CEVA-DSP开发初识(一)
最近开发完了为旌vs819l平台几乎每个模块,其他都没啥难度,dsp模块以前或多或少接触过皮毛,这次有机会好好了解和开发下,做一个完整的记录。
1、DSP的效率为什么很高
首先要理解这个概念,才能掌握dsp编程的核心。核心就是simd架构,像x86平台的sse加速,arm平台的neon加速,dsp平台也高度契合了这种设计思维,并行指令和流水线处理,这是dsp平台能够高速完成复杂算法运算的基础。

为了能够达成这种高速并行设计架构,dsp芯片内嵌了丰富的硬核化资源,如上图重点模块逐一梳理总结下。
1.1、标量处理单元SPU
单核dsp-core有4个spu独立的子单元,负责执行数值计算相关指令。算数运算操作,比如加减法、最值、比较、绝对和取反;乘法和乘累加操作;逻辑运算操作,比如and、nor;位操作,移位、插入和提取;还有其他一些如断言、饱和操作等;设想一下,spu模块一个周期就完成多个源操作数和目标操作数的运算。如scalar mac fixed point,支持8(16x16),4(32x32)运算;scalar mac floating point,支持4(32bit or 16bit)运算。
spu模块我自己总结就是重在构建程序逻辑,下边是详细的模块指令列表。
1.2、矢量处理单元VPU(LVPU)
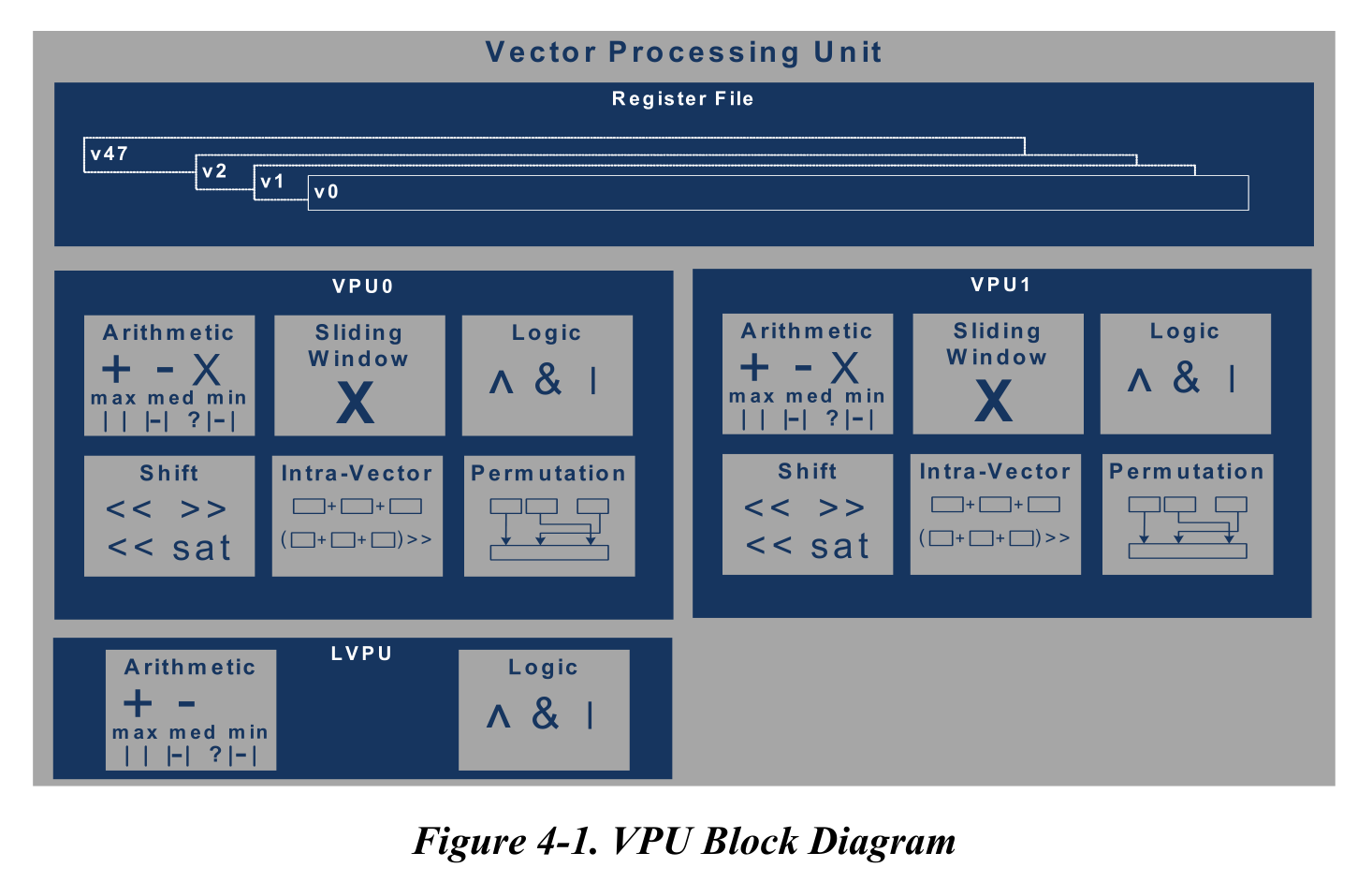
矢量相对于标量,有2个vpu子单元和1个轻量化lvpu子单元,处理vector数据类型的资源,我觉得简单的理解就是矩阵。在dsp运算中是一个多维的表述,如下图。

vpu支持的运算类型更加丰富,以至于文档专门用了一个框图来介绍。如下图,算数运算操作、滑窗运算操作、逻辑运算操作、移位运算操作、内部操作、置换操作等,vpu支持的指令也远多于spu模块,并行的能力上也更强。如支持vector mac fixed point 128(16x8),128(16x16),16(32x32) 运算,vector mac floating point 16(32bit) or 32(16bit) 运算。
附上指令列表:
1.3、加载和存储单元LSU
在使用spu和vpu之前,首先考虑需要把数据加载到寄存器做运算,以及把寄存器运算的结果搬出来。如下图,mem->reg,reg->mem,都通过lsu产生地址和寻址,让编程开发者不用再去关心操作数和寄存器的地址。

对应dsp编程的基础指令ld和st,衍生出了好几种不同应用场景的加载模式。如下图,但我感觉可以常用的指令也就标量的st、ld和矢量的vpst、vpld,如果碰到隔行图像处理,会用到vbcpld。
同样lsu的指令也是并行的。

2、总结
像其他模块,程序控制单元PCU,类似arm的寻址-译码-执行三部曲;内存子系统MSS,内存管理子系统,就不再详细解释了,比较通用。
综上,ceva-dsp的指令在设计上,都是按照simd架构并行的思路,可以同时加载、处理、存储多组源操作数和目标操作数,所以能够实现高效。如果编程上,能够使用这些底层指令来构建算法和逻辑,那自然处理算法的速度就会很快,反之,如果在dsp里边,用简单的c语言编程,就无法发挥出dsp硬件资源的优势。所以,dsp编程开发,我认为会话大量的时间去熟悉dsp指令,只有在指令熟悉的基础上,才能把他们使用好。