【大模型量化】Qwen3-VL + Lora监督微调 + 4bit量化 | VLM模型
本文记录分享Qwen3-VL使用Lora完成监督微调后,进行4bit量化的过程;
- 首先使用LLaMA Factory,对Qwen3-VL-4b进行Lora监督微调,得到微调后的lora权重;
- 然后合并 基础Qwen3-VL-4b权重 + lora权重 = 完整微调权重
- 最后对“完整微调权重”进行4bit量化,进行模型推理,计算模型准确率和召回率。
目录
一、对Qwen3-VL进行Lora 监督微调
二、合并权重
三、使用bnb进行4bit量化
四、量化后的模型推理(实践案例)
一、对Qwen3-VL进行Lora 监督微调
下面是LLaMA Factory 的微调训练配置,用于Qwen3-VL-4B-Instruct 多模态模型 的有监督微调:
| 项 | 配置值 | 作用 & 分析 |
|---|---|---|
| 模型 | Qwen3-VL-4B-Instruct(HuggingFace 源) | 选择了 4B 参量的多模态(图文)模型,适合轻量化多模态任务微调 |
| 微调方法 | LoRA | 低参数量微调(只训练适配器权重),显存占用低、训练速度快 |
| 量化策略 | 4bit(QLoRA)+ bnb 量化 | 进一步压缩显存(4bit 加载模型),结合 LoRA 可在普通消费级显卡(如 16G 显存)上训练 |
| 训练阶段 | Supervised Fine-Tuning (SFT,有监督微调) | 基于标注数据集训练模型生成符合要求的输出 |
微调界面:
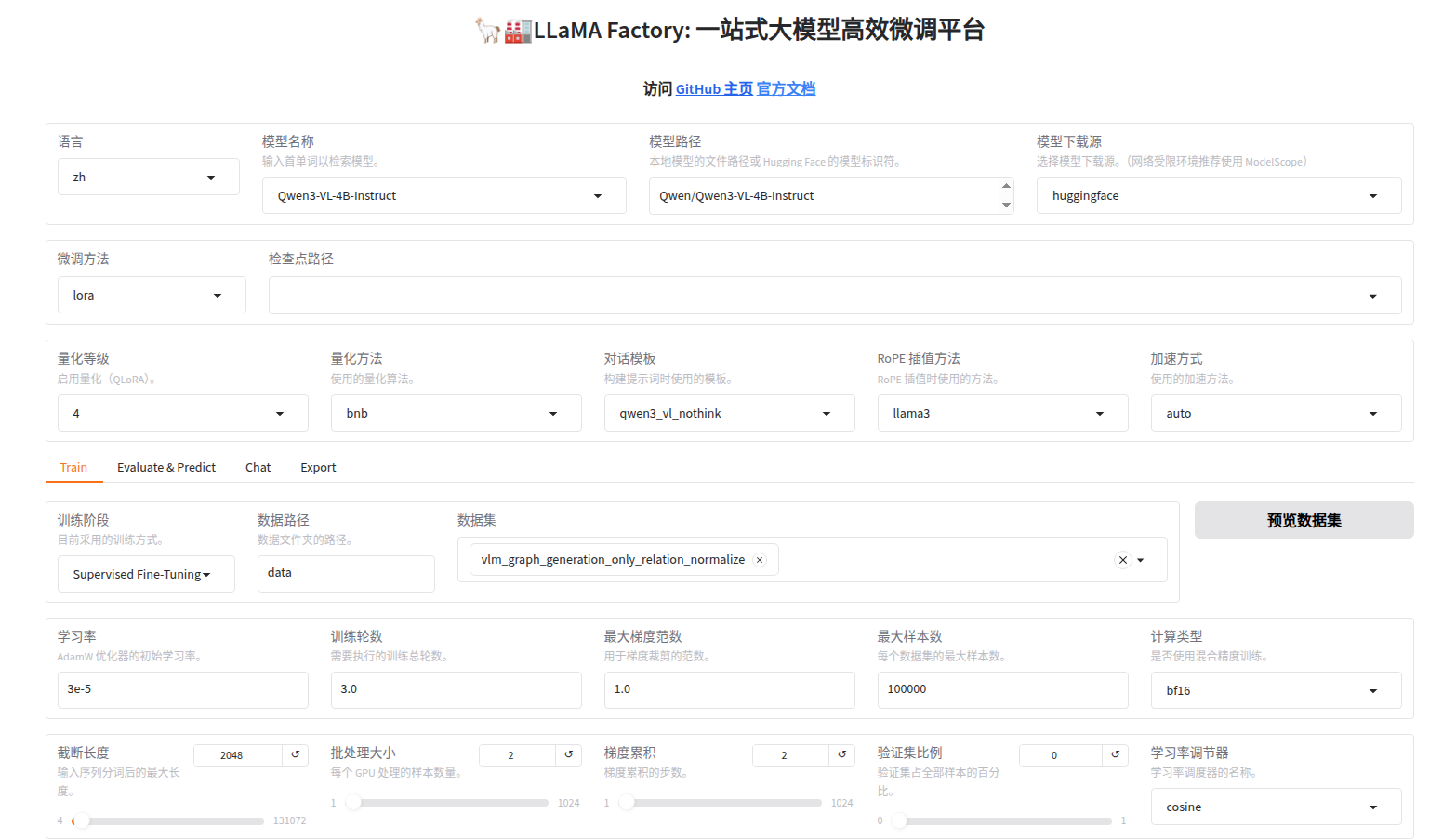
核心超参数配置(仅供参考,需要根据自己的模型调整的)
| 项 | 配置值 | 作用 & 分析 |
|---|---|---|
| 学习率 | 3e-5 | LoRA 微调的常用学习率(比全量微调高 1-2 个数量级) |
| 训练轮数 | 3.0 | 训练轮次较少,适合快速收敛或小数据集(避免过拟合) |
| 批处理 / 梯度累积 | 批大小 2 + 梯度累积 2 → 等效批大小 4 | 小批量 + 梯度累积平衡显存占用与训练稳定性 |
| 截断长度 | 2048 | 匹配 Qwen3-VL 的上下文长度上限,适配长文本 / 多模态输入 |
| 学习率调节器 | cosine(余弦退火) | 训练后期平滑降低学习率,帮助模型稳定收敛 |
| 计算类型 | bf16 | 半精度计算(需显卡支持 Ampere 及以上架构),进一步节省显存并加速训练 |
微调完整后,得到lora权重,默认保存在LLaMA Factory目录下的./saves/Qwen3-VL-4B-Instruct/lora/xxxxxx
二、合并权重
这里的思路:基础Qwen3-VL-4b权重 + lora权重 = 完整微调权重
我们只需确定:基础权重的路径model_name_or_path、lora微调权重路径adapter_name_or_path
然后执行下面命令,进行合并:
llamafactory-cli export \--model_name_or_path "/home/user/.cache/huggingface/hub/models--Qwen--Qwen3-VL-4B-Instruct/snapshots/ebb281ec70b05090aa6165b016eac8ec08e71b17/" \--adapter_name_or_path ./saves/Qwen3-VL-4B-Instruct/lora/train_2025-11-11-08-59-06/ \--export_dir ./model_path/qwen3-vl-4b-merged-t \--template qwen3_vl_nothink
等待合并完成~
[INFO|modeling_utils.py:2341] 2025-11-11 18:21:36,636 >> Instantiating Qwen3VLTextModel model under default dtype torch.bfloat16.
Loading checkpoint shards: 100%|████████████████████████████████████| 2/2 [00:00<00:00, 18.09it/s]
[INFO|configuration_utils.py:939] 2025-11-11 18:21:36,797 >> loading configuration file /home/user/.cache/huggingface/hub/models--Qwen--Qwen3-VL-4B-Instruct/snapshots/ebb281ec70b05090aa6165b016eac8ec08e71b17/generation_config.json
[INFO|configuration_utils.py:986] 2025-11-11 18:21:36,797 >> Generate config GenerationConfig {"bos_token_id": 151643,"do_sample": true,"eos_token_id": [151645,151643],"pad_token_id": 151643,"temperature": 0.7,"top_k": 20,"top_p": 0.8
}.....[INFO|tokenization_utils_base.py:2421] 2025-11-11 18:22:01,214 >> chat template saved in ./model_path/qwen3-vl-4b-merged-test/chat_template.jinja
[INFO|tokenization_utils_base.py:2590] 2025-11-11 18:22:01,214 >> tokenizer config file saved in ./model_path/qwen3-vl-4b-merged-test/tokenizer_config.json
[INFO|tokenization_utils_base.py:2599] 2025-11-11 18:22:01,214 >> Special tokens file saved in ./model_path/qwen3-vl-4b-merged-test/special_tokens_map.json
[INFO|image_processing_base.py:253] 2025-11-11 18:22:01,345 >> Image processor saved in ./model_path/qwen3-vl-4b-merged-test/preprocessor_config.json
[INFO|tokenization_utils_base.py:2421] 2025-11-11 18:22:01,346 >> chat template saved in ./model_path/qwen3-vl-4b-merged-test/chat_template.jinja
[INFO|tokenization_utils_base.py:2590] 2025-11-11 18:22:01,346 >> tokenizer config file saved in ./model_path/qwen3-vl-4b-merged-test/tokenizer_config.json
[INFO|tokenization_utils_base.py:2599] 2025-11-11 18:22:01,346 >> Special tokens file saved in ./model_path/qwen3-vl-4b-merged-test/special_tokens_map.json
[INFO|video_processing_utils.py:600] 2025-11-11 18:22:01,484 >> Video processor saved in ./model_path/qwen3-vl-4b-merged-test/video_preprocessor_config.json
[INFO|processing_utils.py:814] 2025-11-11 18:22:01,484 >> chat template saved in ./model_path/qwen3-vl-4b-merged-test/chat_template.jinja
[INFO|2025-11-11 18:22:01] llamafactory.train.tuner:143 >> Ollama modelfile saved in ./model_path/qwen3-vl-4b-merged-test/Modelfile
合并后的权重大小:
8.3G model_path/qwen3-vl-4b-merged
三、使用bnb进行4bit量化
通过BitsAndBytes工具对 Qwen3-VL 模型进行 4 位量化,以降低模型显存占用,
同时保存量化后的模型、分词器(tokenizer)和处理器(processor),便于后续部署使用。
- 使用
transformers库中的模型加载类(Qwen3VLForConditionalGeneration、AutoModel)、量化配置(BitsAndBytesConfig) - 依赖
torch进行张量计算和设备管理。
模型量化的实力代码,如下所示:
from transformers import Qwen3VLForConditionalGeneration, AutoModel, BitsAndBytesConfig, AutoTokenizer, AutoProcessor
import torchdef quantize_model():# 配置4位bnb量化quantization_config = BitsAndBytesConfig(load_in_4bit=True,bnb_4bit_compute_dtype=torch.float16,bnb_4bit_quant_type="nf4",bnb_4bit_use_double_quant=True,)try:# 尝试使用特定模型类print("尝试使用 Qwen3VLForConditionalGeneration 加载模型...")model = Qwen3VLForConditionalGeneration.from_pretrained("./model_path/qwen3-vl-4b-merged",quantization_config=quantization_config,device_map="auto",trust_remote_code=True)except Exception as e:print(f"使用特定类失败: {e}")print("尝试使用 AutoModel 加载模型...")# 回退到 AutoModelmodel = AutoModel.from_pretrained("./model_path/qwen3-vl-4b-merged",quantization_config=quantization_config,device_map="auto",trust_remote_code=True)# 加载tokenizer和processortokenizer = AutoTokenizer.from_pretrained("./model_path/qwen3-vl-4b-merged",trust_remote_code=True)processor = AutoProcessor.from_pretrained("./model_path/qwen3-vl-4b-merged",trust_remote_code=True)# 保存量化后的模型和相关组件model.save_pretrained("./model_path/qwen3-vl-4b-bnb-quantized-merged")tokenizer.save_pretrained("./model_path/qwen3-vl-4b-bnb-quantized-merged")processor.save_pretrained("./model_path/qwen3-vl-4b-bnb-quantized-merged")print("模型量化并保存完成!")if __name__ == "__main__":quantize_model()通过BitsAndBytesConfig定义量化参数,核心配置包括:
load_in_4bit=True:启用 4 位量化(相比 16 位 / 32 位大幅减少显存占用)。bnb_4bit_compute_dtype=torch.float16:计算时使用 float16 精度,平衡效率与性能。bnb_4bit_quant_type="nf4":采用 “Normalized Float 4” 量化类型,专为自然语言模型优化,精度优于普通 4 位量化。bnb_4bit_use_double_quant=True:启用双重量化(对量化参数再量化),进一步减少内存开销。
量化后的权重大小:
2.7G model_path/qwen3-vl-4b-bnb-quantized-merged
四、量化后的模型推理(实践案例)
这个模型推理示例,是 Qwen3-VL 量化模型的特定类别物体检测与可视化,
核心用于批量处理图像、提取目标物体多维度信息并生成可视化结果。
核心功能:
- 支持指定任意类别的物体(table、cup、bottle 等),输出类别、边界框、颜色、形状、外观 5 类信息。
- 支持批量读取图像目录,自动按自然排序处理文件。
- 生成带边界框和类别的可视化图像,同时打印详细物体描述。
- 包含异常处理和格式容错,确保流程稳定性。
推理代码:
import os
import json
import glob
import re
import torch
import numpy as np
from PIL import Image
import cv2
import time
from transformers import AutoProcessor, AutoModelForImageTextToText# --- 基础路径 ---
QUANTIZED_MODEL_PATH = "./model_path/qwen3-vl-4b-bnb-quantized-merged" # 融合lora微调 4-bit量化
input_dir = "./dataset_label/01_office/"
output_dir = "./Output_DATA/01_office"
# 定义要检测的物体类别
NODE_SPACE = ['table', 'cup', 'bottle', 'chair', 'robot', 'garbage can', 'shelf', 'tissue box', 'potted plant']# 全局初始化模型和处理器
print(f"正在加载修复后的量化Qwen3-VL-4B模型:{QUANTIZED_MODEL_PATH}...")
try:# 使用修复后的量化模型(不指定dtype)model = AutoModelForImageTextToText.from_pretrained(QUANTIZED_MODEL_PATH,device_map="auto",trust_remote_code=True)processor = AutoProcessor.from_pretrained(QUANTIZED_MODEL_PATH)print("修复后的量化Qwen3-VL-4B模型和处理器加载成功!")except Exception as e:print(f"模型加载失败:{str(e)}")exit(1)def call_vlm(image_path, prompt):"""安全的VLM调用函数"""try:# >>>>> 修改点1:直接使用 PIL 加载图像 <<<<<# 假设模型能处理任意大小的有效图像,不再强制调整尺寸image = Image.open(image_path).convert("RGB") # 确保是 RGB 模式messages = [{"role": "user","content": [{"type": "image"},{"type": "text", "text": prompt}]}]text = processor.apply_chat_template(messages,tokenize=False,add_generation_prompt=True)inputs = processor(text=text,images=image,return_tensors="pt",padding=True).to(model.device)# 生成参数with torch.no_grad():generated_ids = model.generate(**inputs,max_new_tokens=512,do_sample=False,num_beams=1,early_stopping=False)generated_ids_trimmed = generated_ids[:, inputs.input_ids.shape[1]:]output_text = processor.batch_decode(generated_ids_trimmed,skip_special_tokens=True,clean_up_tokenization_spaces=False)[0]return output_textexcept Exception as e:print(f"VLM调用失败: {str(e)}")return ""def detect_and_describe_objects(image_path):"""检测图像中的物体,获取其描述并反归一化bbox"""# 构建提示词prompt = f"""请严格检测图像中属于以下类别的所有物体:{NODE_SPACE}。对于每个检测到的物体,请提供:1. 类别 (category)2. 紧贴边缘的边界框 (bbox),格式为 [x1,y1,x2,y2](整数像素坐标)3. 颜色 (color)4. 形状 (shape)5. 外观描述 (appearance)输出要求:- 仅识别列表中的类别。- bbox必须精确且紧密贴合物体边缘。- 描述信息需与bbox内的区域一致。- 严格以 JSON 数组形式返回,不要包含任何额外的文本或代码块标记。输出示例(格式参考):[{{"category": "cup","bbox": [97, 203, 176, 282],"color": "白色","shape": "圆柱形","appearance": "带把手陶瓷杯"}},{{"category": "table","bbox": [10, 318, 639, 474],"color": "原木色","shape": "长方形","appearance": "四腿木质桌面"}}]"""try:# >>>>> 修改点2:直接使用 PIL 获取图像尺寸 <<<<<# 加载图像以获取尺寸用于坐标反归一化with Image.open(image_path) as img_pil:w_img, h_img = img_pil.convert("RGB").size # 确保获取到尺寸print("开始调用VLM进行物体检测...")time_start = time.time()response = call_vlm(image_path, prompt)time_end = time.time()print(f'VLM推理时间:{time_end - time_start:.2f}s')if not response:print("VLM返回空响应")return []# 解析JSON响应try:objects_data = json.loads(response.strip())except json.JSONDecodeError:# 尝试清理常见的格式问题cleaned_response = response.strip()if cleaned_response.startswith('```json'):cleaned_response = cleaned_response[7:]if cleaned_response.startswith('```'):cleaned_response = cleaned_response[3:]if cleaned_response.endswith('```'):cleaned_response = cleaned_response[:-3]cleaned_response = cleaned_response.strip()try:objects_data = json.loads(cleaned_response)except json.JSONDecodeError as e:print(f"JSON解析失败: {e}")print(f"原始响应内容: {response}")return []if not isinstance(objects_data, list):print(f"响应不是列表格式: {objects_data}")return []# 处理并验证每个检测到的物体valid_objects = []for i, obj in enumerate(objects_data):# 验证基本结构if not (isinstance(obj, dict) and obj.get('category') in NODE_SPACE and len(obj.get('bbox', [])) == 4):print(f"警告:跳过无效的检测结果 #{i+1}: {obj}")continue# 提取并转换bbox坐标try:coords = list(map(float, obj['bbox']))x1_norm, y1_norm, x2_norm, y2_norm = coordsexcept (ValueError, TypeError) as e:print(f"警告:跳过坐标格式错误的物体 #{i+1}: {e}")continue# 反归一化 (假设模型输出的是0-1000范围的坐标)x1 = int(round(x1_norm / 1000 * w_img))y1 = int(round(y1_norm / 1000 * h_img))x2 = int(round(x2_norm / 1000 * w_img))y2 = int(round(y2_norm / 1000 * h_img))# 确保坐标在图像范围内x1 = max(0, min(x1, w_img - 1))y1 = max(0, min(y1, h_img - 1))x2 = max(x1 + 1, min(x2, w_img - 1))y2 = max(y1 + 1, min(y2, h_img - 1))# 更新对象字典obj['bbox'] = [x1, y1, x2, y2]valid_objects.append(obj)print(f"共检测并验证了 {len(valid_objects)} 个物体。")return valid_objectsexcept Exception as e:print(f"物体检测过程失败: {str(e)}")return []def visualize_detections(image_path, detected_objects, output_path):"""可视化检测结果:绘制bbox和标签"""try:# 读取图像image_bgr = cv2.imread(image_path)if image_bgr is None:print(f"无法读取图像: {image_path}")returnh_img, w_img = image_bgr.shape[:2] # 获取OpenCV图像的尺寸# 绘制每个检测到的物体for i, obj in enumerate(detected_objects):bbox = obj.get('bbox', [0, 0, 0, 0])category = obj.get('category', 'Unknown')# 确保坐标在有效范围内 (基于OpenCV图像尺寸)x1, y1, x2, y2 = bboxx1 = max(0, min(x1, w_img - 1))y1 = max(0, min(y1, h_img - 1))x2 = max(x1 + 1, min(x2, w_img - 1))y2 = max(y1 + 1, min(y2, h_img - 1))# 绘制边界框cv2.rectangle(image_bgr, (x1, y1), (x2, y2), (0, 255, 0), 2)# 准备标签文本label_parts = [category]# 可以选择性地添加颜色、形状等信息到标签# color = obj.get('color', '')# shape = obj.get('shape', '')# if color: label_parts.append(color)# if shape: label_parts.append(shape)label = " ".join(label_parts)# 计算标签位置(在框上方)(text_width, text_height), baseline = cv2.getTextSize(label, cv2.FONT_HERSHEY_SIMPLEX, 0.5, 1)y_label = y1 - 10 if y1 - 10 > 10 else y1 + 10 + text_height# 绘制标签背景矩形cv2.rectangle(image_bgr, (x1, y_label - text_height - baseline), (x1 + text_width, y_label + baseline), (0, 255, 0), -1)# 绘制标签文字cv2.putText(image_bgr, label, (x1, y_label),cv2.FONT_HERSHEY_SIMPLEX, 0.5, (0, 0, 0), 1)# 保存可视化图像cv2.imwrite(output_path, image_bgr)print(f"检测结果可视化已保存至: {output_path}")except Exception as e:print(f"可视化检测结果失败: {str(e)}")def print_object_descriptions(detected_objects):"""打印每个检测到的物体的详细描述信息"""if not detected_objects:print("未检测到任何物体。")returnprint("\n--- 检测到的物体描述 ---")for i, obj in enumerate(detected_objects):print(f"物体 #{i+1}:")print(f" 类别 (Category): {obj.get('category', 'N/A')}")print(f" 边界框 (Bbox): {obj.get('bbox', 'N/A')}")print(f" 颜色 (Color): {obj.get('color', 'N/A')}")print(f" 形状 (Shape): {obj.get('shape', 'N/A')}")print(f" 外观 (Appearance): {obj.get('appearance', 'N/A')}")print("-" * 20)print("--- 描述结束 ---\n")def natural_sort_key(filename):"""自然排序含数字的文件名"""return [int(t) if t.isdigit() else t.lower()for t in re.split(r'(\d+)', os.path.basename(filename))]def process_images_simple(input_dir, output_dir):"""批量处理图像目录,执行简化任务"""try:os.makedirs(output_dir, exist_ok=True)viz_output_dir = os.path.join(output_dir, "visualizations_simple")os.makedirs(viz_output_dir, exist_ok=True)image_extensions = ['*.jpg', '*.jpeg', '*.png', '*.bmp', '*.gif']image_files = []for ext in image_extensions:image_files.extend(glob.glob(os.path.join(input_dir, ext)))image_files = sorted(image_files, key=natural_sort_key)if not image_files:print(f"在目录 {input_dir} 中未找到图像文件")returnfor image_path in image_files:image_name = os.path.basename(image_path)print(f"\n---------- 处理图像: {image_name} ----------")# 1. 检测物体并获取描述detected_objects = detect_and_describe_objects(image_path)# 2. 打印物体描述print_object_descriptions(detected_objects)# 3. 可视化检测框viz_filename = os.path.splitext(image_name)[0] + "_simple_viz.jpg"viz_path = os.path.join(viz_output_dir, viz_filename)visualize_detections(image_path, detected_objects, viz_path)print(f"---------- 完成处理: {image_name} ----------\n")print("\n所有图像处理完成")except Exception as e:print(f"处理图像目录失败: {str(e)}")if __name__ == "__main__":import argparseparser = argparse.ArgumentParser(description='简化版Qwen3-VL物体检测与可视化工具')parser.add_argument('--input_dir', type=str, default=input_dir, help='包含图像的输入目录')parser.add_argument('--output_dir', type=str, default=output_dir, help='输出结果的目录')args = parser.parse_args()process_images_simple(args.input_dir, args.output_dir)代码流程:
- 初始化:加载量化模型和处理器,自动适配设备(CPU/GPU)。
- 图像读取:批量获取指定目录下的多种格式图像,按自然排序处理。
- VLM 调用:通过提示词引导模型检测目标物体,返回 JSON 格式结果。
- 结果处理:解析 JSON 响应(含格式容错),将归一化坐标反转为像素坐标并校验范围。
- 可视化与输出:用 OpenCV 绘制边界框和标签,保存图像并打印详细物体信息。
运行效果:
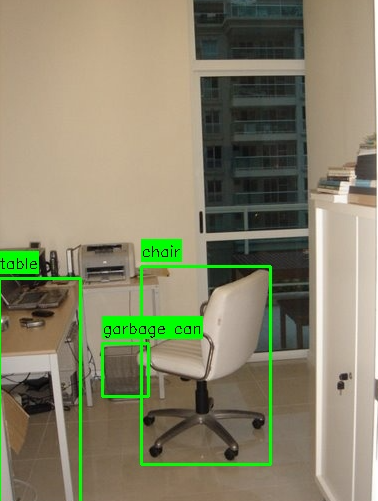
打印信息:
---------- 处理图像: 00_17.jpg ----------
开始调用VLM进行物体检测...
The following generation flags are not valid and may be ignored: ['temperature', 'top_p', 'top_k']. Set `TRANSFORMERS_VERBOSITY=info` for more details.
VLM推理时间:12.07s
共检测并验证了 3 个物体。--- 检测到的物体描述 ---
物体 #1:
类别 (Category): table
边界框 (Bbox): [0, 282, 81, 511]
颜色 (Color): 浅木色
形状 (Shape): 长方形
外观 (Appearance): 带金属桌腿的办公桌
--------------------
物体 #2:
类别 (Category): chair
边界框 (Bbox): [142, 270, 271, 468]
颜色 (Color): 白色
形状 (Shape): 五轮转椅
外观 (Appearance): 带黑色扶手和轮子的办公椅
--------------------
物体 #3:
类别 (Category): garbage can
边界框 (Bbox): [103, 347, 149, 400]
颜色 (Color): 灰色
形状 (Shape): 方形
外观 (Appearance): 金属网格垃圾桶
--------------------
--- 描述结束 ---检测结果可视化已保存至: ./Output_DATA/01_office/visualizations_simple/00_17_simple_viz.jpg
---------- 完成处理: 00_17.jpg ----------
其他案例:



能看到通过4-bit量化的Qwen3-VL-4b模型,还是能准确把物体检测出来,而且物体的框比较贴合
后面部署到NVIDIA Orin板子中,看看效果~
分享完成~