PaddleOCR----制作数据集,模型训练,验证 QT部署(未完成)
部署环境, windows,文档未写完
目录
- 1.安装
- 1.1 paddle框架安装
- 1.2 paddleOCR安装
- 2.制作数据集
- 2.1工具下载
- 2.2 数据集制作
- 2.3 划分训练集和测试集
- 3.训练模型
- 3.1 代码下载
- 3.2 预训练模型下载
- 3.3 文本检测训练
- 3.4 文本识别模型训练
- 4.验证模型
- 4.1 验证文本检测模型
- 4.3 模型导出
- 4.2 推理可视化
- 4.3 文本识别模型
- 4.4 检测和识别一同验证可视化
- 5 QT部署c++
- 5.1 安装Opencv与Paddle Inference
- 遇到问题
- AssertionError: The length of ratio_list should be the same as the file_list.
- 验证时候爆显存
1.安装
1.1 paddle框架安装
conda 创建一个python =3.10的基础环境
根据自己的环境安装paddle框架链接
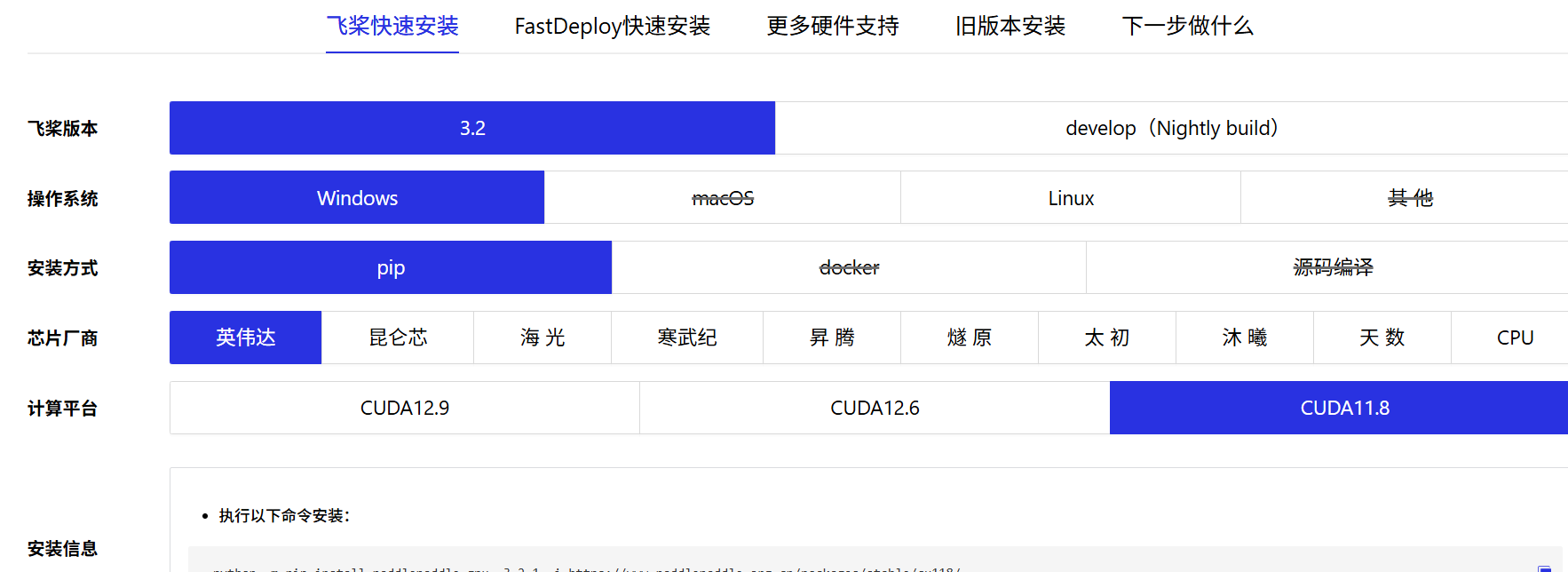
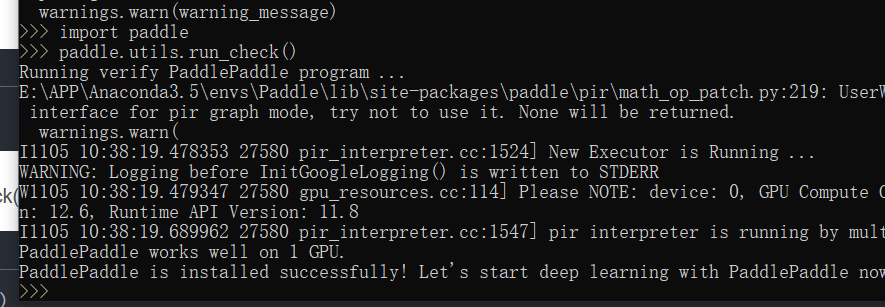
安装完成后进入环境,输入
python
import paddle
paddle.utils.run_check()
如果看到以下输出则没有问题,输入exit()退出
1.2 paddleOCR安装
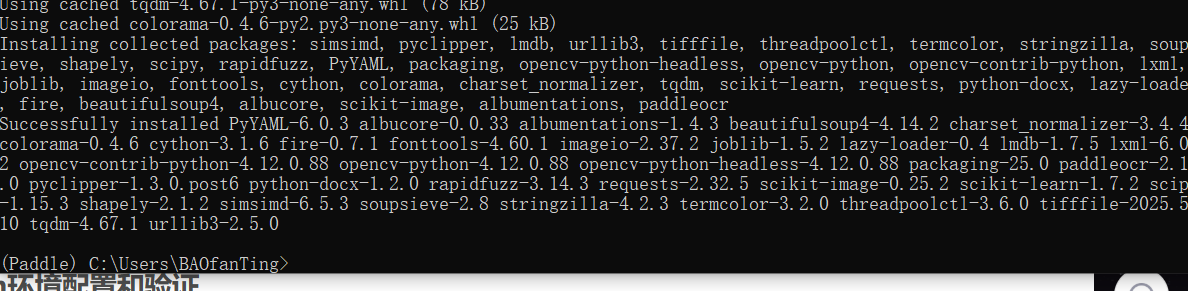
pip install paddleocr出现以下说明安装成功,不用指定版本,指定了还出错
2.制作数据集
2.1工具下载
下载数据集制作工具下载地址
解压后,进入环境,cd到解压目录
pip3 install "paddlex[ocr]" -i https://pypi.tuna.tsinghua.edu.cn/simple/安装必要库
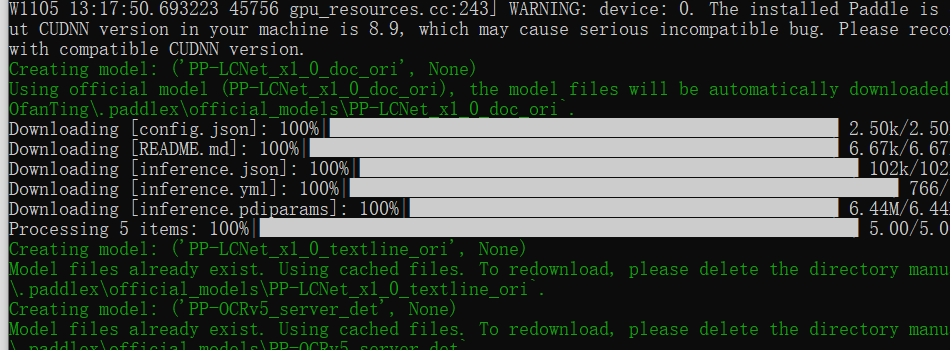
启动插件python ./PPOCRLabel.py,此时会一直下载模型,然后就会打开软件
2.2 数据集制作
打开图片文件夹,矩形框标注,可以更改识别结果,标注完成点击确定
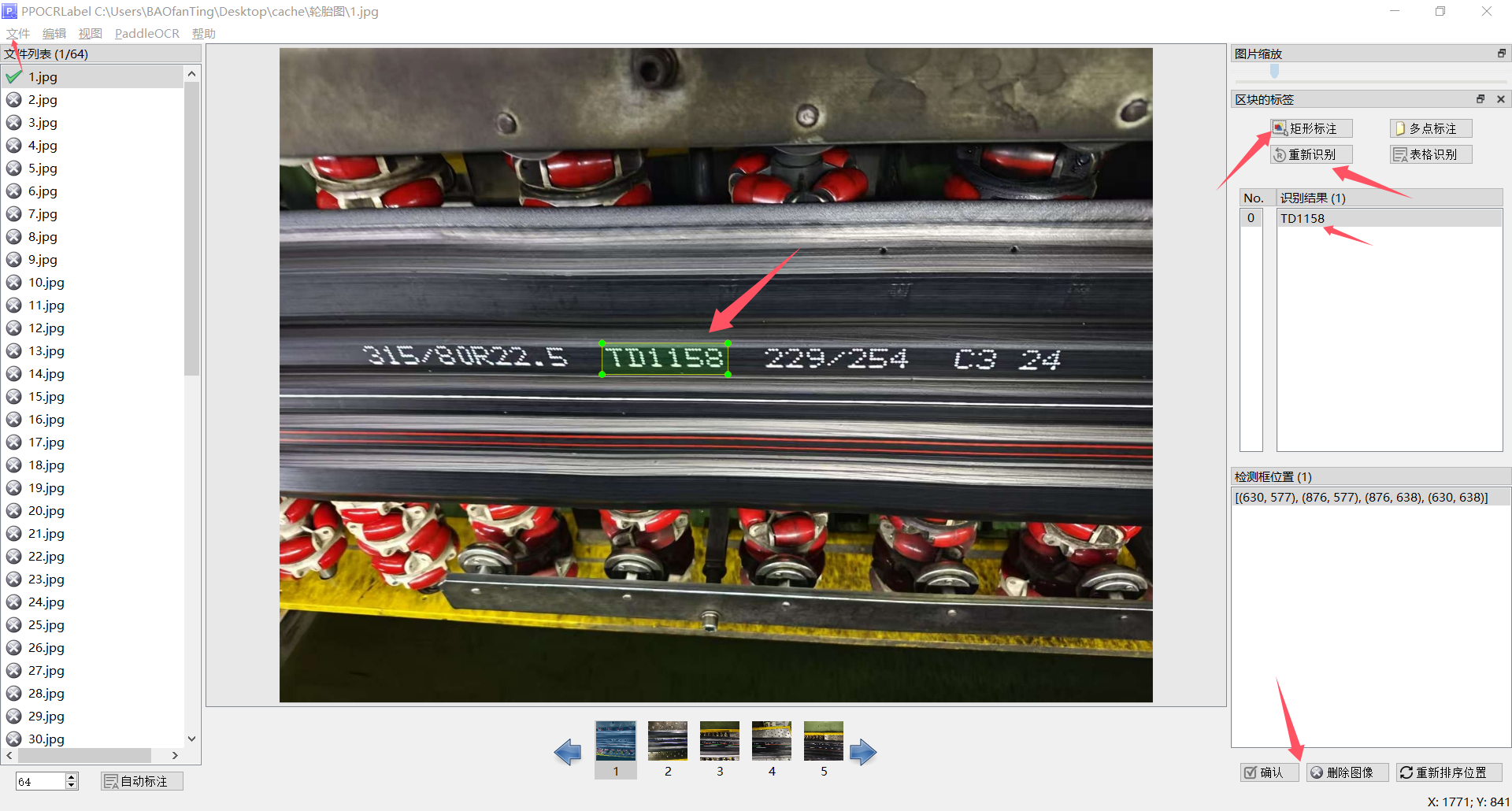
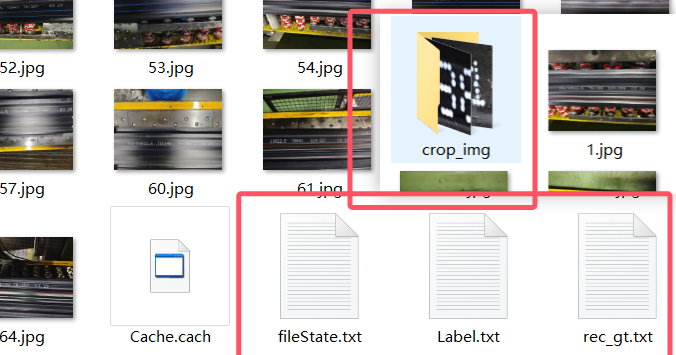
制作完成后,点击文件→导出标记结果,点击文件→导出识别结果,得到四个文件
2.3 划分训练集和测试集
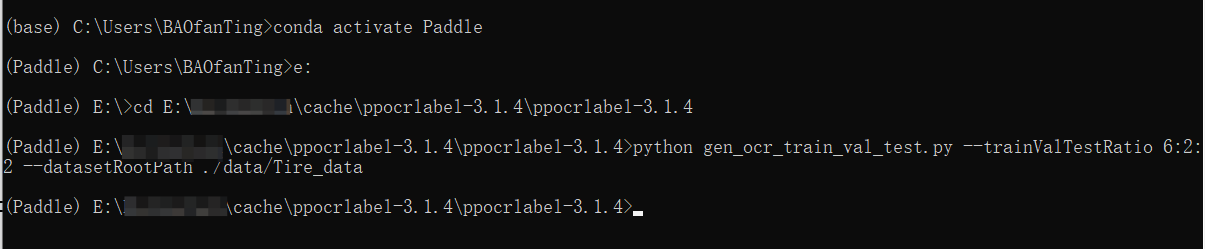
打开conda终端进入环境,cd进入PPOCRLabel文件夹,把图片文件夹复制到data文件夹下,执行划分命令
python gen_ocr_train_val_test.py --trainValTestRatio 6:2:2 --datasetRootPath ./data/Tire_data
–trainValTestRatio 6:2:2 #训练集、验证集和测试集的比例
–datasetRootPath #数据集路径
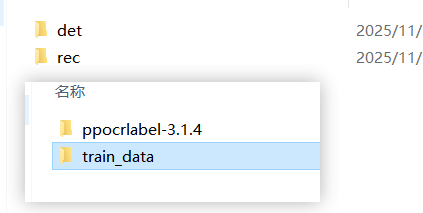
运行完成后再代码的上一级文件夹就会有train_data,里边就是划分好的数据集
3.训练模型
3.1 代码下载
克隆也行,下载也行,下载地址
解压后cd进入,安装必要库pip install -r requirements.txt

3.2 预训练模型下载
https://www.paddleocr.ai/main/version3.x/module_usage/text_detection.html#411下载文本检测和识别的预训练模型
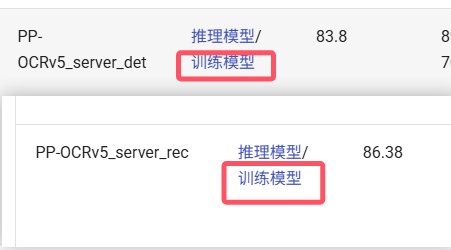
3.3 文本检测训练
windows 端训练 终端输入指令
python tools/train.py -c configs/det/PP-OCRv5/PP-OCRv5_server_det.yml \ # 配置文件路径-o Global.pretrained_model=./model/PP-OCRv5_server_det_pretrained.pdparams \ #模型路径Train.dataset.data_dir=../train_data/det \ # 数据集路径Train.dataset.label_file_list='[../train_data/det/train.txt]' \ # train.txt路径Eval.dataset.data_dir=../train_data/det \ # 数据集路径Eval.dataset.label_file_list='[../train_data/det/val.txt]' # val.txt路径
python tools/train.py -c configs/det/PP-OCRv5/PP-OCRv5_server_det.yml -o Global.pretrained_model=./model/PP-OCRv5_server_det_pretrained.pdparams Train.dataset.data_dir=../train_data/det Train.dataset.label_file_list=[../train_data/det/train.txt] Eval.dataset.data_dir=../train_data/det Eval.dataset.label_file_list=[../train_data/det/val.txt]
3.4 文本识别模型训练
同理
4.验证模型
4.1 验证文本检测模型
进入终端,环境,cd到目录
python3 tools/eval.py -c configs/det/PP-OCRv5/PP-OCRv5_server_det.yml \-o Global.pretrained_model=output/PP-OCRv5_server_det/latest.pdparams \ # 保存的模型地址Eval.dataset.data_dir=./ocr_det_dataset_examples \ # 数据集路径Eval.dataset.label_file_list='[./ocr_det_dataset_examples/val.txt]' #valtext 路径
python tools/eval.py -c configs/det/PP-OCRv5/PP-OCRv5_server_det.yml -o Global.pretrained_model=output/PP-OCRv5_server_det/latest.pdparams Eval.dataset.data_dir=../train_data/det Eval.dataset.label_file_list=[../train_data/det/val.txt]
4.3 模型导出
python tools/export_model.py -c configs/det/PP-OCRv5/PP-OCRv5_server_det.yml -o \ # 配置文件Global.pretrained_model=output/PP-OCRv5_server_det/latest.pdparams \ # 模型参数路径Global.save_inference_dir="./PP-OCRv5_server_det_infer/" #导出地址
python tools/export_model.py -c configs/det/PP-OCRv5/PP-OCRv5_server_det.yml -o Global.pretrained_model=output/PP-OCRv5_server_det/latest.pdparams Global.save_inference_dir="./PP-OCRv5_server_det_infer/"
会得到这三个文件,然后就可以推理
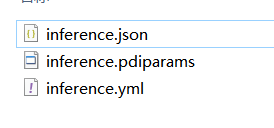
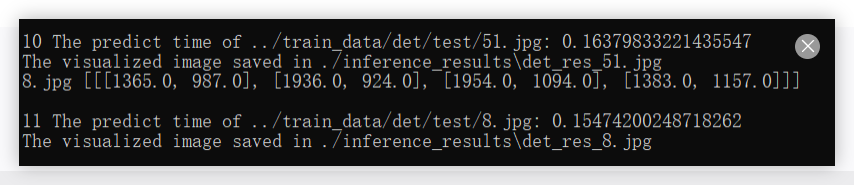
4.2 推理可视化
python tools\infer\predict_det.py \--image_dir "../train_data/det/test/" \ # 预测图像路径--det_model_dir "./output/PP-OCRv5_server_det/" \ # 模型路径--use_gpu true
python tools\infer\predict_det.py --image_dir "../train_data/det/test/" --det_model_dir "./PP-OCRv5_server_det_infer/" --use_gpu true
在这个路径下就能看到识别后的可视化结果
4.3 文本识别模型
同理
4.4 检测和识别一同验证可视化
python tools/infer/predict_system.py --det_model_dir=./ch_PP-OCRv2_det_infer/ \ # 检测模型目录--rec_model_dir=./ch_PP-OCRv2_rec_infer/ \ # 识别模型目录--image_dir=./datasets/img_dir/ \ # 测试图片目录--draw_img_save_dir=./ch_PP-OCRv2_results/ \ # 可视化结果保存目录--is_visualize=True
5 QT部署c++
5.1 安装Opencv与Paddle Inference
参考官方教材,直接安装编译包就行,省去编译过程官方教程
遇到问题
AssertionError: The length of ratio_list should be the same as the file_list.
去掉’','[../train_data/det/train.txt]'变为[../train_data/det/train.txt]
验证时候爆显存
打开配置文件,关闭使用gpuuse-gpu=false