生成模型技术宇宙:从VAE到世界模型,揭示AIGC核心引擎
各位技术爱好者们!我们正身处一场由生成式AI引领的内容创作革命之中。无论是Midjourney绘制的梦幻画作,ChatGPT撰写的流畅文稿,还是Sora生成的逼真视频,其核心都离不开一套日臻完善的生成模型技术栈。
本帖将带你深入这个技术宇宙,纵览其发展历程、核心思想、流派兴衰与未来方向。这是一份为你准备的终极导航图。🌌
一、 核心理念:生成模型是什么?
在深入细节前,我们必须理解其根本任务:学习并模拟真实数据的概率分布 P(X)。
· 判别模型: 学习的是条件概率 P(Y|X) —— “给定输入X,它是什么?”
· 生成模型: 学习的是联合概率 P(X) —— “这样的数据是如何产生的?”
一旦模型掌握了数据的“分布”,它就能从中采样,创造出从未存在过但极其相似的新数据。
二、 技术演进全景图与核心流派
我们可以将主流生成模型分为以下几大流派,它们互为补充,共同演进。
1. 似然派 - 显式建模密度函数
此流派直接对数据分布进行建模,并追求最大化训练数据的“似然”。
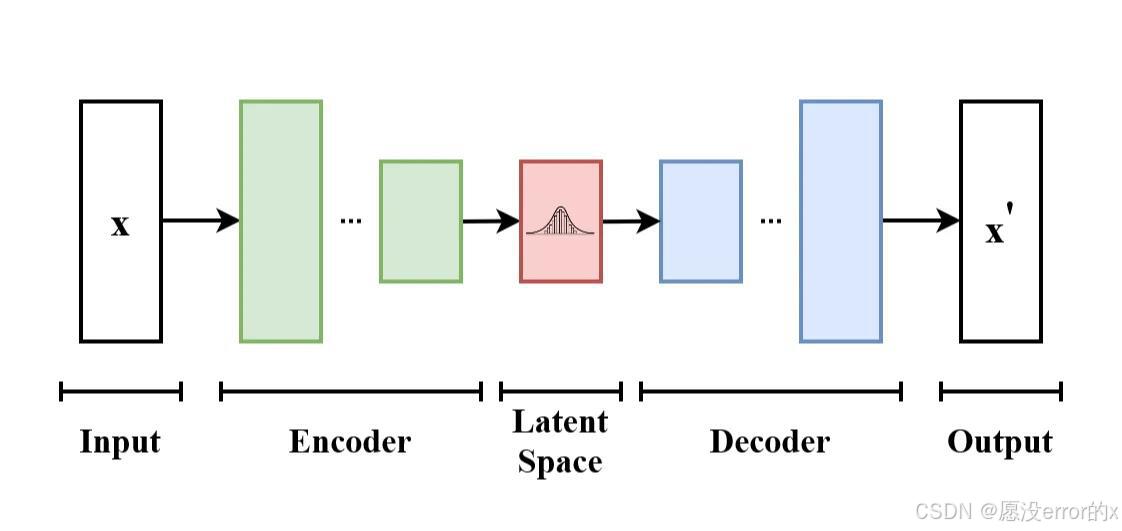
· a) 变分自编码器
· 核心思想: 引入隐变量z,通过编码器学习后验分布q(z|X)的近似,并通过解码器从z重建数据。它最大化的是似然函数的下界。
· 优点: 训练稳定,潜在空间连续,适合插值和数据表示学习。
· 缺点: 生成的样本往往模糊,因为优化的是似然下界而非精确似然。
· 关键变体: VQ-VAE(使用离散编码本,生成质量更高,被用于AudioLM、MusicLM等音频模型)。
· b) 自回归模型
· 核心思想: 将数据(图像、文本、音频)视为一个序列,将联合概率分解为一系列条件概率的乘积:P(X) = Π P(x_i | x_1, ..., x_{i-1})。逐个生成下一个元素。
· 优点: 原理简单,生成质量高。
· 缺点: 生成速度慢,因为必须串行进行,无法并行。
· 著名代表:
· 图像: PixelCNN, PixelRNN
· 文本/代码: GPT系列、T5
· 音频: WaveNet
· c) 流模型
· 核心思想: 通过一系列可逆的、具有易计算雅可比矩阵的变换,将简单分布(如高斯分布)精确地映射到复杂数据分布。
· 优点: 能精确计算似然,潜在空间有意义,训练稳定。
· 缺点: 架构设计受限,计算成本通常较高。
· 著名代表: GLOW, RealNVP
2. 对抗派 - 绕过密度估计
此流派另辟蹊径,不直接建模分布,而是通过“博弈”来学习。
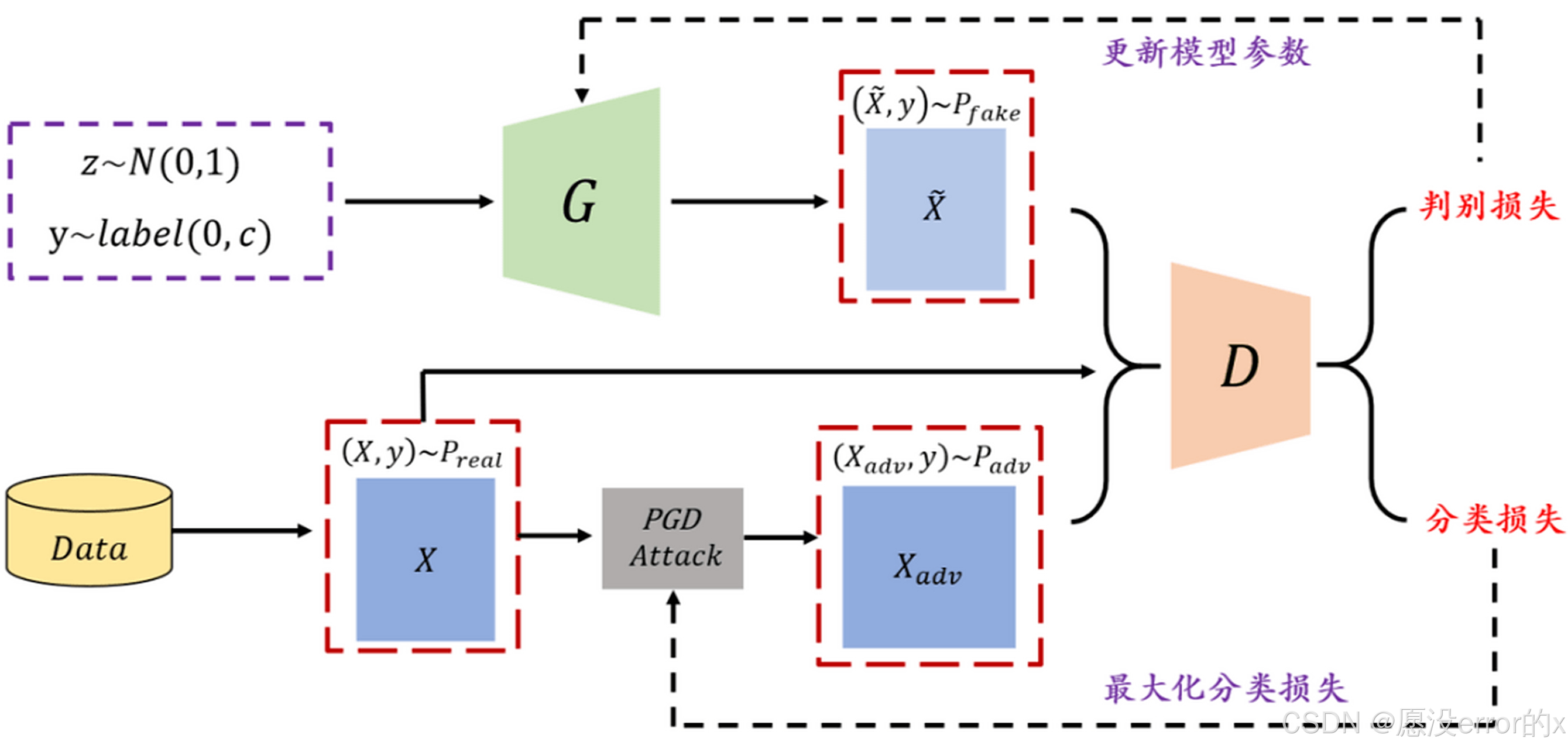
· 生成对抗网络
· 核心思想: “伪造者”生成器和“鉴定官”判别器的二人极小极大博弈。目标是达到纳什均衡:生成器生成的数据分布与真实数据分布无法区分。
· 优点: 在巅峰时期,生成的图像锐利度和细节远超同期其他模型。
· 缺点: 训练极其不稳定(模式崩溃、梯度消失、难以收敛)。
· 著名家族:
· DCGAN: 将CNN引入GAN的奠基之作。
· Wasserstein GAN: 通过Wasserstein距离改进损失函数,极大提升了训练稳定性。
· StyleGAN系列: 风格迁移与生成的里程碑,实现了解耦的、精细的语义控制。
3. 新王当立 - 扩散模型
它结合了似然派的理论优势和对抗派的生成质量,成为当前无可争议的SOTA。
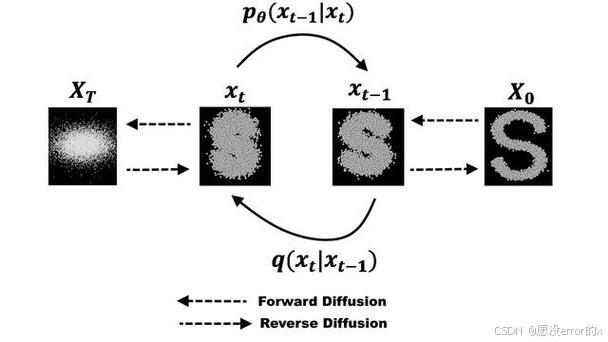
· 核心思想: 受非平衡热力学启发。包含两个过程:
· 前向过程: 固定规则,逐步向数据添加高斯噪声,直至数据变成纯噪声。
· 反向过程: 训练一个神经网络(通常是U-Net),学习如何逐步去噪,从纯噪声中重建出数据。
· 优点: 生成质量顶尖、训练稳定、多样性好。
· 缺点: 原始生成速度慢(需多步迭代)。
· 关键变体与加速技术:
· DDPM: 奠基之作。
· DDIM: 提出了更快的采样算法。
· Latent Diffusion: 在VAE的潜在空间中进行扩散,极大降低计算成本。这就是 Stable Diffusion 的核心。
· Classifier/Classifier-free Guidance: 大幅提升生成样本与文本提示的对齐质量。
· Consistency Models: 一种新兴的加速技术,旨在一步或少数几步内完成生成。
4. 多模态与统一架构派
这是当前最前沿的方向,旨在用一个模型理解并生成多种类型的数据。
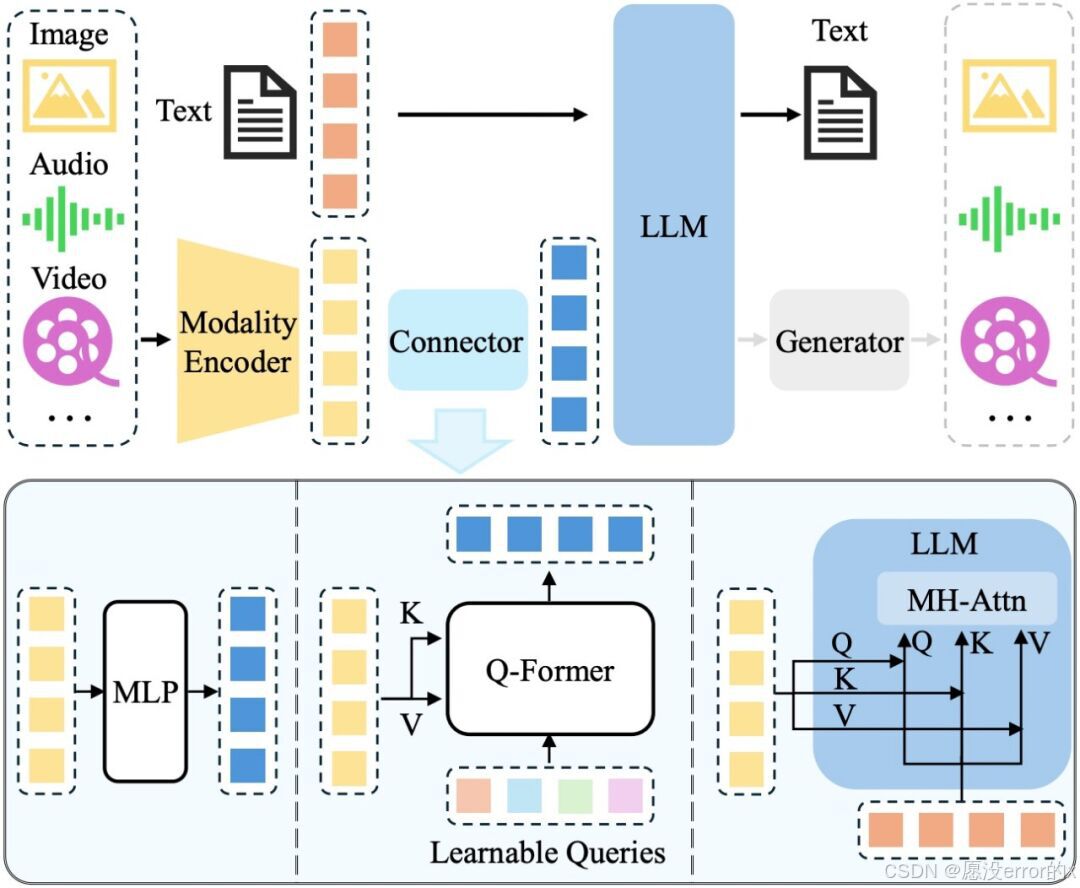
· Transformer + 自回归: 已成为通用序列建模的基石。
· 代表: DALL-E(使用VQ-VAE + 自回归Transformer)、GPT系列、Parti。
· Diffusion + Transformer: 结合扩散模型的高质量生成和Transformer的强大序列建模能力。
· 代表: Sora(核心技术路径:将视频和图像编码为时空Patch,使用Diffusion Transformer进行生成)。
三、超越图像:生成模型的广阔应用天地
· 文本: 写作、翻译、代码生成、对话——大语言模型 的主场。
· 音频: 文本转语音、音乐生成、音效设计、语音克隆。
· 视频: 文生视频、视频编辑、风格迁移、帧预测——Sora, Pika, Runway 等。
· 3D与科学: 生成3D模型和场景;生成新分子结构用于药物发现;生成蛋白质序列。
· 决策与规划: 世界模型——通过生成未来环境的状态来辅助智能体进行决策。
四、 未来趋势与严峻挑战
趋势:
1. 规模化与统一: 构建一个模型处理所有模态(文本、图像、视频、音频、3D)是终极梦想。
2. 可控性精细化: 从“生成什么”到“如何生成”,实现像素级、语义级的精确控制。
3. 效率革命: 一致性模型、对抗性蒸馏等技术正致力于将Diffusion模型推向实时生成。
4. 世界模型: 从生成静态内容到生成动态的环境状态序列,是通往更通用AI的关键路径。
挑战:
1. 算力壁垒: 训练顶尖模型所需的资源使其成为少数巨头的游戏。
2. 安全与伦理: 深度伪造、版权纠纷、偏见与歧视是悬在头顶的达摩克利斯之剑。
3. 可靠性: 模型的“幻觉”问题在关键领域(如医疗、法律)是致命的。
4. 可解释性: 我们仍不清楚这些“黑箱”模型为何能工作得如此之好。
结语:
我们正在见证的,不仅是技术的迭代,更是范式的转移。从为特定任务设计模型,到构建能够理解并生成我们复杂世界的通用基础模型,生成式AI正在重新定义创造力的边界。
这场旅程才刚刚开始。
以上是我的个人看法,欢迎各位大佬评论区补充😊