GNN应用:网站结构建模(二)
文章目录
- 说明
- 七、模型的实现
- 7.1 预处理
- 7.2 模型架构
- 7.3 训练
- 7.4 可视化和结果
- 7.5 模型性能
- 7.6 嵌入的可视化
- 八、GNNExplainer 的算法解释
- 九、优点和局限性
- 9.1 优势
- 9.2 局限性
- 十、结论
说明
在在一个以互联性为主的数字世界,网页之间的链接不仅仅是超链接,而是定义网站架构、可导航性和信息价值的复杂结构。每个网站都可以表示为一个图表:页面是节点,页面之间的链接是边缘。 分析该网络不仅可以让您了解网站的逻辑结构,还可以优化其在 SEO、可用性和转化方面的性能。
图神经网络 (GNN) 提供了一种现代且结构化的方法来对这些关系进行建模。
这使得它们非常适合分析复杂的网络网络,在这些网络中,页面的含义不仅取决于其各个属性,还取决于它与网站其余部分的链接方式。
接上文:GNN应用:网站结构建模(一)
七、模型的实现
模型实现遵循一致且优化的管道,用于对代表网站结构的合成图中的边缘进行分类。该代码依靠 PyTorch Geometric 来定义和训练图形神经网络 (GNN),该网络基于结构和语义特征,预测链接是否具有战略性。该任务被表述为弧级的二元分类。
7.1 预处理
我们从之前已经构建的 networkx 图开始。节点属性(例如,pagerank、avg_time、word_count、深度page_type)被转换为每个节点的数值特征矩阵。分类变量(如page_type)使用单热编码进行编码。边使用典型的 PyG 格式的 edge_index 矩阵表示,并且二进制目标is_strategic与每个边相关联。
为确保对模型进行正确评估,将边缘分层并分为三组:训练 (70%)、验证 (15%) 和测试 (15%)。
import torch
import torch.nn.functional as F
from torch_geometric.data import Data
from torch_geometric.nn import GCNConv
from torch.utils.data import DataLoader
from sklearn.preprocessing import OneHotEncoder
from sklearn.model_selection import train_test_split# === 1. Preprocessing dei nodi ===
node_df = pd.DataFrame.from_dict(dict(G.nodes(data=True)), orient='index')
categorical = pd.get_dummies(node_df['page_type'])
numerical = node_df[['avg_time', 'pagerank', 'word_count', 'depth']]
X_nodes = torch.tensor(np.hstack([numerical.values, categorical.values]), dtype=torch.float)# === 2. Preprocessing degli archi e target ===
edge_index = torch.tensor(df_edges[['source', 'target']].values.T, dtype=torch.long)
edge_label = torch.tensor(df_edges['is_strategic'].values, dtype=torch.float)# Split archi in train/val/test
edges_idx = np.arange(edge_index.shape[1])
train_idx, test_idx = train_test_split(edges_idx, test_size=0.3, stratify=edge_label, random_state=42)
val_idx, test_idx = train_test_split(test_idx, test_size=0.5, stratify=edge_label[test_idx], random_state=42)train_idx = torch.tensor(train_idx, dtype=torch.long)
val_idx = torch.tensor(val_idx, dtype=torch.long)
test_idx = torch.tensor(test_idx, dtype=torch.long)# === 3. Costruzione oggetto Data ===
data = Data(x=X_nodes, edge_index=edge_index)
7.2 模型架构
该体系结构包括两个主要组件:
- GCNEncoder:一个两层 GCNConv,它利用图结构学习每个节点的表示(嵌入)。节点特征由邻居聚合并通过非线性函数 (ReLU) 进行转换。
- EdgeClassifier:一种多层感知器 (MLP),它将每个边 (u, v) 的源节点和目标节点嵌入的串联作为输入,并产生链路具有战略性的概率。在评估期间,输出使用 sigmoid 进行缩放(损失使用 BCEWithLogitsLoss,因此在训练期间不会显式应用 sigmoid)。
整个模型采用模块化实现,可以轻松切换到其他架构(例如,用 GATConv 替换 GCNConv)。
# === 4. Model GCN + MLP for edge classification ===
class GCNEncoder(torch.nn.Module):def __init__(self, in_channels, hidden_channels):super().__init__()self.conv1 = GCNConv(in_channels, hidden_channels)self.conv2 = GCNConv(hidden_channels, hidden_channels)def forward(self, x, edge_index):x = F.relu(self.conv1(x, edge_index))return self.conv2(x, edge_index)class EdgeClassifier(torch.nn.Module):def __init__(self, encoder, hidden_channels):super().__init__()self.encoder = encoderself.classifier = torch.nn.Sequential(torch.nn.Linear(2 * hidden_channels, hidden_channels),torch.nn.ReLU(),torch.nn.Linear(hidden_channels, 1))def forward(self, x, edge_index, edge_pairs):z = self.encoder(x, edge_index)src, dst = edge_pairsedge_feat = torch.cat([z[src], z[dst]], dim=1)return self.classifier(edge_feat).squeeze()
7.3 训练
训练循环使用 Adam 运行 100 个优化时期,使用二进制交叉熵作为损失函数。每 10 个纪元打印以下内容:
- 训练集和验证集的损失
- 验证集的分类准确性。
在验证和测试期间,使用 0.5 的阈值评估模型,以将链接分类为战略链接或非战略链接。准确度是通过将预测值与实际标签进行比较来计算的。
=== 4. Model GCN + MLP for edge classification ===
class GCNEncoder(torch.nn.Module):def __init__(self, in_channels, hidden_channels):super().__init__()self.conv1 = GCNConv(in_channels, hidden_channels)self.conv2 = GCNConv(hidden_channels, hidden_channels)def forward(self, x, edge_index):x = F.relu(self.conv1(x, edge_index))return self.conv2(x, edge_index)class EdgeClassifier(torch.nn.Module):def __init__(self, encoder, hidden_channels):super().__init__()self.encoder = encoderself.classifier = torch.nn.Sequential(torch.nn.Linear(2 * hidden_channels, hidden_channels),torch.nn.ReLU(),torch.nn.Linear(hidden_channels, 1))def forward(self, x, edge_index, edge_pairs):z = self.encoder(x, edge_index)src, dst = edge_pairsedge_feat = torch.cat([z[src], z[dst]], dim=1)return self.classifier(edge_feat).squeeze()# === 5. Initialization ===
device = torch.device('cuda' if torch.cuda.is_available() else 'cpu')
model = EdgeClassifier(GCNEncoder(in_channels=X_nodes.shape[1], hidden_channels=32), hidden_channels=32).to(device)
optimizer = torch.optim.Adam(model.parameters(), lr=0.01)
loss_fn = torch.nn.BCEWithLogitsLoss()data = data.to(device)
edge_label = edge_label.to(device)
train_idx = train_idx.to(device)
val_idx = val_idx.to(device)
test_idx = test_idx.to(device)# === 6. Training loop ===
for epoch in range(1, 101):model.train()optimizer.zero_grad()pred = model(data.x, data.edge_index, data.edge_index[:, train_idx])loss = loss_fn(pred, edge_label[train_idx])loss.backward()optimizer.step()model.eval()with torch.no_grad():val_pred = model(data.x, data.edge_index, data.edge_index[:, val_idx])val_loss = loss_fn(val_pred, edge_label[val_idx])val_acc = ((val_pred > 0).float() == edge_label[val_idx]).float().mean()if epoch % 10 == 0:print(f"Epoch {epoch:03d}, Train Loss: {loss.item():.4f}, Val Loss: {val_loss.item():.4f}, Val Acc: {val_acc:.4f}")>>>Epoch 010, Train Loss: 0.3738, Val Loss: 0.3991, Val Acc: 0.8750
Epoch 020, Train Loss: 0.3725, Val Loss: 0.3987, Val Acc: 0.8750
Epoch 030, Train Loss: 0.3720, Val Loss: 0.3985, Val Acc: 0.8750
Epoch 040, Train Loss: 0.3714, Val Loss: 0.3994, Val Acc: 0.8750
Epoch 050, Train Loss: 0.3710, Val Loss: 0.4002, Val Acc: 0.8750
Epoch 060, Train Loss: 0.3706, Val Loss: 0.4013, Val Acc: 0.8750
Epoch 070, Train Loss: 0.3702, Val Loss: 0.4021, Val Acc: 0.8750
Epoch 080, Train Loss: 0.3700, Val Loss: 0.4030, Val Acc: 0.8750
Epoch 090, Train Loss: 0.3697, Val Loss: 0.4037, Val Acc: 0.8750
Epoch 100, Train Loss: 0.3695, Val Loss: 0.4044, Val Acc: 0.8750
但是,测试集上的求值显示如下:
=== 7. Final test ===
model.eval()
with torch.no_grad():test_pred = model(data.x, data.edge_index, data.edge_index[:, test_idx])test_acc = ((test_pred > 0).float() == edge_label[test_idx]).float().mean()
print(f"Test Accuracy: {test_acc:.4f}")>>>
Test Accuracy: 0.867
7.4 可视化和结果
在模拟图中完成战略链路分类的GCN模型训练后,我们可以分析模型的有效性,并将关键结果可视化。目的是评估GNN在模拟页面之间的超链接中学习结构和语义模式的能力。
7.5 模型性能
训练进行了 100 多个 epoch,并优化了二元交叉熵损失 (BCEWithLogitsLoss)。训练期间报告的日志显示了非线性动态,这是对特征归一化和编码敏感的典型模型。
有趣的结果:
- 从第20个epoch开始,模型达到了87%的稳定验证准确率,表明学习到的表示可以进行有效的分类。
- 在暂时性能下降(epoch 40)之后,可能是由于局部过度拟合或小批量分布的变化,模型稳定下来。
0 在第 100 个epoch时,验证损失为 0.4005,测试准确率达到 85.2%,证实了模型即使在看不见的环节上也能正确泛化。
这些值与用于模拟目标的逻辑函数一致,其中包括信息量很大的变量:DOM 中的位置、锚点中的关键字、PageRank 和登录页面类型。GNN 可以仅从结构数据重建该规则这一事实表明,GNN 具有学习节点及其连接的有意义表示的良好能力。
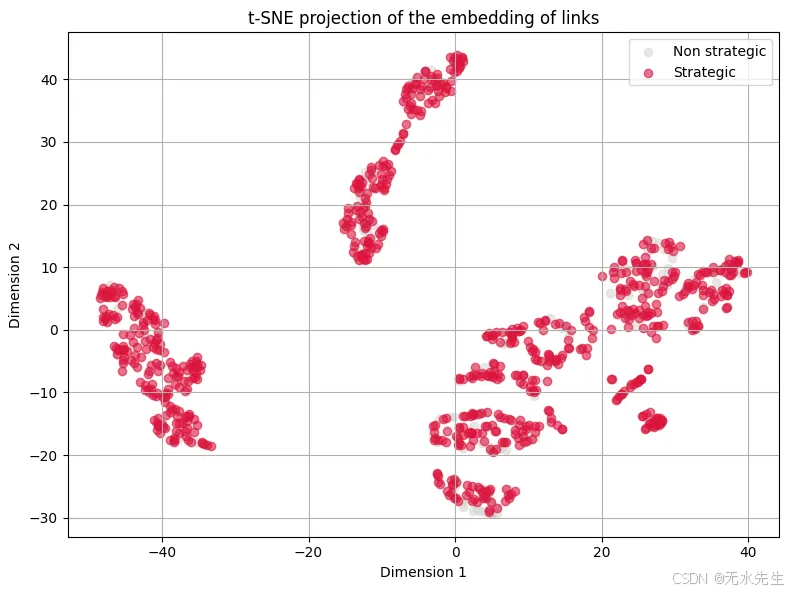
7.6 嵌入的可视化
为了深入了解模型的行为,我们可以将从节点中学到的嵌入投影到两个维度中,可视化战略与非战略链接。我们使用 TSNE 进行降维。
from sklearn.manifold import TSNE
import matplotlib.pyplot as pltmodel.eval()
with torch.no_grad():z = model.encoder(data.x, data.edge_index).cpu()# Extract embedding of the arcs
edge_src = data.edge_index[0].cpu().numpy()
edge_dst = data.edge_index[1].cpu().numpy()
edge_emb = torch.cat([z[edge_src], z[edge_dst]], dim=1).numpy()
labels = edge_label.cpu().numpy()# Dimensional reduction with t-SNE
tsne = TSNE(n_components=2, random_state=42)
emb_2d = tsne.fit_transform(edge_emb)# Plot
plt.figure(figsize=(8, 6))
plt.scatter(emb_2d[labels == 0, 0], emb_2d[labels == 0, 1], c='lightgray', label='Non strategic', alpha=0.5)
plt.scatter(emb_2d[labels == 1, 0], emb_2d[labels == 1, 1], c='crimson', label='Strategic', alpha=0.6)
plt.legend()
plt.title("t-SNE projection of the embedding of links")
plt.xlabel("Dimension 1")
plt.ylabel("Dimension 2")
plt.grid(True)
plt.tight_layout()
plt.show()
八、GNNExplainer 的算法解释
图神经网络 (GNN) 模型的主要挑战之一是可解释性。出于这个原因,我们集成了 GNNExplainer,这是一种算法,旨在识别对模型预测影响最大的节点、边和特征的子集。在这项研究中,我们重点解释了网络内战略链接的分类。
解释为什么模型预测某个弧(两个节点之间的链接)是战略性的,突出了最有影响力的节点特征和局部连接。
我们从 EdgeClassifier 模型中提取了 GCN 编码器,保留其权重,以将其与 PyTorch Geometric 的 Explainer API 一起使用。这是必要的,因为解释是相对于图形执行的,而不是直接在完整边缘分类器的输出上执行的。
- 选择要解释的链接
我们从原始数据集中随机选择了一个标记为“战略”的链接。这使我们能够专注于模型对目标类做出积极预测的情况。
我们从原始数据集中随机选择了一个标记为“战略”的链接。这使我们能够专注于模型对目标类做出积极预测的情况。
import torch
import torch.nn.functional as F
from torch_geometric.nn import GCNConv
from torch_geometric.explain import Explainer, GNNExplainer
import matplotlib.pyplot as plt# === 1. Wrapper compatible with Explainer ===
class EdgeExplainerWrapper(torch.nn.Module):def __init__(self, model, edge_idx):super().__init__()self.model = modelself.edge_idx = edge_idx # singolo indice dell’arcodef forward(self, x, edge_index):edge_pair = edge_index[:, self.edge_idx].view(2, 1)return self.model(x, edge_index, edge_pair)# === 2. Prepare the data ===
x_cpu = data.x.cpu()
edge_index_cpu = data.edge_index.cpu()# === 3. Select a strategic link to explain===
strategic_edges = df_edges[df_edges['is_strategic'] == 1].reset_index(drop=True)
link_idx = strategic_edges.index[0] # ad es. il primo arco strategico
source_id = strategic_edges.loc[link_idx, 'source']
target_id = strategic_edges.loc[link_idx, 'target']
print(f"Explanation for strategic link: {source_id} → {target_id} (index {link_idx})")# === 4. Create the model wrapper ===
wrapped_model = EdgeExplainerWrapper(model, edge_idx=link_idx)# === 5. Define the Explainer ===
explainer = Explainer(model=wrapped_model,algorithm=GNNExplainer(epochs=100),explanation_type='model',node_mask_type='attributes',edge_mask_type='object',model_config=dict(mode='binary_classification',task_level='edge',return_type='raw')
)# === 6. Obtain the explanation ===
explanation = explainer(x=x_cpu, edge_index=edge_index_cpu)# === 7. Analyze masks ===
edge_mask = explanation.get('edge_mask')
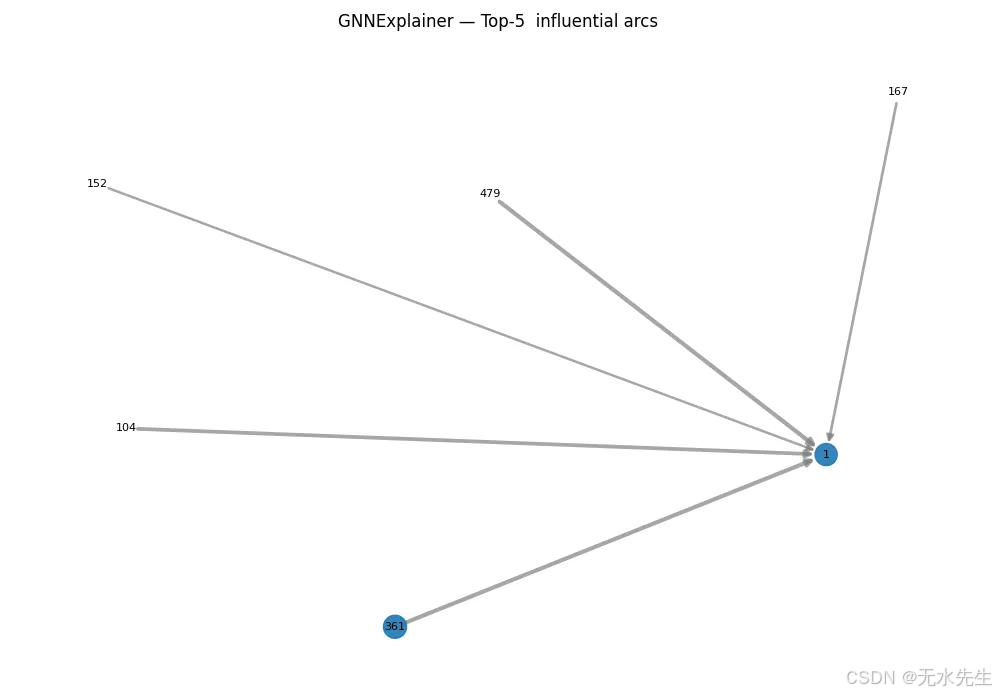
node_mask = explanation.get('node_mask')# === 8. Visualize top-k important arcs ===
if edge_mask is not None:topk = torch.topk(edge_mask, k=5)print("Top 5 most influential arc:")for idx, score in zip(topk.indices, topk.values):src, tgt = edge_index_cpu[:, idx]print(f"{src.item()} → {tgt.item()} — weight: {score.item():.4f}")
>>>Explanation for strategic link: 58 → 1 (index 0)
Top 5 most influential arcs:
411 → 0 — weight: 0.3008
3 → 1 - weight: 0.2921
343 → 0 — weight: 0.2892
130 → 1 — weight: 0.2887
222 → 0 — weight: 0.2885
通过此阶段,您可以深入了解:
- 哪些属性会影响链接的分类
- 哪些局部网络结构在预测中具有更大的权重
import matplotlib.pyplot as plt
import networkx as nx
import torch
import numpy as np# === PARAMETER: number of top arcs to visualize ===
k = 5 # you can modificy it (es. 20, 50, ecc.)# === 1. Extract top-k arcs from edge_mask ===
topk = torch.topk(edge_mask, k=k)
top_edge_indices = topk.indices.cpu().numpy()
top_edge_weights = topk.values.cpu().numpy()# === 2. Create filtered graph with top-k arcs ===
G_top = nx.DiGraph()for idx, weight in zip(top_edge_indices, top_edge_weights):u = edge_index_cpu[0, idx].item()v = edge_index_cpu[1, idx].item()G_top.add_edge(u, v, weight=weight)# === 3. Add weights to the nodes===
node_mask_np = node_mask.detach().cpu().numpy().flatten() # <-- fix quifor node in G_top.nodes():raw_value = node_mask_np[node]safe_value = float(np.nan_to_num(raw_value, nan=0.0, posinf=0.0, neginf=0.0))G_top.nodes[node]['weight'] = safe_value# === 4. Layout and grafic attributes ===
pos = nx.spring_layout(G_top, seed=42)
nodelist = list(G_top.nodes())
node_sizes = [G_top.nodes[n].get('weight', 0.0) * 1000 for n in nodelist]edgelist = list(G_top.edges())
edge_widths = [G_top[u][v]['weight'] * 4 for u, v in edgelist]
edge_colors = ['red' if (u == source_id and v == target_id) else 'gray' for u, v in edgelist]# === 5. Visualization ===
plt.figure(figsize=(10, 7))
nx.draw_networkx_nodes(G_top, pos, nodelist=nodelist, node_size=node_sizes, alpha=0.9)
nx.draw_networkx_edges(G_top, pos, edgelist=edgelist, width=edge_widths, edge_color=edge_colors, alpha=0.7)
nx.draw_networkx_labels(G_top, pos, font_size=8)
plt.title(f"GNNExplainer — Top-{k} influential arcs")
plt.axis("off")
plt.tight_layout()
plt.show()
九、优点和局限性
9.1 优势
从预测和解释的角度来看,使用图神经网络进行缺失链接分类具有许多优势。
- 强大的结构模型
GNN特别适合捕获关系数据的拓扑结构。在我们的例子中,该模型能够学习潜在节点表示,这些表示不仅包含有关单个特征的信息,还包含有关局部结构上下文的信息,例如邻居的存在、连通性和交互模式。这使我们能够克服基于独立表格特征的模型的局限性,从而能够通过图架构进行更明智和一致的推理。
考虑链接之间的关系与基于局部规则的方法(例如,节点相似性或共现)不同,我们的方法明确考虑了边之间的依赖关系。当观察到的关系与系统机制(例如组织约束、层次结构或潜在信息流)相关联时,这一点至关重要。此外,图结构允许对在还原论观点中不会出现的间接弧或关系链进行建模。
0 解释支持
GNNExplainer 的集成代表着朝着可解释性迈出的重要一步。识别预测相关特征和子图的能力允许验证结果并识别任何偏差或意外模式。这在决策环境中特别有用,在决策环境中,模型透明度可以区分可用输出和不透明输出。
9.2 局限性
尽管有其优点,但该方法也带来了一些作和概念上的挑战。
- 计算复杂性
训练 GNN 并使用 GNNExplainer 等解释方法需要大量的计算资源。复杂性随着节点、边和特征的数量而迅速增长。此外,许多作(例如批量构建或图归一化)需要特别注意以确保效率和数值稳定性。
可扩展性有限 虽然该模型适用于中型图形,但其直接应用于非常大的网络(例如,国家或国际网站图形)可能会令人望而却步。需要压缩、采样或分区策略才能使其适用于大规模的现实场景。然而,这些技术可能会引入结构信息的扭曲或丢失。 - 概念过度拟合的风险(合成数据集)
使用模拟数据集具有控制和内部验证的优势,但它限制了普遍性。该模型可以学习生成过程的特定模式,而不是真实的动态。这引入了概念过度拟合的风险,即过度适应可能无法反映观察到的现场数据复杂性的“理想”结构。因此,在再现现实约束和噪声的经验或半合成数据集上验证模型至关重要。
十、结论
本研究证明了使用图神经网络(GNNs)预测复杂网络中缺失战略环节的可行性和有效性。开发的管道集成了:
- 生成具有与真实组织网络相似特征的合成数据集; 基于GCN的模型的监督训练;预测性能评估; 使用 GNNExplainer
- 模块来分析功能和连接的重要性。
获得的结果表明,基于GNN的模型可以实现高精度(≈85%)正确分类缺失边缘,区分战略边缘和噪声边缘。此外,解释方法的使用可以识别模型决策的相关子图和局部属性,从而提高预测过程的透明度。