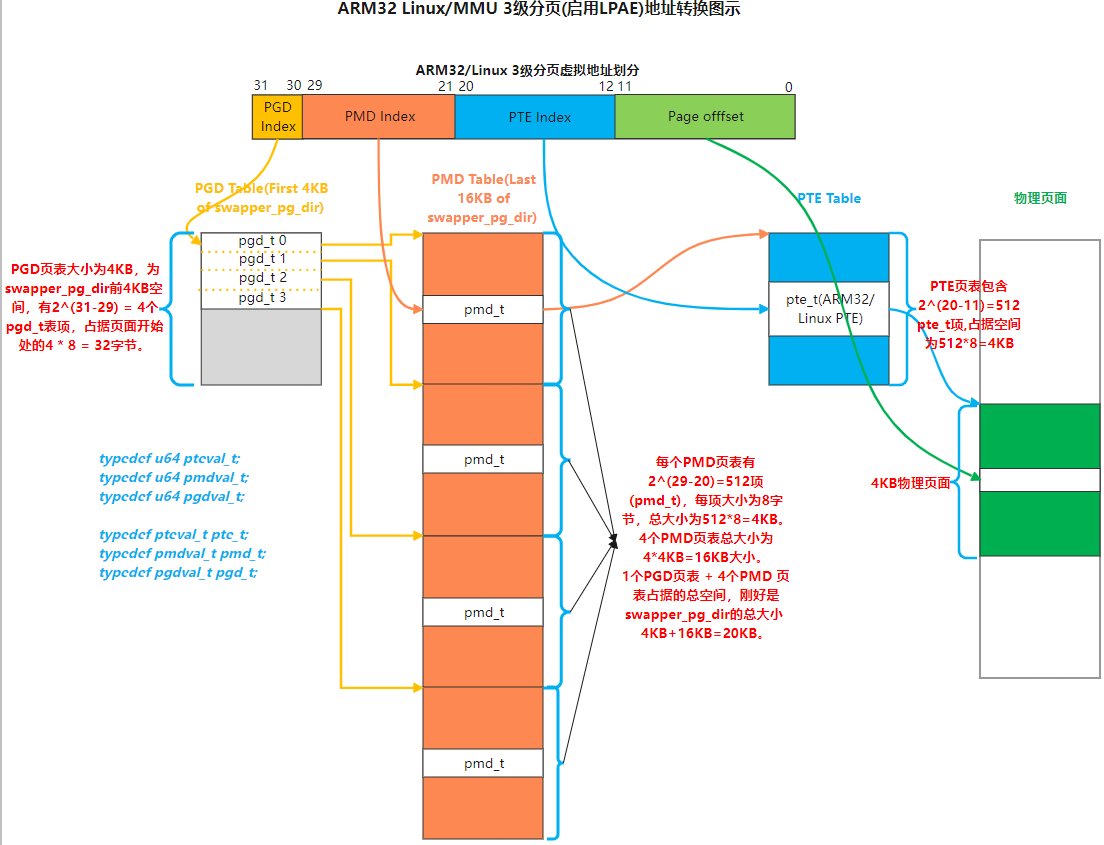
接下来,继续看物理内存页面管理数据的建立过程。
2.2 建立物理内存页面管理数据 pglist_data
本文讨论不连续内存模型(Discontiguous Memory Model)的情形,而事实上通常使用稀疏内存模型(Sparse Memory Model)。但这并不影响对 pglist_data 建立过程的理解。稀疏内存模型(Sparse Memory Model)增加了 mem_section 数据结构,对页面的页框号做了进一步管理,主要实现于 mm/spare.c,感兴趣的读者可以去看看。来看 pglist_data 建立过程的代码细节:
start_kernel()setup_arch()paging_init()...map_lowmem(); /* 建立 low memory 线性映射 */...bootmem_init(); /* 初始化 NUMA 节点 0 内存页面信息管理数据 pg_data_t */...build_all_zonelists(NULL); /* 构建 NUMA 节点 0 的 zone list */build_all_zonelists_init()
void __init bootmem_init(void)
{unsigned long min, max_low, max_high;...max_low = max_high = 0;/** 在 NUMA 下,此时 memblock 仅包含 BOOT CPU 所在 NODE 0 的内存,* 其它的内存在以下情形下添加:* . 非 BOOT CPU 启动时扫描* . 内存设备驱动加载时** @min : DRAM 起始物理地址 页框号* @max_low : lowmem 最大页框号* @max_high: DRAM 结束物理地址 页框号*/find_limits(&min, &max_low, &max_high);/** Now free the memory - free_area_init_node needs* the sparse mem_map arrays initialized by sparse_init()* for memmap_init_zone(), otherwise all PFNs are invalid.*/zone_sizes_init(min, max_low, max_high);/** This doesn't seem to be used by the Linux memory manager any* more, but is used by ll_rw_block. If we can get rid of it, we* also get rid of some of the stuff above as well.*/min_low_pfn = min;max_low_pfn = max_low;max_pfn = max_high;
}static void __init zone_sizes_init(unsigned long min, unsigned long max_low,unsigned long max_high)
{unsigned long zone_size[MAX_NR_ZONES], zhole_size[MAX_NR_ZONES];struct memblock_region *reg;/** initialise the zones.*/memset(zone_size, 0, sizeof(zone_size));/** The memory size has already been determined. If we need* to do anything fancy with the allocation of this memory* to the zones, now is the time to do it.*//** [NUMA 节点 0] lowmem 物理页面总数(包含可能的空洞页面数): * 每两个 memblock_region 之间在空间上可能并非连续的, 存在空洞.*/zone_size[0] = max_low - min;
#ifdef CONFIG_HIGHMEM/** highmem 物理页面总数(包含可能的空洞页面数): * 每两个 memblock_region 之间在空间上可能并非连续的, 存在空洞.*/zone_size[ZONE_HIGHMEM] = max_high - max_low;
#endif/** Calculate the size of the holes.* holes = node_size - sum(bank_sizes)*/memcpy(zhole_size, zone_size, sizeof(zhole_size));/* * 计算 [NUMA 节点 0] 各 zone 的 空洞物理页面总数: * lowmem(ZONE_NORMAL) 和 highmem(ZONE_HIGHMEM). */for_each_memblock(memory, reg) {unsigned long start = memblock_region_memory_base_pfn(reg);unsigned long end = memblock_region_memory_end_pfn(reg);if (start < max_low) { /* 内存区域 @reg 部分 或 全部 位于 lowmem 区间 */unsigned long low_end = min(end, max_low); /* 去掉可能位于 highmem 的部分 *//** 从 lowmem 物理页面总数(包含可能的空洞页面数), * 减去 每个 @reg 位于 lowmem 的物理页面数, 最后* 剩下的就是各个 @reg 之间的空洞页面总数.*/zhole_size[0] -= low_end - start;}
#ifdef CONFIG_HIGHMEMif (end > max_low) { /* 内存区域 @reg 部分 或 全部 位于 highmem 区间 */unsigned long high_start = max(start, max_low);/** 从 highmem 物理页面总数(包含可能的空洞页面数), * 减去 每个 @reg 位于 highmem 的物理页面数, 最后* 剩下的就是各个 @reg 之间的空洞页面总数.*/zhole_size[ZONE_HIGHMEM] -= end - high_start;}
#endif}...free_area_init_node(0, zone_size, min, zhole_size);
}void __paginginit free_area_init_node(int nid, unsigned long *zones_size,unsigned long node_start_pfn, unsigned long *zholes_size)
{pg_data_t *pgdat = NODE_DATA(nid);unsigned long start_pfn = 0;unsigned long end_pfn = 0;...pgdat->node_id = nid; /* 设定 pg_data_t 管理的 NUMA 节点 ID 为 @nid */pgdat->node_start_pfn = node_start_pfn; /* 设定 pg_data_t 管理的 NUMA 节点 物理内存 的 起始页框号 */pgdat->per_cpu_nodestats = NULL;#ifdef CONFIG_HAVE_MEMBLOCK_NODE_MAP...
#elsestart_pfn = node_start_pfn;
#endif/** 计算并设定 NUMA 节点 @pgdat->node_id 内各 zone 的 物理页框总数:* . spanned page 总数(包括 空洞 page 总数) => pglist_data::spanned_pages* . present page 总数(spanned page 总数 - 空洞 page 总数) => pglist_data::present_pages** 计算并设定 NUMA 节点 @pgdat->node_id 的 物理页框总数:* . spanned 物理页框总数 (包括 空洞 page) => zone::spanned_pages* . present 物理页框总数 (不含 空洞 page) => zone::present_pages*/calculate_node_totalpages(pgdat, start_pfn, end_pfn,zones_size, zholes_size);/** 为 NUMA 节点 @pgdat->node_id 分配每物理页框的管理数据 struct page:* 设置到 @pgdat->node_mem_map .* 在非多 NUMA 节点的系统下, 将 mem_map 指向 NUMA 节点 0 的 struct page 数据.*/alloc_node_mem_map(pgdat);...free_area_init_core(pgdat);
}static void __paginginit free_area_init_core(struct pglist_data *pgdat)
{enum zone_type j;int nid = pgdat->node_id;...init_waitqueue_head(&pgdat->kswapd_wait);init_waitqueue_head(&pgdat->pfmemalloc_wait);
#ifdef CONFIG_COMPACTIONinit_waitqueue_head(&pgdat->kcompactd_wait);
#endif...spin_lock_init(&pgdat->lru_lock);lruvec_init(node_lruvec(pgdat));...for (j = 0; j < MAX_NR_ZONES; j++) {struct zone *zone = pgdat->node_zones + j;unsigned long size, realsize, freesize, memmap_pages;unsigned long zone_start_pfn = zone->zone_start_pfn;size = zone->spanned_pages;realsize = freesize = zone->present_pages;.../* 计算 页面管理数据 struct page 占用空间(向上对齐到页面大小) 的 页面数 */ memmap_pages = calc_memmap_size(size, realsize);if (!is_highmem_idx(j)) { /* 非 highmem 内存 zone */if (freesize >= memmap_pages) {/** 更新 非 highmem @j 类型 内存 zone 的 空闲可用页面 数目:* 空闲页面总数 @freesize* 减去 * 用于页面管理的 struct page 数据占用的页面数 @memmap_pages .*/freesize -= memmap_pages;...} else...}/* Account for reserved pages */if (j == 0 && freesize > dma_reserve) {freesize -= dma_reserve; /* @j 类型 内存 zone 的 空闲可用页面 减去 DMA 保留页面 */...}if (!is_highmem_idx(j))nr_kernel_pages += freesize; /* @j 类型 内存 zone 的 空闲页面 计入系统内 非 highmem 总数 *//* Charge for highmem memmap if there are enough kernel pages */else if (nr_kernel_pages > memmap_pages * 2)nr_kernel_pages -= memmap_pages;nr_all_pages += freesize;/* * 设定 @j 类型 内存 zone 纳入伙伴管理系统 管理的页面数: * . 对于 【非 highmem】, * 设定的页面数 【不包含】 用于管理的 struct page 数据占据的页面数;* . 对于 【highmem】, * 设定的页面数 【包含】 用于管理的 struct page 数据占据的页面数.*/ zone->managed_pages = is_highmem_idx(j) ? realsize : freesize;
#ifdef CONFIG_NUMAzone->node = nid; /* 设定 @j 类型 内存 zone 所在的 NUMA 节点 ID */
#endif/** 设置 @j 类型 内存 zone 名称: * "DMA", "DMA32", "Normal", "HighMem", "Movable", "Device" */zone->name = zone_names[j];/* 设置 @j 类型 内存 zone 所在的 * NUMA 内存节点 @node 的 管理对象 pglist_data */zone->zone_pgdat = pgdat;spin_lock_init(&zone->lock);zone_seqlock_init(zone);zone_pcp_init(zone); /* 设置 内存 zone 每 CPU 的 页面管理数据 (PCP) */if (!size)continue;.../** 非 sparse 内存模型(CONFIG_SPARSEMEM=n). * 计算 + 分配 页面块 管理位图 zone pageblock flags (zone->pageblock_flags).*/setup_usemap(pgdat, zone, zone_start_pfn, size);/** . 更新 @zone 所在 pglist_data(NUMA 节点) 管理 的 zone 数目* . 设置 @zone 的 起始页面 页框号* . @zone 所有 order 的 所有 MIGRATE 类型的 空闲列表 初始为 NULL* @zone 所有 order 的 所有 MIGRATE 类型的 空闲页面数 初始为 0* 标记 @zone 已经初始化*/init_currently_empty_zone(zone, zone_start_pfn, size);/** 初始化 NUMA 节点 @nid 内 @zone 的页面管理数据(memmap/struct page):* . 标记每个 pageblock 中的 第 1 个 页面 为 MIGRATE_MOVABLE* . 设置页面 的 {zone 类型, NUMA 节点 ID, section ID} 到 struct page::flags* . 将 页面 的 引用计数 初始为 1* . 初始 页面 为 未映射状态: 映射计数设为 -1* . LRU 列表初始为空* ......*/memmap_init(size, nid, j, zone_start_pfn);}
}static __meminit void zone_pcp_init(struct zone *zone)
{/** per cpu subsystem is not up at this point. The following code* relies on the ability of the linker to provide the* offset of a (static) per cpu variable into the per cpu area.*/zone->pageset = &boot_pageset; /* 内存 zone 每 CPU 的 页面管理数据 (PCP) */...
}void __meminit init_currently_empty_zone(struct zone *zone,unsigned long zone_start_pfn,unsigned long size)
{struct pglist_data *pgdat = zone->zone_pgdat;int zone_idx = zone_idx(zone)/*@zone 的 索引/类型*/ + 1;/* 更新 pglist_data(NUMA 节点) 管理 的 zone 数目 */if (zone_idx > pgdat->nr_zones)pgdat->nr_zones = zone_idx;zone->zone_start_pfn = zone_start_pfn; /* 设置 zone 的 起始物理页面页框号 */.../** zone 空闲列表初始化: * . 所有 order 的 所有 MIGRATE 类型的 空闲列表 初始为 NULL* . 所有 order 的 所有 MIGRATE 类型的 空闲页面数 初始为 0*/zone_init_free_lists(zone);zone->initialized = 1; /* 标记 @zone 已经初始化 */
}static void __meminit zone_init_free_lists(struct zone *zone)
{unsigned int order, t;for_each_migratetype_order(order, t) {INIT_LIST_HEAD(&zone->free_area[order].free_list[t]);zone->free_area[order].nr_free = 0;}
}#define memmap_init(size, nid, zone, start_pfn) \memmap_init_zone((size), (nid), (zone), (start_pfn), MEMMAP_EARLY)void __meminit memmap_init_zone(unsigned long size, int nid, unsigned long zone,unsigned long start_pfn, enum memmap_context context)
{struct vmem_altmap *altmap = to_vmem_altmap(__pfn_to_phys(start_pfn));unsigned long end_pfn = start_pfn + size; /* @zone 的截止页框号 + 1 */pg_data_t *pgdat = NODE_DATA(nid);unsigned long pfn;unsigned long nr_initialised = 0;.../** 更新 所有 memmap 管理(struct page) 的 内存 的最大页框号。* mm/memory.c: highest_memmap_pfn*/if (highest_memmap_pfn < end_pfn - 1)highest_memmap_pfn = end_pfn - 1;/** Honor reservation requested by the driver for this ZONE_DEVICE* memory*/if (altmap && start_pfn == altmap->base_pfn)start_pfn += altmap->reserve;for (pfn = start_pfn; pfn < end_pfn; pfn++) {...
not_early:/** Mark the block movable so that blocks are reserved for* movable at startup. This will force kernel allocations* to reserve their blocks rather than leaking throughout* the address space during boot when many long-lived* kernel allocations are made.** bitmap is created for zone's valid pfn range. but memmap* can be created for invalid pages (for alignment)* check here not to call set_pageblock_migratetype() against* pfn out of zone.*/if (!(pfn & (pageblock_nr_pages - 1))) { /* 如果是 pageblock 中的 第 1 个 页面 */struct page *page = pfn_to_page(pfn);/** . 设置页面 @page 的 {zone 类型, NUMA 节点 ID, section ID} 到 @page->flags* . 将 页面 的 引用计数 初始为 1* . 初始 页面 为 未映射状态: 映射计数设为 -1* . LRU 列表初始为空* ......*/__init_single_page(page, pfn, zone, nid);/** 标记 pageblock 中的 第 1 个 页面 为 MIGRATE_MOVABLE. * pageblock 第 1 个 页面 的 flags 作为 pageblock 内所有* 页面 的 flags ???*/set_pageblock_migratetype(page, MIGRATE_MOVABLE);/* 避免 初始化时间过长, 每初始化完一个 pagebloc, 主动进行调度 */cond_resched();} else { /* pageblock 中的 非 第 1 个 页面??? *//** . 设置页面 @pfn 的 {zone 类型, NUMA 节点 ID, section ID} 到 @page->flags* . 将 页面 的 引用计数 初始为 1* . 初始 页面 为 未映射状态: 映射计数设为 -1* . LRU 列表初始为空* ......*/__init_single_pfn(pfn, zone, nid);}}
}static void __meminit __init_single_page(struct page *page, unsigned long pfn,unsigned long zone, int nid)
{/* 设置页面 @page 的 {zone 类型, NUMA 节点 ID, section ID} 到 @page->flags */set_page_links(page, zone, nid, pfn);init_page_count(page); /* 将 页面 的 引用计数 初始为 1 */page_mapcount_reset(page); /* 初始 页面 为 未映射状态: 映射计数设为 -1 */page_cpupid_reset_last(page);INIT_LIST_HEAD(&page->lru); /* LRU 列表初始为空 */
#ifdef WANT_PAGE_VIRTUAL/* The shift won't overflow because ZONE_NORMAL is below 4G. */if (!is_highmem_idx(zone))set_page_address(page, __va(pfn << PAGE_SHIFT));
#endif
}static void __meminit __init_single_pfn(unsigned long pfn, unsigned long zone,int nid)
{return __init_single_page(pfn_to_page(pfn), pfn, zone, nid);
}
build_all_zonelists_init() 构建 zone 列表,确定了 NUMA node/zone 的分配优先顺序。
static noinline void __init
build_all_zonelists_init(void)
{int cpu;/* 构建所有 NUMA 节点的 zone list */__build_all_zonelists(NULL);/* 每 CPU PCP 设置 */for_each_possible_cpu(cpu)setup_pageset(&per_cpu(boot_pageset, cpu), 0);...
}static void __build_all_zonelists(void *data)
{int nid;int __maybe_unused cpu;pg_data_t *self = data;static DEFINE_SPINLOCK(lock);spin_lock(&lock);#ifdef CONFIG_NUMAmemset(node_load, 0, sizeof(node_load));
#endifif (self && !node_online(self->node_id)) {...} else {/* 为所有 NUMA 节点 构建 FALLBACK 类型的 zonelist */for_each_online_node(nid) {pg_data_t *pgdat = NODE_DATA(nid);build_zonelists(pgdat);}...}spin_unlock(&lock);
}/** 构建 NUMA 节点 @pgdat->node_id FALLBACK 类型的 zonelist.** 函数调用后, NUMA 节点 @pgdat->node_id 的 FALLBACK 类型的 zonelist* 布局如下:** ------------- \* | ...... | |* | ZONE_NORMAL | } <-- NUMA 节点 pgdat->node_id 的 zonelist* | ...... | |* |------------- /* | ...... | \* | ZONE_NORMAL | |* | ...... | } <-- NUMA 节点 [pgdat->node_id + 1, MAX_NUMNODES] 的 zonelist* |-------------| }* | ...... | |* |-------------|/* | ...... | \* | ZONE_NORMAL | |* | ...... | } <-- NUMA 节点 [0, pgdat->node_id - 1] 的 zonelist* |-------------| }* | ...... | |* ------------- /*/
static void build_zonelists(pg_data_t *pgdat)
{int node, local_node;struct zoneref *zonerefs;int nr_zones;local_node = pgdat->node_id;/* 构建 NUMA 节点 @pgdat->node_id 的 FALLBACK 类型 zonelist */zonerefs = pgdat->node_zonelists[ZONELIST_FALLBACK]._zonerefs;nr_zones = build_zonerefs_node(pgdat, zonerefs);zonerefs += nr_zones;/** Now we build the zonelist so that it contains the zones* of all the other nodes.* We don't want to pressure a particular node, so when* building the zones for node N, we make sure that the* zones coming right after the local ones are those from* node N+1 (modulo N)*//* 构建序号 大于 @pgdat->node_id NUMA 节点的 zonelist */for (node = local_node + 1; node < MAX_NUMNODES; node++) {if (!node_online(node))continue;nr_zones = build_zonerefs_node(NODE_DATA(node), zonerefs);zonerefs += nr_zones;}/* 构建序号 小于 @pgdat->node_id NUMA 节点的 zonelist */for (node = 0; node < local_node; node++) {if (!node_online(node))continue;nr_zones = build_zonerefs_node(NODE_DATA(node), zonerefs);zonerefs += nr_zones;}/* 额外一个 zoneref, 设置 ->zone = NULL 作为 zoneref 列表的结束标志 */zonerefs->zone = NULL;zonerefs->zone_idx = 0;
}
static void setup_pageset(struct per_cpu_pageset *p, unsigned long batch)
{pageset_init(p);pageset_set_batch(p, batch);
}static void pageset_init(struct per_cpu_pageset *p)
{struct per_cpu_pages *pcp;int migratetype;memset(p, 0, sizeof(*p));pcp = &p->pcp;pcp->count = 0;for (migratetype = 0; migratetype < MIGRATE_PCPTYPES; migratetype++)INIT_LIST_HEAD(&pcp->lists[migratetype]);
}static void pageset_set_batch(struct per_cpu_pageset *p, unsigned long batch)
{pageset_update(&p->pcp, 6 * batch, max(1UL, 1 * batch));
}static void pageset_update(struct per_cpu_pages *pcp, unsigned long high,unsigned long batch)
{/* start with a fail safe value for batch */pcp->batch = 1;smp_wmb();/* Update high, then batch, in order */pcp->high = high;smp_wmb();pcp->batch = batch;
}
到此,已经初步建立 Linux NUMA NODE 0 内存管理数据结构,完成了包括(但不仅限于)以下工作:
- low memory 的映射,即页表建立
- 每 NUMA 节点内存管理数据 pglist_data 的建立
- 每物理页面管理数据 struct page 的分配
- 各类型 zone 的建立及各 zone 内 frea_area[0~MAX_ORDER] 的初始化(目前为空列表)
- zone 列表构建,实际是构建了 NUMA node/zone 分配的优先顺序
- PCP(Per-CPU-Pageset) 列表初始化 (boot_pageset[])
- 其它
剩下的工作是将 memblock 管理的内存(后文称为 bootmem)移交(或者说释放)给 buddy 管理系统。
2.3 移交 bootmem 给内存管理系统
start_kernel()setup_arch()paging_init()//setup_per_cpu_areas()build_all_zonelists()build_all_zonelists_init()mm_init()mem_init()/* 将 memblock 的内存移交给 buddy 管理 */free_all_bootmem()free_highpages()
unsigned long __init free_all_bootmem(void)
{unsigned long pages;reset_all_zones_managed_pages();pages = free_low_memory_core_early();totalram_pages += pages;return pages;
}static unsigned long __init free_low_memory_core_early(void)
{unsigned long count = 0;phys_addr_t start, end;u64 i;memblock_clear_hotplug(0, -1);/* 保留内存的 page 设置保留标志位: page->flags |= PG_reserved */for_each_reserved_mem_region(i, &start, &end)reserve_bootmem_region(start, end);/** We need to use NUMA_NO_NODE instead of NODE_DATA(0)->node_id* because in some case like Node0 doesn't have RAM installed* low ram will be on Node1*/for_each_free_mem_range(i, NUMA_NO_NODE, MEMBLOCK_NONE, &start, &end,NULL)count += __free_memory_core(start, end);return count;
}static unsigned long __init __free_memory_core(phys_addr_t start,phys_addr_t end)
{unsigned long start_pfn = PFN_UP(start);unsigned long end_pfn = min_t(unsigned long,PFN_DOWN(end), max_low_pfn);if (start_pfn >= end_pfn)return 0;__free_pages_memory(start_pfn, end_pfn);return end_pfn - start_pfn;
}/** 释放 end - start 个 page 到 buddy.* @start : 开始页框号* @end - 1: 结束页框号*/
static void __init __free_pages_memory(unsigned long start, unsigned long end)
{int order;/* 将内存区间 [start, end] 拆分成按 (1UL << order) 大小的块 */while (start < end) {/** buddy 里面的每个 page block 的偏移位置必须要对齐到 (1<<order).* 虽然总希望按最大的 (1<<MAX_ORDER) 进行划分, 但首先要看当前的* 起始位置 start 是否符合要求.*/order = min(MAX_ORDER - 1UL, __ffs(start));while (start + (1UL << order) > end)order--;__free_pages_bootmem(pfn_to_page(start), start, order);start += (1UL << order);}
}void __init __free_pages_bootmem(struct page *page, unsigned long pfn,unsigned int order)
{if (early_page_uninitialised(pfn))return;return __free_pages_boot_core(page, order);
}static void __init __free_pages_boot_core(struct page *page, unsigned int order)
{unsigned int nr_pages = 1 << order;struct page *p = page;unsigned int loop;/* page block 中所有 page 的引用计数清 0 */prefetchw(p);for (loop = 0; loop < (nr_pages - 1); loop++, p++) {prefetchw(p + 1);__ClearPageReserved(p);set_page_count(p, 0);}__ClearPageReserved(p);set_page_count(p, 0);page_zone(page)->managed_pages += nr_pages; /* 释放 nr_pages = 1 << order 到 zone page_zone(page) */set_page_refcounted(page); /* 设置 page block (即第 1 个 page) 的引用计数为 1 */__free_pages(page, order);
}
static void __init free_highpages(void)
{
#ifdef CONFIG_HIGHMEMunsigned long max_low = max_low_pfn;struct memblock_region *mem, *res;/* set highmem page free */for_each_memblock(memory, mem) {unsigned long start = memblock_region_memory_base_pfn(mem);unsigned long end = memblock_region_memory_end_pfn(mem);/* Ignore complete lowmem entries */if (end <= max_low)continue;if (memblock_is_nomap(mem))continue;/* Truncate partial highmem entries */if (start < max_low)start = max_low;/* Find and exclude any reserved regions */for_each_memblock(reserved, res) {unsigned long res_start, res_end;res_start = memblock_region_reserved_base_pfn(res);res_end = memblock_region_reserved_end_pfn(res);if (res_end < start)continue;if (res_start < start)res_start = start;if (res_start > end)res_start = end;if (res_end > end)res_end = end;if (res_start != start)free_area_high(start, res_start);start = res_end;if (start == end)break;}/* And now free anything which remains */if (start < end)free_area_high(start, end);}
#endif
}#ifdef CONFIG_HIGHMEM
static inline void free_area_high(unsigned long pfn, unsigned long end)
{for (; pfn < end; pfn++)free_highmem_page(pfn_to_page(pfn));
}
#endif#ifdef CONFIG_HIGHMEM
void free_highmem_page(struct page *page)
{__free_reserved_page(page);totalram_pages++;page_zone(page)->managed_pages++;totalhigh_pages++;
}
#endif/* Free the reserved page into the buddy system, so it gets managed. */
static inline void __free_reserved_page(struct page *page)
{ClearPageReserved(page);init_page_count(page);__free_page(page);
}#define __free_page(page) __free_pages((page), 0)
free_all_bootmem() 和 free_highpages() 最终都走到了函数 __free_pages():
void __free_pages(struct page *page, unsigned int order)
{if (put_page_testzero(page)) { /* @page 引用计数减 1 后为 0, 可以释放该 page */if (order == 0)free_hot_cold_page(page, false); /* 释放 order == 0 的 page 到当前 CPU 的 PCP 链表 */else__free_pages_ok(page, order); /* 释放其它 order != 0 的 page 到 zone frea_area 列表 */}
}
void free_hot_cold_page(struct page *page, bool cold)
{struct zone *zone = page_zone(page);struct per_cpu_pages *pcp;unsigned long flags;unsigned long pfn = page_to_pfn(page);int migratetype;if (!free_pcp_prepare(page))return;migratetype = get_pfnblock_migratetype(page, pfn);set_pcppage_migratetype(page, migratetype);local_irq_save(flags);.../** We only track unmovable, reclaimable and movable on pcp lists.* Free ISOLATE pages back to the allocator because they are being* offlined but treat HIGHATOMIC as movable pages so we can get those* areas back if necessary. Otherwise, we may have to free* excessively into the page allocator*/if (migratetype >= MIGRATE_PCPTYPES) {if (unlikely(is_migrate_isolate(migratetype))) {free_one_page(zone, page, pfn, 0, migratetype);goto out;}migratetype = MIGRATE_MOVABLE;}/* 添加 @page 到当前 CPU @migratetype 类型的 PCP 链表 */pcp = &this_cpu_ptr(zone->pageset)->pcp;if (!cold) /* 释放的 hot page 放到 PCP 链表 头部 */list_add(&page->lru, &pcp->lists[migratetype]);else /* 释放的 cold page 放到 PCP 链表 尾部 */list_add_tail(&page->lru, &pcp->lists[migratetype]);pcp->count++;if (pcp->count >= pcp->high) {unsigned long batch = READ_ONCE(pcp->batch);free_pcppages_bulk(zone, batch, pcp);pcp->count -= batch;}out:local_irq_restore(flags);
}
static void __free_pages_ok(struct page *page, unsigned int order)
{unsigned long flags;int migratetype;unsigned long pfn = page_to_pfn(page);if (!free_pages_prepare(page, order, true))return;migratetype = get_pfnblock_migratetype(page, pfn);local_irq_save(flags);...free_one_page(page_zone(page), page, pfn, order, migratetype);local_irq_restore(flags);
}static void free_one_page(struct zone *zone,struct page *page, unsigned long pfn,unsigned int order,int migratetype)
{spin_lock(&zone->lock);...__free_one_page(page, pfn, zone, order, migratetype);spin_unlock(&zone->lock);
}static inline void __free_one_page(struct page *page,unsigned long pfn,struct zone *zone, unsigned int order,int migratetype)
{unsigned long combined_pfn;unsigned long uninitialized_var(buddy_pfn);struct page *buddy;unsigned int max_order;max_order = min_t(unsigned int, MAX_ORDER, pageblock_order + 1);...if (likely(!is_migrate_isolate(migratetype)))__mod_zone_freepage_state(zone, 1 << order, migratetype);...continue_merging:while (order < max_order - 1) {buddy_pfn = __find_buddy_pfn(pfn, order);buddy = page + (buddy_pfn - pfn);if (!pfn_valid_within(buddy_pfn))goto done_merging;if (!page_is_buddy(page, buddy, order))goto done_merging;/** Our buddy is free or it is CONFIG_DEBUG_PAGEALLOC guard page,* merge with it and move up one order.*/if (page_is_guard(buddy)) {clear_page_guard(zone, buddy, order, migratetype);} else {list_del(&buddy->lru);zone->free_area[order].nr_free--; /* 低阶 order 向 高阶 order 合并, 低阶 order 页面减少 */rmv_page_order(buddy);}combined_pfn = buddy_pfn & pfn;page = page + (combined_pfn - pfn);pfn = combined_pfn;order++;}if (max_order < MAX_ORDER) {/* If we are here, it means order is >= pageblock_order.* We want to prevent merge between freepages on isolate* pageblock and normal pageblock. Without this, pageblock* isolation could cause incorrect freepage or CMA accounting.** We don't want to hit this code for the more frequent* low-order merging.*/if (unlikely(has_isolate_pageblock(zone))) {int buddy_mt;buddy_pfn = __find_buddy_pfn(pfn, order);buddy = page + (buddy_pfn - pfn);buddy_mt = get_pageblock_migratetype(buddy);if (migratetype != buddy_mt&& (is_migrate_isolate(migratetype) ||is_migrate_isolate(buddy_mt)))goto done_merging;}max_order++;goto continue_merging;}done_merging:set_page_order(page, order);/** If this is not the largest possible page, check if the buddy* of the next-highest order is free. If it is, it's possible* that pages are being freed that will coalesce soon. In case,* that is happening, add the free page to the tail of the list* so it's less likely to be used soon and more likely to be merged* as a higher order page*/if ((order < MAX_ORDER-2) && pfn_valid_within(buddy_pfn)) {struct page *higher_page, *higher_buddy;combined_pfn = buddy_pfn & pfn;higher_page = page + (combined_pfn - pfn);buddy_pfn = __find_buddy_pfn(combined_pfn, order + 1);higher_buddy = higher_page + (buddy_pfn - combined_pfn);if (pfn_valid_within(buddy_pfn) &&page_is_buddy(higher_page, higher_buddy, order + 1)) {list_add_tail(&page->lru,&zone->free_area[order].free_list[migratetype]);goto out;}}/* 非 order == 0 页面放入对应 zone 的 free_list */list_add(&page->lru, &zone->free_area[order].free_list[migratetype]);
out:zone->free_area[order].nr_free++;
}
最终,形成如下图所示的初始的内存系统管理状态:
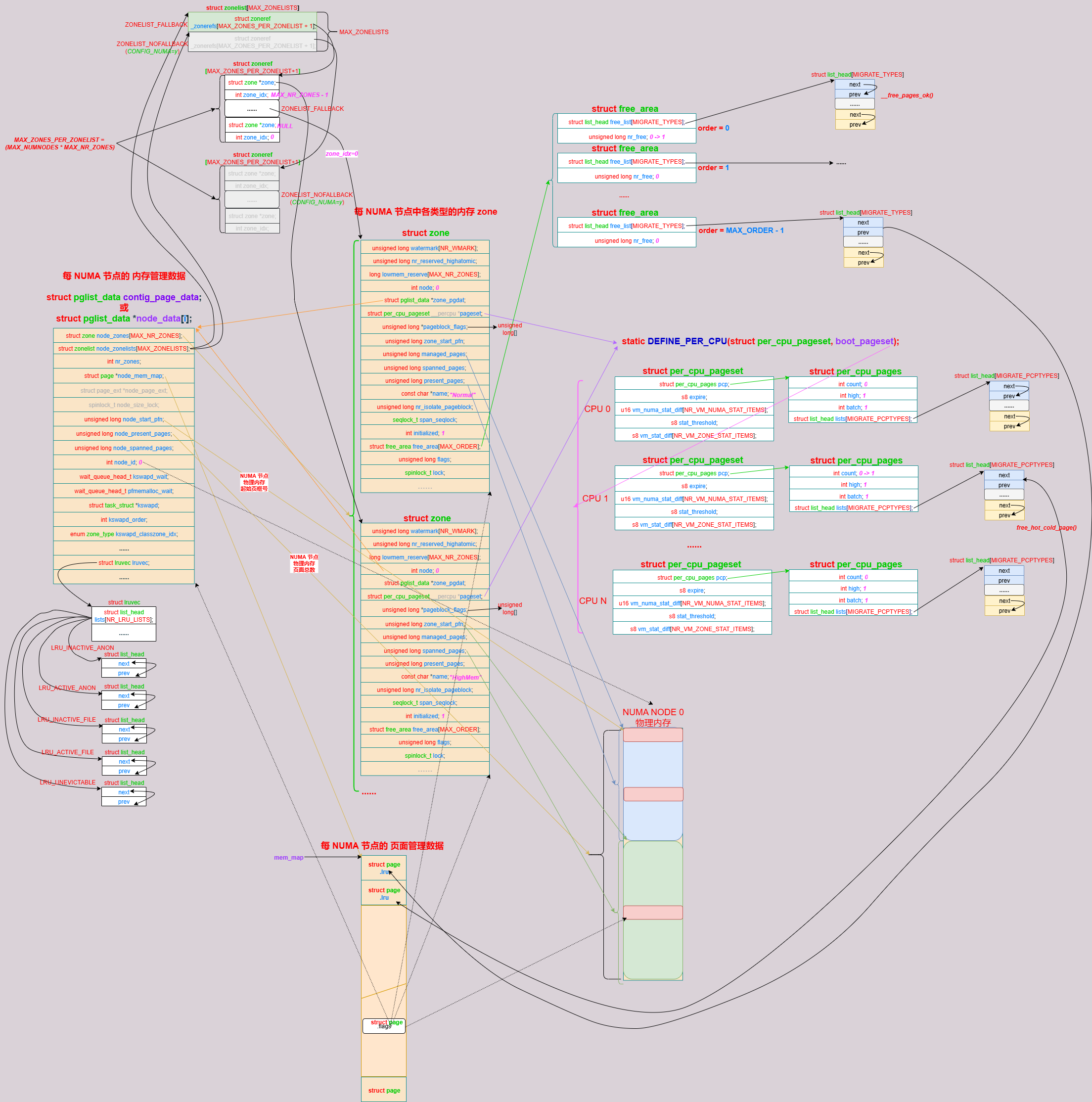
3. 参考资料
[1] Understanding The Linux Virtual Memory Manager
[2] 《Professional Linux Kernel Architeture.pdf》
[3] linux内存子系统 - buddy 子系统2 - memblock 到 buddy