使用新版本cpu编译vLLM cpu端(编译完成,但是SCNet公网转发8000端口后,连不上)
安装python3.12版本
本身系统里有python3.10版本,也有vLLM,而且是DCU vLLM版本,但是需要用到python3.12版本,所以才重新弄整个系统。
为什么要用到python3.12版本? 这里没记,一段时间之后就忘记了。看来不能因为当时记得请,就不记!
一条命令安装pyenv
curl https://pyenv.run | bash
# 或者
curl -fsSL https://pyenv.run | bash把下面3句写入.bashrc文件里面:
export PYENV_ROOT="$HOME/.pyenv"
[[ -d $PYENV_ROOT/bin ]] && export PATH="$PYENV_ROOT/bin:$PATH"
eval "$(pyenv init - bash)"pyenv安装python3.12.9
pyenv install 3.12.9注意添加pyenv的加速镜像,否则很慢
export PYTHON_BUILD_MIRROR_URL="https://registry.npmmirror.com/-/binary/python"
export PYTHON_BUILD_MIRROR_URL_SKIP_CHECKSUM=1设定使用python3.12.9
全局使用设定
pyenv global 3.12.9
目录使用设定
设定在某个目录下使用版本,进入目录进行设定:
pyenv local 3.12.9
比如到 ~/private_data目录里,这行这句,就可以设定为在这个目录中,都是使用python3.12版本
下载vLLM代码
git clone https://github.com/vllm-project/vllm.git vllm_source
cd vllm_sourcepip安装所需要的包
pip install --upgrade pip
pip install "cmake>=3.26" wheel packaging ninja "setuptools-scm>=8" numpy
pip install -v -r requirements/cpu.txt --extra-index-url https://download.pytorch.org/whl/cpu编译
VLLM_TARGET_DEVICE=cpu python setup.py install编译完成
root@notebook-1982767703556689922-ac7sc1ejvp-81431:~/private_data/github/vllm_source# pip show vllm
Name: vllm
Version: 0.11.1rc6.dev53+g0ce743f4e.cpu
Summary: A high-throughput and memory-efficient inference and serving engine for LLMs
Home-page: https://github.com/vllm-project/vllm
Author: vLLM Team
Author-email:
License-Expression: Apache-2.0
Location: /root/.pyenv/versions/3.12.9/lib/python3.12/site-packages/vllm-0.11.1rc6.dev53+g0ce743f4e.cpu-py3.12-linux-x86_64.egg
Requires: aiohttp, anthropic, blake3, cachetools, cbor2, cloudpickle, compressed-tensors, datasets, depyf, diskcache, einops, fastapi, filelock, gguf, intel-openmp, intel_extension_for_pytorch, lark, llguidance, lm-format-enforcer, mistral_common, msgspec, ninja, numba, numpy, openai, openai-harmony, opencv-python-headless, outlines_core, packaging, partial-json-parser, pillow, prometheus-fastapi-instrumentator, prometheus_client, protobuf, psutil, py-cpuinfo, pybase64, pydantic, python-json-logger, pyyaml, pyzmq, regex, requests, scipy, sentencepiece, setproctitle, setuptools, six, tiktoken, tokenizers, torch, torchaudio, torchvision, tqdm, transformers, triton, typing_extensions, watchfiles, xgrammar
Required-by:
下载个模型测试一下
VLLM_USE_MODELSCOPE=true vllm serve baidu/ERNIE-4.5-0.3B-PT --trust-remote-code失败,有报错
(APIServer pid=9856) 2025-11-03 19:54:05,648 - modelscope - WARNING - Repo baidu/ERNIE-4.5-0.3B-PT not exists on https://www.modelscope.cn, will try on alternative endpoint https://www.modelscope.ai.
(APIServer pid=9856) 2025-11-03 19:54:06,543 - modelscope - ERROR - Repo baidu/ERNIE-4.5-0.3B-PT not exists on either https://www.modelscope.cn or https://www.modelscope.ai
详细报错见:“报错(APIServer pid=5173) requests.exceptions.HTTPError: <Response [404]>”
换用Huggingface的,至少能启动了
vllm serve baidu/ERNIE-4.5-0.3B-PT --trust-remote-code输出:
(APIServer pid=9958) INFO 11-03 19:55:24 [serving_completion.py:68] Using default completion sampling params from model: {'temperature': 0.8, 'top_p': 0.8}
(APIServer pid=9958) INFO 11-03 19:55:24 [serving_chat.py:130] Using default chat sampling params from model: {'temperature': 0.8, 'top_p': 0.8}
(APIServer pid=9958) INFO 11-03 19:55:24 [api_server.py:2021] Starting vLLM API server 0 on http://0.0.0.0:8000
(APIServer pid=9958) INFO 11-03 19:55:24 [launcher.py:38] Available routes are:
(APIServer pid=9958) INFO 11-03 19:55:24 [launcher.py:46] Route: /openapi.json, Methods: HEAD, GET测试一下,在SCNet转向到8000端口,
https://c-1982767703556689922.ksai.scnet.cn:58043/v1/models输出是:
{"object":"list","data":[{"id":"baidu/ERNIE-4.5-0.3B-PT","object":"model","created":1762171140,"owned_by":"vllm","root":"baidu/ERNIE-4.5-0.3B-PT","parent":null,"max_model_len":131072,"permission":[{"id":"modelperm-03dd329bca95465ba70cc152602ef958","object":"model_permission","created":1762171140,"allow_create_engine":false,"allow_sampling":true,"allow_logprobs":true,"allow_search_indices":false,"allow_view":true,"allow_fine_tuning":false,"organization":"*","group":null,"is_blocking":false}]}]}
看着正常啊,但是为什么就是不对呢?
换用deepseek模型试试deepseek-ai/DeepSeek-R1-Distill-Qwen-1.5B
vllm serve deepseek-ai/DeepSeek-R1-Distill-Qwen-1.5B --trust-remote-code一样的情况,看着运行成功了,但是
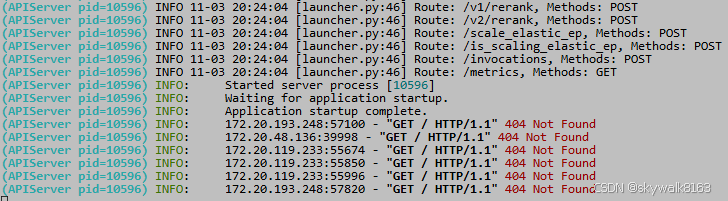
在SCNet设置8000端口转发的时候,报404 Not Found ,当然勉强能转发出去,但是好像这样模型验证就是失败的。
不知道是不是因为自己编译的vLLM有问题导致的。
问题待续
调试
报错(APIServer pid=5173) requests.exceptions.HTTPError: <Response [404]>
root@notebook-1982767703556689922-ac7sc1ejvp-81431:~/private_data# VLLM_USE_MODELSCOPE=true vllm serve baidu/ERNIE-4.5-0.3B-PT --trust-remote-code
[W1103 10:33:53.161544580 OperatorEntry.cpp:218] Warning: Warning only once for all operators, other operators may also be overridden.
Overriding a previously registered kernel for the same operator and the same dispatch key
operator: aten::_addmm_activation(Tensor self, Tensor mat1, Tensor mat2, *, Scalar beta=1, Scalar alpha=1, bool use_gelu=False) -> Tensor
registered at /pytorch/build/aten/src/ATen/RegisterSchema.cpp:6
dispatch key: AutocastCPU
previous kernel: registered at /pytorch/aten/src/ATen/autocast_mode.cpp:327
new kernel: registered at /opt/workspace/ipex-cpu-dev/csrc/cpu/autocast/autocast_mode.cpp:112 (function operator())
INFO 11-03 10:34:01 [importing.py:44] Triton is installed but 0 active driver(s) found (expected 1). Disabling Triton to prevent runtime errors.
INFO 11-03 10:34:01 [importing.py:68] Triton not installed or not compatible; certain GPU-related functions will not be available.
(APIServer pid=5173) INFO 11-03 10:34:07 [api_server.py:1952] vLLM API server version 0.11.1rc6.dev53+g0ce743f4e
(APIServer pid=5173) INFO 11-03 10:34:07 [utils.py:253] non-default args: {'model_tag': 'baidu/ERNIE-4.5-0.3B-PT', 'model': 'baidu/ERNIE-4.5-0.3B-PT', 'trust_remote_code': True}
(APIServer pid=5173) 2025-11-03 10:34:07,571 - modelscope - WARNING - Repo baidu/ERNIE-4.5-0.3B-PT not exists on https://www.modelscope.cn, will try on alternative endpoint https://www.modelscope.ai.
(APIServer pid=5173) 2025-11-03 10:34:08,198 - modelscope - ERROR - Repo baidu/ERNIE-4.5-0.3B-PT not exists on either https://www.modelscope.cn or https://www.modelscope.ai
(APIServer pid=5173) Traceback (most recent call last):
(APIServer pid=5173) File "/root/.pyenv/versions/3.12.9/bin/vllm", line 33, in <module>
(APIServer pid=5173) sys.exit(load_entry_point('vllm==0.11.1rc6.dev53+g0ce743f4e.cpu', 'console_scripts', 'vllm')())
(APIServer pid=5173) ^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^
(APIServer pid=5173) File "/root/.pyenv/versions/3.12.9/lib/python3.12/site-packages/vllm-0.11.1rc6.dev53+g0ce743f4e.cpu-py3.12-linux-x86_64.egg/vllm/entrypoints/cli/main.py", line 73, in main
(APIServer pid=5173) args.dispatch_function(args)
(APIServer pid=5173) File "/root/.pyenv/versions/3.12.9/lib/python3.12/site-packages/vllm-0.11.1rc6.dev53+g0ce743f4e.cpu-py3.12-linux-x86_64.egg/vllm/entrypoints/cli/serve.py", line 59, in cmd
(APIServer pid=5173) uvloop.run(run_server(args))
(APIServer pid=5173) File "/root/.pyenv/versions/3.12.9/lib/python3.12/site-packages/uvloop/__init__.py", line 96, in run
(APIServer pid=5173) return __asyncio.run(
(APIServer pid=5173) ^^^^^^^^^^^^^^
(APIServer pid=5173) File "/root/.pyenv/versions/3.12.9/lib/python3.12/asyncio/runners.py", line 195, in run
(APIServer pid=5173) return runner.run(main)
(APIServer pid=5173) ^^^^^^^^^^^^^^^^
(APIServer pid=5173) File "/root/.pyenv/versions/3.12.9/lib/python3.12/asyncio/runners.py", line 118, in run
(APIServer pid=5173) return self._loop.run_until_complete(task)
(APIServer pid=5173) ^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^
(APIServer pid=5173) File "uvloop/loop.pyx", line 1518, in uvloop.loop.Loop.run_until_complete
(APIServer pid=5173) File "/root/.pyenv/versions/3.12.9/lib/python3.12/site-packages/uvloop/__init__.py", line 48, in wrapper
(APIServer pid=5173) return await main
(APIServer pid=5173) ^^^^^^^^^^
(APIServer pid=5173) File "/root/.pyenv/versions/3.12.9/lib/python3.12/site-packages/vllm-0.11.1rc6.dev53+g0ce743f4e.cpu-py3.12-linux-x86_64.egg/vllm/entrypoints/openai/api_server.py", line 1996, in run_server
(APIServer pid=5173) await run_server_worker(listen_address, sock, args, **uvicorn_kwargs)
(APIServer pid=5173) File "/root/.pyenv/versions/3.12.9/lib/python3.12/site-packages/vllm-0.11.1rc6.dev53+g0ce743f4e.cpu-py3.12-linux-x86_64.egg/vllm/entrypoints/openai/api_server.py", line 2012, in run_server_worker
(APIServer pid=5173) async with build_async_engine_client(
(APIServer pid=5173) ^^^^^^^^^^^^^^^^^^^^^^^^^^
(APIServer pid=5173) File "/root/.pyenv/versions/3.12.9/lib/python3.12/contextlib.py", line 210, in __aenter__
(APIServer pid=5173) return await anext(self.gen)
(APIServer pid=5173) ^^^^^^^^^^^^^^^^^^^^^
(APIServer pid=5173) File "/root/.pyenv/versions/3.12.9/lib/python3.12/site-packages/vllm-0.11.1rc6.dev53+g0ce743f4e.cpu-py3.12-linux-x86_64.egg/vllm/entrypoints/openai/api_server.py", line 192, in build_async_engine_client
(APIServer pid=5173) async with build_async_engine_client_from_engine_args(
(APIServer pid=5173) ^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^
(APIServer pid=5173) File "/root/.pyenv/versions/3.12.9/lib/python3.12/contextlib.py", line 210, in __aenter__
(APIServer pid=5173) return await anext(self.gen)
(APIServer pid=5173) ^^^^^^^^^^^^^^^^^^^^^
(APIServer pid=5173) File "/root/.pyenv/versions/3.12.9/lib/python3.12/site-packages/vllm-0.11.1rc6.dev53+g0ce743f4e.cpu-py3.12-linux-x86_64.egg/vllm/entrypoints/openai/api_server.py", line 218, in build_async_engine_client_from_engine_args
(APIServer pid=5173) vllm_config = engine_args.create_engine_config(usage_context=usage_context)
(APIServer pid=5173) ^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^
(APIServer pid=5173) File "/root/.pyenv/versions/3.12.9/lib/python3.12/site-packages/vllm-0.11.1rc6.dev53+g0ce743f4e.cpu-py3.12-linux-x86_64.egg/vllm/engine/arg_utils.py", line 1318, in create_engine_config
(APIServer pid=5173) maybe_override_with_speculators(
(APIServer pid=5173) File "/root/.pyenv/versions/3.12.9/lib/python3.12/site-packages/vllm-0.11.1rc6.dev53+g0ce743f4e.cpu-py3.12-linux-x86_64.egg/vllm/transformers_utils/config.py", line 528, in maybe_override_with_speculators
(APIServer pid=5173) config_dict, _ = PretrainedConfig.get_config_dict(
(APIServer pid=5173) ^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^
(APIServer pid=5173) File "/root/.pyenv/versions/3.12.9/lib/python3.12/site-packages/modelscope/utils/hf_util/patcher.py", line 185, in patch_get_config_dict
(APIServer pid=5173) model_dir = get_model_dir(pretrained_model_name_or_path,
(APIServer pid=5173) ^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^
(APIServer pid=5173) File "/root/.pyenv/versions/3.12.9/lib/python3.12/site-packages/modelscope/utils/hf_util/patcher.py", line 161, in get_model_dir
(APIServer pid=5173) model_dir = snapshot_download(
(APIServer pid=5173) ^^^^^^^^^^^^^^^^^^
(APIServer pid=5173) File "/root/.pyenv/versions/3.12.9/lib/python3.12/site-packages/modelscope/hub/snapshot_download.py", line 132, in snapshot_download
(APIServer pid=5173) return _snapshot_download(
(APIServer pid=5173) ^^^^^^^^^^^^^^^^^^^
(APIServer pid=5173) File "/root/.pyenv/versions/3.12.9/lib/python3.12/site-packages/modelscope/hub/snapshot_download.py", line 300, in _snapshot_download
(APIServer pid=5173) endpoint = _api.get_endpoint_for_read(
(APIServer pid=5173) ^^^^^^^^^^^^^^^^^^^^^^^^^^^
(APIServer pid=5173) File "/root/.pyenv/versions/3.12.9/lib/python3.12/site-packages/modelscope/hub/api.py", line 527, in get_endpoint_for_read
(APIServer pid=5173) self.repo_exists(
(APIServer pid=5173) File "/root/.pyenv/versions/3.12.9/lib/python3.12/site-packages/modelscope/hub/api.py", line 685, in repo_exists
(APIServer pid=5173) raise HTTPError(r)
(APIServer pid=5173) requests.exceptions.HTTPError: <Response [404]>