[性能测试]
性能学习目标
- 什么是性能测试,为什么要做性能测试
- 什么是负载测试,稳定性测试
- 能说出常用性能指标的含义
- 口述性能测试流程
理论
概述
- 什么是性能?软件质量属性中的效率(与效率有关)
- 效率特性:
- 时间特性 : 系统处理用户请求的响应时间
- 资源特性 : 运行过程中,系统资源消耗情况(CPU,内存,磁盘IO/input,output)
- 什么是性能测试?
- 使用自动化测试工具,模拟不同使用环境,对软件各项性能指标进行测试和评估的过程
- 性能测试测什么?
- 后台代码的性能
- 数据库,系统架构性能
- 服务器资源(CPU,内存,磁盘,网络)利用率等
- 性能测试的目的
- 评估当前系统的性能(竞品/第三方软件获取)
- 找系统的性能瓶颈,优化性能
- 评估软件能否满足未来2-3年的使用需求
- 性能与功能测试对比
- 接口功能:
- 测试当前接口功能是否满足需求,正向-逆向测试用例实现
- 接口性能:
- 测试不同业务场景,是否满足用户需求,测试对象时间,资源
- 对比:二者相辅相成,一般功能在前,性能后
- 接口功能:
策略
一般按照先基准,后负载,再稳定性测试的测试顺序,展开性能测试
- 基准测试(单用户测试)
- 围绕一个用户展开性能测试,获取测试数据,为后续多用户并发测试提供数据参考
- 负载测试–超出最大负载后,系统不一定瘫痪
- 采用逐步加压的方式,向服务器发送请求,找出预设情况下,系统的最大负载(有指标).
- 稳定性测试
- 系统在一定负载下进行长时间(1×24,3×24,7×24)运行,测试是否满足预设的性能指标
- 其他测试
- 并发测试:
- 一个极短的时间内,测试服务器瞬时并发访问的处理能力.
- 100个用户同时登录不是并发!!!但抢红包,抢购,秒杀是
- 压力测试:
- 采用逐步加压向服务器发送请求,找出系统被崩溃的临界点,目的是对系统的极限性能有了解.
- 并发测试:
指标
- 响应时间
- 从客户端发出请求,到接收服务器回发的响应数据所经历的 所有时间
- 响应时间 = 网络时间 + 应用程序处理时间
- 并发数
- 同一时间内,向服务器发送请求的用户数量
- 吞吐量
- 单位时间内处理客户端请求的数量,是衡量服务器性能的重要参考指标
- 常用参考值 :
- TPS : 每秒事务数(默认吞吐量使用)
- QPS : 每秒请求数
- 点击数
- 不是点击页面的次数,而是页面上的元素向web服务器发送请求的次数
- 只有web服务器才有点击数的性能指标
- 错误率
- 系统在一定负载下,失败业务的概率,错误率=(失败业务数/总业务数)*100%
- 项目中错误率应该由产品给出特定的说明,默认错误率为0.05%
- 资源利用率
- 系统运行过程中,服务器各个硬件资源使用的情况,(资源的使用率/总的资源可用量)*100%
- 参考值 : 产品经理给出则按需求文档数据,没有则参考默认值,超出则有瓶颈,CPU(75%-85%),内存(80%),磁盘(90%)除了存储占比,还可以衡量读写占比,网络(80%)
- PV和UV
流程
- 性能测试需求分析
- 性能测试计划及方案
- 性能测试用例
- 建立测试环境
- 测试用例编写/录制
- 执行测试脚本
- 监控性能测试数据
- 性能分析和调优(多轮)
- 编写性能测试报告,总结
- 性能分析:
- 熟悉被测系统 :
- 熟悉业务
- 熟悉技术架构
- 测试内容 :
- 按业务 : 找出需要性能测试的业务,按用户使用频率高低划分
- 按技术架构 : 测试逻辑复杂度较高的业务
- 测试策略 : 基准测试,负载测试,稳定性测试,根据实际业务分析是否需要并发/压力测试
- 测试指标 : 有明确需求按照需求文档给出的数据,没有则分析竞品系统获取参考数据指标
- 熟悉被测系统 :
- 测试计划和方案
- 测什么
- 谁来测
- 怎么测
- 搭建测试工具环境
- 所需要的测试工具相关环境
- 部署性能测试使用的项目环境
- 要求: 硬件,软件,网络必须与线上环境完全一致
- 一部分项目,直接使用线上环境开展测试
- 编写/录制脚本
- 不推荐使用脚本录制
- 借助性能测试工具,自己编写脚本
- 执行测试脚本 : 工具生成的脚本,按预设的指标设置,执行基准测试压测等
- 性能测试监控 : 按预设性能指标,对系统资源使用情况进行监控
- 性能分析和调优
- 根据测试脚本或命令,看测试结果,对比实际与预期结果间关系
- 由易到难分析性能瓶颈:
- 硬件资源(CPU,内存,磁盘)
- 网络资源
- 中间件(应用服务器), 数据库的 配置(外键设置等)
- 源代码,数据库脚本
- 系统架构(一般极少)
- 性能测试报告总结
- 包含生成的性能测试报告图表(图 表为主)
- 标注出现性能瓶颈的位置,原因,解决思路,调优方法
- 当前项目测试过程中的风险如何处理,未来可能存在的风险
- 总结项目测试过程中的过程与教训
性能测试工具
- loadrunner
- 优点 : 支持ip欺骗,有详细的分析报表
- 缺点 : 收费,体积庞大,无法定制功能
- jmeter
- 优点 : 开源,免费,有丰富的学习资料和扩展组件
- 缺点 : 不支持ip欺骗,分析报表相较于loadrunner不够精细
Jmeter基本使用
- 启动
- ApacheJmeter.jar : 启动jmeter,借助命令java -jar ApacheJmeter.jar
- jmeter.bat : windows下的jmeter的启动文件
- 文件目录 :
- jmeter.log : jmeter的日志文件
- jmeter.properties : 系统配置文件
- jmeter.sh : linux下jmeter的启动文件
- jmeter.server : linux下实现分布式 服务启动配置文件
- jmeter.server.bat : windows下实现分布式,服务启动配置文件
- 作用域
- 元件 : 监听器定时器断言等一系列组件的组合
- 组件 : 一个个具体的业务功能
- 元件执行顺序 :
- 相同元件 : 按书写顺序执行
- 不同元件 : 按照如下顺序
- 配置元件
- 前置处理器
- 定时器
- 取样器
- 后置处理程序
- 断言
- 监听器
- jmeter案例
- 步骤 : 在测试计划 --> 线程组 --> 添加http请求 --> 添加监听器 --> 查看结果树
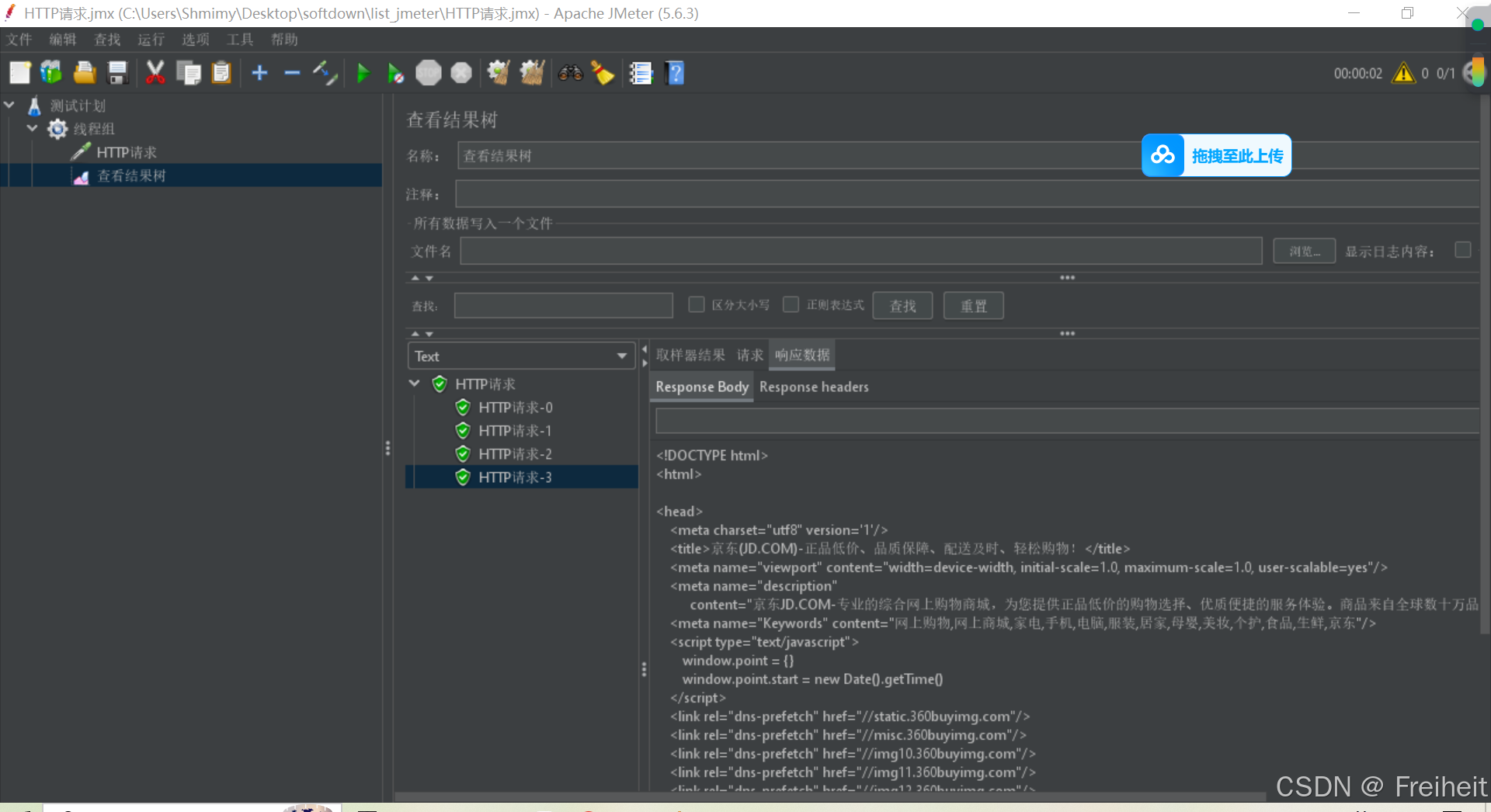
- 线程数 : 并发用户数
- 爬坡时间 : 启动所有线程 消耗的总时间
- 循环次数 : 每个线程循环的次数
- 延迟创建线程直至需要 : 线程发送请求前,临时创建
- 调度器 : 持续时间和启动延时的开关
- 持续时间 : 当前请求持续发送的总时间(可以溢出),受爬坡时间影响
- 启动延迟 : 指定n秒后再启动线程发送请求
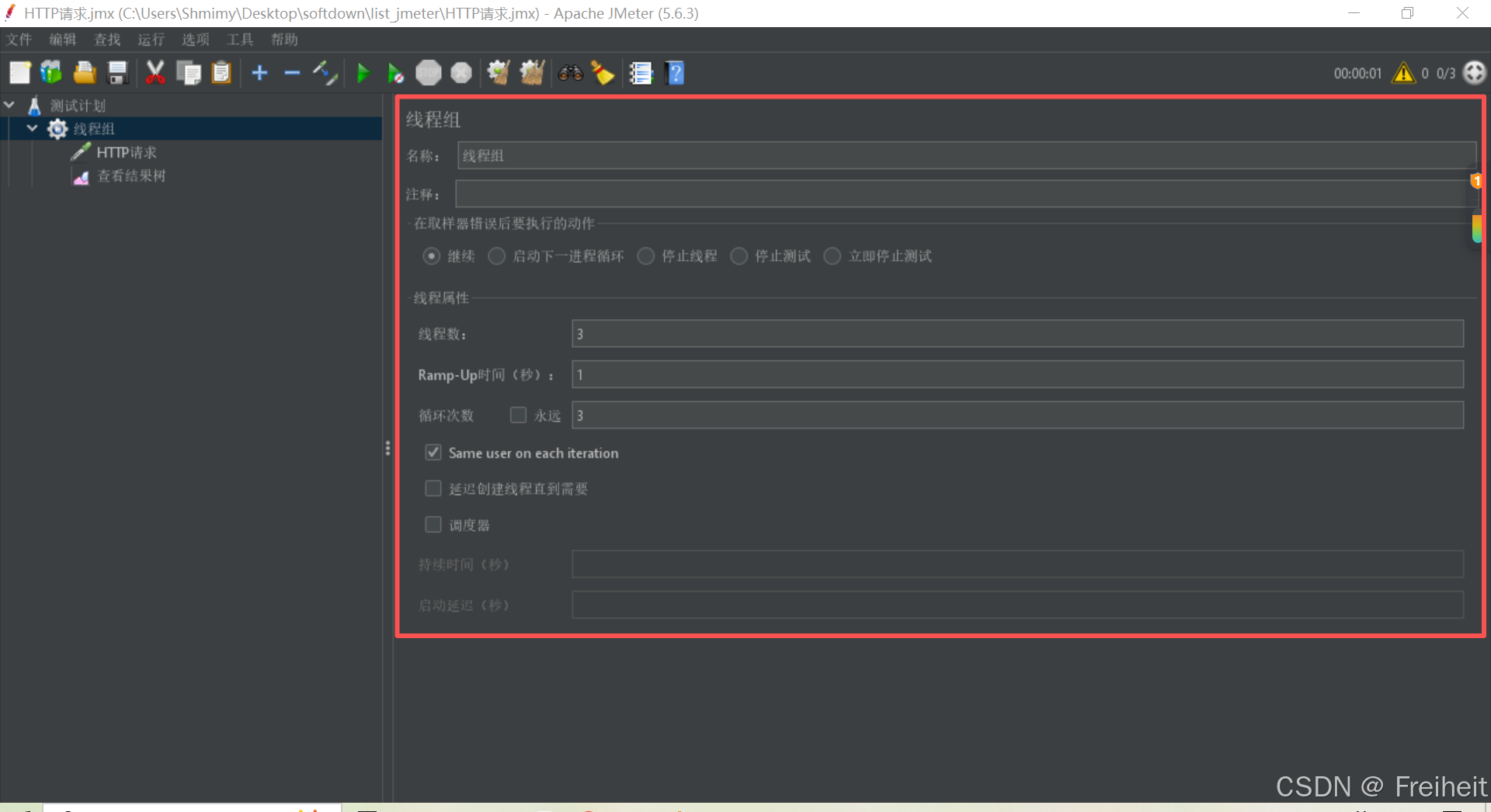
- 步骤 : 在测试计划 --> 线程组 --> 添加http请求 --> 添加监听器 --> 查看结果树
- 取样器:
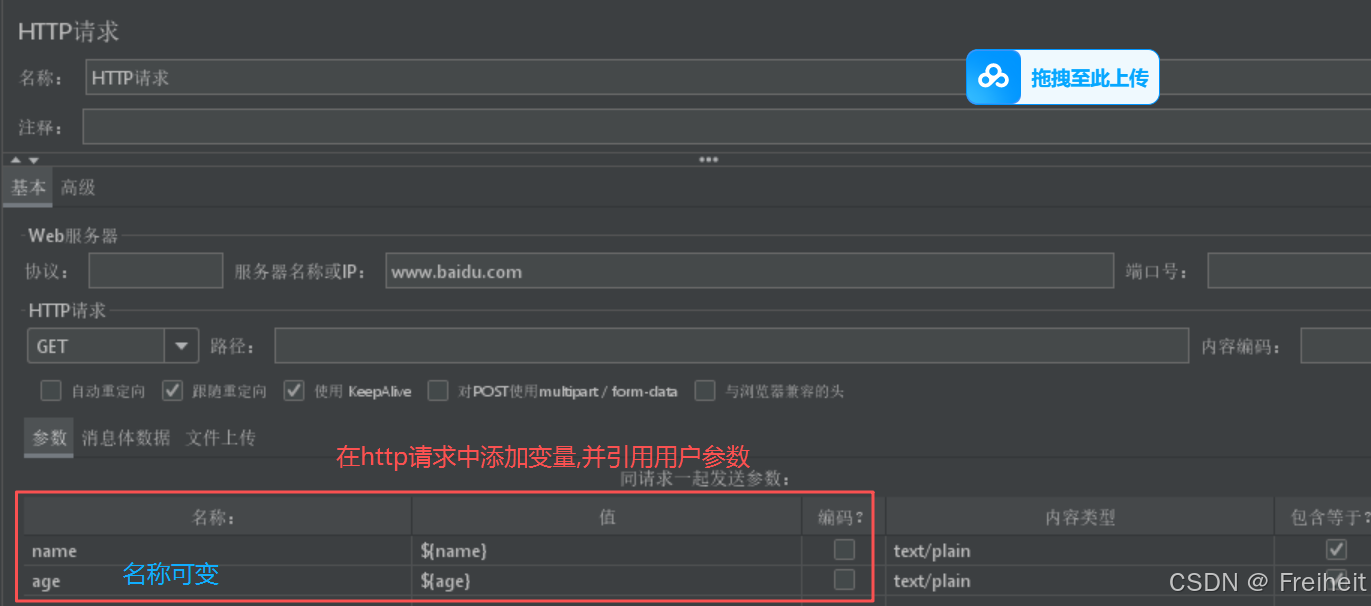
- 在http请求页-参数:
- get请求:参数值会作为URL中的查询参数使用
- 非get请求 : 会作为请求体中的数据,数据类型为x-www-form-urlencoded表单类型
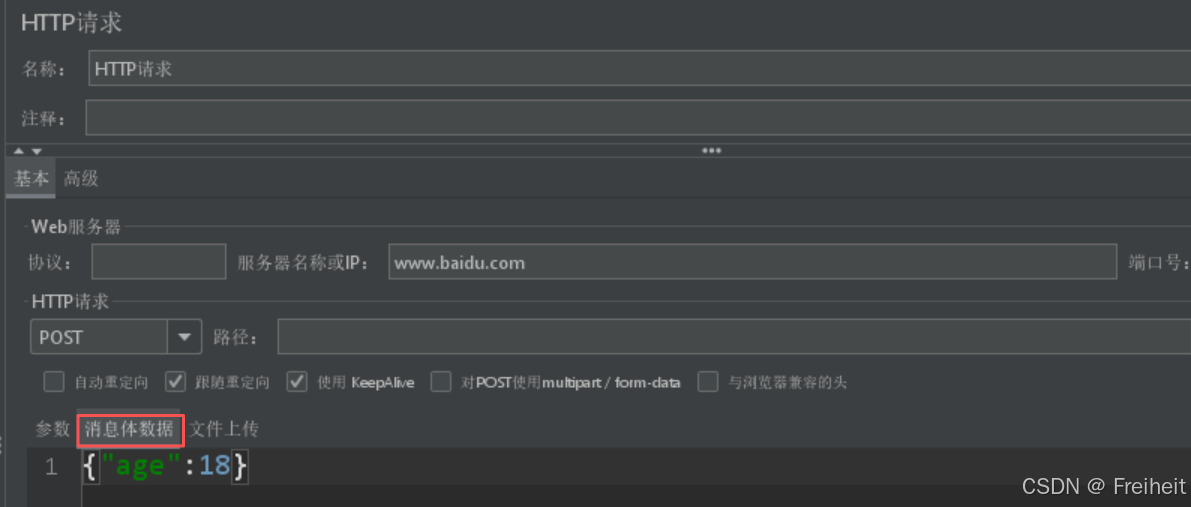
- 在http请求页-消息体数据中:
- 设置json数据类型请求体数据,如{“age”:18}
- 需要给线程添加"http信息头管理器"
- 在http请求管理器当中添加content-type对应值为application/json
- 设置json数据类型请求体数据,如{“age”:18}
- 在http请求页-参数:

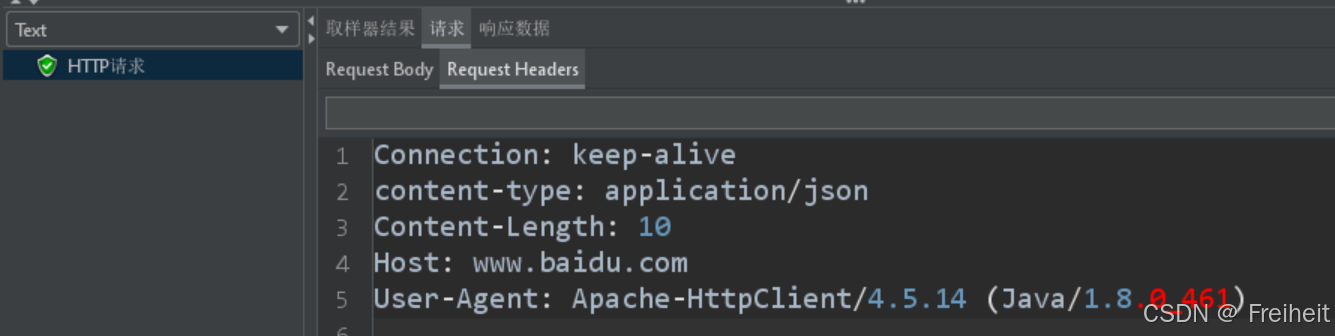
- 查看结果树:
- 取样器结果可以查看到响应状态码,请求中可以看到请求头和请求体
- 可以修改显示格式text/json等
参数化
- 分类:
- 用户定义变量
- 用户参数
- CSV Data Set Config
- 函数
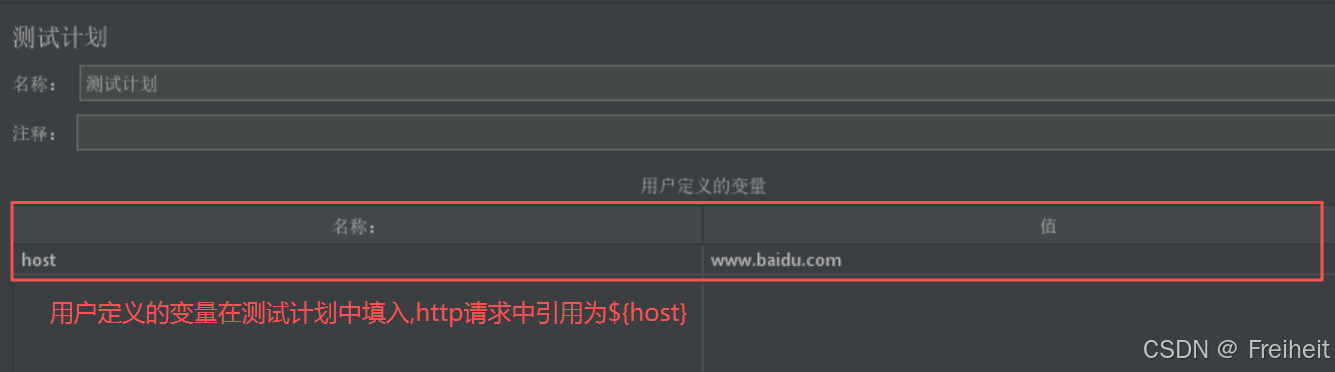
- 使用用户定义的变量,访问百度首页
- 设置变量 : 写入键值对,引用时写入${变量名}
- 应用场景 : 多个请求 , 使用相同的公共数据时,使用用户定义的变量

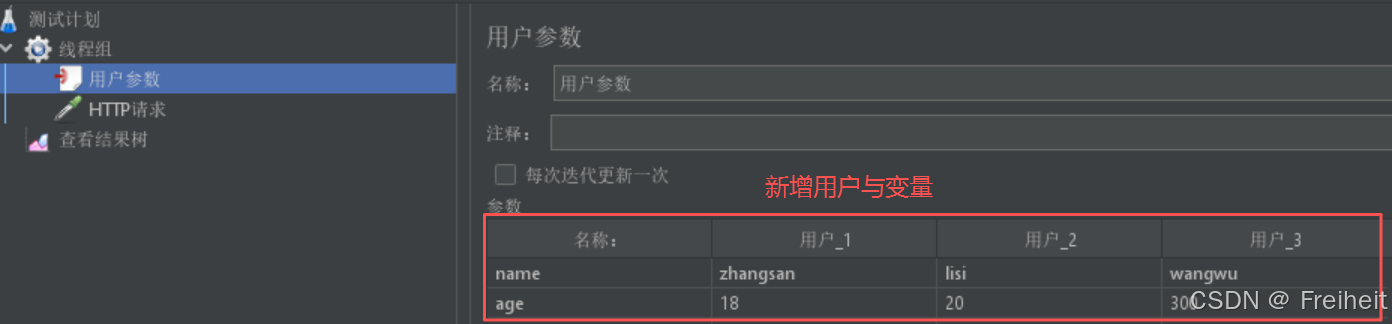
- 用户参数
- 请求百度首页,3个用户访问,要求每个用户携带不同的姓名和年龄
- 步骤 : 线程组 -> 前置处理器(用户参数)
- 在测试计划添加线程组,http请求,查看结果树
- 在线程组上修改线程组为3, 再添加前置处理器-用户参数
- 添加三个用户,给用户设置对应的值
- 在http请求中,使用值
- CSV Data
- 实现 : 访问百度首页,1个用户循环访问3次,每次携带不同的name和age
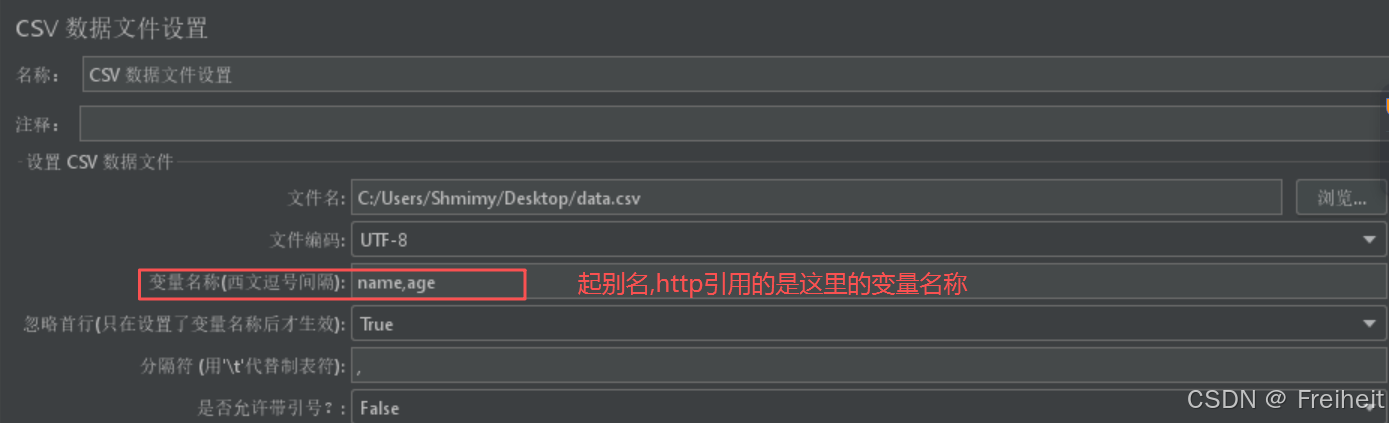
# csv格式 name,age ------------ 第一行为字段名 user01,20 ------------此后每一行都是字段值 user02,30- 步骤 :
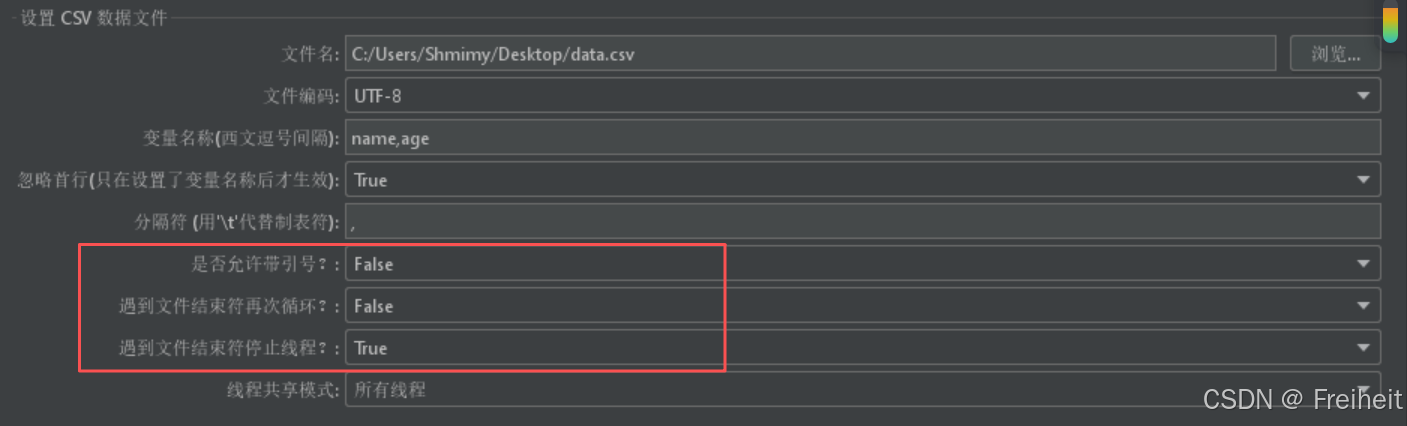
- 测试计划-配置元件(CSV数据文件设置)
- 测试计划->添加线程->http请求-> 查看结果树->设置线程数为->循环次数为3
- 填写csv文件设置内容,文件编码为utf-8,变量名与数据文件中的字段对应,忽略首行改为True

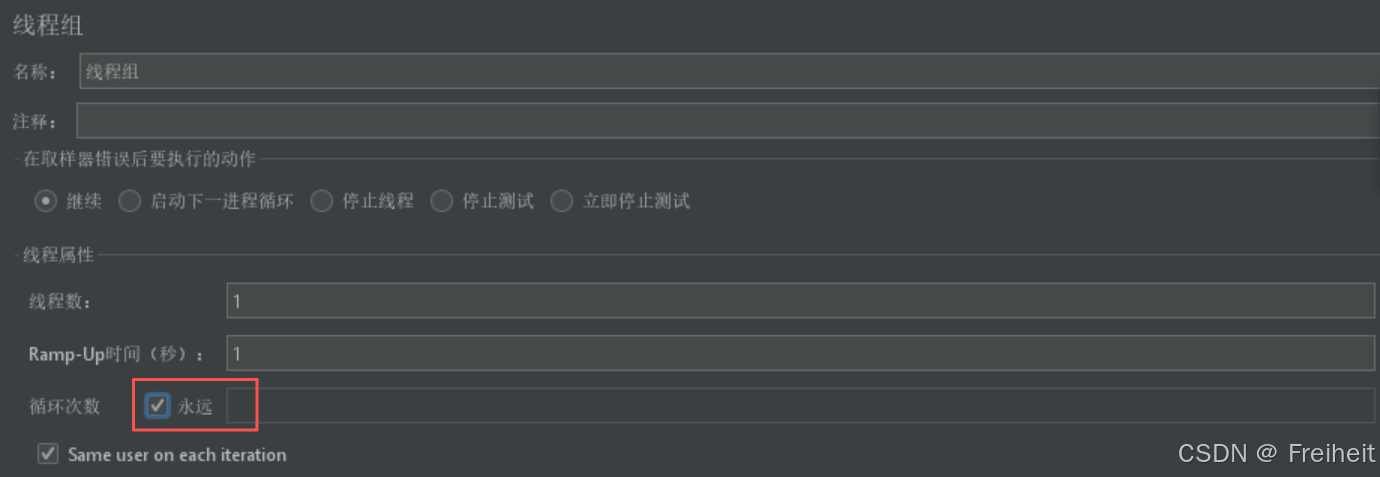
如果遇到不清楚需要开启多少循环次数的文件?
1.修改线程组,循环次数为永远
2.修改csv文件设置的内容遇到文件结束符再次循环设置为False遇到文件结束符停止线程设置为True
计算机中每一个文件,内容结束后都有一个结束标记,文件结束符(用户不可见,计算机可见)
- 应用场景 : 单用户测试,需要使用大量不同的场景,如注册!!
- 计数函数
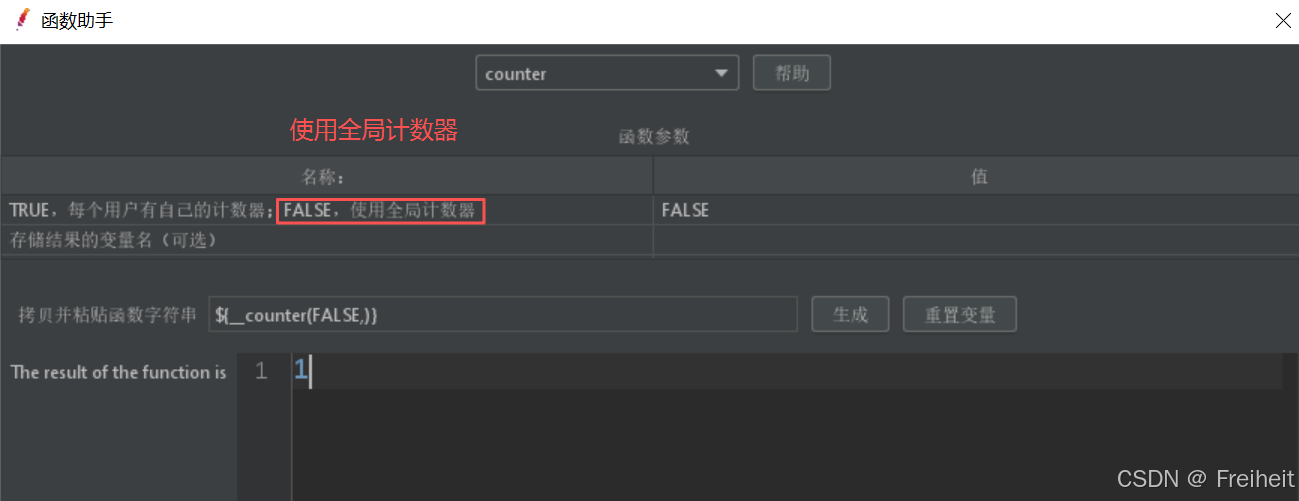
- eg : 给京东发送50次请求,每个请求带有序列号 自己是第几次请求
- 步骤 : 函数助手对话框选择适合的__counter函数
- 做函数相应的设置 (如只需一个计数器,FALSE)
- 粘贴到http请求名称中即可

- 使用京东发送50次请求,每次请求携带序号不同的用户名
- 步骤 : 添加名称和值,在值中使用函数助手
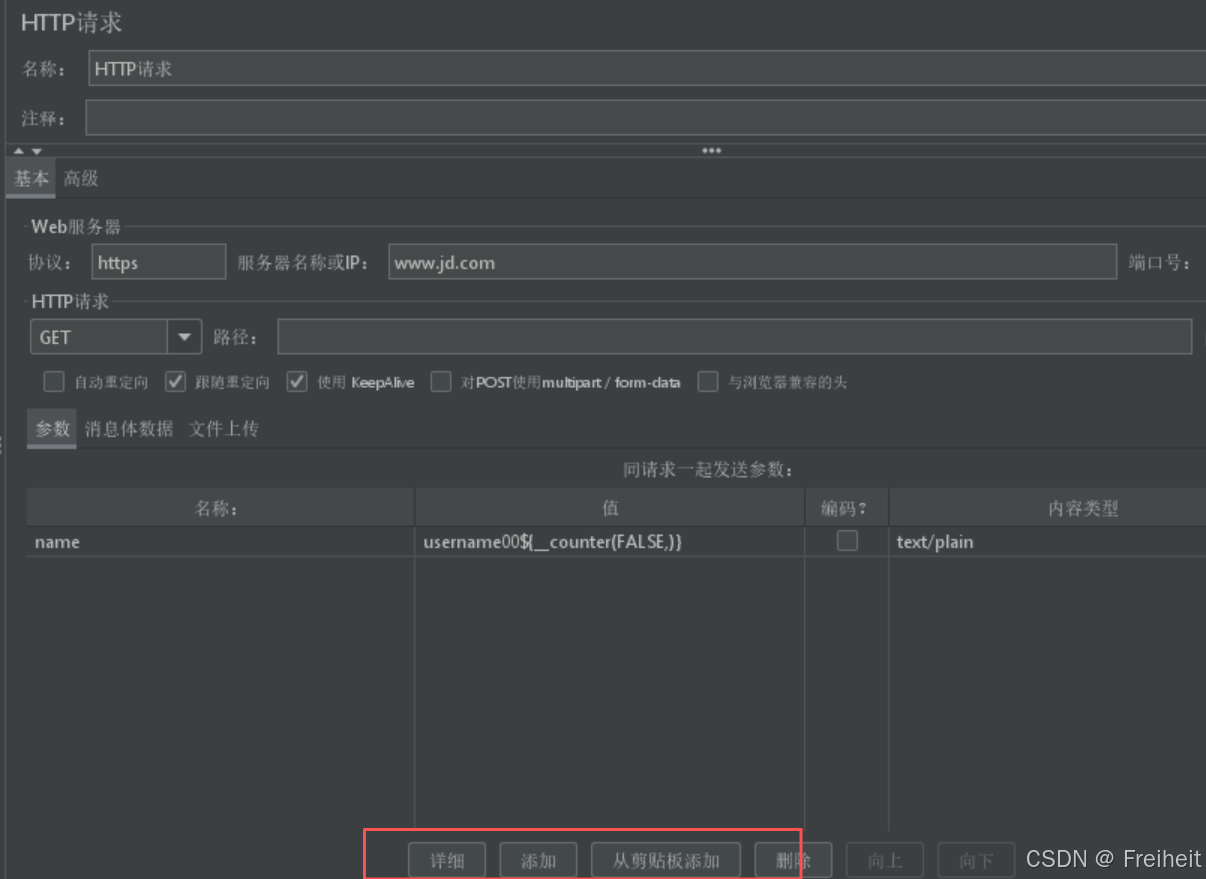
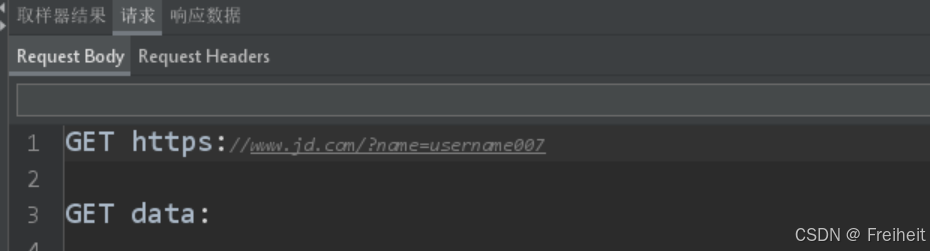
- 应用场景 : 发送请求时需要提供唯一的数据作为请求参数
Jmeter断言
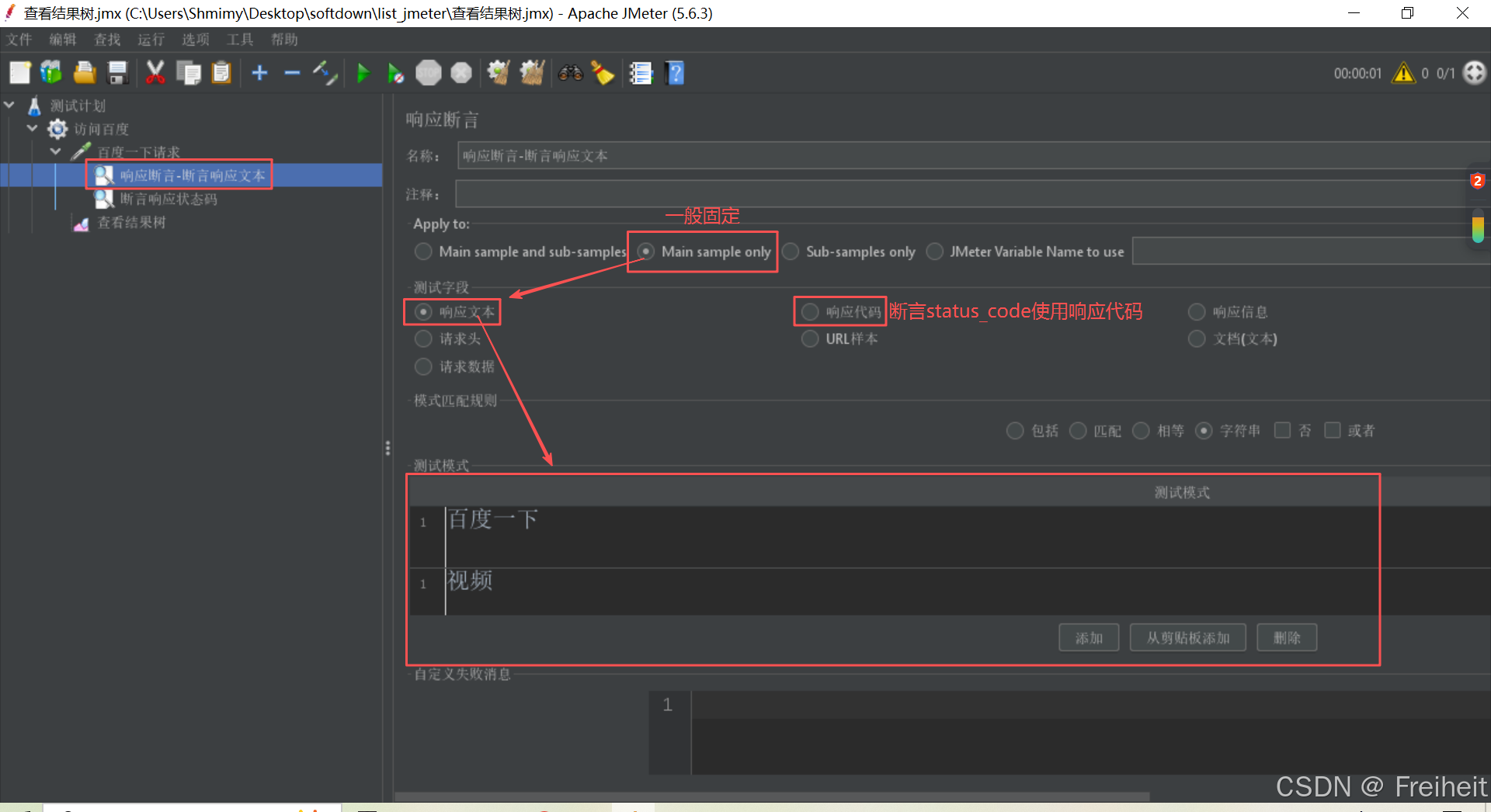
- 响应断言
- jmeter 请求百度,程序检查响应数据中 是否包含 ’ 百度一下 , 你就知道 ’
- 位置 : http请求-断言-响应断言(不同类型断言时 , 多加几个断言)
- 类型 :
- 响应文本 : 断言响应体中包含的字符串(一个响应文本可放置多个字符串关键字)
- 响应状态码 : 断言响应状态码
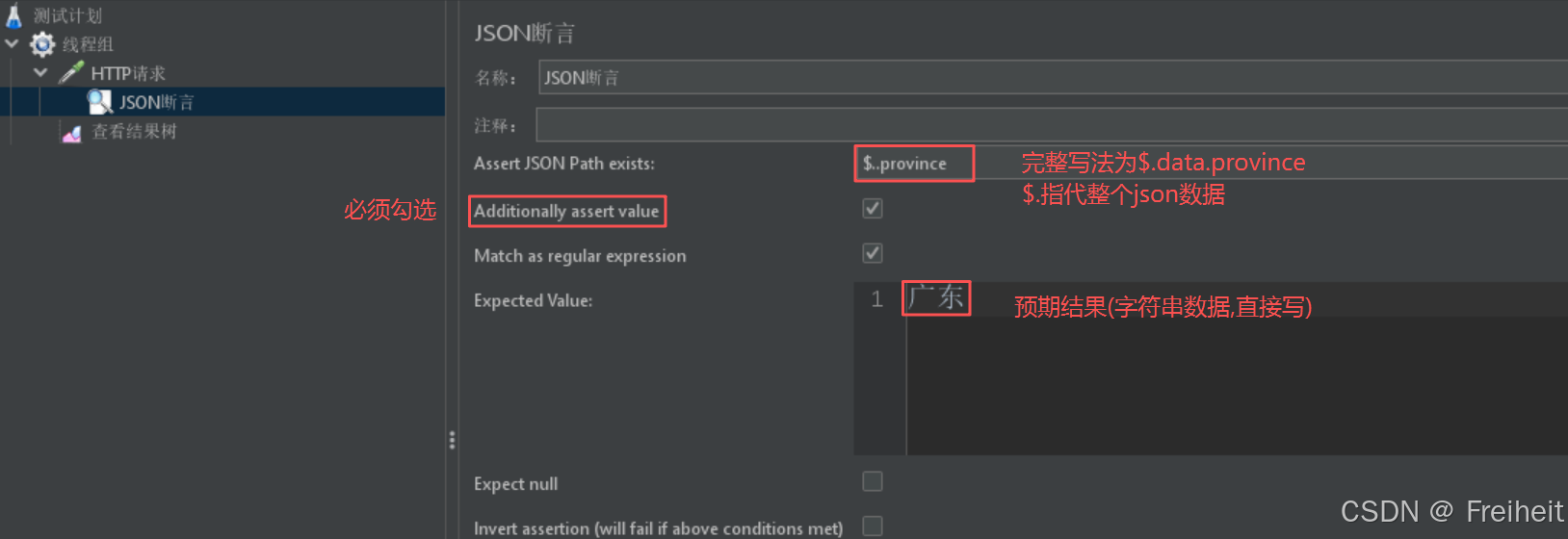
- json断言(需要指定具体某个值时)
- 断言手机号13719717401的归属地为广东
- 说明 : $.代表整个json响应结果
- $.一级键名,二级键名…
- $…N级键名(N是几级,前面应该有几个点)
- 如何选择:
- 响应数据为json数据时,首选json断言
- 否则选择响应断言
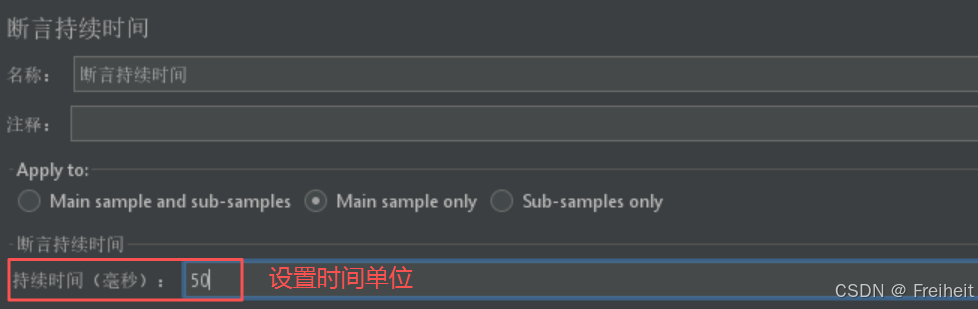
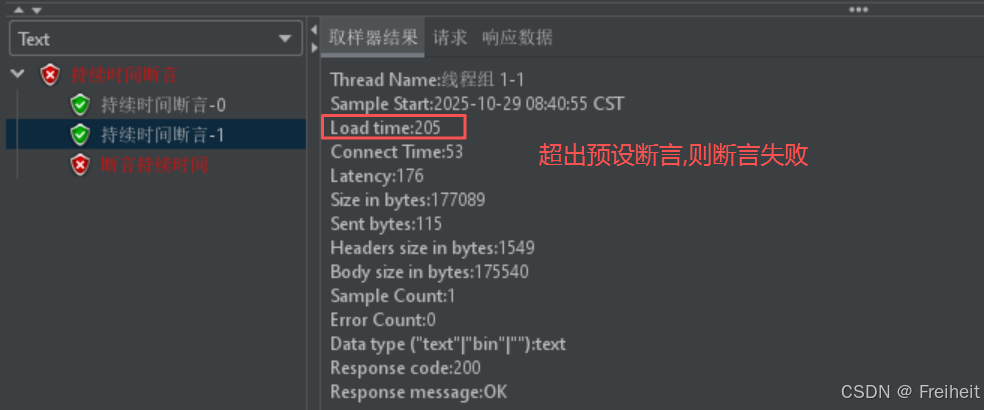
- 持续时间断言(看load time)
- 访问京东页面要求响应时间小于50ms
jmeter关联(解决接口依赖)
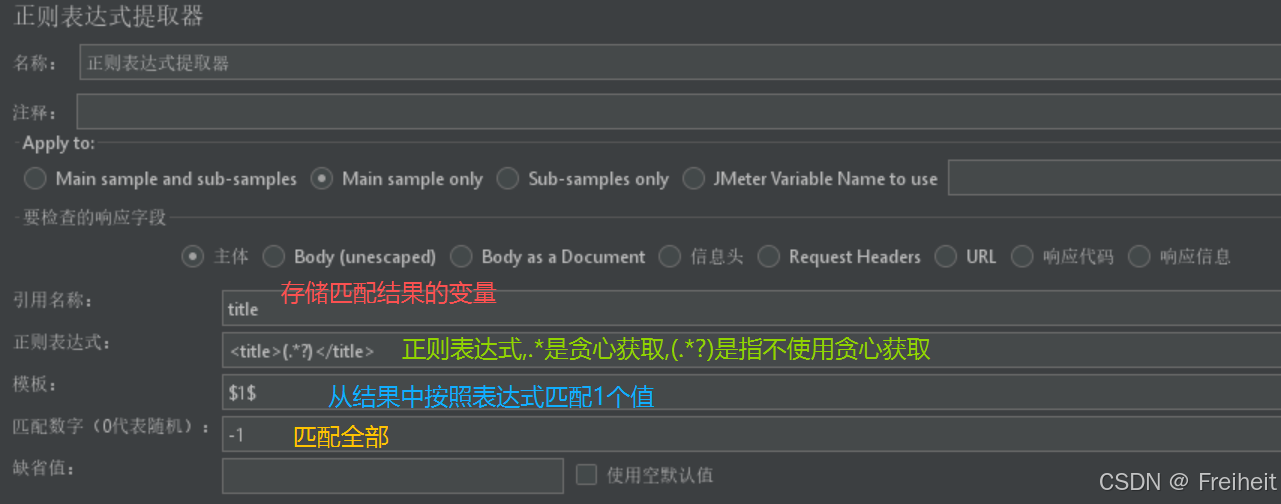
- 正则表达式提取器(从响应文本中按正则表达式提取字符串)
- 步骤 :
- 添加线程组,http请求-itcast(在前),http请求-baidu,查看结果树
- http-请求-itcast -> 后置处理器 -> 正则表达式处理器
- 设置正则表达式提取器
- 引用名称-设置 存储提取到数据的变量名
- 正则表达式
- 模板111,匹配数字-1(代表匹配全部)
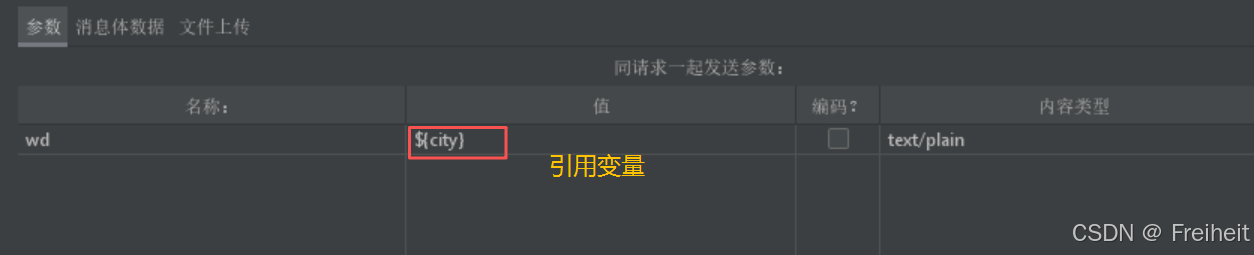
- 使用提取到的数据${变量名}
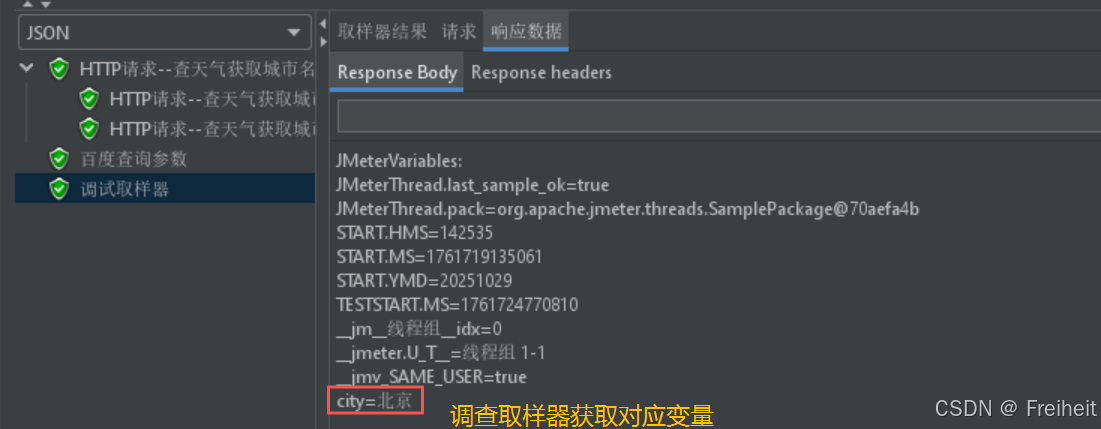
- 看正则表达式的匹配结果,在线程上添加调试取样器,可以在调试取样器中查看变量名
- 步骤 :

-
应用场景 : 请求间有依赖关系,可以用正则表达式从响应结果中匹配数据
-
小结 :
-
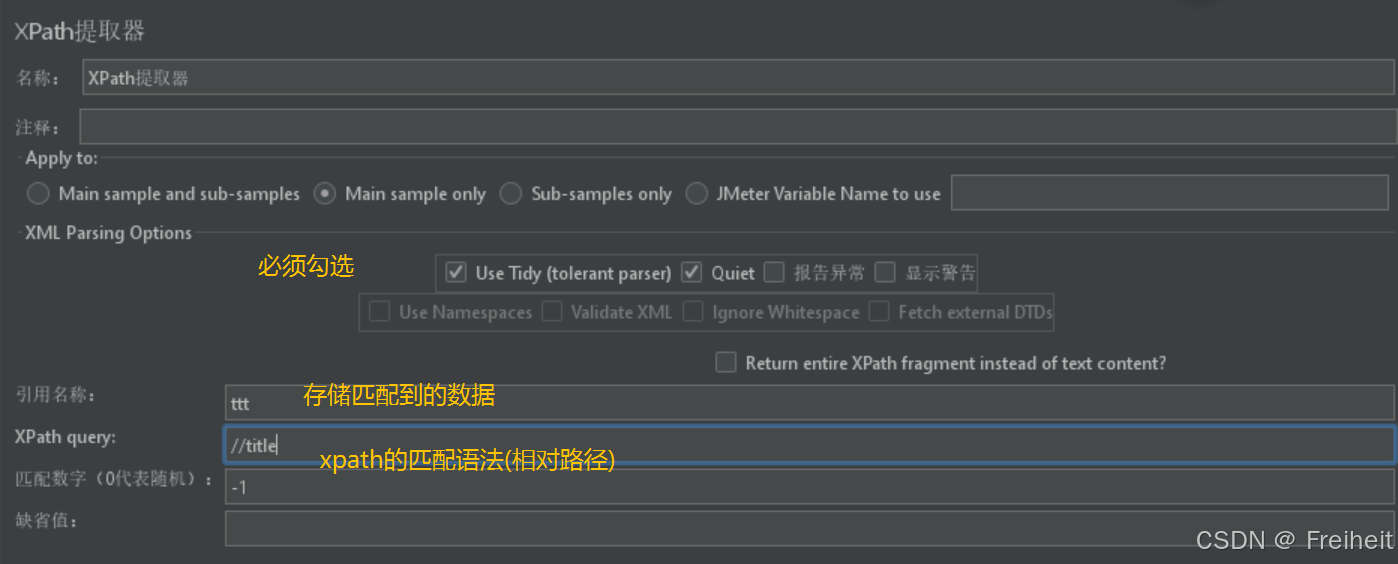
xpath提取器
- x代表xml页面或mhtml页面
- path是按路径匹配
- 位置 : http请求->
-
使用场景 : 请求发送响应结果为xml或html数据时使用
-
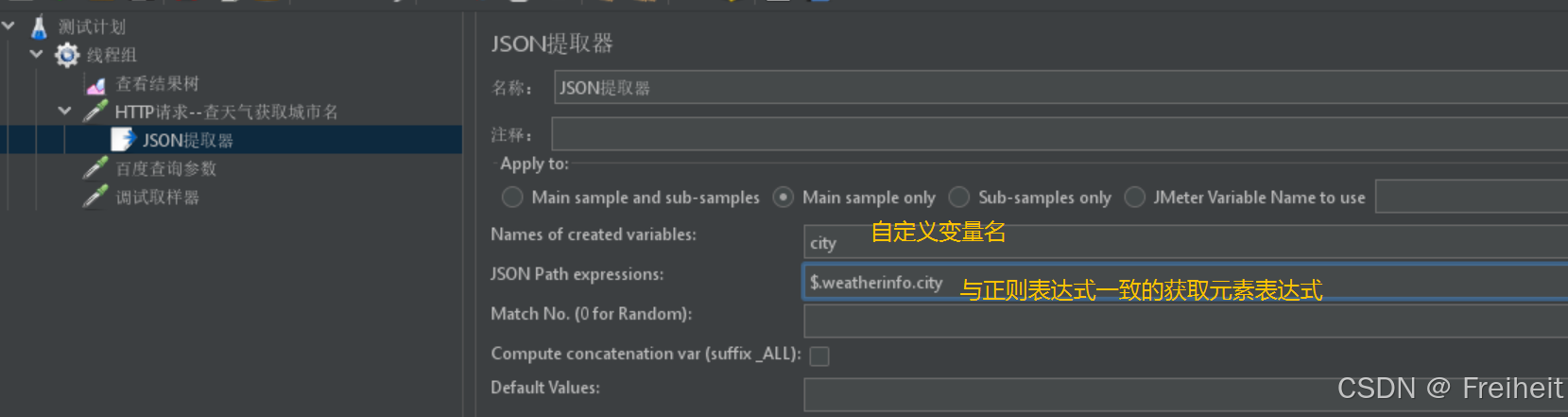
json提取器(发送响应数据为json时用)
- 位置 : http请求-后置处理器-json提取器
- 实现步骤 : 创建线程组,http请求-查天气获取城市名-百度搜索城市名等,查看结果树
- http请求-查天气获取城市名-后置处理器-json提取器
- json提取器设置 : 变量名(保存的json数据),提取表达式($.代表整个json结果)
- 在百度搜索中,使用${变量名},使用提取到的数据
- 应用场景 : 发送http请求时,返回结果为json数据,则使用json提取器
- 跨线程组使用变量
- 说明:
- 在jmeter中,线程组内定义的变量,默认不能跨线程组使用
- 也没有所谓的全局/环境变量
- 实现原理:
- 将A线程组内的变量当作属性设置到jmeter配置文件jmeter.properties中
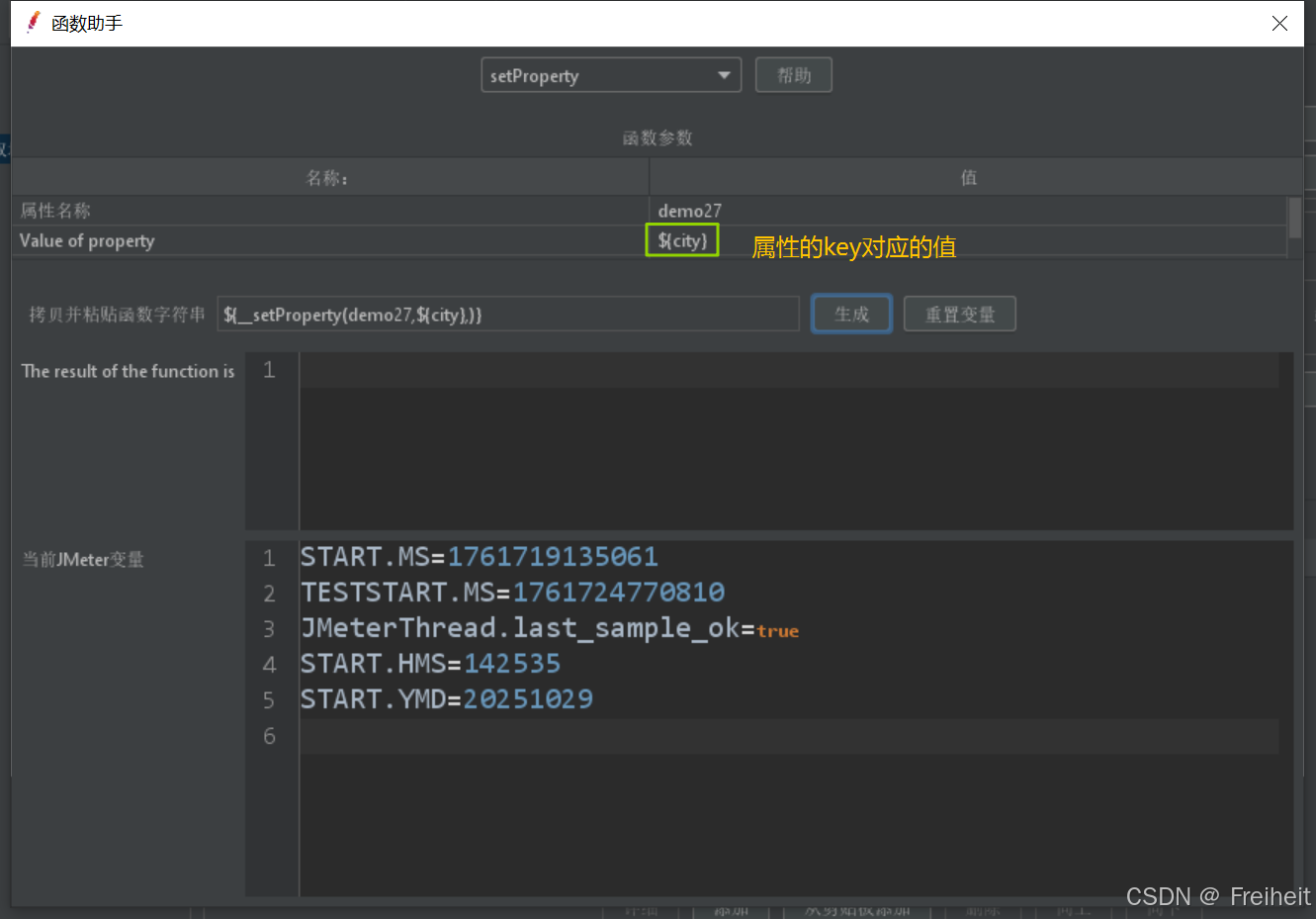
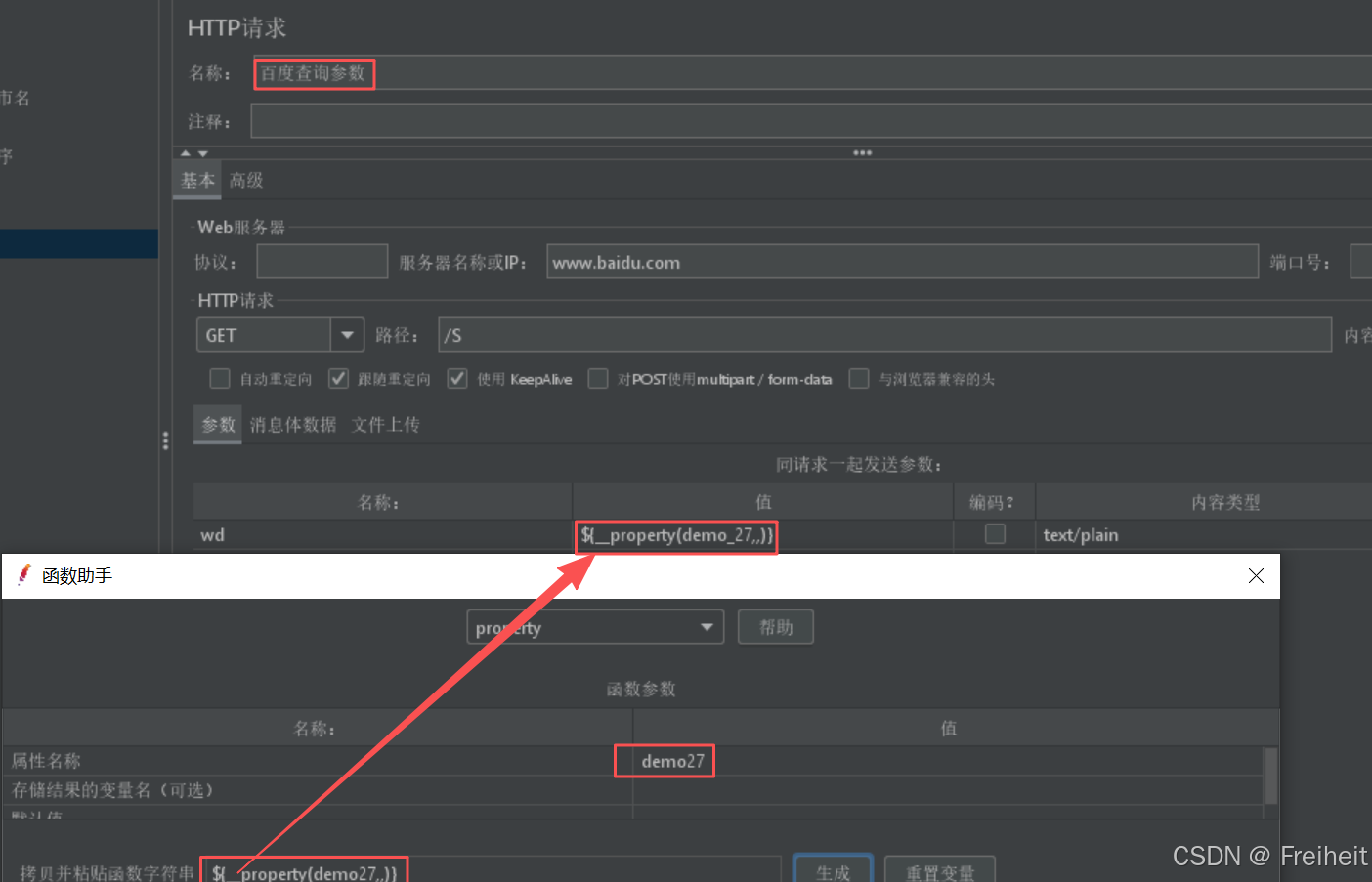
- 使用函数__setProperty
- B线程组中,从jmeter配置文件中读取属性
- 使用函数__Property
- 将A线程组内的变量当作属性设置到jmeter配置文件jmeter.properties中
- 说明:
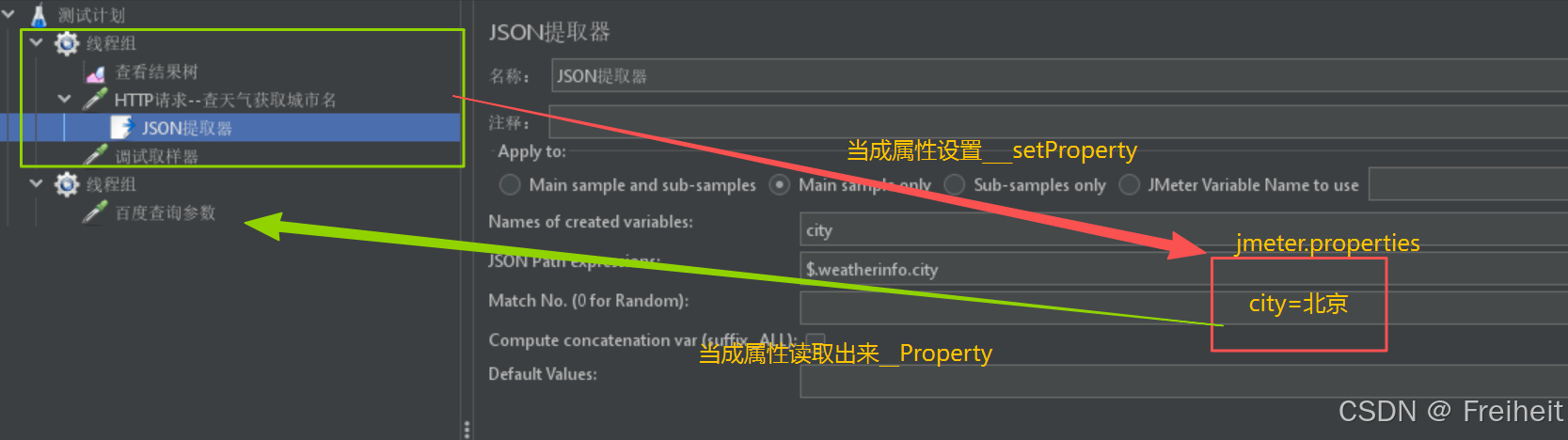
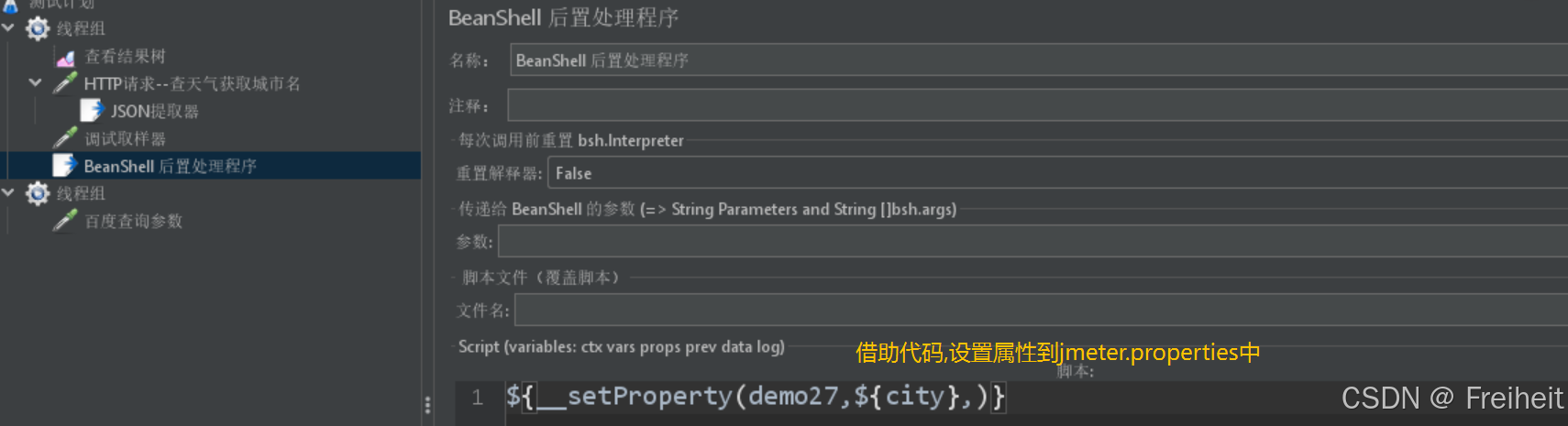
注意BeanShell必须要在http请求下,才可以在查看结果树中调试找到对应的值
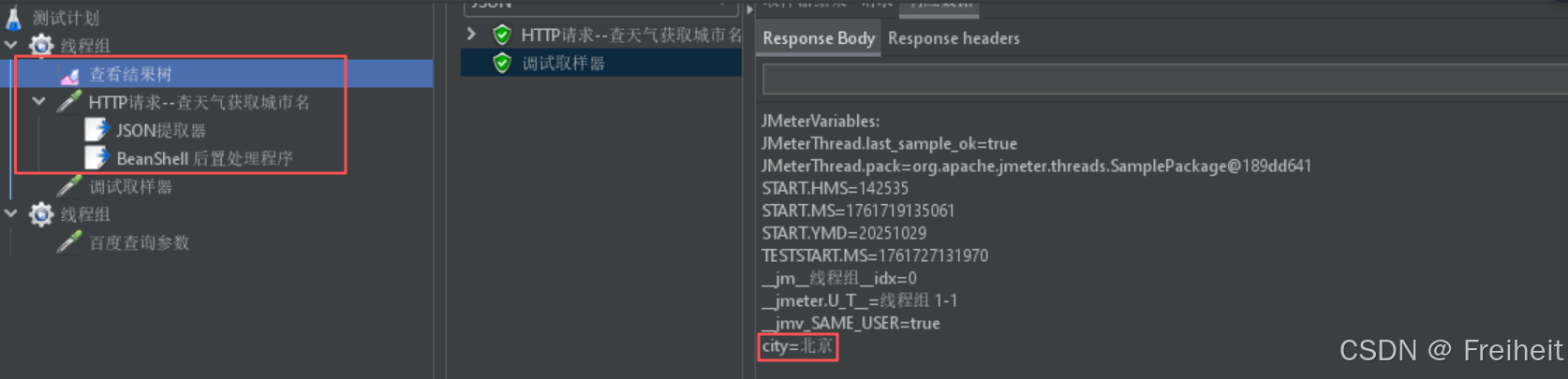
借助函数读取属性
-
步骤:
- 测试计划中勾选独立运行每个线程组(按顺序执行)
- 创建线程组1发送请求查天气,获取城市名,使用json提取器提取城市名保存在city变量中
- 创建线程组2,发送请求使用城市名
- 借助函数,使用setproperty生成设置属性的代码
- 将属性代码写入beanshell中(在http请求下)
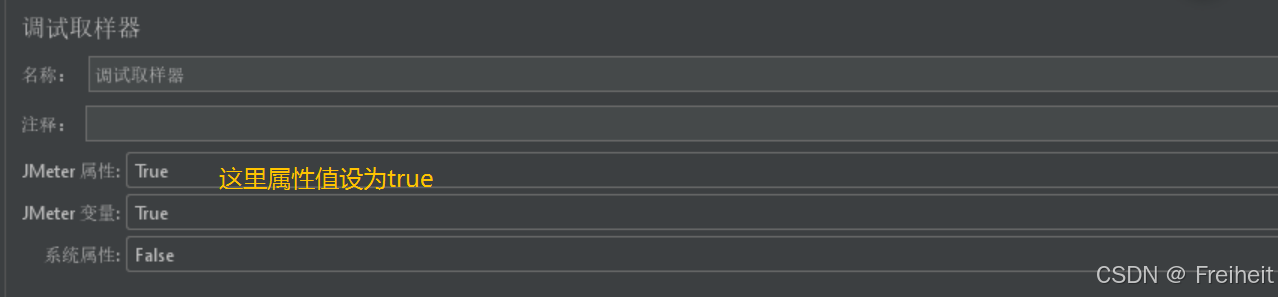
- 添加调试取样器去查看
- 修改jmeter的属性为True,查看
- 使用函数助手,使用__property函数,生成获取属性的代码
- 将代码写入百度http请求当中
-
jmeter录制脚本(了解)
- 步骤
- 创建测试计划,添加线程组,添加非测试原件-http代理服务器
- 设置http代理服务器,
- 端口号
- 选择自己创建的线程组
- 修改当前系统的代理IP和port
- 回到jmeter中,点击http代理服务器中的启动按钮
- 在弹出的小框中填写提示性信息,操作浏览器访问待测系统
- 步骤
-
目标 :
- 掌握jmeter连接数据库的使用步骤
- 掌握jmeter逻辑控制器和定时器的使用
连接数据库
- 为什么连接数据库?
- 校验测试数据 : 请求发送返回的响应数据中没提到数据库中变化的数据(没办法用断言),断言使用的预期结果,直接从数据库中获取.
- 构造测试数据 :
- 发送请求时,使用的数据需要数据库构造
- 数据只能使用一次时
- 清理测试数据(脏数据)
- 连接数据库步骤?
- 添加数据库驱动(jar包)
- 配置数据库连接池 属性(IP,port,用户名,密码,数据库名)
- 发送jdbc请求 (执行sql语句)
- 实现数据库驱动?
- 临时设置
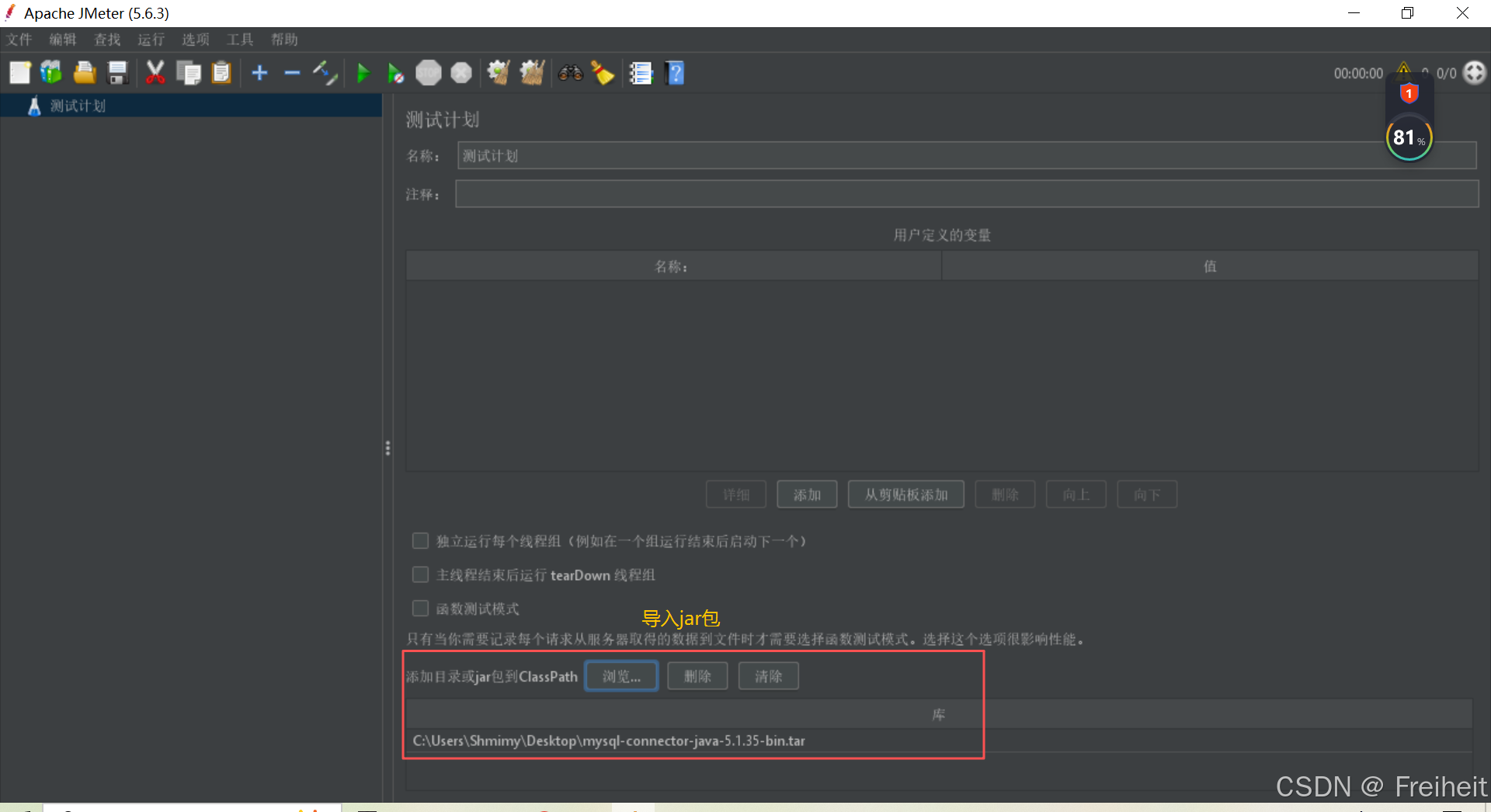
- 永久设置 : 将jar包放到apache/bin目录中
- 临时设置
- 配置连接池属性 :
配置原件 -> JDBC Connection Configuration
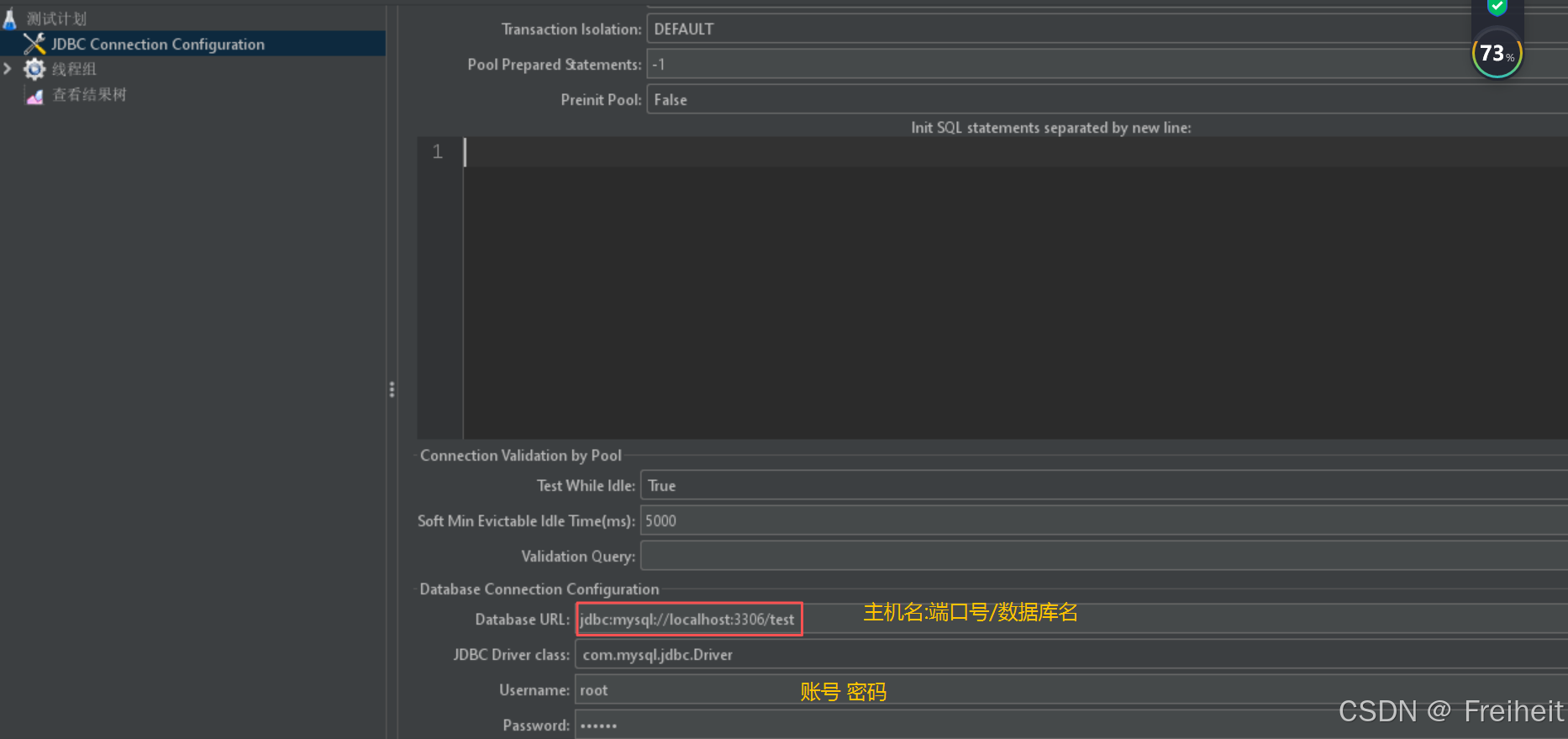
- 配置内容 :
- Database URL : jdbc:mysql://ip地址:端口号/数据库名
- JDBC Driver class : com.mysql.jdbc.Driver(从下拉列表中选)
- 用户名密码自己写
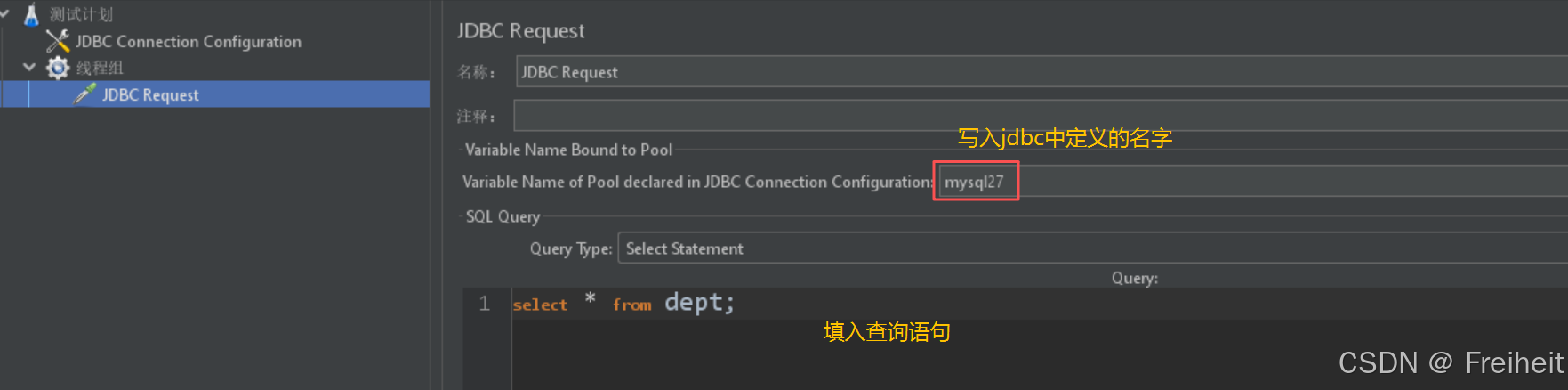
- 添加JDBC请求
- 添加线程组 -> 取样器 -> JDBC Request
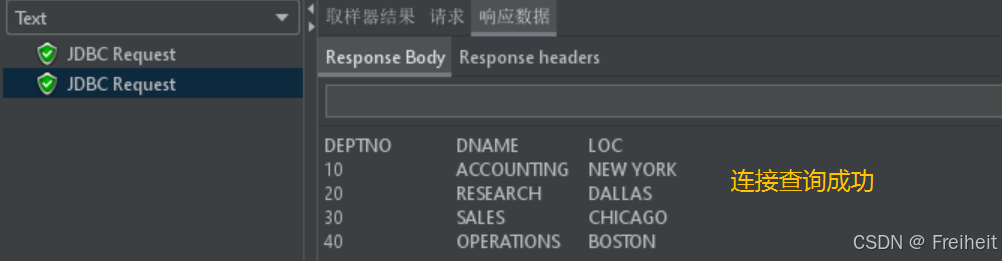
逻辑控制器(通过判断,执行分支循环等,改变脚本执行流程)
- 如果(if)控制器
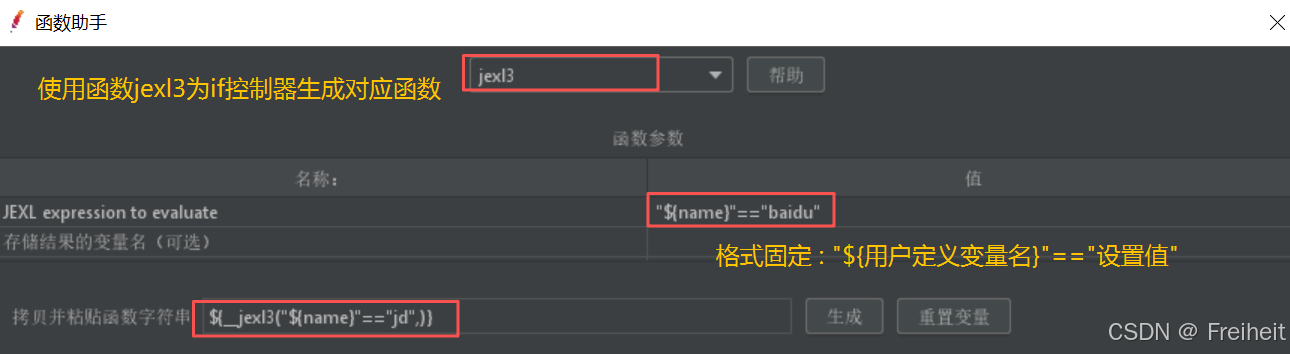
- 使用用户定义变量,定义name变量,值可以是baidu或jd,用变量值控制是否访问对应网站
- 线程组-逻辑控制器-if 控制器(内部放http请求)
- 使用函数设置if控制器中的参数,并将代码写入控制器中
- 使用用户定义变量,定义name变量,值可以是baidu或jd,用变量值控制是否访问对应网站

- 循环控制器
- 在一个线程中,请求50次百度,1次京东
- 步骤 : 逻辑控制器 -> 循环控制器 -> http请求为子集(可在聚合报告查看总量)
- 在一个线程中,请求50次百度,1次京东


- 仅一次控制器
- 逻辑控制器-仅一次控制器,不受线程组属性影响循环次数影响,放子集只运行一次

- 逻辑控制器-仅一次控制器,不受线程组属性影响循环次数影响,放子集只运行一次
- 事务控制器
- 事务 : 对应系统中的业务,一个事务中可以有一个/多个请求
- 当需要将多个请求当作一个请求看待时,需要业务控制器,eg : 登录,搜索,下单,支付
- 步骤 : 逻辑控制器 -> 事务控制器,将请求添加到事务控制器中,勾选generate添加聚合报告

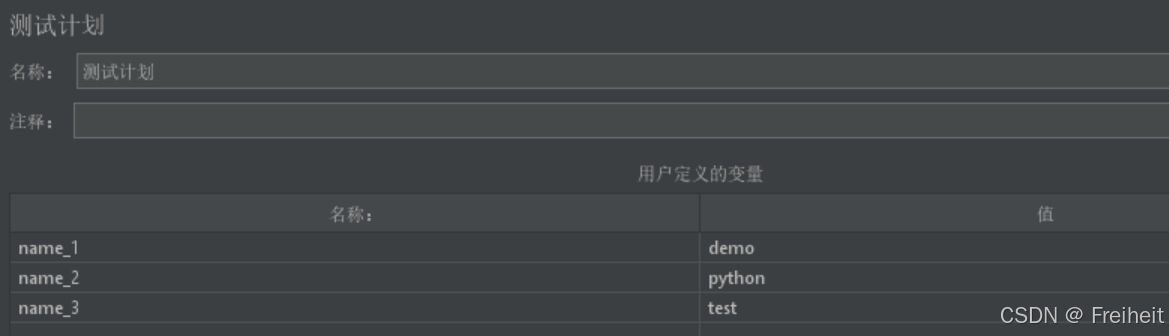
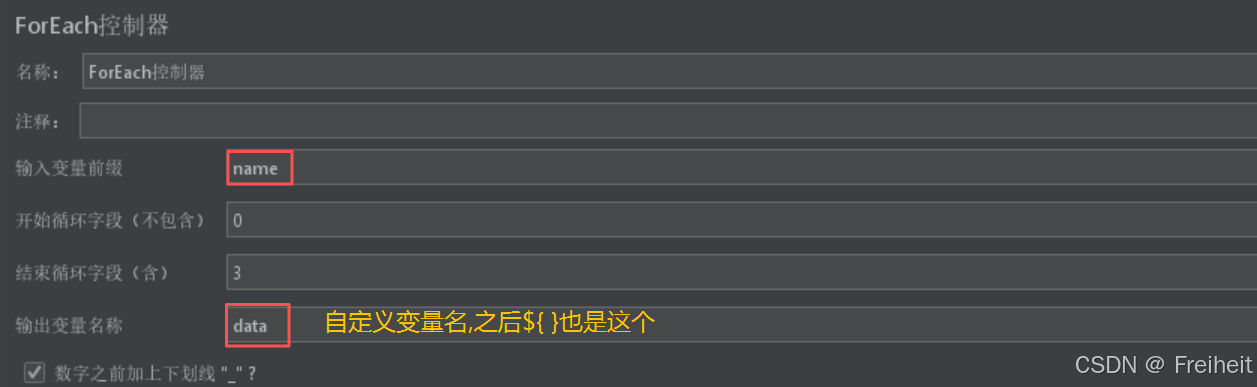
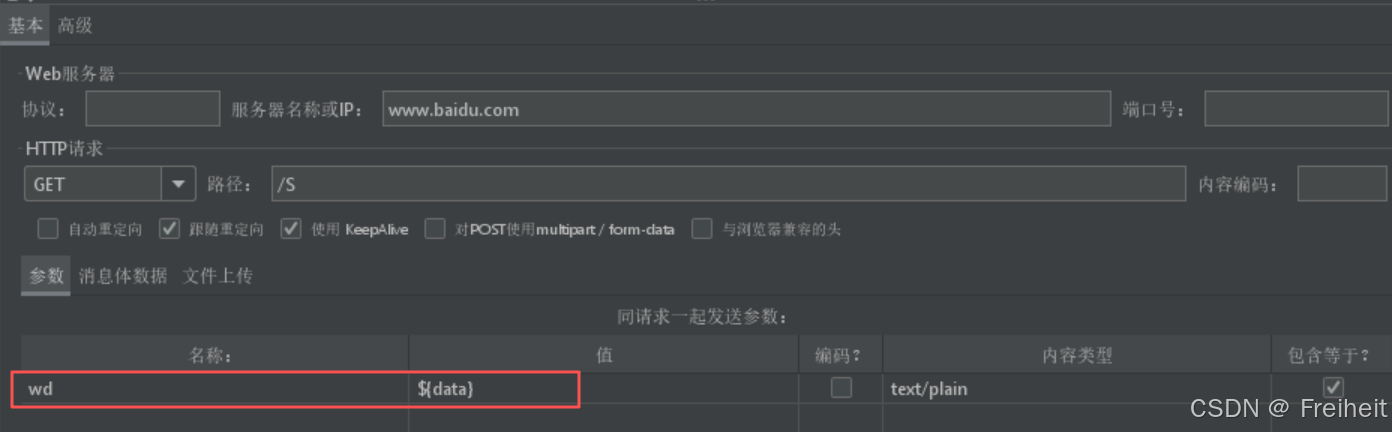
- ForEach控制器(便利,对应for in)
- 一组关键字[demo,python,test],使用用户定义的变量,存储并依次取出,交给百度搜索
- 步骤 : 用户定义的变量名中起相同的前缀,填入数值,起始为1则填0,结束为最后一个数字
- 打开foreach控制器填入对应的变量名内容
- 一组关键字[demo,python,test],使用用户定义的变量,存储并依次取出,交给百度搜索
- foreach应用场景 : 需要对一组数据中的数据进行遍历提取
定时器(都是http请求的子集)
- 同步定时器
- 模拟一个时间点上,100个用户瞬时并发访问百度网页
- http请求下添加定时器 -> 同步定时器
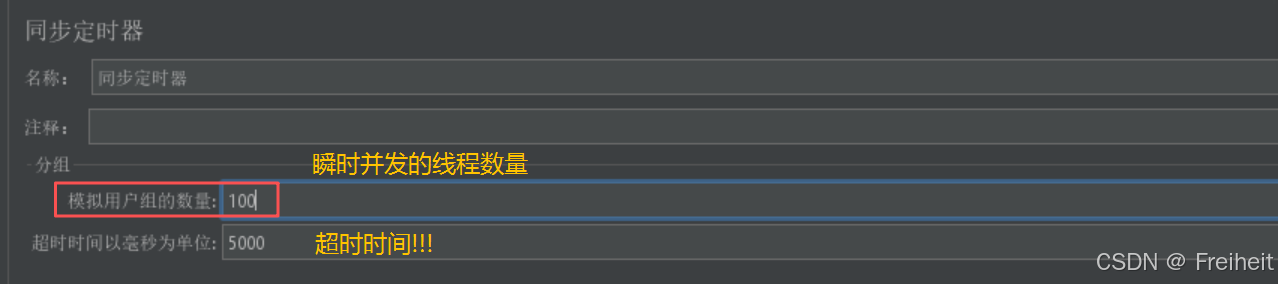
- 注意 : 超时时间必须要设置!!
- 当模拟用户数少于并发线程数时,超时时间到达后会自动发送请求
- 模拟用户数大于并发线程数时,
- 到达设定线程数会自动发送请求(定时时间未到)
- 剩余线程数,在超时时间到达后,自动发送请求
- 常数吞吐量定时器
- 一个用户以20QPS(20次/秒)的频率访问百度首页,持续运行一段时间,统计运行情况
- 位置 : http请求下 --> 定时器 --> 常数吞吐量定时器
- 设置线程组一个线程永久循环查看聚合报告QPS数值
- 作用 : 控制每秒向服务器发送请求的数值
- 目的 : 测试服务器是否能达到预设的QPS值
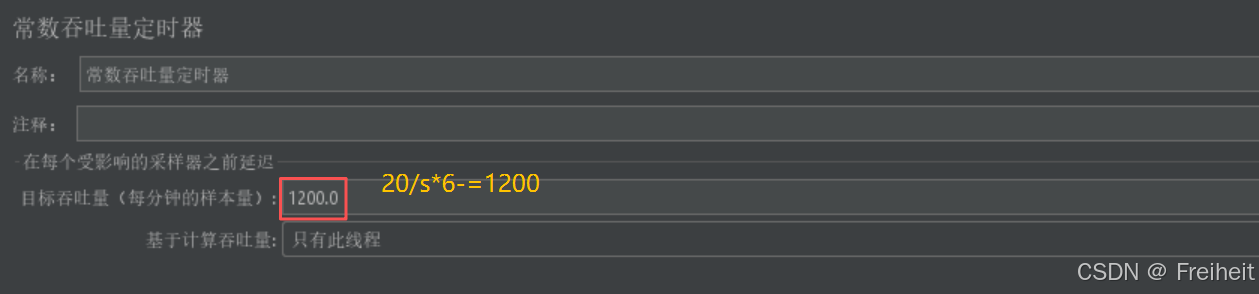
- 思考 : 百度服务器是否能达到80QPS? 不能,最高大约在66-67左右
- 固定定时器
- 位置 : 线程组 - 定时器 - 固定定时器
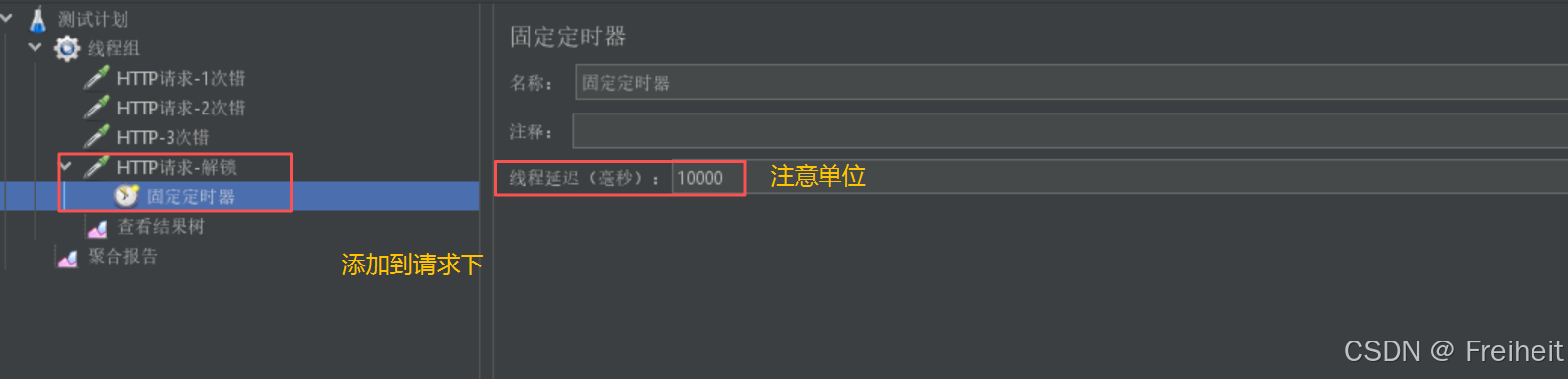
- 实现一个功能可以有多个方法
- 位置 : 线程组 - 定时器 - 固定定时器
- 固定定时器中,与线程组属性中启动延迟功能比,固定定时器更精准(ms),固定定时器可以针对某一个请求定时.
- 掌握jmeter分布式测试的配置使用
- 生成jmeter的测试报告
- 独立安装jmeter常用插件
分布式
- 为什么使用分布式?
- 计算机的硬件配置会在性能测试过程中,成为制约数据设置的 重要瓶颈
- 什么是分布式
- 将一个测试目标,分摊到多个主机上,分开部署执行
- 分布式原理
分布式配置
- 新建分布式测试文件夹,进入文件夹新建执行机和控制机(控制机A和控制机B),将jmeter的安装包分别复制到各个文件中

执行机
- 配置当前代理机的port(272)
- 修改 bin/jmeter.properties文件下server_port
- 禁用SSL(335)
- 修改bin/jmeter.properties文件下server.rmi.ssl.disable=true
控制机
- 配置控制机管理的 代理机的ip和port(258)
- 修改 bin/jmeter.properties文件下remote_hosts值,设置代理机的IP和port,如果有多个ip就逗号隔开
- 禁用SSL
- 修改bin/jmeter.properties文件下设置server.rml.ssl.disable=true


启动执行机A与B
- /bin/jmeter-server.bat启动两个执行机
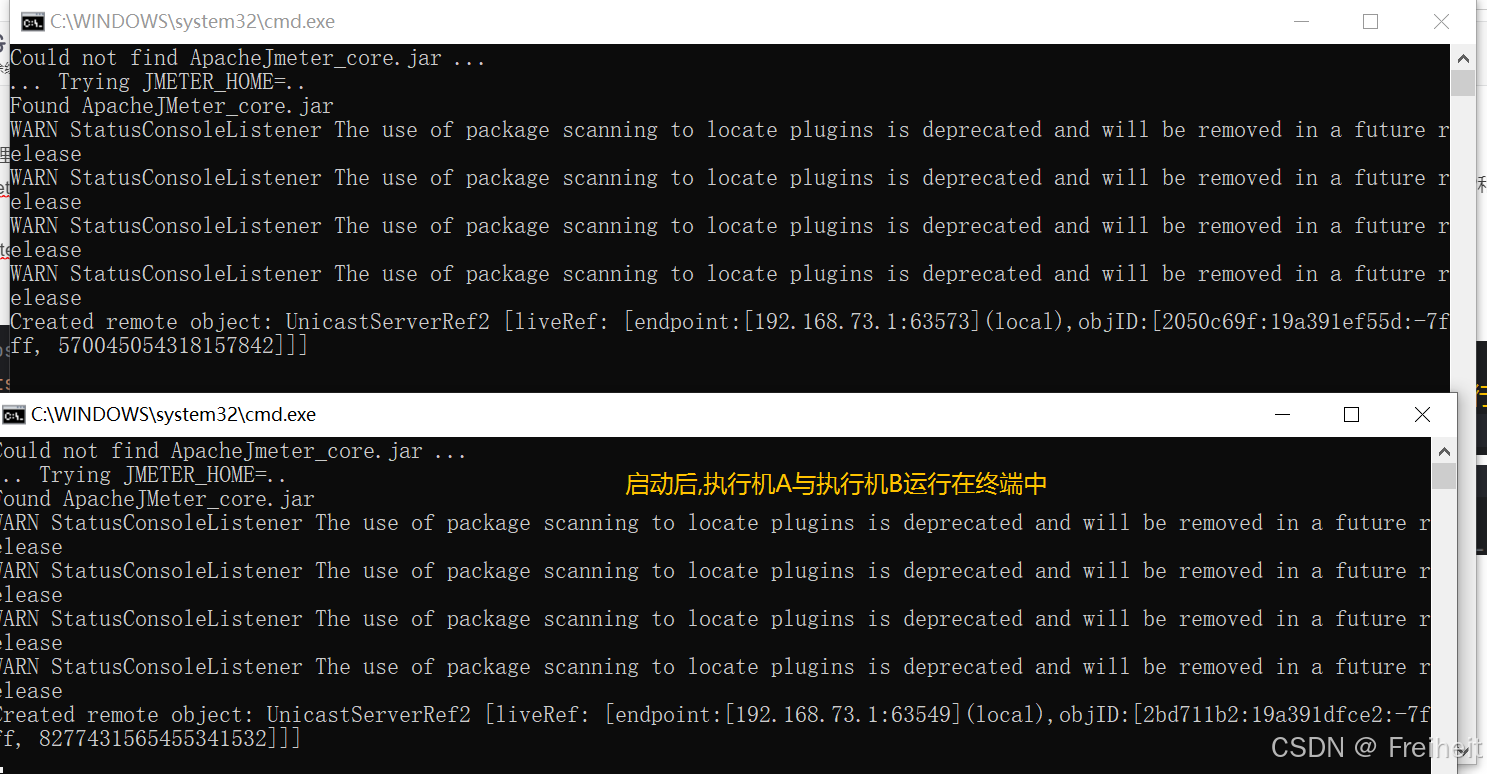
如果报错,则进入jmeter-server文件修改30行RMI_HOST_DEF=-Djava.rmi.server.hostname=127.0.0.1保存,并用管理员身份运行jmeter-server.bat文件
启动控制机
- 配置线程数
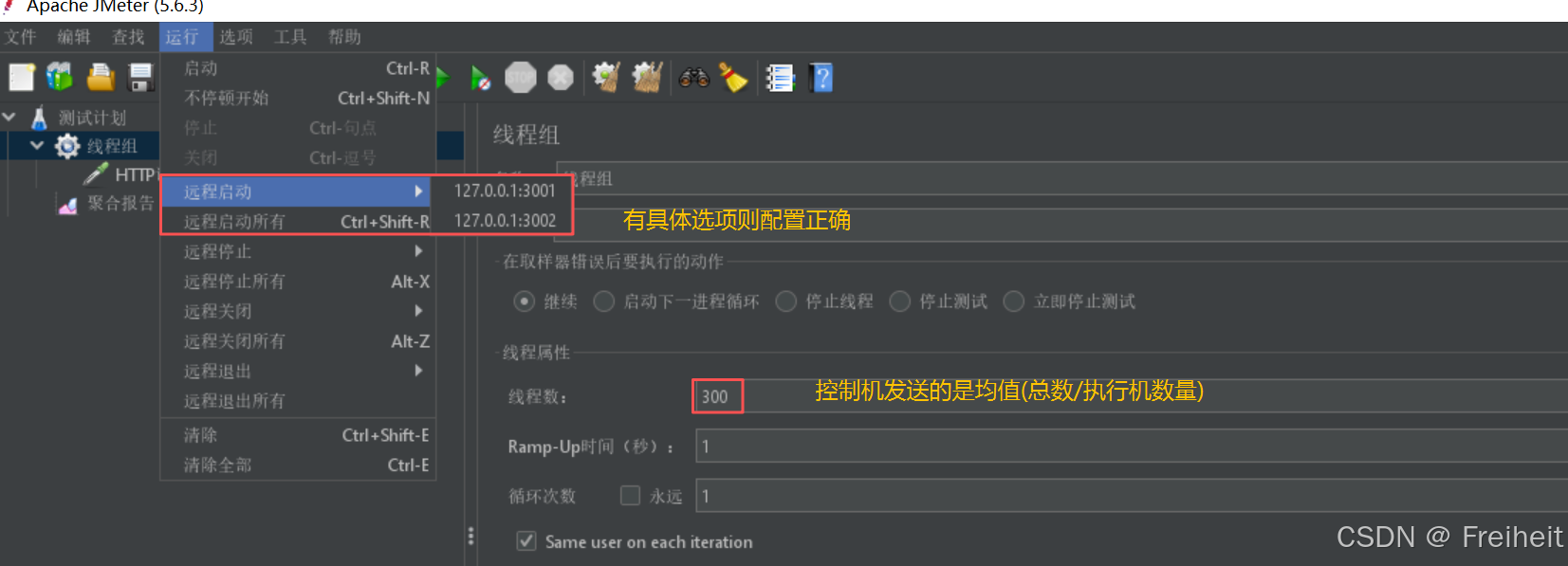
- 运行结果
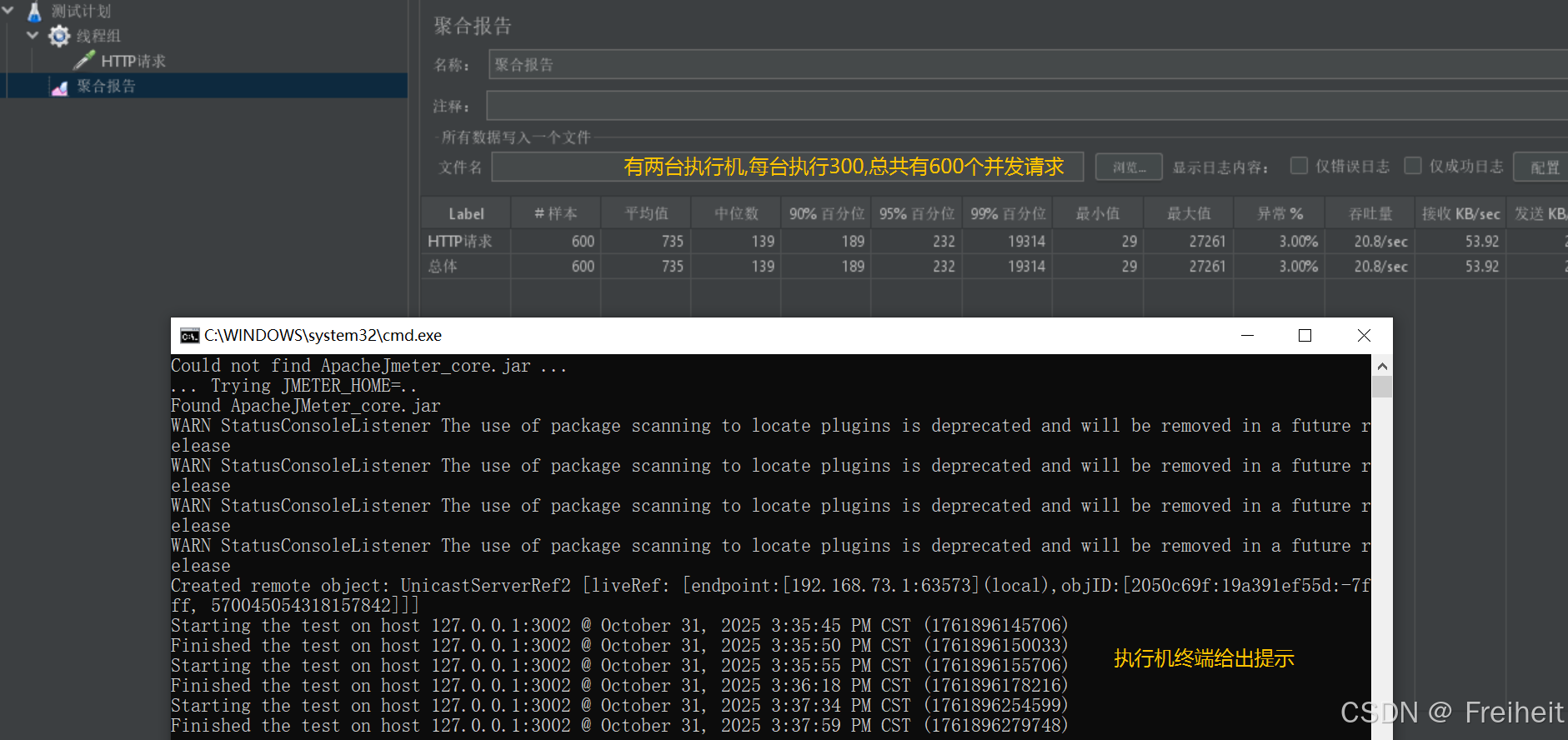
性能测试报告
聚合报告
- 各项指标含义

- label : 样本标签名
- 样本 : 发送请求的数量
- 平均值 : 代表所有请求,发送的平均响应时间,单位ms
- 50%(中位数) : 代表50%请求,发送的响应时间,单位ms
- 90%,95%99% : 代表相对应数值的请求,发送的响应时间,单位ms
- 最小值,最大值 : 最少/最大的 响应时间
- 异常% : 错误请求的比例
- 吞吐量 : 单位时间内,发送到服务器的事务数量(QPS)
- 接收/发送 : 单位时间内,接收/发送请求的速率
- 性能重点关注指标
- 样本,平均值,95%,异常,吞吐量
- 导出聚合报告
- 保存表格数据,生成的是csv数据文件

- 保存表格数据,生成的是csv数据文件
html报告
jmeter -n -t [jmx file] -l [result file] -e -o [html report folder]
- jmeter -n -t hello.jmx -l result.jtl -e -o ./report
- -n : 非GUI格式执行jmeter
- -t [jmx file] : 测试计划保存的路径及.jmx文件名,路径可绝对可相对
- -l [result file] : 保存生成结果的文件,jtl格式
- -e : 测试结束后,生成测试报告
- -o [html report folder] : 存放生成测试报告的路径,可绝对可相对
result.jtl和./report会自动生成,如果在执行时已存在,则需要删除
TPS一般算法
- 核心 指导原则
- 二八原则,80%请求发送再20%的时间内
- 一般计算公式
- TPS = 总请求数80% / 有效的工作时长 3600s * 20%
- 同步并发数
- TPS = (总请求数* 80% / 有效的工作时长* 3600s * 20%) * 3
- OA系统,20w人使用,平均每天使用8h,性能测试并发数多少?
- (200000*80%/5760)*3=83左右
插件安装使用
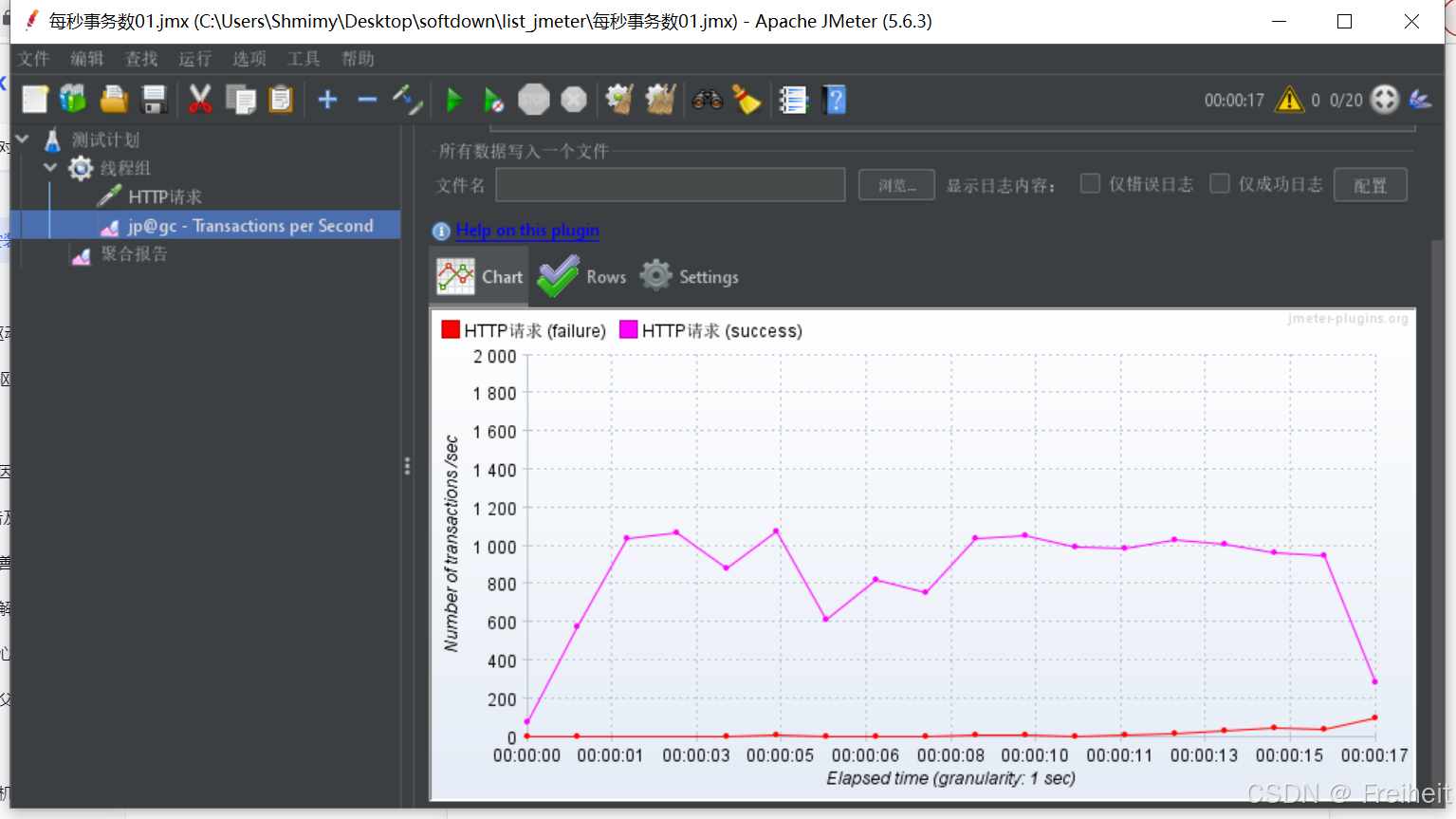
每秒事务数
可实时查看TPS状态
线程组

perfmon工具
- 查看服务器资源利用率(CPU,内存,磁盘,网络等)
- 注意 : 服务器的资源使用情况不能随便查看(需要服务器配合)
- 实现步骤 :
- 在监看的服务器安装,监听服务器资源的工具
- 使用jmeter下的perfmon工具,监听.
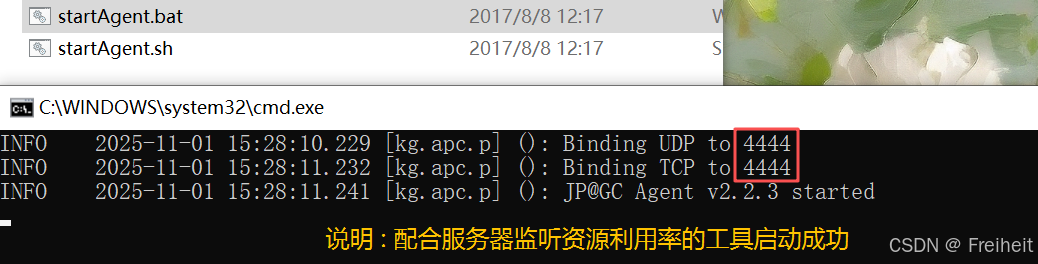
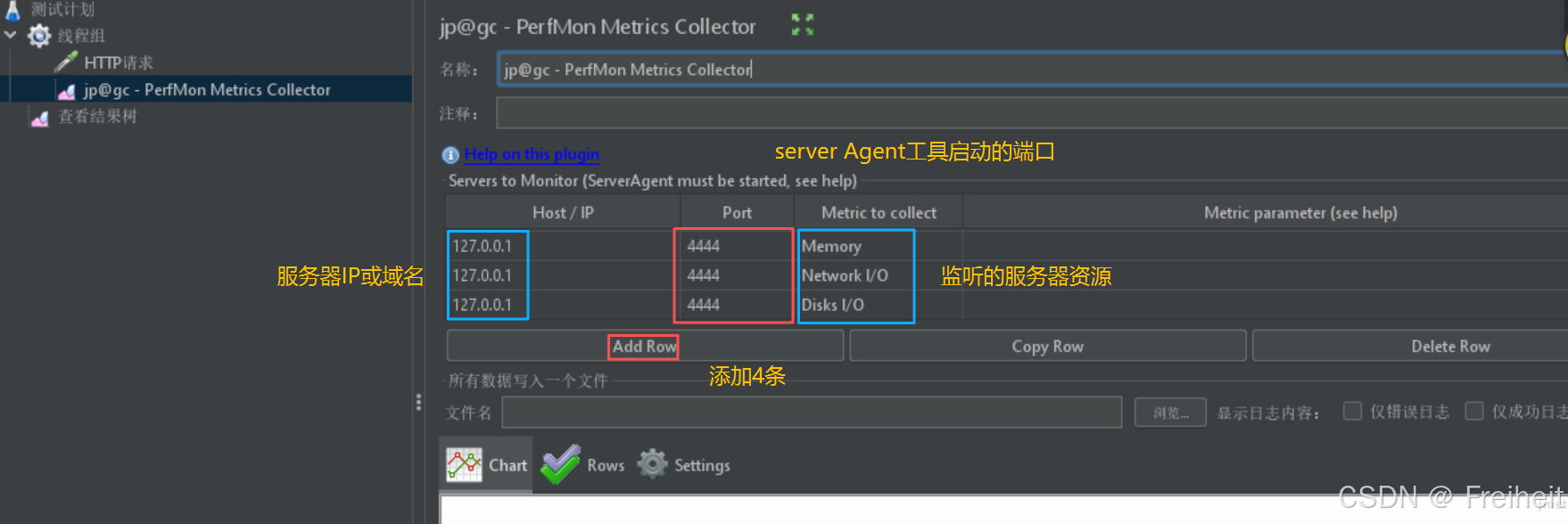
- 步骤 :
- 添加监听器jp@gc - PerfMon Metrics Collector
- 添加对应的ip地址,端口号,查看相应资源
- linux同理(只命令不同)