AXI-5.3.1 Memory type requirements
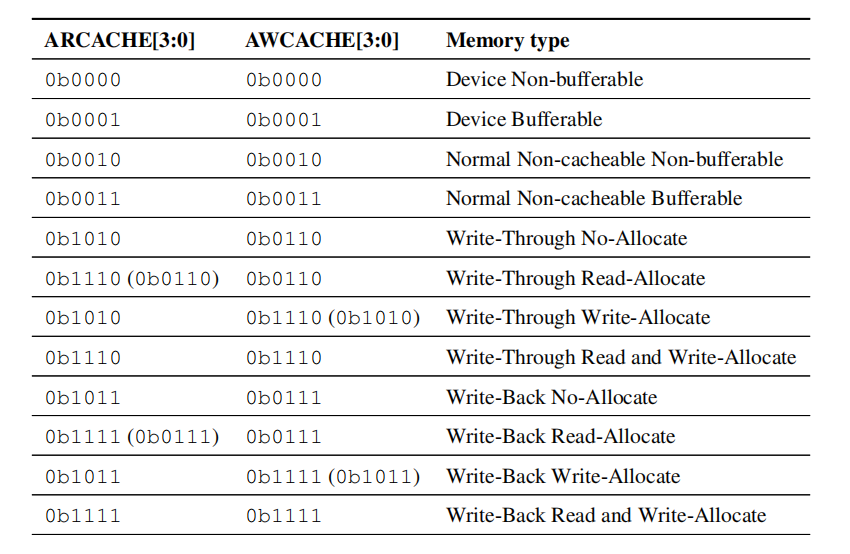
按照分类名称可以看出,内存类型主要分为两大类:Device 和 Normal。Normal 类型又进一步细分为 Non-cacheable、Write-Through 和 Write-Back。
第一类:Device Memory(设备内存)
这类内存用于访问内存映射外设的寄存器。其特点是访问通常有副作用,且对顺序和精确性要求极高。
-
0b0000: Device Non-bufferable-
行为:事务不可缓冲、不可缓存、不可修改。
-
举例:写入一个 UART 的命令寄存器来发送一个字符。这个写入操作必须立即且精确地到达 UART 控制器,不能被延迟或合并。任何缓冲或优化都可能改变硬件行为,导致字符发送失败。
-
-
0b0001: Device Bufferable-
行为:事务可缓冲,但不可缓存、不可修改。
-
举例:向一个帧缓冲区(Frame Buffer)写入连续的像素数据。虽然帧缓冲区是外设,但允许写入操作在中间缓冲区暂存可以提高系统性能,因为图形渲染对吞吐量要求高,而对单次写入的精确时序要求不那么严格。但事务仍然不能合并或缓存。
-
第二类:Normal Memory(普通内存)
这类内存用于访问普通的 RAM(如 DDR)。其特点是没有副作用,系统可以对其进行各种优化以提升性能。
-
0b0010/0b0011: Normal Non-cacheable-
行为:数据不被缓存,但可以缓冲(Bufferable)或不缓冲(Non-bufferable)。
-
举例:共享内存区域。例如,一块被 CPU 和 DMA 控制器共同访问的内存。为了避免缓存一致性问题(即CPU缓存了数据,而DMA直接修改了主内存,导致数据不一致),最简单的方法就是将其标记为
Non-cacheable。这样所有访问都直接作用于主内存,保证了所有主设备看到的数据都是一致的。
-
-
Write-Through(透写)缓存策略
-
行为:数据可以被缓存。当 CPU 写入数据时,数据会同时写入缓存和主内存。
-
举例:
0b1110 / 0b1110: Write-Through Read and Write-Allocate-
场景:一段被多个核心共享的代码或数据。
-
好处:任何核心的写操作都会立即更新主内存,其他核心的缓存可以通过监听总线来使自己的旧副本失效,从而保证一致性。这简化了多核缓存一致性协议,但写操作延迟较高(因为每次都要写主内存)。
-
-
-
Write-Back(回写)缓存策略
-
行为:数据可以被缓存。当 CPU 写入数据时,数据只写入缓存,并被标记为“脏”。只有当这个缓存行被替换出去时,才写回主内存。
-
举例:
0b1111 / 0b1111: Write-Back Read and Write-Allocate-
场景:CPU 的私有数据或一个核心正在频繁计算的中间结果。
-
好处:写操作的延迟极低,因为不需要访问慢速的主内存。同时,也减少了总线流量。这是性能最高的缓存模式。
-
-
-
Allocate 属性的细分
-
在上述缓存策略中,
Allocate位(包括Other Allocate)被用来精细控制缓存分配策略。 -
Write-Through Read-Allocate(0b1110 / 0b0110): 建议只在读未命中时分配缓存行,写未命中时不分配。适用于读多写少的内存。 -
Write-Back Write-Allocate(0b1011 / 0b1111): 建议只在写未命中时分配缓存行。这是回写模式下的典型行为:当写入一个不在缓存中的数据时,先将整个缓存行从内存读入缓存,然后再修改缓存中的部分数据。
-
之所以这样分类的根本原因是为了在性能、数据一致性和硬件正确性 之间实现最优平衡。
-
保证与外设交互的正确性
-
设立
Device类型是为了安全。它通过强制Non-modifiable等属性,确保了对外设寄存器的每一次访问都是精确的,防止了可能改变硬件行为的优化。这是系统稳定性的基石。
-
-
最大化内存子系统性能
-
设立
Normal类型及其子类是为了性能。它解锁了缓存、写缓冲区等所有性能优化技术。 -
Write-Back vs Write-Through:这是在写延迟/带宽和一致性协议复杂度之间的权衡。Write-Back 性能更高,但一致性协议更复杂;Write-Through 一致性更简单,但写性能较差。
-
-
精细化管理稀缺的缓存资源
-
Allocate位的细分(No-Allocate, Read-Allocate, Write-Allocate)允许系统根据数据的访问模式来智能地使用缓存。这可以防止缓存污染,确保高频访问的数据能留在缓存中。
-
-
简化软件编程模型
-
通过将内存划分为具有明确定义行为的类型,操作系统和驱动开发者可以轻松地为不同的任务选择合适的内存属性。例如,为DMA缓冲区设置
Non-cacheable,为线程堆栈设置Write-Back。
-
这些内存类型编码的诞生,是计算机体系结构数十年发展的结晶,直接响应了以下技术演进和需求:
-
内存映射I/O的普及
-
早期计算机使用独立的I/O指令和地址空间。而现代处理器(尤其是RISC架构)普遍使用内存映射I/O,即用普通的加载/存储指令访问外设。
-
带来的问题:总线如何知道一次访问目标是“普通内存”还是“有特殊行为的外设”?
-
解决方案:定义
Device和Normal内存类型,从硬件层面区分二者。
-
-
缓存层次结构成为标准
-
缓存是解决处理器-内存速度鸿沟的核心技术。但随着多级缓存和多核的出现,缓存一致性成为巨大挑战。
-
背景:需要明确的协议来定义缓存行为。
-
解决方案:AXI 协议通过
Write-Through和Write-Back类型,将两种最主要的缓存更新策略标准化。这使得不同供应商的IP核能够在一个共享的缓存一致性框架下协同工作。
-
-
多核处理器的兴起
-
多核系统要求对共享数据的访问有严格的定义。
-
Normal Non-cacheable类型提供了一种简单但性能较低的共享方式。 -
Write-Through类型为维护多核一致性提供了一种硬件支持的模式(尽管性能不是最优)。 -
而现代系统通常使用基于
Write-Back的更复杂的一致性协议(如MESI),但AxCACHE信号为启动这些协议提供了最初的线索(例如,一个Write-Back的读请求可能会触发一个“共享”探测)。
-
-
对能效和带宽的极致追求
-
Write-Back模式通过减少对主内存的访问次数,直接降低了系统功耗和总线带宽占用。 -
Allocate策略的细分使得系统可以避免不必要的缓存行填充,进一步节约了功耗和带宽。这些优化在移动设备和数据中心等高能效场景下至关重要。
-
Device Non-bufferable 内存类型的要求
Device Non-bufferable 是 AXI 协议中限制最严格、行为最可预测的内存类型。它被设计用于与那些对访问精确性和时序有极高要求的硬件外设进行交互。通过一个具体的场景来理解其所有要求:
-
场景:CPU 需要配置一个 SPI(串行外设接口)控制器以启动一次数据传输。
-
首先,CPU 需要向 控制寄存器(地址
0x4000_1000)写入0x01以启用 SPI 主模式。 -
然后,CPU 需要向 数据寄存器(地址
0x4000_1004)写入要发送的数据字节0xAB。 -
最后,CPU 需要轮询 状态寄存器(地址
0x4000_1008)直到“发送完成”位被置起。
-
现在,看规则如何应用于此:
-
1. 写响应必须来自最终目的地
-
行为:当 CPU 写入控制寄存器后,它必须等待来自 SPI 控制器本身 的写响应(BRESP)。这个响应意味着配置命令已经被 SPI 控制器接收并生效。
-
举例:如果系统中存在一个写缓冲区,它不能立即返回响应给 CPU。它必须等待 SPI 控制器真正处理了这次写入。这确保了当 CPU 收到响应后,可以确信 SPI 控制器已经准备好接收下一个命令(如写入数据)。
-
-
2. 读数据必须来自最终目的地
-
行为:当 CPU 读取状态寄存器时,它得到的数据必须是直接从 SPI 控制器 读回的实时状态。
-
举例:任何中间缓存或旧数据副本都是不可接受的。因为状态位(如“发送完成”或“发送缓冲区空”)可能在任何时刻由硬件改变。如果 CPU 读到一个缓存的旧状态,它可能会错误地认为传输尚未完成,或者错误地认为缓冲区已满,从而导致程序逻辑错误。
-
-
3. 事务是不可修改的
-
行为:上述的三个访问(写控制、写数据、读状态)必须保持为三个独立的、原子性的事务。
-
举例:系统不能将“写控制”和“写数据”这两个写操作合并成一个突发传输。因为 SPI 控制器硬件可能要求先配置模式,再写入数据。合并操作可能会破坏这个顺序,或者被硬件视为一个非法操作。同样,事务的地址、长度和大小也绝对不能改变。
-
-
4. 读数据不能预取
-
行为:当 CPU 读取状态寄存器时,系统只能读取该状态寄存器本身的值,而不能顺带读取相邻的、CPU 并未请求的寄存器。
-
举例:假设状态寄存器在
0x1008,而旁边有一个波特率寄存器在0x100C。系统不能因为 CPU 读0x1008就一次性把0x1008和0x100C都读回来。因为对波特率寄存器的读取操作本身,在某些设计中可能就会产生不必要的副作用(尽管不常见),或者至少是浪费了总线带宽。
-
-
5. 写事务不能合并
-
行为:每个写操作都必须独立完成。
-
举例:如果 CPU 需要先后向两个不同的外设寄存器发送两个独立的命令,系统绝对不能将它们合并。每个命令都可能触发一个独立的硬件状态机,合并写入会使得硬件无法区分这两个命令,导致功能失效。
-
之所以设立如此严格的 Device Non-bufferable 类型,其核心原因是 保证与内存映射外设交互的绝对正确性。
-
外设寄存器具有“副作用”
-
这是最根本的原因。普通的内存(如 RAM)访问的“作用”就是改变或读取存储单元的值。而外设寄存器则不同,一次写入可能意味着“启动一个引擎”、“清除一个标志”或“发送一个命令”;一次读取可能意味着“锁存当前输入”、“确认一个中断”或“读取一个瞬时状态”。
-
因为这些操作都有副作用,所以每一次访问都必须是精确的、原子的、不可分割的。任何优化(如合并、缓冲、预取)都可能改变这些副作用的次数和顺序,从而彻底改变硬件的运行状态。
-
-
保证操作的强顺序和可见性
-
在驱动程序中,操作外设的序列通常是严格设计好的。程序员需要确信,在收到一个写操作的响应后,前一个操作已经完成,后续操作可以安全进行。
-
Device Non-bufferable通过要求响应来自最终目的地,为软件提供了一个强大的同步点。这简化了软件编程模型,无需插入复杂的内存屏障指令就能保证操作的顺序。
-
-
读取必须反映实时状态
-
外设的状态(如“数据就绪”、“繁忙”、“错误”)是动态变化的。软件依赖读取这些状态来做决策。如果数据被缓存或预取,软件读到的就是一个“过时”的快照,将导致决策错误。
-
这些规则的诞生,直接源于计算机系统架构中 内存映射I/O 的引入及其带来的挑战。
-
内存映射I/O的普及
-
在早期计算机中,I/O 拥有独立的地址空间和专用的指令(如 x86 的
IN和OUT指令)。这从硬件上就将内存访问和 I/O 访问分开了。 -
背景转变:现代处理器,特别是 RISC 架构(如 ARM),普遍采用内存映射I/O,即 CPU 使用普通的加载/存储指令来访问外设。这简化了 CPU 设计,但将区分内存和 I/O 的职责转移给了总线协议和内存系统。
-
-
总线性能优化与硬件正确性的冲突
-
为了提升性能,计算机系统引入了缓存、写缓冲区、事务合并等高级特性。这些优化对于普通内存访问是巨大的福音。
-
出现的问题:当这些优化机制被不加区分地应用到外设访问上时,就会导致灾难性的后果。驱动工程师发现,他们的代码在理论上是正确的,但在实际的硬件上却无法工作,因为总线在“背后”重新排序和合并了他们的操作。
-
解决方案:总线协议必须提供一种机制,让软件能够显式地禁止所有这些优化。
Device Non-bufferable内存类型就是对这个问题的直接回答。它定义了一个“安全区”,在这个区域内的所有访问都按照程序员最直观的理解来执行,不做任何“聪明”的改动。
-
-
嵌入式与实时系统的需求
-
在嵌入式系统和实时系统中,硬件的时序行为必须是可预测的。一个写入操作需要多长时间能生效?一个状态读取是否能得到最新值?
Device Non-bufferable的严格规则为这些问题提供了确定的答案,使得设计满足实时性要求的系统成为可能。
-
note:Device Non-bufferable 内存类型是 AXI 协议为协调 “高性能内存子系统” 和 “精确外设控制” 这对矛盾而设立的一道“防火墙”。它承认了外设世界的特殊性和脆弱性,并通过一系列禁止优化的规则,为软件与硬件的可靠交互提供了坚实的基础。可以说如果没有它,基于内存映射I/O的现代计算系统将无法稳定工作。
Device bufferable 内存类型的要求
Device Bufferable 类型同样用于访问内存映射外设,但它为写操作提供了一点灵活性,以换取性能提升,同时仍然保持对读操作和事务原子性的严格要求。还是通过一个具体的场景来理解:
-
场景:一个 GPU 或 DMA 控制器需要向帧缓冲区 写入大量的像素数据。帧缓冲区是位于显示控制器内部的一块内存,用于存储屏幕上显示的图像。
现在逐条分析规则如何应用于此:
-
1. 写响应可以从一个中间点获得
-
行为:这是与
Device Non-bufferable最核心的区别。当主设备(如GPU)写入数据时,一个中间的写缓冲区 可以立即返回一个“完成”响应,而不必等待数据真正到达最终的显示控制器。 -
举例:GPU 写入一个像素数据。系统中的一个互联结构或内存控制器内的写缓冲区接收了这个数据,并立刻告诉 GPU:“好了,写完了,你可以继续了”。GPU 因此被释放,可以立即开始处理下一个像素,而不需要等待相对较慢的显示控制器。
-
对比:如果是
Device Non-bufferable,GPU 必须等待显示控制器本身的响应,这会严重拖慢渲染速度。
-
-
2. 写事务必须及时在最终目的地变得可见
-
行为:这是一个重要的限制条件。虽然响应可以来自中间点,但数据不能无限期地停留在缓冲区里。它必须在一个“及时”的时间范围内被推送到最终目的地。
-
举例:对于帧缓冲区,这个“及时”通常意
-