Java-168 Neo4j CQL 实战:WHERE、DELETE/DETACH、SET、排序与分页
TL;DR
- 场景:在 Neo4j 中完成多标签创建、复杂筛选、批量删改、排序与分页等核心 CRUD。
- 结论:按语法要点+性能与坑点双清单落地,避免“删不掉节点/分页不稳定/正则误配”等常见翻车。
- 产出:可直接抄用的 Cypher 片段、分页与删除策略、错误速查卡与版本适配提示。

版本矩阵
| 功能项 | 已验证 | 说明 |
|---|---|---|
| 多标签 CREATE (n:A:B) | 5.x ✅ | 4.x 同样可用;注意一次性赋多标签便于查询与约束管理。 |
| WHERE 基础比较(=、!=、<>、>、>=、<、<=、IS NULL) | 5.x ✅ | 与 SQL 语义一致;建议结合索引提升过滤性能。 |
| 布尔运算 AND/OR/NOT/XOR | 5.x ✅ | 部分场景更稳妥用 (a OR b) AND NOT (a AND b) 替代 XOR,减少兼容性疑虑。 |
| 字符串匹配:STARTS WITH/ENDS WITH/CONTAINS | 5.x ✅ | 大小写敏感;需注意前缀/后缀索引策略。 |
| 正则 =~ | 5.x ✅ | 基于 Java 正则,反斜杠需双重转义(示例中的 \.)。 |
| DELETE / DETACH DELETE | 5.x ✅ | 删节点前若仍有关系会报错;批量删用 DETACH DELETE。 |
| REMOVE(删属性/标签) | 5.x ✅ | 删属性后读取为 NULL;删标签影响后续匹配。 |
| SET(新增/更新属性) | 5.x ✅ | 支持多属性同时设置;注意类型与覆盖。 |
| ORDER BY(含多列) | 5.x ✅ | 分页务必配合稳定次序(如追加 id(n))。 |
| SKIP + LIMIT 分页 | 5.x ✅ | 大数据量性能一般,用游标/锚点分页可优化。 |
| DISTINCT 去重 | 5.x ✅ | 与 SQL 语义一致;注意与聚合混用的列集一致性。 |
CREATE创建多个标签
CREATE (<node-name>:<label-name1>:<label-name2>.....:<label-namen>)
如:
CREATE (person:Person:Beauty:Picture {cid:20,name:"小美女"})
WHERE 子句
简单 WHERE 子句
简单 WHERE 子句用于对节点或关系的属性进行基本筛选,语法如下:
WHERE <condition>
示例应用场景:
MATCH (p:Person)
WHERE p.name = 'Alice'
RETURN p// 匹配年龄大于30岁的人员
MATCH (p:Person)
WHERE p.age > 30
RETURN p
复杂 WHERE 子句
复杂 WHERE 子句允许使用布尔运算符组合多个条件,语法如下:
WHERE <condition> <boolean-operator> <condition>
支持的布尔运算符包括:
- AND
- OR
- NOT
- XOR
示例:
// 查找年龄在25到35岁之间且居住在北京的人员
MATCH (p:Person)
WHERE p.age >= 25 AND p.age <= 35 AND p.city = 'Beijing'
RETURN p// 查找名为Alice或者年龄小于20岁的人员
MATCH (p:Person)
WHERE p.name = 'Alice' OR p.age < 20
RETURN p
WHERE 子句中的比较运算符
Neo4j CQL 中的比较运算符与 SQL 类似,包括:
- 等于:
= - 不等于:
!=或<> - 大于:
> - 小于:
< - 大于等于:
>= - 小于等于:
<= - IS NULL
- IS NOT NULL
特殊运算符:
=~:正则表达式匹配STARTS WITH:字符串开头匹配ENDS WITH:字符串结尾匹配CONTAINS:字符串包含
示例:
// 正则表达式匹配邮箱
MATCH (p:Person)
WHERE p.email =~ '.*@gmail\\.com'
RETURN p// 查找名字以"John"开头的人员
MATCH (p:Person)
WHERE p.name STARTS WITH 'John'
RETURN p// 查找地址中包含"Street"的人员
MATCH (p:Person)
WHERE p.address CONTAINS 'Street'
RETURN p
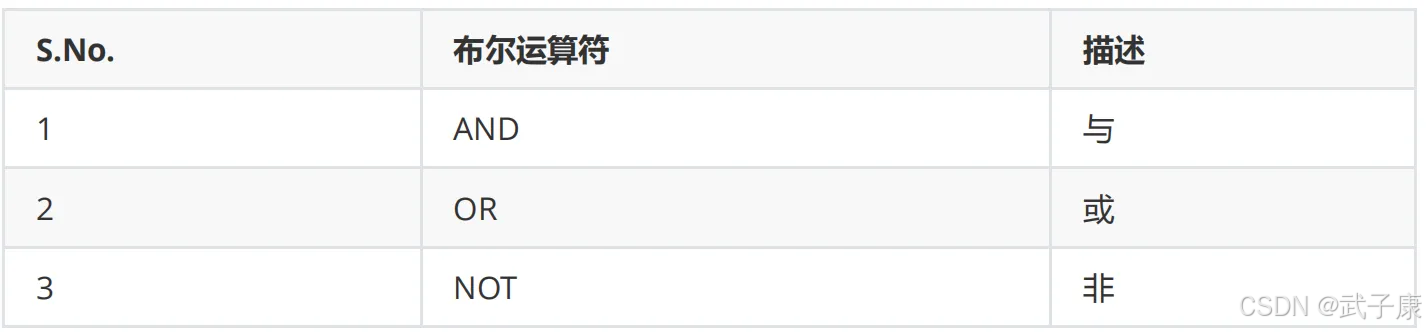
MATCH (person:Person)
WHERE person.name = 'wzk1' OR person.name = 'wzk5'
RETURN person
执行结果如下所示:
DELETE 子句 和 REMOVE子句
DELETE
DELETE语句用于从图中删除节点、关系或路径。删除操作支持以下几种模式:
- 删除节点:
MATCH (n:Person {name:"wzk1"})
DELETE n
注意:删除节点前需要先删除与该节点关联的所有关系,否则会报错。
- 删除关系:
MATCH (:Person {name:"wzk1"})-[r:Couple]->(:Person)
DELETE r
这是最常用的删除模式,可以只删除特定关系而保留节点。
- 删除路径:
MATCH p = (:Person {name:"wzk1"})-[r:Couple]-(:Person)
DELETE r
这个示例删除了"wzk1"和其配偶之间的Couple关系,但保留了两个Person节点。
其他使用场景:
- 批量删除满足条件的节点和关系:
MATCH (n)-[r]->(m)
WHERE n.age > 30 AND r.type = 'FRIEND'
DELETE n, r, m
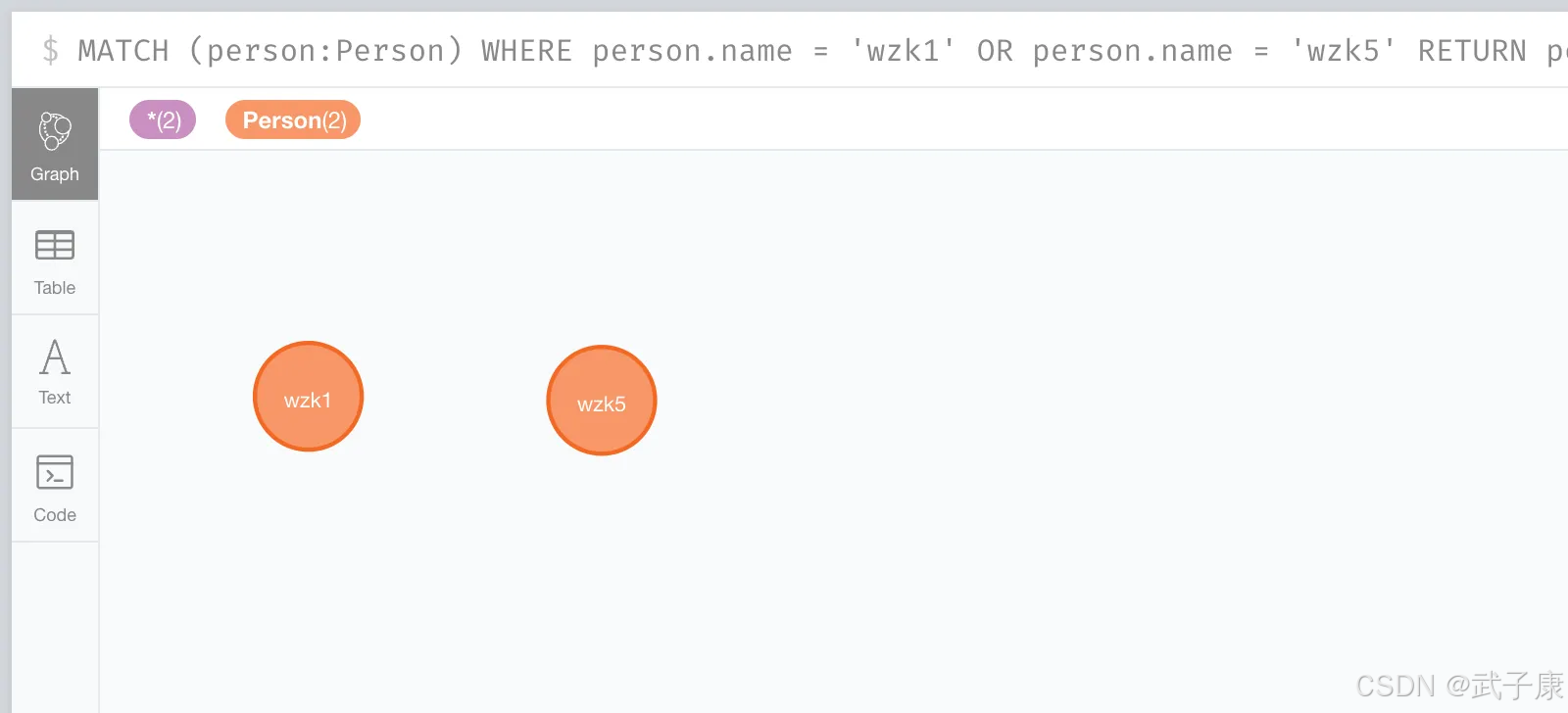
- 使用DETACH DELETE强制删除节点及其所有关系:
MATCH (n:Person {name:"wzk1"})
DETACH DELETE n
可以看到之前的节点关系没有了:
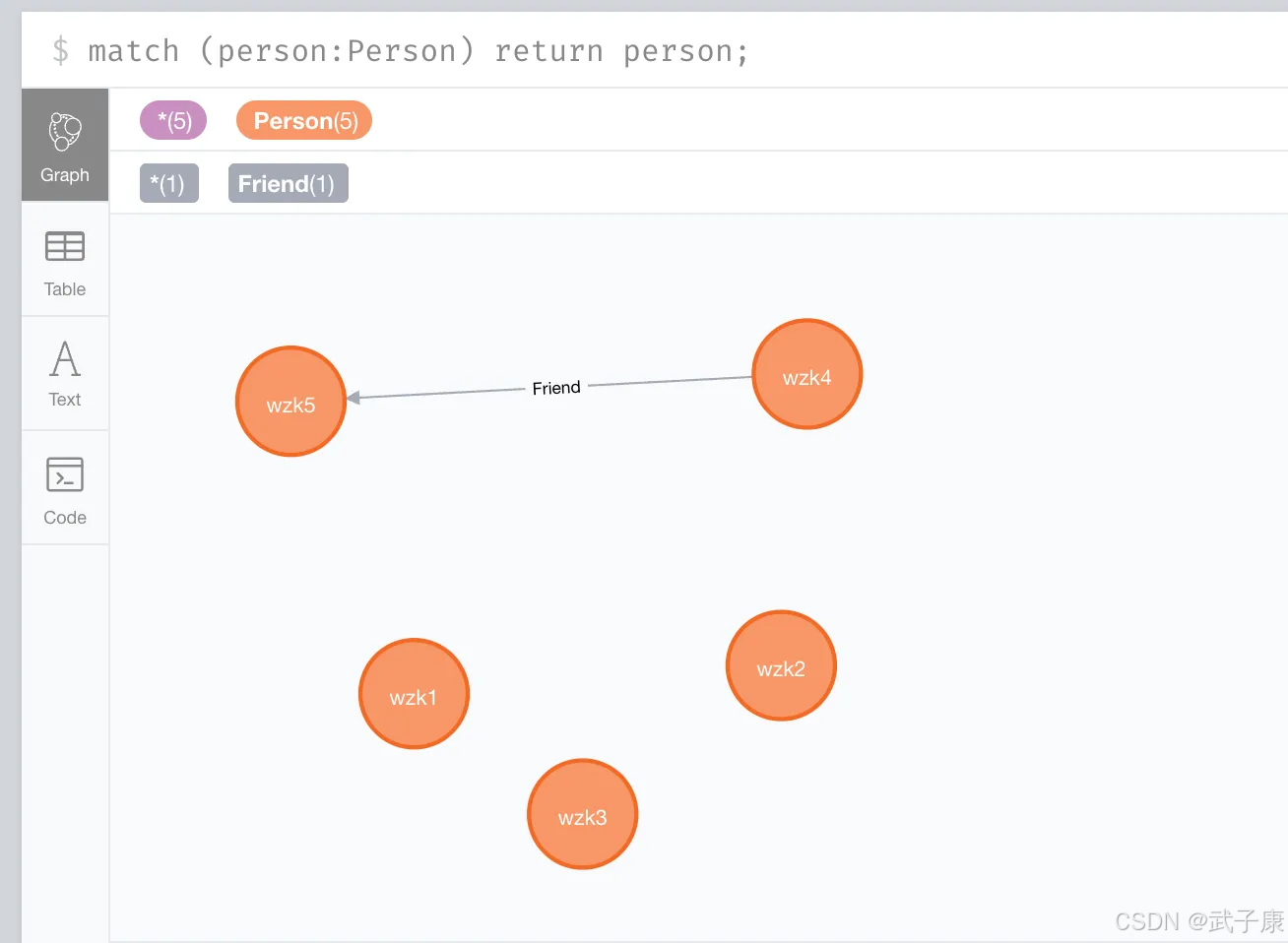
REMOVE
删除节点或者关系的标签,删除节点或者关系的属性
MATCH (person:Person {name:"wzk4"})
REMOVE person.cid
可以看到这里的值已经是 NULL 了:
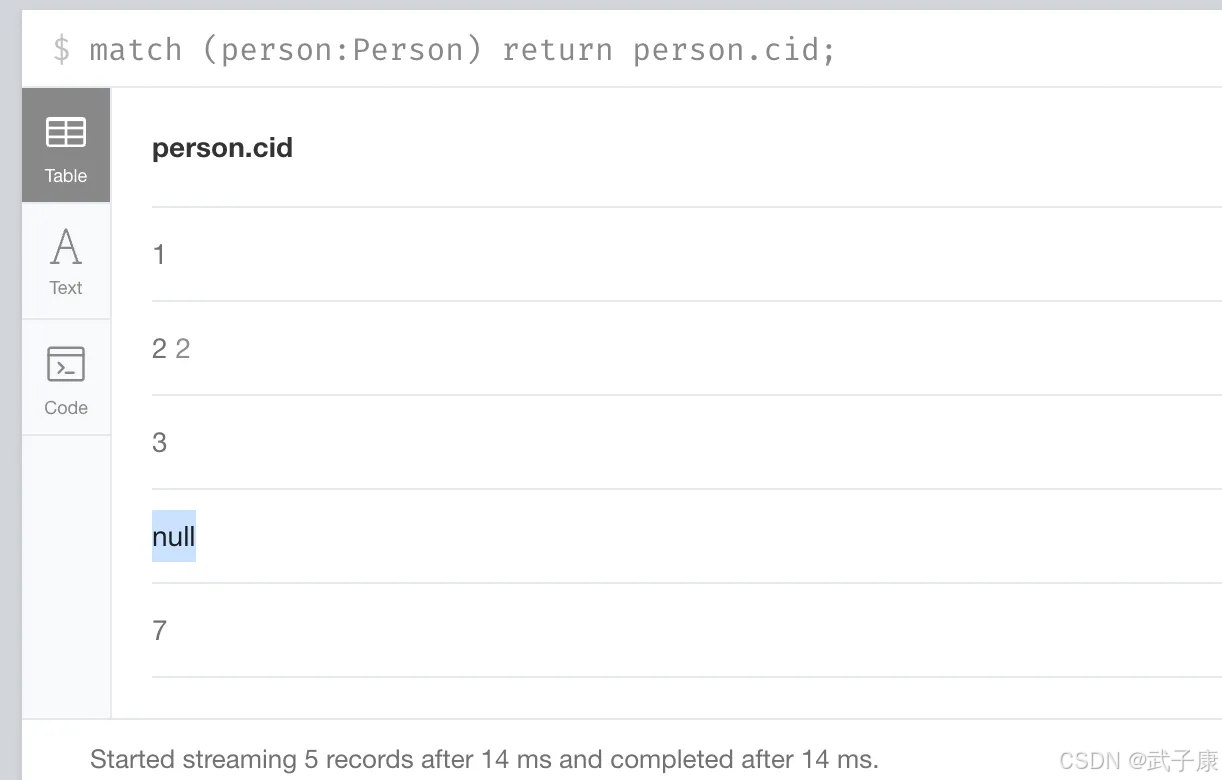
SET
向现有节点或者关系添加属性,更新属性值
MATCH (person:Person {cid:1})
SET person.money = 3456,person.age=25
这里可以看到数据已经修改了:

ORDER BY
"ORDER BY"子句是用于对MATCH查询返回的结果进行排序的关键操作。它允许我们根据指定的属性值对结果集进行组织,这在数据分析中非常实用。
排序方向:
- 升序(ASC):从小到大排列(默认设置)
- 降序(DESC):从大到小排列
使用场景示例:
- 按薪资高低显示员工列表
- 按产品价格排序商品目录
- 按学生成绩排名
语法说明:
MATCH (person:Person) # 匹配Person类型的节点
RETURN person.name, person.money # 返回姓名和资金属性
ORDER BY person.money DESC # 按资金降序排列
其他示例:
- 升序排列(可省略ASC):
MATCH (student:Student)
RETURN student.name, student.score
ORDER BY student.score
- 多列排序:
MATCH (employee:Employee)
RETURN employee.name, employee.salary, employee.department
ORDER BY employee.department ASC, employee.salary DESC
查询结果如下所示:

SKIP 和 LIMIT
在Neo4j图数据库查询中,SKIP和LIMIT子句经常配合使用来实现分页功能,这种方式与关系型数据库中的分页查询原理类似。
SKIP用于跳过指定数量的记录,而LIMIT则用于限制返回的记录数。当两者结合使用时,就可以实现典型的分页查询效果:
SKIP 4表示跳过前4条记录LIMIT 2表示只返回接下来的2条记录
这种组合特别适用于需要分批加载大量数据的场景,比如:
- 前端表格的分页显示
- 处理大数据集时的分批处理
- API接口中的分页响应
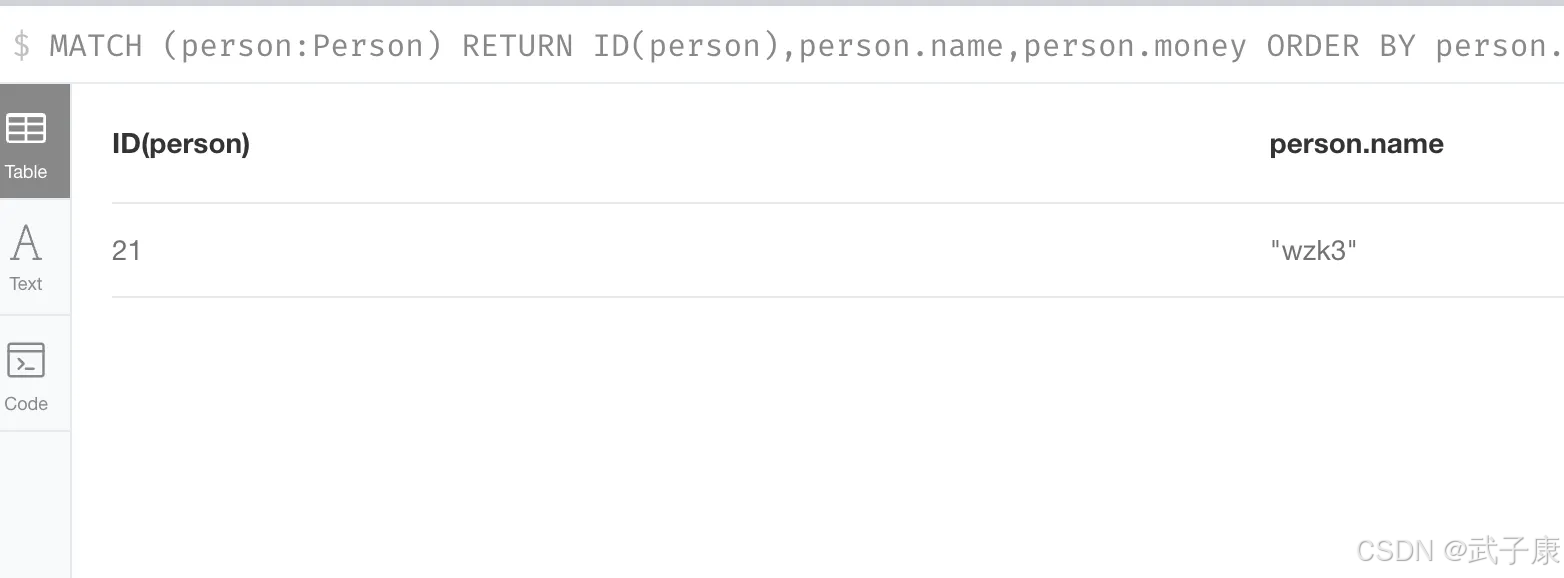
示例中这个查询的执行逻辑是:
MATCH (person:Person) // 查找所有Person节点
RETURN ID(person), person.name, person.money // 返回ID、姓名和资金属性
ORDER BY person.money DESC // 按资金降序排序
SKIP 4 LIMIT 2 // 跳过前4条,取接下来的2条
这相当于获取按资金排序后的第5-6条记录(假设索引从0开始)。如果要实现10条/页的分页:
- 第一页:
SKIP 0 LIMIT 10 - 第二页:
SKIP 10 LIMIT 10 - 第三页:
SKIP 20 LIMIT 10 - 依此类推
在实际应用中,通常会将当前页码和每页记录数作为参数动态构建查询:
MATCH (n:Node)
RETURN n
SKIP $pageSize * ($pageNum - 1)
LIMIT $pageSize
注意:SKIP和LIMIT的性能会受数据集大小影响,在大数据量情况下,可能需要配合索引优化查询性能。
执行的结果如下所示:
DISTINCT
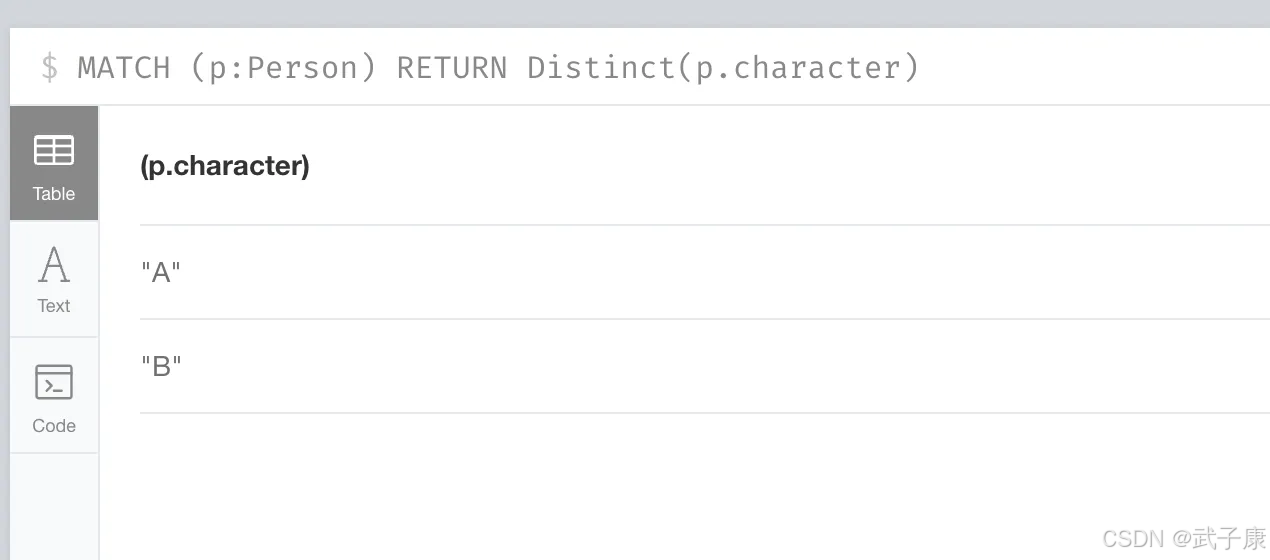
这个函数的用法类似于SQL中的DISTINCT关键字,主要用于去重操作,返回的是集合中的所有不同值。在Cypher查询语言中,DISTINCT的作用与SQL完全相同,都是用来消除结果集中的重复记录。
例如上面的Cypher查询语句:
MATCH (p:Person) RETURN Distinct(p.character)
它的作用是:
- 首先匹配图中所有标签为
Person的节点 - 然后获取这些节点的
character属性值 - 最后通过
DISTINCT关键字过滤掉重复的character值,只返回唯一的属性值集合
这种去重操作在以下场景特别有用:
- 统计某个属性的不同取值数量
- 获取分类列表时避免重复值
- 需要唯一值集合进行后续处理时
类似功能的SQL语句是:
SELECT DISTINCT character FROM Person
在实际图数据库应用中,这个功能经常用于数据分析和报表生成,比如统计用户的各种特征分布情况。
执行的结果如下所示:
错误速查卡(表:症状/根因/定位/修复)
| 症状 | 根因 | 定位 | 修复 |
|---|---|---|---|
| Cannot delete node , … still has relationships | 直接 DELETE 节点但存在关系 | MATCH (n)-[r]-() WHERE id(n)=… | 先删关系或用 DETACH DELETE n(审慎使用)。 |
| 分页结果来回跳动 | ORDER BY 不稳定(缺少唯一次序) | 查看排序键是否唯一 | 追加 , id(n) 或业务唯一键,确保稳定排序。 |
| 正则匹配异常/全量命中 | Java 正则未转义或边界书写错误 | 用小样本 WHERE prop =~ ‘…’ RETURN count(*) | 按 Java 正则转义(如 \.),必要时使用锚点 ^…$。 |
| STARTS WITH 命中过少/大小写不符 | 匹配大小写敏感 | 用大小写不同样本测试 | 统一大小写或改用正则/LOWER()(评估索引影响)。 |
| 删多节点误删扩散 | 匹配范围过宽(无精确 WHERE) | PROFILE/EXPLAIN 检查行数 | 先 MATCH … RETURN count(*) 确认,再执行 DELETE/DETACH. |
| 批量查询很慢 | 无索引全表扫 | PROFILE 查看 NodeByLabelScan | 为高频过滤属性建索引/约束;重写谓词。 |
| SET 后类型错乱 | 不同类型覆盖同一属性 | RETURN properties(n) 检查类型 | 统一类型或用显式转换;为关键属性约束类型策略。 |
| XOR 表达式行为不如预期 | 复杂逻辑/版本差异语义误会 | 断点打印布尔输入 | 用 (A OR B) AND NOT (A AND B) 明确表达互斥关系。 |
其他系列
🚀 AI篇持续更新中(长期更新)
AI炼丹日志-29 - 字节跳动 DeerFlow 深度研究框斜体样式架 私有部署 测试上手 架构研究,持续打造实用AI工具指南!
AI-调查研究-108-具身智能 机器人模型训练全流程详解:从预训练到强化学习与人类反馈
🔗 AI模块直达链接
💻 Java篇持续更新中(长期更新)
Java-154 深入浅出 MongoDB 用Java访问 MongoDB 数据库 从环境搭建到CRUD完整示例
MyBatis 已完结,Spring 已完结,Nginx已完结,Tomcat已完结,分布式服务正在更新!深入浅出助你打牢基础!
🔗 Java模块直达链接
📊 大数据板块已完成多项干货更新(300篇):
包括 Hadoop、Hive、Kafka、Flink、ClickHouse、Elasticsearch 等二十余项核心组件,覆盖离线+实时数仓全栈!
大数据-278 Spark MLib - 基础介绍 机器学习算法 梯度提升树 GBDT案例 详解
🔗 大数据模块直达链接